机器学习相关知识
-
理解标签和特征的含义
以周志华老师在《机器学习》中判断好瓜的问题为例——给你一个西瓜,如何判断出一个它是不是正熟的好瓜?对于人类来说,根据以前的经验,我们首先会从西瓜这个具体的事物中抽取一些有用的信息,比如西瓜的颜色、瓜蒂的形状、敲击的声音等,然后根据一定的规则在这些信息的基础上进行判断————一般情况下我们认为颜色青绿、根蒂蜷缩、敲击浊响的西瓜是好瓜。
上述问题中,西瓜的颜色、瓜蒂的形状、敲击的声音就是特征,而“好瓜”和“坏瓜”这两个判断就是标签。
更抽象一点,特征是做出某个判断的证据,标签是结论。
机器学习主要的工作就是提取出有用的特征(比如卖西瓜的人的性别这个特征对判断西瓜是否是好瓜基本是没有用的,就不是一个好的特征),然后根据已有的实例(例如有一堆瓜,里面有好瓜也有坏瓜,并且已经标注(已有标签),也知道这些瓜的颜色、根蒂形状和敲击声音),构造从特征到标签的映射。
链接:https://www.zhihu.com/question/47235657/answer/104978721
-
监督学习和无监督学习:
-
监督学习:监督学习是最常见的一种机器学习,它的训练数据是有标签的,训练目标是能够给新数据(测试数据)以正确的标签。
例如,想让AI知道什么是猫什么是狗,一开始我们先将一些猫的图片和狗的图片(带标签)一起进行训练,学习模型不断捕捉这些图片与标签间的联系进行自我调整和完善,然后我们给一些不带标签的新图片,让该AI来猜猜这些图片是猫还是狗。
经典的算法:支持向量机、线性判别、决策树、朴素贝叶斯
-
无监督学习:无监督学习常常被用于数据挖掘,用于在大量无标签数据中发现些什么。它的训练数据是无标签的,训练目标是能对观察值进行分类或者区分等。相对于监督学习,无监督学习使用的是没有标签的数据。机器会主动学习数据的特征,并将它们分为若干类别,相当于形成「未知的标签」。
经典的算法:k-聚类、主成分分析等;
链接:https://www.zhihu.com/question/27138263/answer/635004780
-
-
拟合:过拟合、欠拟合、
-
评估模型泛化能力数据集切割:
-
留出法(hold_out method):常见的形式是把数据集切割成训练集、测试集和验证集,三者依次为Train/Test/Validation。
模型在训练阶段使用训练集,然后在测试集上评估模型效果 (此时训练集上的模型效果仅供参考,原因是用原来的数据集得到模型,在自身上验证,效果比较理想,但在实际应用过程中可能会大打折扣), 最后在验证集上评估。
训练集和测试集的分布非常接近,所以单用测试集做为效果评估指标显然不够,此时需要一批新的数据对模型在未知数据集(验证集)上做预测,以此刻画模型在新的数据集上的泛化误差。
在
sklearn提供的通用接口中,训练集和测试集的切分用train_test_split进行切割。train_test_split( *arrays, test_size=None,train_size=None,random_state=None,shuffle=True,stratify=None) # test_size可取0-1或者小于样本总量的整数,train_size为它的补集 # random_state为随机种子,值为非空时,可以复现,数值改变不会提升模型的性能 # shuffle 切割前打乱顺序 # stratify 分层train = pd.read_csv(r"E:\数分学习\hands-on-data-analysis-master\第三章项目集合\train.csv") data = pd.read_csv(r"E:\数分学习\hands-on-data-analysis-master\第三章项目集合\clear_data.csv") X = data y = train['Survived'] X_train,X_test,y_train,y_test = train_test_split( X,y, random_state=42,shuffle=True,stratify=y) -
交叉验证
-
留一法
-
自助法
-
模型建立
# 导入逻辑回归和随机森林包
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
-
逻辑回归模型
LogisticRegression(penalty='l2', *, dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver='lbfgs', max_iter=100, multi_class='auto', verbose=0, warm_start=False, n_jobs=None, l1_ratio=None)- penalty:
{‘l1’, ‘l2’, ‘elasticnet’, ‘none’}, default=’l2’正则化参数,为了解决过拟合,一般选择l2,当预测效果差的时候选择l1试试。如果是l1,solver只能选择liblinear class_weight:dict or ‘balanced’, default=None权重参数C:float, default=1.0值越小,正则化越强,复杂度越低- `solver:{‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’, ‘saga’}, default=’lbfgs’
lr1 = LogisticRegression(class_weight ='balanced').fit(X_train, y_train) print('逻辑回归训练集得分:{:.3f}'.format(lr1.score(X_train, y_train))) print('逻辑回归测试集得分:{:.3f}'.format(lr1.score(X_test, y_test))) - penalty:
-
随机森林模型
RandomForestClassifier(n_estimators=100, *, criterion='gini', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='sqrt', max_leaf_nodes=None, min_impurity_decrease=0.0, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, class_weight=None, ccp_alpha=0.0, max_samples=None)n_estimators:int, default=100随机树的个数max_depth:int, default=None最大深度
rfc = RandomForestClassifier().fit(X_train, y_train) print('随机森林训练集得分:{:.3f}'.format(rfc.score(X_train, y_train))) print('随机森林测试集得分:{:.3f}'.format(rfc.score(X_test, y_test))) rfc.predict(X_test) # 输出预测结果 rfc.predict_proba(X_test) # s
模型评估
-
模型评估是为了知道模型的泛化能力。
-
交叉验证(cross-validation)是一种评估泛化性能的统计学方法,它比单次划分训练集和测试集的方法更加稳定、全面。
-
在交叉验证中,数据被多次划分,并且需要训练多个模型。
-
最常用的交叉验证是 k 折交叉验证(k-fold cross-validation),其中 k 是由用户指定的数字,通常取 5 或 10。

from sklearn.model_selection import cross_val_score lr = LogisticRegression() score = cross_val_score(lr, X_train,y_train, cv=10) -
准确率(precision)度量的是被预测为正例的样本中有多少是真正的正例
-
召回率(recall)度量的是正类样本中有多少被预测为正类
-
f-分数是准确率与召回率的调和平均
概念理解参考:https://www.bilibili.com/video/BV14v411H7Gq?p=2
-
混淆矩阵
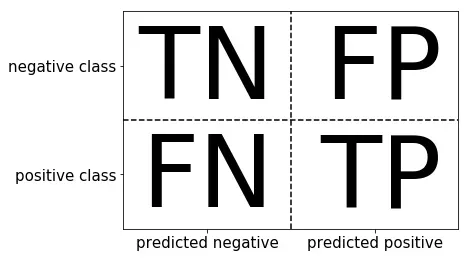
(准确率)
(精确率)
(召回率)
(F分数,精确率和准确率的调和平均数)
from sklearn.metrics import confusion_matrix lr = LogisticRegression().fit(X_train, y_train) y_pre = lr.predict(X_train) # 计算混淆矩阵 confusion_matrix(y_train,y_pre) # 输出 准确率,精确率,召回率以及f分数等 print(classification_report(y_train,y_pre)) -
ROC曲线
接收者操作特征曲线,或者叫ROC曲线(英语:Receiver operating characteristic curve),是一种坐标图式的分析工具,用于选择最佳的信号侦测模型、舍弃次佳的模型或者在同一模型中设置最佳阈值。
对于样本数据,我们使用分类器对其进行分类,分类器会给出每个数据为正例的概率,我们可以针对此来设定一个阈值,当某个sample被判断为正例的概率大于这个阈值时,认为该sample为正例,小于则为负例,然后通过计算我们就可以得到一个(TPR , FPR)对,即图像上的一个点,我们通过不断调整这个阈值,就得到若干个点,从而画出一条曲线。
from sklearn.metrics import roc_curve fpr, tpr, thresholds = roc_curve(y_test, lr.decision_function(X_test)) plt.plot(fpr, tpr,label="ROC Curve") plt.xlabel("FPR") plt.ylabel("TPR (recall)") #找到最接近0的阈值的坐标 close_zero = np.argmin(np.abs(thresholds)) plt.plot(fpr[close_zero], tpr[close_zero], 'o', markersize=10, label="threshold zero", fillstyle="none", c='k', mew=2) plt.legend(loc=4) #直接绘制roc曲线 from sklearn.metrics import plot_roc_curve lr1 = LogisticRegression(class_weight ='balanced').fit(X_train, y_train) lr2 = LogisticRegression(C=100).fit(X_train, y_train) LR1_dis = plot_roc_curve(lr,X_test,y_test,name = 'LR',response_method='decision_function') LR2_dis = plot_roc_curve(lr1,X_test,y_test,name = 'LR1',response_method='decision_function',ax=LR1_dis.ax_) LR2_dis = plot_roc_curve(lr2,X_test,y_test,name = 'LR2',response_method='decision_function',ax=LR1_dis.ax_)
转载请注明:
作者:vision
文章标题:copilot在Pycharm的应用
文章来源:1:城南花开;2:vision_wang的csdn
文章出处登录后可见!