研究背景:传统的机器学习(主要是监督学习)遵循封闭世界学习的假设(将当前未知的事物都设为假的假设),对于他们每个测试类都有一个训练类可用。然而,这样的模型无法识别训练期间看不见的类(即看不见的类),开放世界机器学习(OWML)则处理看不见的类。
研究内容:first 概述OWML对现实世界的重要性;next 探索和讨论OWML的不同维度。本文对OWML的各种技术进行了系统评价;介绍了OWML的研究差距、挑战和未来方向。
研究意义:本文将帮助研究人员了解 OWML 的全面发展以及将研究扩展到合适领域的可能性。它还将有助于选择适用的方法和数据集以进一步探索这一点。
知识背景补充
开集识别简单定义是,一个在训练集上训练好的模型,当利用一个测试集(该测试集中包含训练集中没有的类别)进行测试时,如果输入已知类别数据,输出具体的类别,如果输入的是未知类别的数据,则进行合适的处理。
远离已知数据的空间(包括KKCs(具有明确标签的正训练样本)和KUCs(被标记为负样本,不必要被划分为一个具体的类别))通常被认为是开放空间 ,因此将该空间中的任何样本任意标注为KKC必然会带来风险,这被称为开放空间风险(open space risk)
此文结构
• Section 1 Introduction
• Section 2 介绍 OWML背景信息
• Section 3 解释本文采用的评审方法和 OWML的分类
• Section 4 介绍计算机视觉和图像处理 (CV-IP) 中 OWML的相关工作
• Section 5 介绍自然语言处理 (NLP) 中 OWML的相关工作
• Section 6 回顾了一些研究人员在 OWML 中使用的标准基准数据集
• Section 7 讨论OWML中使用的一些基线算法
• Section 8 讨论OWML的相关领域。解释 OWML 中的一些研究挑战和未来方向(第 9 节和第 10 节)
• Section 10 总结全文
1. Introduction
将示例识别为看不见或对其进行分类的能力称为开放世界学习。
然而,在现实世界的场景中,交互式和自动化应用程序在动态环境中工作,并且来自新类的数据会定期到达。在这种情况下,遵循封闭世界假设的模型无法解决这种情况。
OWML不限于特定的机器学习,可以在执行预期工作的同时学习以前没有学习过的新事物。换句话,我们可以说开放世界的机器学习可以让机器像普通人一样学习。
研究内容:首先,概述了OWML对现实世界的重要性。还介绍了计算机视觉和自然语言处理中使用的众多OWML方法的分类。此外,对现有作品进行了表格总结,强调了对优缺点的讨论。此外,讨论了OWML中用于计算机视觉和自然语言处理的一些基准算法。总结讨论有助于在给定的学习环境中为特定问题选择适当的方法。
此文的主要贡献:• 提出了一种基于任务的分类法,可以区分开放世界机器学习 (OWML) 的关键特征及其关系。 • 从效率和其他参数方面分析了几种技术及其特点。 • 讨论了 OWML 中用于计算机视觉和图像处理以及自然语言处理的各种数据集及其特征,以彻底了解结果。 • 简要介绍了各种研究空白和挑战,有助于将工作扩展到 OWML。 • 介绍了OWML 的一些相关领域,以通过不同的技术确定开放世界问题。
2. Background and Formal Definition
什么是open:在开放世界学习中,分类是开放的,或者模型可以增量学习。它可以了解新类并更新现有模型(无需重新训练)。开放世界机器学习也称为累积学习和开放世界识别 。(增量学习是指一个学习系统能不断地从新样本中学习新的知识,并能保存大部分以前已经学习到的知识。增量学习非常类似于人类自身的学习模式。因为人在成长过程中,每天学习和接收新的事物,学习是逐步进行的,而且,对已经学习到的知识,人类一般是不会遗忘的。)
开放世界机器学习使用seen数据进行训练,使用seen, seen-unseen, and unseen的数据进行测试,是唯一对不可见实例具有拒绝能力的方法。
开放世界机器学习使用可见数据进行训练,并对可见数据进行分类并拒绝不可见数据。
分类器的目标是将每个测试示例 𝑥 分类到 𝑚 个见过的类别之一或将其识别为未见过的类别。
开放世界机器学习中的学习过程可以定义为以下三个步骤:
• 步骤1:𝑀𝑡(分类器,基于具有类标签𝑆𝑡 = (𝑠1, 𝑠2, …, 𝑠𝑡) 的数据的所有先前类别𝑡) 有足够的能力对看到的类 𝑠𝑖 ∈ 𝑆𝑡 进行分类,或者将它们作为看不见的类拒绝并将它们放入拒绝集 𝑅𝑒 。 𝑅𝑒 可能有多个新类或未知类的实例。
• 步骤2:现在,系统可以识别 𝑅𝑒 中的隐藏类 𝑐,并根据这些数据准备训练集找到未知的类。
• 步骤3 :模型将从更新的训练数据集(以前的数据+ 新识别的数据集)中学习。模型𝑀𝑡更新为新模型𝑀𝑡+𝑐。
3. Review Methodology
这部分前面主要讲对owml领域l现有作品的评审方法
后面讲OWML的分类(如图)
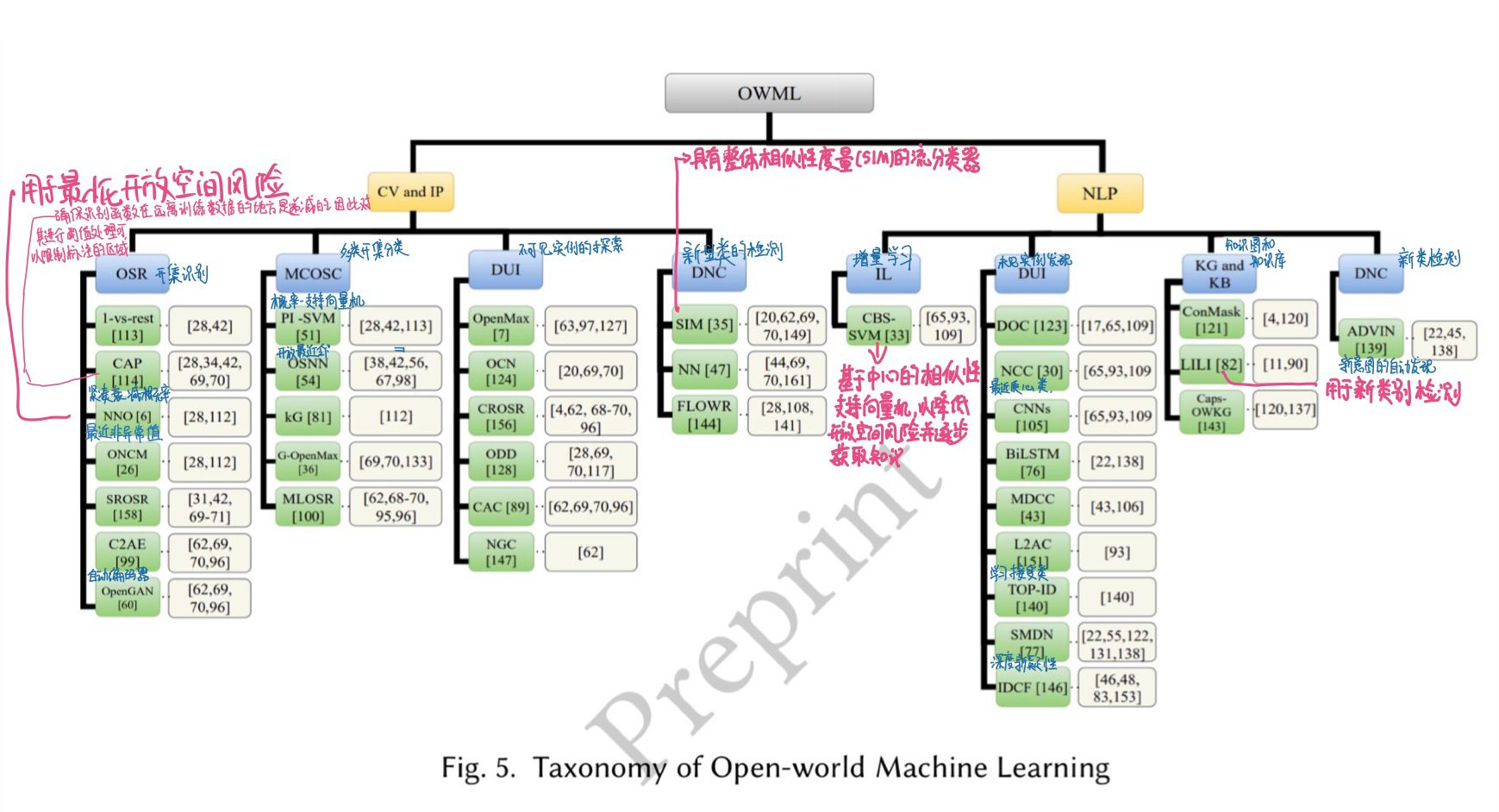
4. Open-world Machine Learning in Computer Vision and Image Processing
4.1开集识别
开放性形式化: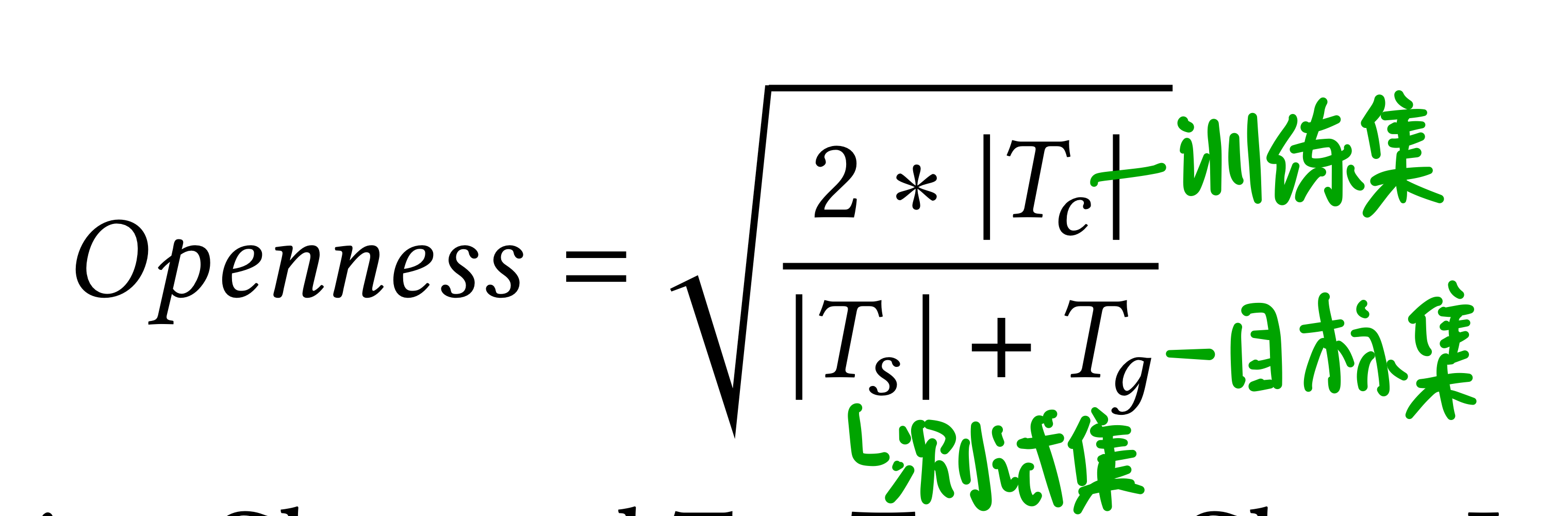 产生的开放性百分比在0-100之间。其中 0=完全封闭类,100表示最大开放性。
产生的开放性百分比在0-100之间。其中 0=完全封闭类,100表示最大开放性。
(1) 1-vs-Set
1-vs-Set 算法通过处理两个平面优化来处理未知类的危害,可能会产生线性分类器。它雕刻一个决策空间的边缘距离的1-class或binary svm的线性核。
[114]提出了一种基于 Weibull 校准 SVM (W-SVM) 的新模型紧凑减弱概率 (CAP);当点从已知数据向开放空间移动时,它会降低成员类的概率值。CAP可以降低已知数据的开放空间风险。
[113]确定通过优化两个平面,1-vs-set机器可以管理风险并产生线性分类器。
类的三个基本类别,已知类(带有抽象标记的类,即正例)、已知未知类(负例)和未知类(未见类)。该算法是专门为未知类设计的,该算法将开放空间风险从无限推导出为有限。
1-vs-set 机器通过测试将类标签分配给示例。它使用了多类的概率决策分数。它根据最高概率或超出阈值的概率通过多个分类器对示例进行分类。低于阈值的示例被视为未知而被拒绝。这项工作通过引入一种新算法 W-SVM,将紧凑衰减概率(CAP)形式化以解决开放集再生问题,该算法集成了紧凑的减弱概率模型和概率估计理论
(2)最近非异常值(NNO)
NNO是两个开放空间风险和阈值空间的开放空间风险的模型组合。
NNO可以识别未知对象并将这些看不见的类作为新类包含在内。因此,NNO是一种开放世界算法。
(3)C2AE
该方法使用类条件自动编码器通过新颖的训练和测试方法来识别开放集。所提出的模型分为两个部分,封闭集分类和开放集识别。编码器学习了第一个用于近距离分类的任务,而解码器学习了下一个用于开放类识别的任务。训练是使用闭集模型完成的。闭集模型由已知类组成。它训练编码器和分类器,并按常规计算分类损失;在训练近集编码器后,训练开集识别模块,该模块由具有权重的自动编码器网络和解码器组成,用于根据标签条件向量重建图像。
(4)OpenGAN
通过开放数据生成来识别开放集。 OpenGAN 由 GAN 鉴别器组成,用于对测试示例进行分类。它是针对开集和闭集数据训练的二元分类器。有许多其他技术可用于近距离分类,但每种技术都有局限性,但 OpenGAN 通过将它们与各种技术见解相结合来克服它们。第一步,OpenGAN 在现有研究中已经使用的一些实际异常数据上选择了 GAN Discriminator。第二步合成“假”数据并将其添加到完整的开放训练示例中。
4.2 多类开集分类
(1)开集最近邻(OSNN)
OSNN使用相似度而不是相似度分数,并应用阈值来查找类之间的相似性
(2)Generative OpenMax (G-openMax)
它计算的是未见类而不是已见类的决策分数。它是 OpenMax 的扩展,由 GANs网络组成。所提出的方法对可见和不可见的类都使用了可视化;它还使用了对 GAN 的概率估计,以及以前见过的类传播来产生合理且适应领域的合成看不见的样本。
(3)基于多任务学习的开放集识别(MLOSR)
它基于用于开放集视觉识别中的多任务处理的神经网络。所提出的方法是分类网络、解码器网络和特征提取器网络的组合。它利用解码器网络拒绝开放集,解码器网络重构错误。它还使用 EVT [25] 从看到的类中重建模型尾部误差。 EVT 提高了模型的整体性能。特征提取器网络接受输入并生成潜在的。分类器使用这个潜在解码器来预测输入图像的类别标签和重建。整个网络已经针对输入图像的重建和分类进行了训练。 EVT 对误差分布的重建轨迹进行了建模。用于开放集识别测试的 EVT 和分类分数的重建错误概率。
4.3 Discovery of Unseen Instances (DUI)
(1)OpenMax
它可以评估输入是看不见的类的可能性。 OpenMax 拒绝不相关的图像,降低错误率,并管理开放空间风险。 OpenMax 通过测量针对有限上层类的模型向量与输入的激活向量之间的距离来估计类。 OpenMax 提供了未知类的可能性。这里 OpenMax 有一个 SoftMax 的扩展版本,其中包括未知类的概率。该方法在深度网络中使用元识别并找到分数来估计测试对象与已知类别的距离。为了估计分数,激活层已用于深度网络。元识别和 OpenMax 可以区分可见和不可见的类别,并避免将愚蠢的图像分类到已知类别中。
(2)开放集识别的分类重建学习(CROSR)
用于稳健的未知类,而不会影响已知类的分类准确性。CROSR 训练的网络用于输入数据的分类和恢复。在学习区分看不见的和看得见的类别时,这种技术有助于改进隐含的解释。尽管牺牲了可见类分类的效率,但为了提供持久的不可见识别,CROSR 方法使用隐式结构进行重建。CROSR 基于 OpenMax 公式。它重构输入数据以检测 unseen 类。他们在所见类中使用排他性学习算法来构建他们的分类器。 CROSR 是一种基于 DHRNets 的开放集分类系统,将可见分类与不可见检测相结合。
(3)NGC
一种新颖的基于图的噪声标签学习框架,在测试时,它通过利用模型预测的置信度和数据的几何特征来纠正分布中的噪声标签并过滤分布外的示例。 NGC 无需任何额外训练即可识别和丢弃分布外的样本。
4.4 Detection of Novel Classes (DNC)
(1)SIM
框架SIM是一种半监督流分类器,可在高维数据流上执行分类并检测新类。它使用潜在特征空间进行分类,并且开放世界的分类器实现了度量学习,流分类并检测了看不见的数据中的新类。对图像和文本数据进行了性能评估。
5 Open-world Machine Learning in Natural Language Processing (NLP)
5.1 Incremental Learning (IL)
该系统可以继续从新颖的输入中学习新任务,同时保留以前获得的知识。每当新任务出现并发生变化时,训练方法就会出现。该模型根据新颖的任务和旧知识来保留所学到的内容。增量学习与传统机器学习最明显的区别是它不会丢失以前的知识。
(1)基于中心的相似性空间学习SVM (cbs-svm)
在开放世界中对类进行分类使用相同的基于阈值概率的看不见的类拒绝方法。系统使用相似性方法来学习看不见的/新的类。它搜索了相似的类集,并学会了分离新类。要学习一个单独的新类,它会构建一个二进制分类器。检测到或指定新类后,更新现有的分类器,以避免对下一个看不见的类造成混淆。
5.2 Discovery of Unseen Instances (DUI)
(1)Deep Open Classification (DOC)
识别可能不属于任何训练类的新类或任务。
DOC将使用sigmoid的1-vs-rest最终层来代替OpenMax [115] 构建多类分类器,以降低开放空间风险。DOC使用具有高斯拟合的sigmoid函数来减轻决策边界并降低开放空间风险。DOC使用卷积神经网络 (CNN) 与1-vs-rest sigmoid层和高斯拟合进行分类。
(2)Nearest Centroid Class (NCC) (最近的质心类)
NCC来检测开放世界机器学习中看不见的类。这是一种增量学习方法,可以采用质心类的最接近邻居的集合。类有集群,在集群中,每个类都有最小点。这些是与集群相关联的成员资格点。每个类必须具有加入特定集群的最低成员资格点。类也表示数据点,类的中心是数据点。具有最近的类中心数据点的新类允许加入集群。
(3)双向长短期记忆 (BiLSTM)
双向长短期记忆 (BiLSTM) 网络使用裕度损失。LSTM网络将类内的方差最小化,并将类间意图的方差最大化。已使用用于创建向量和区分未知意图的手套词嵌入局部异常值因子loof [12]。损失层从深度判别特征中检测已知意图,而LOF检测未知意图。
(4)Learning to Accept Classes
这是基于元学习的。L2AC仅维护动态已知类,这些类允许添加新颖类而无需重新训练模型。在L2AC中,每个已知类都充当训练示例的一小部分。测试仅使用元分类器 (使用已知和新颖的类)。L2AC模型有两个主要机制,ranker和元分类器。ranker从与测试示例可比或最接近的已知类中检索示例。元分类器是L2AC的核心机制,它是一种二进制分类器,可根据概率分数区分已知的类或以其他方式拒绝。
(5)Towards Open Intent Discovery (TOP-ID)
它是一种两阶段机制,用于预测语句的意图,然后在输入语句中标记意图。该模型由具有对抗训练方法的BiLSTM [116] 和条件随机场 (CRF) 组成,并且通过域增加了鲁棒性和性能。TOP-ID可以用自然语言自动检测用户的意图。它不需要任何先验知识来进行意图检测。
(6)Softmax and Deep Novelty (SMDN)
用于检测未知意图。SMDN分类器可以在任何模型上运行,而无需更改现有模型的体系结构。该模型使用SoftMax,该SoftMax通过计算校准的置信度得分进行分类,并通过计算决策边界来检测未知意图。LOF [12] 用作输出层,以检测未知意图。
(7)Inductive Collaborative Filtering (IDCF) (归纳式协同过滤)
它为用户输入提供归纳学习,同时还确保足够的表达能力和适应性。IDCF使用两个表示模型来提取特定于用户的嵌入,即meta latents。它分解了一组基本用户的数据矩阵,然后采用了一种注意技术,该技术可以在基本用户中学习隐藏的图表,并根据用户过去的排名习惯查询用户。对于查询用户,通过所揭示的关联图来启用用户特定表示的归纳计算。在轻微的情况下,IDCF标准版本可以将恢复损失降低到与香草矩阵分解技术相似的水平。根据经验,IDCF为换能协作过滤 (CF) 模型提供了实际的接近均方根误差 (RMSE)。
5.3 Knowledge-graph & Knowledge-base (KG & KB)
知识图谱:是结构化的语义知识库,用于以符号形式描述物理世界中的概念及其相互关系,其基本组成单位是“实体—关系—实体”三元组,以及实体及其相关属性—值对,实体间通过关系相互联结,构成网状的知识结构。
(1)ConMask(内容掩蔽)
它是开放世界中知识图谱完成 (KGC) 的模型。该模型通过其名称,文本字段中给出的描述来学习任何实体的嵌入,并将未知类别的实体标识到知识图谱中。ConMask使用依赖于内容掩蔽的关系来提取相关块并减少嘈杂的文本描述。提取相关块后,将具有完全连接的CNN的模型训练为与知识图中的实体一致的块。
5.4 Detection of Novel Classes (DNC)
(1)Automatic Discovery of Novel Intents and domains (ADVIN)
从未标记的数据中发现新颖的文本域和意图。ADVIN分为三个阶段: 从大量未标记的数据中发现新颖的领域和意图,知识转移以及将相关意图链接到相应的新颖领域。为了识别新颖意图的实例,使用了基于BERT的多类分类器。DOC 用于区分看不见的意图。在发现新发现意图的类别的第二阶段,它使用层次聚类方法来传递知识。最后,通过将新颖的意图链接到新颖的领域,ADVIN使用seen类的集群作为理想的集群和知识转移模块来表示集群。
6 Datasets Used in Open-world Machine Learning
介绍了各种数据集。Caltech-256,MNIST,Fashion-MNIST,ImageNet,Tiny-ImageNet,CIFAR-10,SVHN,20-NewsGroup,Amazon Product Reviews,50-Class Reviews,WordNet,SwDa。
7 Baseline Algorithms Used in Open-world Machine Learning
7.1 Center-Based Similarity (CBS)
CBS是一种分类方法,将数据点分为可见类和看不见类。它适用于基于中心的相似性空间学习技术。CBS递增地学习新闻类,并使用1-vs-rest层对看不见的类进行分类 [32]。1-vs-rest是开放世界机器学习中发现看不见的类的关键概念之一。
7.2 Incremental Class Learning
人类学习过程的思想鼓励了增量学习。它像人类一样通过经验学习大部分知识。它按时间学习新知识,而不是寻找现有知识。
7.3 Nearest Class Mean (NCM) (最近的类均值)
最近类均值 (NCM) 一般用于大规模图像分类。在大多数研究中,用于大规模图像分类的两种方法是k最近邻 (K-NN) 和最近类均值 (NCM),最近类均值 (NCM) 比K-NN更灵活。NCM通过其分量的平均特征向量来表征类。
7.4 1-vs-rest
1-vs-rest是一种提供拒绝能力的方法。
9 挑战
由于即将到来的事件具有不可预测的性质,在动态环境中学习仍然是一项具有挑战性的任务。我们如何集成分类器以获取未知类的子知识并降低开放空间风险。开放世界机器学习的重大挑战是:
• Incremental Volume of Data
• Identifying a Novel Classes:
• Updating a Knowledge-Base
• Open-space Risk
• Open Framework:
• Efficient Discovery of Novel Classes
• Retention of Obtained Knowledge
10 Future Directions
Open-world Models.现有的开放世界机器学习模型正在以混合方式工作,并部分解决了该问题。缺乏可以端到端工作的可用模型。开放世界机器学习的端到端模型可以加强对已知已知类和已知未知类这两个类别的分类。据我们所知,没有可用于未知-未知类识别的有前途的模型,这是开放世界机器学习中具有挑战性的类别之一。未知-未知类分类的现有方法值得进一步扩展。
Rejection of Unknown Classes.增加未知类的拒绝能力的进一步工作可以使系统更可靠,因为现实世界的应用程序在动态环境中工作时面临许多未知对象。现有模型需要更多的改进,以高精度拒绝看不见的类。
Identification of Unseen Classes.大多数现有模型要么检测已知,要么拒绝未知,但是在拒绝类别为未知之后,没有有希望的机制可以进一步识别被拒绝数据中的类别。需要能够识别拒绝数据中隐藏子句数量的模型
11 Conclusion
本文综述了近十年来开放世界机器学习领域的研究成果。还讨论了开放词机器学习的重要性和许多实际应用。文献中提出了许多算法、模型和框架,以解决与开放世界设置相关的众多目标。该领域相对较新;因此,信息来源不足。本文的回顾将有助于理解开放世界场景、工作方式和相关挑战。我们在CV-IP和NLP中提供了基于任务的OWML分类。此外,我们还讨论了各种技术,并在OWML中使用了数据集。还分析了许多技术的局限性,以促进这些方法的有希望的未来扩展。
文章出处登录后可见!