面向 NLP 初学者的深度 spaCy 教程
学习自然语言处理的 Scikit-learn
Introduction
不,我们今天不会构建具有数十亿参数的语言模型。我们将从小处着手,学习使用 spaCy 的 NLP 基础知识。我们将仔细研究该库的工作原理以及如何使用它轻松解决初学者/中级 NLP 问题。
这篇文章已经很长了,所以我会在这里剪掉它,然后跳到文章的重点。
What is spaCy?
spaCy 就像自然语言处理的 Sklearn。它是一个行业标准,具有广泛的功能,可以以最先进的速度、准确性和性能解决许多 NLP 任务。
其核心是管道,您可以将其视为已经在数百万个文本实例上训练的特定语言模型。
它也是 spaCy 生态系统的头部,包括 Prodigy、Forte、displaCy、explacy、ADAM、Coreferee 等数十个库和工具。[0]
spaCy 还可以与来自 TensorFlow、PyTorch 和其他框架的自定义模型握手。
目前,spaCy 支持 66 种语言作为单独的管道,并且正在缓慢添加新语言。
Basics of spaCy
在了解 spaCy 的工作原理之前,让我们安装它:
pip install -U spacyspaCy 有三个用于英语的管道,具有用于复杂任务的不同大小和功能。在本教程中,我们只需要安装中小型管道,但为了完整起见,我也包括了大型管道:
导入 spaCy 后,我们需要加载我们刚刚安装的管道之一。现在,我们将加载小的并将其存储到 nlp:
在 spaCy 生态系统中,将任何已加载的语言模型命名为 nlp 是一种约定。现在可以在任何文本上调用此对象以开始信息提取:
# Create the Doc object
doc = nlp(txt)doc 对象也是一个约定,现在它已经填充了关于给定文本的句子和单词的额外信息。
通常, doc 对象只是一个迭代器:
您可以使用切片或索引符号来提取单个标记:
>>> type(token)spacy.tokens.token.Token>>> len(doc)31
标记化是将句子分成单词和标点符号。单个标记可以是单词、标点符号或名词块等。
如果您提取多个标记,那么您将拥有一个 span 对象:
>>> span = doc[:5]
>>> type(span)spacy.tokens.span.Span>>> span.text'The tallest living man is'
spaCy 也是为提高内存效率而构建的。这就是为什么 token 和 span 对象都只是 doc 对象的视图。没有重复。
预训练的英语管道和许多其他管道具有特定于语言的规则,用于标记化和提取其词汇属性。以下是其中的 6 个属性:
一些有趣的属性是 lemma_,它返回从任何后缀、前缀、时态或任何其他语法属性中剥离的基本词,以及识别文字和字母数字的 like_num。
您将把大部分时间花在这四个对象上——nlp、doc、token 和 span。让我们仔细看看它们之间的关系。
架构和核心数据结构
让我们再次从 nlp 开始,它是引擎盖下的 Language 对象:
语言对象在数百万个文本实例和标签上进行了预训练,并以其二进制权重加载到 spaCy 中。这些权重允许您在新数据集上执行各种任务,而不必担心毛茸茸的细节。
正如我之前提到的,spaCy 拥有针对 22 种语言的经过全面训练的管道,其中一些您可以在下面看到:
对于其他 +40 种语言,spaCy 仅提供基本的标记化规则,其他功能正在慢慢与社区努力集成。
也可以直接从 lang 子模块加载语言模型:
处理完一段文本后,单词和标点符号存储在 nlp 的词汇对象中:
>>> type(nlp.vocab)spacy.vocab.Vocab
这个词汇在文档之间共享,这意味着它存储了所有文档中的所有新词。相比之下,doc 对象的词汇表只包含来自 txt 的单词:
>>> type(doc.vocab)spacy.vocab.Vocab
在内部,spaCy 以散列进行通信以节省内存,并有一个名为 StringStore 的双向查找表。您可以获取字符串的哈希值,或者如果您有哈希值则获取字符串:
>>> type(nlp.vocab.strings)spacy.strings.StringStore>>> nlp.vocab.strings["google"]1988622737398120358>>> nlp.vocab.strings[1988622737398120358]'google'
当标记进入词汇表时,它们会丢失所有特定于上下文的信息。因此,当您从词汇中查找单词时,您正在查找词位:
>>> lexeme = nlp.vocab["google"]
>>> type(lexeme)spacy.lexeme.Lexeme
词素不包含特定于上下文的信息,如词性标签、形态依赖等。但它们仍然提供单词的许多词汇属性:
>>> print(lexeme.text, lexeme.orth, lexeme.is_digit)google 1988622737398120358 False
orth 属性用于词位的散列。
因此,如果您通过 doc 对象查看一个单词,它就是一个标记。如果它来自一个词汇,它就是一个词位。
现在,让我们更多地讨论一下 doc 对象。
在文本上调用 nlp 对象会生成文档及其特殊属性。
您可以通过从 tokens 模块导入 Doc 类来手动创建文档:
Doc 需要三个参数 – 来自 nlp 的词汇表、一个单词列表和另一个列表,指定单词是否后跟空格(包括最后一个)。 doc 中的所有令牌都有此信息。
>>> len(doc)4>>> doc.text'I love Barcelona!'
Spans 也是它们自己的一个类,并公开一系列属性,即使它们只是 doc 对象的视图:
txt = """The hardest working muscle in your body is your heart:
It pumps more than 2,000 gallons of blood a day
and beats more than 2.5 billion times in a 70-year life span."""
doc = nlp(txt)
span = doc[:10]
>>> type(span)
spacy.tokens.span.Span
>>> print(span.text)
The hardest working muscle in your body is your heart
>>> print(span.start, span.end)
0 10要手动创建 span 对象,请将 doc 对象和标记的开始/结束索引传递给 Span 类:
from spacy.tokens import Span
span = Span(doc, 0, 10)
>>> span.text
'The hardest working muscle in your body is your heart'命名实体识别 (NER)
NLP 中最常见的任务之一是预测命名实体,如人、位置、国家、品牌等。
在 spaCy 中执行 NER 非常容易。处理完一段文本后,只需提取 doc 对象的 ents 属性即可:
txt = """Cleopatra wasn't actually Egyptian!
As far as historians can tell, Egypt's
famous femme fatal was actually Greek!.
She was a descendant of Alexander the Great's
Macedonian general Ptolemy"""
nlp = spacy.load("en_core_web_md")
doc = nlp(txt)
for ent in doc.ents:
print(f"{ent.text:<20}{ent.label_:<20}")
[OUT]:
Cleopatra PERSON
Egyptian NORP
Egypt GPE
Greek NORP
Macedonian NORP
Ptolemy PERSON克娄巴特拉被认为是一个人,而埃及是一个地缘政治实体(GPE)。要知道其他标签的含义,可以使用explain函数:
>>> spacy.explain("GPE")
'Countries, cities, states'
>>> spacy.explain("NORP")
'Nationalities or religious or political groups'除了打印文本,您还可以使用 spaCy 的可视实体标记器,可通过 displacy 获得:
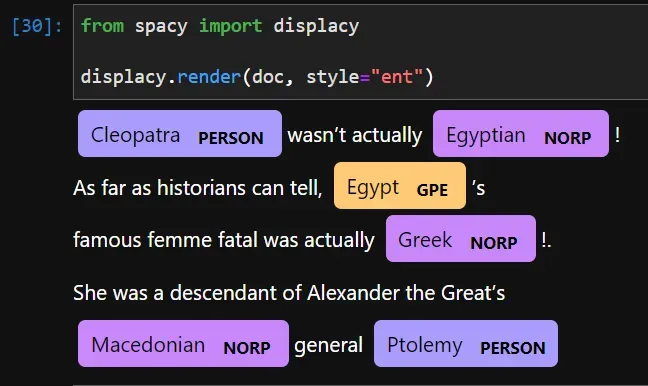
图像显示亚历山大大帝不被识别为人,因为它不是一个常见的名字。但无论如何,我们可以手动将 Alexander 标记为 PERSON。
首先,通过给它一个标签(PERSON)来提取全名作为一个跨度:
from spacy.tokens import Span
alexander = Span(doc, 31, 34, label="PERSON")
alexander
Alexander the Great然后,使用 span 更新 ents 列表:
doc.ents = list(doc.ents) + [alexander]现在,也将其替换为标签:
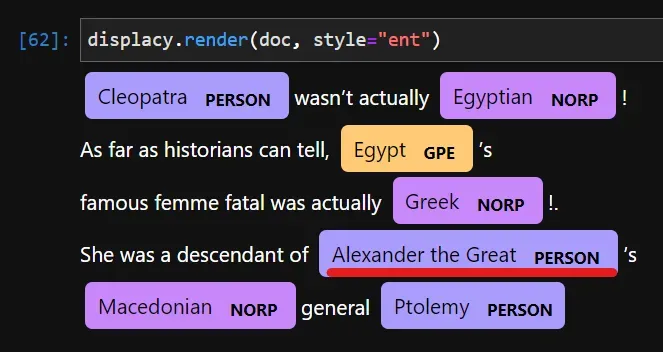
您也可以使用 set_ents 函数设置新实体:
# Leaves the rest of ents untouched
doc.set_ents([alexander], default="unmodified")预测词性 (POS) 标签和句法依赖性
spaCy 还为文档的语法分析提供了丰富的工具选择。记号的词汇和语法属性作为属性给出。
例如,让我们看一下每个标记的词性标记及其句法依赖性:
txt = "The first footprints on the moon will remain there for a million years"
doc = nlp(txt)
print(
f"{'Text':<20} {'Part-of-speech':<20} "
f"{'Dependency':<20} {'Dependency text':<20}\n"
)
for token in doc:
print(f"{token.text:<20} {token.pos_:<20} "
f"{token.dep_:<20} {token.head.text:<20}")
[OUT]:
Text Part-of-speech Dependency Dependency text
The DET det footprints
first ADJ amod footprints
footprints NOUN nsubj remain
on ADP prep footprints
the DET det moon
moon NOUN pobj on
will AUX aux remain
remain VERB ROOT remain
there ADV advmod remain
for ADP prep remain
a DET quantmod million
million NUM nummod years
years NOUN pobj for输出包含一些令人困惑的标签,但我们可以推断出其中一些标签,如动词、副词、形容词等。让我们看看其他一些标签的解释:
pos_tags = ["DET", "AUX", "ADP"]
dep_tags = ["amod", "nsubj", "nummod"]
for pos in pos_tags:
print(pos, "-->", spacy.explain(pos))
for dep in dep_tags:
print(dep, "-->", spacy.explain(dep))
[OUT]:
DET --> determiner
AUX --> auxiliary
ADP --> adposition
amod --> adjectival modifier
nsubj --> nominal subject
nummod --> numeric modifier上表的最后一列表示“第一个”、“第一个脚印”、“留在那里”等单词关系。
spaCy 包含许多更强大的语言分析功能。作为最后一个示例,以下是提取名词块的方法:
txt = """The teddy bear is named after President Theodore Roosevelt.
After he refused to shoot a captured black bear on a hunt,
a stuffed-animal maker decided to create
a bear and name it after the president."""
doc = nlp(txt)
for chunk in doc.noun_chunks:
print(chunk.text)
[OUT]:
The teddy bear
President Theodore Roosevelt
he
a captured black bear
a hunt
a stuffed-animal maker
a bear
it
the president从 spaCy 用户指南的此页面了解有关语言功能的更多信息。[0]
自定义基于规则的标记化
到目前为止,spaCy 完全控制了标记化规则。但是一种语言可能有许多不符合 spaCy 规则的特定于文化的特质和边缘情况。例如,在前面的示例中,我们看到“亚历山大大帝”作为一个实体被遗漏了。
txt = """Cleopatra wasn't actually Egyptian!
As far as historians can tell, Egypt's
famous femme fatal was actually Greek!.
She was a descendant of Alexander the Great's
Macedonian general Ptolemy"""如果我们再次处理相同的文本,spaCy 将实体视为三个标记。我们需要告诉它,像亚历山大大帝或破碎的布兰这样的名字应该被视为一个单一的标记,而不是三个,因为将它们分开是没有意义的。
让我们看看如何通过创建自定义标记化规则来做到这一点。
我们将从创建一个模式作为字典开始:
# Create a pattern
pattern = [
{"IS_ALPHA": True, "IS_TITLE": True},
{"IS_STOP": True},
{"IS_ALPHA": True, "IS_TITLE": True},
]在 spaCy 中,您可以组合使用大量关键字来解析几乎任何类型的令牌模式。例如,上述模式适用于三标记模式,第一个和最后一个标记是字母数字文本,中间一个是停用词(如 the、and、or 等)。换句话说,我们匹配“亚历山大大帝”,但没有明确告诉 spaCy。
现在,我们将使用以下模式创建一个 Matcher 对象:
from spacy.matcher import Matcher
# Init the matcher with the shared vocab
matcher = Matcher(nlp.vocab)
# Add the pattern to the matcher
matcher.add("TITLED_PERSON", [pattern])处理完文本后,我们在 doc 对象上调用这个 matcher 对象,它返回一个匹配列表。每个匹配都是一个包含三个元素的元组 – 匹配 ID、开始和结束:
# Process the text
doc = nlp(txt)
# Find all matches
matches = matcher(doc)
# Iterate over matches
for match_id, start, end in matches:
# Get the span
span = doc[start:end]
print(span.text)
[OUT]: Alexander the Great您可以随意调整图案。例如,您可以将诸如 OP 之类的量词与 reGex 关键字一起使用,或者使用 reGex 本身:
pattern = [
{"TEXT": {"REGEX": "[a-zA-Z]+"}},
{"IS_DIGIT": True, "OP": "?"}, # Match one or more times
{"DEP": "quantmod"}, # Match based on dependency
# etc.
]您可以从此处了解有关基于自定义规则的匹配的更多信息。[0]
词向量和语义相似度
NLP 的另一个日常用例是预测语义相似度。相似度分数可用于推荐系统、抄袭、重复内容等。
spaCy 使用中型模型中可用的词向量(解释如下)计算语义相似度:
nlp = spacy.load("en_core_web_md")
doc1 = nlp("What a lukeworm sentiment.")
doc2 = nlp("What a short sentence.")
>>> doc1.similarity(doc2)
0.9200780919749721所有 doc、token 和 span 对象都有这种相似性方法:
token1 = doc1[-1]
token2 = doc2[2]
>>> token1.similarity(token2)
0.5222234129905701这三个类也可以相互比较,就像一个跨度的标记:
>>> doc1[0:2].similarity(doc[3])0.8700238466262817
相似度是使用词向量计算的,词向量是词的多维数学表示。例如,这里是文档中第一个标记的向量:
array = doc1[0].vector
>>> array.shape
(300,)
>>> array[:10]
array([-0.73351 , 0.41392 , -0.4425 , -0.29127 , -0.096179, 0.097562,
0.13151 , -0.51825 , 0.10671 , 2.4144 ], dtype=float32)All about pipelines
在引擎盖下,语言模型不是一个管道,而是一个集合:
nlp = spacy.load("en_core_web_sm")
>>> nlp.pipe_names
['tok2vec', 'tagger', 'parser', 'attribute_ruler', 'lemmatizer', 'ner']当使用 nlp 处理文本时,首先将其标记化并传递到上述列表中的每个管道,然后依次修改并返回带有新信息的 Doc 对象。以下是 Spacy 文档中的说明:

但是,spaCy 没有针对您在现实世界中可能遇到的任何 NLP 问题的自定义管道。例如,您可能希望在将文本传递到其他管道之前执行预处理步骤,或者编写回调以在管道之间提取不同类型的信息。
对于这种情况,您应该学习如何编写自定义管道函数并将它们添加到 nlp 对象中,以便在您对文本调用 nlp 时自动运行它们。
以下是如何执行此操作的基本概述:
from spacy.language import Language
@Language.component("your_component")
def your_component(doc):
# Do something on the doc
print(f"There are {len(doc)} tokens in this text.")
return doc您需要通用语言类并在您的函数上装饰其组件方法。自定义函数必须接受并返回 doc 对象的单个参数。上面,我们定义了一个简单的管道,可以打印出 doc 对象的长度。
让我们将它添加到 nlp 对象中:
>>> nlp.add_pipe("your_component")
>>> nlp.pipe_names
['tok2vec',
'tagger',
'parser',
'attribute_ruler',
'lemmatizer',
'ner',
'your_component'] 如您所见,自定义管道已添加到末尾。现在,我们将对示例文本调用 nlp:
>>> doc = nlp("Bird dies, but you remember the flight.")There are 9 tokens in this text.
Working as expected.
现在,让我们做一个更严肃的例子。我们将回到“亚历山大大帝”示例并编写一个管道,将征服者的名字添加为一个实体。我们希望所有这些都自动发生,而不需要在管道之外找到实体。
这是完整的代码:
from spacy.language import Language
from spacy.matcher import Matcher
from spacy.util import filter_spans
nlp = spacy.load("en_core_web_sm")
@Language.component("titled_person")
def titled_person(doc):
pattern = [
{"IS_ALPHA": True, "IS_TITLE": True},
{"IS_STOP": True},
{"IS_ALPHA": True, "IS_TITLE": True},
]
# Create the matcher
matcher = Matcher(nlp.vocab)
# Add the pattern
matcher.add("TITLED_PERSON", [pattern])
matches = matcher(doc)
matched_spans = [Span(doc, start, end, label="PERSON") for _, start, end in matches]
# Filter the entities for potential overlap
filtered_matches = filter_spans(list(doc.ents) + matched_spans)
# Add the matched spans to doc's entities
doc.ents = filtered_matches
return doc
>>> nlp.add_pipe("titled_person")
我们定义模式,创建匹配器对象,将匹配项添加到实体,并返回文档。让我们测试一下:
txt = """Cleopatra wasn't actually Egyptian!
As far as historians can tell, Egypt's
famous femme fatal was actually Greek!.
She was a descendant of Alexander the Great's
Macedonian general Ptolemy"""
doc = nlp(txt)
>>> nlp.pipe_names
['tok2vec',
'tagger',
'parser',
'attribute_ruler',
'lemmatizer',
'ner',
'titled_person']
>>> doc.ents
(Egyptian, Egypt, Greek, Alexander the Great, Ptolemy)它按预期工作。
到目前为止,我们一直在将自定义管道附加到末尾,但我们可以控制这种行为。 add_pipe 函数具有参数来精确指定要插入函数的位置:
nlp.add_pipe("titled_person", first=True) # Beginning
nlp.add_pipe("titled_person", after="parser") # After parser
nlp.add_pipe("titled_person", before="tagger") # Before POS taggerConclusion
今天,您已经朝着掌握自然语言处理的 Scikit-learn 迈出了大胆的一步。有了本文的知识,您现在可以在 spaCy 的用户指南中自由漫游,该指南与 Scikit-learn 的一样大且信息丰富。[0]
感谢您的阅读!
我的更多故事……
文章出处登录后可见!