


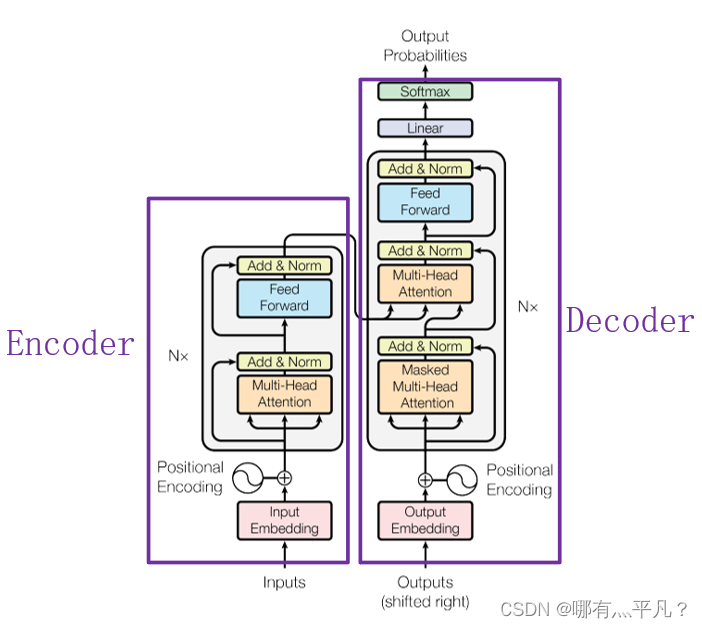
Transformer是什么呢?




self attention
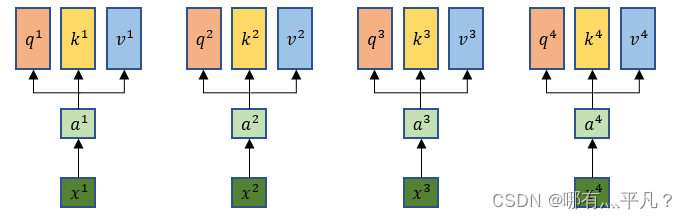

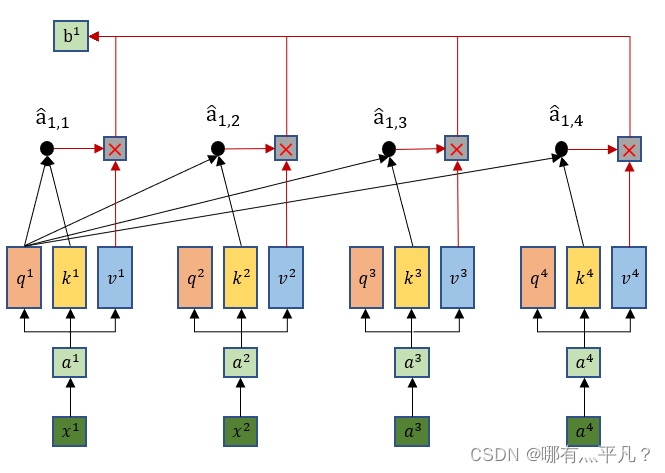

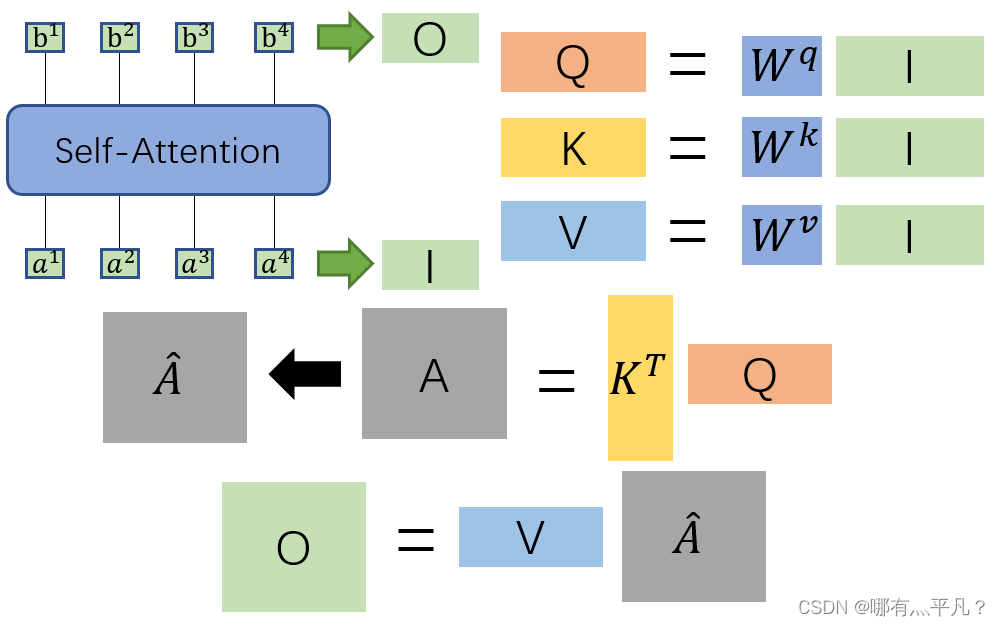
那么self attention是这么做平行化的呢?
咱们复习一下前面说到的q、k、v的计算:
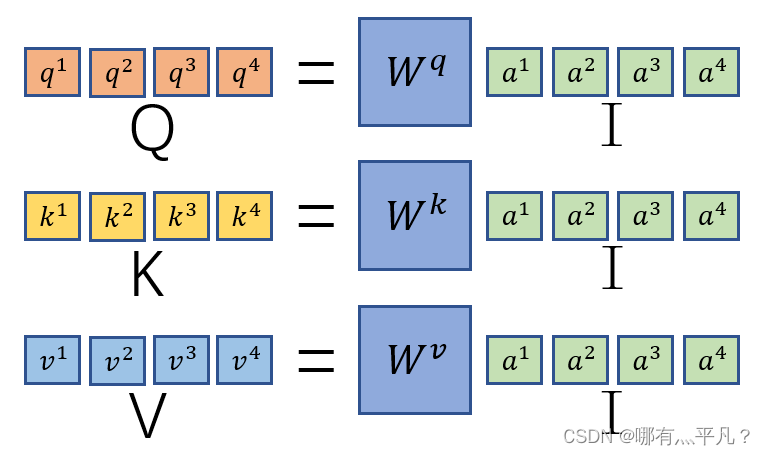

然后我们再回忆观察一下
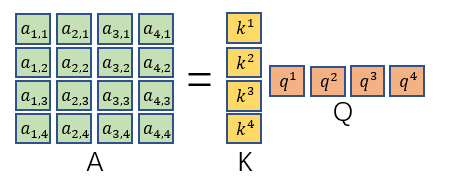

最后再把
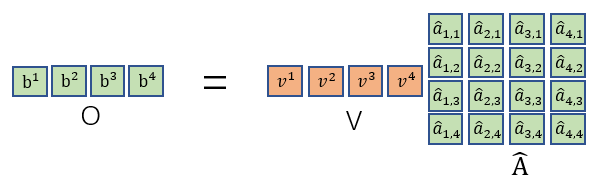


self-attention的变形——Multi-head Self-attention
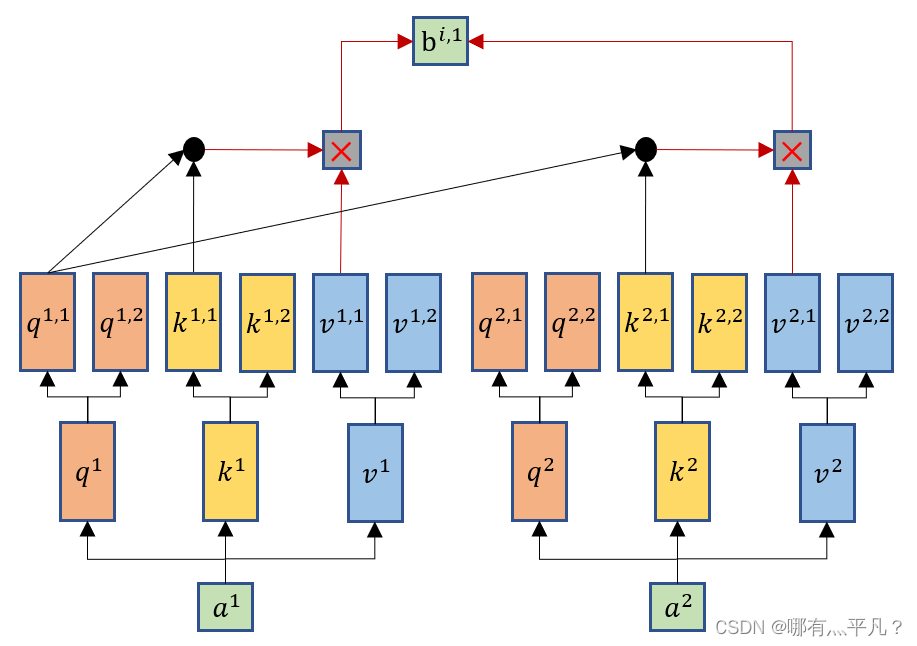

那么这个Multi-head Self-attention设置多个q,k,v有什么好处呢?
Positional Encoding


文章出处登录后可见!