



原文标题 :Are You Still Using the Elbow Method?
你还在用肘法吗?
Elbow 方法是查找 k-means 聚类数的最流行方法。但还有更好的选择

我请 ChatGPT 就如何为 k-means 选择正确数量的集群提供建议。这是答案:


ChatGPT 建议使用所谓的“肘部方法”,这是迄今为止许多在线和离线资源中引用最多的方法。
然而,肘法的流行是相当莫名其妙的!事实上,正如我们将在本文中看到的那样,这种方法几乎总是优于现有的不同方法。
如果您想知道在为数据集确定最佳聚类数时如何轻松击败 Elbow 方法,请继续阅读。
Testing the elbow
Elbow 方法背后的逻辑如下。
因为我们想知道什么是最好的聚类数 (k),所以我们尝试不同的 k 值,例如,所有介于 1 和数据集观测值的平方根之间的整数值。在每次迭代中,我们记录所谓的“惯性”。
inertia = []
for k in range(1, 14):
inertia.append(KMeans(n_clusters=k).inertia_)惯性是每个点与其所属簇的中心之间距离的平方和。因此,随着 k 的增加,惯性会变小是有道理的。事实上,随着聚类的增多,每个聚类也变得更小,因此每个点都更接近其聚类的中心。最终,当 k 等于数据点数时,惯性必然为零。
这个想法是 k 的最佳值是惯性曲线的最大曲率点。这是较低的惯性值不值得额外的复杂性(即更多的集群)的地方。该点称为曲线的弯头。
要定位惯性曲线的肘部,我们可以使用一个名为 kned 的 Python 库:
from kneed import KneeLocator
k_elbow = KneeLocator(
x=range(1, 14),
y=inertia,
curve="convex",
direction="decreasing").elbow让我们看一下由 3 个簇组成的二维数据集的示例:

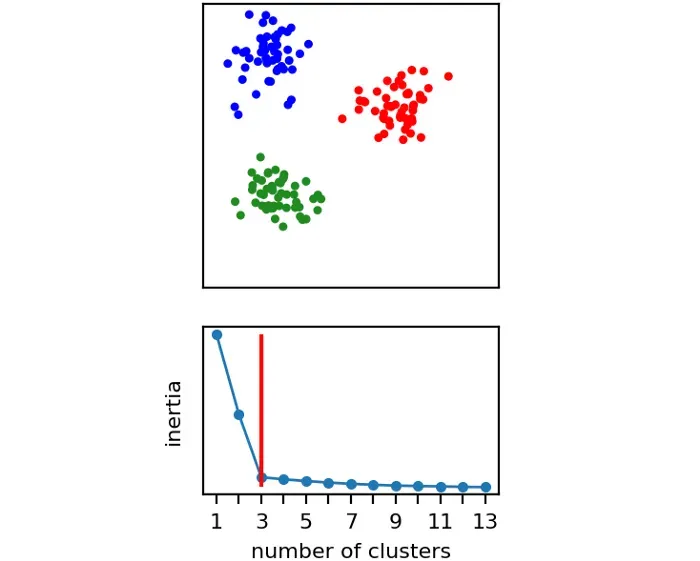
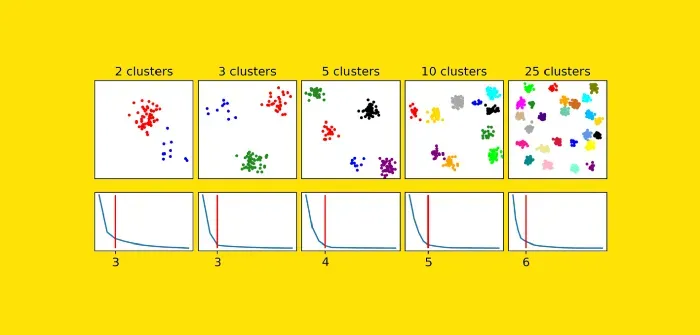
在这种情况下,Elbow 方法猜测正确的簇数:3。但它是否也适用于其他数据集?
Let’s see.

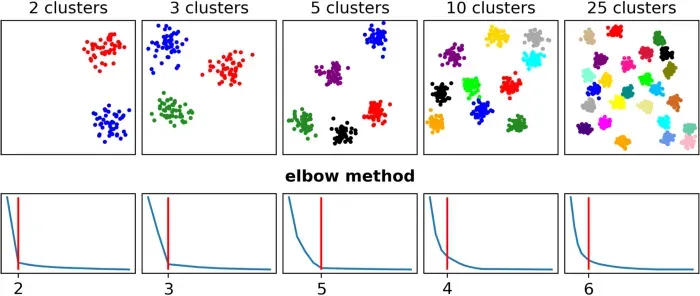
Elbow 方法在三个数据集(2、3 和 5)中猜测了正确的簇数,但在其他两个示例(10 和 25)中严重低估了它。
好吧,肘部方法可能没有像我们希望的那样起作用。但是市场上有更好的东西吗?
超越肘法
Elbow 方法基于惯性,惯性是集群拟合优度的得分。但是如果我们想使用不同的方法,我们将需要使用不同的分数。
让我们看一下 Scikit-Learn 中直接可用的选项。

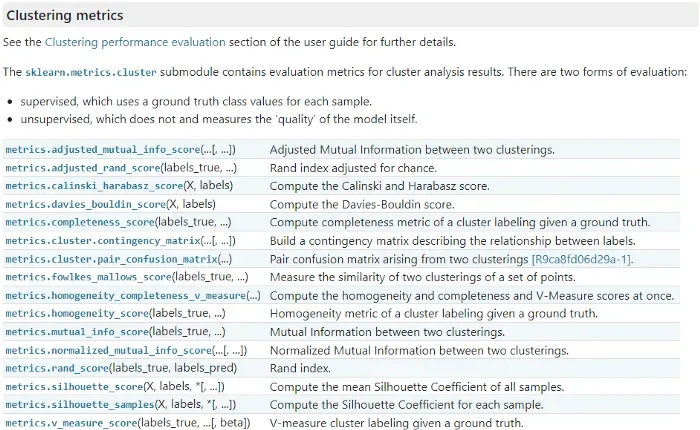
实际上,其中许多指标对我们来说都不起作用,因为它们需要 labels_true 作为输入,而我们想在没有真实标签的情况下测试这些方法。
因此,在这个列表中,我们只能使用将 X 和标签作为输入的指标。因此,只有“Calinski-Harabasz”、“Davies-Bouldin”和“Silhouette”适合我们。
除了这些,我将添加另一个未在 Scikit-Learn 中实现的分数。分数是“BIC”(贝叶斯信息准则),我将其包括在内,因为本文表明它表现得非常好。对于 BIC,我将使用 Bob Hancock 在这个 GitHub 存储库中所做的实现。由于代码在 GoLang 中,我已将其翻译成以下 Python 函数:[0][1]
def bic_score(X, labels):
"""
BIC score for the goodness of fit of clusters.
This Python function is directly translated from the GoLang code made by the author of the paper.
The original code is available here: https://github.com/bobhancock/goxmeans/blob/a78e909e374c6f97ddd04a239658c7c5b7365e5c/km.go#L778
"""
n_points = len(labels)
n_clusters = len(set(labels))
n_dimensions = X.shape[1]
n_parameters = (n_clusters - 1) + (n_dimensions * n_clusters) + 1
loglikelihood = 0
for label_name in set(labels):
X_cluster = X[labels == label_name]
n_points_cluster = len(X_cluster)
centroid = np.mean(X_cluster, axis=0)
variance = np.sum((X_cluster - centroid) ** 2) / (len(X_cluster) - 1)
loglikelihood += \
n_points_cluster * np.log(n_points_cluster) \
- n_points_cluster * np.log(n_points) \
- n_points_cluster * n_dimensions / 2 * np.log(2 * math.pi * variance) \
- (n_points_cluster - 1) / 2
bic = loglikelihood - (n_parameters / 2) * np.log(n_points)
return bic综上所述,我们现在有五个分数可以比较:
- Inertia (elbow method);
- Calinski-Harabasz;
- Davies-Bouldin;
- Silhouette;
- BIC.
过程是相同的:对于每个数据集,我们使用 k = 1、k = 2、k = 3、……来拟合 k-means 对于每个 k,我们计算这五个分数。这意味着我们最终得到 5 条曲线,每个指标一条。
在这一点上,我们如何决定什么是最优的 k?由于惯性,我们已经知道答案:它位于“肘部”。其他分数使用起来更简单,因为它们的行为要么是“越高越好”,要么是“越低越好”:
- 惯性→弯头更好;
- Calinski-Harabasz → 越高越好;
- Davies-Bouldin → 越低越好;
- 轮廓→越高越好;
- BIC → 越高越好。
那么让我们看看这些分数如何在我们的五个数据集上发挥作用。

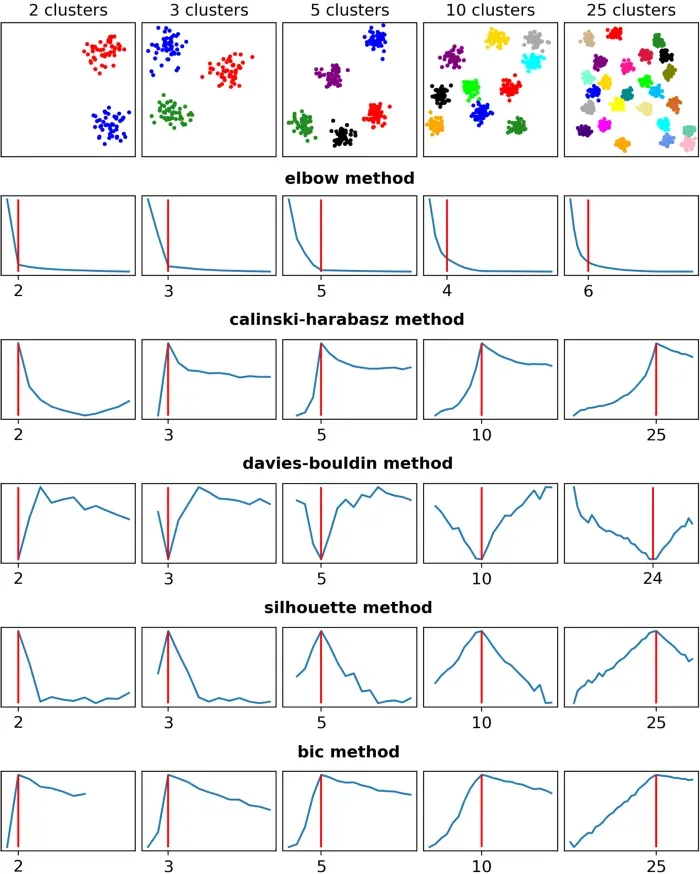
正如我们所见,Elbow 方法正确猜测了三个数据集,而在其余两个数据集中完全错过了目标。相反,其他方法猜对了所有数据集(第五个数据集上的 Davies-Bouldin 除外,它非常接近实数:24 而不是 25)。
但也许这些数据集太简单了。事实上,所有数据集都是由大小相同的集群组成的。这是一种不太可能发生的情况:在大多数真实数据集中,我们期望聚类具有不同数量的观察值。
因此,让我们看看大小不等的集群会发生什么。
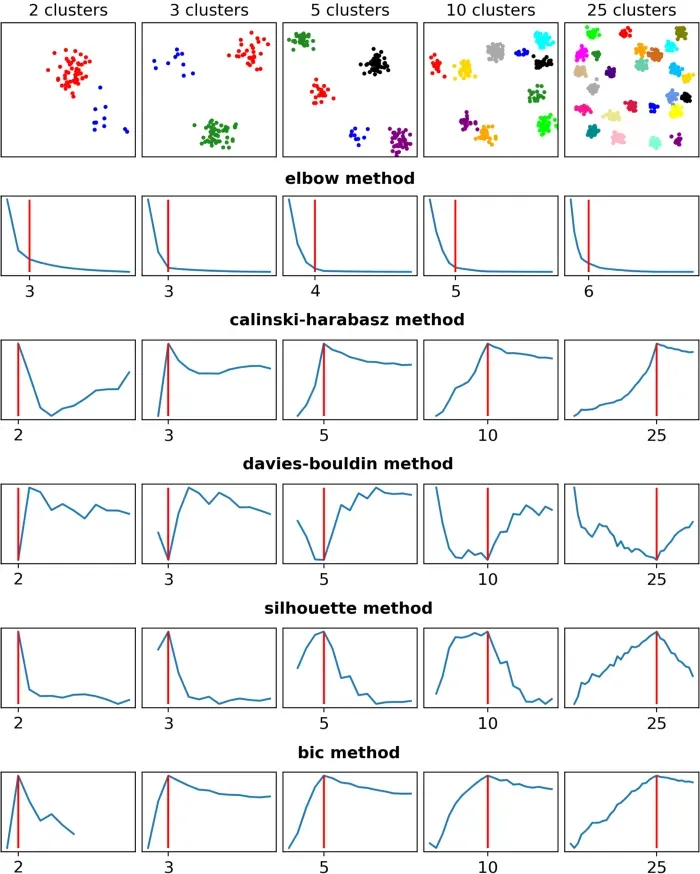
这一次,肘法与其他方法的区别比以前更加明显。事实上,虽然 Elbow 方法只对一个集群做出了正确的选择,但其他四种方法正确地猜测了所有五个数据集。
这些例子很有趣,但它们仍然没有告诉我们哪种方法更可取。为了回答这个问题,我们应该进行更大规模的比较。
A systematic comparison
我构建了 30 个数据集,每个数据集都有不同数量的集群,从 1 到 30。每个集群都有不同数量的观察值。
对于每个数据集,我尝试了不同的 k 值并记录了五个结果分数(Inertia、Calinski-Harabasz、Davies-Bouldin、Silhouette 和 BIC)。然后,根据我们在上面看到的规则,我确定了每个方法推荐的 k 值。
为了确定哪种方法胜出,我绘制了每个数据集的真实聚类数(x 轴)和每种方法建议的聚类数(y 轴)。显然,最好的方法是靠近平分线的方法。

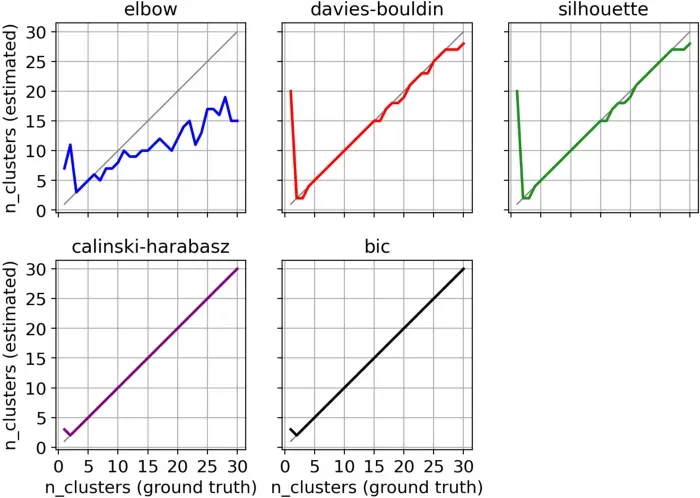
从图中可以明显看出,Elbow 方法是迄今为止表现最差的方法。 Davies-Bouldin 和 Silhouette 在大多数情况下都是正确的,或者至少非常接近真实情况(真正的 k 等于 1 时除外)。但明显的赢家(持平)是 Calinski-Harabasz 和 BIC。
我们还可以通过计算一种方法猜测真实簇数(准确率)的次数以及它们与真实值的平均距离(平均距离)有多远来总结这些视觉见解:

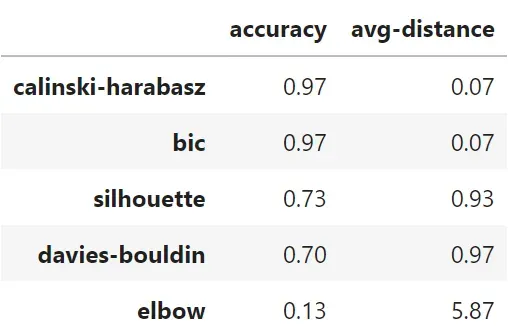
Calinski-Harabasz 和 BIC 在 97% 的案例中是正确的(30 个中有 29 个),这令人印象深刻。 Silhouette 的正确率为 73%(30 人中有 22 人),Davies-Bouldin 的正确率为 70%(30 人中有 21 人)。 Elbow 方法与其他方法相去甚远,只有 13%(30 个中有 4 个)。
Conclusions
In this article, we have seen that, despite its popularity, the Elbow method is pretty much the worst choice one can do when setting the number of clusters for a dataset. Indeed, all the four alternatives that we tested did much better than the Elbow method. In particular, Calinski-Harabasz and BIC performed extremely well, with only one mistake out of 30 datasets.
您可以在本笔记本中找到本文使用的所有 Python 代码。[0]
感谢您的阅读!我希望你喜欢这篇文章。如果你愿意,请在 Linkedin 上加我![0]
文章出处登录后可见!