
论文地址:https://arxiv.org/abs/1905.11946
代码地址:https://githeb.com/TensorFlow/tpu/tree/master/Models/Offical/Efficientnet
卷积神经网络(ConvNet)通常是在固定的资源预算下开发的,如果有更多的资源可用,则会扩大规模以获得更好的精度。在本文中,我们系统地研究了模型缩放,发现仔细平衡网络深度、宽度和分辨率可以带来更好的性能。基于这一观察结果,我们提出了一种新的缩放方法,该方法使用一个简单而高效的复合系数来统一缩放所有维度的深度/宽度/分辨率。我们演示了该方法在扩展移动网和ResNet上的有效性。更进一步,我们使用神经结构搜索来设计一个新的基线网络,并将其放大以获得一系列称为EfficientNets的模型,这些模型获得了比以前的ConvNets更高的精度和效率。特别是,我们的EfficientNet-B7在ImageNet上达到了最先进的84.3%的TOP-1准确率,同时比现有最好的ConvNet小8.4倍,推理速度快6.1倍。我们的EfficientNets在CIFAR-100(91.7%)、Flowers(98.8%)和其他3个迁移学习数据集上的迁移效果也很好,达到了最先进的准确率,参数减少了一个数量级。源代码在https://githeb.com/TensorFlow/tpu/tree/master/Models/Offical/Efficientnet
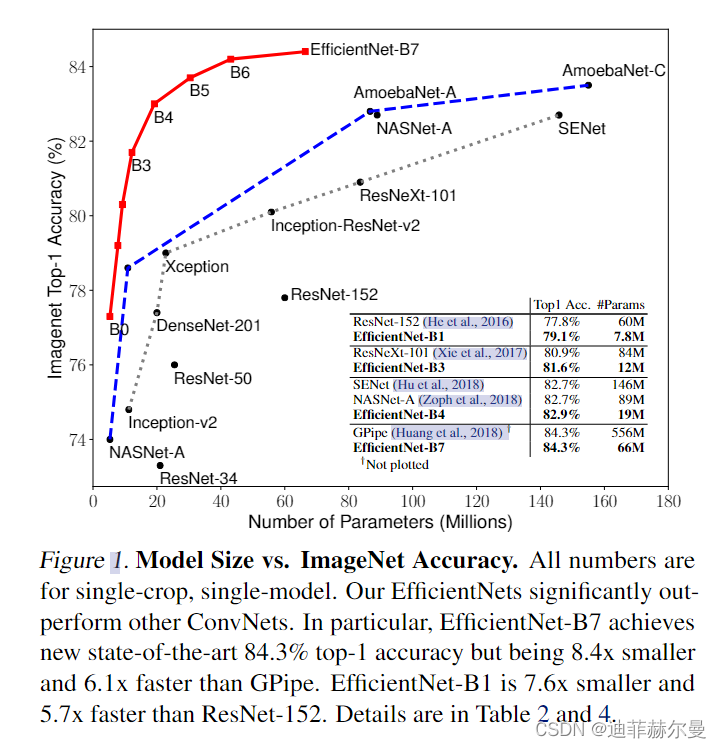
EfficientNet-B0网络结构
EfficientNet提供了多个版本满足各种应用场景,本文提供的是EfficientNet-B0版本
将YOLOv5主干网络替换为Efficient-B0:
yolov5lEfficient-B0.yaml
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# EfficientNet-B0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, stem, [32, 'ReLU6']], # 0-P1/2 ch_out, act
[-1, 1, MBConvBlock, [16, 3, 1, 1, 0]], # 1 ch_out, k_size, s, expand
[-1, 1, MBConvBlock, [24, 3, 2, 6, 0.028, True]], # 2-P2/4 ch_out, k_size, s, expand, drop_connect_rate, se
[-1, 1, MBConvBlock, [24, 3, 1, 6, 0.057]],
[-1, 1, MBConvBlock, [40, 5, 2, 6, 0.085]], # 4-P3/8 ch_out, k_size, s, expand, drop_connect_rate, se
[-1, 1, MBConvBlock, [40, 5, 1, 6, 0.114]],
[-1, 1, MBConvBlock, [80, 3, 2, 6, 0.142]], # 6-P4/16 ch_out, k_size, s, expand, drop_connect_rate, se
[-1, 1, MBConvBlock, [80, 3, 1, 6, 0.171]],
[-1, 1, MBConvBlock, [80, 3, 1, 6, 0.200]],
[-1, 1, MBConvBlock, [112, 5, 1, 6, 0.228]], # 9
[-1, 1, MBConvBlock, [112, 5, 1, 6, 0.257]],
[-1, 1, MBConvBlock, [112, 5, 1, 6, 0.285]],
[-1, 1, MBConvBlock, [192, 5, 2, 6, 0.314]], # 12-P5/32 ch_out, k_size, s, expand, drop_connect_rate, se
[-1, 1, MBConvBlock, [192, 5, 1, 6, 0.342]],
[-1, 1, MBConvBlock, [192, 5, 1, 6, 0.371]],
[-1, 1, MBConvBlock, [192, 5, 1, 6, 0.400]],
[-1, 1, MBConvBlock, [320, 3, 1, 6, 0.428]], # 16
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 11], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 21
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 5], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 25 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 21], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 28 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 17], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 31 (P5/32-large)
[[24, 27, 30], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
在YOLOv5项目中添加方式:
common.py中加入以下代码:
# EfficientNetLite
class SeBlock(nn.Module):
def __init__(self, in_channel, reduction=4):
super().__init__()
self.Squeeze = nn.AdaptiveAvgPool2d(1)
self.Excitation = nn.Sequential()
self.Excitation.add_module('FC1', nn.Conv2d(in_channel, in_channel // reduction, kernel_size=1)) # 1*1卷积与此效果相同
self.Excitation.add_module('ReLU', nn.ReLU())
self.Excitation.add_module('FC2', nn.Conv2d(in_channel // reduction, in_channel, kernel_size=1))
self.Excitation.add_module('Sigmoid', nn.Sigmoid())
def forward(self, x):
y = self.Squeeze(x)
ouput = self.Excitation(y)
return x * (ouput.expand_as(x))
class drop_connect:
def __init__(self, drop_connect_rate):
self.drop_connect_rate = drop_connect_rate
def forward(self, x, training):
if not training:
return x
keep_prob = 1.0 - self.drop_connect_rate
batch_size = x.shape[0]
random_tensor = keep_prob
random_tensor += torch.rand([batch_size, 1, 1, 1], dtype=x.dtype, device=x.device)
binary_mask = torch.floor(random_tensor) # 1
x = (x / keep_prob) * binary_mask
return x
class stem(nn.Module):
def __init__(self, c1, c2, act='ReLU6'):
super().__init__()
self.conv = nn.Conv2d(c1, c2, kernel_size=3, stride=2, padding=1, bias=False)
self.bn = nn.BatchNorm2d(num_features=c2)
if act == 'ReLU6':
self.act = nn.ReLU6(inplace=True)
def forward(self, x):
return self.act(self.bn(self.conv(x)))
class MBConvBlock(nn.Module):
def __init__(self, inp, final_oup, k, s, expand_ratio, drop_connect_rate, has_se=False):
super(MBConvBlock, self).__init__()
self._momentum = 0.01
self._epsilon = 1e-3
self.input_filters = inp
self.output_filters = final_oup
self.stride = s
self.expand_ratio = expand_ratio
self.has_se = has_se
self.id_skip = True # skip connection and drop connect
se_ratio = 0.25
# Expansion phase
oup = inp * expand_ratio # number of output channels
if expand_ratio != 1:
self._expand_conv = nn.Conv2d(in_channels=inp, out_channels=oup, kernel_size=1, bias=False)
self._bn0 = nn.BatchNorm2d(num_features=oup, momentum=self._momentum, eps=self._epsilon)
# Depthwise convolution phase
self._depthwise_conv = nn.Conv2d(
in_channels=oup, out_channels=oup, groups=oup, # groups makes it depthwise
kernel_size=k, padding=(k - 1) // 2, stride=s, bias=False)
self._bn1 = nn.BatchNorm2d(num_features=oup, momentum=self._momentum, eps=self._epsilon)
# Squeeze and Excitation layer, if desired
if self.has_se:
num_squeezed_channels = max(1, int(inp * se_ratio))
self.se = SeBlock(oup, 4)
# Output phase
self._project_conv = nn.Conv2d(in_channels=oup, out_channels=final_oup, kernel_size=1, bias=False)
self._bn2 = nn.BatchNorm2d(num_features=final_oup, momentum=self._momentum, eps=self._epsilon)
self._relu = nn.ReLU6(inplace=True)
self.drop_connect = drop_connect(drop_connect_rate)
def forward(self, x, drop_connect_rate=None):
"""
:param x: input tensor
:param drop_connect_rate: drop connect rate (float, between 0 and 1)
:return: output of block
"""
# Expansion and Depthwise Convolution
identity = x
if self.expand_ratio != 1:
x = self._relu(self._bn0(self._expand_conv(x)))
x = self._relu(self._bn1(self._depthwise_conv(x)))
# Squeeze and Excitation
if self.has_se:
x = self.se(x)
x = self._bn2(self._project_conv(x))
# Skip connection and drop connect
if self.id_skip and self.stride == 1 and self.input_filters == self.output_filters:
if drop_connect_rate:
x = self.drop_connect(x, training=self.training)
x += identity # skip connection
return x
yolo.py中添加如下代码:
本人更多YOLOv5实战内容导航🍀🌟🚀
-
手把手带你Yolov5 (v6.2)添加注意力机制(一)(并附上30多种顶会Attention原理图)🌟强烈推荐🍀新增8种
-
空间金字塔池化改进 SPP / SPPF / SimSPPF / ASPP / RFB / SPPCSPC / SPPFCSPC🚀
参考文献:

文章出处登录后可见!