涵盖所有考点,复习绝对高效,点赞+留邮箱获取pdf版本
山东大学编译原理复习提纲
一、简答与计算
1.1 必考
1. 编译过程
- 画图表示编译过程的各阶段,并简要说明各阶段的功能:
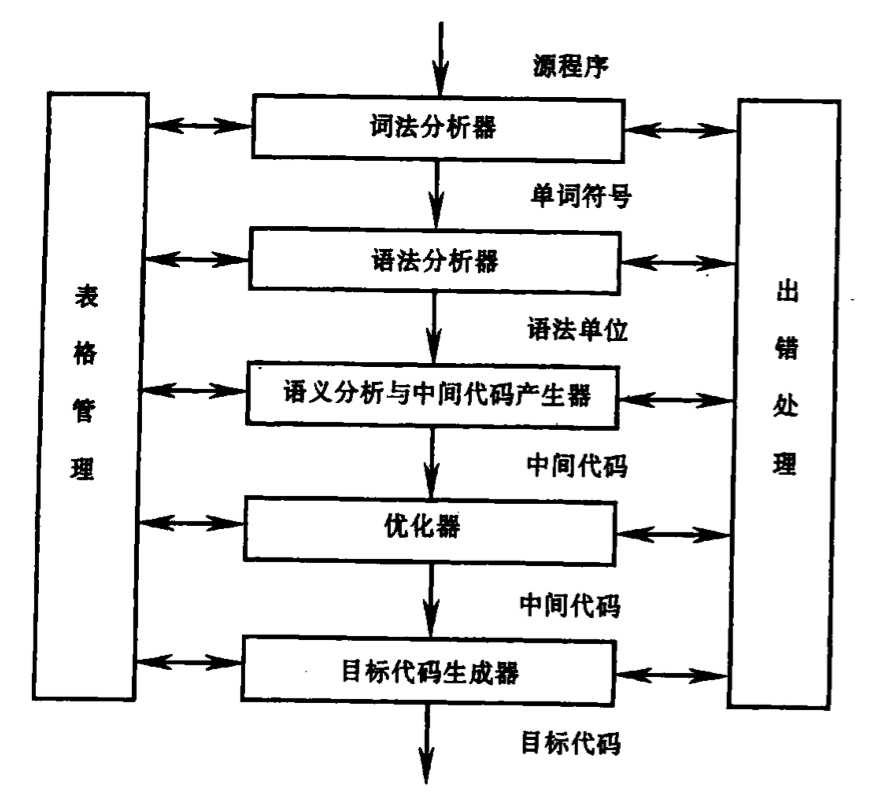
- 词法分析器:输入源程序,进行词法分析,输出单词符号;
- 语法分析器:根据文法构建分析表,对单词符号进行语法分析,检查程序是否符合语法规则;
- 语义分析与中间代码生成器:按照文法翻译规则对语法分析器归约出的语法单位进行语义分析,并把它们翻译成一定形式的中间代码;
- 优化器:对中间代码进行优化处理;
- 目标代码生成器:把中间代码翻译成目标代码。
2. 消除左递归


如果从开始符号依次推导出 A1 A2 A3 ,则按其逆序排序时得到的产生式最少。
3. 消除回溯

通过反复提取左公因子可以消除回溯。
4. 提左公因子

5. 后缀表达式
中缀转后缀算法:
初始化符号栈,顺序读取中缀表达式,遇到 ( 则将其入栈,遇到 ) 则依次弹出栈顶元素到结果串中,直到遇到 ( ,将其出栈但不附加到结果串;
遇到 +-,弹出栈顶的所有操作符,附加到结果串中,然后自己进栈;
遇到 */,先让栈顶的 */ 出栈,附加到结果串中,然后自己进栈;
遇到数字,直接附加到结果串中;
最后若符号栈非空,将符号栈栈顶元素依次附加到结果串中。
// 中缀转后缀
vector<string> interToPost(vector<string> vec)
{
vector<string> res;
stack<string> op_stack;
for (int i = 0; i < vec.size(); i++) {
if (vec[i] == "(")
op_stack.push(vec[i]);
else if (vec[i] == ")") {
while (op_stack.top() != "(") {
res.push_back(op_stack.top());
op_stack.pop();
}
// 左括号出栈
op_stack.pop();
}
// 遇到+-,先让栈中的+-*/出栈
else if (vec[i] == "+" || vec[i] == "-") {
while (!op_stack.empty() && op_stack.top() != "(") {
res.push_back(op_stack.top());
op_stack.pop();
}
op_stack.push(vec[i]);
}
// 遇到*/,先让栈中的*/出栈
else if (vec[i] == "*" || vec[i] == "/") {
while (!op_stack.empty() && (op_stack.top() == "*" || op_stack.top() == "/")) {
res.push_back(op_stack.top());
op_stack.pop();
}
op_stack.push(vec[i]);
}
else
res.push_back(vec[i]);
}
while (!op_stack.empty()) {
res.push_back(op_stack.top());
op_stack.pop();
}
return res;
}
计算后缀表达式:
初始化数据栈,顺序读取后缀表达式,遇到操作符 op 则将栈次顶元素 op 栈顶元素,弹出操作数并压入运算结果;
遇到数据,则直接压入栈顶;
最终栈顶元素就是结果。
// 计算后缀表达式
double solvePostPrefix(vector<string> post_prefix) {
stack<double> dataStack;
double num1, num2, result;
for (auto x : post_prefix) {
if (x == "+" || x == "-" || x == "*" || x == "/") {
num1 = dataStack.top();
dataStack.pop();
num2 = dataStack.top();
dataStack.pop();
if (x == "+")
result = num2 + num1;
if (x == "-")
result = num2 - num1;
if (x == "*")
result = num2 * num1;
if (x == "/")
result = num2 / num1;
dataStack.push(result);
}
else {
double num = strToDouble(x);
dataStack.push(num);
}
}
return dataStack.top();
}
1.2 选考
1. 编译、翻译和解释
- 翻译程序:把一种语言程序(源语言)转换成另一种语言程序(目标语言);
- 编译程序:源语言为高级语言,目标语言为低级语言的翻译程序;
- 解释程序:以源语言作为输入,但不产生目标程序,而是边翻译边执行源程序本身。
2. 中间代码
是一种含义明确、便于处理的记号系统,通常独立于具体的硬件但与指令形式有某种程度的接近,或者能够比较容易的转换为机器指令,常见的形式有:
- 三元式;
- 间接三元式;
- 四元式;
- 逆波兰式;
- 树形表示。
3. 目标代码
把中间代码变换为特定机器上的低级语言代码,产生出足以发挥硬件效率的目标代码是一件非常不容易的事情。常见的形式有:
-
汇编指令代码:需要汇编才能执行;
-
绝对指令代码:可以立即执行;
-
可重定位指令代码:运行前必须借助于一个链接装配程序,把各个目标模块(包括系统提供的库模块)连接在一起,确定程序装入内存中的起始地址,使之成为一个可以运行的绝对指令代码程序。
4. 属性文法
- S-属性文法:只含有综合属性的文法;
- L-属性文法:含有综合属性或继承属性,且改继承属性仅依赖于:
- 产生式体该符号左边的那些属性;
- 产生式头的继承属性;
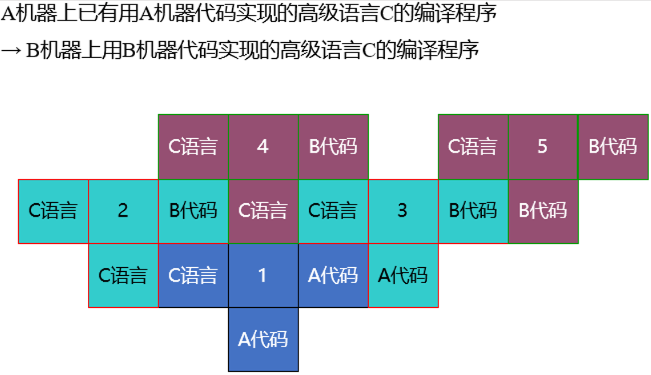
5. T 型图
6. 高级语言的分类
-
强制式语言:面向底层和语句,每个语句的执行引起若干存储单元中值的改变;
-
应用式语言:更注重程序所表示的功能,每条语句都封装了复杂的功能;
-
基于规则的语言:检查一定的条件,当它满足值,则执行适当的动作;
-
面向对象的语言:主要特征是封装性、继承性、多态性。
7. 闭包
用 Σ* 表示 Σ 上所有符号串的全体,空字 ε 也在其中,称为 Σ 的闭包。
- Σ = {a, b},则 Σ* = {ε, a, b, aa, ab, bb, aaa, …}。
8. 上下文无关文法

9. 构造文法

文章出处登录后可见!