



原文标题 :Finding the Best Classification Threshold for Imbalanced Classifications with the Interactive Confusion Matrix and Line Charts
使用交互式混淆矩阵和折线图找到不平衡分类的最佳分类阈值
使用 binclass-tools 惊人的 Python 包将您对二进制分类问题的分析提升到一个新的水平

即将训练分类模型的数据科学家经常会发现自己正在分析生成的混淆矩阵,以查看模型的性能是否令人满意。让我们仔细看看这是怎么回事。
引入混淆矩阵
术语“混淆”是指模型可以正确或错误地预测观察结果,然后在分类中可能会混淆。如果我们考虑一个二元分类模型(其可能的结果只能是两个,例如,真或假),模型的混淆矩阵是一个矩阵,它组织为测试数据集的目标变量获得的预测输出(作为输入给定)到模型)与该变量在数据集中的真实值相关。通过这种方式,可以识别正确预测的数量和错误预测的数量(假阳性和假阴性)。将问题中感兴趣的类别定义为正类(例如,交易是欺诈性的,因此正类为真),假阳性是那些预测为真(预测为正类)但实际上不是(假预测)的观察结果);另一方面,假阴性是那些预测为假的观察结果(预测为负类),但实际上不是(假预测)。了解了这些定义后,您可以自己得出真阳性和真阴性的含义。
模型结果的这种排列允许了解模型的性能是否符合预期。通常,二元模型的混淆矩阵如下所示:

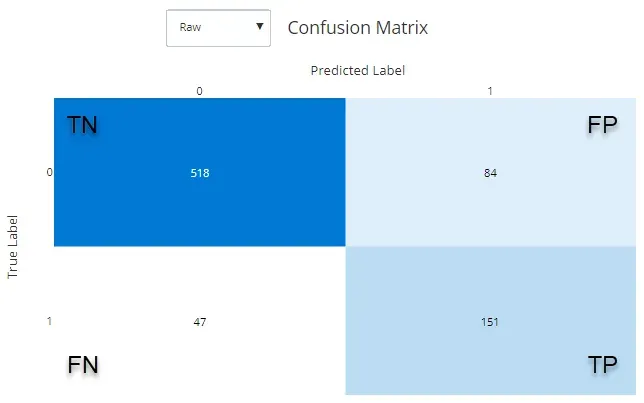
一旦确定了混淆矩阵的 4 个象限的值,就可以确定衡量模型性能的定量和定性指标,如参考文献所示(参见参考文献 1)。
乍一看,混淆矩阵的四个象限的值似乎对于所分析的模型是不变的。然而,在幕后,这些值是根据一个非常具体的假设计算的。
注意分类阈值
二元分类模型主要返回目标变量中每个类别的相似概率分数,它衡量了为该观察获得的预测是正类的可能性有多大。如果你使用 Python 训练分类模型,我们所说的分数通常是通过 Scikit-learn predict_proba 函数获得的。该分数具有以下属性:
- 它是一个介于 0 和 1 之间的实数
- 将观察与正类相关联的分数和将同一观察与负类相关联的分数相加,我们得到 1
任何学过一点数学的人都会认识到,这些属性与有助于定义概率测度的属性相同。然而,我们的分数并不是真正的概率度量,即使可以通过应用称为模型校准的转换使我们的分数近似于概率度量。也就是说,我们之前谈到的混淆矩阵值的假设如下:[0]
一般而言,计算与二元分类模型相关联的混淆矩阵所示的 TP、TN、FP、FN 的值时,考虑到预测为正类,如果分数大于或等于 0.5,则为负类如果小于 0.5
上一条语句的 0.5 值称为分类阈值,可以在 0 和 1 之间变化。要了解阈值的用途,假设您已经训练了一个二元分类模型来检测房屋火灾中的烟雾。您的模型将在安装在厨房的真实烟雾探测器中实施。现在假设测试产品的实验室将检测器安装在烤肉的炉子附近。如果传感器阈值设置为较低的值,则检测器很可能会在烤肉时报告火灾(误报)。为了使探测器更可靠,实验室技术人员应在多次实验后将阈值提高到被认为适合识别真正火灾的值。
改变阈值,我们去修改预测的类。例如,使用 0.5 的阈值(分数 0.54 大于阈值 0.5,因此观察结果为真)以 0.54 的分数分类为真的观察,如果阈值更改为 0.6(分数 0.54 小于阈值 0.6,所以它是错误的)。因此,通过改变阈值,我们前面提到的所有定量和定性指标(例如准确率和召回率)也会发生变化。所以,很明显:
分类器性能随着阈值的变化而变化
因此,您很好理解,使用默认值为 0.5 的阈值的分类器可能会导致结果质量低下,尤其是在处理不平衡数据集时,因为不平衡数据的概率分布往往会偏向多数阶级。
此时,一旦模型训练完毕,问题是:“好的,现在我应该为我的模型使用什么阈值?”。通常适用于任何复杂决策情况的坏消息是:
没有适用于所有情况的最佳阈值。这取决于需要满足的业务。
在详细介绍阈值调整的不同情况之前,让我们快速提醒一下最常用于不平衡分类的指标,这些指标是更复杂的模型来训练和测量。
不平衡分类的评估指标
让我们在下面回顾一些对初学者有用的基本概念,以便能够衡量不平衡二元分类的性能。随着分析的案例不同,相同的概念将有助于解释最佳阈值。
精确召回权衡
假设您需要训练一个二元分类模型来检测欺诈性信用卡交易。这是一个典型的不平衡问题,兴趣类(欺诈交易=正类)中的标签数量远少于负类中的标签数量。在这种情况下,为了评估分类器而经常考虑的指标是 Precision 和 Recall(在平衡问题的情况下,通常考虑 Sensitivity 和 Specificity)。
现在,需要问的问题是:“将健康交易归类为欺诈性交易,还是将欺诈性交易归类为健康更严重?”。如果对健康的交易强制进行检查,您的成本只是与检查所需的时间有关。另一方面,如果欺诈交易被错误分类为健康,欺诈的成本明显高于前一种情况。
被错误分类为健康(负类)的欺诈交易(正类)属于假负(FN)集。当 FN 减少时,一个增加(保持 TP 数量不变)的指标是精确召回。其实看Recall的定义我们有:

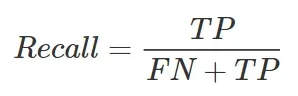
从上面的公式可以看出,如果我们想通过使其趋于 0 来最小化 FN 的数量,那么 Recall 的值将趋于 TP/TP = 1。
因此,第一件事就是将阈值移动到使召回率最大化为 1 的值。不幸的是,人们会发现要使召回率趋于 1,必须将阈值移动到非常接近 0。但这意味着将几乎所有交易归类为欺诈!实际上,召回公式中不存在的误报 (FP) 的数量不成比例地增长,并且分类器区分所有预测为欺诈的观察结果实际上是欺诈的能力被取消。换句话说,称为 Precision 的指标的值急剧下降到零,从定义它的以下公式可以看出:

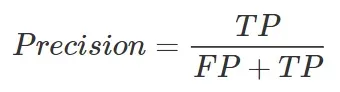
从上式可以看出,如果FPs趋向于一个比TP大很多的N,Precision会趋向于TP/N~0
你学到的是著名的 Precision-Recall 权衡,它包括以下内容:
除非您处理的是完美模型(FP = FN = 0),否则不可能同时拥有高精度和高召回率。对于不太完美的模型,如果增加 Precision,就会降低 Recall,反之亦然。
下面显示了示例模型的 Precision-Recall 曲线,展示了上述权衡:

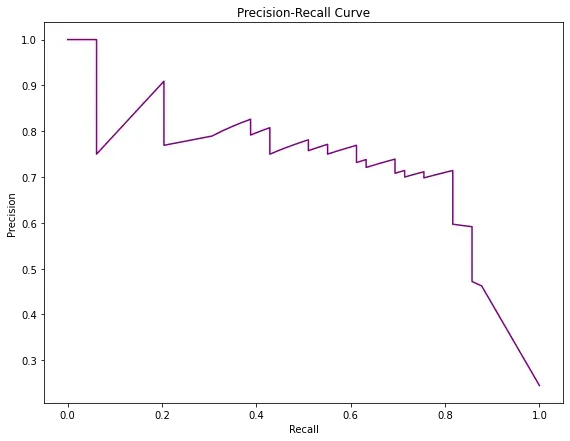
为了同时考虑 Precision 和 Recall,我们可以考虑由两者的调和平均值给出的度量,也称为 F1-score:

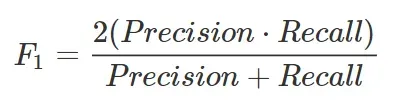
如果您希望对定义指标中的一个或另一个赋予更多权重,您可以通过引入“不平衡”β系数来推广该公式:

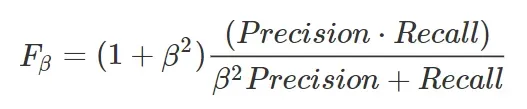
例如,如果您认为 Recall 的重要性是 Precision 的两倍,则可以将 β 设置为 2。相反,如果您认为 Precision 比 Recall 重要 2,则 β 将为 ½。
回到我们的欺诈交易问题,确定 Recall 比 Precision 重要得多,您可以考虑 β > 1 并优化阈值,使 F-score 取最大值。
从精确度、召回率和 F 分数到马修斯相关系数
有一个重要的事实需要考虑。 Precision 和 Recall(因此还有 F-score,它是两者的函数)认为正类是感兴趣的类别,并回答以下问题:
“在所有阳性预测示例(FP + TP)中,有多少阳性检测(TP)是正确的?” (精确)
“在所有实际的正例(FN + TP)中,我们能够识别出多少个正例(TP)?” (记起)
如果您仔细查看上述定义,真阴性 (TN) 永远不会出现。如果感兴趣的类别(稀有类别)被标记为阳性(大多数情况下都是如此),这可能不是问题。例如,在这种情况下,F1 分数仍然是不平衡分类的有效指标。事实上,如果模型不能正确预测负类,错误的预测就会输入 FP。所以 Precision 的值会下降,因为它被定义为 TP/(FP+TP),因此 F1-score 的值也会下降。总之,在这种情况下,正确预测的负类越少,F1 分数就越低。
有时可能会发生感兴趣的类别没有标记为正面,而是标记为负面的情况。在这种情况下,F1 分数的值会误导对问题的正确分析。有关更多详细信息,请查看参考资料(参考文献 7)。
因此,需要引入一个新的指标,该指标也将 TN 考虑在内,并且无论正类分配如何都是稳定的。
那些研究过一些统计数据的人肯定会遇到克拉梅相关系数(Cramér’s V),它衡量两个分类变量之间的关联强度。好吧,在 1975 年,Brian W. Matthews 引入了一个相关系数,它是适用于 2×2 混淆矩阵的 Cramér V 的一个特例。我们正在谈论定义如下的马修斯相关系数(MCC):

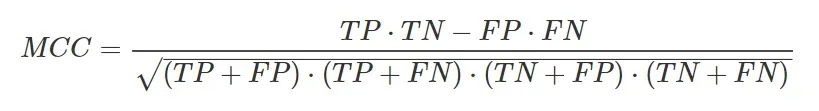
除了通常的相关系数外,MCC 还采用 [-1, 1] 范围内的值。在分类的情况下,值 -1 表示模型预测正类和负类的方式与它们在目标变量中的实际值完全相反。如果 MCC 取值 0,则模型随机预测正类和负类。在值为 1 的情况下,模型是完美的。此外,如果正类重命名为负类,则 MCC 是不变的,反之亦然。 MCC的主要特点如下:
只有当模型能够正确预测大多数正面观察和大多数负面观察时,MCC 才是唯一得分高的指标。
在快速回顾了不平衡分类问题(处理起来最复杂)中最常用的指标之后,我们可以回到本文的主题,即如何在这些情况下设置阈值。
为您的模型选择正确的阈值
确定阈值的“最佳值”意味着找到最大化或最小化特定目标函数的值,它衡量模型的好坏并适合要解决的业务问题。归根结底,这是一个优化问题。
基本上,有两种优化阈值的方法:
- 基于特定指标的优化
- 基于成本的优化
在第一种情况下,选择感兴趣的指标(例如,F2-score 或 MCC)并确定所选指标指示模型最大性能的阈值(这意味着必须最大化或最小化指标取决于它的性质)。
另一方面,在第二种情况下,使用了所谓的成本矩阵,因此可以将成本与混淆矩阵的每个类别相关联。通过这种方式,通过最小化与每个类别相关的成本总和来给出最佳阈值。
一旦确定了感兴趣的目标函数,无论是度量还是成本,以及是否需要最大化或最小化,都可以通过操作所谓的阈值移动来找到最佳阈值:
- 将阈值从 0 变为 1,步长为 0.01,记录每个阈值的目标函数的所有值。
- 选择最大化(或最小化)函数的阈值。
但是,以这种方式确定的值将严格依赖于训练数据集,并且可能不是对阈值最佳值的良好估计。
最近开发了一种通用方法,它始终基于从训练数据集中获得的目标函数的值,称为 GHOST(通用阈值移位程序)。总之,它使用使用分层随机抽样绘制的训练数据集的 N 个子集,以便它们保留类分布。然后,对于每个子集,它应用由每个阈值给出的目标函数。这样,对于每个阈值,将有由 N 个子集给出的目标函数的 N 个值。此时,它会计算上述值的每个阈值的中值,以便您仅获得与阈值相关联的单个“稳定”值。您可以在参考资料中找到更多详细信息(参考文献 8)。
使用 binclass-tools Python 包控制一切
既然深入分析的所有方面的大图更加清晰,您就会明白,主要困难之一是随着阈值的变化而了解手头最重要的指标。只有这样,您才能根据所选的业务标准快速了解模型的性能何时接近所需的性能。
正是这种需求促使我开发了一个新的 Python 包,其中包含一些用于此类分析的有用工具。我们正在谈论令人惊叹的 binclass-tools 包:


让我们看一下该软件包提供的一些最重要的工具。
交互式混淆矩阵
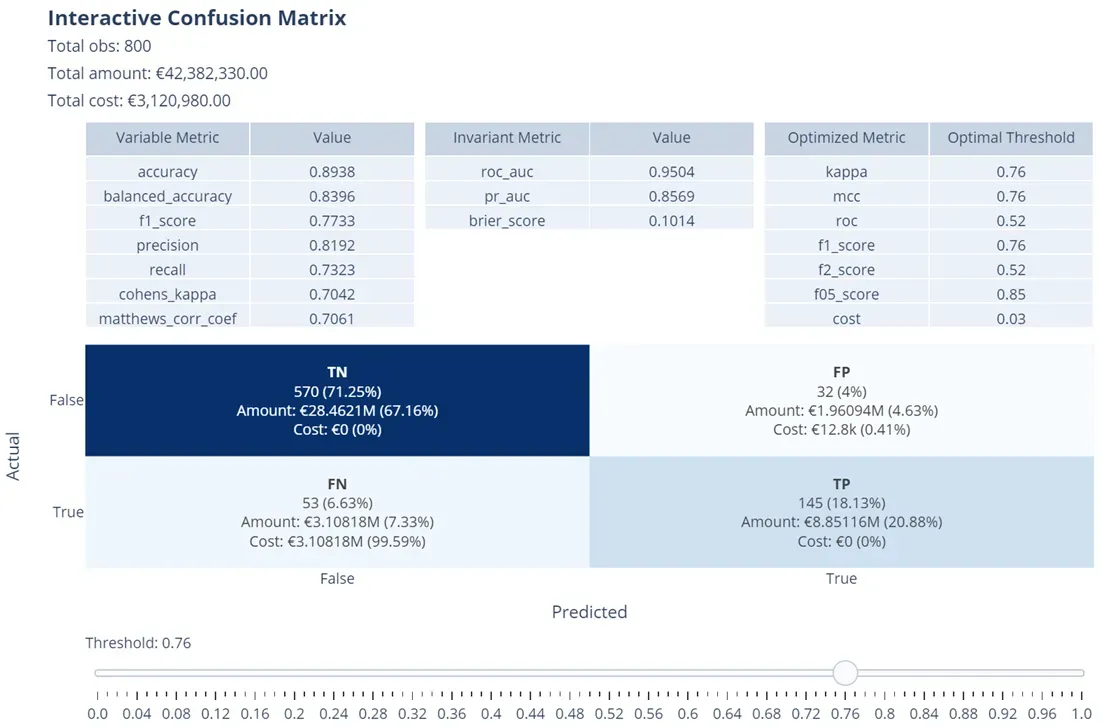
软件包中最有趣的工具之一是交互式混淆矩阵,这是一个交互式绘图,可让您查看二元分类最重要的指标如何随着阈值的变化而变化,包括与矩阵中的类别相关的任何金额和成本:


从图 9 可以看出,阈值与范围从 0 到 1 的滑块相关联,具有用户选择的步长(在示例中为 0.02)。随着滑块的移动,一些显示的测量值和指标会相应改变。
剧情分为两部分:
- 底部是混淆矩阵,它突出了属于 TP、TN、FP、FN 类别的观察数量以及与单个观察相关的数量或成本的可能度量。这是因为通过汇总从训练数据集的列中获取的单个观察值的数量来查看与每个类别相关的总量如何变化可能会很有趣。同样,通过对每个观察的平均成本或每个观察的成本列表中的值求和来了解与每个类别相关的总成本如何变化可能会很有趣。这些值显然会随着阈值的变化而变化,并且每个值旁边都显示它代表的百分比值
- 最上面是三张桌子。左边的第一个包含所有那些取决于阈值的指标,因此会随着幻灯片的移动而变化(例如,准确性、F1 分数等)。另一方面,中间表包含所有那些随着阈值变化而不变的指标(例如 ROC AUC 或 PR AUC)。右侧的第三个也是最后一个表格仅在您在调用生成绘图的函数期间指定它时才会出现,该函数包含相对于左侧列中显示的指标而言最佳的所有阈值。最佳阈值的计算是通过 GHOST 完成的(如上一节所述)。由于此计算可能花费不可忽略的时间,因此可以选择要优化的特定指标,也可以选择所有指标。目前可以优化的指标有:Cohen’s kappa、Matthews相关系数、ROC曲线、F1-score、F2-score、F0.5-score和Costs。
使用交互式混淆矩阵分析二元分类器的预测的便利性是毋庸置疑的。类似地,显示随着阈值变化的金额或成本趋势的图表也可能很有用。
交互式混淆折线图
从通过交互式混淆矩阵完成的分析中,分析人员可能不仅对查看值感兴趣,而且对可视化与每个类别的混淆矩阵相关的可能金额或成本随着阈值的变化而变化的趋势感兴趣。这就是为什么 binclass-tools 包还允许您绘制交互式混淆折线图的原因:


您可以从图 10 中观察到,除了代表所选阈值处的金额/成本的 4 个图表中的每一个的一个点外,还有黑色“菱形”表示第一个阈值,其中存在金额的交换和成本曲线。曲线交换点也可以不止一个。
如果分析师希望关注混淆矩阵中任何类别组合的总量或成本值,还有另一个非常有用的图可用。
交互式金额成本折线图
假设您想帮助公司团队使用欺诈检测分类器分析可能的欺诈行为。假设分类器将欺诈类检测为阳性,分析师可能会提出以下几点:
- 如果模型检测到 TP,则交易金额会从可能是欺诈的金额中“保存”下来,因此可以将其视为公司的收益。
- 所有那些被归类为良好但实际上是欺诈的观察结果(因此是 FN)在所有意图和目的上都是等于相关交易总额的损失。因此,它们是成本。
- 此外,团队必须对模型预测为欺诈但实际上不是(FP)的所有交易进行的检查是成本,尽管其规模小于与欺诈相关的那些。在这些情况下,通常会考虑每次检查的固定成本。
如果现在分析师想要比较他认为收益的表现(TP 数量)与他认为损失的表现(FN 数量 + 每个 FP 的固定成本),他可以这样做,这要归功于 Interactive Amount-成本折线图:

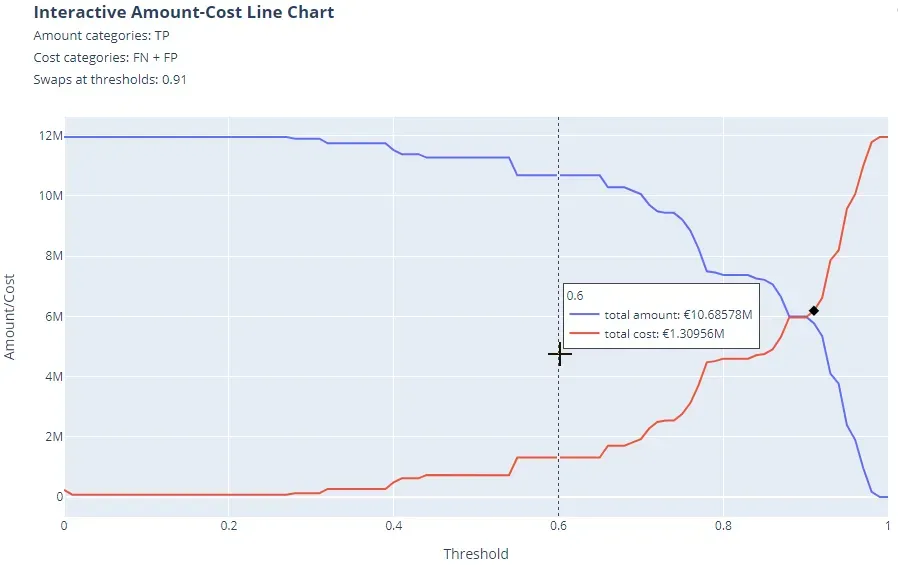
同样在该图中,黑色“菱形”表示金额和成本曲线交换发生的第一个阈值。
至此,使用上面提到的图就可以很容易地满足基于分类器的盈亏分析的需求。
凉爽的!但是我在哪里可以找到这个很棒的包裹?
一段时间以来,我一直在想将函数放在一个库中,以便对二进制分类器提供的结果进行交互式分析。由于我的可用时间不足,Python(或 R)中的实现始终是阻塞步骤。自从我得到一位同事的承诺帮助我开发上述功能后,实现这个项目的可能性变得更加现实。这就是为什么由于 Greta Villa 在 Python 方面的专业知识,所有这些想法的实现都是可能的。[0]
也就是说,我决定在 GitHub 上将该项目作为开源项目提供,原因有两个:
- 我想与整个数据科学家社区分享一个工具,它可以让二元分类器的分析变得更容易。
- 我依靠社区可能提供的帮助来建议新功能、改进现有代码或帮助我们开发包的未来版本。
binclass-tools 包是在 PyPI 上发布的,因此您只需要以下代码行即可将其安装到您的 Python 环境中:[0]
pip install binclass-tools有关如何使用包中包含的功能的更多详细信息,请参阅其 GitHub 页面:
我们打算添加交互式 ROC 和 Precision-Recall 图,以及在未来版本中简化模型校准操作的包装器。
欢迎对包提供任何反馈!
References
- 如何确定分类模型的质量和正确性?第 2 部分 — 定量质量指标[0]
- 什么是平衡和不平衡数据集?[0]
- 不平衡分类的评估指标之旅[0]
- 实际用例中的精确召回权衡[0]
- Matthews 相关系数 (MCC) 相对于 F1 分数的优势和二元分类评估的准确性[0]
- 马修斯相关系数 (MCC) 是
比 Cohen 的 Kappa 和 Brier 提供更多信息
二元分类评估得分[0] - 马修斯相关系数:何时使用,何时避免[0]
- GHOST:调整决策阈值以处理机器学习中的不平衡数据[0]
文章出处登录后可见!