



文@202020
在此前的中,我们介绍了二维人体姿态估计(2D Human Pose Estimation,以下简称2D HPE)的基本概念、常用数据集,以及自顶向下的2D HPE算法。
本文将结合 MMPose 对自底向上的 2D HPE 算法做一些介绍。
2D HPE 旨在从图像或者视频中预测人体关节点(或称关键点,比如头,左手,右脚等)的二维空间位置坐标。2D HPE 的应用场景非常广泛,包括动作识别,动画生成,增强现实等。传统的 2D HPE 算法,设计手工特征提取图像信息,从而进行关键点的检测。近年来随着深度学习的快速发展,基于深度学习的 2D HPE 算法取得了重大突破,算法精度得到了大幅提升。
当前主流的 2D HPE 方法主要可以分为自顶向下(top down)和自底向上(bottom up)两种方式。


如上图所示,自顶向下的方法首先进行人体检测,检测出输入图片中的一个或者多个人,然后对于每个人单独预测其关键点。而自底向上的方法同时预测图片中的所有关键点,然后将不同类型的关键点聚合成人体。
自顶向下的方法主要有如下两方面的问题:1)依赖人体框检测的效果。如果检测器没有检测到某个人体,或者一个框内框出了多个人体(在密集人群场景中,会经常遇到),自顶向下的方法会失效。2)自顶向下方法的计算复杂度随着图片中总人数的增加而线性上升。在人数比较多的场景,耗时难以满足实时性要求。而自底向上的算法,能够有效解决这两方面的问题,因此也受到了研究者的广泛关注。
1、主流算法
1.1、基于 Part Affinity Fields 的方法
- OpenPose
OpenPose [1] 算法基于 CPM(Convolutional Pose Machines)[5]模型结构设计了一个多阶段(multi-stage)的卷积神经网络,每个stage的输入是上一个stage输出和图像特征的融合,其网络结构如下图所示。

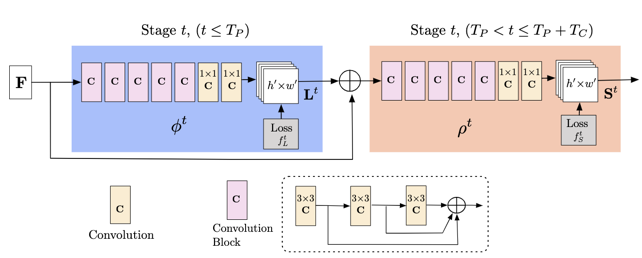
OpenPose 用神经网络同时预测多人关节点热度图(Heatmap 或 Confidence Map) 和关节点亲和场(Part Affinity Fields, PAFs)。其中,关节点热度图代表了关节点的位置;而 PAFs 表示不同关节点之间的骨架连接关系。PAFs是一组二维向量图,其每个像素表征该位置的骨架连接方向信息。


OpenPose 首先使用 NMS 算法,从关键点热度图中得到一系列候选关节点,再利用关节点亲和场来匹配关节点。然而,将候选关键点进行关节匹配并得到完整的人体的过程,是一个NP-Hard问题。OpenPose 采用了 greedy inference 算法,将关节点作为图的顶点,把关节点之间的PAFs向量看作两点间的边的权重,将多人检测问题转换成了一个二分图匹配问题,并用匈牙利算法求得局部最优匹配。
1.2、基于 Associative Embedding 的方法
- Associative Embedding
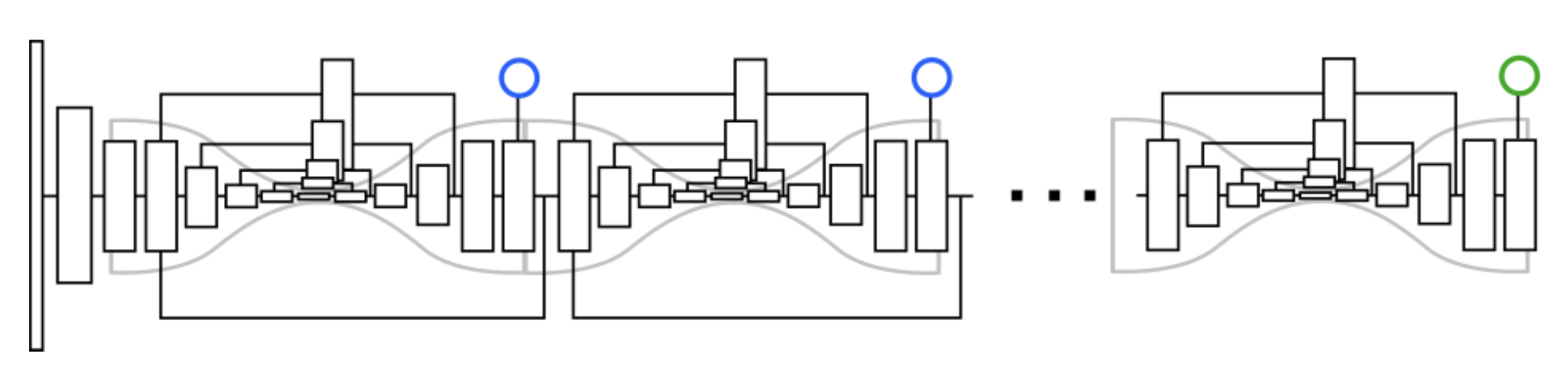
AE(Associative Embedding) [2]算法采用了基于堆叠沙漏网络(Stacked Hourglass [6])的网络结构,连续进行上采样和下采样,融合多尺度特征。

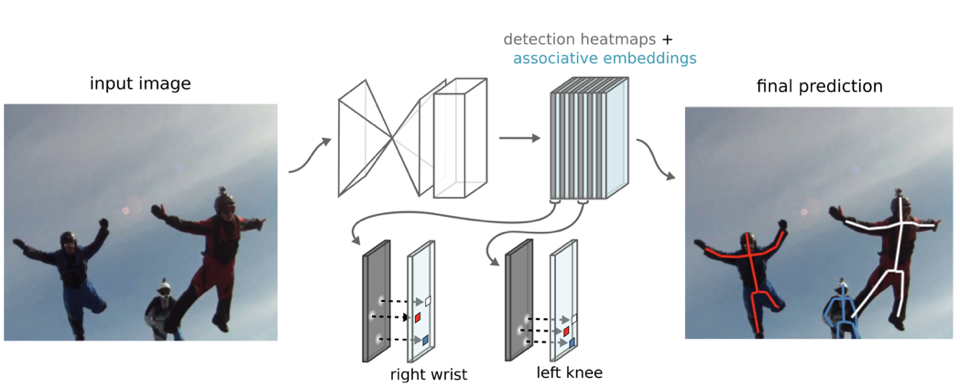
该算法提出了关联嵌入特征图(Associative Embedding),以实现关键点聚类。如下图所示,网络会预测 N 张关键点热度图,用于多人关键点定位;同时预测 N 张关联嵌入特征图,用于关键点聚类。在训练过程中,要求同一个人的各个关键点的关联嵌入特征尽可能相似(Pull loss),不同人的关联嵌入特征尽可能不同(Push loss)。在预测阶段,我们只需要对关联嵌入特征的取值进行聚类,即可将关键点匹配成人体姿态。

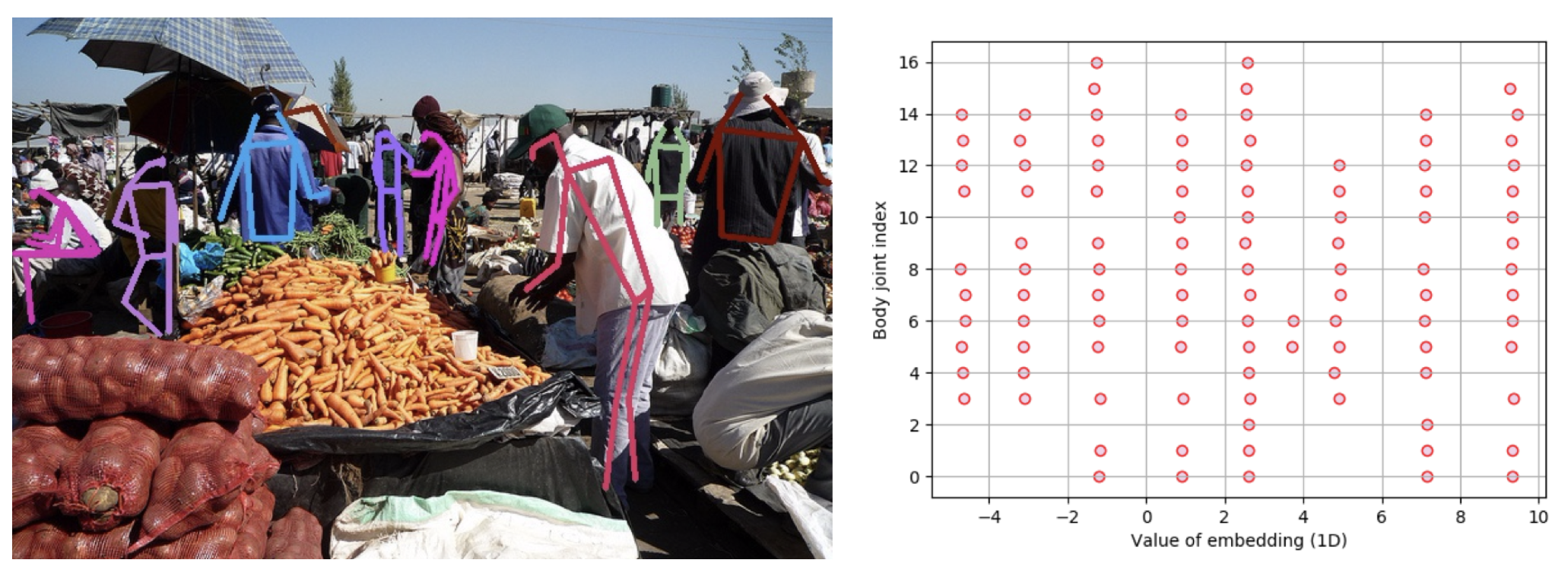
下图对网络预测的关联嵌入特征图进行了可视化。由图中可以看出,同一个人不同关键点的关联嵌入特征图的取值非常接近,且不同人的关联嵌入特征图的取值各不相同。

- HigherHRNet
该算法整体沿用了 AE 的思想,设计了 HigherHRNet 网络结构,致力于解决自底向上的人体姿态估计方法的尺度变化问题,有利于同时预测图片中不同尺度大小的人体姿态。HigherHRNet特征金字塔由 1)HRNet [7]的特征图输出和 2)通过转置卷积上采样的高分辨率输出组成。该模型采用多分辨率监督训练和多分辨率聚合推理,能够更精确地定位关键点。

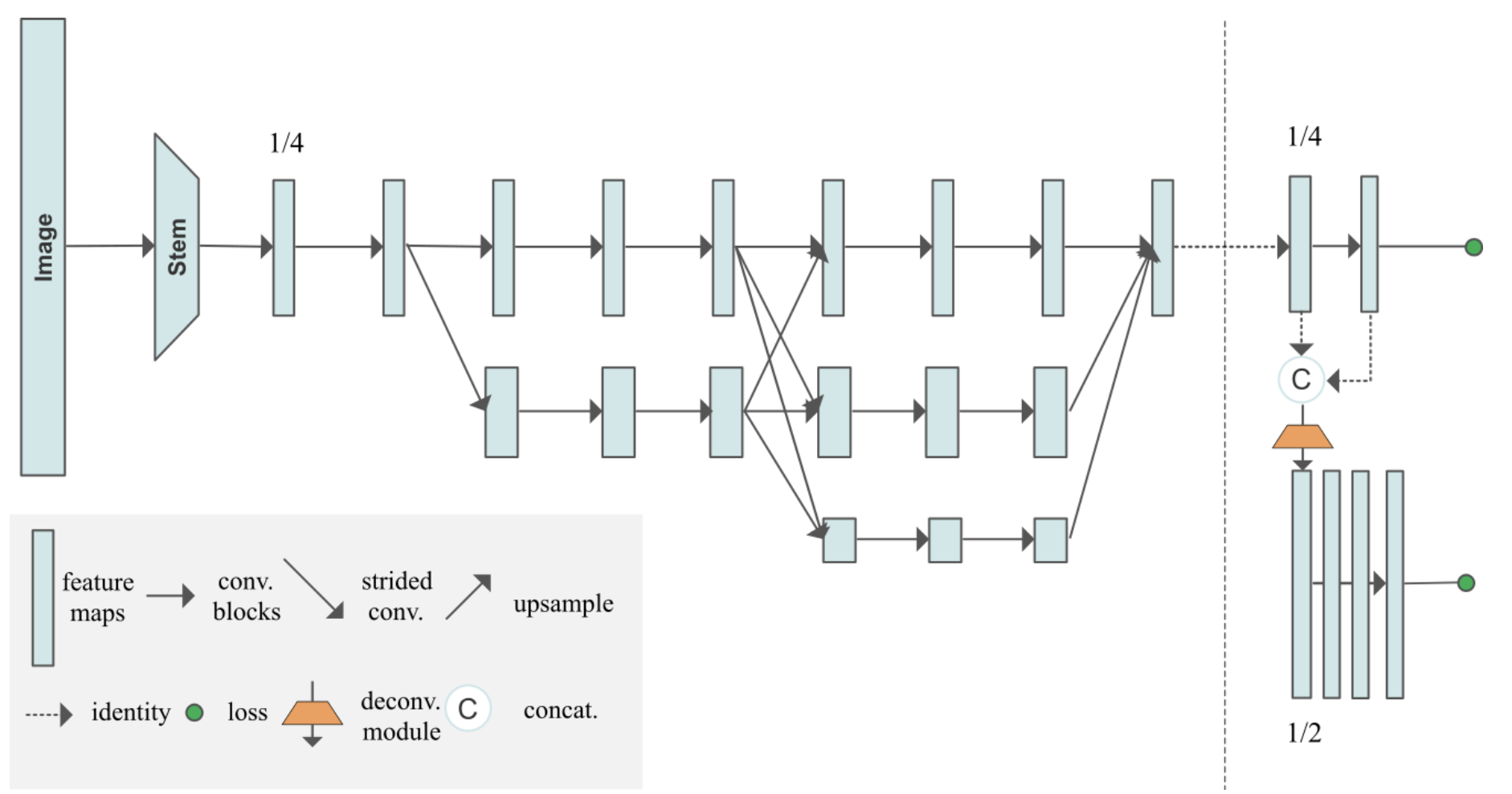
1.3、基于中心点回归的方法
- SPM
近几年,单阶段人体姿态检测器逐渐流行。而SPM(Single-Stage Multi-Person Pose Machines)[4]是其中的代表性方法,也是最早的单阶段多人姿态估计方法之一。该算法同样采用堆叠沙漏(Stacked Hourglass [6])网络结构。SPM抛弃了以往的”先检测所有关键点,再进行聚合”的策略。它提出首先检测人体中心点,再回归从人体中心到各个关键点的偏移向量。

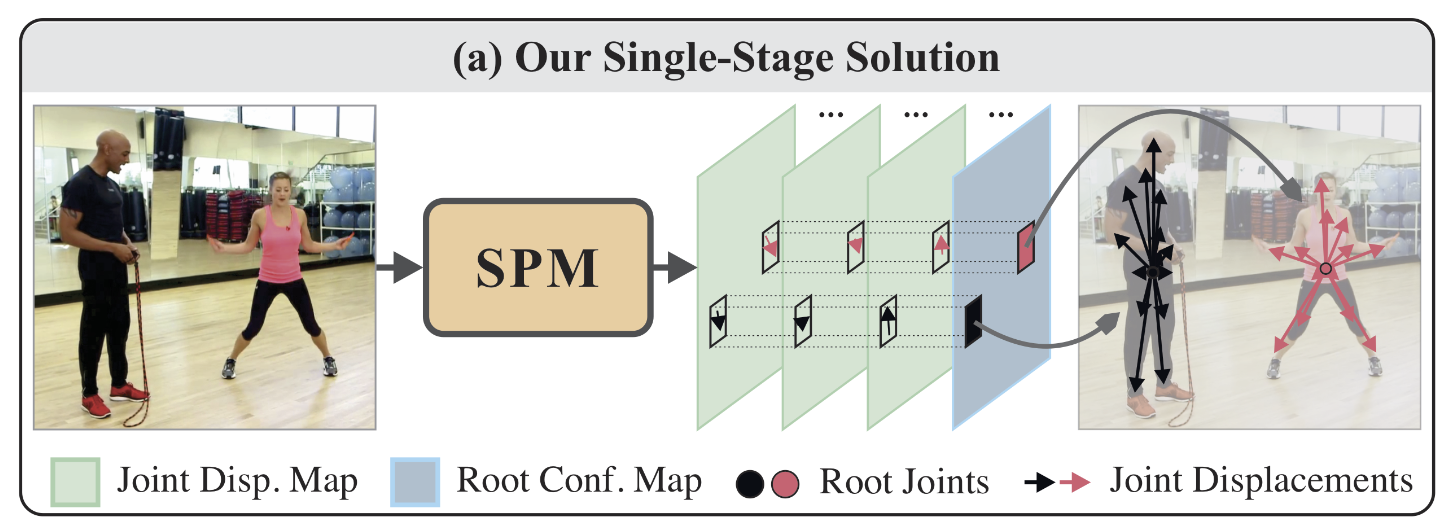
如上图所示,SPM算法在预测一张人体根节点的热度图(Root Conf. Map)的同时,预测了N*2张关键点偏移向量图(Joint Disp. Map)。在预测阶段,首先根据根节点热度图,定位各个人体的中心点坐标。中心点坐标再加上各个关键点的偏移向量,最终得到了每个人的姿态动作。
2、MMPose 中的 2D HPE 算法实现
MMPose现已支持 Associative Embedding, HigherHRNet 等不同的算法模型。我们也提供了基于图像和视频的demo,感兴趣的话不妨先尝试一下~

接下来,我们以HigherHRNet为例介绍自底向上的2D HPE算法在MMPose中的实现。
2.1 、模型
- Backbone
模型的骨干网络(Backbone)为HRNet模型(具体实现见hrnet.py),输入为3通道的图片,输出为 num_branches=4 个不同分辨率下的特征。特征分辨率越小的branch,其特征通道数越多 num_channels=(32, 64, 128, 256) 。
backbone=dict(
type='HRNet', # 骨干网络的类型
in_channels=3, # 输入通道数
extra=dict(
stage1=dict(
num_modules=1, # 串行module数
num_branches=1, # 并行branch数
block='BOTTLENECK', # 使用block的类型
num_blocks=(4, ), # 使用block的数量
num_channels=(64, )), # 特征通道数
stage2=dict(
num_modules=1, # 串行module数
num_branches=2, # 并行branch数
block='BASIC', # 使用block的类型
num_blocks=(4, 4), # 使用block的数量
num_channels=(32, 64)), # 特征通道数
stage3=dict(
num_modules=4, # 串行module数
num_branches=3, # 并行branch数
block='BASIC', # 使用block的类型
num_blocks=(4, 4, 4), # 使用block的数量
num_channels=(32, 64, 128)), # 特征通道数
stage4=dict(
num_modules=3, # 串行module数
num_branches=4, # 并行branch数
block='BASIC', # 使用block的类型
num_blocks=(4, 4, 4, 4), # 使用block的数量
num_channels=(32, 64, 128, 256))), # 特征通道数
)- Head
模型的Head部分,采用了 AEHigherResolutionHead ,具体实现见ae_higher_resolution_head.py。该网络头用于产生多分辨率的输出结果。模型训练的损失类型为 MultiLossFactory ,来分别监督多人关键点热度图和关联嵌入特征图。
keypoint_head=dict(
type='AEHigherResolutionHead', # 网络头的类型
in_channels=32, # 输入通道数
num_joints=17, # 输出关节点数
tag_per_joint=True, # 是否每个关节点使用单独的关联嵌入特征图
extra=dict(final_conv_kernel=1, ), # final_conv 为1x1的卷积
num_deconv_layers=1, # 反卷积层数量
num_deconv_filters=[32], # 反卷积层的输出通道数
num_deconv_kernels=[4], # 反卷积层的卷积核大小
num_basic_blocks=4, # BasicBlock的数量
cat_output=[True], # 是否级联输出
with_ae_loss=[True, False], # 是否使用AE损失
loss_keypoint=dict(
type='MultiLossFactory', # 损失函数类别
num_joints=17, # 关节点数量
num_stages=2, # 网络头阶段数
ae_loss_type='exp', # AE损失类型
with_ae_loss=[True, False], # 是否使用AE损失
push_loss_factor=[0.001, 0.001], # push损失的权重
pull_loss_factor=[0.001, 0.001], # pull损失的权重
with_heatmaps_loss=[True, True], # 是否使用热度图损失
heatmaps_loss_factor=[1.0, 1.0])) # 热度图损失的权重
)2.2、数据
- Data config
以下是与训练数据相关的一些配置,具体实现见bottom_up_coco.py。
data_cfg = dict(
image_size=512, # 输入图片尺寸
base_size=256, # 基准尺寸
base_sigma=2, # 热度图高斯分布的标准差
heatmap_size=[128, 256], # 输出多分辨率热度图的尺寸
num_joints=channel_cfg['dataset_joints'], # 关键点个数
dataset_channel=channel_cfg['dataset_channel'], # 数据集所对应的通道列表
inference_channel=channel_cfg['inference_channel'], # 模型输出的通道列表
num_scales=2, # 输出分辨率的个数
scale_aware_sigma=False, # 高斯分布的标准差是否随尺度变化
)
data_root = 'data/coco' # 数据集路径
data = dict(
samples_per_gpu=24, # 训练阶段,每张GPU的批处理大小
workers_per_gpu=2, # 每个GPU的数据读取线程数量
train=dict(
type='BottomUpCocoDataset', # 训练数据集名称
ann_file=f'{data_root}/annotations/person_keypoints_train2017.json', # 训练数据集标签路径
img_prefix=f'{data_root}/train2017/', # 训练数据集图片路径前缀
data_cfg=data_cfg,
pipeline=train_pipeline),
val=dict(
type='BottomUpCocoDataset', # 验证数据集名称
ann_file=f'{data_root}/annotations/person_keypoints_val2017.json', # 验证数据集标签路径
img_prefix=f'{data_root}/val2017/', # 验证数据集图片路径前缀
data_cfg=data_cfg,
pipeline=val_pipeline),
test=dict(
type='BottomUpCocoDataset', # 测试数据集名称
ann_file=f'{data_root}/annotations/person_keypoints_val2017.json', # 测试数据集标签路径
img_prefix=f'{data_root}/val2017/', # 测试数据集图片路径前缀
data_cfg=data_cfg,
pipeline=val_pipeline),
)- Pipeline
数据预处理的pipeline主要由以下几个步骤组成:
- LoadImageFromFile:读取图片。
- BottomUpRandomAffine:随机仿射变换。
- BottomUpRandomFlip:随机水平翻转 。
- ToTensor:图片转换为Tensor。
- NormalizeTensor:输入Tensor归一化,减均值,除方差。
- BottomUpGenerateTarget:根据标签,生成所需GT。
- Collect:整合训练中需要用到的数据。
train_pipeline = [
dict(type='LoadImageFromFile'), # 读取图片
dict(
type='BottomUpRandomAffine', # 数据增强:随机仿射变换
rot_factor=30, # 最大旋转幅度
scale_factor=[0.75, 1.5], # 随机缩放范围
scale_type='short', # 以图像的长边或短边进行缩放
trans_factor=40), # 最大中心点偏移
dict(
type='BottomUpRandomFlip', # 数据增强:随机翻转
flip_prob=0.5), # 翻转概率
dict(type='ToTensor'), # 数据格式转换为 Tensor
dict(
type='NormalizeTensor', # 输入Tensor归一化
mean=[0.485, 0.456, 0.406], # 归一化均值
std=[0.229, 0.224, 0.225]), # 归一化方差
dict(
type='BottomUpGenerateTarget', # 根据标签,生成GT
sigma=2, # 热度图高斯分布的标准差
max_num_people=30, # 最大人数
),
dict(
type='Collect', # 整合训练中所需要的数据
keys=['img', 'joints', 'targets', 'masks'], # 保留的key
meta_keys=[]), # 保留的meta-key
]2.3、训练配置
- Optimizer
采用Adam作为优化器,并设置初始学习率为0.0015。
optimizer = dict(
type='Adam', # 优化器的类型
lr=0.0015, # 基础学习率
)
optimizer_config = dict(grad_clip=None) # 不进行梯度裁剪- Learning rate policy
学习率采用阶梯状衰减,分别在第200和第260个epoch,降低学习率(默认每次降低到 0.1倍),总计训练300个epoch。我们采用了预热启动(warmup)策略,初始设置非常小的学习率(0.001倍的初始学习率lr),并在前500个迭代轮次中,线性增加为lr=0.0015。
lr_config = dict(
policy='step', # 学习率调整策略
warmup='linear', # 预热启动策略
warmup_iters=500, # 预热启动的训练迭代数
warmup_ratio=0.001, # 预热启动阶段初始学习率为 warmup_ratio * lr
step=[200, 260]) # 学习率下降的轮次,分别在第200和第260个epoch,降低学习率
total_epochs = 300 # 总迭代轮数3、总结
本文介绍了 2D HPE 一些自底向上的算法,并以 HigherHRNet 为例,介绍了 MMPose 中的具体算法实现。希望大家通过本文的阅读能够对自底向上的 2D HPE 有一个初步的认识,也欢迎大家使用 MMPose 来支持相关的研究与应用~
如下链接,可以访问公众号哦:
参考文献
[1] Cao, Zhe, et al. "OpenPose: realtime multi-person 2D pose estimation using Part Affinity Fields." IEEE transactions on pattern analysis and machine intelligence 43.1 (2019): 172-186.
[2] Newell, Alejandro, Zhiao Huang, and Jia Deng. "Associative embedding: End-to-end learning for joint detection and grouping." NIPS. 2017.
[3] Cheng, Bowen, et al. "Higherhrnet: Scale-aware representation learning for bottom-up human pose estimation." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
[4] Nie, Xuecheng, et al. "Single-stage multi-person pose machines." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.
[5] Wei, S. E., Ramakrishna, V., Kanade, T., & Sheikh, Y. (2016). Convolutional pose machines. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition (pp. 4724-4732).
[6] Newell, A., Yang, K., & Deng, J. (2016, October). Stacked hourglass networks for human pose estimation. In European conference on computer vision (pp. 483-499). Springer, Cham.
[7] Sun, K., Xiao, B., Liu, D., & Wang, J. (2019). Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 5693-5703).
版权声明:本文为博主OpenMMLab原创文章,版权归属原作者,如果侵权,请联系我们删除!