参考文章:https://blog.csdn.net/tengfei461807914/article/details/81588808
https://zhuanlan.zhihu.com/p/31103280
背景减除
计算机视觉的前景和背景:
- 前景:你感兴趣、要研究的对象,如车辆识别统计中的车辆
- 背景:不是你想要研究的对象,如车辆识别统计中的天空、数目、阴影等等
**背景减除(Background Subtraction)是许多基于计算机视觉、目标跟踪等任务中的一个非常重要的预处理步骤。**例如使用固定的摄像头来统计一个房间的进出人数或者交通摄像头提取关于交通工具的信息等等。在所有这些例子当中,你首先要做的就是把人和交通工具单独提取出来。从技术上来讲,你需要把移动的前景从静止的背景当中提取出来。
如果你要一张单独的背景图片,例如一个没有游客的房间照片,没有任何交通工具的街道照片等等,这有一个很简单的方法,只要从新的图片当中减去背景图片即可。你就能得到单独的前景照片。但是在多数的例子当中,你不可能有这样的背景照片,所以我们需要从我们手头有的照片中提取前景。当存在阴影等效果的时候,这相当复杂了。因为影子是会移动的,简单的减除方法会将阴影部分同样当成是前景。这是个很糟糕的事情。
如果我们有完整的静止的背景帧,那么我们可以通过帧差法来计算像素差从而获取到前景对象。**但是在大多数情况下,我们可能没有这样的图像,所以我们需要从我们拥有的任何图像中提取背景。当运动物体有阴影时,由于阴影也在移动,情况会变的变得更加复杂。**为此引入了背景减除算法,通过这一方法我们能够从视频中分离出运动的物体前景,从而达到目标检测的目的。
方法选择:
- MOG:基于混合高斯进行背景建模
- MOG2:基于混合高斯进行背景建模,MOG的升级版本
- GMG:基于像素颜色进行背景建模,其主要依赖的是像素点的素值
- CNT:基于像素点计数进行背景建模,其主要依赖的是像素点相同数值的计数值
- KNN:基于K最近邻进行背景建模,根据附近颜色的相似度来进行的背景提取
MOG
-
MOG算法,即高斯混合模型分离算法,全称Gaussian Mixture-based Background/Foreground Segmentation Algorithm。2001年,由P.KadewTraKuPong和R.Bowden在论文“An improved adaptive background mixture model for real-time tracking with shadow detection”中提出。它使用 K(K=3~5)个高斯分布混合对背景像素进行建模。使用这些颜色(在整个视频中)存在时间的长短作为混合的权重。背景的颜色一般持续的时间最长,而且更加静止。
-
cv2.bgsegm.createBackgroundSubtractorMOG([, history[, nmixtures[, backgroundRatio[, noiseSigma]]]])
- history:Length of the history.历史时间长度
- nmixtures:Number of Gaussian mixtures.高斯混合成分的数量
- backgroundRatio:Background ratio.背景比率
- noiseSigma:Noise strength (standard deviation of the brightness or each color channel).噪声强度(亮度或各颜色通道的标准差)。–阈值
-
在编写代码时,我们需要使用函数:cv2.bgsegm.createBackgroundSubtractorMOG() 创建一个背景对象。这个函数有些可选参数,比如要进行建模场景的时间长度,高斯混合成分的数量,阈值等。将他们全部设置为默认值。然后在整个视频中我们是需要使用cv2.backgroundsubtractor.apply() 就可以得到前景的掩膜了.
- 移动的物体会被标记为白色,背景会被标记为黑色的
使用示例:
import cv2
import numpy as np
cap = cv2.VideoCapture(0)
# 创建mog2对象
mog = cv2.bgsegm.createBackgroundSubtractorMOG()
while True:
ret, frame = cap.read()
if ret == True:
fgmask = mog.apply(frame)
cv2.imshow('video', fgmask)
key = cv2.waitKey(1)
# 用户按esc退出
if key == 27:
break
# 最后别忘了, 释放资源
cap.release()
cv2.destroyAllWindows()
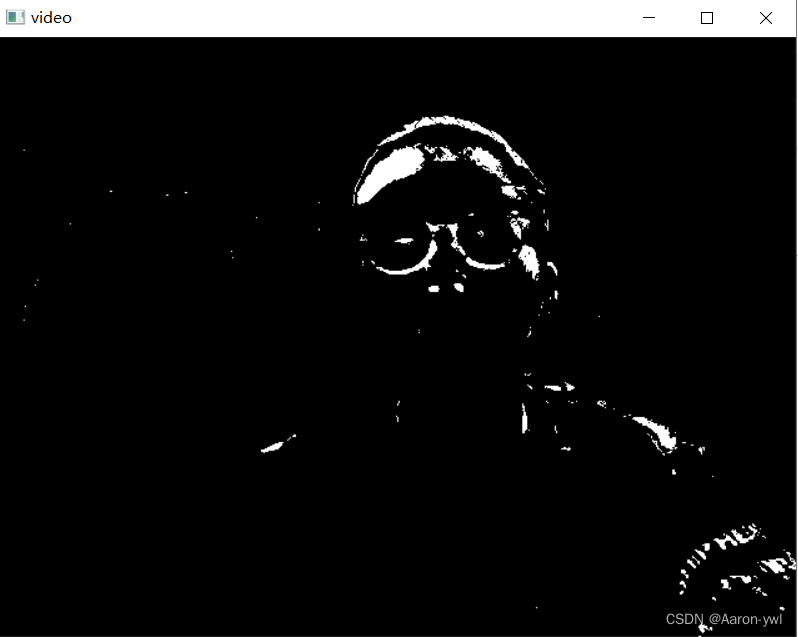
MOG2
-
该方法同样是使用基于高斯混合模型的背景前景分割算法。基于两篇论文:
Improved adaptive Gausian mixture model for background subtractionEfficient Adaptive Density Estimation per Image Pixel for the Task of Background Subtraction
该算法的一个重要特征是它对每个像素点**选择了合适数量的高斯分布模型。**因此它也提供了一个在光照变换场景中更好的适应能力。
-
cv2.createBackgroundSubtractorMOG2([, history[, varThreshold[, detectShadows]]])
- history:Length of the history.历史时间长度
- varThreshold:hreshold on the squared Mahalanobis distance between the pixel and the model.方差阈值,用于判断当前像素是前景还是背景。一般默认16,如果光照变化明显,如阳光下的水面,建议设为25,36,具体去试一下也不是很麻烦,值越大,灵敏度越低。
- detectShadows:If true, the algorithm will detect shadows and mark them.如果为真,算法将检测阴影并标记它们。它会降低一旦速度,所以如果不需要这个特性,可设置成False.
-
在编写代码时,我们需要使用函数:**cv2.createBackgroundSubtractorMOG2() 创建一个背景对象。这个函数有些可选参数,比如要进行建模场景的时间长度,阈值等。将他们全部设置为默认值。**然后在整个视频中我们是需要使用backgroundsubtractor.apply() 就可以得到前景的掩膜了.
- 移动的物体会被标记为白色,背景会被标记为黑色的
使用示例:
import cv2
import numpy as np
cap = cv2.VideoCapture(0)
# 创建mog对象
mog2 = cv2.createBackgroundSubtractorMOG2()
while True:
ret, frame = cap.read()
if ret == True:
fgmask = mog2.apply(frame)
cv2.imshow('video', fgmask)
key = cv2.waitKey(1)
# 用户按esc退出
if key == 27:
break
# 最后别忘了, 释放资源
cap.release()
cv2.destroyAllWindows()
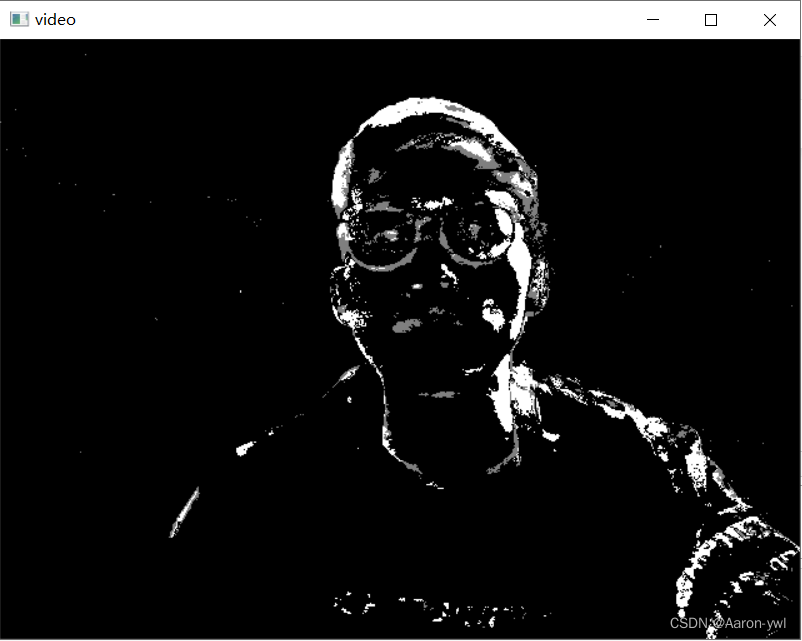
GMG
-
该算法结合了静态背景图片估计和每个像素的贝叶斯分割方法。来源于论文:
Visual Tracking of Human Visitors under Variable-Lighting Conditions for a Responsive Audio Art Installation该系统运行了一个成功的音频交互的艺术装置,该装置叫“Are We There Yet?” 而且运行了很长时间哦~(略过一些废话)
该方法默认使用前120帧图像进行建模(所以在打开视频的时候你得等一会再把移动的物体放上),使用概率前景分割算法,即使用贝叶斯推断方法来识别一个物体是否是前景。
该估计算法是一种自适应的估计方法,新的被观察物体比旧的观察物体有更改的权重,这样可以适应变化的光照。一些形态学吕布的操作,例如闭运算和开运算可以用来去除不想要的噪声。
**在开始的前几帧(默认是120)当中你会得到一个黑色的窗口。**这很适合使用形态学滤波的开运算来去除噪声。 -
cv2.bgsegm.createBackgroundSubtractorGMG([, initializationFrames[, decisionThreshold]])
- initializationFrames:number of frames used to initialize the background models.用于初始化背景模型的帧数,默认是120
- decisionThreshold:Threshold value, above which it is marked foreground, else background.阈值,超过该阈值,标记为前景,否则为背景,默认为0.8
import cv2
import numpy as np
cap = cv2.VideoCapture(0)
# 创建GMG对象
gmg = cv2.bgsegm.createBackgroundSubtractorGMG()
while True:
ret, frame = cap.read()
if ret == True:
fgmask = gmg.apply(frame)
cv2.imshow('video', fgmask)
key = cv2.waitKey(1)
# 用户按esc退出
if key == 27:
break
# 最后别忘了, 释放资源
cap.release()
cv2.destroyAllWindows()

CNT
该算法无参考文献,故只根据源码进行简单解释
CNT算法是一种不需要对背景点进行高斯建模处理的方法,它仅仅只使用过去连续N帧内的像素点值的信息以及其他一点额外的信息,因此速度很快,效果也不错。
- cv2.bgsegm.createBackgroundSubtractorCNT([, minPixelStability[, useHistory[, maxPixelStability[, isParallel]]]])
- minPixelStability:number of frames with same pixel color to consider stable.考虑稳定的相同像素颜色的帧数。
- useHistory:determines if we’re giving a pixel credit for being stable for a long time.决定我们是否给一个像素信用,因为它是稳定的很长一段时间。
- maxPixelStability:maximum allowed credit for a pixel in history.历史上一个像素的最大允许积分。
- isParallel:determines if we’re parallelizing the algorithm.决定了我们是否在并行化算法。
import cv2
import numpy as np
cap = cv2.VideoCapture(0)
# 创建CNT对象
cnt = cv2.bgsegm.createBackgroundSubtractorCNT()
while True:
ret, frame = cap.read()
if ret == True:
fgmask = cnt.apply(frame)
cv2.imshow('video', fgmask)
key = cv2.waitKey(1)
# 用户按esc退出
if key == 27:
break
# 最后别忘了, 释放资源
cap.release()
cv2.destroyAllWindows()

KNN
-
cv2.createBackgroundSubtractorKNN([, history[, dist2Threshold[, detectShadows]]])
- history:Length of the history.历史时间长度
- dist2Threshold:Threshold on the squared distance between the pixel and the sample to decide.whether a pixel is close to that sample. This parameter does not affect the background update.阈值由像素和样本之间的平方距离来决定。一个像素是否接近该样本。该参数不影响后台更新。
- detectShadows:If true, the algorithm will detect shadows and mark them.如果为真,算法将检测阴影并标记它们。它会降低一旦速度,所以如果不需要这个特性,可设置成False.
import cv2 import numpy as np cap = cv2.VideoCapture(0) # 创建KNN对象 knn = cv2.createBackgroundSubtractorKNN() while True: ret, frame = cap.read() if ret == True: fgmask = knn.apply(frame) cv2.imshow('video', fgmask) key = cv2.waitKey(1) # 用户按esc退出 if key == 27: break # 最后别忘了, 释放资源 cap.release() cv2.destroyAllWindows()
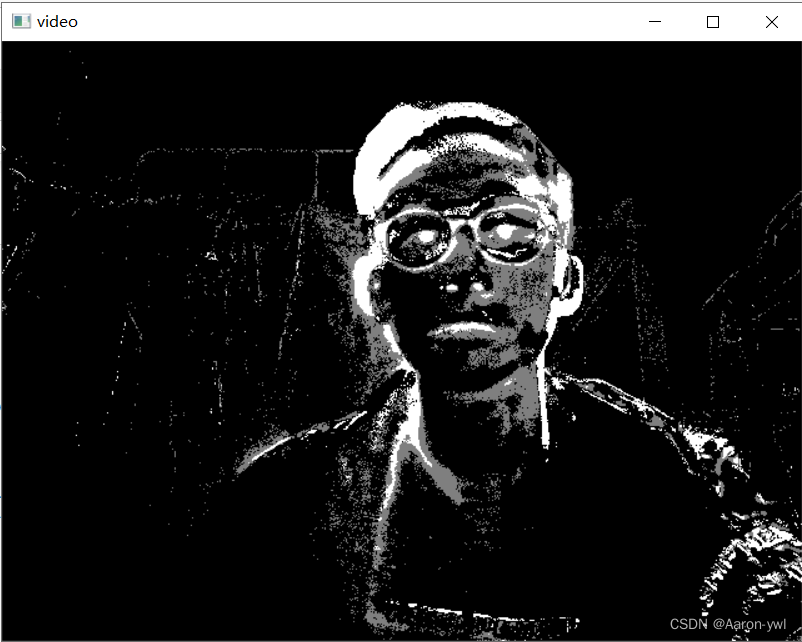
感兴趣的伙伴可以试一试哦!安装了cv2后copy直接就可以运行!!!
总结
如果追求速度的话,可以尝试使用CNT,MOG2,KNN。
如果追求质量的话,可以使用MOG2,KNN。
总的来说实际应用中,MOG2用的最多,KNN其次,CNT一般用于Raspberry Pi和多检测任务中。
附OpenCV目录:OpenCV总目录学习笔记
智科专业小白,写博文不容易,如果喜欢的话可以点个赞哦!

文章出处登录后可见!