创建多层感知器 (MLP) 分类器模型以识别手写数字
神经网络和深度学习课程:第 16 部分

现在,我们已经熟悉了神经网络的大部分基础知识,正如我们在前面部分中讨论的那样。是时候利用我们的知识为实际应用构建神经网络模型了。
与卷积神经网络 (CNN)、循环神经网络 (RNN)、自动编码器 (AE) 和生成对抗网络 (GAN) 等其他主要类型相比,多层感知器 (MLP) 是最基本的神经网络架构类型。
Table of contents
-----------------
1. Problem understanding2. Introduction to MLPs3. Building the model
- Set workplace
- Acquire and prepare the MNIST dataset
- Define neural network architecture
- Count the number of parameters
- Explain activation functions
- Optimization (Compilation)
- Train (fit) the model
- Epochs, batch size and steps
- Evaluate model performance
- Make a prediction4. The idea of "Base Model"5. Parameters vs hyperparameters in our MLP model
- Hyperparameter examples6. Summary
- The idea of "parameter efficient"Prerequisites - My own articles
-------------------------------
1. Previous parts of my neural networks and deep learning course
Problem understanding
今天,我们将构建一个多层感知器 (MLP) 分类器模型来识别手写数字。我们有 10 个类别(0 到 9)下的 70,000 个手写数字的灰度图像。我们将使用它们来训练和评估我们的模型。
识别手写数字是一个多类分类问题,因为手写数字的图像属于 10 个类别(0 到 9)。如果我们将手写数字 2 的图像输入到我们的 MLP 分类器模型中,它将正确预测该数字是 2。
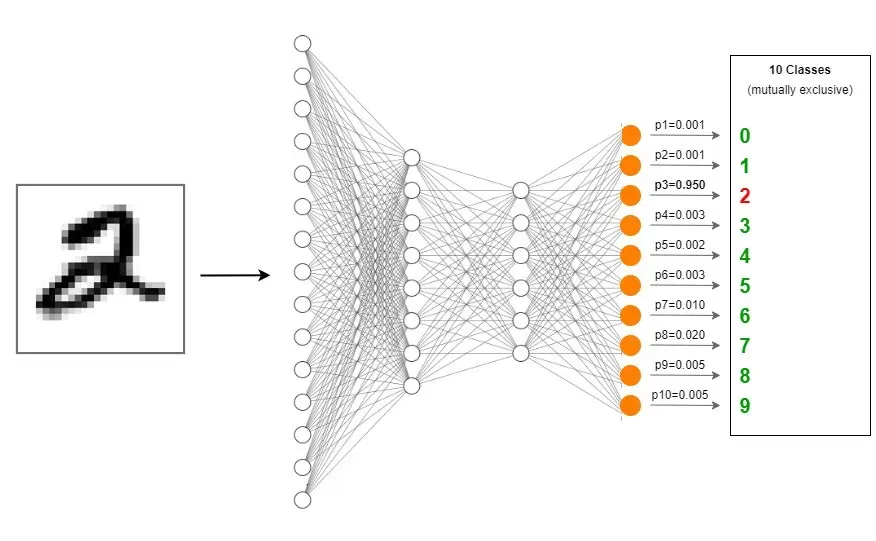
多层感知器 (MLP) 简介
在我们继续之前,有必要介绍一下多层感知器 (MLP)。我已经在第 2 部分中定义了 MLP 是什么。[0]
有关 MLP 的要点突出显示:
- 在 MLP 中,感知器(神经元)堆叠在多个层中。
- 每一层的每个节点都连接到下一层的所有其他节点。
- 单层内的节点之间没有连接。
- MLP 是完全(密集)连接的神经网络(FCNN)。因此,我们使用 Keras 中的 Dense() 类来添加图层。
- 在 MLP 中,数据在一个(正向)方向上通过层从输入移动到输出。
- 在一些文献中,MLP 也称为前馈神经网络 (FFNN) 或深度前馈网络 (DFFN)。
- MLP 是一种顺序模型。因此,我们使用 Keras 中的 Sequential() 类来构建 MLP。[0]
Building the model
我们将按照以下步骤构建模型。
设置深度学习工作场所来运行代码
我已经在第 12 部分详细解释了整个过程。[0]
如果您想在 Google Colab 中运行代码,请阅读第 13 部分。[0]
获取、理解和准备 MNIST 数据集
我们使用 MNIST(修改后的国家标准与技术研究院)数据集来训练和评估我们的模型。它包含 10 个类别(0 到 9)下的 70,000 个手写数字的灰度图像。
以下代码块显示了如何在构建模型之前获取和准备数据。我不打算解释这段代码,因为我已经在第 15 部分详细介绍过。因此,我强烈建议您在继续下一步之前阅读它。[0]
定义神经网络架构
- 网络类型:多层感知器(MLP)
- 隐藏层数:2
- 总层数:4(两个隐藏层+输入层+输出层)
- 输入形状: (784, ) — 输入层中的 784 个节点
- 隐藏层 1:256 个节点,ReLU 激活[0]
- 隐藏层 2:256 个节点,ReLU 激活[0]
- 输出层:10 个节点,Softmax 激活[0]
这是网络架构的代码。输入层是明确定义的。您也可以隐式定义它。阅读第 10 部分中的完整指南。[0]

统计参数个数
可训练参数的数量是 269,322!这是什么?通过训练我们的神经网络,我们将找到这些参数的最佳值。
这些参数包括网络中的权重和偏差项。要了解更多信息,请阅读本节。[0]
在深度学习中,这些参数用权重矩阵(W1、W2、W3)和偏置向量(b1、b2、b3)表示。要了解更多信息,请阅读本节。[0]
可训练参数的总数等于权重矩阵和偏置向量中的总元素数。
- 从输入层到第一个隐藏层:784 x 256 + 256 = 200,960
- 从第一个隐藏层到第二个隐藏层:256 x 256 + 256 = 65,792
- 从第二个隐藏层到输出层:10 x 256 + 10 = 2570
- Total tranable parameters: 200,960 + 65,792 + 2570 = 269,322
Explain activation functions
输入层不需要激活函数。
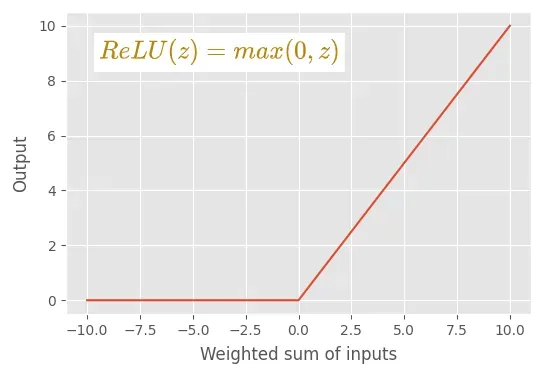
我们需要在隐藏层中使用非线性激活函数。这是因为手写数字分类是一项非线性任务。如果隐藏层中没有非线性激活函数,我们的 MLP 模型将不会学习数据中的任何非线性关系。因此,我们在两个隐藏层中都使用了 ReLU 激活函数。 ReLU 是一种非线性激活函数。[0]
在输出层,我们使用 Softmax 激活函数。它是多类分类问题的唯一选择。输出层有 10 个节点,对应于 10 个标签(类)。[0]
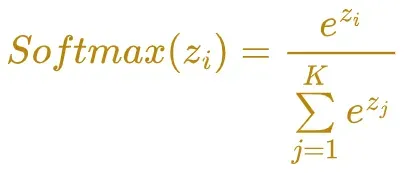
Softmax 函数计算一个事件(类)在 K 个不同事件(类)上的概率值。这些类是互斥的;如果我们对每个类别的概率值求和,我们得到 1.0。
Optimization
这也称为编译。这里我们配置学习参数。阅读本节以了解更多信息。[0]
训练(拟合)模型
在这里,我们为 fit() 方法提供训练数据(X 和标签)。
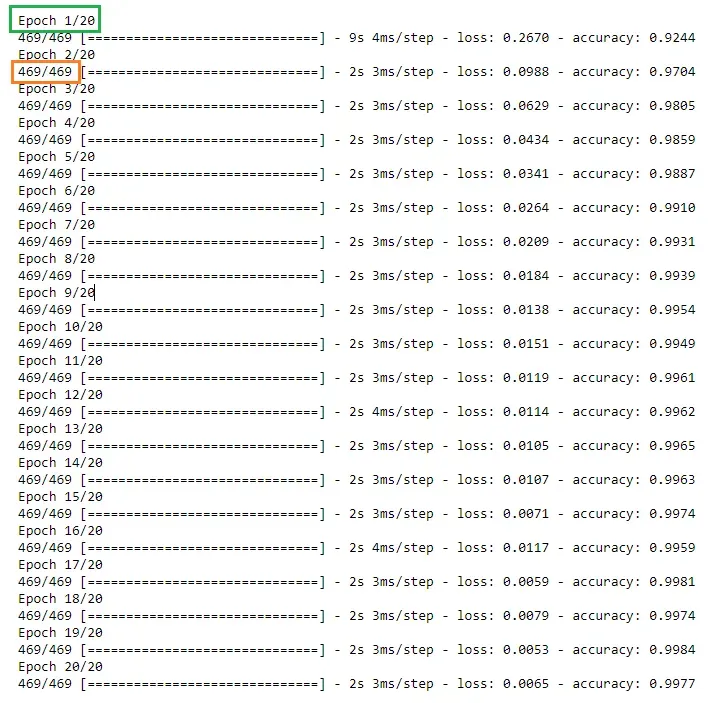
时期、批量大小和步骤
一个时期是对整个训练数据集的完整传递。在这里,Adam 优化器遍历整个训练数据集 20 次,因为我们在 fit() 方法中配置了 epochs=20。
我们将训练集分成批次(样本数)。 batch_size 是样本大小(每批包含的训练实例数)。批次数通过以下方式获得:
No. of batches = (Size of the train dataset / batch size) + 1根据上面的等式,这里我们得到 469 (60,000 / 128 + 1) 个批次。我们加 1 来补偿任何小数部分。
在一个 epoch 中,fit() 方法处理 469 个步骤。模型参数将在每个优化时期更新 469 次。
在每个 epoch 中,算法采用前 128 个训练实例并更新模型参数。然后,它采用接下来的 128 个训练实例并更新模型参数。该算法将执行此过程,直到每个 epoch 完成 469 个步骤。
Evaluate model performance
在这里,我们使用评估()方法的测试数据(X 和标签)评估我们的模型。我们从不使用训练数据来评估模型。
根据算法中涉及的随机性,您会得到略有不同的结果。您可以通过如下设置随机种子来获得静态结果。
import numpy as np
import tensorflow as tfnp.random.seed(42)
tf.random.set_seed(42)
Make a prediction
现在,我们使用 predict() 方法对看不见的数据进行预测。我们使用 test_images 集的第五张图像。该图像代表数字 4。如果我们的模型是准确的,它应该预测数字 4 的更高概率值。让我们看看。
# make a prediction
import matplotlib.pyplot as plt
digit = test_images[4]
plt.imshow(digit, cmap="binary")
digit = np.reshape(digit, (-1, 784))
digit = digit.astype('float32') / 255
MLP.predict(digit, verbose=0)
因为我们在输出层使用了 Softmax 激活函数,所以它返回一个 1D 张量,其中有 10 个元素对应于每个类的概率值。预测数字位于概率值最高的索引处。请注意,索引从零开始。
要获得概率值最高的索引,我们可以使用 np.argmax() 函数。
np.argmax(MLP.predict(digit, verbose=0))这将返回 4!因此,我们的 MLP 模型正确地对新数据进行了预测!
由于所有类都是互斥的,因此上述一维张量中所有概率值的总和等于 1.0。
The base model
我们刚刚在 MNIST 数据上构建的 MLP 分类器模型被认为是我们的神经网络和深度学习课程中的基础模型。我们将在 MNIST 数据上构建几个不同的 MLP 分类器模型,并将这些模型与这个基础模型进行比较。
我们的 MLP 模型中的参数与超参数
注意:要了解参数和超参数之间的区别,请阅读我写的这篇文章。[0]
早些时候,我们计算了 MLP 模型中的参数数量(权重和偏差项)。
即使对于一个简单的 MLP,我们也需要为以下控制参数值的超参数指定最佳值,然后是模型的输出。
Hyperparameters
- 网络中的隐藏层数
- 每个隐藏层的节点数
- 损失函数的类型
- 优化器的类型
- 评估指标的类型
- 每个隐藏层中的激活函数类型
- Batch size
- Number of epochs
- Learning rate
我们可以通过改变这些超参数的值来构建许多不同的模型。例如,我们可以向网络添加 3 个隐藏层并构建一个新模型。我们可以在每个隐藏层中使用 512 个节点并构建一个新模型。我们可以改变 Adam 优化器的学习率并构建新模型。我们可以在隐藏层中使用 Leaky ReLU 激活函数代替 ReLU 激活函数并构建一个新模型。每一次,我们都会得到不同的结果。
请注意,某些超参数的值只有一个选项。例如,损失函数的类型始终是分类交叉熵,输出层中的激活函数的类型始终是 Softmax,因为我们的 MLP 模型是多类分类模型。
Summary
我们的基本 MLP 模型获得了更高的准确度分数。然而,我们的 MLP 模型参数效率不高。即使对于这个小型分类任务,它也需要 269,322 个可训练参数用于 2 个隐藏层,每个隐藏层 256 个单元。
在下一篇文章中,我将向您介绍一个特殊的技巧,可以在不改变 MLP 模型架构和不降低模型准确率的情况下显着减少可训练参数的数量![0]
今天的文章到此结束。
如果您有任何问题或反馈,请告诉我。
我希望你喜欢阅读这篇文章。如果您想支持我作为一名作家,请考虑注册成为会员以无限制地访问 Medium。每月只需 5 美元,我将收到您的会员费的一部分。[0]
非常感谢您一直以来的支持!下一篇文章见。祝大家学习愉快!
MNIST dataset info
- 引文:Deng, L.,2012。用于机器学习研究的手写数字图像 mnist 数据库。 IEEE 信号处理杂志,29(6),第 141-142 页。
- 来源:http://yann.lecun.com/exdb/mnist/[0]
- 许可证:Yann LeCun(纽约大学 Courant 研究所)和 Corinna Cortes(纽约谷歌实验室)拥有 MNIST 数据集的版权,该数据集可根据知识共享署名-相同方式共享 4.0 国际许可证 (CC BY-SA) 获得。您可以在此处了解有关不同数据集许可类型的更多信息。[0][1]
Rukshan Pramoditha
2022–06–09[0]
文章出处登录后可见!