概述
本文提出了一种新的语言模型-Bert,由transformer中的标准的双向编码器表示。该结构通过在所有层中对左右两边上下文进行联合调节,来对无标签文本进行预训练。实验证明,在该预训练模型上加入特定输出层后能够在多个文本任务中取得最好的成绩。包括将GLUE分数提升到了80.5%,7.7个百分点的绝对提升。
介绍
目前有两种将预训练的语言表征应用于下游任务的策略:feature-based和fine-tuning。前者(如ELMo)使用特定的任务架构,包括将预训练的表征作为额外的特征。后者(如GPT)引入最小的特定任务参数,简单地迁移所有预训练参数来在下游任务上进行训练。
这两种方法在预训练过程种共享相同的目标函数,都是使用单向的语言模型来学习总体的语言表征。由于目前标准的语言模型是单向的,对于预训练结构的选择有一定限制。例如GPT中,使用了从左到右的一个结构,每个token只能关注到在自己之前的token。对于句子级别的任务这是次优的,并且使用基于token级任务的预训练模型来进行微调可能是有害的。因为在这种情况下,从两个方向来纳入上下文是非常重要的。
本文提出的Bert通过在预训练中使用”masked language model“,缓解了以上提到的限制。该模块将输入的token随机地mask,然后通过上下文来对这个token进行预测。除此之外,还增加"next sentence prediction“模块来对预训练文本对表征。
本文主要贡献:
1)证明了语言表征上双向预训练的重要性;
2)表明了预训练好的表征可以减少很多大型工程化特定任务架构的需求;
3)在11个NLP任务上取得了最好的成绩;
无监督的feature-based
预训练的词嵌入是现代NLP系统中的一部分,和从头开始学习的embedding比有一个很大的提升。为了训练词嵌入向量,已经有了从左到右的语言模型,和在上下文中区分正确和错误的单词的模型。同样,在句子和段落上,之前的工作是对候选句子进行排序,或者给点定前句子的表征来生成下后一句等。
ELMo等沿着不同的维度概括了传统词嵌入的研究,从一个从左到右和一个从右到左的语言模型中提取上下文敏感的特征。每个token'的上下文表示是从左到右和从右到左表示的串联。Melamud等人提出使用LSTMs从左右两边上下文中预测单词,该模型是基于特征而不是深度双向特征。Fedus等人表明cloze任务可以用来提高文本生成模型的稳健性。
无监督的fine-tuning
该方法的首要任务是在无标签的文本上预训练词嵌入的参数。已经有通过在无标签文本上进行预训练来生成上下文token表征的句子或文档编码器,并且能在有监督的下游任务中进行微调。这种方法的好处就是需要从头开始学习的参数很少。
从有监督的数据中迁移学习
目前已经有很多工作表示在大数据集上进行监督训练是有效的,计算机视觉上的研究也表明使用大型的预训练模型进行迁移学习的重要性。
方法
Bert主要通过两个步骤:pre-training和fine-tuning。在预训练中,模型在没有标签的数据集上进行不同的预训练任务。fine-tuning时,使用预训练的参数来进行初始化,并利用下游任务中有标签的数据进行微调。
模型结构
Bert是一个多层双向的Transformer编码器,本文提出了两种模型大小base版和large版,
base版: L=12, H=768, A=12, Total Parameters=110M
large版: L=24, H=1024,A=16, Total Parameters=340M
其中base版与GPT大小相似,但Bert使用的时双向自注意力,GPT每个token只能关注到自己前面的token。
BERT的整体预训练和微调结构如下图所示,
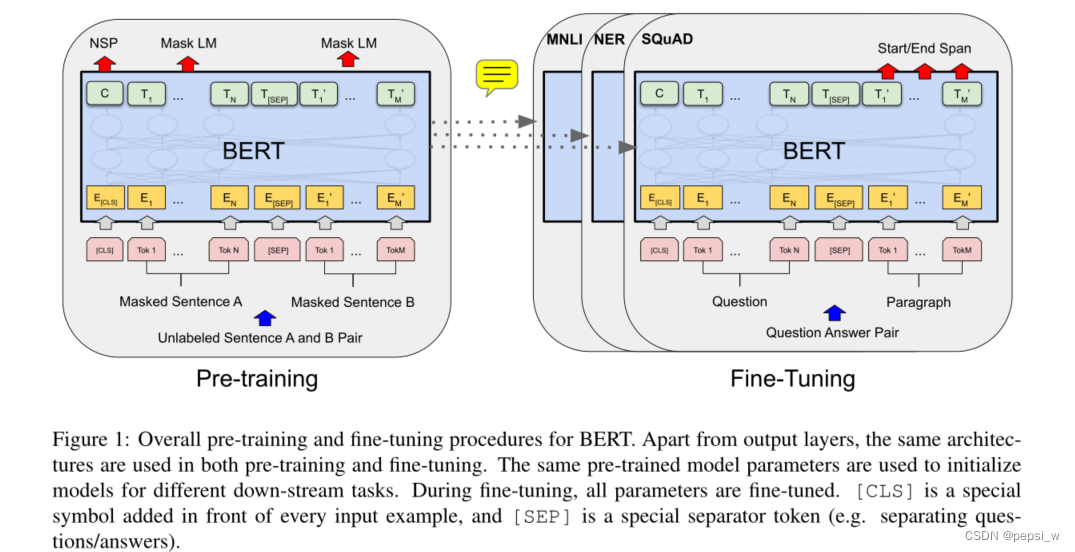
除了输出层外,在预训练和微调中使用了相同的架构。相同的预训练模型参数被用来初始化不同下游任务的模型。在微调过程中,所有的参数都要进行微调。[CLS]是添加在每个输入例子前面的特殊符号,[SEP]是一个特殊的分隔符(例如分隔问题/答案)。
输入输出表示
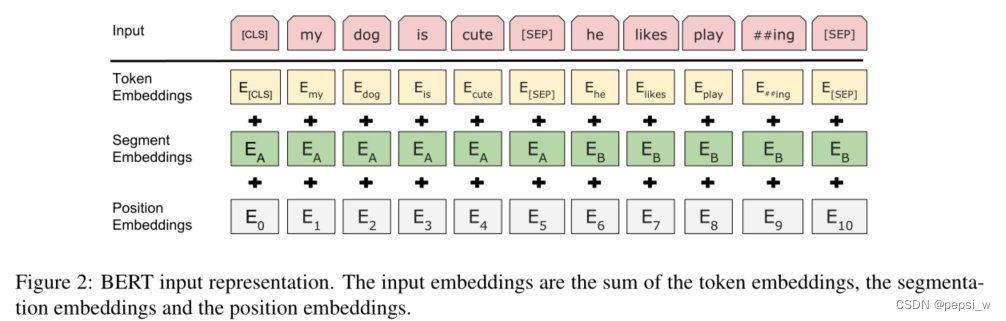
为了使Bert能够适应于各种下游任务,输入的表征要能够用一个token序列来明确的表示一个句子或一对句子。使用WordPiece词嵌入,每个序列中的第一个token是特殊分类token(cls),该token对应的最终隐藏状态被用来作为分类任务的序列表示。一对句子也是使用一个序列来表示,使用两种方法来对不同句子进行区分,第一种是使用SEP这个特殊的token来进行区分,第二种是在每个token中加入一个可学习的向量,用来表示该token是属于句子A还是句子B。
预训练-Masked LM
一般来说,双向模型比一个从左到右或从右到左的单向模型好很多,因为这样能够使每个单词都能间接的看到自己。为了训练一个深度双向表征,将输入随机的make掉一部分,然后对该部分进行预测。这个过程称为“masked LM”。在本文的实验中,以15%的概率随机的对每个序列中所有的WordPiece token进行mask。由于在微调时,不会有mask这个token,为了缓和这种误差,我们不对所有需要mask的位置都使用真实的mask token,10%的概率不进行改变,10%的概率使用随机的token进行替换,80%的概率使用mask token。
预训练-Next Sentence Prediction (NSP)
为了使模型能够理解两个句子之间的关系,作者对一个二进制的下一句预测任务进行预训练。A和B两个句子,有50%的可能,B是A的下一句,有50%的可能,B是从其他对句中选择的。通过后面的实验,我们证明该预训练对于QA和NLI是非常有效的。另外,和之前只将句子嵌入转移到下游任务中不同,Bert将所有的参数用来对终端模型进行初始化。
Fine-tuning
通过调换适当的输入和输出,Bert能够在不同的下游任务上直接进行微调。对于文本对的应用,通常是在应用双向注意力前单独地编码。Bert通过自注意力机制来统一这两个阶段,因为用自我注意对串联的文本进行编码,有效地包括了两个句子之间的双向交叉注意。
实验
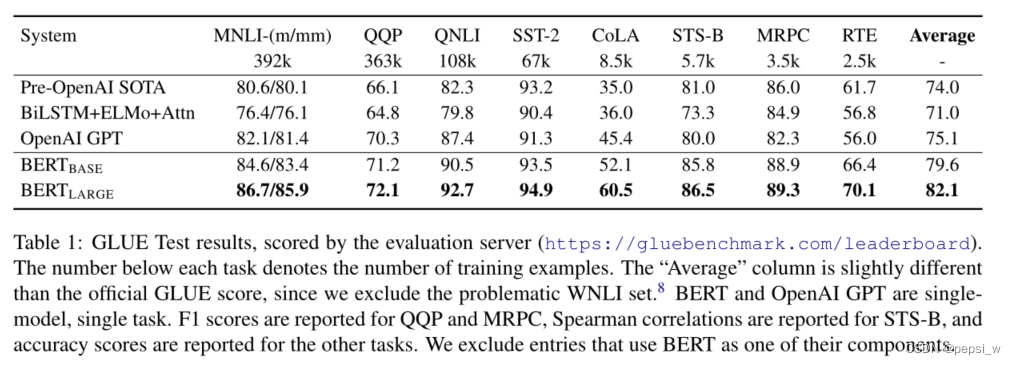
在通用语言理解评估(GLUE)上进行实验结果如下所示,无论是base还是large版本,在所有任务上均比其他模型表现好,提升幅度达到了4.6%和7.0%。并且large版本比base版本表现更好,特别是在训练数据较少的情况下。
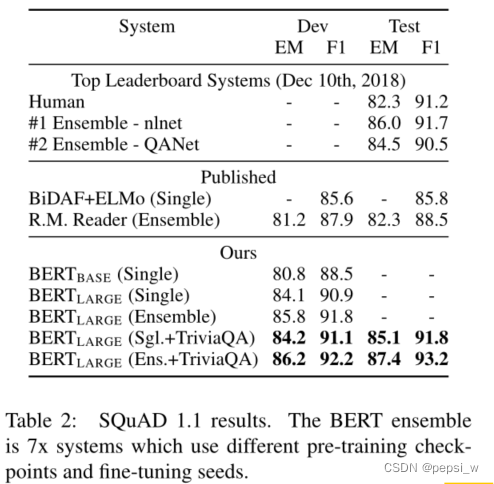
在SQuAD1.1上与其他模型进行对比,结果如下:
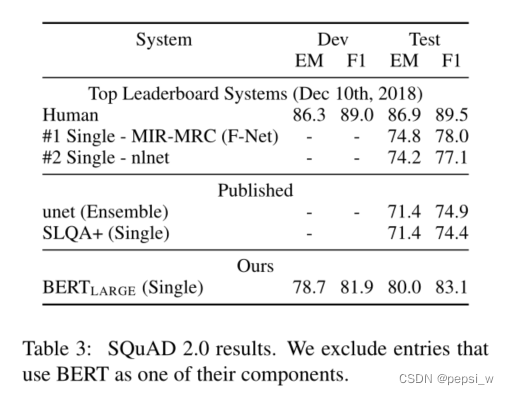
在SQuAD2.0上进行实验结果如下,Bert模型在F1上至少获得了5.1%的提升。
在SWAG数据集上进行实验,结果如下所示:(在对SWAG数据集进行微调时,在句子A和四个选项中构建了四个输入序列,每个序列都包含给定的句子A和一个可能的续篇句子B)。可以看出Bert模型比其他模型效果好很多。比GPT提升了8.3%。

消融实验
证明预训练两个任务的有效性,1)只在MLS任务上进行训练。2)和GPT类似,使用一个从左到右LTR模型(在微调时也使用只向左的约束),并且不在NSP任务上进行训练。对比实验结果如下表所示:
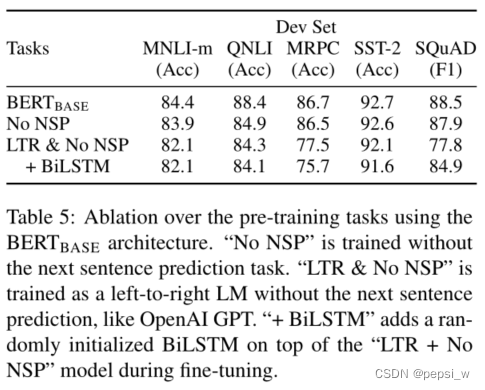
可以看出缺少了NSP任务,在QNLI上性能下降得比较大,对于双向表示的影响,总体来说,使用单向表示会导致性能下降,在MRPC和SQuAD上下降更明显。很明显,在token级别的预测任务上,LTR由于缺少token右边的信息,效果不如双向表征好,在加入BiLSTM后,虽然结果有一定的提高但还是与Bert有差距。并且BiLSTM会影响GLUE任务的效果。
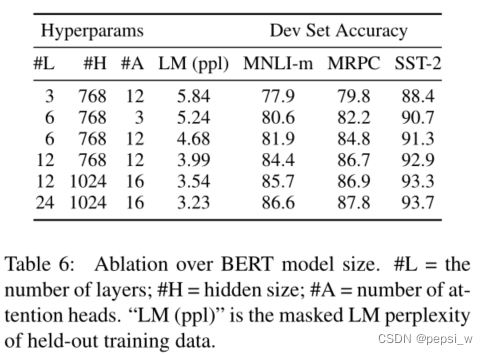
不同尺寸的模型,在同样的数据集、超参数和训练方式下的结果如下表所示,作者认为只要模型经过充分的预训练,扩展到极端的模型规模也会导致在非常小的规模任务上的巨大改进。
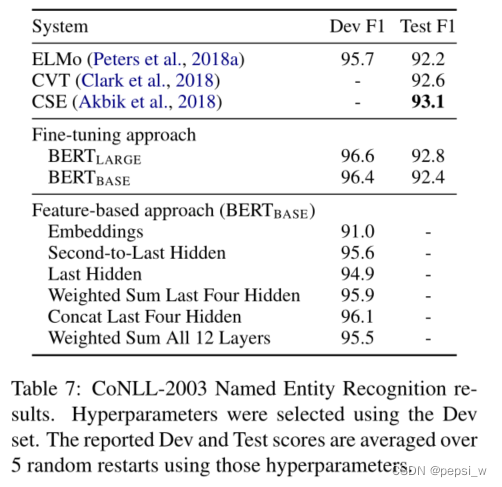
对微调和基于特征的Bert进行比较,实验结果如下,可以看出Bert对于这两种方法都是有效的。
结论
语言模型的迁移学习带来的提高表明,丰富的无监督预训练是许多语言理解系统的一个组成部分。本文将这些发现进一步推广到深度双向结构,使得同一预训练模型能够成功地处理多个NLP任务。
感谢博主:Da大象的博客_CSDN博客
文章出处登录后可见!