前言
最近实习需要搞的工程涉及到姿态估计,对这2天的学习做一下总结归纳,第一步就是准备数据集,查资料后发现window环境下使用的标注软件就是labelme(coco-annotator好像就可以直接输出coco格式的JSON文件,后期继续学习),labelme产出的JSON文件需要转换到coco格式的JSON文件,然后将JSON文件转成Yolo需要的txt文件,才能送工程进行训练,转来转去的个人感觉非常麻烦。
本博文主要内容是分享关键点的labelme2coco——JSON文件转换,cocoJSON2cocotxt的转换,以及coco_kpts文件夹的内容布局。
一、labelme标注关键点的使用:
用labelme标注关键点与后续的labelme2coco转换代码息息相关,假设标注对象是人体,关键点有17个:“nose”,“left_eye”, “right_eye”,“left_ear”, “right_ear”,“left_shoulder”, “right_shoulder”,“left_elbow”, “right_elbow”,“left_wrist”, “right_wrist”,“left_hip”, “right_hip”,“left_knee”, “right_knee”,“left_ankle”, “right_ankle”,label编号从1依次排到17,然后再把人用rectangle框出来label编号为bbox(Yolopose是需要画框的,并且numclass已经固定好了为person),所有的Group id都不用写,JSON文件会自动补上null但不影响我们后续操作,填写label及Group id的界面如下图所示:
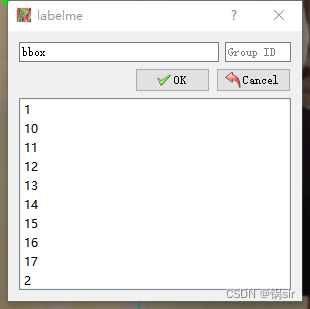
选取一张图片,把17个关键点都标注出来,再把人框出来,如果对象显示半个身体,不满17个关键点,也无所谓,没有哪个部位就把那个部位标注数值空出来就可以了,一张图片操作结束后,就如下图所示:

coco图片的格式是12位数字,标注完后的JSON文件用相同的名称命名即可。
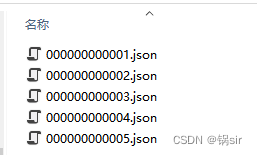
二、labelme2coco_keypoints.py
CSDN上的其他转换代码,我都没法直接跑,也没有相关的讲解,于是我就拿了现有的代码修改了一些,并记录了我的学习过程。先介绍一下哪些部分需要修改的,然后在附上整个代码,以17个人体关键点标注好的JSON文件为例。
"keypoints":#这是固定的,要是其他的关键点标注,则需要修改内容并且与前面的label编号一一对应。
[
"nose",
"left_eye", "right_eye",
"left_ear", "right_ear",
"left_shoulder", "right_shoulder",
"left_elbow", "right_elbow",
"left_wrist", "right_wrist",
"left_hip", "right_hip",
"left_knee", "right_knee",
"left_ankle", "right_ankle"
],
"skeleton": [
[16, 14],
[14, 12],
[17, 15],
[15, 13],
[12, 13],
[6, 12],
[7, 13],
[6, 7],
[6, 8],
[7, 9],
[8, 10],
[9, 11],
[2, 3],
[1, 2],
[1, 3],
[2, 4],
[3, 5],
[4, 6],
[5, 7]
]
json_file[-17:-5]#这是为了取文件的名称,比如000000000001,如果文件名称变了,则需要修改
json_file[-17:-4]#这是为了取文件的名称,比如000000000001.(多一个.)
keypoints 里面放的是(x,y,v):x,y是坐标值,v一般取2,0代表没有该点,1代表该点存在但是被遮挡了,2代表该点存在且没有被遮挡。(具体可以参考coco数据集的格式,本文主要介绍如何应用)
keypoints = [0] * 3 * 17 #这里是我们标注的关节点个数 如有改动,需要修改
json_path = r'E:\val2017\Json' #存放需要转换的json文件夹,变动需要修改
c = tococo(json_path, save_path=r'E:\val2017\annotations\val.json', a=1) #输出的地址及名称,变动需要修改
整个代码如下,可以做到一个文件夹下所有的JSON文件一起转换并输出一个coco格式的JSON文件
import numpy as np
import json
import glob
import codecs
import os
class MyEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, np.integer):
return int(obj)
elif isinstance(obj, np.floating):
return float(obj)
elif isinstance(obj, np.ndarray):
return obj.tolist()
else:
return super(MyEncoder, self).default(obj)
class tococo(object):
def __init__(self, jsonfile, save_path, a):
self.images = []
self.categories = [
{
"supercategory": "person",
"id": 1,
"name": "person",
"keypoints":
[
"nose",
"left_eye", "right_eye",
"left_ear", "right_ear",
"left_shoulder", "right_shoulder",
"left_elbow", "right_elbow",
"left_wrist", "right_wrist",
"left_hip", "right_hip",
"left_knee", "right_knee",
"left_ankle", "right_ankle"
],
"skeleton": [
[16, 14],
[14, 12],
[17, 15],
[15, 13],
[12, 13],
[6, 12],
[7, 13],
[6, 7],
[6, 8],
[7, 9],
[8, 10],
[9, 11],
[2, 3],
[1, 2],
[1, 3],
[2, 4],
[3, 5],
[4, 6],
[5, 7]
]
}
]
self.annotations = []
self.jsonfile = os.listdir(jsonfile)
self.save_path = save_path # 保存json的路径
self.class_id = a # class 我们的类别只有一个 person
self.coco = {}
self.path = jsonfile
def labelme_to_coco(self):
for num, json_file in enumerate(self.jsonfile):
json_file = os.path.join(self.path, json_file)
data = codecs.open(json_file, 'r')
data = json.load(data)
self.images.append(self.get_images(json_file[-17:-4] + 'jpg', data["imageHeight"], data["imageWidth"]))
shapes = data["shapes"]
annotation = {} # 一个annotation代表一张图片中的所有samples
num_keypoints = 0
keypoints = [0] * 3 * 17 #这里是我们标注的关节点个数 如有改动,需要修改
flag = 0
for shape in shapes:
if shape['shape_type'] == 'rectangle' or shape["label"] == 'bbox':
bbox = []
temp = shape["points"]
try:
x_min = min(temp[0][0], temp[1][0])
except IndexError as e:
print('class: {}, image: {}'.format(self.class_id, int(json_file[-17:-5])))
x_max = max(temp[0][0], temp[1][0])
y_min = min(temp[0][1], temp[1][1])
y_max = max(temp[0][1], temp[1][1])
bbox.append(x_min)
bbox.append(y_min)
w = x_max - x_min + 1
h = y_max - y_min + 1
bbox.append(w)
bbox.append(h)
annotation['bbox'] = bbox
flag = flag + 1
else:
idx = int(shape['label'])
try:
keypoints[(idx - 1) * 3 + 0] = shape['points'][0][0]
keypoints[(idx - 1) * 3 + 1] = shape['points'][0][1]
keypoints[(idx - 1) * 3 + 2] = 2
num_keypoints = num_keypoints + 1
except IndexError as e:
print('class: {}, image: {}'.format(self.class_id, int(json_file[-17:-5])))
if flag == 0:
print('{}\\{} does not contain bbox\n'.format(self.class_id, json_file))
annotation['segmentation'] = [[]]
annotation['num_keypoints'] = num_keypoints
annotation['iscrowd'] = 0
annotation['keypoints'] = keypoints
annotation['image_id'] = int(json_file[-17:-5]) # 对应的图片ID
if 'bbox' not in annotation:
annotation['bbox'] = [0, 0, data['imageWidth'], data['imageHeight']]
annotation['area'] = 0
else:
annotation['area'] = int(bbox[2] * bbox[3])
annotation['category_id'] = 1
annotation['id'] = int(json_file[-17:-5]) # 对象id
self.annotations.append(annotation)
self.image_id = int(json_file[-17:-5])
self.coco["images"] = self.images
self.coco["categories"] = self.categories
self.coco["annotations"] = self.annotations
def get_images(self, filename, height, width):
image = {}
image["height"] = height
image['width'] = width
image["id"] = int(filename[-16:-4])
image["file_name"] = filename
return image
def get_categories(self, name, class_id):
category = {}
category["supercategory"] = "person"
category['id'] = class_id
category['name'] = name
return category
def save_json(self):
self.labelme_to_coco()
coco_data = self.coco
# 保存json文件
json.dump(coco_data, open(self.save_path, 'w'), indent=4, cls=MyEncoder) # indent=4 更加美观显示
return self.image_id
json_path = r'E:\val2017\Json_old' #保存json的文件夹路径
c = tococo(json_path, save_path=r'E:\val2017\annotations_old\val.json', a=1) #我们将我们的左右json文件合成为一个json文件,这是最后json文件的名称
image_id = c.save_json()
本人将5个JSON文件放在同一个文件夹下运行转换代码,最后val.json通过VS2022(其他软件也可以)打开后内容如下所示:

三、coco api来检查coco格式的JSON文件是否有问题
# !/usr/bin python3
# encoding : utf-8 -*-
# @author : liangjian
# @software : PyCharm
# @file : 0408.py
# @Time : 2021/4/8 21:51
import skimage.io as io
import pylab
import time as time
import json
import numpy as np
from collections import defaultdict
import itertools
import matplotlib.pyplot as plt
from matplotlib.collections import PatchCollection
def _isArrayLike(obj):
return hasattr(obj, '__iter__') and hasattr(obj, '__len__')
class COCO:
def __init__(self, annotation_file=None):
"""
Constructor of Microsoft COCO helper class for reading and visualizing annotations.
:param annotation_file (str): location of annotation file
:param image_folder (str): location to the folder that hosts images.
:return:
"""
# load dataset
self.dataset, self.anns, self.cats, self.imgs = dict(), dict(), dict(), dict()
self.imgToAnns, self.catToImgs = defaultdict(list), defaultdict(list)
if not annotation_file == None:
print('loading annotations into memory...')
tic = time.time()
dataset = json.load(open(annotation_file, 'r'))
assert type(dataset) == dict, 'annotation file format {} not supported'.format(type(dataset))
print('Done (t={:0.2f}s)'.format(time.time() - tic))
self.dataset = dataset
self.createIndex()
def createIndex(self):
# create index
print('creating index...')
anns, cats, imgs = {}, {}, {}
imgToAnns, catToImgs = defaultdict(list), defaultdict(list)
if 'annotations' in self.dataset:
for ann in self.dataset['annotations']:
imgToAnns[ann['image_id']].append(ann)
anns[ann['id']] = ann
if 'images' in self.dataset:
for img in self.dataset['images']:
imgs[img['id']] = img
if 'categories' in self.dataset:
for cat in self.dataset['categories']:
cats[cat['id']] = cat
if 'annotations' in self.dataset and 'categories' in self.dataset:
for ann in self.dataset['annotations']:
catToImgs[ann['category_id']].append(ann['image_id'])
print('index created!')
# create class members
self.anns = anns
self.imgToAnns = imgToAnns
self.catToImgs = catToImgs
self.imgs = imgs
self.cats = cats
def getCatIds(self, catNms=[], supNms=[], catIds=[]):
"""
filtering parameters. default skips that filter.
:param catNms (str array) : get cats for given cat names
:param supNms (str array) : get cats for given supercategory names
:param catIds (int array) : get cats for given cat ids
:return: ids (int array) : integer array of cat ids
"""
catNms = catNms if _isArrayLike(catNms) else [catNms]
supNms = supNms if _isArrayLike(supNms) else [supNms]
catIds = catIds if _isArrayLike(catIds) else [catIds]
if len(catNms) == len(supNms) == len(catIds) == 0:
cats = self.dataset['categories']
else:
cats = self.dataset['categories']
# print(' ')
# print('keypoints的cat就只有人1种')
# print(cats)
cats = cats if len(catNms) == 0 else [cat for cat in cats if cat['name'] in catNms]
cats = cats if len(supNms) == 0 else [cat for cat in cats if cat['supercategory'] in supNms]
cats = cats if len(catIds) == 0 else [cat for cat in cats if cat['id'] in catIds]
# print(cats)
ids = [cat['id'] for cat in cats]
return ids
def loadCats(self, ids=[]):
"""
Load cats with the specified ids.
:param ids (int array) : integer ids specifying cats
:return: cats (object array) : loaded cat objects
"""
if _isArrayLike(ids):
return [self.cats[id] for id in ids]
elif type(ids) == int:
return [self.cats[ids]]
def getImgIds(self, imgIds=[], catIds=[]):
'''
Get img ids that satisfy given filter conditions.
:param imgIds (int array) : get imgs for given ids
:param catIds (int array) : get imgs with all given cats
:return: ids (int array) : integer array of img ids
'''
imgIds = imgIds if _isArrayLike(imgIds) else [imgIds]
catIds = catIds if _isArrayLike(catIds) else [catIds]
if len(imgIds) == len(catIds) == 0:
ids = self.imgs.keys()
else:
ids = set(imgIds)
for i, catId in enumerate(catIds):
if i == 0 and len(ids) == 0:
ids = set(self.catToImgs[catId])
else:
ids &= set(self.catToImgs[catId])
return list(ids)
def loadImgs(self, ids=[]):
"""
Load anns with the specified ids.
:param ids (int array) : integer ids specifying img
:return: imgs (object array) : loaded img objects
"""
if _isArrayLike(ids):
return [self.imgs[id] for id in ids]
elif type(ids) == int:
return [self.imgs[ids]]
def getAnnIds(self, imgIds=[], catIds=[], areaRng=[], iscrowd=None):
"""
Get ann ids that satisfy given filter conditions. default skips that filter
:param imgIds (int array) : get anns for given imgs
catIds (int array) : get anns for given cats
areaRng (float array) : get anns for given area range (e.g. [0 inf])
iscrowd (boolean) : get anns for given crowd label (False or True)
:return: ids (int array) : integer array of ann ids
"""
imgIds = imgIds if _isArrayLike(imgIds) else [imgIds]
catIds = catIds if _isArrayLike(catIds) else [catIds]
if len(imgIds) == len(catIds) == len(areaRng) == 0:
anns = self.dataset['annotations']
else:
# 根据imgIds找到所有的ann
if not len(imgIds) == 0:
lists = [self.imgToAnns[imgId] for imgId in imgIds if imgId in self.imgToAnns]
anns = list(itertools.chain.from_iterable(lists))
else:
anns = self.dataset['annotations']
# 通过各类条件如catIds对anns进行筛选
anns = anns if len(catIds) == 0 else [ann for ann in anns if ann['category_id'] in catIds]
anns = anns if len(areaRng) == 0 else [ann for ann in anns if
ann['area'] > areaRng[0] and ann['area'] < areaRng[1]]
if not iscrowd == None:
ids = [ann['id'] for ann in anns if ann['iscrowd'] == iscrowd]
else:
ids = [ann['id'] for ann in anns]
return ids
def loadAnns(self, ids=[]):
"""
Load anns with the specified ids.
:param ids (int array) : integer ids specifying anns
:return: anns (object array) : loaded ann objects
"""
if _isArrayLike(ids):
return [self.anns[id] for id in ids]
elif type(ids) == int:
return [self.anns[ids]]
def showAnns(self, anns):
"""
Display the specified annotations.
:param anns (array of object): annotations to display
:return: None
"""
if len(anns) == 0:
return 0
if 'segmentation' in anns[0] or 'keypoints' in anns[0]:
datasetType = 'instances'
elif 'caption' in anns[0]:
datasetType = 'captions'
else:
raise Exception('datasetType not supported')
if datasetType == 'instances':
ax = plt.gca()
ax.set_autoscale_on(False)
polygons = []
color = []
for ann in anns:
c = (np.random.random((1, 3)) * 0.6 + 0.4).tolist()[0]
# if 'segmentation' in ann:
# if type(ann['segmentation']) == list:
# # polygon
# for seg in ann['segmentation']:
# poly = np.array(seg).reshape((int(len(seg)/2), 2))
# polygons.append(Polygon(poly))
# color.append(c)
# else:
# # mask
# t = self.imgs[ann['image_id']]
# if type(ann['segmentation']['counts']) == list:
# rle = maskUtils.frPyObjects([ann['segmentation']], t['height'], t['width'])
# else:
# rle = [ann['segmentation']]
# m = maskUtils.decode(rle)
# img = np.ones( (m.shape[0], m.shape[1(余下全部)], 3(from 1, 10张取一张)) )
# if ann['iscrowd'] == 1(余下全部):
# color_mask = np.array([2.0,166.0,101.0])/255
# if ann['iscrowd'] == 0:
# color_mask = np.random.random((1(余下全部), 3(from 1, 10张取一张))).tolist()[0]
# for i in range(3(from 1, 10张取一张)):
# img[:,:,i] = color_mask[i]
# ax.imshow(np.dstack( (img, m*0.5) ))
if 'keypoints' in ann and type(ann['keypoints']) == list:
# turn skeleton into zero-based index
sks = np.array(self.loadCats(ann['category_id'])[0]['skeleton']) - 1
kp = np.array(ann['keypoints'])
x = kp[0::3]
y = kp[1::3]
v = kp[2::3]
for sk in sks:
if np.all(v[sk] > 0):
# # 画点之间的连接线
plt.plot(x[sk], y[sk], linewidth=1, color=c)
# 画点
plt.plot(x[v > 0], y[v > 0], 'o', markersize=4, markerfacecolor=c, markeredgecolor='k',
markeredgewidth=1)
plt.plot(x[v > 1], y[v > 1], 'o', markersize=4, markerfacecolor=c, markeredgecolor=c,
markeredgewidth=1)
p = PatchCollection(polygons, facecolor=color, linewidths=0, alpha=0.4)
ax.add_collection(p)
p = PatchCollection(polygons, facecolor='none', edgecolors=color, linewidths=2)
ax.add_collection(p)
elif datasetType == 'captions':
for ann in anns:
print(ann['caption'])
pylab.rcParams['figure.figsize'] = (8.0, 10.0)
annFile = r'E:\val2017\annotations_old\val.json' #转换之后的json文件路径
img_prefix = r'E:\val2017' #图片文件夹路径
# initialize COCO api for instance annotations
coco = COCO(annFile)
# getCatIds(catNms=[], supNms=[], catIds=[])
# 通过输入类别的名字、大类的名字或是种类的id,来筛选得到图片所属类别的id
catIds = coco.getCatIds(catNms=['person'])
# getImgIds(imgIds=[], catIds=[])
# 通过图片的id或是所属种类的id得到图片的id
imgIds = coco.getImgIds(catIds=catIds)
# imgIds = coco.getImgIds(imgIds=[1407])
# loadImgs(ids=[])
# 得到图片的id信息后,就可以用loadImgs得到图片的信息了
# 在这里我们随机选取之前list中的一张图片
img = coco.loadImgs(imgIds[np.random.randint(0, len(imgIds))])[0]
I = io.imread('%s/%s' % (img_prefix, img['file_name']))
plt.imshow(I)
plt.axis('off')
ax = plt.gca()
# getAnnIds(imgIds=[], catIds=[], areaRng=[], iscrowd=None)
# 通过输入图片的id、类别的id、实例的面积、是否是人群来得到图片的注释id
annIds = coco.getAnnIds(imgIds=img['id'], catIds=catIds, iscrowd=None)
# loadAnns(ids=[])
# 通过注释的id,得到注释的信息
anns = coco.loadAnns(annIds)
print('anns:', anns)
coco.showAnns(anns)
plt.imshow(I)
plt.axis('off')
plt.show()
需要修改的地方为
annFile = r'E:\val2017\annotations\val.json' #转换之后的coco格式json文件路径
img_prefix = r'E:\val2017' #图片文件夹路径
如果不出意外的话,就不会出现意外了,可以看到你标注的效果如下图所示:

总结
至此,labelme下的JSON转coco格式的JSON就完成了,由于篇幅问题,coco格式的JSON转yolo需要的txt相关介绍,在Yolopose关键点检测:自己标注数据集,制作数据集(二)中有相关讲解。
文章出处登录后可见!