前面已经写了4篇关于yolov5的文章,链接如下:
1、基于libtorch的yolov5目标检测网络实现——COCO数据集json标签文件解析
2、基于libtorch的yolov5目标检测网络实现(2)——网络结构实现
3、基于libtorch的yolov5目标检测网络实现(3)——Kmeans聚类获取anchor框尺寸
4、C++实现Kmeans聚类算法获取COCO目标检测数据集的anchor框
其中:
-
第一篇讲COCO数据集json标签的解析;
-
第二篇讲yolov5神经网络正向传播的liborch实现;
-
第三篇讲使用Opencv提供的Kmeans算法来获取anchor框尺寸;
-
第四篇讲自己使用C++实现的Kmeans算法来获取anchor框尺寸,相对来说,本篇获取的anchor比第三篇获取的更精确。
本文我们主要讲yolov5网络的损失函数计算原理。
01
目标检测结果精确度的度量
目标检测任务有三个主要目的:
(1)检测出图像中目标的位置,同一张图像中可能存在多个检测目标;
(2)检测出目标的大小,通常为恰好包围目标的矩形框;
(3)对检测到的目标进行识别分类。
所以,判断检测结果精确不精确,主要基于以上三个目的来衡量:
(1)首先我们来定义理想情况:图像中实际存在目标的所有位置,都被检测出来。检测结果越接近这个理想状态,也即漏检/误检的目标越少,则认为结果越精确;
(2)同样定义理想情况:检测到的矩形框恰好能包围检测目标。检测结果越接近这个理想状态,那么认为结果越精确;
(3)对检测到的目标,进行识别与分类,分类结果与目标的实际分类越符合,说明结果越精确。
如下图所示,人、大巴为检测目标,既要检测出所有人和大巴的位置,也要检测出包围人和大巴的最小矩形框,同时还要识别出哪个矩形框内是人,哪个矩形框内是大巴。

02
yolov5网络的损失函数构成
前文我们也讲过yolov5网络的基本思想:
把640*640的输入图像划分成N*N(通常为80*80、40*40、20*20)的网格,然后对网格的每个格子都预测三个指标:矩形框、置信度、分类概率。
其中:
-
矩形框表征目标的大小以及精确位置。
-
置信度表征所预测矩形框(简称预测框)的可信程度,取值范围0~1,值越大说明该矩形框中越可能存在目标。
-
分类概率表征目标的类别。
所以在实际检测时:
-
首先判断每个预测框的预测置信度是否超过设定阈值,若超过则认为该预测框内存在目标,从而得到目标的大致位置。
-
接着根据非极大值抑制算法对存在目标的预测框进行筛选,剔除对应同一目标的重复矩形框(非极大值抑制算法我们后续再详细讲)。
-
最后根据筛选后预测框的分类概率,取最大概率对应的索引,即为目标的分类索引号,从而得到目标的类别。
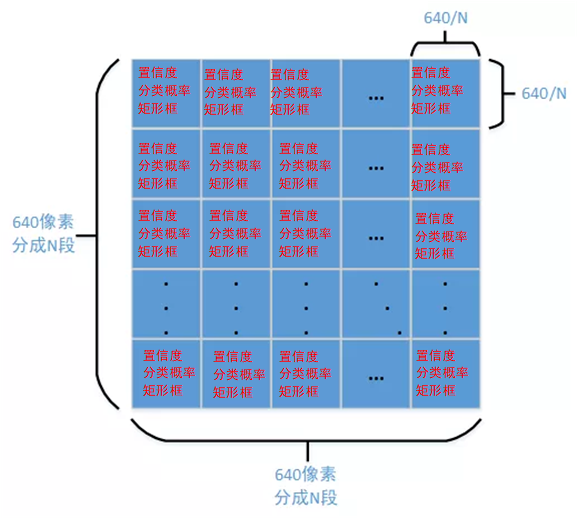
损失函数的作用为度量神经网络预测信息与期望信息(标签)的距离,预测信息越接近期望信息,损失函数值越小。由上述每个格子的预测信息可知,训练时主要包含三个方面的损失:矩形框损失(lossrect)、置信度损失(lossobj)、分类损失(lossclc)。因此yolov5网络的损失函数定义为:
Loss=a*lossobj + b*lossrect + c*lossclc
也即总体损失为三个损失的加权和,通常置信度损失取最大权重,矩形框损失和分类损失的权重次之,比如:
a = 0.4
b = 0.3
c = 0.3
yolov5使用CIOU loss计算矩形框损失,置信度损失与分类损失都用BCE loss计算,下面我们会详细介绍各种损失函数的计算原理。
03
mask掩码矩阵
下面我们以80*80网格为例来说明mask掩码的定义、用途,以及如何获取。40*40网格与20*20网格也类似。
什么是mask掩码?
神经网络对一张图像分割成的80*80网格预测了3*80*80个预测框,那么每个预测框都存在检测目标吗?显然不是。所以在训练时首先需要根据标签作初步判断,哪些预测框里面很可能存在目标?mask掩码为这样的一个3*80*80的bool型矩阵:3*80*80个bool值与3*80*80个预测框一一对应,根据标签信息和一定规则判断每个预测框内是否存在目标,如果存在则将mask矩阵中对应位置的值设置为true,否则设置为false。
mask掩码有什么用?
神经网络对80*80网格的每个格子都预测三个矩形框,因此输出了3*80*80个预测框,每个预测框的预测信息包括矩形框信息、置信度、分类概率。实际上,并非所有预测框都需要计算所有类别的损失函数值,而是根据mask矩阵来决定:
-
仅mask矩阵中对应位置为true的预测框,需要计算矩形框损失;
-
仅mask矩阵中对应位置为true的预测框,需要计算分类损失;
-
所有预测框都需要计算置信度损失,但是mask为true的预测框与mask为false的预测框的置信度标签值不一样。
对于80*80网格,其各类损失函数的计算表达式如下,其中a为mask为true时置信度损失的权重,通常取值0.5~1之间,使得网络在训练时更加专注于mask为true的情况。
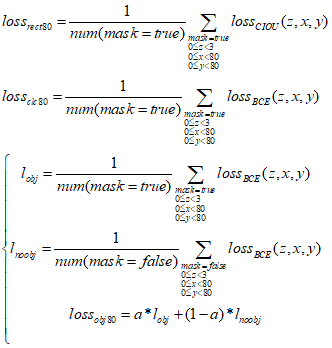
40*40网格和20*20网格的损失函数计算与80*80网格类似,最后把所有网格的损失函数值作加权和,即得到一张训练图像的最后的损失函数值:
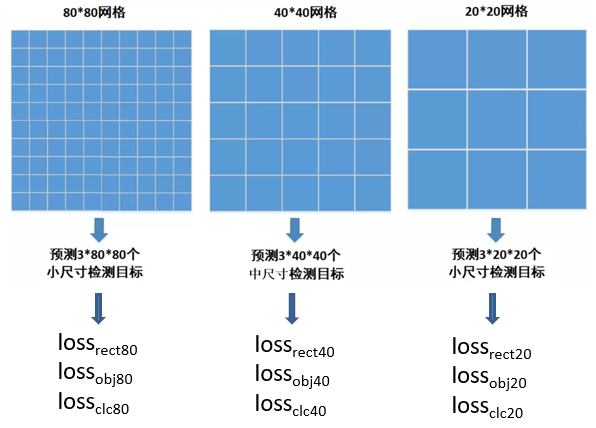
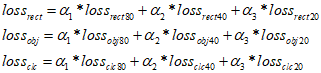
上式中α1、α2、α3为各网格损失函数值的权重系数。考虑到图像中往往小型目标比较多,中型目标次之,大型目标最少,因此通常把80*80网格的权重α1设置最大,40*40网格的权重α2次之,20*20网格的权重α3最小,使得训练时网络更加专注于数量多的目标,比如α1、α2、α3依次取0.5、0.3、0.2。
怎么得到mask掩码?
下面我们详细说明一下mask矩阵是怎么得到的。
首先将3*80*80的mask矩阵全部设置为false。对于COCO数据集json标签文件中标注的一张图像中的每个目标框,都按照以下步骤作判断,并根据判断结果将mask矩阵的对应位置设置为true:
(1)从json标签文件解析出单张图像中所有目标框的中心坐标和宽高,以及图像的宽高。假设解析得到一个目标框的中心坐标为(x, y),宽、高分别为w、h,图像的宽高分别为wi、hi。需要将(x, y)转换为640*640图像的坐标(x', y'),并将w、h转换为640*640图像中目标框的宽高wgt、hgt。
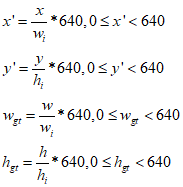
(2)然后由(x', y')计算该目标框在80*80网格中的网格坐标(xg,yg),注意xg,、yg都是浮点数。
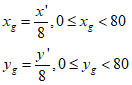
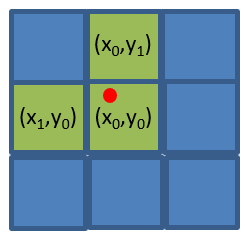
(3)接着对xg、yg向下取整,得到整型网格坐标(x0, y0)。同时为了加快训练的收敛速度,yolov5对网格(x0, y0)的左右、上下再各取一个邻近的网格:(x1, y0)和(x0, y1)。具体怎么取呢?如下图,红点为点(xg,yg):
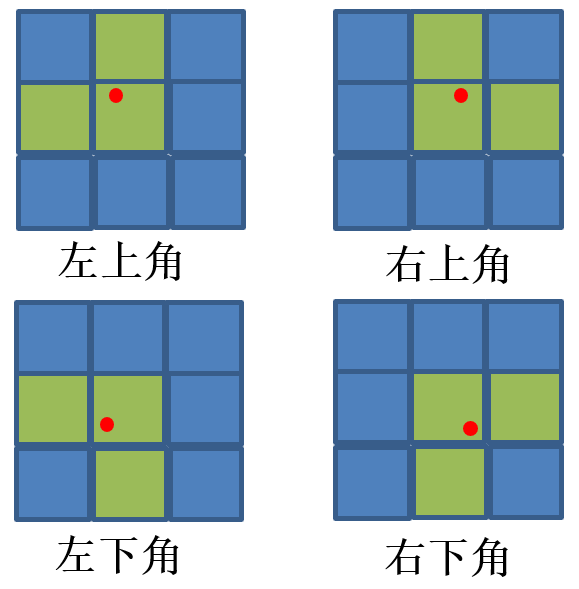
-
如果点(xg,yg)在格子的左上角,则取左边、上方的两个格子;
-
如果点(xg,yg)在格子的右上角,则取右边、上方的两个格子;
-
如果点(xg,yg)在格子的左下角,则取左边、下方的两个格子;
-
如果点(xg,yg)在格子的右下角,则取右边、上下方的两个格子;
根据以上原则,x1和y1可按下式计算,其中round为四舍五入运算:
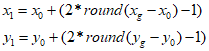
(4)经过第(3)步,得到三个互相邻近的格子(x0, y0)、(x1, y0)、(x0, y1),我们认为该目标框位于这三个格子的附近。
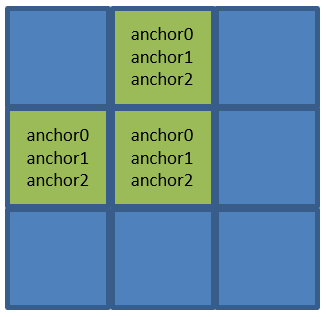
前文我们讲使用Kmeans聚类算法获取九个anchor框的时候,就讲过:
-
宽、高最小的anchor0、anchor1、anchor2分配给80*80网格的每个格子;
-
宽、高次小的anchor3、anchor4、anchor5分配给40*40网格的每个格子;
-
宽、高最大的anchor6、anchor7、anchor8分配给20*20网格的每个格子。
因此80*80网格中(x0, y0)、(x1, y0)、(x0, y1)这三个格子都对应anchor0、anchor1、anchor2这三个anchor框。
(5)假设anchor0、anchor1、anchor2这三个anchor框的宽高分别为(w0, h0)、(w1, h1)、(w2, h2),从json标签文件解析得到该目标框的宽高为(wgt, hgt),然后分别计算(wgt, hgt)与(w0, h0)、(w1, h1)、(w2, h2)的比例,再根据比例剔除不满足要求的anchor框:

将保留的anchor框标记为true,剔除的anchor框标记为false,那么anchor0、anchor1、anchor2对应的标记为(m0, m1, m2):
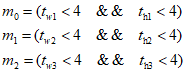
(6)根据80*80网格中(x0, y0)、(x1, y0)、(x0, y1)这三个坐标位置,我们分别对mask矩阵赋值:
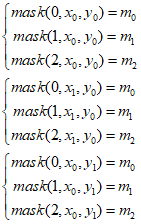
对一张图像中的所有目标框,都作以上判断并对mask矩阵赋值,即可得到该图像的mask矩阵。
04
矩形框损失计算原理
这里为什么先讲矩形框损失呢?因为后面讲的置信度损失原理会使用到矩形框损失。
我们前文讲过,yolov5对每个格子预测3个不同位置和大小的矩形框,其中每个矩形框的信息为矩形中心的x坐标、y坐标,以及矩形宽、高。假设对某个格子预测的矩形框为(xp, yp, wp, hp),该格子对应的目标矩形框为(xl, yl, wl, hl),下面依次讲解几种最常见的矩形框损失函数的计算原理。
-
L1、L2、smooth L1损失函数
首先是L1损失函数:
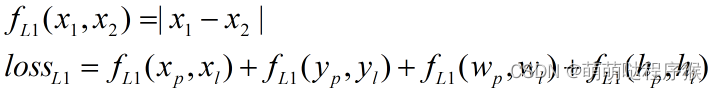
其次是L2损失函数:
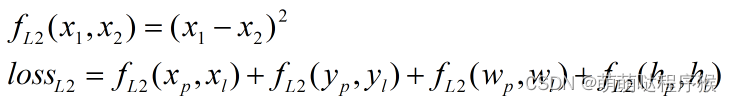
接着是smooth L1损失函数:
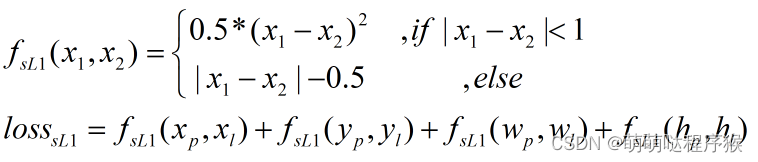
以上式子中,记d=x1-x2,分别画出fL1(d)、fL2(d)、fsL1(d)的曲线如下图:
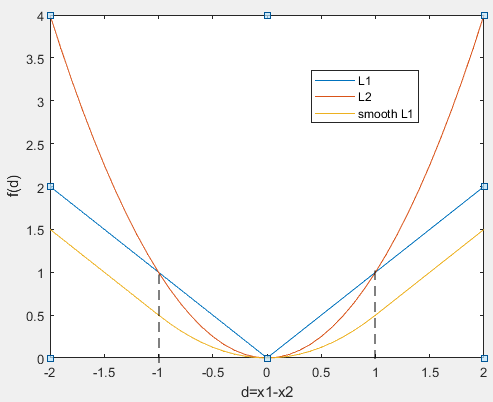
由以上计算公式和曲线可以看出:
(1)fL1(d)函数的左右两侧曲线对于d的导数(斜率)是恒定不变的,但是在d=0处该函数不可导,然而随着训练的进行,d=x1-x2会逐渐接近0,这就导致在训练后期损失函数的值在某个值附近波动,很难收敛。
(2)fL2(d)函数在d=0出处是可导的,不存在fL1(d)函数的问题,但是在前期训练阶段d很大的时候,fL2(d)函数对于d的导数也会很大,这很可能会导致梯度爆炸问题,从而训练没能朝着最优化的方向进行。
(3)fsL1(d)函数为分段函数,它将fL1(d)函数、fL2(d)函数的优点结合起来,同时完美规避了fL1(d)函数、fL2(d)函数的缺点。
-
IOU系列损失函数
上述计算矩形框的L1、L2、smooth L1损失时有一个共同点,都是分别计算矩形框中心点x坐标、中心点y坐标、宽、高的损失,最后再将四个损失值相加得到该矩形框的最终损失值。这种计算方法的前提假设是中心点x坐标、中心点y坐标、宽、高这四个值是相互独立的,实际上它们具有相关性,所以该计算方法存在问题。
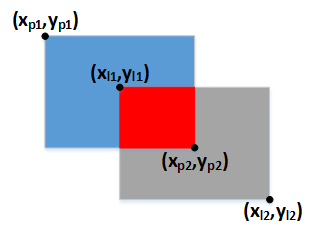
于是,IOU系列损失函数(IOU、GIOU、DIOU、CIOU)又被陆续提了出来。计算IOU系列损失函数需要使用矩形框左上角、右下角的坐标,假设预测矩形框的左上角、右下角坐标分别为(xp1, yp1)、(xp2, yp2),标签矩形框的左上角、右下角坐标分别为(xl1, yl1)、(xl2, yl2),如下图所示:
矩形框的中心坐标、宽、高可根据下式转换到左上角、右下角坐标:
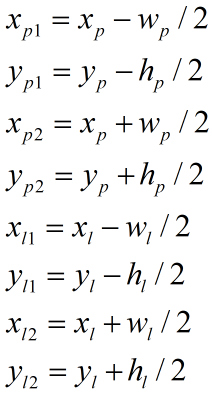
下面分别介绍IOU、GIOU、DIOU、CIOU损失函数的计算原理。
(1)IOU loss
IOU为两个方框相交区域面积与相并部分面积的比值,所以也称为交并比。
首先求相交部分面积:
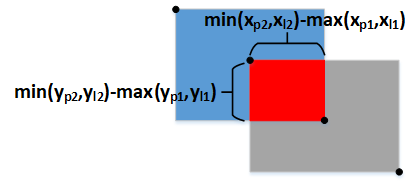
![]()
然后求相并部面积:
![]()
从而得到交并比IOU:
![]()
IOU的取值范围为0~1,当两个矩形框完全没有交集时,IOU为0,当它们完全重合时IOU为1,也即重合度越小IOU越接近0,重合度越大IOU越接近1。
最后得到IOU loss的计算公式如下,两个矩形框重合度越高IOU loss越接近0:
![]()
(2)GIOU loss
当两个矩形框完全没有重叠区域时,无论它们距离多远,它们的IOU都为0。这种情况下梯度也为0,导致无法优化。为了解决这个问题,GIOU又被提了出来。
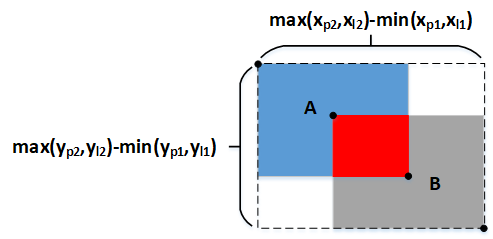
如上图所示,GIOU在IOU的基础上,把包围矩形框A和矩形框B的最小矩形框(图中的虚线框)的面积也加入到计算中。
GIOU可按下式计算,其中S1为A、B相交部分的面积(红色区域)。其中S3为包围A、B的最小矩形框的面积,S2为A、B相并区域的面积(蓝色+红色+灰色区域)。
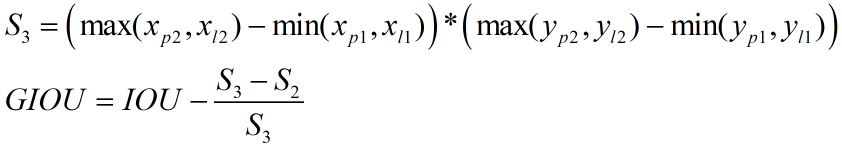
由上式可知GIOU相比IOU,新增了(S3-S2)/S3这一项。新增项表示什么意义呢?由上述可知S3-S2为虚线框中白色区域的面积,也即虚线框中不属于A也不属于B的空白区域,那么(S3-S2)/S3就是空白区域面积占虚线框面积的比例,这个比例越大说明A、B距离越远、重叠度越小,反之则A、B距离越近、重叠度越大。
GIOU的取值范围是-1~1,当A、B完全没有重叠区域时IOU为0,那么GIOU取负值,极端情况,当A、B无重叠区域且距离无限远时,此时(S3-S2)/S3等于1,那么GIOU取-1;另一个极端情况,当A、B完全重叠时(S3-S2)/S3等于0,IOU为1,那么GIOU取1。
因此,GIOU解决了当A、B完全没有重叠区域时IOU恒为0的问题。
最后得到GIOU loss的计算公式:
![]()
(3)DIOU loss
GIOU虽然把IOU的问题解决了,但它还是基于面积的度量,并没有把两个矩形框A、B的距离考虑进去。为了使训练更稳定、收敛更快,DIOU随之被提了出来,DIOU把矩形框A、B的中心点距离ρ、外接矩形框(虚线框)的对角线长度c都直接考虑进去,如下图所示:
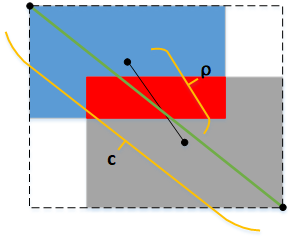
DIOU可按下式计算:
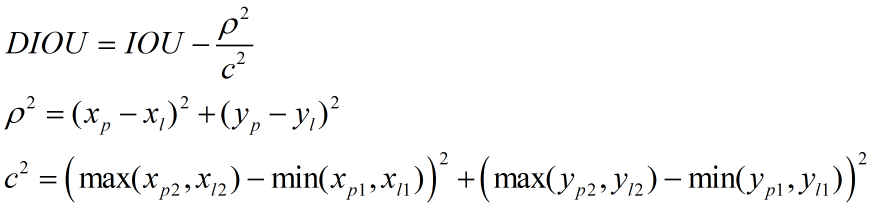
由上式可知DIOU的取值范围也为-1~1,当两个框A、B完全重合时DIOU取1,当A、B距离无限远时,DIOU取-1。
从而得到DIOU loss的计算公式:
![]()
(4)CIOU loss
yolov5使用CIOU loss来衡量矩形框的损失。
DIOU把两个矩形框A、B的重叠面积、中心点距离都考虑了进去,但并未考虑A、B的宽高比。为了进一步提升训练的稳定性和收敛速度,在DIOU的基础上CIOU又被提了出来,它将重叠面积、中心点距离、宽高比同时加入了计算。
CIOU可按下式计算:

上式中,ρ为框A和框B的中心点距离,c为框A和框B的最小包围矩形的对角线长度,v为框A、框B的宽高比相似度,α为v的影响因子。
反正切arctan函数的取值范围是0~Π/2,那么v的取值范围为0~1,当框A、框B的的宽高比相等时v取0,当框A、框B的的宽高比相差无限大时v取1。
当框A、框B的距离无限远,且宽高比差别无限大时DIOU取-1,v取1,alpha取0.5,此时CIOU取-1-0.5=-1.5;当框A、框B完全重叠时,DIOU取1,v取0,α取0,则CIOU取1。因此CIOU取值范围是-1.5~1。
IOU越大也即A、B的重叠区域越大,则α越大,从而v的影响越大;反之IOU越小也即A、B的重叠区域越小,则α越小,从而v的影响越小。因此在优化过程中:
-
如果A、B的重叠区域较小,则宽高比v在损失函数中影响较小,此时着重优化A、B的距离;
-
如果A、B的重叠区域较大,则宽高比v在损失函数中影响也较大,此时着重优化A、B的宽高比。
用一句话来说,就是越缺什么,就越着重弥补什么,从而达到加速优化训练的收敛速度和稳定性的目的。
由以上可得CIOU loss的计算公式为:
![]()
05
置信度损失计算原理
下面以80*80网格为例,详细讲置信度损失的计算原理,40*40和20*20网格的置信度损失计算原理与80*80网格一样,可依此类推。
-
神经网络预测的置信度
对于一张图像分割成的80*80的网格,神经网络对其中每个格子都预测三个位于该格子附近的矩形框(简称预测框),每个预测框的预测信息包括中心坐标、宽、高、置信度、分类概率,因此神经网络总共输出3*80*80个0~1的预测置信度,与3*80*80个预测框一 一对应。每个预测框的置信度表征这个预测框的靠谱程度,值越大表示该预测框越可信靠谱,也即越接近目标的真实最小包围框。
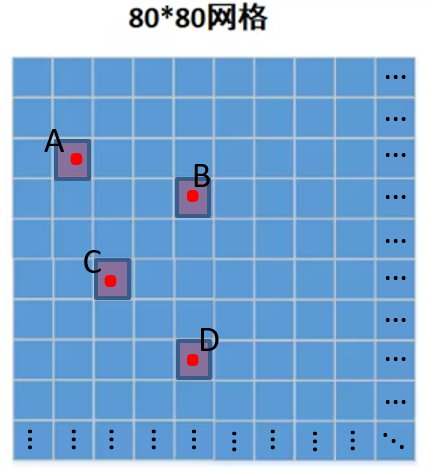
比如下图中,红点A、B、C、D表示检测目标,那么每个红点所在格子的三个预测置信度应该比较大甚至接近1,而其它格子的预测置信度应该较小甚至接近0。
-
置信度的标签
标签的维度应该与神经网络的输出维度保持一致,因此置信度的标签也是维度为3*80*80的矩阵。
这里就用到了上文我们讲的mask掩码矩阵:以维度同样为3*80*80的mask矩阵为标记,对置信度标签矩阵进行赋值。yolo之前版本直接对mask矩阵为true的地方赋值1,mask矩阵为false的地方赋值0,认为只要mask为true就表示对应预测框完美包围了目标。这样做就太绝对了,因为mask为true只是表示该预测框在目标附近而已,并不一定完美包围了目标。所以yolov5改变了做法:对mask为true的位置不直接赋1,而是计算对应预测框与目标框的CIOU,使用CIOU作为该预测框的置信度标签,当然对mask为false的位置还是直接赋0。
这样一来,标签值的大小与预测框、目标框的重合度有关,两框重合度越高则标签值越大。当然,上文我们讲CIOU的取值范围是-1.5~1,而置信度标签的取值范围是0~1,所以需要对CIOU做一个截断处理:当CIOU小于0时直接取0值作为标签。
-
BCE loss损失函数
假设置信度标签为矩阵L,预测置信度为矩阵P,那么矩阵中每个数值的BCE loss的计算公式如下:
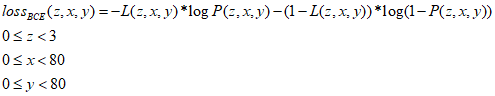
注意BCE loss要求输入数据的取值范围必须在0~1之间。
从得到80*80网格的置信度损失值:
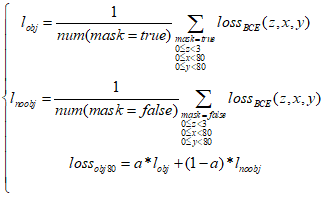
此外,我们称对应mask位true的预测框为正样本,对应mask为false的预测框为负样本,负样本肯定是远远多于正样本的,为了使训练更专注于正样本,后来Focal loss又被提了出来,我们在此暂时不细说,下篇文章再详细介绍吧。
06
分类损失计算原理
下面也以80*80网格为例,详细讲分类损失的计算原理,40*40和20*20网格的分类损失计算原理与80*80网格一样,可依此类推。
神经网络对80*80网格的每个格子都预测三个预测框,每个预测框的预测信息都包含了N个分类概率。其中N为总类别数,比如COCO数据集有80个类别,那么N取80。所以对于COCO数据集,每个预测框有80个0~1的分类概率,那么神经网络总共预测3*80*80*80个分类概率,组成预测概率矩阵。
80*80网格的标签概率矩阵与预测概率矩阵的维度一样,也是3*80*80*80。每个预测框的标签,由解析json标签文件得到,是一个0~79的数值,需要将0~79的数值转换成80个数的独热码:

然而,为了减少过拟合,且增加训练的稳定性,通常对独热码标签做一个平滑操作。如下式,label为独热码中的所有数值,α为平滑系数,取值范围0~1,通常取0.1。
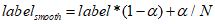
同样假设置标签概率为矩阵Lsmooth,预测概率为矩阵P,那么矩阵中每个数值的BCE loss的计算公式如下:
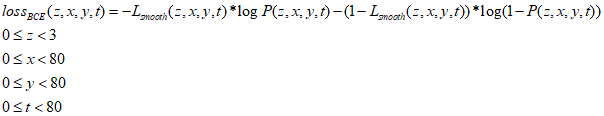
于是得到80*80网格的分类损失函数值的计算公式:
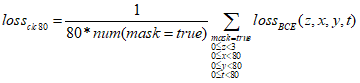
07
结语
好了,本文我们就讲到这里。说点题外话,隔了两三个月没有更新文章了,感觉很对不起粉丝们。因为本人在年底不仅换了工作,工作城市也换了,免不了一番奔波与适应,所以更新就被耽搁了。不过呢,我还是会在业余抽时间来学习、更新,不辜负粉丝们对我的期望~祝朋友们新年快乐,事事顺心(迟来的祝福^^)!
欢迎关注"萌萌哒程序猴"微信公众号,接下来会不定时更新更加精彩的内容,敬请期待~
文章出处登录后可见!