目录
前言
上一篇博客讲了计算图的加载和预处理,真是费了不少劲啊……
这一篇博客和大家一起学习PPQ精髓之一:计算图的分割与调度。第一讲就说过PPQ把计算图分成了三类:可量化、不可量化、争议区。计算图分割的目的就是把这三类区域分割出来;为了适应多平台,PPQ已经在计算图的调度上也分了很多种,我们一一道来。
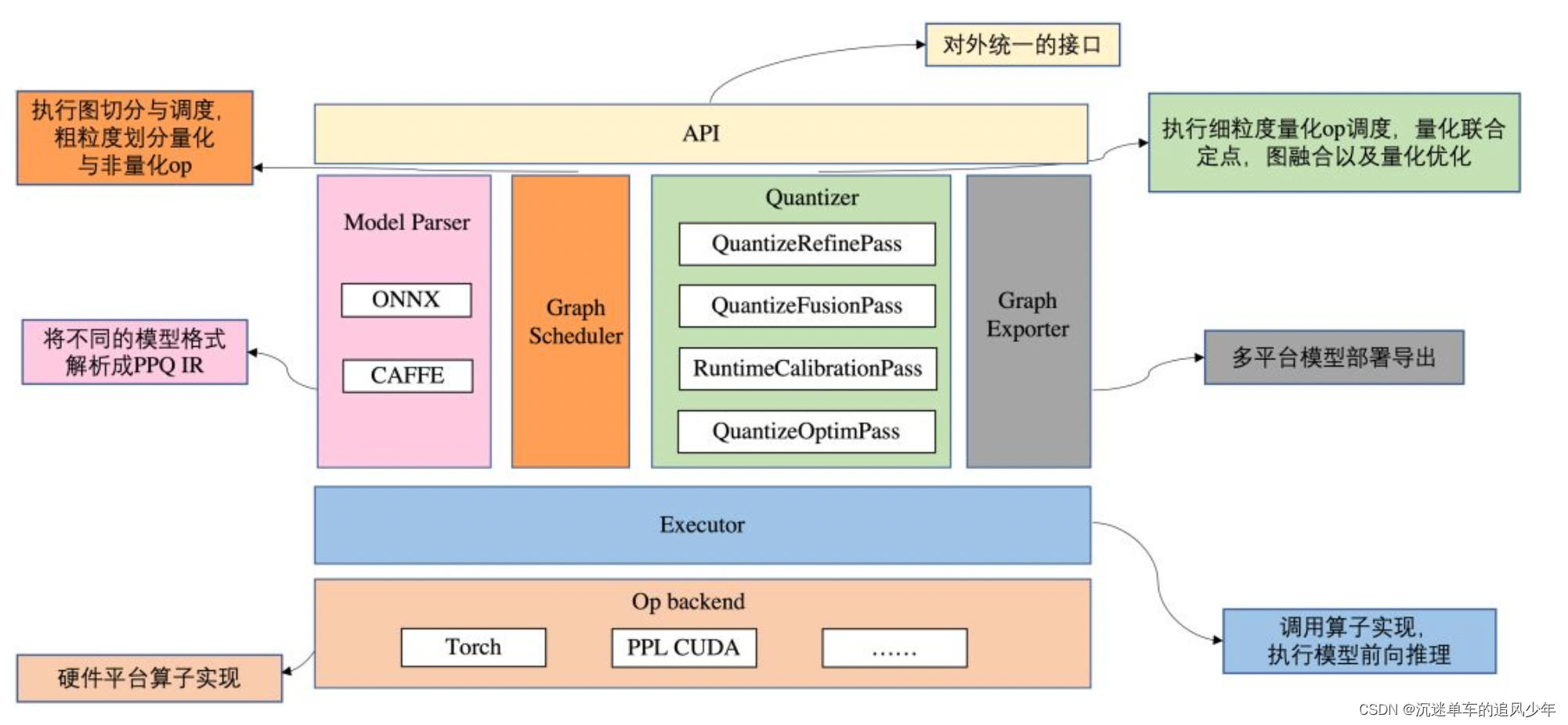
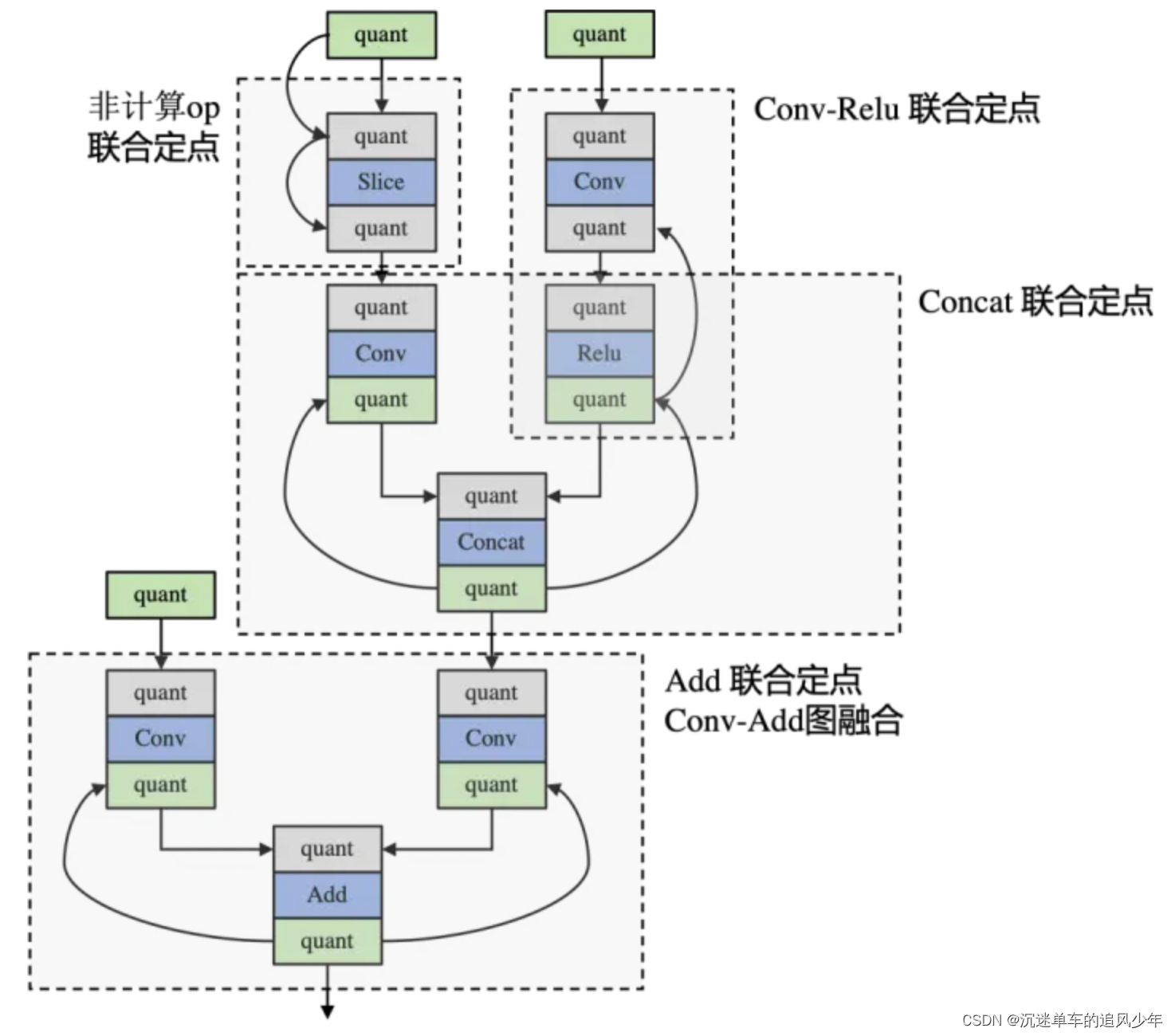
分割调度类型
PPQ一共有六种类型,写在DISPATCHER_TABLE字典中:
DISPATCHER_TABLE = {
"conservative": ConservativeDispatcher,
"pplnn": PPLNNDispatcher,
"aggresive": AggresiveDispatcher,
"pointwise": PointDispatcher,
"allin": AllinDispatcher,
'perseus': Perseus
}我们就先从保守调度类型conservative为例开始看吧!
计算图的切割
三种调度平台
首先回忆一下上一讲用的在计算图中搜索的所需算子的方法opset_matching(),现在我们用这个方法来搜索我们所需要的算子!
我们现在要搜索三类算子,然后调度到不同平台上:quant_platform、SOI_platform、fp32_platform。
- quant_platform:图形的所有可量化部分都将被分派到此平台。
- SOI_platform:形状或索引相关操作将分派到此平台。
- fp32_platform:有一些操作同时从quant_platform和SOI_platform接收结果,它们将被分派到fp32_platform。
小插曲,此处的注释貌似写错了:
Shape or Index算子为什么不能被量化?
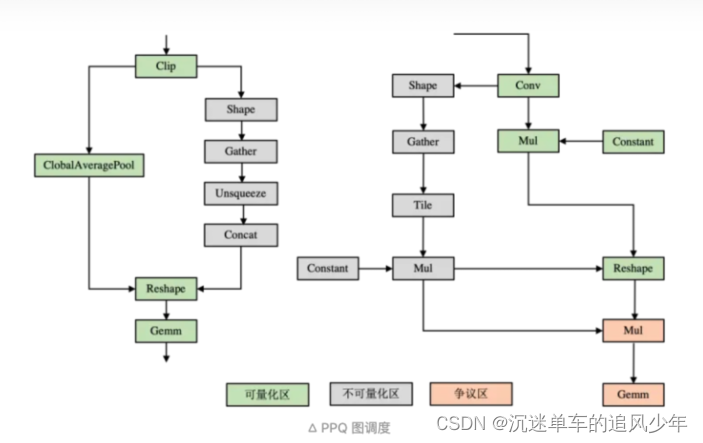
在图中 shape 算子的输出要作为参数传递给 reshape 算子,如果我们在这条路径上插入任何量化操作,会导致 reshape 算子的输入被改变。
例如 shape 算子的输出为 [1, 3, 224, 224],我们知道 int8 量化只能表示 256 个数,而对称量化在正数半轴只有 128 个数可以表示,假设我们选取 scale = 2,其量化后的值将会变为 [0, 4, 224, 224]。那么后续的逻辑自然就执行不通了。
分割量化操作
opset_matching()方法又大显神功,把所有可计算量化的算子都装入quant_operations当中。
quant_operations = search_engine.opset_matching(
sp_expr = lambda x: x.is_computing_op,
rp_expr = value_tracing_pattern,
ep_expr = lambda x: (x.type not in quant_types) or x.is_boundary,
direction = 'down')
quant_operations.filter(lambda x: x.type not in quant_types)Shape or Index操作
先按照算子类型是否是shape、topk、nonmaxsuppression寻找计算图:
computing_extensions = search_engine.opset_matching(
sp_expr = lambda x: x.is_computing_op,
rp_expr = value_tracing_pattern,
ep_expr = lambda x: x.type in {'Shape', 'TopK', 'NonMaxSuppression'} or x.is_boundary,
direction = 'down')但是在某些特定情况下,单个匹配无法处理。为了覆盖所有与形状相关的操作,需要反向匹配。
注释是这么描述的,但是我还不是特别理解,后面会结合实例再思考一下:
# we assume all 'Shape', 'NonMaxSuppression', 'ConstantOfShape', 'Topk' operations are SOI generators.
shape_forward_matching = search_engine.opset_matching(
sp_expr = lambda x: x in generators and x.type not in {'Constant'},
rp_expr = value_tracing_pattern,
ep_expr = lambda x: (x in recivers or
x in quant_operations or
x.is_boundary or
x.is_computing_op),
direction = 'down')
# remove computing operations and quant operations from matching
shape_forward_matching.filter(lambda x: x.is_computing_op or x in quant_operations)
# update matchings, ready for further searching.
SOI_operations.update(shape_forward_matching)
while True:
# there are some particular cases where a single matching can not handle.
# to cover all shape-related operations, a reverse matching is required.
shape_backward_matching = search_engine.opset_matching(
sp_expr = lambda x: x in SOI_operations and x.type != 'Shape',
rp_expr = reverse_tracing_pattern,
ep_expr = lambda x: (x in SOI_operations or
x in quant_operations or
x.is_boundary or
x.is_computing_op),
direction = 'up')
# remove computing operations and quant operations from matching
shape_backward_matching.filter(lambda x: x.is_computing_op or x in quant_operations)
if all([(op in SOI_operations) for op in shape_backward_matching]): break
# update matchings
SOI_operations.update(shape_backward_matching)fp32(非量化)操作
剩下的就全是非量化区域啦~
组装分割计算图
刚才依赖opset_matching方法把我们所需要切割的都找到了,接下来我们组装一个字典集然后返回,大功告成!
# generate dispatching table.
dispatching_table = {}
for operation in graph.operations.values():
if operation in SOI_operations and operation not in computing_extensions:
dispatching_table[operation.name] = SOI_platform
elif operation in quant_operations:
dispatching_table[operation.name] = quant_platform
else:
dispatching_table[operation.name] = fp32_platform因为在SOI匹配的时候,做了正向和反向两次匹配,所以这里需要删除重复匹配:
for operation in graph.operations.values():
# move Topk, Shape, NonMaxSuppression to the platform same as their input.
if operation.type in {'Shape', 'TopK', 'NonMaxSuppression'}:
source_op = operation.inputs[0].source_op
if source_op is not None:
dispatching_table[operation.name] = dispatching_table[source_op.name]
else: dispatching_table[operation.name] = fp32_platform
# move activations to the platform same as their input.
if operation.is_linear_activation:
source_op = operation.inputs[0].source_op
if source_op is not None:
dispatching_table[operation.name] = dispatching_table[source_op.name]PPL NN 计算图分割策略
刚才是以保守调度策略为例说明了计算图分割的大体过程,因为大致流程是一样的,下面重点讲讲其他的策略不同点。
PPL NN的的量化策略是从conv到conv作为可量化区域,区别于保守调度策略中的从可计算op调度:
quant_operations = search_engine.opset_matching(
sp_expr = lambda x: x.type == 'Conv',
rp_expr = lambda x, y: value_tracing_pattern(x, y) and y.type in quant_types,
ep_expr = lambda x: x.type == 'Conv',
direction = 'down')其他的等用到的时候再看吧,这里就不细看了~
后记
其实还有不少地方我没有看明白,比如不同平台是软件层面的分类还是硬件层面的分类?分类标准是加速运算还是为了分割计算图方便后续调度量化?……后面将探索这些疑点!
文章出处登录后可见!