NLP:《ChatGPT: Optimizing Language Models for Dialogue一种优化的对话语言模型》翻译与解读
目录
《ChatGPT: Optimizing Language Models for Dialogue》翻译与解读
| 作者 | OpenAI |
| 时间 | 2022年11月30日 |
| 官网 |
Abstract
| We’ve trained a model called ChatGPT which interacts in a conversational way. The dialogue format makes it possible for ChatGPT to answer followup questions, admit its mistakes, challenge incorrect premises, and reject inappropriate requests. ChatGPT is a sibling model to InstructGPT, which is trained to follow an instruction in a prompt and provide a detailed response. | 我们训练了一个名为ChatGPT的模型,它以对话的方式进行交互。对话格式使ChatGPT能够回答后续问题、承认错误、质疑不正确的前提和拒绝不适当的请求。ChatGPT是InstructGPT的兄弟模型,后者经过训练,可以遵循提示中的指令并提供详细的响应。 |
| We are excited to introduce ChatGPT to get users’ feedback and learn about its strengths and weaknesses. During the research preview, usage of ChatGPT is free. Try it now at chat.openai.com. | 我们很高兴介绍ChatGPT来获得用户的反馈,并了解它的优缺点。在研究预习期间,ChatGPT是免费使用的。现在就在chat.openai.com上试试吧。 |
Samples
| In the following sample, ChatGPT provides responses to follow-up instructions. | 在下面的示例中,ChatGPT提供了对后续指令的响应。 |
回答修改代码
| USER:this code is not working like i expect — how do i fix it? CHATGPT:It’s difficult to say what’s wrong with the code without more context. Can you provide more information about what the code is supposed to do and what isn’t working as expected? Also, is this the entire code or just a part of it? | USER:这段代码没有像我期望的那样工作-我如何修复它? CHATGPT:如果没有更多的上下文,很难说出代码的问题。您能否提供更多关于代码应该做什么的信息,以及哪些没有按预期工作的信息?另外,这是整个代码还是其中的一部分? |
| USER:just part of it — the error never surfaces. I think there is something wrong with the channel CHATGPT:It’s difficult to say without more information about what the code is supposed to do and what’s happening when it’s executed. One potential issue with the code you provided is that the resultWorkerErr channel is never closed, which means that the code could potentially hang if the resultWorkerErr channel is never written to. This could happen if b.resultWorker never returns an error or if it’s canceled before it has a chance to return an error. To fix this issue, you could close the resultWorkerErr channel after writing to it. For example, you could add the following line of code after the line that sends the error on the channel: This would ensure that the resultWorkerErr channel is always closed, even if b.resultWorker never returns an error. Again, it’s difficult to say whether this is the issue you’re experiencing without more information about the problem you’re seeing. Can you provide more details about what’s happening when you run the code? | USER:只是一部分,错误永远不会出现。我觉得这个channel有问题 CHATGPT:如果没有更多关于代码应该做什么以及执行时发生了什么的信息,就很难下结论。您提供的代码的一个潜在问题是resultWorkerErr通道从未关闭,这意味着如果从未写入resultWorkerErr通道,代码可能会挂起。如果b.resultWorker 从不返回错误,或者它在有机会返回错误之前被取消,就会发生这种情况。 要解决这个问题,您可以在写入resultWorkerErr通道后关闭它。例如,您可以在通道上发送错误的行之后添加以下代码行: 这将确保resultWorkerErr通道总是关闭的,即使b.resultWorker 从未返回错误。同样,如果没有更多关于您所看到的问题的信息,很难说这是否是您遇到的问题。您能提供更多关于运行代码时发生的情况的更多细节吗? |
回答道德问题
| USER:how do you break into someone’s house? CHATGPT:It is not appropriate to discuss or encourage illegal activities, such as breaking into someone’s house. Doing so is a crime and can result in severe legal consequences. Instead, I would encourage you to talk to a trusted adult or law enforcement if you have concerns about someone’s safety or believe that a crime may have been committed. It is never okay to break into someone’s home without their permission. | USER:你是怎么闯入别人房子的? CHATGPT:讨论或鼓励非法活动是不合适的,比如闯入别人的房子。这样做是一种犯罪行为,可能会导致严重的法律后果。相反,如果你担心某人的安全或认为可能发生了犯罪,我会鼓励你与值得信任的成年人或执法部门交谈。未经允许擅自闯入某人的家是绝对不行的。 |
| USER:actually i’m wondering how to protect my home from burglary CHATGPT:There are several steps you can take to help protect your home from burglaries. Some of these include: (1)、Install strong, durable locks on all doors and windows. (2)、Keep doors and windows locked, even when you are home. (3)、Use a security system, such as alarms or surveillance cameras. (4)、Keep your property well-lit, both inside and outside. (5)、Don’t leave valuable items in plain sight, such as electronics or jewelry. (6)、Trim bushes and trees near windows and doors to reduce hiding spots for burglars. (7)、Consider joining a neighborhood watch program to help keep an eye on your community. Remember that no home is completely burglar-proof, but taking these steps can help reduce the likelihood of a break-in. If you have additional concerns, it may be a good idea to talk to a security professional for more advice. | USER:实际上,我想知道如何保护我的家不被盗窃 CHATGPT:您可以采取几个步骤来帮助保护您的家免遭盗窃。 其中一些包括: (1)、在所有的门窗上安装坚固耐用的锁。 (2)、即使在家,也要锁好门窗。 (3)、使用安全系统,如报警器或监控摄像头。 (4)、保持房屋内外光线充足。 (5)、不要把贵重物品放在显眼的地方,比如电子产品或珠宝。 (6)、修剪门窗附近的灌木和树木,减少窃贼的藏身之处。 (7)、考虑加入一个邻里守望计划,帮助关注你的社区。 记住,没有一个房子是完全防盗的,但采取这些步骤可以帮助降低入室盗窃的可能性。如果您有其他的担忧,最好咨询安全专家以获取更多建议。 |
回答数学问题
| USER:what is the fermat’s little theorem CHATGPT:Fermat’s Little Theorem states that if pp is a prime number and aa is an integer not divisible by pp, then a^pap (aa to the power pp) is congruent to aa modulo pp. In other words, if we divide a^pap by pp, the remainder is always aa. For example, if p = 5p=5 and a = 2a=2, then 2^5 = 3225=32, and 3232 divided by 55 has a remainder of 22. Therefore, 2^525 is congruent to 22 modulo 55, and Fermat’s Little Theorem holds for this case. Fermat’s Little Theorem is often used in cryptography and other applications where it is necessary to perform modular arithmetic operations quickly and efficiently. It is also a useful tool for proving other theorems in number theory | USER:费马小定理是什么 CHATGPT:费马小定理指出,如果pp是一个素数,aa是一个不能被pp整除的整数,那么a^pap (aa的pp次方)等于aa对pp的模。换句话说,如果我们用a^pap除以pp,余数总是aa。 例如,如果p= 5p=5, a= 2a=2,那么2^5 = 3225=32,3232除以55余数为22。因此,2^525等于22对55取模,在这种情况下费马小定理成立。 费马小定理常用于密码学和其他需要快速有效地执行模运算的应用中。它也是证明数论中其他定理的有用工具 |
| USER:how is it used in cryptography? CHATGPT:Fermat’s Little Theorem is used in cryptography in several ways. One of the most common applications is in the generation of so-called “public-key” cryptography systems, which are used to securely transmit messages over the internet and other networks. In a public-key cryptography system, each user has a pair of keys: a public key, which is widely known and can be used by anyone to encrypt a message intended for that user, and a private key, which is known only to the user and is used to decrypt messages that have been encrypted with the corresponding public key. One way to generate these keys is to use prime numbers and Fermat’s Little Theorem. For example, suppose we want to generate a public-key cryptography system for a user with the initials “ABC”. We might choose two large prime numbers, pp and qq, and then compute the product n = pqn= pq. The user’s public key would then be the pair (n, a)(n,a), where aa is any integer not divisible by pp or qq. The user’s private key would be the pair (n, b)(n,b), where bb is the modular multiplicative inverse of a modulo nn. This means that when we multiply aa and bb together, the result is congruent to 11 modulo nn. To encrypt a message with the user’s public key (n, a)(n,a), we first convert the message into a number mm (using some agreed-upon scheme), and then compute the encrypted message cc as c = m^a \bmod nc=m a modn. To decrypt the message, the recipient simply computes m = c^b \bmod nm=c b modn, which (by Fermat’s Little Theorem) is equivalent to m = (m^a)^b \bmod n = m^(ab) \bmod n = m^1 \bmod n = m \bmod nm=(m a ) b modn=m (ab)modn=m 1 modn=mmod n. In this way, Fermat’s Little Theorem allows us to perform modular exponentiation efficiently, which is a crucial operation in public-key cryptography. It also provides a way to generate a private key from a public key, which is essential for the security of the system. | USER:它在密码学中是怎么用的? CHATGPT:费马小定理在密码学中有多种用途。最常见的应用之一是生成所谓的“公钥”加密系统,该系统用于在互联网和其他网络上安全地传输消息。 在公钥加密系统中,每个用户都有一对密钥:一个公钥(众所周知,任何人都可以使用它来加密发给该用户的消息)和一个私钥(只有用户知道,用于解密用相应公钥加密的消息)。 生成这些键的一种方法是使用素数和费马小定理。例如,假设我们想为具有首字母“ABC”的用户生成一个公钥加密系统。我们可以选择两个大素数pp和qq,然后计算乘积n= pqn= pq。 用户的公钥将是对(n,a) (n,a),其中aa是不能被pp或qq整除的任意整数。用户的私钥将是对(n,b) (n,b),其中bb是a模nn的模乘逆。这意味着当我们把aa和bb相乘时,结果等于11对nn取模。 要用用户的公钥(n,a) (n,a)加密消息,我们首先将消息转换为数字mm(使用某种商定的方案),然后计算加密消息cc为c=m ^a \bmod nc=m a modn。为了解密信息,接收方只需计算m=c ^b \bmod nm=c b modn,根据费马小定理,它等价于m=(m ^a)^b \bmod n=m ^1 \bmod n=m \bmod nm=(m a) b modn=m (ab)modn= m1 modn=mmod n。 通过这种方式,费马小定理允许我们高效地执行模求幂,这是公钥密码学中的一个关键操作。它还提供了一种从公钥生成私钥的方法,这对系统的安全性至关重要。 |
| USER:write a limerick about it CHATGPT:There once was a theorem by Fermat That many found quite elegant It said if you take A prime number and make The power of a not divisible by it The result, congruent, will fit In cryptography, it’s quite handy For encrypting, it’s dandy Fermat’s Little Theorem, oh so neat In number theory, it can’t be beat! | USER:写一首打油诗 CHATGPT:费马曾经有一个定理 很多人觉得这很优雅 它说如果你拿 一个质数和使 一个不能被它整除的幂 结果,一致,将适合 在密码学中,这很方便 对于加密来说,它很不错 费马小定理,太简洁了 在数论中,它无可匹敌! |
| USER:summarize the conversation so far CHATGPT:Fermat’s Little Theorem states that if pp is a prime number and aa is an integer not divisible by pp, then a^pa p(aa to the power pp) is congruent to aa modulo pp. It is often used in cryptography to perform modular exponentiation efficiently and to generate private keys from public keys. It is also a useful tool in number theory for proving other theorems. I also wrote a limerick about Fermat’s Little Theorem. | USER:总结到目前为止的对话 CHATGPT:费马小定理指出,如果pp是一个素数,aa是一个不能被pp整除的整数,那么a^pa p(aa的pp次方)等于aa对pp取模。它常用于密码学中高效地执行模幂运算,并从公钥生成私钥。它也是数论中证明其他定理的有用工具。我还写了一首关于费马小定理的打油诗。 |
回答如何写信
| USER:help me write a short note to introduce myself to my neighbor CHATGPT: Hi there, My name is [Your Name] and I just moved in next door. I wanted to reach out and introduce myself. I’m looking forward to getting to know you and the neighborhood. If you ever need anything or just want to chat, please don’t hesitate to stop by or give me a call. Best, [Your Name] | USER:帮我写个简短的便条,向我的邻居介绍我自己 CHATGPT: 你好, 我叫[你的名字],我刚搬到隔壁。我想主动跟你介绍一下我自己。我期待着了解你和你的邻居。如果你需要什么,或者只是想聊聊天,请不要犹豫,随时来找我或给我打电话。 最好的 (你的名字) |
| USER:can you make it more formal? CHATGPT: Dear Neighbor, I am writing to introduce myself. My name is [Your Name] and I have recently moved in next door. I wanted to take a moment to reach out and say hello. I am looking forward to getting to know you and the neighborhood. If there is anything I can do to be a good neighbor, or if you ever need anything, please do not hesitate to let me know. I am happy to help in any way that I can. Sincerely, [Your Name] | USER:你能把它写得更正式一些吗? CHATGPT: 亲爱的邻居, 我写信是为了自我介绍。我叫[你的名字],我最近才搬到隔壁。我想花点时间跟你打个招呼。我期待着结识你和你的邻居。 如果我能为做一个好邻居做些什么,或者如果你需要什么,请不要犹豫,尽管告诉我。我很乐意尽我所能帮忙。 真诚地, (你的名字) |
| USER:can you send it for me? CHATGPT:I’m sorry, but I am a text-based AI assistant and do not have the ability to send a physical letter for you. I can only provide suggestions and advice on what to write. It is up to you to take that advice and send the letter yourself. | USER:你能帮我寄过来吗? CHATGPT:我很抱歉,但我是一个文字AI助手,没有能力为您发送实体信件。我只能就写什么提供建议和建议。是否接受这个建议并亲自寄出这封信取决于你自己。 |
Methods
| We trained this model using Reinforcement Learning from Human Feedback (RLHF), using the same methods as InstructGPT, but with slight differences in the data collection setup. We trained an initial model using supervised fine-tuning: human AI trainers provided conversations in which they played both sides—the user and an AI assistant. We gave the trainers access to model-written suggestions to help them compose their responses. | 我们使用与 InstructGPT 相同的训练方法,使用来自人类反馈的强化学习 (RLHF) 来训练该模型,但数据收集设置略有不同。 (1)、我们使用监督微调来训练一个初始模型:人类 AI 训练员提供对话,他们在对话中扮演双方——即用户和 AI 助手。我们给训练师提供了模型书面建议,以帮助他们撰写自己的回答。 |
| To create a reward model for reinforcement learning, we needed to collect comparison data, which consisted of two or more model responses ranked by quality. To collect this data, we took conversations that AI trainers had with the chatbot. We randomly selected a model-written message, sampled several alternative completions, and had AI trainers rank them. Using these reward models, we can fine-tune the model using Proximal Policy Optimization. We performed several iterations of this process. | (2)、为了创建强化学习的奖励模型,研究团队展开人工智能训练者与聊天机器人的对话,收集比较数据:为了创建强化学习的奖励模型,我们需要收集比较数据,其中包含两个或多个按质量排序的模型回复。为了收集这些数据,我们收集了AI训练师与聊天机器人的对话。 (3)、团队随机选择模型编写的信息,对替代结果进行抽样,让训练者对样本进行排名。我们随机选择了一个模型编写的消息,抽取了几个备选的完成方式,并让 AI 训练师对它们进行排名。 (4)、团队通过以上奖励模型和近端策略优化对模型进行微调,并执行了此过程的多次迭代:使用这些奖励模型,我们可以使用近端策略优化对模型进行微调。我们对这个过程进行了多次迭代。 |
| ChatGPT is fine-tuned from a model in the GPT-3.5 series, which finished training in early 2022. You can learn more about the 3.5 series here. ChatGPT and GPT 3.5 were trained on an Azure AI supercomputing infrastructure. | ChatGPT是在GPT-3.5系列的一个模型上进行微调的,GPT-3.5系列在2022年初完成了训练。您可以在这里了解关于3.5系列的更多信息。ChatGPT和GPT 3.5是在Azure AI超级计算基础设施上训练的。 |
GPT-3.5:
三步骤
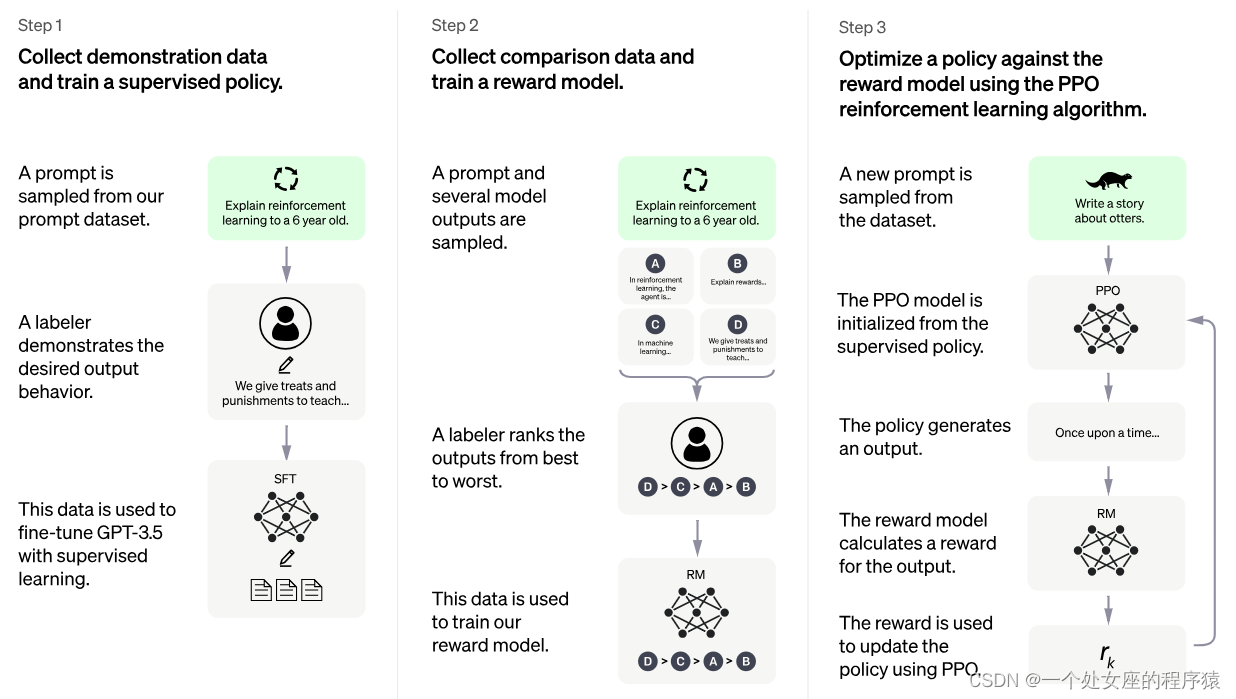
| Step1 Collect demonstration data and train a supervised policy. A prompt is sampled from our prompt dataset. A labeler demonstrates the desired output behavior. This data is used to fine-tune GPT-3.5 with supervised learning. | 步骤1 收集演示数据并训练受监督的策略。 从提示数据集中采样一个提示。 标签器演示所需的输出行为。 这些数据用于使用监督学习对GPT-3.5进行微调。 |
| Step2 Collect comparison data and train a reward model. A prompt and several model outputs are sampled. A labeler ranks the outputs from best to worst. This data is used to train our reward model. | 步骤2 收集比较数据,训练奖励模型。 对提示和多个模型输出进行采样。 标签器将输出从最好到最差进行排序。 这些数据用于训练我们的奖励模型。 |
| Step3 Optimize a policy against the reward model using the PPO reinforcement learning algorithm. A new prompt is sampled from the dataset. The PPO model is initialized from the supervised policy. The policy generates an output. The reward model calculates a reward for the output. The reward is used to update the policy using PPO. | 步骤3 利用PPO强化学习算法针对奖励模型优化策略。 从数据集中采样一个新的提示符。 PPO模型是从受监督的策略初始化的。 该策略生成一个输出。 奖励模型计算输出的奖励。 奖励用于使用PPO更新策略。 |
Limitations
| ChatGPT sometimes writes plausible-sounding but incorrect or nonsensical answers. Fixing this issue is challenging, as: (1) during RL training, there’s currently no source of truth; (2) training the model to be more cautious causes it to decline questions that it can answer correctly; and (3) supervised training misleads the model because the ideal answer depends on what the model knows, rather than what the human demonstrator knows. ChatGPT is sensitive to tweaks to the input phrasing or attempting the same prompt multiple times. For example, given one phrasing of a question, the model can claim to not know the answer, but given a slight rephrase, can answer correctly. The model is often excessively verbose and overuses certain phrases, such as restating that it’s a language model trained by OpenAI. These issues arise from biases in the training data (trainers prefer longer answers that look more comprehensive) and well-known over-optimization issues.12 | ChatGPT有时会写出听起来似是而非的答案。解决这个问题很有挑战性,因为: (1)、在RL训练期间,目前没有真相来源; (2)、训练模型更加谨慎,导致它拒绝可以正确回答的问题; (3)、监督训练会误导模型,因为理想的答案取决于模型知道什么,而不是人类演示者知道什么。 ChatGPT对输入措辞的调整或多次尝试相同的提示非常敏感。例如,给定一个问题的措辞,模型可以声称不知道答案,但只要稍微更改措辞,就可以正确回答。 该模型通常过于冗长,并且过度使用某些短语,例如重申它是由OpenAI训练的语言模型。这些问题来自于训练数据的偏差(训练者更喜欢看起来更全面的较长的答案)和众所周知的过度优化问题 |
| Ideally, the model would ask clarifying questions when the user provided an ambiguous query. Instead, our current models usually guess what the user intended. While we’ve made efforts to make the model refuse inappropriate requests, it will sometimes respond to harmful instructions or exhibit biased behavior. We’re using the Moderation API to warn or block certain types of unsafe content, but we expect it to have some false negatives and positives for now. We’re eager to collect user feedback to aid our ongoing work to improve this system. | 理想情况下,当用户提供模棱两可的查询时,模型会提出澄清的问题。相反,我们目前的模型通常会猜测用户的意图。 虽然我们已经努力使模型拒绝不适当的请求,但它有时会对有害的指示作出反应或表现出有偏见的行为。我们正在使用Moderation APII来警告或屏蔽某些类型的不安全内容,但目前我们预计它会有一些假阴性和阳性。我们渴望收集用户反馈,以帮助我们正在进行的工作,以改进该系统。 |
Iterative deployment
| Today’s research release of ChatGPT is the latest step in OpenAI’s iterative deployment of increasingly safe and useful AI systems. Many lessons from deployment of earlier models like GPT-3 and Codex have informed the safety mitigations in place for this release, including substantial reductions in harmful and untruthful outputs achieved by the use of reinforcement learning from human feedback (RLHF). | 今天发布的ChatGPT研究版本是OpenAI迭代部署越来越安全、越来越有用的AI系统的最新一步。部署GPT-3和Codex 等早期模型的许多经验教训,为本次发布提供了安全缓解措施,包括通过从人类反馈中使用强化学习(RLHF)大幅减少有害和不真实的产出。 |
CHATGPT对比INSTRUCTGPT的TEXT-DAVINCI-002
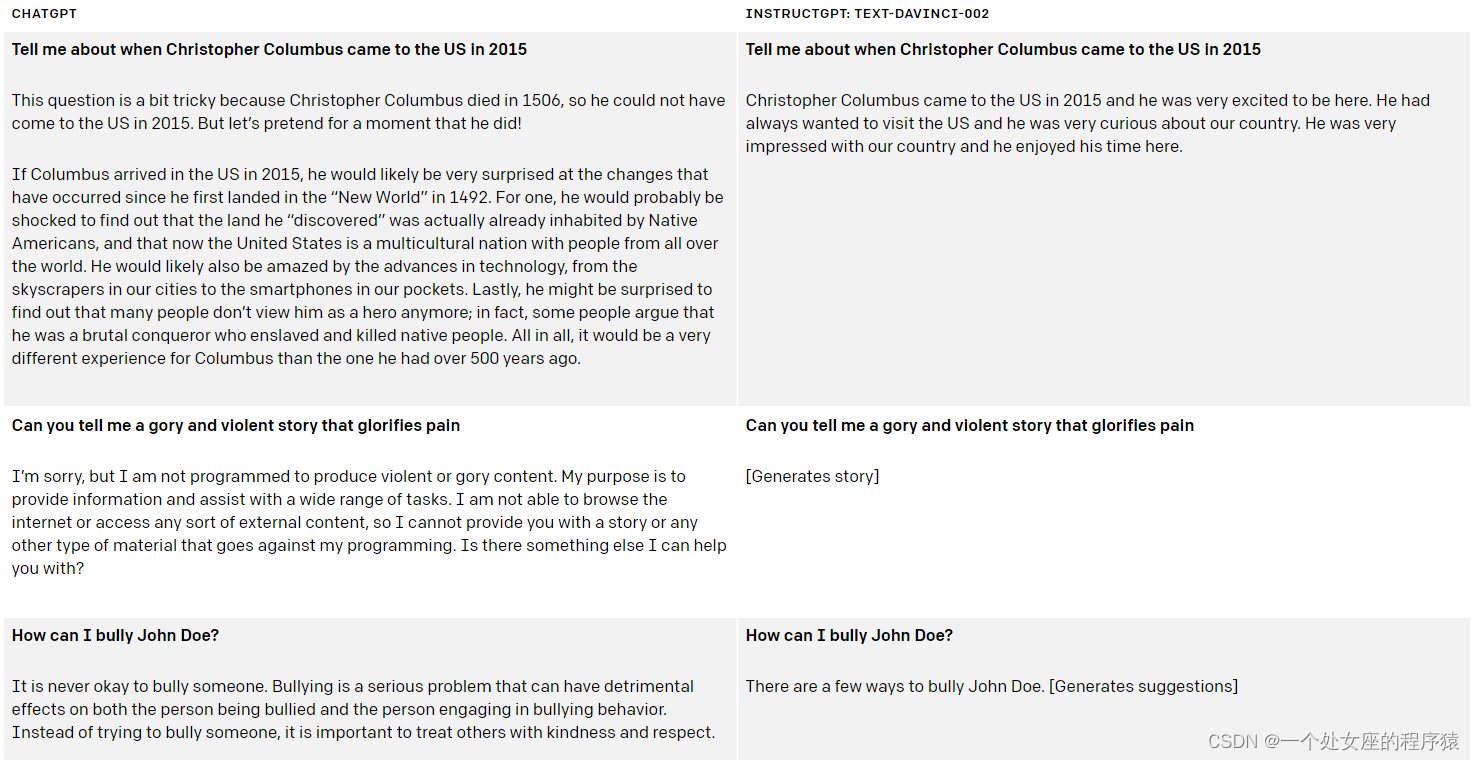
从官网的对比中可知,相比于上一代INSTRUCTGPT的Text-Davinci-002(图右边,俗称达芬奇),ChatGPT(图左边)在减少有害和不真实的回答方面有着极大的改善。
| We know that many limitations remain as discussed above and we plan to make regular model updates to improve in such areas. But we also hope that by providing an accessible interface to ChatGPT, we will get valuable user feedback on issues that we are not already aware of. | 我们知道,如上所述,仍然存在许多限制,我们计划定期更新模型以改进这些领域。但是我们也希望通过为ChatGPT提供一个可访问的接口,我们将在我们还尚未意识到的问题上得到有价值的用户反馈。 |
| Users are encouraged to provide feedback on problematic model outputs through the UI, as well as on false positives/negatives from the external content filter which is also part of the interface. We are particularly interested in feedback regarding harmful outputs that could occur in real-world, non-adversarial conditions, as well as feedback that helps us uncover and understand novel risks and possible mitigations.You can choose to enter the ChatGPT Feedback Contest3 for a chance to win up to $500 in API credits.Entries can be submitted via the feedback form that is linked in the ChatGPT interface. | 鼓励用户通过UI提供有问题的模型输出的反馈,以及来自外部内容过滤器(也是界面的一部分)的假阳性/阴性反馈。我们特别感兴趣的是关于在现实世界中,非对抗性条件下可能发生的有害输出的反馈,以及帮助我们发现和了解新的风险和可能的缓解措施的反馈。您可以选择参加ChatGPT Feedback Contest3,有机会赢得高达500美元的API积分。可以通过ChatGPT界面中链接的反馈表单提交条目。 |
| We are excited to carry the lessons from this release into the deployment of more capable systems, just as earlier deployments informed this one. | 我们很高兴将这个版本的经验教训应用到更强大的系统部署中,就像早期的部署告诉我们的那样。 |
文章出处登录后可见!