原文标题 :Data Wrangling with PySpark, for Beginners
初学者使用 PySpark 处理数据
从 Pandas 用户的角度看 PySpark 入门

Pandas 库是数据科学家的主要工具,由于其功能和易用性,许多人开始依赖该模块进行数据处理。
不幸的是,Pandas 在处理大数据方面存在不足,随着大数据变得越来越普遍,这带来了一个问题。
PySpark 是 Apache Spark 的 Python API,是处理大量数据的绝佳替代方案。
不幸的是,尽管 PySpark 具有巨大的实用性,但它并没有获得与 Pandas 相同的吸引力。由于它不是一个纯 Python 框架,PySpark 具有更大的学习曲线,可能会阻止其他人学习使用该工具。
在这里,我们从 Pandas 用户的角度探索 PySpark 作为数据争论的工具。
为什么 PySpark 适合大数据?
PySpark 在处理更大数据集方面优于 Pandas 的原因在于其两个最明显的特性。
- PySpark 利用并行处理
与在一台机器上运行所有操作的 Pandas 不同,PySpark 利用并行处理,这需要与多台机器并行运行操作,从而以更快的处理速度获得结果。
2. PySpark 实现惰性求值
PySpark 还通过结合惰性求值来优化其操作。简单地说,它只会在必要时得出运算结果。这种方法有助于最大限度地减少任何数据处理过程的计算和运行时间。
这与使用热切评估的 Pandas 库形成对比。 Pandas 中的所有计算都会在调用操作后立即执行,结果会立即存储在内存中。虽然这对于小型数据集是可行的,但当可扩展性成为一个问题时,它就会成为一个障碍。
PySpark vs Pandas:语法
幸运的是,PySpark 数据帧的语法与 Pandas 的语法非常相似。
我们可以通过对使用 Mockaroo 生成的模拟数据集执行多项操作来展示 PySpark 语法。[0]
为了更好的视角,我们将在适用时对 Pandas 执行相同的操作。
1. 创建 Spark 会话
火花会话用作创建和操作数据帧的入口点。它促进了 PySpark 中的所有后续操作。
默认情况下,创建的会话将使用所有可用的核心。
2. Load a dataset
让我们用 Pandas 和 PySpark 加载第一个模拟数据集。
Pandas:
PySpark:
# loading data with PySpark
df_pyspark = ss.read.csv('MOCK_DATA.csv', header=True, inferSchema=True)在加载数据时,Pandas 会自动根据它读取的数据进行推断。例如,具有数值的特征将被分配 int 或 float 数据类型。
另一方面,PySpark 没有做出这样的推论。默认情况下,PySpark 会将标题视为第一行,将所有列视为字符串变量。为了防止 PySpark 做出任何错误假设,用户必须为 header 和 inferSchema 参数分配值。
3. View the dataset
Pandas:
# view data with Pandas
df_pandas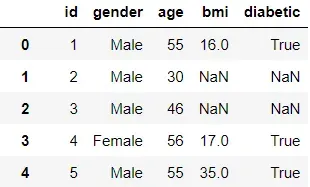
PySpark:
# view data with PySpark
df_pyspark.show()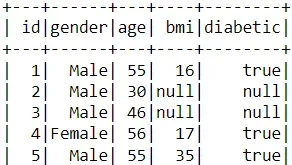
由于 PySpark 实现了延迟执行,因此它需要一个触发器来派生任何操作的结果。在这种情况下,show 函数充当触发器,让用户查看加载的数据集。
4. Select columns
Pandas:
# selecting column(s) with Pandas
df_pandas['age']
df_pandas[['age', 'bmi']]PySpark:
# selecting column(s) with PySpark
df_pyspark.select('age')
df_pyspark.select('age', 'bmi')5. 描述数据集的特征
Pandas:
# show summary of each column with Pandas
df_pandas.describe()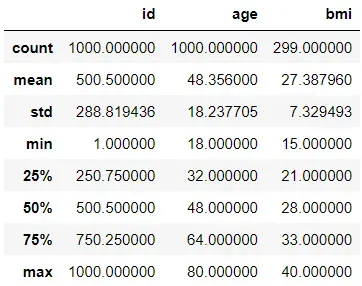
PySpark:
# show summary of each column with PySpark
df_pyspark.describe().show()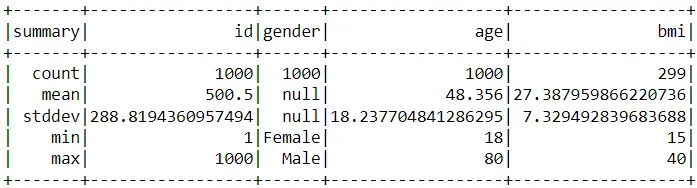
尽管 Pandas 和 PySpark 使用相同的 describe 函数,但两个包的代码输出略有不同。
首先,PySpark 不会泄露列的第 25、第 50 和第 75 个百分位值。其次,与 Pandas 不同,PySpark 包括分类特征的描述性统计(在本例中为性别列)。
6. Rename columns
使用 Pandas 和 PySpark,我们将 id 列重命名为“person_id”。
Pandas:
# rename column with pandas
df_pandas = df_pandas.rename({'id':'person_id'})PySpark:
# rename column with PySpark
df_pyspark = df_pyspark.withColumnRenamed('id', 'person_id')7. Add columns
接下来,我们添加一列显示受试者在 10 年内的年龄。
Pandas:
# add new column with Pandas
df_pandas['age in 10 years'] = df_pandas['age'] + 10PySpark:
# add new column with PySpark
df_pyspark = df_pyspark.withColumn('age in 10 years', df_pyspark['age']+10)8. Remove columns
之后,我们删除新添加的列。
Pandas:
# remove column with pandas
df_pandas = df_pandas.drop('age in 10 years', axis=1)PySpark:
# remove column with Pyspark
df_pyspark = df_pyspark.drop('age in 10 years')Pandas 和 PySpark 都使用 drop 函数删除列。唯一的区别是 PySpark 不包含轴参数。
9. Remove missing values
Pandas:
# remove null values with Pandas
df_pandas = df_pandas.dropna()PySpark:
# remove null values with PySpark
df_pyspark = df_pyspark.na.drop()10. Filtering
在这个过滤操作中,我们只保留 50 岁以上的人的记录。
Pandas:
# filtering with Pandas (option 1)
df_pandas = df_pandas[df_pandas.age>50]
# filtering with Pandas (option 2)
df_pandas = df_pandas[df_pandas['age']>50]PySpark:
# filtering with PySpark (option 1)
df_pyspark = df_pyspark[df_pyspark.age>50]
# filtering with PySpark (option 2)
df_pyspark = df_pyspark.filter(df_pyspark['age']>50)PySpark 与 Pandas 非常相似,允许使用括号过滤记录。它还允许用户使用过滤器功能过滤值。
11. Aggregation
让我们通过查找每个性别组的所有特征的平均值来执行聚合。
Pandas:
# performing aggregation with pandas
df_pandas.groupby('gender').mean()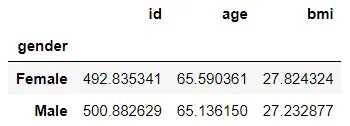
PySpark:
# perform aggregationw with PySpark
df_pyspark.groupby('gender').mean().show()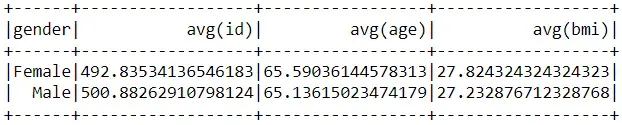
两个包之间的唯一区别是 PySpark 在输出的列名中包含聚合类型(类似于 SQL)。
12. Joins
我们现在有额外的数据显示我们想要与当前数据集合并的每个 id 的工作和收入。
Pandas:
# join datasets
df_pandas2 = pd.read_csv('MOCK_DATA2.csv')
df_pandas_join = df_pandas.merge(df_pandas2, on='id', how='inner')
# preview of data
df_pandas_join.head()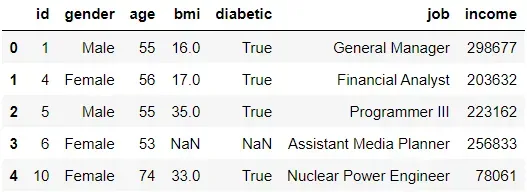
PySpark:
# join datasets
df_pyspark2 = ss.read.csv('MOCK_DATA2.csv', header=True, inferSchema=True)
df_pyspark_join = df_pyspark.join(df_pyspark2, on='id', how='inner')
# preview of data
df_pyspark_join.show(5)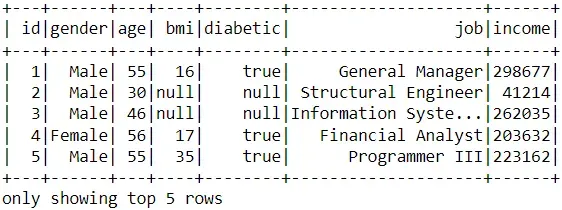
13. 转换为 Pandas 数据框
最后,我们通过使用 toPandas 函数将合并的 PySpark 数据框转换为 Pandas 数据框来结束练习。
# convert to pandas dataframe after join
df_pandas = df_pyspark_join.toPandas()
df_pandas.head()
PySpark 的缺点(对于 Pandas 用户)
尽管 Pandas 和 PySpark 数据帧之间的语法相似,但 Pandas 用户可能仍然难以适应新包。
在长时间使用 Pandas 后,Pandas 用户可能对数据处理有明显的感知。不幸的是,使用 Pandas 数据帧处理数据的一些原则可能不会延续到 PySpark。
PySpark 的一些功能可能会妨碍 Pandas 用户。
- PySpark 不支持行索引
行索引(即,为每一行分配一个索引号)在 Pandas 中可能很常见,但在 PySpark 中没有位置。习惯于通过索引访问行或使用 Pandas 遍历行的用户可能会发现难以导航 PySpark。
2. PySpark 不具备与 Pandas 相同的功能
Pandas 库提供了大量可以增强项目的工具(例如,可视化)。不幸的是,可以使用 Pandas 数据帧执行的某些任务无法使用 PySpark 数据帧执行。
注意:对于这种情况,用户可以使用 toPandas 函数将 PySpark 数据帧转换为 Pandas 数据帧。
3. PySpark 错误更难调试
PySpark 错误消息可能难以解释和解决。此外,PySpark 不像 Pandas 那样拥有相同数量的社区支持。因此,在 PySpark 中进行调试可能是一项艰苦的工作。
Conclusion

尽管数据科学家可以单独使用 Pandas 模块成功完成许多项目,但如果他们缺乏适当的方法来处理更大的数据集,他们就不应该满足于自己的技能。毕竟,随着行业转向大数据解决方案,像 PySpark 这样的工具将不可避免地成为必需品。
幸运的是,尽管 Pandas 和 PySpark 之间存在差异,但两个包共享相似的语法,因此从一个包过渡到另一个包应该是可行的。
祝您在数据科学工作中好运!
文章出处登录后可见!