



原文标题 :How to Find the Best Theoretical Distribution for Your Data.
如何为您的数据找到最佳理论分布。
了解底层数据分布是数据建模的重要步骤,并且具有许多应用程序,例如异常检测、合成数据创建和数据压缩。

了解数据的基本(概率)分布有很多建模优势。确定基础分布的最简单方法是使用直方图目视检查随机变量。使用候选分布,可以创建各种图,例如概率分布函数图 (PDF/CDF) 和 QQ 图。但是,要确定确切的分布参数(例如位置、比例),必须使用定量方法。在此博客中,我将描述为什么确定数据集的潜在概率分布很重要。如何使用目测和定量方式确定最佳拟合,以及参数分布和非参数分布之间的区别。分析是使用 distfit 库执行的,并且随附一个笔记本以便于访问和试验。
分布拟合和概率密度函数的重要性。
概率密度函数是统计学中的一个基本概念。简而言之,对于给定的随机变量 X,我们的目标是指定函数 f 以自然描述 X 的分布。另请参阅底部的术语部分以了解更多关于概率密度函数的信息。尽管有很多很好的材料描述了这些概念 [1],但理解为什么了解数据集的底层数据分布很重要仍然具有挑战性。让我尝试用一个小类比来解释重要性。假设您需要从地点 A 前往地点 B,您更喜欢哪种类型的汽车?答案很简单。您可能会从探索地形开始。有了这些信息,您就可以选择最适合的汽车(跑车、四轮驱动车等)。从逻辑上讲,跑车更适合平坦平坦的地形,而四轮驱动更适合崎岖不平的丘陵地形。换句话说,如果不对地形进行探索性分析,就很难选择最好的汽车。然而,这样的探索步骤在数据建模中很容易被遗忘或忽略。
在做出建模决策之前,您需要了解底层数据分布。
当涉及到数据时,探索数据的基本特征也很重要,例如偏度、峰度、离群值、分布形状、单变量、双峰等。根据这些特征,更容易决定哪种模型最适合使用,因为大多数模型都有数据的先决条件。例如,一种众所周知且流行的技术是主成分分析 (PCA)。此方法计算协方差矩阵并要求数据为多变量正态分布以使 PCA 有效。此外,还已知 PCA 对异常值敏感。因此,在执行 PCA 步骤之前,您需要知道您的数据是否需要(对数)归一化或是否需要删除异常值。有关 PCA 的更多详细信息,请参见此处 [2]。[0]
直方图可以建立直觉。
直方图是数据分析中众所周知的图表,它是数据集分布的图形表示。直方图总结了落在 bin 内的观察值的数量。使用 matplotlib hist() 等库,可以直接对数据进行目视检查。改变 bin 数量的范围将有助于通过直方图的形状来识别密度是否看起来像一个常见的概率分布。检查还将提示数据是对称的还是偏斜的,以及它是否具有多个峰值或异常值。在大多数情况下,您会观察到如图 1 所示的分布形状。
- 正态分布的钟形。
- 指数或帕累托分布的下降或上升形状。
- 均匀分布的平面形状。
- 不符合任何理论分布的复杂形状(例如,多个峰)。

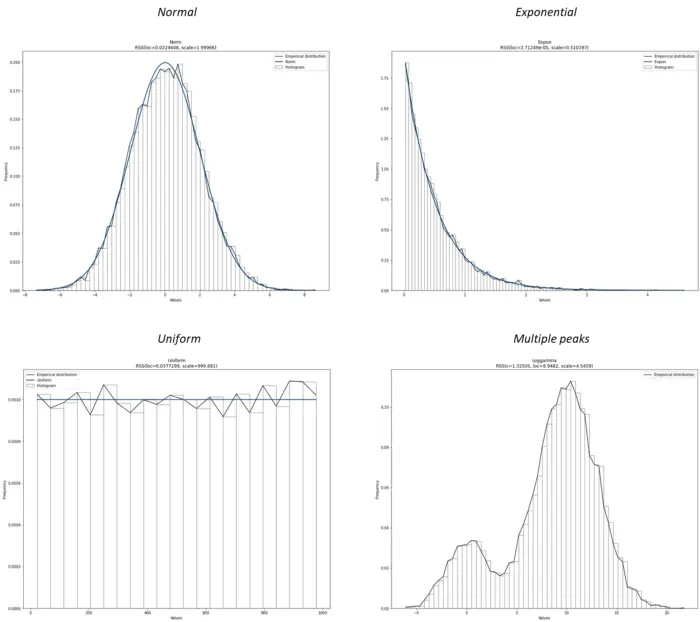
如果您发现具有多个峰(双峰或多峰)的分布,则峰不应随着不同数量的箱而消失。双峰分布通常暗示混合种群。此外,如果您观察到给定值或小范围值的密度出现大峰值,则可能指向可能的异常值。离群值通常出现在分布的尾部并且远离密度的其余部分。
直方图是检查相对少量样本(随机变量或数据点)的好方法。然而,当样本数量增加或绘制两个以上的直方图时,视觉效果会变得很麻烦,并且与理论分布的视觉比较难以判断。相反,累积分布函数 (CDF) 图或分位数-分位数图(QQ 图)可能更具洞察力。但是这些图需要与经验数据分布最匹配(或拟合)的候选理论分布。因此,让我们在下一节中确定最佳理论分布!有关随机变量和理论分布的更多信息,另请参阅底部的术语部分。
确定理论分布的四个步骤。
可以通过四个步骤发现适合经验数据分布的 PDF:
- 从直方图中计算密度和权重。第一步是将数据展平为一个数组,并通过将观察结果分组到箱中并计算每个箱中的事件数来创建直方图。箱数的选择很重要,因为它控制着分布的粗糙度。试验不同的 bin 大小可以提供对同一数据的多个视角。在 distfit 中,bin 宽度可以手动定义或根据观察结果本身以数学方式确定。后一个选项是默认选项。
- 根据数据估计分布参数。在参数方法中,下一步是根据(选定的)理论分布估计形状、位置和尺度参数。这通常涉及诸如最大似然估计 (MLE) 之类的方法来确定最适合数据的参数值。例如,如果选择正态分布,则 MLE 方法将估计数据的均值和标准差。
- 检查拟合优度。一旦估计了参数,就可以评估理论分布的拟合度。这可以使用拟合优度检验来完成。流行的统计检验是残差平方和(RSS,也称为 SSE)、Wasserstein、Kolmogorov-Smirnov 和能量检验(也可用于 distfit)。
- 选择最佳理论分布。此时,使用拟合优度检验统计量对理论分布进行检验和评分。现在可以对分数进行排序,并可以选择具有最佳分数的理论分布。
作为最后一步,可以使用交叉验证、引导程序或保留数据集等方法验证模型。必须检查模型是否泛化良好,并检查是否满足独立性和正态性等假设。一旦理论分布得到拟合和验证,它就可以用于许多应用(继续阅读下面的部分)。
在数据科学领域工作时,分布拟合有很大的好处。它不仅是为了更好地理解、探索和准备数据,而且是为了带来快速和轻量级的解决方案。
distfit 库会为您的数据找到最合适的。
Distfit 是一个 python 包,用于随机变量的单变量分布的概率密度拟合。它可以找到参数、非参数和离散分布的最佳拟合。此外,它还提供视觉洞察力,以便使用各种图表更好地做出决策。最重要的功能总结:
使用 distfit 库,只需几行代码即可轻松找到最佳理论分布。
- 找到参数、非参数和离散分布的最佳拟合。
- 预测(新)未见样本的异常值/新颖性。
- 根据拟合分布生成合成数据。
- 图:直方图、概率密度函数图、累积密度函数图 (CDF)、帕累托图、分位数-分位数图 (QQ-plot)、概率图和汇总图。
- 保存和加载模型。
安装非常简单,可以从 PyPi 完成。
pip install distfit如何使用参数拟合确定最佳拟合?
通过参数拟合,我们根据输入数据对人口分布的参数进行假设。或者换句话说,直方图的形状应该与任何已知的理论分布相匹配。参数拟合的优点是计算效率高,结果易于解释。缺点是当样本数量较少时,它可能对异常值敏感。 distfit 库可以确定 scipy 库中使用的 89 个理论分布的最佳拟合。为了对拟合度进行评分,有四种拟合优度统计检验;残差平方和(RSS 或 SSE)、Wasserstein、Kolmogorov-Smirnov (KS) 和能量。对于每个拟合的理论分布,返回 loc、scale 和 arg 参数,例如正态分布的均值和标准差。
为您的数据集找到最佳匹配的理论分布需要拟合优度统计检验。
在下面的示例中,我们将从均值 = 2 和标准差 = 4 的正态分布生成数据。我们将使用 distfit 从数据本身估计这两个参数。如果您已经知道分布系列(例如,钟形),则可以指定分布的子集。默认值是常见分布的子集(如图 1 所示)。请注意,由于随机成分,结果可能与我在重复实验时显示的略有不同。
# Import libraries
import numpy as np
from distfit import distfit
# Create random normal data with mean=2 and std=4
X = np.random.normal(2, 4, 10000)
# Initialize using the parametric approach.
dfit = distfit(method=’parametric’, todf=True)
# Alternatively limit the search for only a few theoretical distributions.
dfit = distfit(method='parametric', todf=True, distr=['norm', 'expon'])
# Fit model on input data X.
dfit.fit_transform(X)
# Print the bet model results.
dfit.model
# 'stats': 'RSS',
# 'name': 'loggamma',
# 'params': (761.2276, -725.194369, 109.61),
# 'score': 0.0004758991728293508,
# 'loc': -725.1943699246272,
# 'scale': 109.61710960155318,
# 'arg': (761.227612981012,),
# 'CII_min_alpha': -4.542099829801259,
# 'CII_max_alpha': 8.531658573964933
# 'distr': <scipy.stats._continuous_distns.loggamma_gen>,
# 'model': <scipy.stats._distn_infrastructure.rv_continuous_frozen>,检测到的最佳拟合(即具有最低 RSS 分数)是对数伽马分布。最佳拟合的结果存储在 dfit.model 中,但我们也可以检查 dfit.summary 中描述的所有其他 PDF 的拟合(参见下面的代码部分)并创建一个绘图(图 2)。
# Print the scores of the distributions:
dfit.summary[['distr', 'score', 'loc', 'scale']]
# distr score loc scale
#0 loggamma 0.000476 -725.19437 109.61711
#1 t 0.00048 2.036554 3.970414
#2 norm 0.00048 2.036483 3.970444
#3 beta 0.000481 -72.505842 133.797587
#4 gamma 0.000498 -304.071325 0.051542
#5 lognorm 0.000507 -325.188197 327.201051
#6 genextreme 0.001368 0.508856 3.947172
#7 dweibull 0.005371 2.102396 3.386271
#8 uniform 0.079545 -12.783659 30.766669
#9 expon 0.108689 -12.783659 14.820142
#10 pareto 0.108689 -1073741836.783659 1073741824.0
# Plot the top fitted distributions.
model.plot_summary()
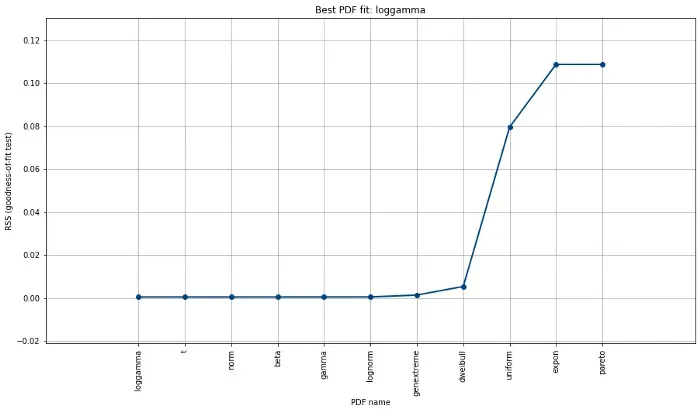
但是为什么尽管我们生成了随机正态数据,正态分布的残差平方和却没有最低?
好吧,首先,我们的输入数据集将始终是一个限制在(窄)范围内的有限列表。相反,理论(正态)分布在两个方向上都趋于无穷大。其次,所有的统计分析都是基于模型,而所有的模型都只是对现实世界的简化。或者换句话说,为了近似理论分布,我们需要使用多个统计测试,每个都有自己的(缺点)优势。最后,一些分布具有非常灵活的特性,(log)gamma 就是一个明显的例子。对于较大的 k,伽玛分布收敛于正态分布 [4]。
结果是前 7 个分布具有相似且较低的 RSS 分数,其中包括正态分布。我们可以在摘要统计中看到,正态分布的估计参数是 loc=2.036 和 scale=3.97,这与我们最初生成的随机样本总体(mean=2,std=4)非常接近。综合考虑,一个非常好的结果。
选择最佳模型不是统计问题;这是一个建模决定。
现在很高兴认识到统计测试只会帮助您朝正确的方向看,选择最佳模型不是统计问题;这是一个建模决策[5]。想一想:loggamma 分布是重右尾分布,而正态分布是对称的(两条尾巴都相似)。这在使用置信区间和预测尾部异常值时会产生巨大差异。明智地选择您的发行版,使其与应用程序相匹配。
情节指导更好的决定。
最佳做法是同时使用统计数据和视觉策划来决定最佳分布拟合是什么。使用帕累托图、PDF/CDF 和 QQ 图可能是指导这些决策的一些最佳工具。例如,图 2 说明了拟合优度测试统计数据,其中前 7 个 PDF 具有非常相似且较低的 RSS 分数。 dweibull 分布排名第 8,RSS 得分也较低。然而,通过目视检查我们会发现,尽管 RSS 分数相对较低,但它毕竟不是一个很好的选择。
让我们开始使用直方图和 PDF 绘制经验数据。请注意,这样的图也称为 Pareto 图。这些图将有助于直观地指导分布是否合适。我们可以在图 3 中看到带有置信区间的 PDF(左)和右侧的 CDF 图。置信区间自动设置为 95% CII,但可以在初始化期间使用 alpha 参数进行更改。使用绘图功能时,它会自动以条形和直线、PDF/CDF 和置信区间显示直方图。所有这些属性都可以手动自定义(请参阅下面的代码部分)。
# Create subplot
fig, ax = plt.subplots(1,2, figsize=(25, 10))
# Pareto plot (PDF with histogram)
dfit.plot(chart='PDF', ax=ax[0])
# Plot the CDF
dfit.plot(chart='CDF', ax=ax[1])
# Change or remove properties of the chart.
dfit.plot(chart='PDF',
emp_properties=None,
bar_properties=None,
pdf_properties={'color': 'r'},
cii_properties={'color': 'g'})
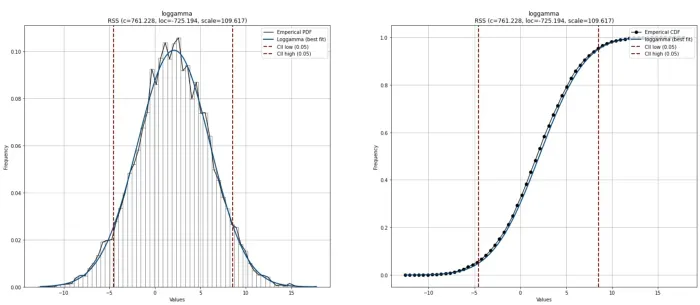
我们还可以使用 n_top 参数绘制所有其他估计的理论分布。目视检查证实,除少数例外,许多分布与经验数据非常吻合。分布从最适合(最高)到最差(最低)排列。在这里我们可以看到 dweibull 分布的拟合度很差,中间有两个峰。仅使用 RSS 分数很难判断是否使用此分布。均匀分布、指数分布和帕累托分布很容易显示出较差的 RSS 分数,现在也可以使用该图进行确认。
# Create subplot
fig, ax = plt.subplots(1,2, figsize=(25, 10))
# Pareto plot (PDF with histogram)
dfit.plot(chart='PDF', n_top=11, ax=ax[0])
# Plot the CDF
dfit.plot(chart='CDF', n_top=11, ax=ax[1])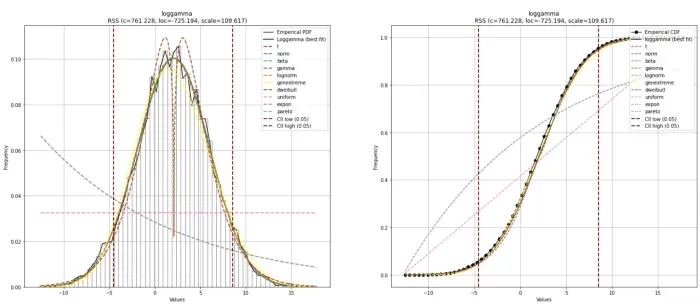
Quantile-Quantile plot.
我们还可以查看另外一个情节,即 QQ 情节。 QQ 图通过将分位数相互绘制来比较经验概率分布与理论概率分布。如果两个分布相等,则 QQ 图上的点将完全位于直线 y = x 上。我们可以使用 qqplot 函数制作 QQ 图(图 5)。左侧面板显示最佳拟合,右侧面板包括所有拟合的理论分布。有关如何解释 QQ 图的更多详细信息,请参阅此博客 [3]。
# Create subplot
fig, ax = plt.subplots(1,2, figsize=(25, 10))
# Plot left panel with best fitting distribution.
dfit.qqplot(X, ax=ax[0])
# plot right panel with all fitted theoretical distributions
dfit.qqplot(X, n_top=11, ax=ax[1])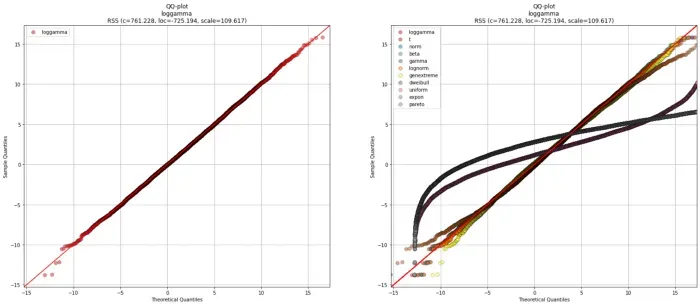
使用非参数拟合确定最佳分布拟合。
非参数密度估计是指人口样本“无分布”,这意味着数据与常见的理论分布不相似。在distfit中,非参数密度拟合实现了两种非参数方法:分位数和百分位数方法。这两种方法都假设数据不遵循特定的概率分布。在分位数方法的情况下,数据的分位数被建模,这对于具有偏态分布的数据很有用。在百分位数方法的情况下,百分位数被建模,这在数据包含多个峰值时非常有用。在这两种方法中,优点是它对异常值具有鲁棒性并且不对基础分布做出假设。在下面的代码部分中,我们使用方法 method=’quantile’ 或 method=’percentile’ 进行初始化。所有功能,如预测和绘图,都可以按照前面代码部分所示的相同方式使用。
# Load library
from distfit import distfit
# Create random normal data with mean=2 and std=4
X = np.random.normal(2, 4, 10000)
# Initialize using the quantile or percentile approach.
dfit = distfit(method='quantile')
dfit= distfit(method='percentile')
# Fit model on input data X and detect the best theoretical distribution.
dfit.fit_transform(X)
# Plot the results
fig, ax = dfit.plot()确定离散数据的最佳分布。
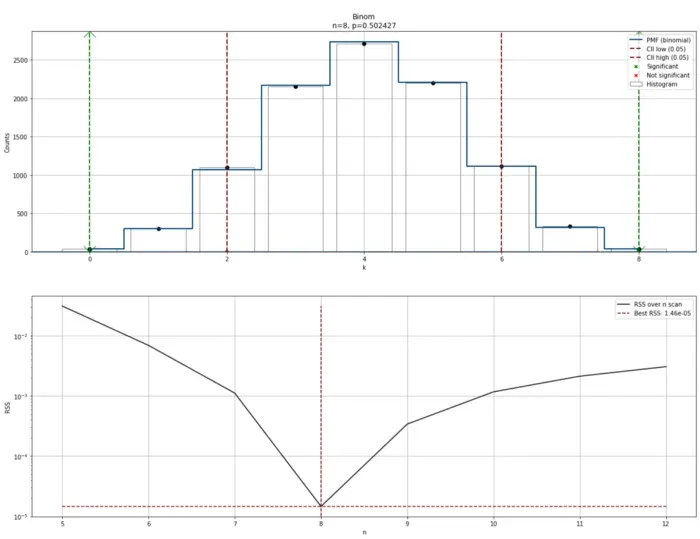
如果随机变量是离散的,则 distift 库包含离散拟合选项。使用二项分布得出最佳拟合。这些问题可以概括如下:给定一个非负整数列表,我们能否为离散分布拟合一个概率分布,并比较拟合的质量?对于离散量,正确的术语是概率质量函数 (PMF)。就离散分布而言,一个整数列表的 PMF 的形式为 P(k),并且只能拟合二项分布,具有合适的 n 和 p 值,并且此方法在 distfit 中实现。请参阅下面的代码部分,其中使用 n=8 和 p=0.5 创建了离散数据集。随机变量作为 distfit 的输入给出,distfit 检测到参数 n=8 和 p=0.501366,表明拟合非常好。
# Load library
from scipy.stats import binom
from distfit import distfit
# Parameters for the test-case:
n = 8
p = 0.5
# Generate 10000 randon discrete data points of the distribution of (n, p)
X = binom(n, p).rvs(10000)
# Initialize using the discrete approach.
dfit = distfit(method='discrete')
# Find the best fit.
dfit.fit_transform(X)
# print results
print(dfit.model)
# 'name': 'binom',
# 'score': 0.00010939074999009602,
# 'chi2r': 1.5627249998585145e-05,
# 'n': 8,
# 'p': 0.501366,
# 'CII_min_alpha': 2.0,
# 'CII_max_alpha': 6.0}
# 'distr': <scipy.stats._discrete_distns.binom_gen at 0x14350be2230>,
# 'model': <scipy.stats._distn_infrastructure.rv_discrete_frozen at 0x14397a2b640>,
# Make predictions
results = dfit.predict([0, 2, 8])使用绘图功能绘制结果。
# Plot the results
dfit.plot()
# Change colors or remove parts of the figure.
# Remove emperical distribution
dfit.plot(emp_properties=None)
# Remove PDF
dfit.plot(pdf_properties=None)
# Remove histograms
dfit.plot(bar_properties=None)
#Remove confidence intervals
dfit.plot(cii_properties=None)
分布拟合的应用。
了解数据集中的基础分布是许多应用程序的关键。我总结几点。
- 新颖性检测的异常检测是密度估计的明显应用。这可以通过计算给定分布和参数的置信区间来实现。异常检测适用于需要对异常情况进行清晰、早期预警的广泛工程情况。异常或新颖性是可能位于低密度区域的观察结果。 distfit 库计算置信区间,以及在给定拟合分布的情况下样本为异常值/新颖性的概率。请注意,重要性已针对多重测试进行了校正。因此,离群值可以位于置信区间之外,但不会标记为显着。
# Import libraries
import numpy as np
from distfit import distfit
# Create random normal data with mean=2 and std=4
X = np.random.normal(2, 4, 10000)
# Initialize using the parametric approach (default).
dfit = distfit(multtest='fdr_bh', alpha=0.05)
# Fit model on input data X.
dfit.fit_transform(X)
# With the fitted model we can make predictions on new unseen data.
y = [-8, -2, 1, 3, 5, 15]
dfit.predict(y)
# Print results
print(dfit.results['df'])
# y y_proba y_pred P
# 0 -8.0 0.017455 down 0.005818
# 1 -2.0 0.312256 none 0.156128
# 2 1.0 0.402486 none 0.399081
# 3 3.0 0.402486 none 0.402486
# 4 5.0 0.340335 none 0.226890
# 5 15.0 0.003417 up 0.000569
# Plot the results
dfit.plot()- 合成数据生成:概率分布拟合可用于生成类似于真实世界数据的合成数据。通过将概率分布拟合到真实世界的数据,可以生成可用于检验假设和评估算法性能的合成数据。在下面的代码部分,我们将首先从正态分布生成随机变量,估计分布参数,然后我们可以开始使用拟合分布创建合成数据。
# Import libraries
import numpy as np
from distfit import distfit
# Create random normal data with mean=2 and std=4
X = np.random.normal(2, 4, 10000)
# Initialize using the parametric approach (default).
dfit = distfit()
# Fit model on input data X.
dfit.fit_transform(X)
# The fitted distribution can now be used to generate new samples.
X_synthetic = dfit.generate(n=1000)- 优化和压缩:概率分布拟合可用于优化概率分布的各种参数,例如均值和方差,以最佳地拟合数据。找到最佳参数有助于更好地理解数据。另外,如果只用loc、scale、arg参数就可以描述成百上千个观测值,是对数据非常强的压缩。
- 对输入数据集属性的非正式调查是密度估计的一种非常自然的使用。密度估计可以为数据中的偏度和多模态提供有价值的指示。在某些情况下,它们会得出不言自明的结论,而在其他情况下,它们会为进一步分析和数据收集指明方向。
- 检验假设:概率分布拟合可用于检验关于数据集的潜在概率分布的假设。例如,可以使用拟合优度检验将数据与正态分布进行比较,或使用卡方检验将数据与泊松分布进行比较。
- 建模:概率分布拟合可用于对天气模式、股票市场趋势、生物学、人口动态和预测性维护等复杂系统进行建模。通过将概率分布拟合到历史数据,可以提取有价值的见解并创建可用于预测未来行为的模型。
Final words.
我谈到了参数、非参数和离散随机变量的概率密度拟合的概念。使用 distfit 库,可以直接在 89 个理论分布中检测出最佳理论分布。它流水线化了直方图的密度估计过程、估计分布参数、测试拟合优度以及返回最佳拟合分布的参数。可以使用各种绘图功能探索最佳拟合,例如直方图、帕累托图、CDF/PDF 图和 QQ 图。所有地块都可以定制并轻松组合。此外,还可以对新的未见过的样本进行预测。另一个功能是使用拟合模型参数创建合成数据。
在数据科学领域工作时,了解分布拟合有很大的好处。它不仅是为了更好地理解、探索和准备数据,而且是为了带来快速和轻量级的解决方案。很高兴认识到统计测试只能帮助您朝正确的方向看,选择最佳模型不是统计问题;这是一个建模决定。明智地选择你的模型。
注意安全。保持冷淡。
Cheers E.
如果您觉得这篇文章有帮助,请使用我的推荐链接注册成为 Medium 会员或关注我以访问类似的博客,从而帮助支持我的内容。[0][1]
Software
Let’s connect!
Terminology.
本博客中最重要的定义/术语:
“随机变量是值未知的变量,或者是为每个实验结果赋值的函数。随机变量可以是离散的(具有特定值)或连续的(连续范围内的任何值)”[1]。它可以是数据集中针对特定特征(例如人体身高)的单列。它也可以是您的整个数据集,由传感器测量并包含数千个特征。
概率密度函数 (PDF) 是一种统计表达式,用于定义连续随机变量的概率分布(结果的可能性)[1, 6]。正态分布是 PDF(众所周知的钟形曲线)的常见示例。术语 PDF 有时也被描述为“概率函数”的“分布函数”。[0]
理论分布是 PDF 的一种形式。理论分布的例子有正态分布、二项分布、指数分布、泊松分布等 [7]。 distfit 库包含 89 个理论分布。
经验分布(或数据分布)是观察到的随机变量(输入数据)[8] 的基于频率的分布。直方图通常用于可视化经验分布。
References
- W. Kenton,概率密度函数的基础知识 (PDF),以示例为例,2022 年,Investopedia。[0]
- E. Taskesen,什么是 PCA 载荷以及如何有效地使用双标图? 2022 年中期。[0]
- P. Varshney,Q-Q 图解释,Medium 2020。[0]
- Gamma Distribution, Wikipedia.[0]
- A. Downey,你的数据正常吗?提示:不。 2018 年,博客。[0]
- 概率密度函数,维基百科。[0]
- 概率分布列表,维基百科[0]
- 经验分布函数,维基百科[0]
文章出处登录后可见!