



I. INTRODUCTION
作为替代的BTP解决方案,最近开发的同态加密(HE)(例如,[5])加密生物测定模板,然后在加密的通道中执行模板比较。在客户端[5]中解密模板比较结果。然而,HE方法通常需要很高的计算成本[3]。
虽然对齐实现了所期望得到的性能,但是需要额外计算上的开销。如果有BTP附加操作,则时间复杂度大大增加!
我们所提出的是一个可取消的生物识别方案,它的灵感来自众所周知的梯度直方图[13]。与现有的生物识别工作将HOG视为特征提取方法[14],[15]不同,我们展示了一个新的个HOG变体,它可以直接将未对齐的虹膜编码特征转换为对齐健壮的可取消模板。在这里,我们概述了选择HoG作为实现我们的可取消生物识别方案的合适方法的主要动机:
- HOG是通过对本地信息的统计读数得出的,该信息自然具有对齐-健壮属性。因此,该机制可用于消除转换期间的irisCode对齐问题。
- 在HOG中使用的多对一映射提供了原始irisCode特征的隐藏,该特征对于BTP中的不可逆性至关重要。
由于所得到的可取消模板对于比对来说是健壮的,因此在模板比较期间不需要特征比对,这提高了识别过程的效率。简而言之,我们的贡献重点如下:
- 我们设计了一种新的可取消的生物特征识别方案,称为随机增强梯度直方图(R·HOG),用于保护未对齐的虹膜编码特征。可取消模板对于虹膜代码中的水平移位问题是健壮的;因此,与现有的作品相比,它需要较少的计算开销或存储空间,例如,[16],[17]。
- 认证性能在基准CASIA-IrisV3-Internal and CASIA-IrisV4-Thousand数据集上是合理的。此外,使用基准评估框架对R·HOG的不可链接性进行了检验[18]。
- 我们基于个主要攻击,例如通过输入枚举攻击、Brute强迫攻击、虚假接受攻击和生日攻击,研究了R·hog的安全性和隐私性。
II. RELATED WORK
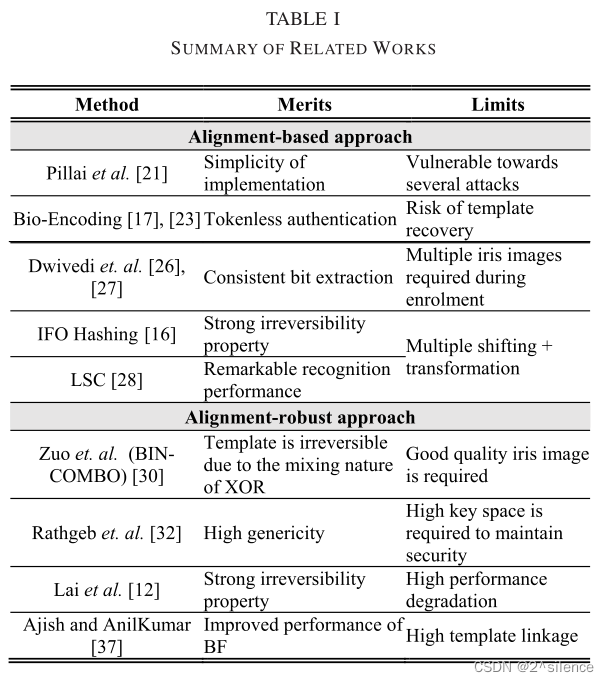
在这一节中,我们回顾了几个与我们的方案相关的虹膜可取消生物特征识别的工作。这些方案被大致分为(A)基于对齐的方法和(B)对齐-稳健方法。在基于对准的方法中,可取消的生物测定方案需要特征对准过程来处理虹膜特征的对准问题。通常,在BTP中有种类型的特征对齐。第一种类型是将可取消生物测定方案应用于多个个移位的生物测定实例,然后将所有移位的个实例变换为可取消模板以用于存储或比较的目的(例如,[16])。另一种类型是基于参考生物特征提取移位不变的生物特征,然后将该移位不变的生物特征变换成个可取消的生物模板(例如,[17])。另一方面,对齐稳健方法是指对于两个个相似的未对齐特征,可以直接产生相似的可取消模板的BTP方案。由于页面长度的要求,我们只关注虹膜可取消的生物特征识别。其他种类的生物识别安全和隐私解决方案可以在[1]、[19]、[20]中找到种。尽管基于深度神经网络(DNN)的种特征在人脸生物识别中受到广泛关注,但虹膜编码仍是目前虹膜识别中使用最多的特征。因此,现有的大多数可取消的生物识别作品都是为了保护虹膜代码而设计的。因此,我们的综述主要集中在个传统的虹膜特征上。
A. Alignment-Based Approach
B. Alignment-Robust Approach

III. PRELIMINARY
A. Histogram of Oriented Gradient (HoG)
方向梯度直方图(HOG)[13]是在计算机视觉(CV)领域中被广泛使用以检测图像中的对象的特征描述符。HOG通过梯度量级和方向来表征对象的局部结构和形状。对于特征形式化的简单视图,使用直方图来统计地记录图像中梯度取向的频率分布(梯度大小)。经典HOG特征提取的过程是:(A)给定图像I,HOG将I分成几个重叠区域(cells),并计算每个cell的梯度取向的直方图。每个直方图bin由跨越0◦−180◦或0◦−360◦的固定范围方向定义。(B)之后,每个单元将梯度幅度添加到相应的直方图框。(C)最后,应用直方图归一化来提高HOG 特征对光照变化的稳健性。在HOG算法中,将357个重叠的单元格分组为一个block,并在每个block中进行归一化。最后,归一化的块直方图表示HOG描述符。
(一个cell有一个直方图,归一化是在block范围内的)
IV . METHODOLOGY
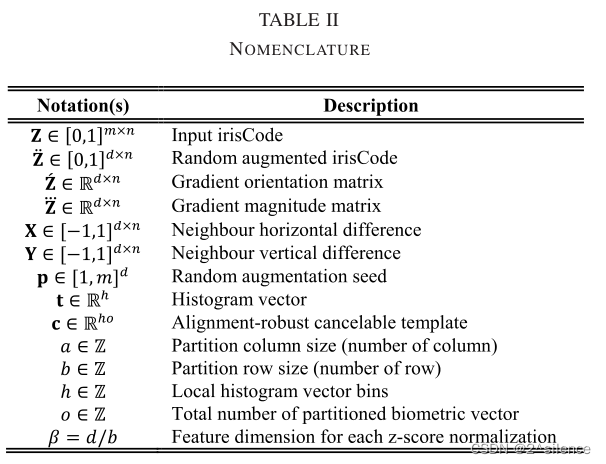

A. Overview
R·HOG方法可以分解成两个主要组件:a)输入虹膜编码的随机和区别性特征变换。这涉及使用随机生成的变换密钥,以列向量方式增加输入 irisCode。B)多对一映射过程,以将随机化虹膜编码特征变换为不可逆特征向量(可取消模板)。这涉及随机虹膜编码特征的每个不重叠的分区中的梯度出现计数。由于普遍的可消除虹膜模板对于对准是稳健的,所以参考的可撤销虹膜模板可以直接与存储的探测的可撤销虹膜模板比较,没有如上所述的预对齐策略,大大降低了认证过程的时间复杂度。
B. Detailed Approach
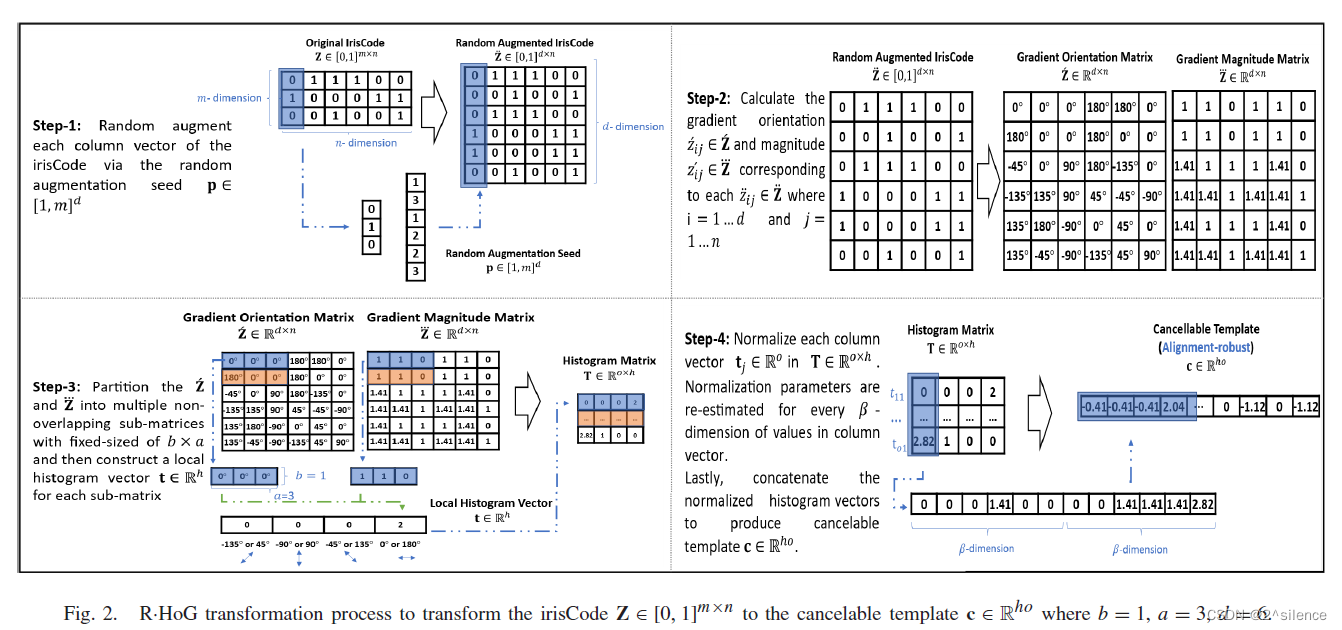
1)R·HOG可取消T模板生成:在虹膜验证中,在虹膜扫描过程中,头部倾斜、相机倾斜或眼睛旋转导致提取的虹膜代码[11]中的水平位移位问题。位移位问题可能导致严重的验证性能降低;因此,许多现有的虹膜可消除生物识别方案需要预对准过程来处理该问题。然而,预对准过程可能增加认证过程的时间复杂性。在这篇文章中,我们展示了一种新的使用定向梯度直方图(HOG)来从个未对准的虹膜编码(特征)中导出对齐鲁棒的可取消模板。HOG最初被设计为,用于统计记录像素梯度的频率分布以检测图像中的对象[13]。与现有的只猪生物识别相关工作研究特征提取[14]、[15]不同,我们探索了基于猪的特征在BTP中的非常规用法。提出的随机增强梯度直方图(R·HOG)是基于HOG的特征[13]的扩展,结合了列矢量随机增强和梯度方向分组机制。
在所提出的方案中,通过使用HIS-直方图向量来记录虹膜编码中局部信息(梯度方向)的频率分布来产生对齐鲁棒的生物特征向量(或可取消模板)。为了在之前服务于原始虹膜编码的验证性能,我们对输入的虹膜编码进行了特征增强处理。这样,增加了梯度方向的种群,并且提高了相似输入虹膜编码的可取消模板的相似度。由于虹膜编码的水平位移位,随机增强以列向量的方式执行。由于涉及随机生成的信息,这使得能够更新属性,其中所提出的方案可以为相同的输入虹膜代码产生多个个不相关的可取消模板
在R·HOG中,每个直方图向量由使用基于方向的直方图来构建,以记录每个


给定未对准的虹膜编码

1)列向量随机增强(








2)梯度取向和大小计算(






左-右,上-下,方向是小的指向大的
其中X和Y表示水平和垂直差矩阵,而rCirShift(.)和cCirShift(.)是行式循环移位函数和列式循环移位函数,例如,rCirShift(


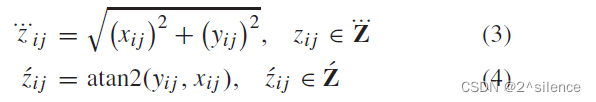

其中atan2(.)。是指四象限的逆切线,i=1…d和j=1…n表示元素在矩阵中的位置(行和列)。在我们的例子中,atan2(0,0)的结果被计算为0◦。
3)特征矩阵划分和直方图形式化(









4)Z-Score变换:对于每个列向量







其中i=1…o表示


之后,将h个







所提出的方案实质上是一种对齐稳健的变换方案,其将未对齐的虹膜编码
命题1:给定两个向量




讨论:在步骤3变换中,所提出的方案将生物特征变换为直方图向量



通过以上讨论表明,所提出的方案可以将虹膜码
C. Comparison of Cancelable Template
一般来说,直方图特征之间的相似性比较可以通过计算欧几里得距离来完成。在方案中,可抵消的虹膜模板是一个串联的直方图向量,因此,我们采用归一化的欧几里德相似性作为比较器。给定使用相同的随机增强种子

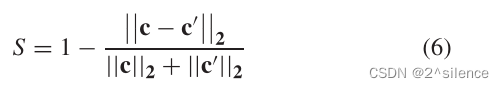

其中


V. EXPERIMENTS AND DISCUSSIONS
A. Experimental Setup
在这一小节中,解释了实验设置。本文重点提出了一种可撤销的生物识别方案,因此,我们采用了文献[11]、[38]中的软件来提取虹膜编码。所提出的方案使用MA TLAB(V er. R2021b),并在配备固态硬盘(SSD)500 GB、Intel Core i7 第七代CPU 2.80赫兹和内存DDR4 24GB的PC上进行模拟。
1) Dataset and Comparison Protocol:
为了验证提出的方案,我们使用了两个公开可用的数据集,即CASIA-IrisV3-Internal和CASIA-IrisV4-Thousand[39]。CASIA-IrisV3-Internal是一个数据集,共有个249个受试者(每个受试者都有不同数量的虹膜图像)。为了与现有的虹膜可取消生物特征识别工作(例如,[17]、[26])一致,我们的实验只考虑了左眼。除此之外,我们通过选择具有7个虹膜图像的受试者来子集数据集,以标准化每只眼睛的比较数字。因此,总共提取了868个虹膜编码(124个被试,每个被试×7个样本)用于实验。对于 CASIA-IrisV3-Internal,我们采用[16]中的设置来获得 IrisCode。
另一方面,CASIA-IrisV4-Thousand数据集包括总共1000名不同年龄的受试者[39]。在CASIA-IrisV4-Thousand获取虹膜期间的光切换增加了类内变化(例如,镜面反射)[39]。同样,实验中只考虑了个左眼图像。IrisParseNet1[38]被应用到虹膜图像的预处理中,应用

在实验中,验证性能的评估主要基于真实/冒名顶替者比较分数分布的等错误率(EER)(%)[40]。给定具有m个对象和每个对象n个数个样本的数据集,下面是比较试验:
- 类内(或真正的)比较试验:交叉比较来自同一子个对象的可取消模板;因此,为每个受试者生成n个样本的
- 类间(或冒名顶替者)比较试验:交叉比较从不同对象的第一个样本生成的所有可取消模板;因此,总共生成


对于CASIA-IrisV3-内部,2604个真正的比较分数和7626个冒名顶替者的比较分数。对于CASIA-IRISV4-000,有42750个真实比较分数和 450775个冒充比较分数。由于在该方案中随机生成数据(即随机增强种子
B. Parameter Estimation
在这一小节中,通过几个实验来验证变换参数对所提出的R·HOG的验证性能的影响。需要注意的是,参数h固定为4,而参数β固定为d b。有三个可调参数,即a、b和d)。
1) Effect of Random Augmentation Size d:
在这一子节中,我们考察了随机增强大小d与验证性能的关系。在所提出的方案中,对输入的虹膜编码进行随机增强,以增加R·HOG中梯度Orienta变换入库的信息量,并使用参数d来控制这一过程。为了验证d,通过设置d从20到250进行实验;而其他参数固定在a=32,b=1。注意到d=20只实现了随机洗牌效果,因为初始行大小虹膜代码m=20。表III列出了不同d在 CASIA-IrisV3-INTERNAL中可取消模板的EER和特征维度。
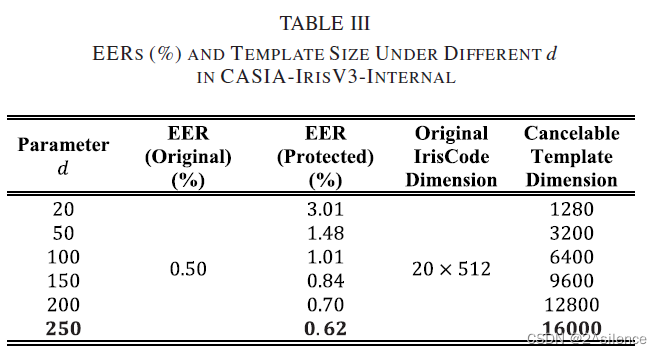

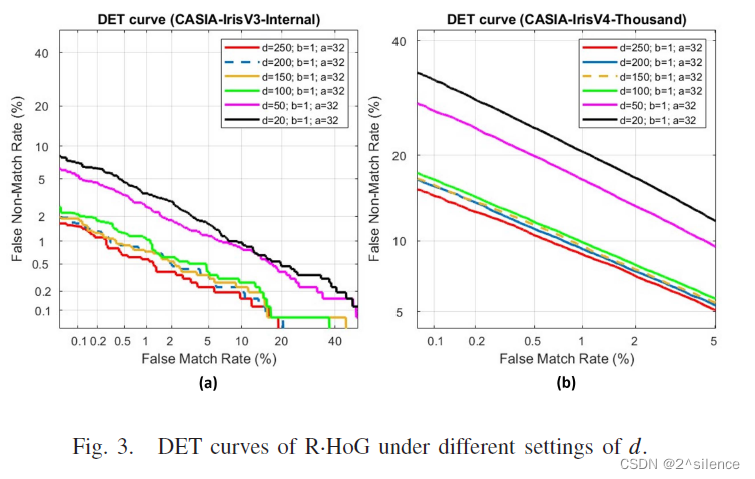
从表中我们观察到,EER随着d的增加而减小。这意味着随机增强正在对改善可撤销模板的识别性能产生效果。从表中可以看出,当d=20(没有增强)时,EER处于最高点,当d从20到100时,EER开始下降。然后,当d≥100时,递减进入较慢的速度.。在d=250时,EER达到低点,其中EER=0.62%。此外,d对两个数据集的影响也可以从下面的检测误差权衡(DET)曲线中观察到。尽管d可以增加,但我们没有考虑d>250,因为这会导致大的可取消模板维度和用于转换的高计算时间。在这里,对于两个个数据集都选择了d=250。

2) Effect of Partition Column Size a, Row Size b:
在所提出的方案中,对齐鲁棒的可抵消模板是由来自个虹膜编码的多个非重叠分割块(ZPart∈[0,1]b×a)的局部直方图向量连接而成的。参数a和b用于确定每个分区块的列和行大小。为了验证个不同尺度的分区块,在a和b的不同设置下进行了个实验,而d固定为250。表IV列出了在两个数据集中具有个不同设置的a和b的可取消模板的EER。此外,图4和图5描绘了在不同a和b下的R.Hog 的DET曲线。
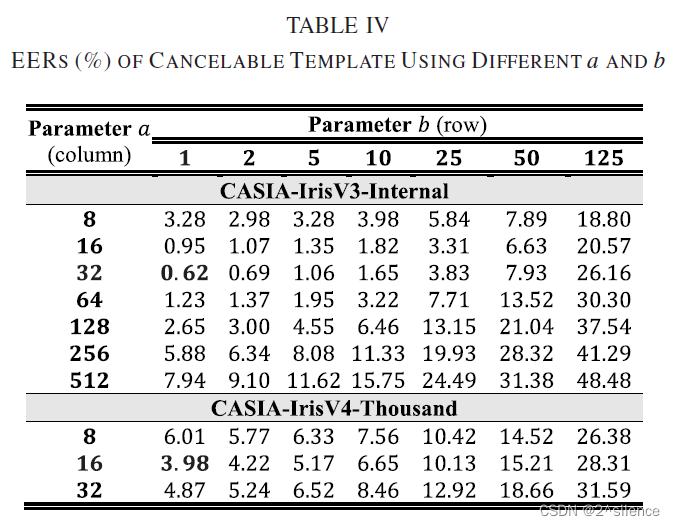
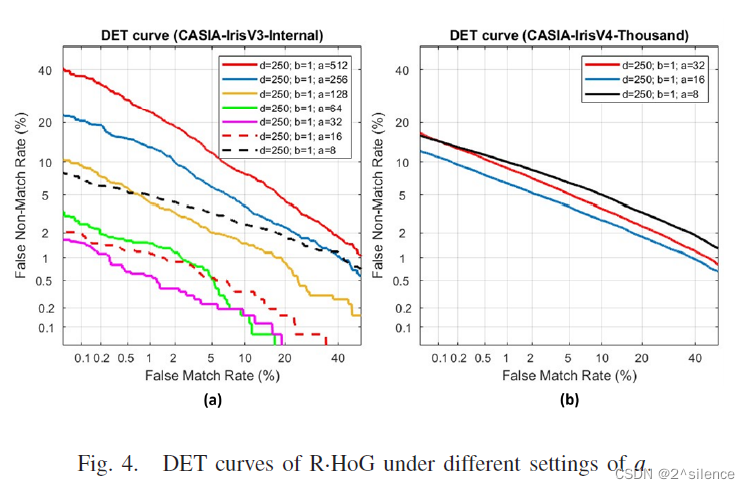


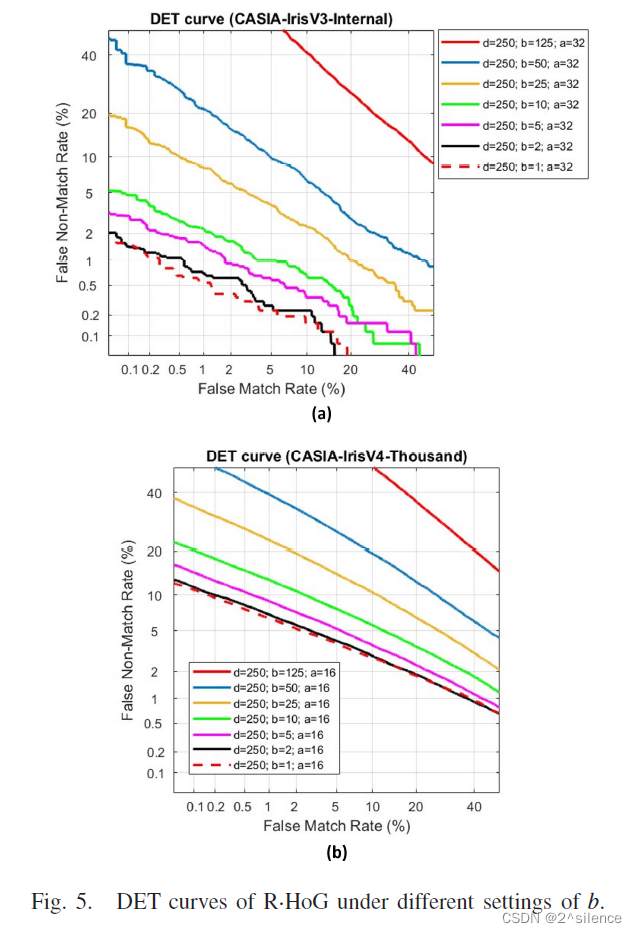

正如预期的那样,特征划分可以提高可取消模板的验证性能。从表中可以看出,当710a和710b较大时,EER处于较高的水平。如观察到的,EER随着a和b的减小而逐渐降低。观察到a和b的较低设置可以实现更好的验证性能,因为EER平均低于较高的a和b。因此,建议降低a和b以获得更好的验证性能。由于高a导致高EER,即使在the CASIA-IrisV3-Internal中,因此在随后的实验中不考虑a>32。尽管a的减量可能会降低EER,但不能将a设置为a非常低的值,因为EER开始增加。在我们的上下文中,我们选择{a=32,b=1}作为CASIA-IrisV3-Internal的设置,而选择{a=16,b=1}作为CASIA- IrisV4-Thousand的设置。
3) Summary of Parameter Estimation:
在整个参数估计中,得出了几点结论:
1)增加随机增强大小d可以降低等误码率(EER)(%)。这是因为在直方图公式处理期间,相似虹膜编码的梯度方向的增大;因此,
2)随机增强大小d导致所产生的可取消模板的模板大小和转换所需的时间的增加。因此,在为d选择合适的值时,必须考虑计算开销和性能之间的权衡。
3)通过分割虹膜代码可以保持原始虹膜代码的验证性能。参数a和b用于确定子块的列和行大小。为了保持原始虹膜编码的验证性能,a和b应该保持在较低的值。还应注意的是,不能将a设置为非常低的值,以防止直方图公式的梯度方向不足。
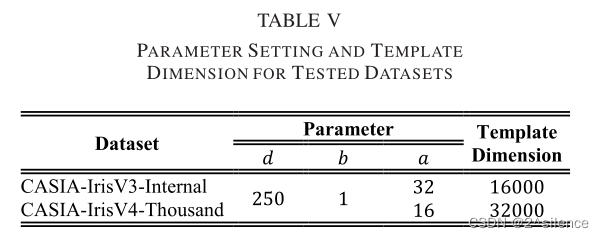
最后,下表列出了我们的测试组的参数设置摘要。随后的实验是基于列表参数进行的。

C. Verification Performance and Comparison
在这一小节中,我们给出了与ISO/IEC 19795[40]中列出的不同指标相关联的提出的R.HOG的验证性能。
1) Verification Performance of R·HoG:
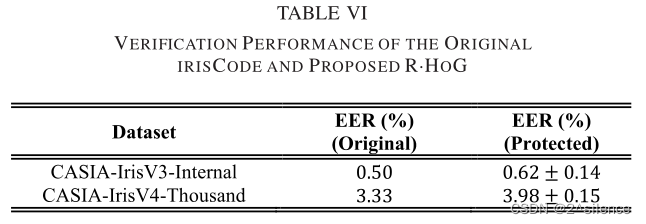
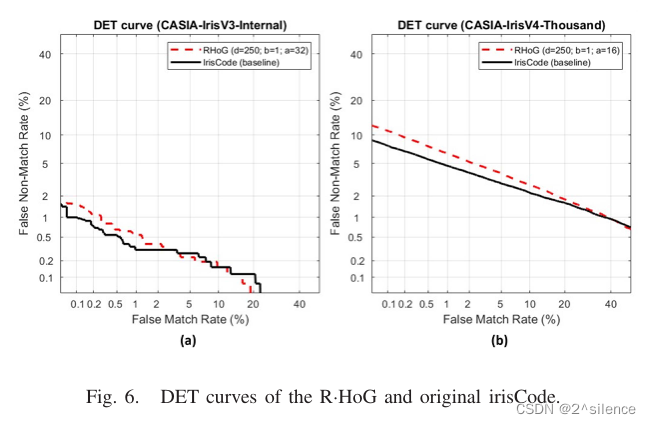
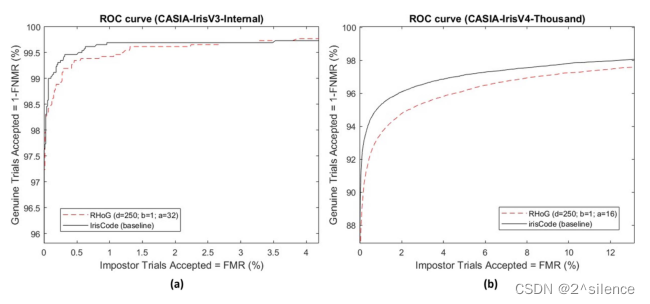
这一小节从(i)平均EER、(ii)接收器工作特性(ROC)/检测误差折衷(DET)曲线和(iii)错误匹配率(FMRS)下的错误不匹配率(FNMR)来呈现所提出的R.HOG 的验证性能。表六以表格形式列出了原虹膜编码和拟议的R.HOG 在EER方面的验证性能。对于CASIA-IrisV3-内部,基于的水平移位获得了原始虹膜编码的验证性能。
对于CASIA-IrisV3-Internal,原始模板是基于±16水平移位获得的。对于CASIA-IrisV4-Thousand,应用±8水平移位与原始模板比较。从列表的EER中可以看出,所提出的R·HOG能够保持原始虹膜编码的验证性能。另一方面,基于描绘的 ROC/DET曲线,观察到R·HOG的验证性能与CASIA- IrisV3-Internal中的原始irisCode相当,而在CASIA-IrisV4-Thousand中观察到更大的退化速率。



2) Comparison to the SOTA Iris Template Protection Methods:
在本小节中,提出的R·HOG模板和现有虹膜模板保护方法的验证性能(EER)是基于CASIA-IrisV3-Internal报道的,由于它被大多数存在的方法所应用。可以观察到,现有的不同作品中实验的虹膜图像数量是不同的,尽管使用的是相同的数据集。例如,我们使用了个CASIA-IrisV3-内部子集,有124个(左眼)受试者个,每个受试者7个样本。此外,现有研究中还没有标准化的比对方案。例如,我们的比较协议包括2604个真正的比较,个分数和7626个冒充比较分数,每个实验中CASIA-IrisV3-Internal。因此,很难在不同研究之间进行公平的比较。然而,为基准目的,报告了拟议计划和现有计划的摘要。如上所述,基于DNN的虹膜验证方法很少见;因此,不考虑。
D. Runtime and Time Complexity
在该子部分中,根据将未对准的虹膜代码转换成对准稳健的可消除虹膜模板的运行时间(秒)来评估提出的方案的计算效率。对注册过程的模拟包括:(i)辅助数据生成和(ii)R·HOG 变换。验证过程包括(i)R·HOG 转换和(ii)模板比对。通过将生产的可撤销模板与预先存储的模板进行比较来模拟模板的比较。对于每个数据集,对所有可用的样本重复实验。对于个实例,在CASIA-IrisV3-Internal上进行总共868了轮测试。此外,利用 SIC-Gen算法4[41]生成由30,000个合成虹膜编码组成的合成数据集。为了生成正确大小的虹膜代码,

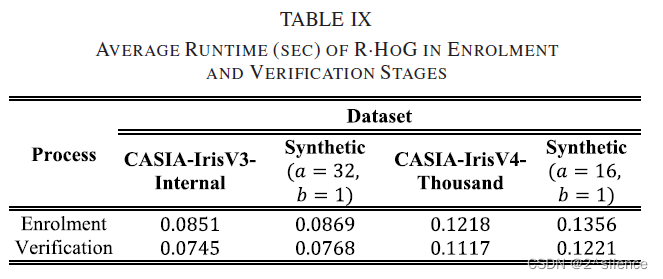

从表中可以看出,对于所有数据库注册阶段的运行时间比验证阶段长。这主要是由于在每个注册模拟中初始化伪随机数生成器的开销。
除此之外,R·HOG过程的时间复杂度将原始虹膜码转换为可取消模板被表示为Big-O记法。根据算法1,R·HOG可以被构造在四个独立的环路上,每个环路都具有复杂度dn、dn、oab和ho,其中oab=dn,因为
在原始虹膜编码中,使用了归一化的Ha-ming相似性(带水平移位),而对于R·hog,使用了归一化的欧几里得相似性(直接比较)。因此,还计算并报告了与两种虹膜编码的模板比较的持续时间。模板比较所需的平均时间在表X中报告。
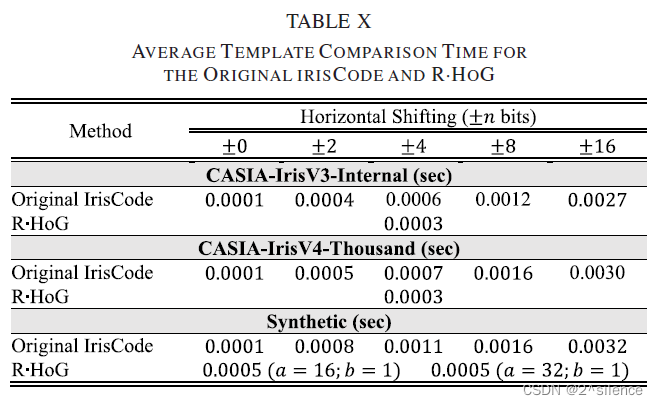

如预期的那样,±n位移位的增量可能增加比较两个给定虹膜码的时间。另一方面,在较低的移位下,R·HOG编码的比较时间与原始虹膜编码的相当。这主要归因于在一对产生的可取消模板之间的直接比较(没有移动)。
VI. SECURITY AND PRIVACY EVALUATION
在这一部分中,我们评估了提出的可取消生物特征识别方案的安全性和保密性。在我们的评估中,假设最坏的情况,其中对手研究变换算法。此外,变换参数(d,a,b,β和h)和辅助信息(
A. Irreversibility Evaluation
不可逆性是指从可取消模板中恢复原始虹膜代码的不可行性。在这个子部分中,使用三个攻击来评估不可逆性,其中攻击者的目标是从个受损的可取消虹膜模板和个随机增强种子中恢复输入的虹膜代码。
1) Inversion Attack via Single Record:
在这一小节中,我们讨论了从单个可取消模板


知道可取消模板




命题2:给定z-score归一化向量
讨论:假设存在向量


其中i=1,…,o,t的恢复(去归一化)可以通过反转归一化过程来实现。在这种情况下,我们可以反转公式(7)来计算



其中i=1,…,o,已知


命题3:没有μ和σ,从归一化向量
讨论:Z-score归一化是利用输入数据的概率分布来将输入数据转换成重新缩放的数据的过程。通常,Z-score归一化可以为不同的输入产生具有相似尺度的归一化数据。假设有三个向量,即t1=[1,0,1],t2=[2,0,2]和t3=[3,0,3],应用z-Score归一化,将μ和σ设置为相应向量的平均值和标准偏差。尽管t1、t2和t3不同,Z-score归一化产生相似的归一化向量,即

上述陈述讨论了以逆变换方式从归一化向量恢复原始向量的可行性。它表明,当归一化参数(即,在我们的例子中为μ和σ)未知时,归一化过程是不可逆的。在该方案中,μ和σ是生物统计相关信息,因此真正的用户可以在验证阶段重新生成μ和σ。因此,在生成可取消的模板c之后,处置μ和σ而不存储它们。由于无法获得μ和σ,因此很难为进一步的反演尝试揭示原始向量
2) Inversion Attack via Multiple Records:
在这个攻击中,攻击者试图基于多个被攻破的可取消的模板
命题4:给定两个来自不同




讨论:在所提出的方案中,对输入Z应用随机增过程以产生






在参数{a=4,b=1,β=4,h=4}的情况下,在第四步变换期间首先获得




上述陈述讨论了使用来自不同c的
3) Attack via Input Enumeration:
在该攻击中,攻击者旨在通过输入枚举攻击恢复原始虹膜编码


![]()

其中,猜测尝试指的是猜测中正确的

B. Security Evaluation
在可撤销生物特征识别中,安全属性是指利用猜测的模板抵抗攻击获得非法访问的方案的的可行性。在这一小节中,我们使用针对生物识别系统的三个主要安全攻击来评估安全属性。
1) Brute-Force (BF) Attack::
在该攻击中,攻击者穷尽地猜测可取消模板






整个



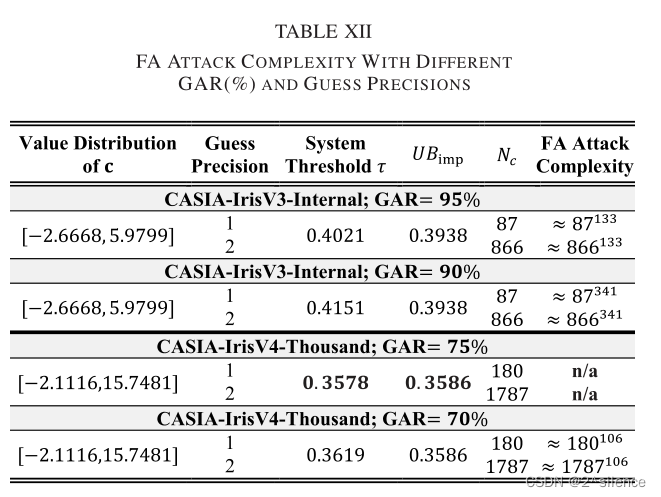
2) False Acceptance (FA) Attack:
生物识别系统是一种基于阈值的决策系统,当比较分数超过系统阈值

传统上,通过计算生成的

FA攻击是在最坏情况下进行的,其中对手第一次生成

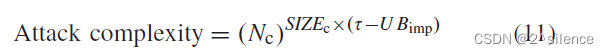

其中,

![]()

由于该评估的主要目的是找到合适的
表XII列出了在两个数据集中不同阈值



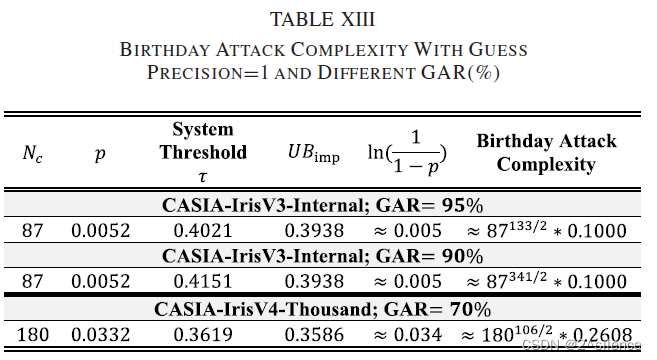
3) Birthday Attack:
在BTP中,生日攻击指的是它利用生物特征的冲突来获得对系统的访问权限的攻击[35]。在本文中,生日攻击是攻击者的目标是获得一个假虹膜代码
这种分析是通过计算攻击的生日界限来确定的[43]。在这里,我们对生日界限(攻击企图)进行简要描述,然后将生日攻击公式化到我们的案例中。假设变换函数f(Z)可以产生H个可能的输出,则获得
![]()

其中p是Z和
在我们的文中,生日攻击作为FA攻击的扩展来进行,其中对手最初猜测


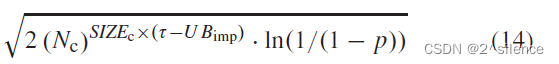

其中p是
表 XIII列出了两个数据集相对于系统阈值不同的真实接受率(GAR)的攻击复杂性。从表中我们观察到,与虚假接受攻击( the false acceptance attack)相比,攻击的复杂性降低了。然而,通过将


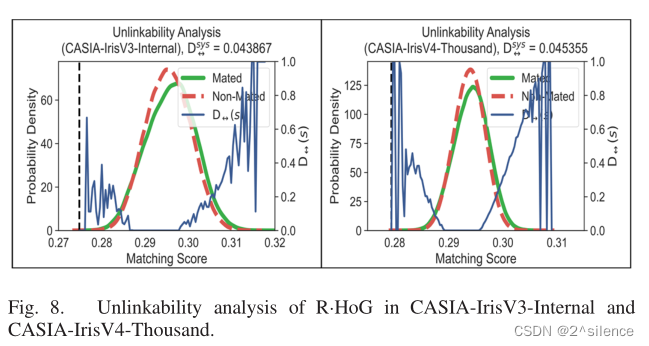
C. Unlinkability Evaluation
不可链接性对于可撤销的生物特征方案是重要的,对于相同的生物特征输入以允许可取消模板的再现,同时最小化不同应用中的多个生产的可取消模板之间的链接。在这一小节中,我们基于源于[18]的基准分析框架来论证R·HOG的不可链接性。具体地,该评估框架依赖于两个指标,即


- Local measure:
- Global Measure:
这些指标是根据配对/非配对的个样本得分分布(the mated/non-mated samples score distributions)[18]来计算的,该分布是通过以下个比较试验产生的:
- Mated samples comparison trial: 交叉比较从每个虹膜产生的个可取消模板c。
- Non-mated samples comparison trial:交叉比较不同虹膜的第一个样本产生的个c。
在两个比较试验中,使用不同的

VII. CONCLUSION
在本文中,我们提出了一种对齐稳健的可取消的生物特征识别方案,称为R·HOG用于虹膜模板保护。该方法借鉴了方向梯度直方图的思想,克服了虹膜特征的预对齐问题,生成了一个对齐稳健的可抵消虹膜模板,用于有效的比对。两个主要机制:利用列矢量随机增强和定向分组机制,使R·HOG具有性能保持性和不可逆性。在最坏情况下验证了的识别性能,其识别性能可以接受,的平均EER=0.62%(CASIA-IrisV3-Internal),的EER=3.98%(CASIA-IrisV4-Thousand)。除此之外,我们证明了R.HOG可撤销生物识别方案能够抵抗主要的安全和隐私攻击,例如虚假接受攻击和生日攻击。通过牺牲一定的水平的真实接受率(GAR)来换取较高的阈值
文章出处登录后可见!