文@870203
点云语义分割,现已加入 MMDet3D 全家桶!
0 写在前面
近年来,随着自动驾驶和机器人等领域的飞速发展,3D 点云处理得到了学术界和工业界的广泛关注,基于点云的物体识别、检测、分割等任务中涌现出了一大批优越的算法。有感于此,MMDet3D 项目上线以来,致力于集成最经典和最前沿的点云感知算法,至今已一年有余,得到了社区 (还算) 热烈的反响。
但是,如果有用户认为 MMDet3D 库如其名,只支持 3D 点云检测,那想必这位朋友没有认真看我们的README和每月的 Release Highlights (虽然笔者也几乎没有看过,以及,程序员讨厌看文档不是天性吗 x)——我们还支持多模态 3D 检测、纯视觉 3D 检测以及 3D 语义分割模型。纯视觉方法已经在这篇中得到介绍,本文将主要语义分割方面的工作。
1 点云语义分割简介
与 2D 图像的语义分割任务类似,3D 点云语义分割的输入是一个无序点集 ,输出则是逐点的语义标签
,其中
是点云除了坐标以外的特征数,常见的有 RGB 颜色、归一化坐标和反射强度等。
值得注意的是,和基于点云的 3D 检测类似,点云语义分割在室内和室外场景下有很大的不同,这是由于室内点云往往点的分布较为均匀,而室外点云存在近处稠密、远处稀疏的问题。虽有模型旨在打通二者之间的壁垒,但当前主流算法的推理策略大都大相径庭——对于室内点云,采取类似滑动窗口 (sliding window) 的方法,将完整的场景截取为多个 、点数固定的小块,模型只需处理局部点云块;对于室外点云这显然是行不通的,因为不同块点云密度的差异会严重影响模型性能,此外出于速度的考虑,这些模型往往直接作用于全场景点云。

由于 MMDet3D 目前只支持了室内点云语义分割的算法,本文将聚焦这一方向,等将来支持了室外分割算法再拿来水一篇 PR (雾)。
2 相关工作介绍
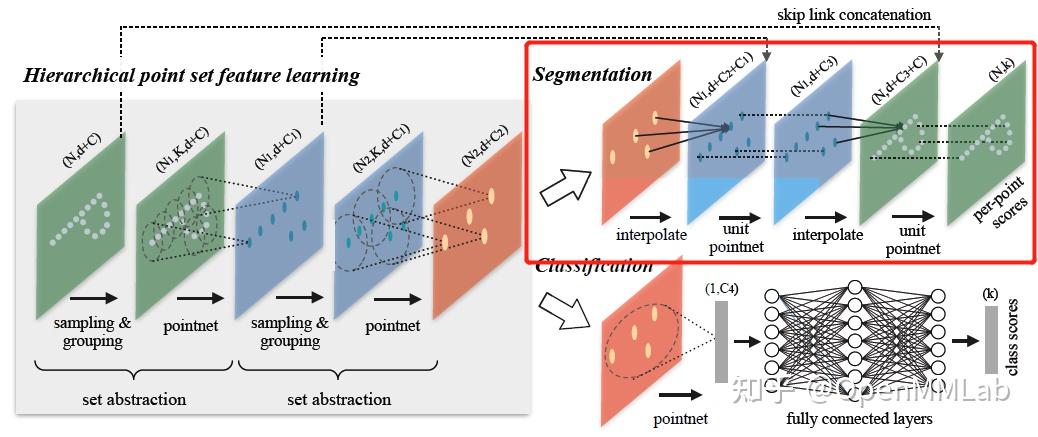
相比基于点云的 3D 检测,点云语义分割是一个稠密预测的问题,不存在 anchor 设计、loss target 分配等复杂的问题。已有点云分割器大多采用经典的 U-Net 结构,由一个编码器不断降采样点云并提取特征,再由一个解码器上采样点云并实现特征融合,最终预测点云的语义分割掩码。这是由于这一任务设定上相对简单,因此几乎所有提出新的点云特征提取机制的文章都会包含分割实验来证明其方法的有效性。在笔者看来,室内点云分割任务最重要的就是如何有效提取局部点云的几何特征,有以下几种代表性的方法:
- 只基于全局特征的 PointNet,及其变体 PointNet ,这类方法缺少近邻点之间的互动 (interaction)
- 挖掘邻域点关系的模型,例如基于图卷积网络的 DGCNN 等,基于注意力机制 (attention) 的 PointASNL 等和基于 RNN 的 RSNet 等
- 基于点卷积 (point convolution) 的方法,最近两三年非常流行,例如 PointConv, KPConv, PAConv,这类方法的显存占用和计算复杂度是一个问题
- 基于 Transformer 的方法,例如 Point Transformer,效果也是非常惊人
这里也稍微提一下室外场景分割的做法,因为需要一次性处理所有场景点,受限于显存和计算量等,大多算法都将 3D 点云变换到 2D 网格 (grid),再用 2D CNN 处理,常见的 2D 网格表征有前视图 (frontal view-image), range image, 鸟瞰图 (bird's-eye-view, BEV image) 等;当然也有直接对点进行操作的方法,例如 RandLA-Net 等。这部分 Cylinder3D 一文进行了很详尽的回顾,顺带一提 Cylinder3D 也是我们目标复现的算法之一,并以此为基础在 MMDet3D 中支持室外场景分割任务,敬请期待。
3 主流数据集
目前最常见的室内点云语义分割数据集是 S3DIS 和 ScanNet,室外数据集有 SemanticKITTI, Semantic3D, nuScenes 等。我们着重介绍前两者,MMDet3D 中有支持哦~
- S3DIS:S3DIS 数据集包含了 3 栋建筑中 6 个区域的一共 271 间房间,房间类型涵盖了常见的室内场景,如会议室、办公室、过道、储藏间等。该数据集总共扫描有约 2.73 亿个点,每个点包含三维坐标及 RGB 颜色信息,并标注有一个明确的语义标签。S3DIS 数据集共有 13 类标注,分别为:天花板、地板、墙壁、横梁 (beam)、支柱 (column)、窗户、门、桌子、椅子、沙发、书架、挂板 (board,如白板) 和其他类 (clutter)。由于官方没有提供训练-验证-测试集的划分,MMDet3D 支持灵活的选择一个区域进行留一验证,例如论文中最常见的在区域 1, 2, 3, 4, 6 训练,在区域 5 上测试
- ScanNet:ScanNet 数据集共包含 1,613 个扫描场景,其中训练集 1,201 个、验证集 312 个、测试集 100 个。该数据集中每个点同样提供三维坐标及 RGB 颜色信息,但是,有的点并无标注信息(unannotated)。遵循前人工作,MMDet3D 选取其中 20 类进行实验,分别是:墙壁、地板、橱柜、床、椅子、沙发、餐桌、门、窗户、书架、挂画、柜台、办公桌、窗帘、冰箱、浴帘、马桶、水槽、浴缸和其他类。我们遵循了该数据集官方的训练-验证-测试集划分,并提供指令便于用户生成提交到官方在线 benchmark 的结果。值得一提的是,相比使用 RGB-D 相机扫描而得的 S3DIS 数据,ScanNet 数据由 Matterport 仪器采集,物体部分 (part) 缺失的情况比 S3DIS 严重,看起来显得更加“支离破碎”

4 XX 都能懂的 MMDet3D 分割教程
现在 MMDet3D 已经实现了 PointNet 和 PAConv 两个点云语义分割算法,DGCNN 也预计一周内将要完成。如前所述,一个分割器只由编码器和解码器组成,这里我们以 PointNet (SSG) 为例展示一下如何用 MMDet3D 快速搭建点云分割模型。
4.0 demo
我们提供了 PointNet (SSG) 在 ScanNet 数据集上的 demo,可以让用户体验我们强大的可视化工具 (并检验一下环境配好没有,因为引入 MMSeg 导致的依赖关系令人头大…)
4.1 编码器
编码器在 MMDet3D 中又称为骨干网络 (backbone,为了和 3D 检测模型一致),PointNet 的编码器由四个 PointSAModule (set abstraction) 构成,分别进行降采样点和特征提取。
backbone=dict(
type='PointNet2SASSG',
in_channels=6,
num_points=(1024, 256, 64, 16),
radius=(0.1, 0.2, 0.4, 0.8),
num_samples=(32, 32, 32, 32),
sa_channels=((32, 32, 64), (64, 64, 128), (128, 128, 256), (256, 256, 512)),
fp_channels=(),
norm_cfg=dict(type='BN2d'),
sa_cfg=dict(
type='PointSAModule',
pool_mod='max',
use_xyz=True,
normalize_xyz=False)) 4.2 解码器
PointNet 的解码器由四个 PointFPModule (feature propagation) 构成。损失函数采用了简单的交叉熵损失,值得注意的是,这里使用了 `class_weight` 这一参数,这是为了解决点云分割中不同类别物体点数极度不均衡的问题,经试验对结果会有 ~1% mIoU 的影响。
decode_head=dict(
type='PointNet2Head',
num_classes=20,
ignore_index=20,
fp_channels=((768, 256, 256), (384, 256, 256), (320, 256, 128),
(128, 128, 128, 128)),
channels=128,
dropout_ratio=0.5,
conv_cfg=dict(type='Conv1d'),
norm_cfg=dict(type='BN1d'),
act_cfg=dict(type='ReLU'),
loss_decode=dict(
type='CrossEntropyLoss',
use_sigmoid=False,
# computed in pre-processing
class_weight=[
2.389689, 2.7215734, 4.5944676, 4.8543367, 4.096086, 4.907941,
4.690836, 4.512031, 4.623311, 4.9242644, 5.358117, 5.360071,
5.019636, 4.967126, 5.3502126, 5.4023647, 5.4027233, 5.4169416,
5.3954206, 4.6971426
],
loss_weight=1.0)) 4.3 数据流程 (pipeline)
数据预处理相比 3D 检测也简单许多,简单拆解如下:
- `PointSegClassMapping`:将原始分割掩码的标签 id 转换为连续标签 (例如训练 20 类就转换成 [0, 20)),不使用的类转换为 `ignore_index`,便于计算时忽略
- `IndoorPatchPointSample`:如前所述,将整个场景的点云进行切块作为网络输入。有的情况下`use_normalized_coord=True`,这意味着我们使用归一化坐标作为额外的特征,即绝对 XYZ 坐标除以该场景点云最大的 XYZ 值。这一特征的意义在于,例如 `normalized_z` 接近 0 则该点很可能属于地板,而接近 1 则很可能是天花板
- `NormalizePointsColor`:将点的 RGB 颜色信息归一化至 [0, 1]
train_pipeline = [
dict(
type='LoadPointsFromFile',
coord_type='DEPTH',
shift_height=False,
use_color=True,
load_dim=6,
use_dim=[0, 1, 2, 3, 4, 5]),
dict(
type='LoadAnnotations3D',
with_bbox_3d=False,
with_label_3d=False,
with_mask_3d=False,
with_seg_3d=True),
dict(
type='PointSegClassMapping',
valid_cat_ids=(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 14, 16, 24, 28,
33, 34, 36, 39),
max_cat_id=40),
dict(
type='IndoorPatchPointSample',
num_points=num_points,
block_size=1.5,
ignore_index=len(class_names),
use_normalized_coord=False,
enlarge_size=0.2,
min_unique_num=None),
dict(type='NormalizePointsColor', color_mean=None),
dict(type='DefaultFormatBundle3D', class_names=class_names),
dict(type='Collect3D', keys=['points', 'pts_semantic_mask'])
] 出于复现的目的,我们这里仅仅使用了 PointNet 原文的数据增广策略;在 PAConv 中我们还实现了诸如旋转、缩放、扰动和颜色丢弃多种增广方法,实验表明对性能有 ~3% mIoU 的提升。
4.4 优化器
我们采用了 Cosine 衰减的 Adam 优化器,它比原文的 Step 衰减有巨大的提升 (>5% mIoU);我们采用了极大的 `weight_decay=1e-2` 作为正则项,相比 `1e-4` 有 ~2% mIoU 的提升;最后,更长的训练轮数也有很小的帮助,相比训练 150 轮,训练 200 轮提升了 ~0.2% mIoU。
optimizer = dict(type='Adam', lr=0.001, weight_decay=0.01)
optimizer_config = dict(grad_clip=None)
lr_config = dict(policy='CosineAnnealing', warmup=None, min_lr=1e-5)
runner=dict(type='EpochBasedRunner', max_epochs=200)4.5 总结
以上简要叙述了 PointNet (SSG) 在 ScanNet 数据集上的复现流程,最终相比原论文,我们达到了超过 10% mIoU 的提升,总结出的一些技巧是通用的,比如更长的训练时间、Cosine 学习率衰减,这些也用在了 PAConv 的复现中,此处不予赘述。
很有趣的是,PointNet 在 ScanNet 数据集上使用或不使用 RGB 颜色作为输入信息,训练得到的分割器性能差距在 1% 以内;但是对于人眼来说,颜色信息可以极大的辅助判断物体的完整性 (颜色的一致性,如桌面/椅背都是同色)。我推测这或许是因为 PointNet 的最大池化操作过于激进,导致相邻点之间的颜色信息无法充分互相作用。
5 后记
本文简要介绍了点云语义分割这一任务和 MMDet3D 的支持算法,欢迎大家使用 MMDet3D 来支持自己的研究和工作。
实际上笔者有幸于今年四月加入 MMDet3D 团队实习,初与 mentor 交流时,听说要做分割也很意外,不过几个月尝试下来,确实有很多可以复用的代码,也重构了一些模块,使 MMDet3D 更加通用高效,此前和同事打趣说,我们真应该改名叫 MMScene3D hhh
最后放个卫星,MMDet3D 正在进行一个巨大坐标系重构项,以解决代码里现存的不少令人费解的 hack/trick,我们将统一 LiDAR, Depth, Camera 三大坐标系 (虽然语义分割并未受到影响),敬请期待 MMDet3D 之后的 PR 介绍!
References
[1] Armeni I, Sax S, Zamir A R, et al. Joint 2d-3d-semantic data for indoor scene understanding[J]. arXiv preprint arXiv:1702.01105, 2017.
[2] Behley J, Garbade M, Milioto A, et al. Semantickitti: A dataset for semantic scene understanding of lidar sequences[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 9297-9307.
[3] Qi C R, Su H, Mo K, et al. Pointnet: Deep learning on point sets for 3d classification and segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 652-660.
[4] Qi C R, Yi L, Su H, et al. PointNet : Deep Hierarchical Feature Learning on Point Sets in a Metric Space[J]. Advances in Neural Information Processing Systems, 2017, 30.
[5] Wang Y, Sun Y, Liu Z, et al. Dynamic graph cnn for learning on point clouds[J]. Acm Transactions On Graphics (tog), 2019, 38(5): 1-12.
[6] Yan X, Zheng C, Li Z, et al. Pointasnl: Robust point clouds processing using nonlocal neural networks with adaptive sampling[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 5589-5598.
[7] Huang Q, Wang W, Neumann U. Recurrent slice networks for 3d segmentation of point clouds[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 2626-2635.
[8] Wu W, Qi Z, Fuxin L. Pointconv: Deep convolutional networks on 3d point clouds[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 9621-9630.
[9] Thomas H, Qi C R, Deschaud J E, et al. Kpconv: Flexible and deformable convolution for point clouds[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 6411-6420.
[10] Xu M, Ding R, Zhao H, et al. PAConv: Position Adaptive Convolution with Dynamic Kernel Assembling on Point Clouds[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 3173-3182.
[11] Zhao H, Jiang L, Jia J, et al. Point transformer[J]. arXiv preprint arXiv:2012.09164, 2020.
[12] Hu Q, Yang B, Xie L, et al. Randla-net: Efficient semantic segmentation of large-scale point clouds[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 11108-11117.
[13] Zhu X, Zhou H, Wang T, et al. Cylindrical and asymmetrical 3d convolution networks for lidar segmentation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 9939-9948.
[14] Dai A, Chang A X, Savva M, et al. Scannet: Richly-annotated 3d reconstructions of indoor scenes[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 5828-5839.
[15] Hackel T, Savinov N, Ladicky L, et al. Semantic3d. net: A new large-scale point cloud classification benchmark[J]. arXiv preprint arXiv:1704.03847, 2017.
版权声明:本文为博主OpenMMLab原创文章,版权归属原作者,如果侵权,请联系我们删除!