


知识抽取 – 潘登同学的KG笔记
前言
知识抽取是知识图谱与NLP的交叉领域;
知识图谱工程
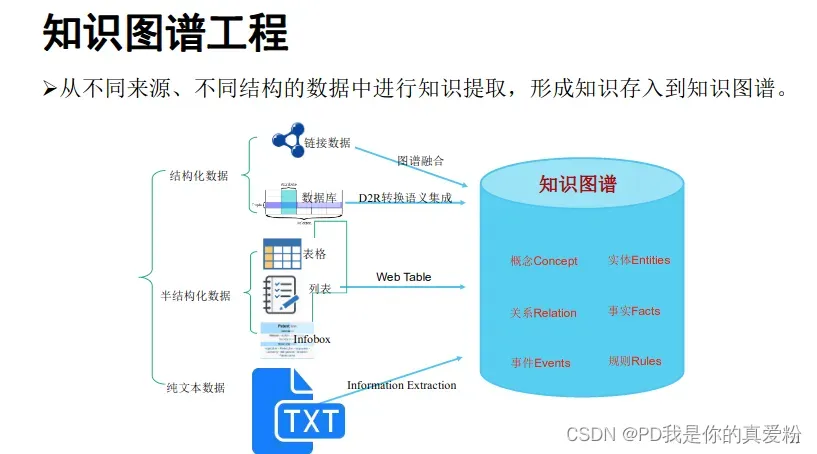

-
可以从关系型数据库中获取知识
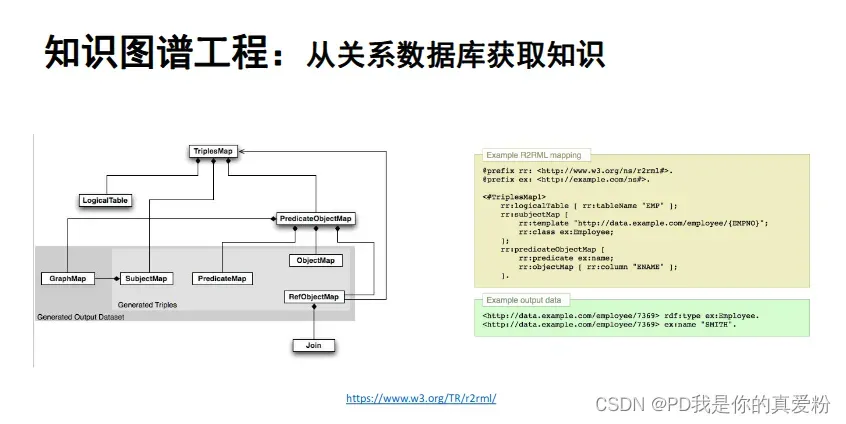
-
从视觉数据获取知识,(Scene Graph Construction之前的Caption-LSTM看图说话也可以理解为从视觉数据获取知识)
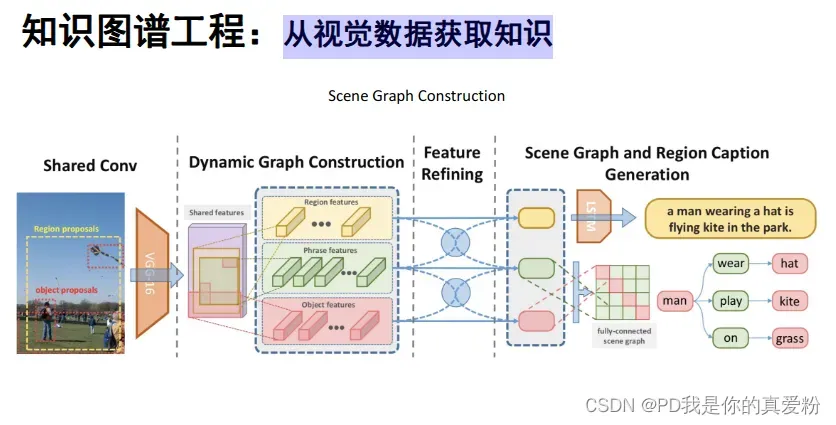
-
从文本获取知识




知识抽取
实体识别与分类
核心就是NLP的序列标注问题,这里不再赘述;
最开始先是机器学习模型HMM为主,后被深度学习模型取代BiLSTM-CRF;
总结一下HMM模型即可
- 模型参数估计与学习: EM算法
- 求观测序列的概率: 前向后向算法(动规)
- 解码隐藏状态序列: 维特比算法(动规)
实体识别解码策略
对于网络的Head部分有这样几个常用的结构
-
Softmax层,简单粗暴
-
CRF层,考虑上下文信息(在CRF层之前是一个映射到类别的FC层)
-
Seq2Seq
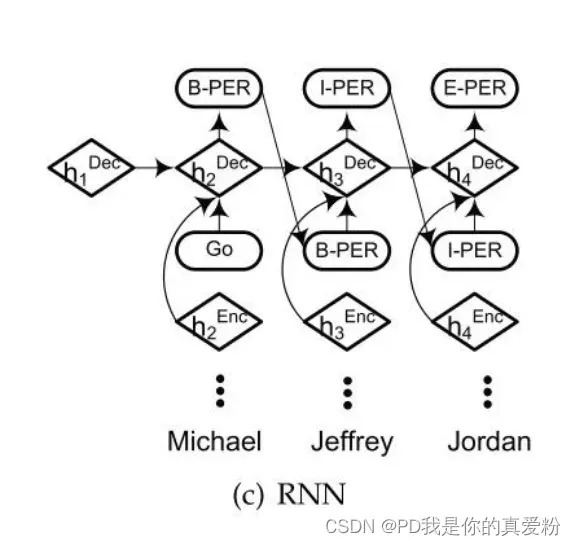
-
指针网络



指针网络
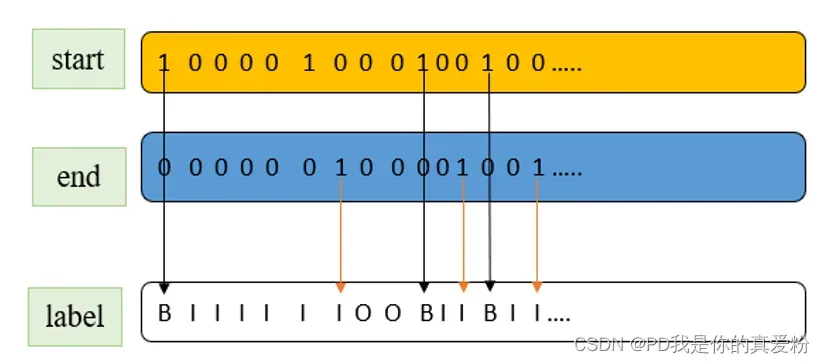
指针网络是将序列标注问题转化为两个子问题:先分块再分类。指针网络会贪婪地从头开始找下一个块结束的位置(开始的位置很显然,第一个块的开始位置是起始点,后面的开始位置都是前面一块的结束位置的后继位置)如上图d所示,在起始块”<s>“后一块的结束块位置是”Jordan”,这样就得到块”Michael Jeffrey Jordan”,然后将这个块进行分类确定类别,之后再继续找下一个块的结束位置,找到”was”,这样就得到一个新的块”was”,再将这个块进行分类,然后这样循环下去直到序列结束。指针网络主要就起到确定块起始位置的作用。
指针网络的铺垫模型
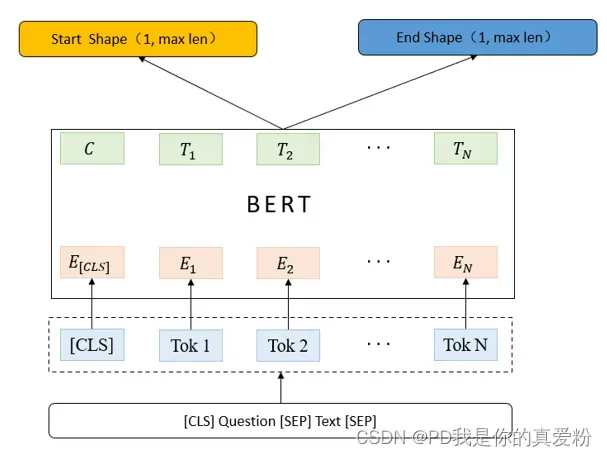
举例说明指针网络的用法: 基于Bert的阅读理解任务,根据输入<CLS>问题<SEP>文本<SEP>,Bert Encoder后接FC层生成与输入序列长度相等的两个向量,这两个向量分别表示一个词的起始和结束,如果是起始或者结束则为1,否则为0(接了softmax层);
输入:
<CLS>请抽出这段话含有的朝代。<SEP>贼吕布在东汉末年认了三个爹,李白生于唐朝,朱元璋建立了明朝<SEP>
输出: 东汉、唐朝、明朝


其loss函数则为

指针网络
指针网络解决的是实体重叠问题,这类问题在NER问题中一般不存在,所以指针网络(PointerNet)最早应用于MRC中,而MRC中通常根据1个question从passage中抽取1个答案片段,转化为2个n元SoftMax分类预测头指针和尾指针。对于NER可能会存在多个实体Span,因此需要转化为n个2元Sigmoid分类预测头指针和尾指针。
将指针网络应用于NER中,可以采取以下两种方式:
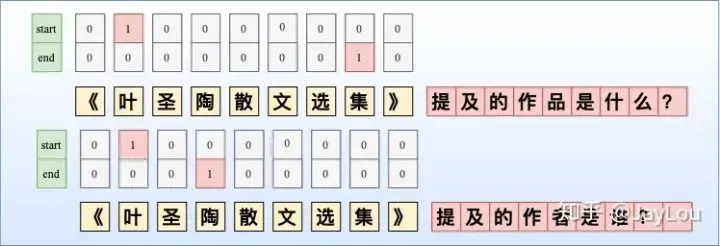
- MRC-QA+单层指针网络。在ShannonAI的文章中,构建query问题指代所要抽取的实体类型,同时也引入了先验语义知识。如图所示,由于构建query问题已经指代了实体类型,所以使用单层指针网络即可;除了使用指针网络预测实体开始位置、结束位置外,还基于开始和结束位置对构成的所有实体Span预测实体概率。此外,这种方法也适合于给定事件类型下的事件主体抽取,可以将事件类型当作query,也可以将单层指针网络替换为CRF。
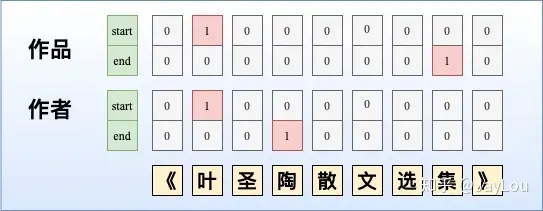
- 多层label指针网络。由于只使用单层指针网络时,无法抽取多类型的实体,我们可以构建多层指针网络,每一层都对应一个实体类型。


关系抽取
实体关系抽取的任务定义:
- 从文本中抽取出两个或者多个实体之间的语义关系;
- 从文本获取知识图谱三元组的主要技术手段,通常被用于知识图谱的补全。
完整的关系抽取包括实体抽取和关系分类两个子过程。实体抽取子过程也就是命名实体识别,对句子中的实体进行检测和分类;关系分类子过程对给定句子中两个实体之间的语义关系进行判断,属于多类别分类问题。
- 例如,对于句子“青岛坐落于山东省的东部”,实体抽取子过程检测出这句话具有“青岛”和“山东”两个实体。关系分类子过程检测出这句话中“青岛”和“山东”两个实体具有“坐落于”关系而不是“出生于”关系。在关系抽取过程中,多数方法默认实体信息是给定的,那么关系抽取就可以看作是分类问题。
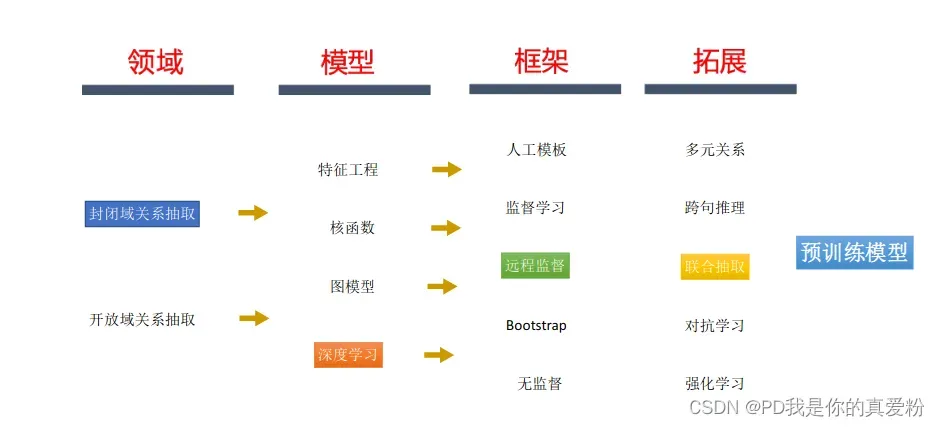

基于模板的方法
-
触发词匹配
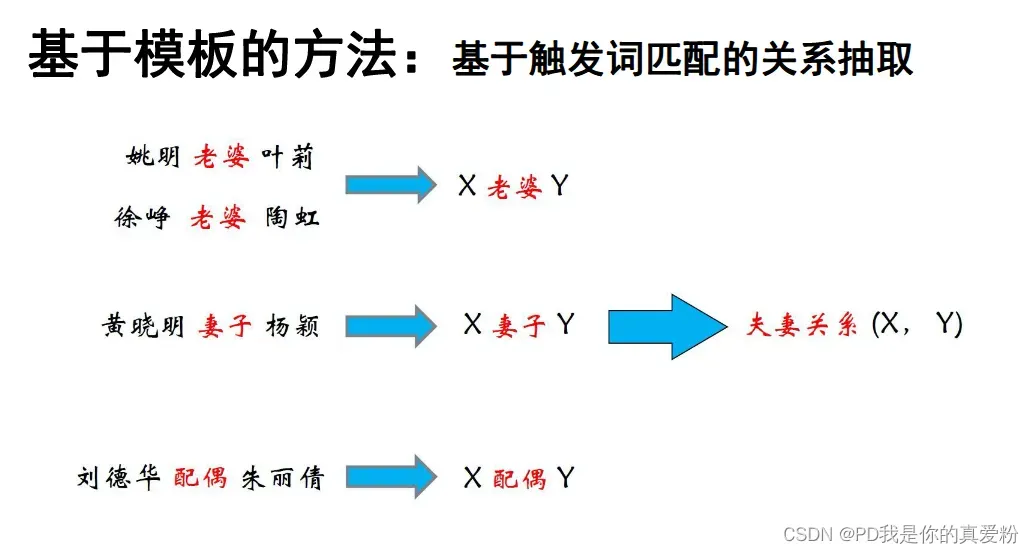
-
依存句法匹配
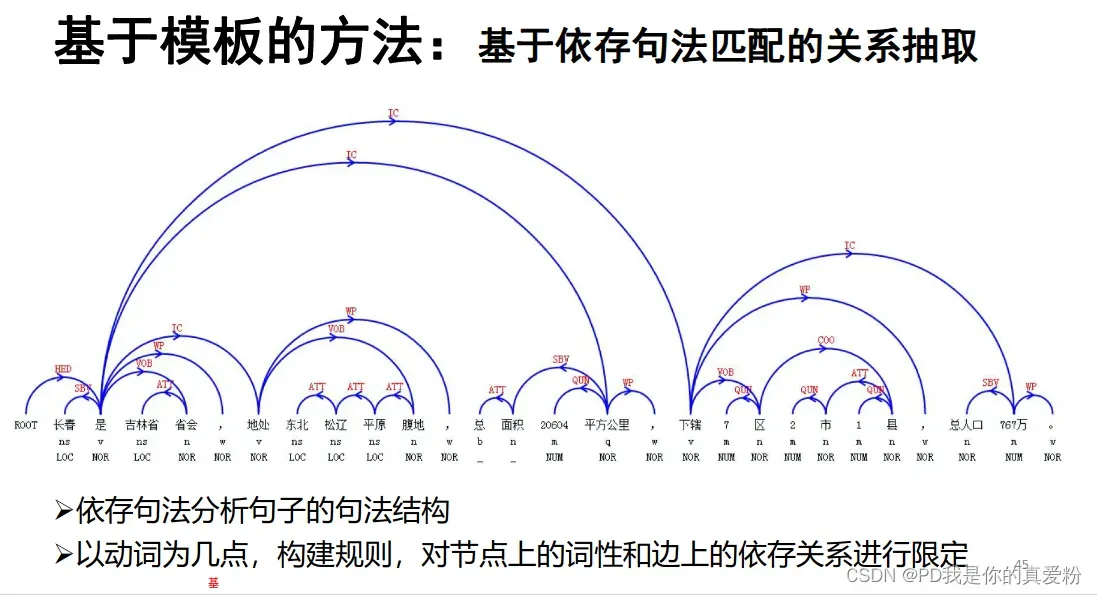


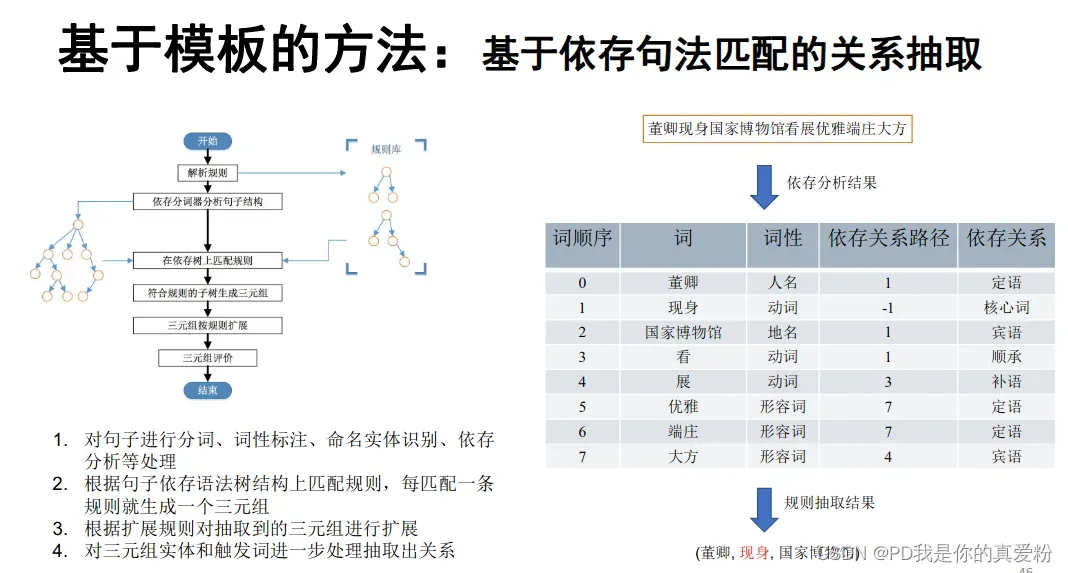

优缺点
- 在小规模数据集上容易实现,构造简单;
- 在特定领域的模板需要专家构建,难以维护,可移植性差,规则集合小的时候,召回率很低;
基于机器学习的模型
根据使用机器学习方法不同,可以将关系抽取划分为三类:基于特征向量的方法、基于核函数的方法以及基于神经网络的方法。
-
基于特征向量的方法,通过从包含特定实体对的句子中提取出语义特征,构造特征向量,然后通过使用支持向量机、最大熵、条件随机场等模型进行关系抽取。

-
基于核函数的方法,其重点是巧妙地设计核函数来计算不同关系实例特定表示之间的相似度。缺点:而如何设计核函数需要大量的人类工作,不适用于大规模语料上的关系抽取任务。



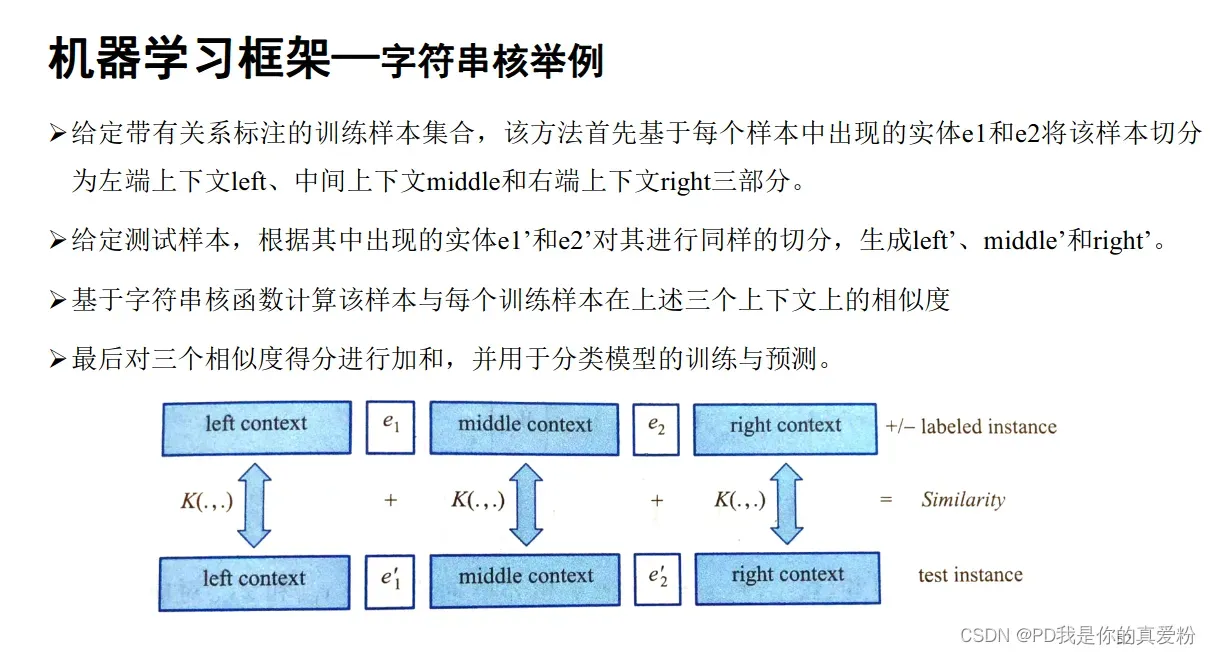

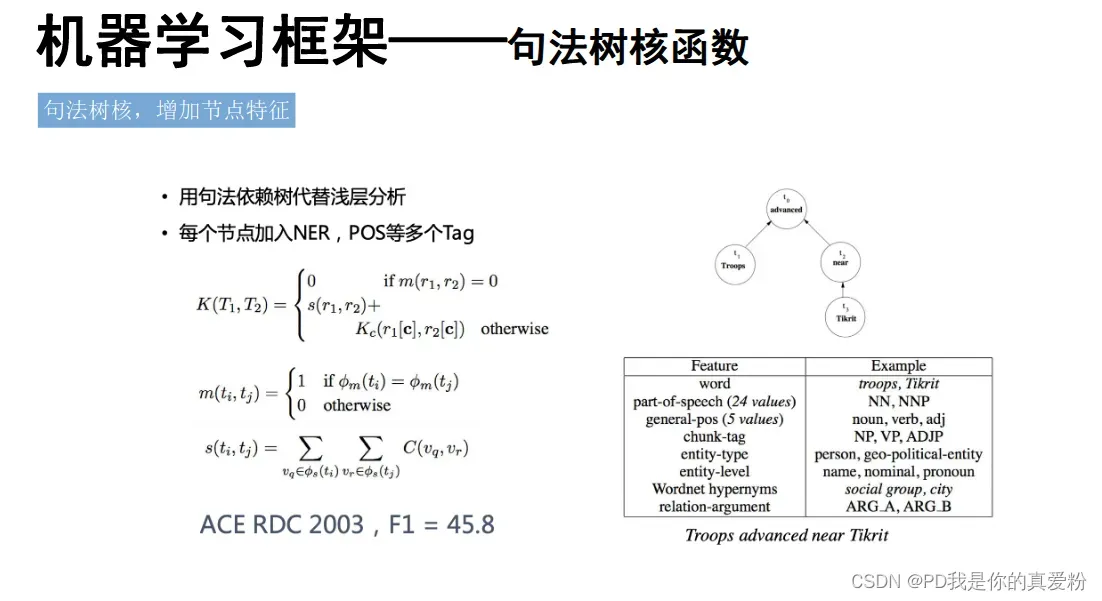



总结
- 基于特征的方法需要人工设计特征,这类方法适用于标注数量较少,精度要求较高,人工能够胜任的情况。
- 基于核函数的方法能够从字符串或句法树中自动抽取大量特征,但这类方法始终是在衡量两段文本在子串或子树上的相似度,并没有从语义的层面对两者做深入比较。
- 此外,上述两类方法通常都需要做词性标注和句法分析,用于特征抽取或核函数计算,这是典型的pipeline做法,会把前序模块产生的错误传导到后续的关系抽取任务,并被不断放大。
- 深度学习技术不断发展,端到端的抽取方法能大幅减少特征工程,并减少对词性标注等预处理模块的依赖,成为当前关系抽取技术的主流技术路线。
深度学习模型
-
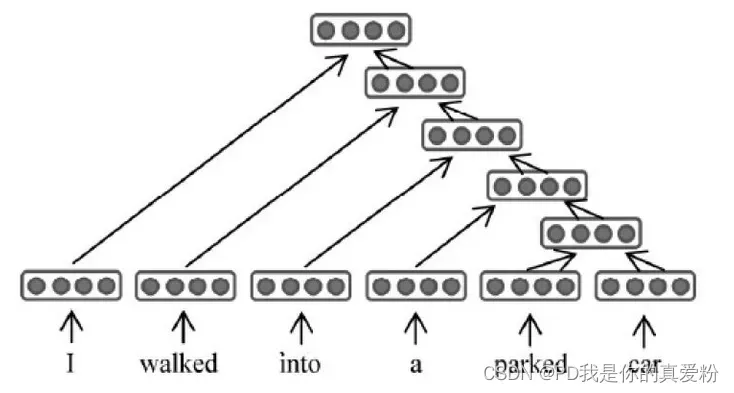
基于递归神经网络的关系抽取: 首先利用自然语言处理工具对句子进行处理,构建特定的二叉树,然后解析树上所有的相邻子节点,以特定的语义顺序将其组合成一个父节点,如下图所示。这个过程递归进行,最终计算出整个句子的向量表示。向量计算过程可以看作是将句子进行一个特征抽取过程,该方法对所有的邻接点采用相同的操作。 每个输入都由一个向量与一个矩阵组成,向量可以通过词向量构成,矩阵表示该词对临词的作用(采用高斯核函数进行初始化) 原论文: emantic Compositionality through Recursive Matrix-Vector Spaces
-
基于卷积神经网络的关系抽取: 基于卷积神经网络的关系抽取方法接受一个特定的向量矩阵作为输入,通过卷积层和池化层的操作将输入转换成一个固定长度的向量,并使用其他特征进行语义信息汇总,再进行抽取。基于卷积神经网络的关系抽取方法框架如图所示,除了输入层、数据表示层之外,还有窗口层、卷积层、池化层、语义信息汇总层、分类层。 原论文: Relation Classification via Convolutional Deep Neural Network





-
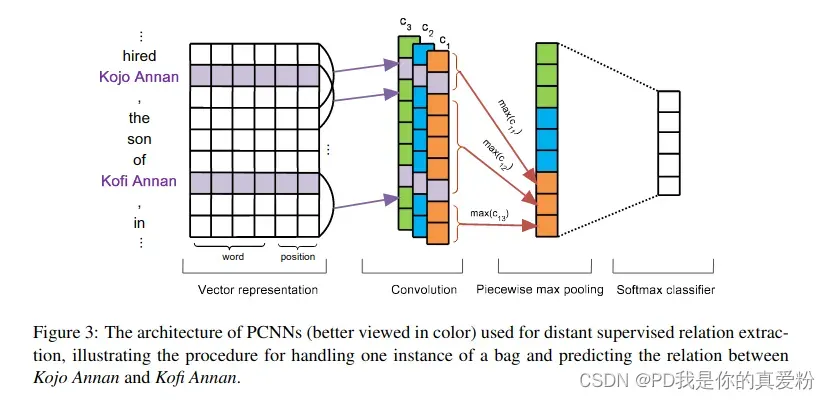
Piece-wise CNN Model: 是一个对位置敏感的CNN网络, 原论文: Relation Classification via Convolutional Deep Neural Network
-
BiLSTM的关系抽取
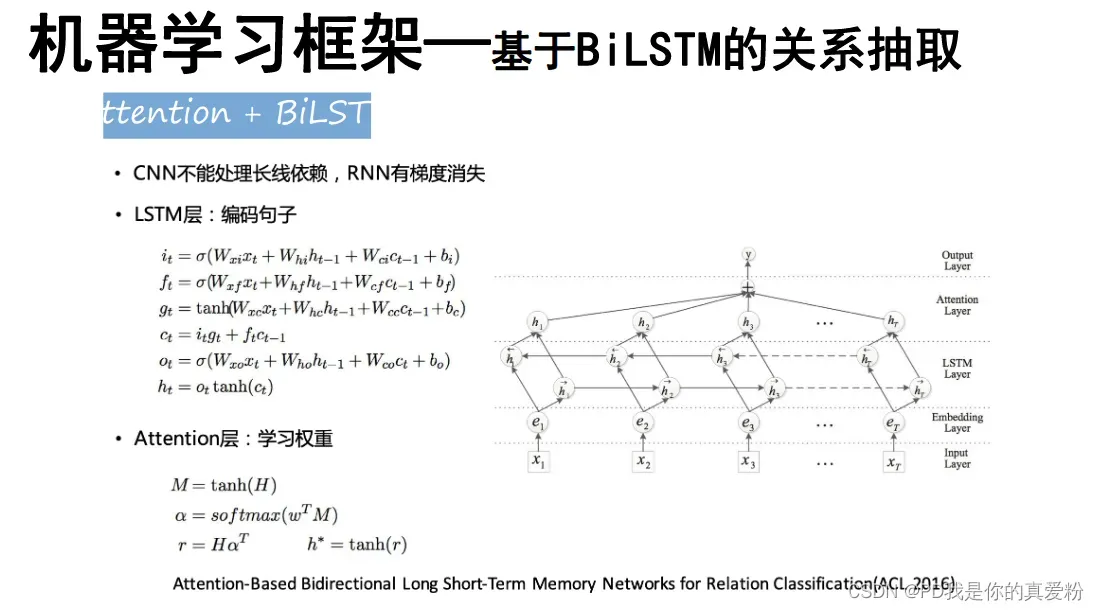
-
图神经网络
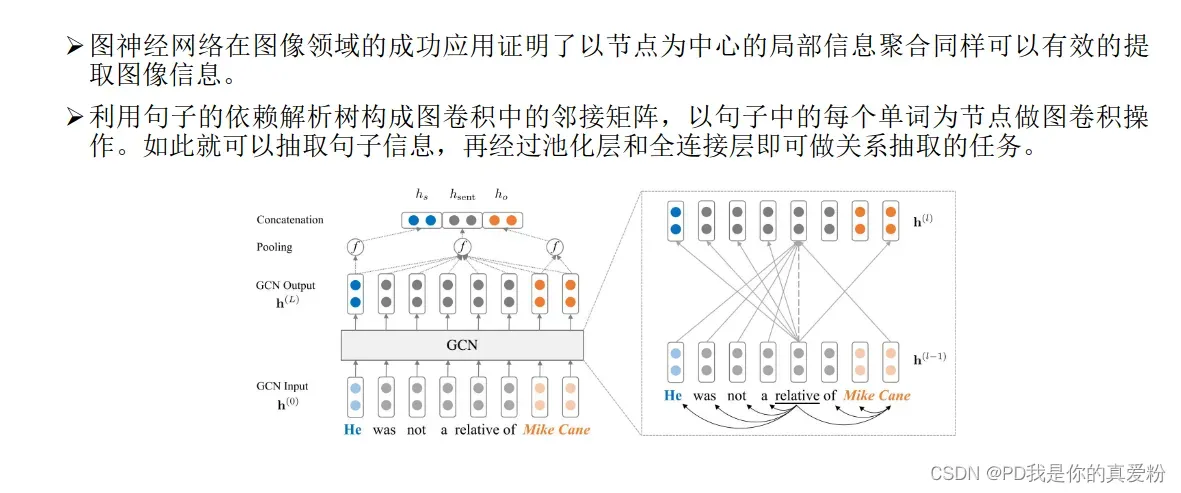
-
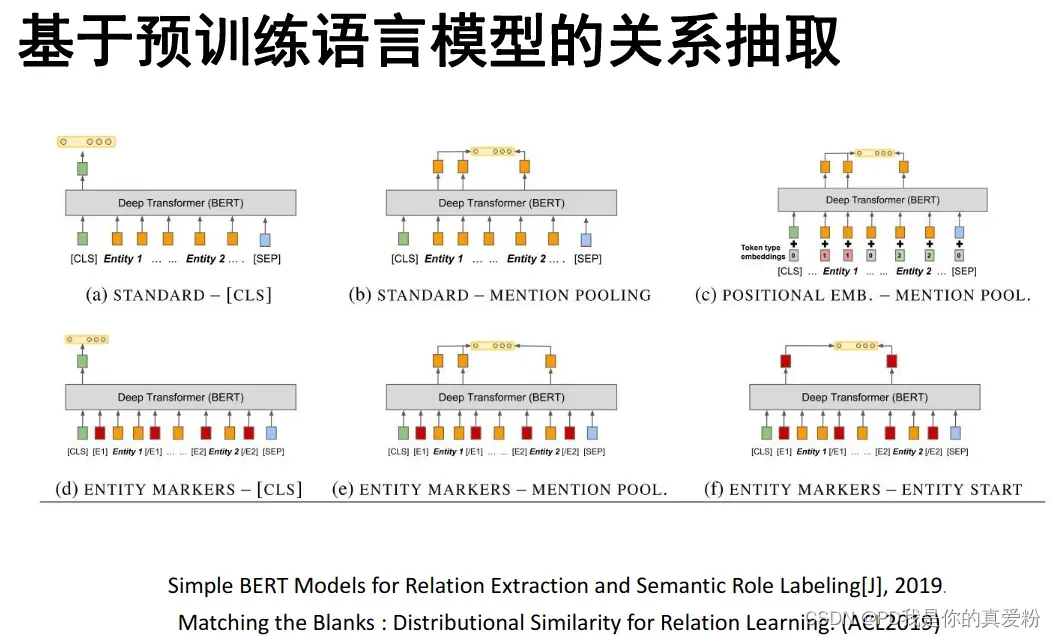
Bert




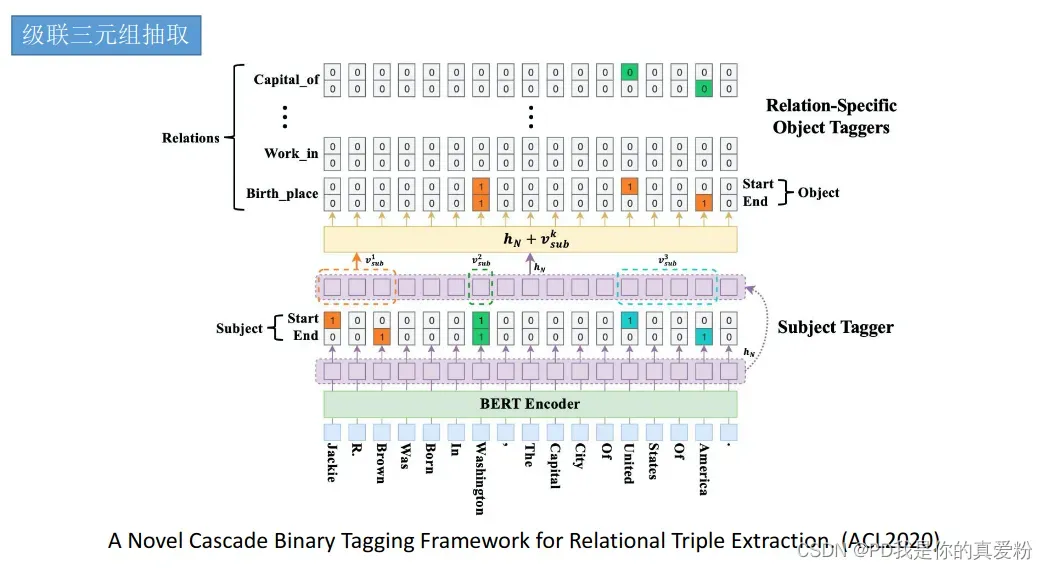
实体与关系联合抽取模型

多标签关系抽取,传统模型主要关注单标签关系抽取,但同一个句子可能包含多个关系。采用胶囊神经网络
可以帮助实现多标签的关系抽取。
胶囊神经网络
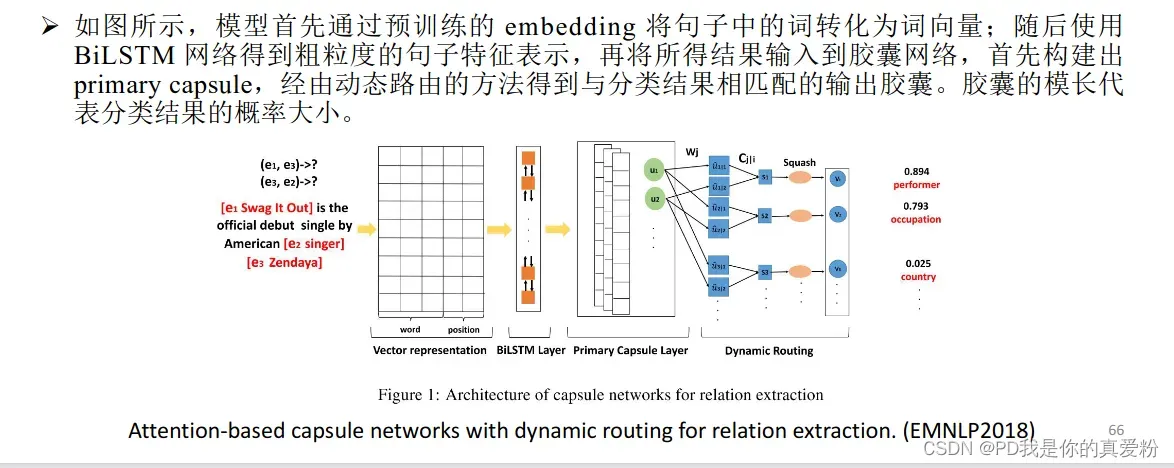



跨句推理问题
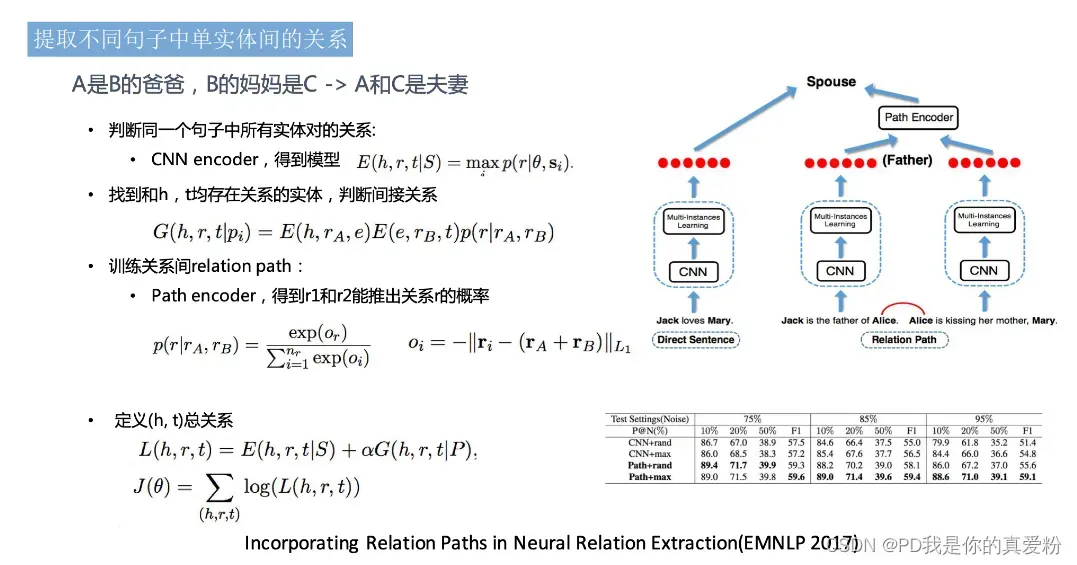

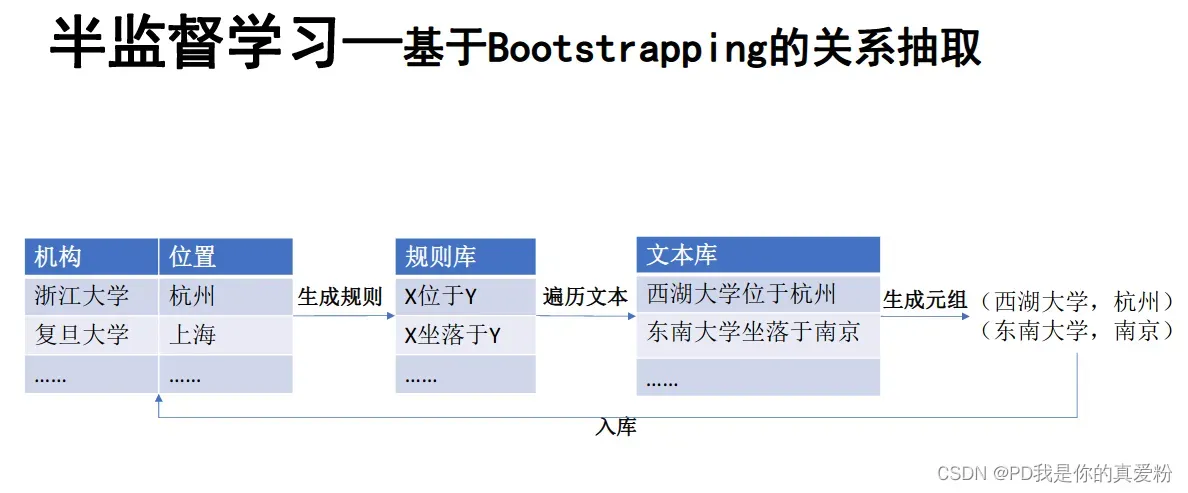
半监督学习
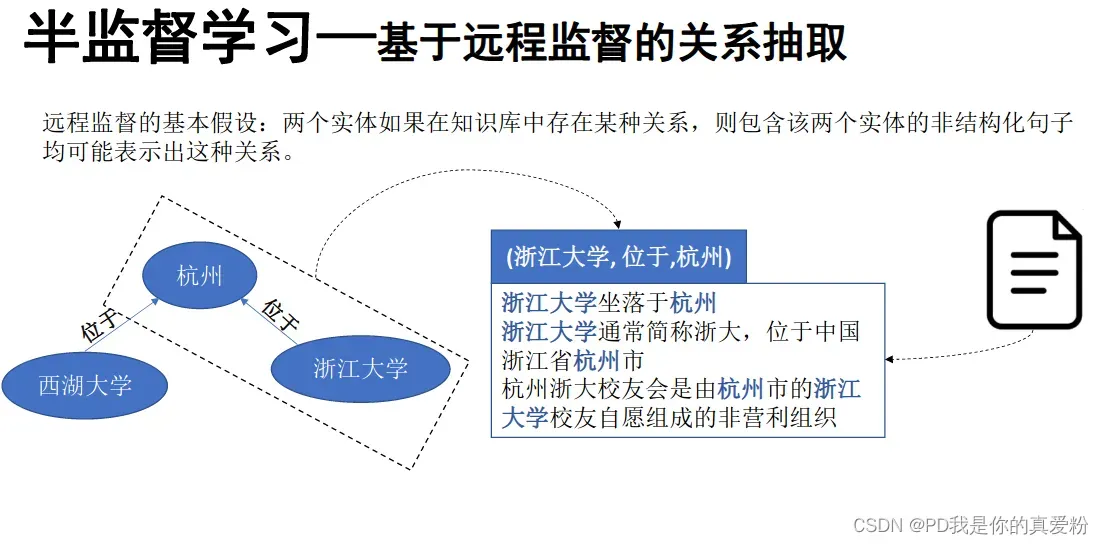

对于半监督学习的假设非常强,可能不太现实,会有很多噪声,所以有如下两个解决方案
-
Attention机制
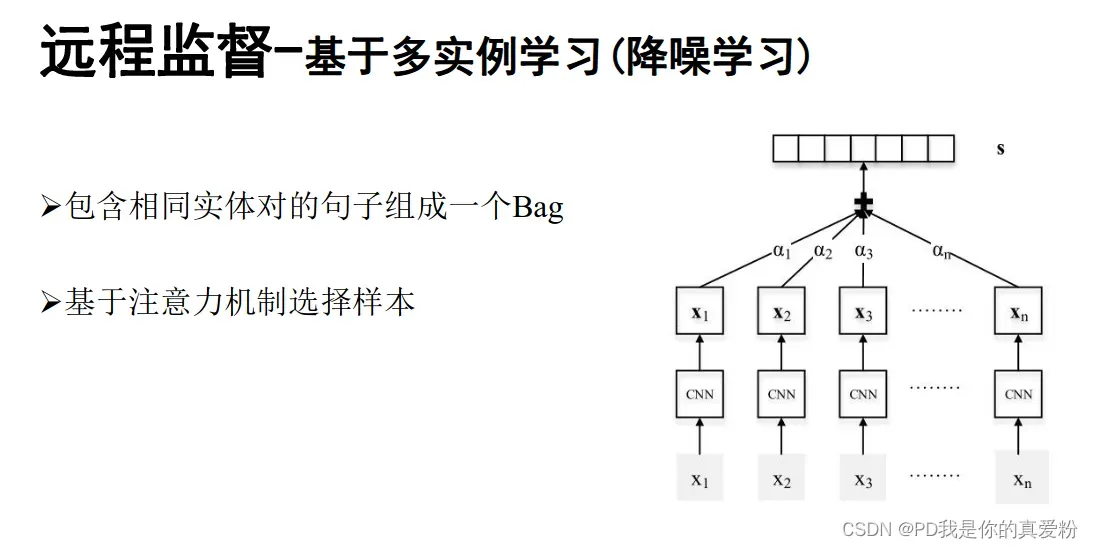
-
强化学习
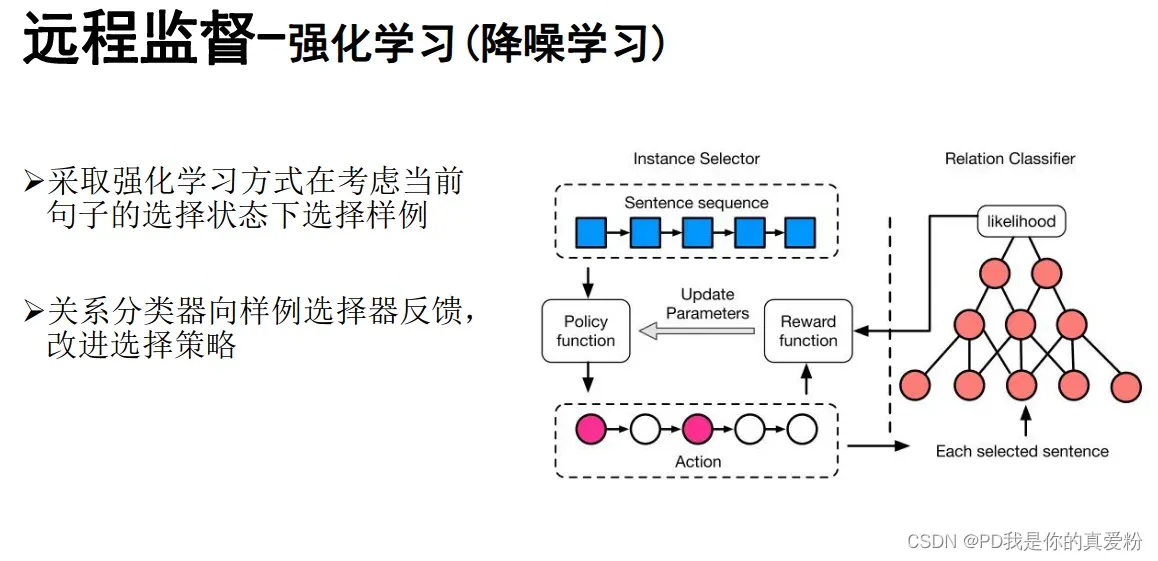


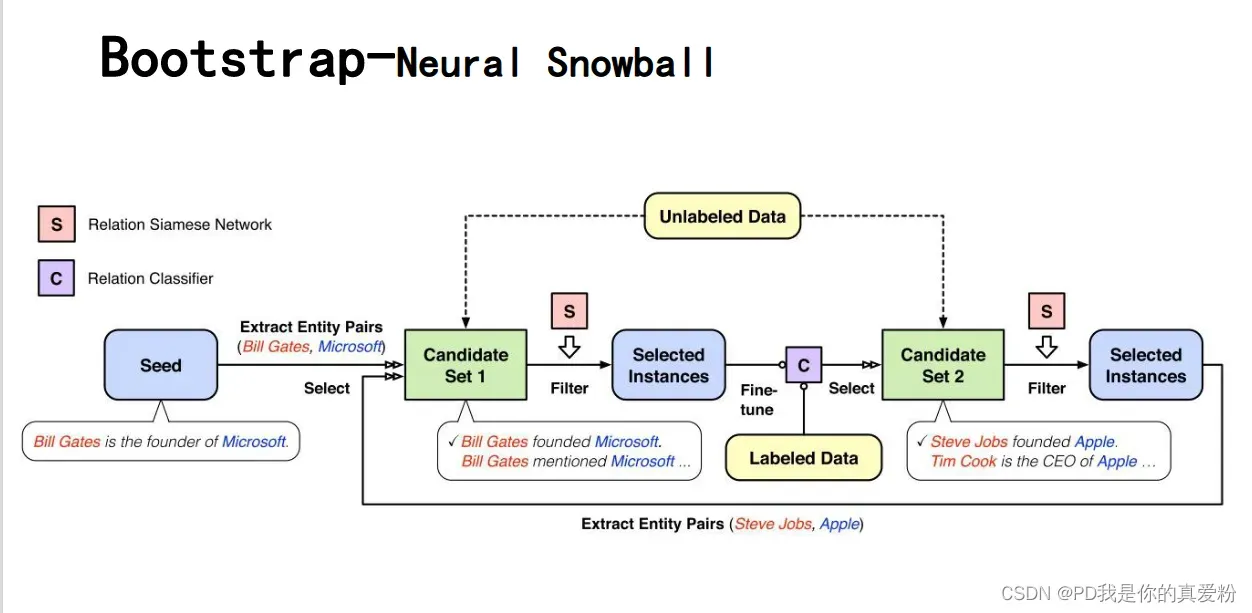
Bootstrap-Neural Snowball


而Bootstrapping会产生语义漂移问题,一些解决方案


总结
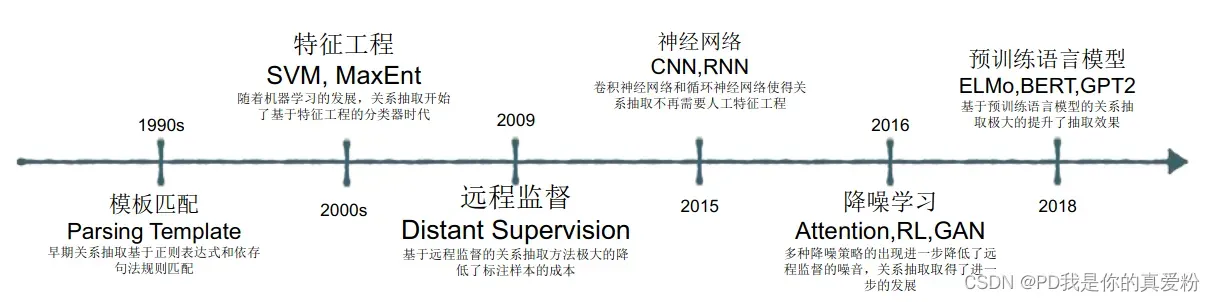

主流关系抽取模型框架 DeepKE https://github.com/zjunlp/deepke
属性补全
定义
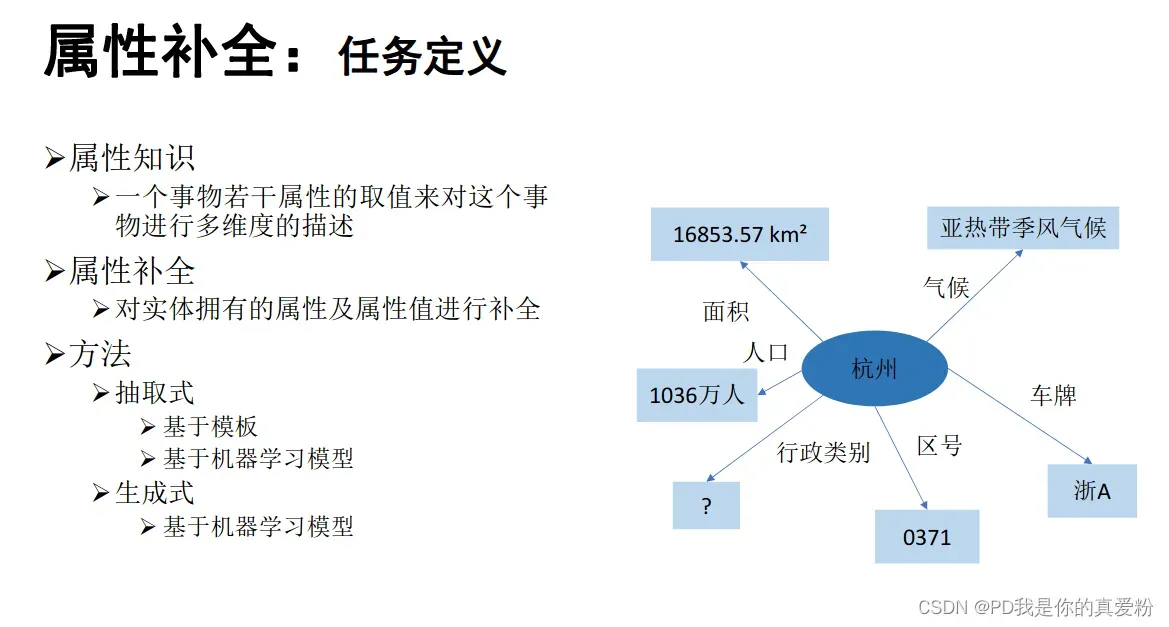

抽取式模型
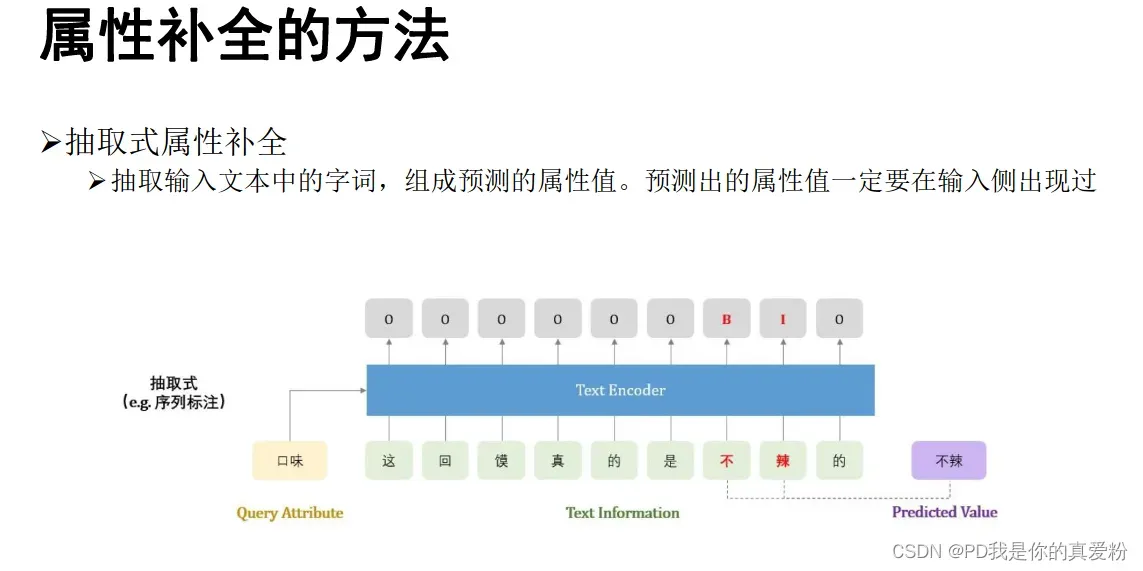

- 只能抽取在输入文本中出现过的属性值
- 预测属性值一定在输入中出现过,具有一定可解释性,准确性也更高
生成式模型


- 可以预测不在文本中出现的属性值
- 只能预测可枚举的高频属性,导致很多属性值不可获取
- 预测出来的属性值没有可解释性
例子
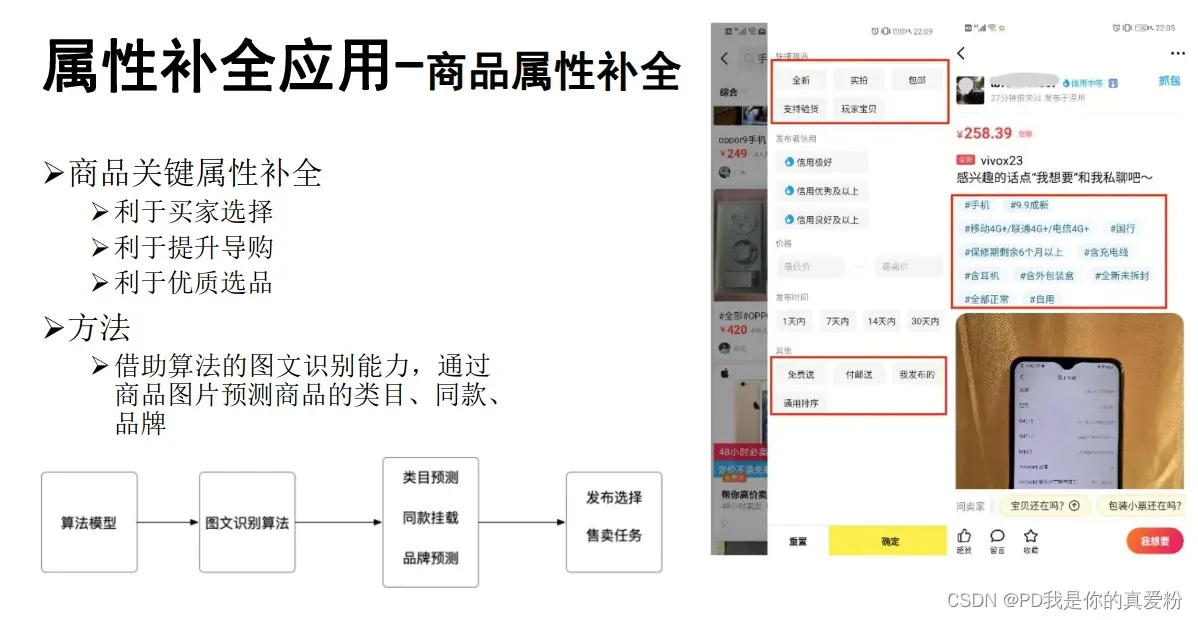

概念抽取
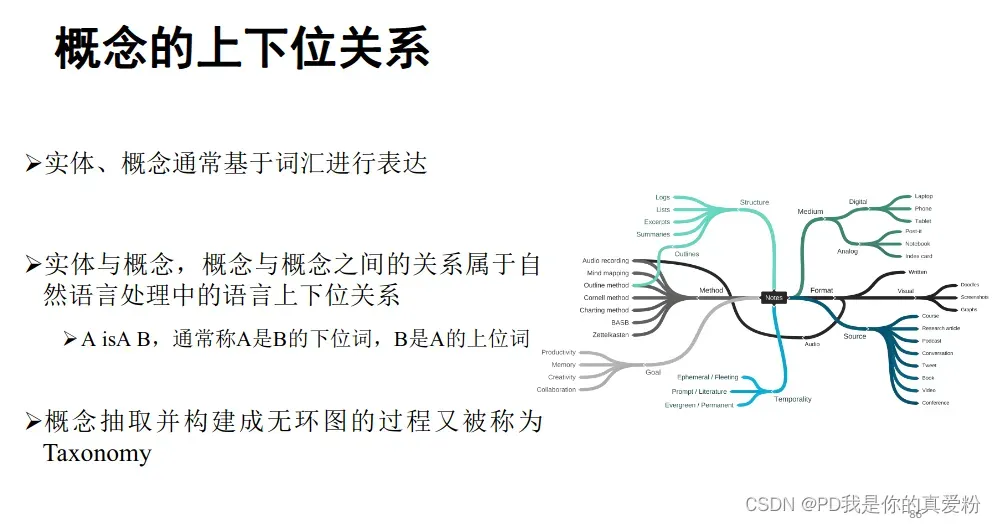
概念使得人们能更好地理解世界,而知识图谱理解概念则通过isA关系、subclassOf关系来构建
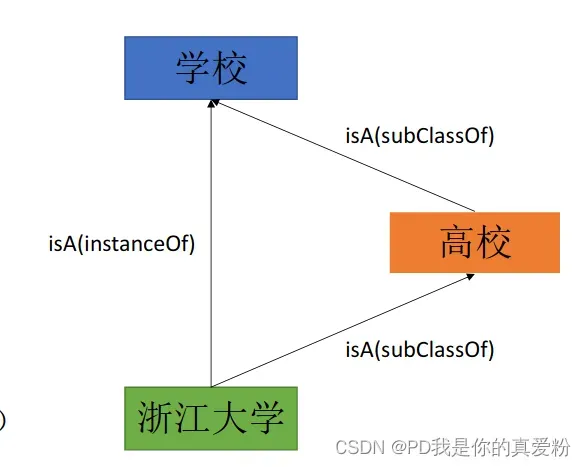


三种概念抽取的方法
- 基于模板的抽取
- 基于百科的抽取
- 基于机器学习
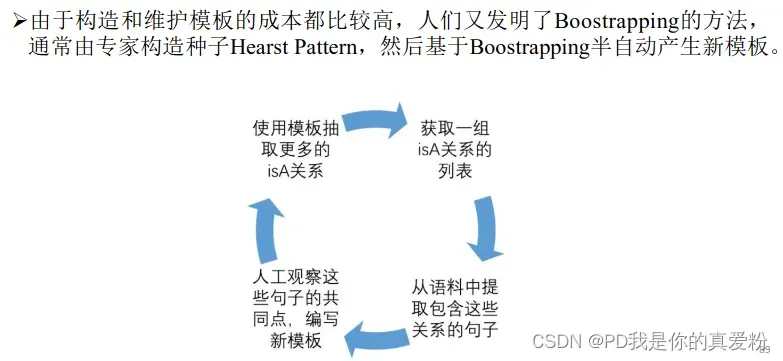
基于模板的抽取



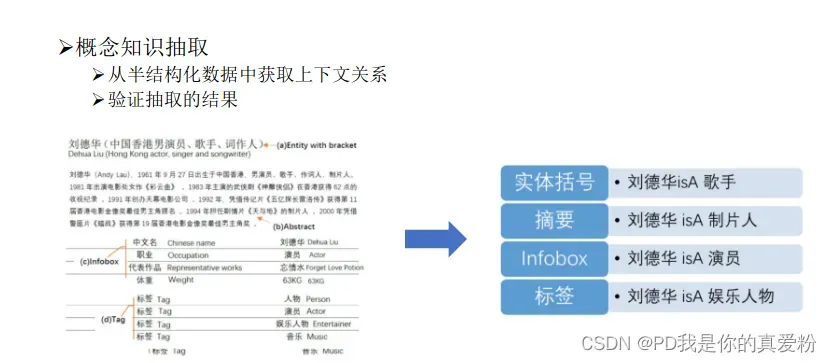
基于百科的抽取

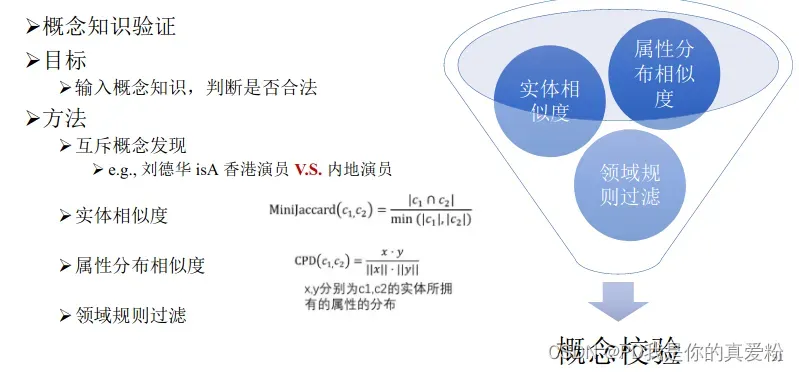

基于机器学习的抽取


浙大知识图谱 OpenConcept http://openconcept.openkg.cn/
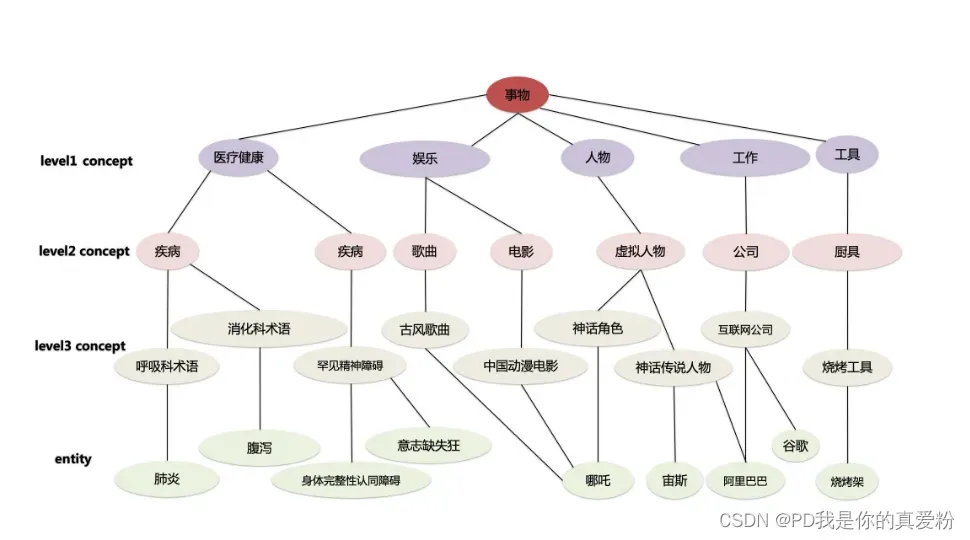

总结
- 概念(Concept)是人类在认识过程中,从感性认识上升到理性认识,把所感知的事物的共同本质特点抽象出来的一种表达;
- 概念知识一般可以通过基于模板、基于百科和基于序列标注等方法进行获取;
- 概念知识可以帮助自然语言理解,促进搜索、推荐等应用的效果;
事件识别与抽取
事件定义
- 事件是发生在某个特定的时间点或时间段、某个特定的地域范围内,由一个或者多个角色参与的一个或者多个动作组成的事情或者状态的改变。
- 不同的动作或者状态的改变代表不同类型的事件
- 同一个类型的事件中不同的要素代表了不同的事件实例
- 同一个类型的事件中不同粒度的要素代表不同粒度的事件实例
事件抽取的定义
从无结构文本中自动抽取结构化事件知识:
- 什么人/组织,什么时间,在什么地方,做了什么事
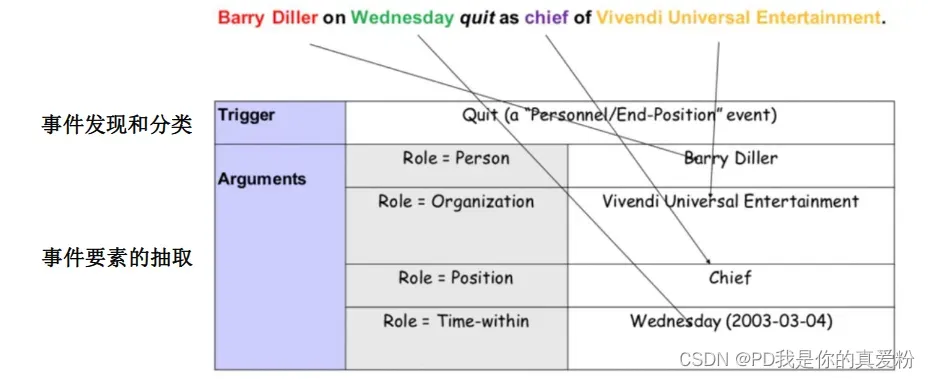

事件抽取一般分为两步
- 事件的发现和分类–识别触发词:体现发生事件的核心词语(关键动词),将其分类
- 事件的要素抽取–找到参与事件的实体与实体所扮演的角色
两种事件识别与抽取的方法
- 模式匹配
- 机器学习
- 基于特征
- 基于结构
- 基于神经网络
模式匹配


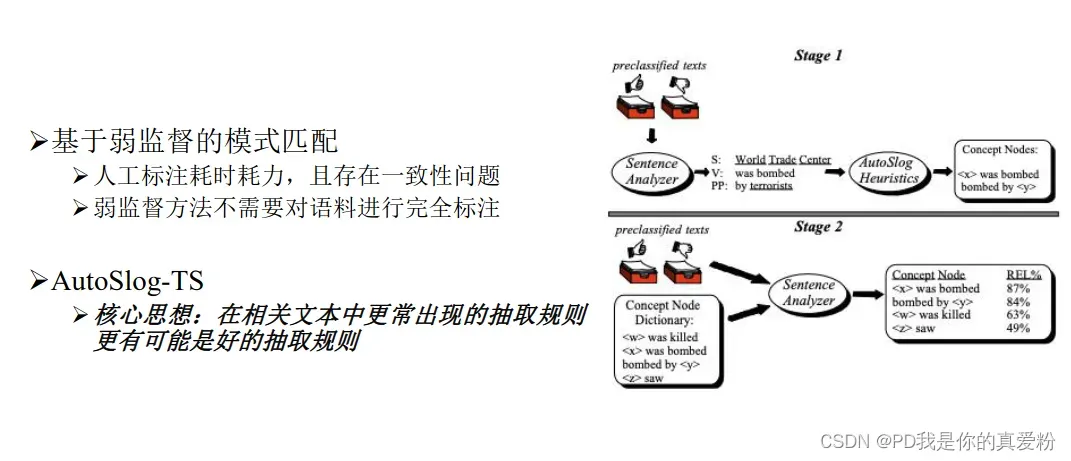

- 于模式匹配的方法在特定领域中性能较好,便于理解和后续应用,但对于语言、领域和文档形式都有不同程度的依赖,覆盖度和可移植性较差
- 模式匹配的方法中,模板准确性是影响整个方法性能的重要因素,主要特点是高准确率低召回率
机器学习–基于特征
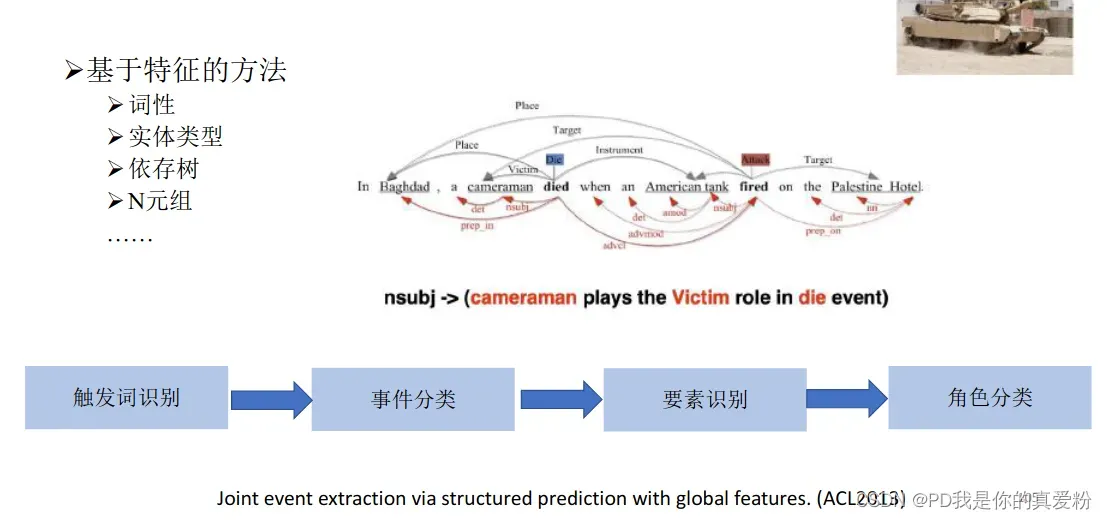

机器学习–基于结构
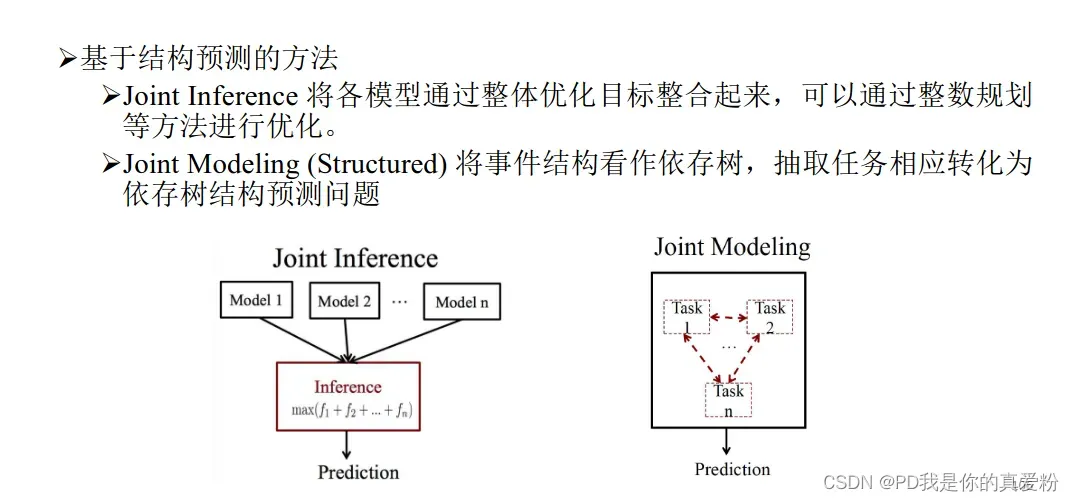

机器学习–基于神经网络
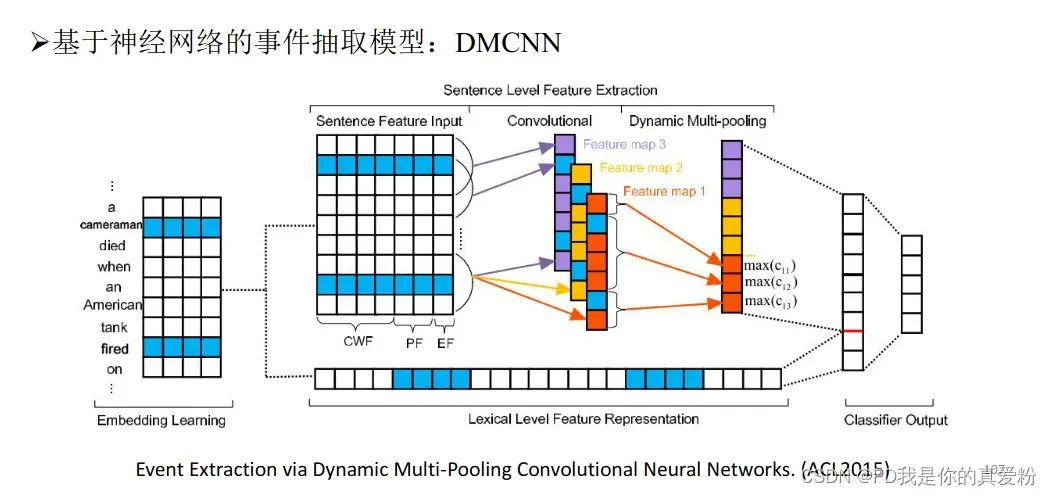

但是深度学习方法需要大量标注样本,而样本难标注,远程监督困难等问题仍然存在;
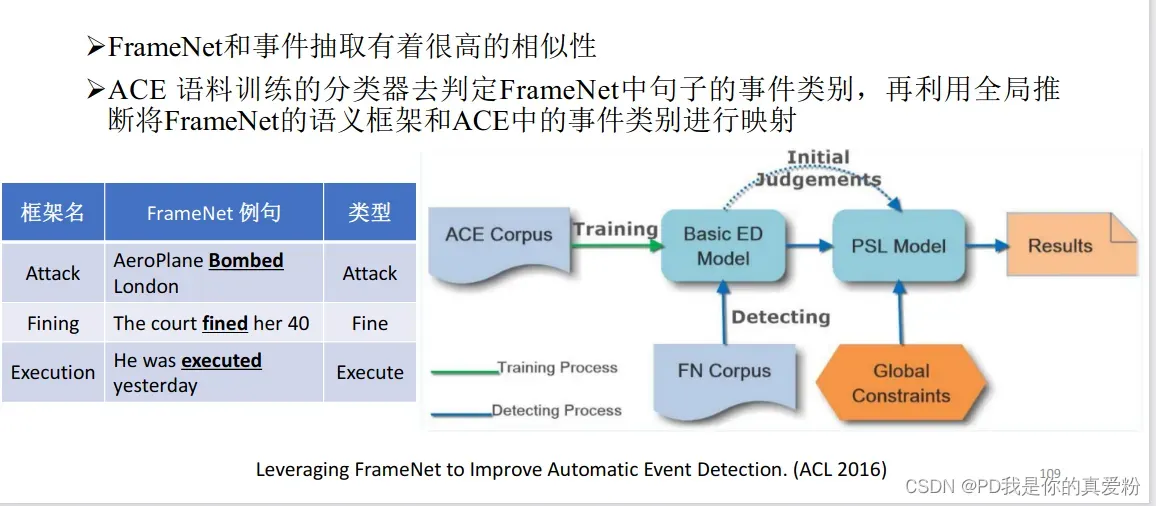
基于外部弱监督的深度学习模型
- 主要依赖语言专家定义的FrameNet知识库

百度发表的中文事件抽取模型 DUEE https://ai.baidu.com/broad/subordinate?dataset=duee
知识抽取技术前沿
基于深度学习的抽取方法依赖海量标注数据,在真实的场景中,数据通常是长尾的(各类别分布不均衡),数据的标注成本大等;在少样本,零样本面临严峻的挑战;对于日新月异的新知识,模型在学习新知识时会遗忘掉以往的知识;
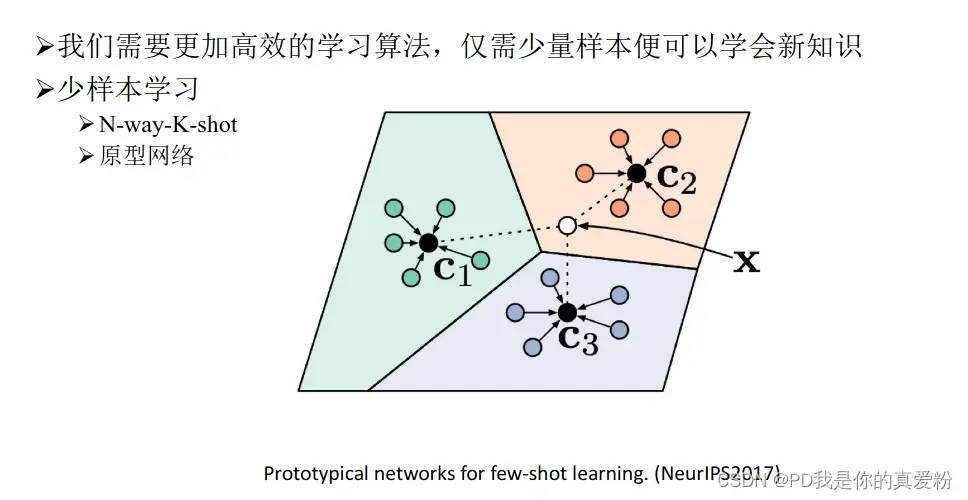
少样本知识抽取
-
原型网络
-
混合注意力原型网络
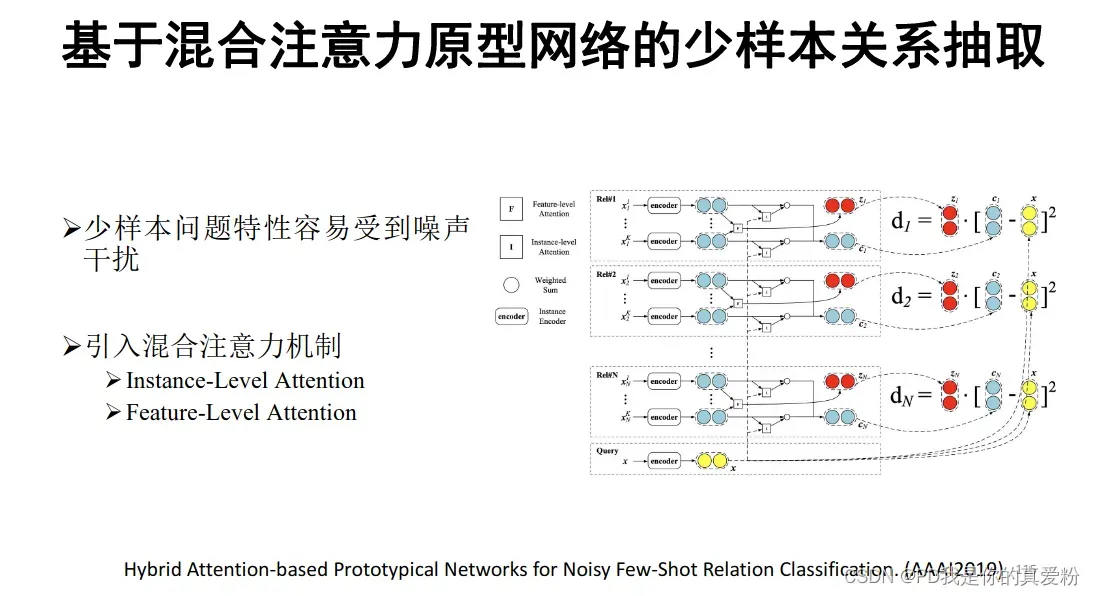
-
原型网络抽取三元组信息
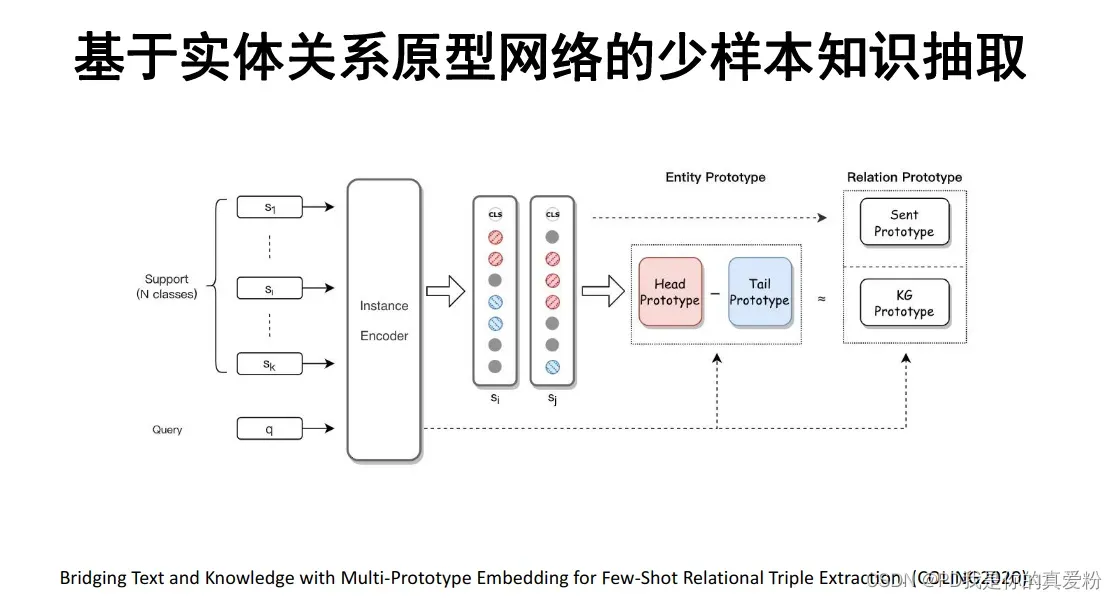



零样本知识抽取
-
基于阅读理解的零样本关系抽取

-
基于规则引导的零样本关系抽取
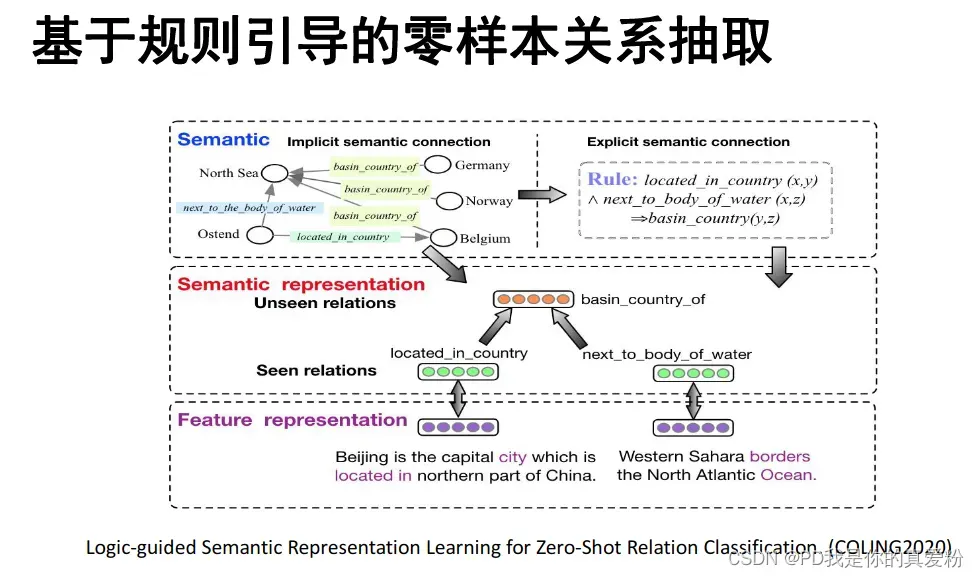


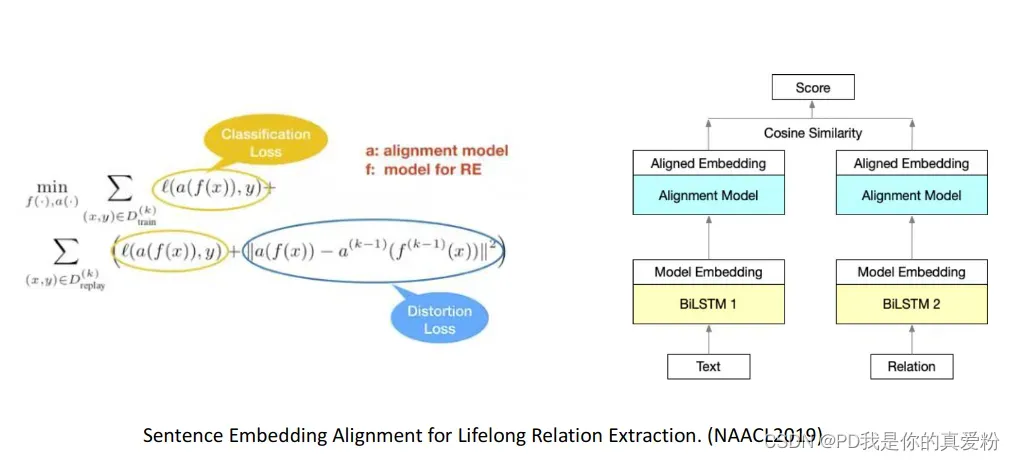
终身知识抽取
- 基于表示对齐的终身关系抽取
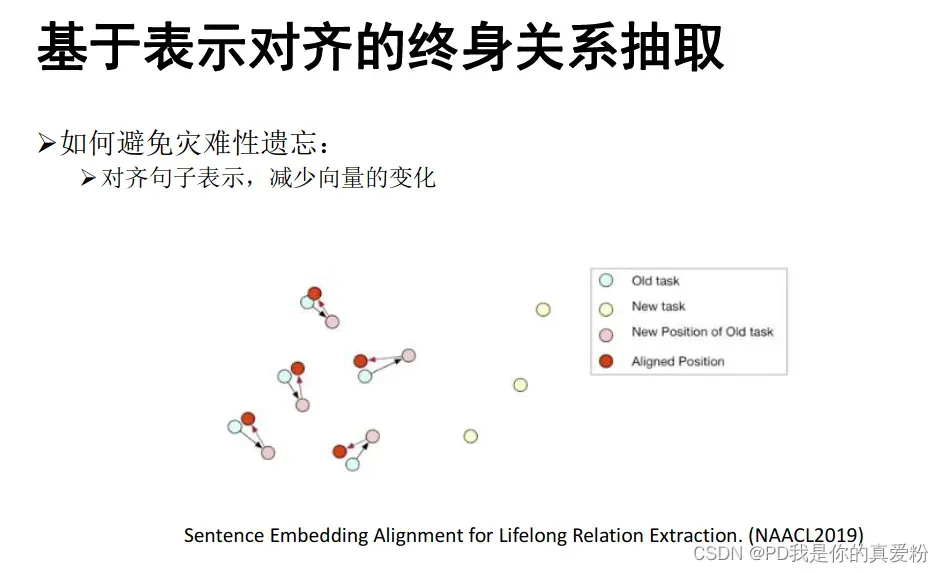


文章出处登录后可见!