前言
今天继续写王喆老师的《深度学习推荐系统》,我会根据已经梳理好的知识体系对其中的模型分别讲解。前面也已经讲过很多模型了,前一个模型是Deep&Cross其中是对W&D模型的Deep部分进行的改进。按理说今天还是将根据W&D的思想衍生而来的其他模型,但是今天先讲一下FM在深度学习时代的三大延伸模型变体FNN(Factorization Machine supported Neural Network)模型, DeepFM(Factorization-Machine based Neural Network)模型和NFM(Neural Factorization Machine)模型中的FNN模型,主要是为后面的两个模型打好基础。老规矩先来一下知识结构体系图。
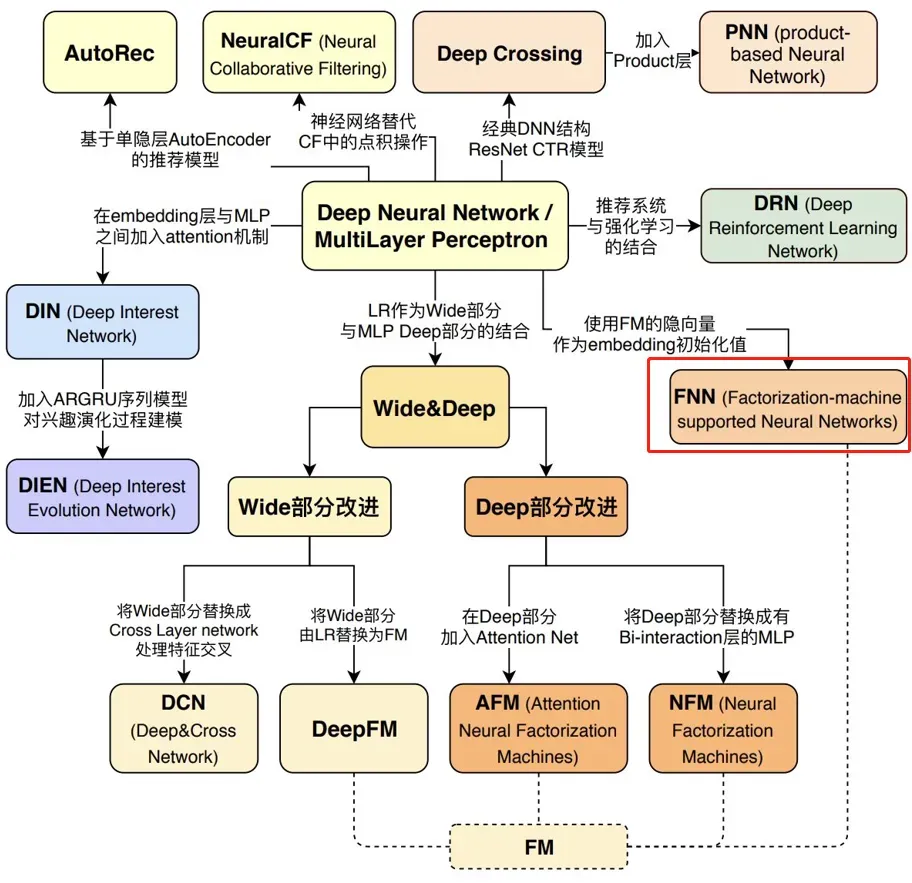
前面也写了很多经典的推荐系统中的模型了,今天也就在这里总结一下过去,展望一下未来。
对于现在的推荐算法来说总的就三点,一是加大特征之间的交叉,来增强算法的表达能力,在这一点上面DNN有着天然的优势,使得特征之间的高阶交互信息的挖掘和学习变得天然了一些, 可以非常容易的学习到特征之间的高阶交叉信息。二是虽然高阶的特征交叉非常好,但是过于深层的网络很容易产生无法训练的情况,因为推荐系统不像CV一样,数据大多都是稀疏向量,很难取训练大的网络。而且大型的DNN网络没有很强的记忆能力,并不能根据实时数据进行更新。所以2016年,W&D的提出开启了一个新篇章, 使得后面在其基础上出现了各种各样的组合模型,比如DCN,FNN,DeepFM, NFM等。三是像W&D需要进行繁重的特征工程,根据不同的特征进行不痛的操作,这样也是对人力不友好的。所以接下来的一个发展就是端到端的无脑高。在这里说一句题外话,虽然我也没有做过一些实际的推荐系统项目,但是我感觉在公司里面实习项目的时候还是做特征工程更多一些,就像kagger比赛一样,获胜者永远都是对数据敏感的那一队,这里说的不对的还希望大佬给出指正,感谢!
一、FNN模型原理
这是2016年多伦多大学学院的研究人员提出的模型, CTR预测任务中,针对传统的线性模型LR不能够利用特征之间的交互信息, 而一些非线性模型,如FM,表达能力不够强的问题, 在深度学习时代,提出了FM与DNN的组合模型基于因子分解机的神经网络(Factorization Machine supported Neural Network, FNN)模型, 该模型的灵感来自于图像领域CNN通过相邻层连接扩大感受野的做法,在CNN中通过缩小特征图的大小,进而获取更好的感受野,在FNN中也是类似,使用DNN来对FM显示表达的二阶特征进行再交叉,从而产生更加高阶的特征组合,加权模型对数据模式的学习能力。所以我还是持有这也观点,那就是深度学习很多领域都是相同的,并没有存在着某一个单独的学科,任重而道远啊。下面是这个模型的架构:
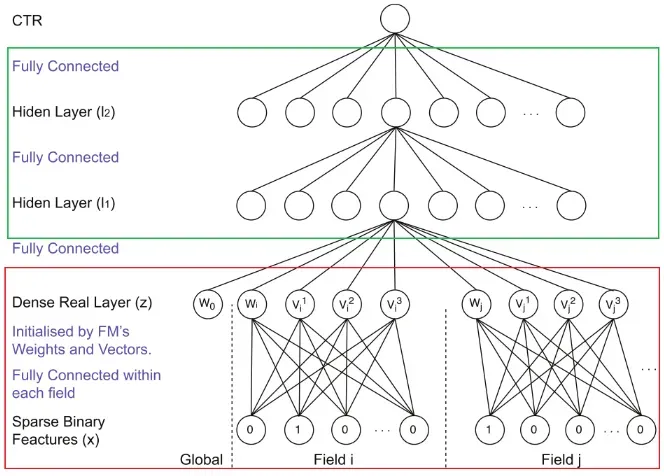
该模型初步看类似于Deep Crossing模型的经典深度神经网络,从稀疏输入向量到稠密向量的转换依然是embedding结构,但是该篇论文对embedding层的结构进行了改进,针对Embedding层收敛速度慢的问题,FNN模型用FM模型替换了下面的Embedding层,并且在模型的正式训练之前,先提前训练好FM,然后用FM训练好的特征隐向量对正式训练的模型进行Embedding层的初始化操作。这样在正式训练的时候,就加速了模型的收敛过程。
首先来看一下为什么说正式训练的embedding是很耗时间的。贴一下张图解释一下:

相信大家看完整张图就已经很清楚了,但是在这里我还需要唠叨的一句话就是,这个方法仅仅是减少了embedding训练的收敛时间,并没有减少参数,我当时在看这个的时候就进入到了这个误区。FNN采用了两阶段训练方式,这种两阶段方式的应用,是为了将FM作为先验知识加入到模型中,防止因为数据稀疏带来的歧义造成模型参数偏差。这样既可以加速模型收敛,也可以充分利用FM的特征表达。
首先是FM模型, 回忆一下数学公式:
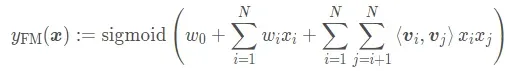
记不太清楚的小伙伴也可以回头看看我这篇文章。
参数主要是包括偏置, 一阶特征的权重
和二阶隐向量部分
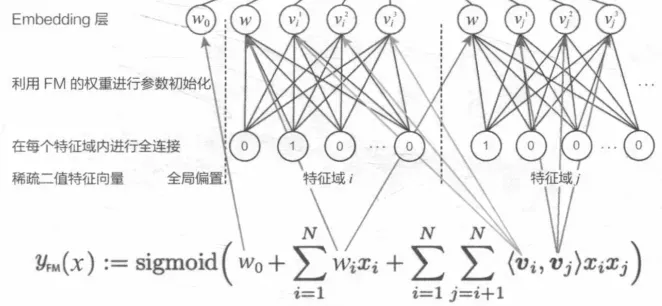
假设FM隐向量的维度是m , 第i 个特征域(Field i)的第k 维特征的隐向量![]() ,那么隐向量的第l 维
,那么隐向量的第l 维![]() 就会成为连接输入神经元k 与Embedding神经元l 之间连接的权重。 这里需要说明的是,FNN模型中是对特征域进行的特征划分,这种方式也成了后续处理高维稀疏性数据的通用做法,目的是为了减少模型参数量。这个可以看FFM那里,其实就是对于各个特征学习embedding表示,而不是先把特征one-hot之后再做,具体实现可能好理解一些,就是对每个类别特征直接LabelEncoder,对于每个样本,取出他们对应的embedding层向量计算即可。
就会成为连接输入神经元k 与Embedding神经元l 之间连接的权重。 这里需要说明的是,FNN模型中是对特征域进行的特征划分,这种方式也成了后续处理高维稀疏性数据的通用做法,目的是为了减少模型参数量。这个可以看FFM那里,其实就是对于各个特征学习embedding表示,而不是先把特征one-hot之后再做,具体实现可能好理解一些,就是对每个类别特征直接LabelEncoder,对于每个样本,取出他们对应的embedding层向量计算即可。
如果只看上图还看不太清楚的话,相信接下来这一些公式大家就可以彻底明白这些特征是如何进行处理的了。
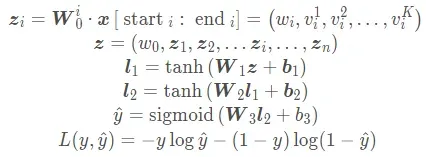
下标n代表的是一共有多少特征,其实就是把FM产出的低维稠密特征向量进行简单拼接,作为全连接层的输入了。这个计算就又是之前那些DNN计算的套路了, 每一层tanh激活,最终使用sigmoid得到输出值。
这样子的好处就是神经网络可以有更搞笑的在因子机中学习,高维交叉的计算复杂度问题就这样被解决了。FM在隐藏空间中可以很好的学习良好结构的数据表示,对任何进一步模型建立都有帮助。 具体训练中,其实作者对于FM和DNN都是先做一个单独的预训练, 前者采用了SGD,后者采用了RBM pre-training, 然后进行统一的训练方式,类似于迁移学习的思路。这样可以大大加速模型的收敛程度。
然后就是一些论文的细节问题了。该paper后面的实验里面做的比较充分,不仅做了对比实验, 还做了超参数调优, 架构选择和正则化方式的相关对比实验, 这里认识到了一种菱形架构, 超越了普通的那种神经网络, 作者分析原因可能是这种特殊形状的网络对神经网络能力有一定的约束,有更好的泛化能力。 作者在对比正则策略的时候提到了dropout比L2有效的一个原因之前也没注意过, 在用每个训练用例训练时, 每个隐藏单元都按照一定的概率随机的从网络中排除, 即每个训练用例都可以看做一个新的模型, 而这些模型的平均化则是一种特殊的bagging行为, 这有利于提高DNN模型的泛化能力。
二、FNN的不足
FNN采用了组合模型的思想,引入了DNN,可以进行特征的高阶组合, 减少了特征工程,并在一定程度上增强了FM的学习能力, 在模型训练的时候也是采用了一些预训练的方式。这些尝试都是一些新思路,我们可以学习,这些感觉比模型本身重要, 当然,FNN是存在一些问题的。
简单的讲, FNN几个比较大的缺点:
1、两阶段的训练模型,应用过程不太方便,且模型能力受限于FM表征能力的上限
2、只关注于高阶组合特征的交叉
3、两阶段训练方式也有问题。FM中特征组合,使用的隐向量的点积运算。将FM得到的隐向量移植到DNN中作为DNN的输入, 全连接层这时候会将输入向量的所有元素加权求和,且不会对Field进行区分。 这个其实又回到了之前说Deep Crossing时的问题,全连接隐层把所有特征进行了统一的交叉学习, 这在很多场景下其实是不太合理的(这样可能会使的即使没有半毛钱关系的特征在这种情况下也会发生点关系,也可能会使几个很亲密的特征也很难擦出点火花),没有什么针对性, 所以使得模型的学习能力受到限制。 所以DNN和FM在理解特征组合的层面上时存在差距的。 所以之前的PNN中, 采用了一个专门研究特征交叉的product-layer来换掉了这里的FM,换掉了Deep Crossing中的Stacking-layer层, 使得能够进行特征之间的两两交互,使得特征交叉的学习有了针对性(这里也要注意一点, 虽然PNN模型整理的比较早,但其实它的出现是在FNN的后面的, DeepFM中,作者也对比了这几个模型)。这种两阶段的训练方式给神经网络的调参带来了难题, 因为FNN的底层参数是预训练得到的, 所以在反向传播更新参数的时候,不能学习率过大,否则会将FM得到的信息给抹去。所以底层的学习率要小一些。
参考:AI上推荐 之 FNN、DeepFM与NFM(FM在深度学习中的身影重现)
文章出处登录后可见!