前沿
这篇文章会以比较轻松的方式,跟大家交流下如何控制文本生成图片的质量。
要知道如何控制文本生成质量,那么我们首先需要知道我们有哪些可以控制的参数和模块。要知道我们有哪些控制的参数和模块,我们就得知道我们文本生成图片的这架机器或者这个系统,包括了哪些部件和模块。同时需要知道这些部件和模块会如何影响生成的图片质量,如此我们才能更好的去协调和控制生成图片质量。
有了图片生成机器或系统,这就相当于有了一架很牛逼的生产引擎。围绕着生产引擎必然可以配置更多的转化部件,才能让这台机器更加牛逼。但是增加哪些部件呢,又为什么要增加这些部件呢,这必然是和生产的piepleline关联的,我们的生产工序和生产工艺决定了我们该如何假设我们的piepleline。
如此我们会从以上三个层次去介绍可以如何控制图片生成。
1.该如何工业化的稳定的设计我们生产工艺和链路
2.围绕生产工艺和链路该配备哪些生产组件和部件配合我们强大生产引擎组合出牛逼生产系统
3.改如何设置好参数让我们生成引擎达到产出图质量稳定,性能优良
生产引擎——stablediffusion
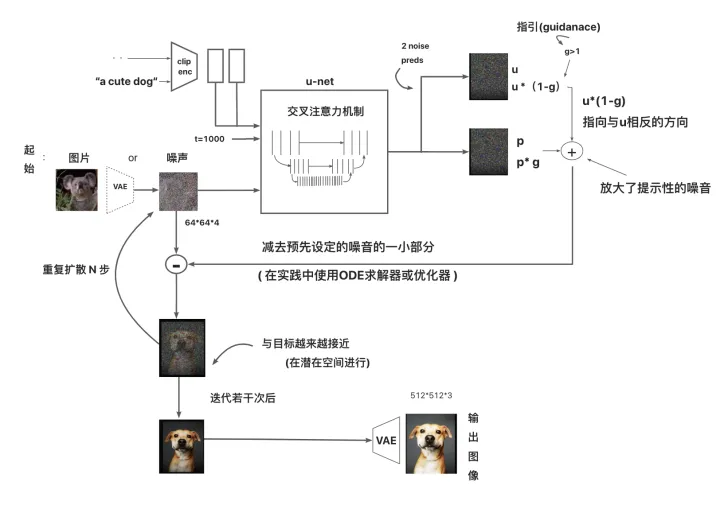
如上图所示,我们的生产引擎stablediffusion引擎,主要有4大部分:
1.图输入
2.文字输入
3.生成模型
4.输出部分
图输入部分又包括两部分:图片(随机噪声、约束图片)、图片编码器(vae encode)
文字输入部分包括两部分:描述文字(prompt优化)、文字编码器(clip)
生成模型:把图编码、文编码作为原料,经过不同生成模型(生产步数、生成器ddim、sde、euler…)
输出部分:经过生成模型产出图,可以是单步也可以是多步
生产集成车间——stablediffusion_webui
webui看起来就是一张皮,或者是把各个模块串接起来的链路,感觉没什么高科技;然而这东西像插线板一样的把各个模块连接自由组合的东西,却让stablediffusion产生出强大的生成力和可能的创造力。
这东西就像是一个生产集成车间,把各种的机器设备放到了一起,并且把各组件可能需要的连接组合都预先提供转接工具。从虚线来讲就是让各种生产工序可能的串接方式和组合排序方式产生可能。
image2image是个很好工序的转接头,可以让生成的图转入到其它风格的sd模型做进一步生成,也可以转到lora控制的光照、纹理、色彩层做进一步生成。
lora也是一个很好的转接头,每个lora层可以训练控制模型的小风格:光照、色系、质感、纹理;sd基底模型不变,上面换lora层让图片经过一道一道的lora加工达到最后要的效果。
现有的生产工艺
辅助工序
编辑、修改、mask、outpaint、inpaint
Embbeding
这改变的输入部分
1.文本输入,让输入的prompt更优化,是否可能通过把人输入prompt转换成这个训练数据集的标注数据
2.文本转embbeding,是否可以用自己图文数据集合来finetune clip编码器
3.图编码,是否可以选用更适合自己数据集合的编码器vae
4.图约束,是否可以输入图结构
5.图文输入,用Dreambooth方式生成指代符代表输入embbeding,保证生成图片一致
textual investor
在大多数文本到图像模型的文本编码阶段,第一阶段涉及将提示转换为数字表示。这通常是通过将单词转换为标记来完成的,每个标记相当于模型字典中的一个条目。然后将这些条目转换为“嵌入”——特定标记的连续向量表示。这些嵌入通常作为训练过程的一部分进行学习。在我们的工作中,我们发现了代表特定的、用户提供的视觉概念的新嵌入。然后将这些嵌入链接到新的伪词,这些伪词可以像任何其他词一样合并到新句子中。从某种意义上说,正在对冻结模型的文本嵌入空间进行反演,称这个过程为“文本倒置”。
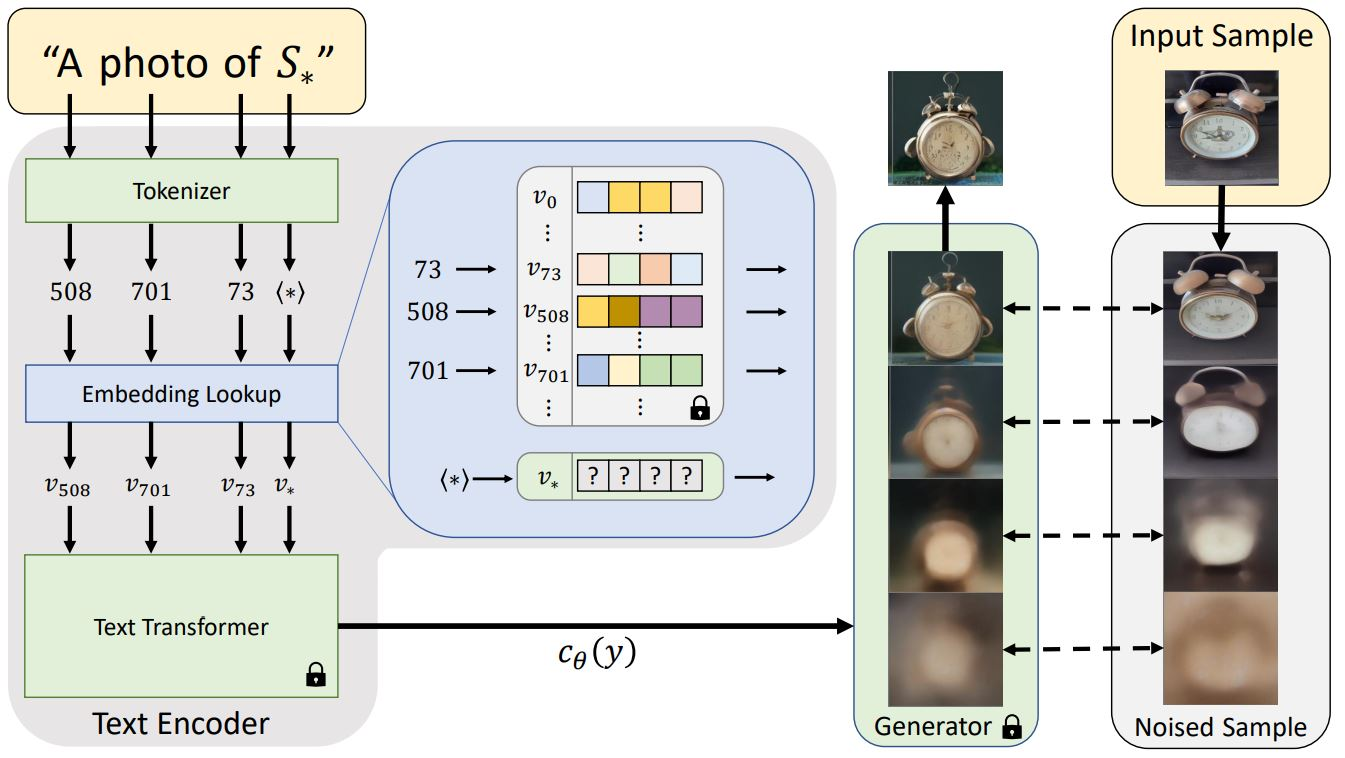
这个应该是在文本输入端编码器上做文章。Textual Inversion 训练为了 embeddings,embeddings 为 Ai 提供处理过的输入数据,告诉这个角色“具体是什么”,训练特殊的人物,角色会更好。
Dreambooth
用Dreambooth方式生成指代符代表输入embbeding,保证生成图片一致,做角色、单物体多样化很有效果。
AI生图已经进入商用落地阶段,ChatGPT也实现了通用智能对话能力,未来一段时间AI将是新一轮淘金热潮的风口。而且不像区块链比特币,AI目前国内还是十分宽松,短期内也没有一刀切的风险,合法合规赚钱相对国外还更简单。
1. 生成漂亮头像

Dreambooth模型算法生成漂亮头像
2. 角色扮演

Dreambooth模型算法角色扮演
3. 动物创意图
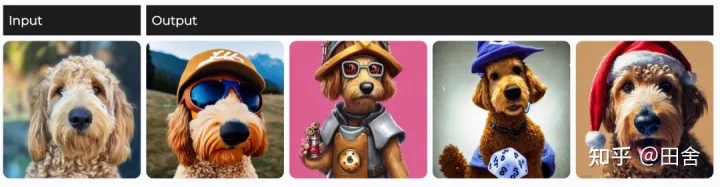
Dreambooth模型算法动物创意图
4. 动漫二次创作
Dreambooth模型算法动漫二次创作
5. 商品展示图

Dreambooth模型算法 商品展示图
6. 风格化模型
Dreambooth模型算法风格化模型
以上是Dreambooth的能力示范,每个能力都可以落地成不同的商业服务场景。
vae
VAE (Variational Auto-Encoder 变分自动编码器)模型有两部分,分别是一个编码器和一个解码器,常用于AI图像生成
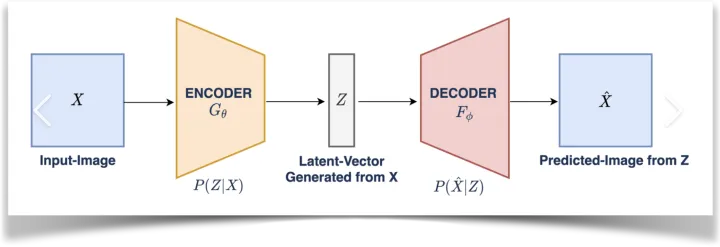
在潜在扩散模型(Latent Diffusion Models)组成中就有VAE模型的身影。
其中编码器(encoder)被用于把图片转换成低维度的潜在表征,转换完成后的潜在表征将作为U- Net 模型的输入.
反之,解码器(decoder)将把潜在表征重新转回图片形式.
在潜在扩散模型的训练过程中,编码器被用于取得图片训练集的潜在表征(latents),这些潜在表征被用于前向扩散过程(每一步都会往潜在表征中增加更多噪声).
在推理生成时,由反向扩散过程生成的 denoised latents 被VAE 的解码器部分转换回图像格式.
所以说 ,在潜在扩散模型的推理生成过程中我们只需用到VAE的解码器部分.
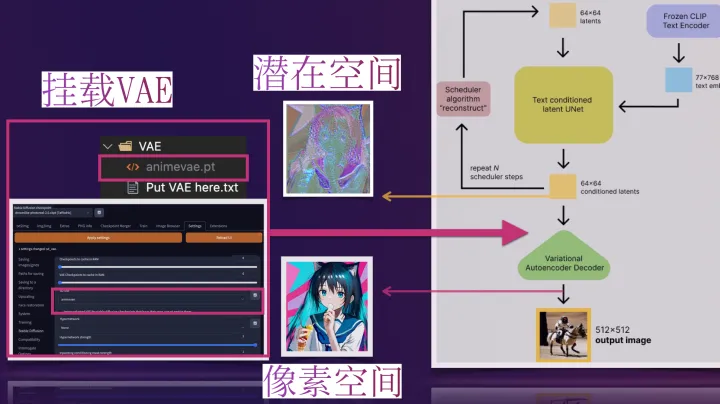
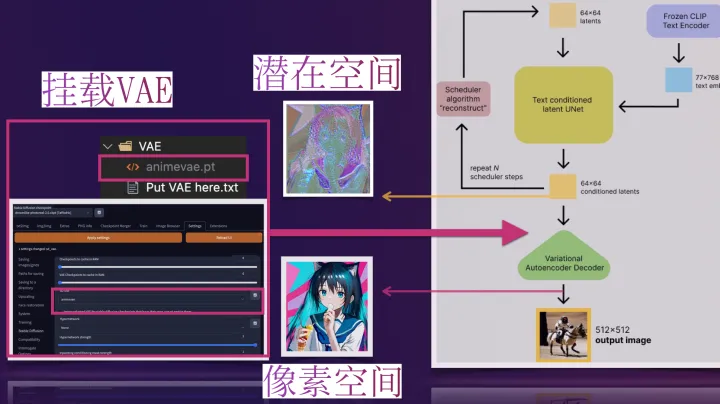
WebUI中的VAE
那些比较流行预训练的模型一般都是内置了训练好的VAE模型的,不用我们再额外挂载也能做正常的推理生成(挂载后生成图像的效果会有一点点细微的区别),此时VAE pt文件的作用就像HDR ,增加一点点图片色彩空间之类的一些自定义模型
可如果一些预训练模型文件不内置VAE(或训练他们自己的VAE,此时通常会在他们的模型发布说明中告诉你从哪得到他们的VAE)。我们就必须给它找一个VAE挂载上去,用来将推理时反向扩散最后生成的 denoised latents 转换回图像格式,否则webui里最后生成输出给我们的就是类似彩噪的潜在表征(latents),此时VAE pt文件的作用就像解压软件 ,为我们解压出肉眼友好可接受的图像.
做了张图来直观地说明展示下
网络模型
hypernetwork
Hypernetworks 会对超网络的改动,与 embeddings 不同,Hypernetworks 会对模型进行微调,所以泛化效果更加好,训练画风会更好。
网络merge fix
有多个风格的网络,是否可以通过权重方式组合出介于a、b风格之间的风格
分层融合
如–input_blocks "0:0.3",0是input层序号,0.3是第二个权重的占比,多层描述之间以英文逗号分隔,层内以英文冒号分隔。
这里的权重比例指的是第二个权重的占比。
如果不需要融合middle_blocks,可以直接删除–middle_blocks这一行。
支持safetensors格式和ckpt格式权重的融合与保存(根据文件格式自动判断)。
!python tools/merge_unet_blocks.py ./ckpt_models/xxx1.safetensors ./ckpt_models/xxx2.safetensors \
–input_blocks "0:0.5, 1:0.5, 2:0.5, 3:0.6, 4:0.5, 5:0.5, 6:0.5, 7:0.5, 8:0.5, 9:0.5, 10:0.5, 11:0.5" \
–middle_blocks "0:0.5, 1:0.5, 2:0.6" \
–output_blocks "0:0.5, 1:0.5, 2:0.5, 3:0.6, 4:0.5, 5:0.5, 6:0.5, 7:0.5, 8:0.5, 9:0.5, 10:0.5, 11:0.5" \
–out "0:0.5, 2:0.3" \
–time_embed "0:0.5, 2:0.3" \
–dump_path ./ckpt_models/merged.ckpt
以上这段等价于:(即只为特别层指定融合时的比例,其他层融合时共用基础比例–base_alpha 0.5)
!python tools/merge_unet_blocks.py ./ckpt_models/xxx1.safetensors ./ckpt_models/xxx2.ckpt \
–base_alpha 0.5 \
–dump_path ./ckpt_models/merged.safetensors
你也可以,以相同的比例合并整个unet层:
链路
instruct pix2pix
instruct-pix2pix作者团队提出了一种通过人类自然语言指令编辑图像的方法。他们的模型能够接受一张图像和相应的文字指令(也就是prompt),根据指令来编辑图像。作者团队使用两个预训练模型(一个是语言模型GPT-3, 另一个是文本到图像模型Stable Diffusion) 生成大量编辑图像的样例数据,然后基于这些数据训练出InstructPix2Pix模型,能够在推理过程中适用于真实图像和用户提供的指令。由于它在前向传播中执行编辑并且不需要对每个示例进行fine-tine或 inversion,模型仅需几秒钟就可快速完成图片的编辑。


Lora
LoRA: Low-Rank Adaptation of Large Language Models 是微软研究员引入的一项新技术,主要用于处理大模型微调的问题。目前超过数十亿以上参数的具有强能力的大模型 (例如 GPT-3) 通常在为了适应其下游任务的微调中会呈现出巨大开销。 LoRA 建议冻结预训练模型的权重并在每个 Transformer 块中注入可训练层 (秩-分解矩阵)。因为不需要为大多数模型权重计算梯度,所以大大减少了需要训练参数的数量并且降低了 GPU 的内存要求。研究人员发现,通过聚焦大模型的 Transformer 注意力块,使用 LoRA 进行的微调质量与全模型微调相当,同时速度更快且需要更少的计算。
用于 Diffusers 的 LoRA
尽管 LoRA 最初是为大模型提出的,并在 transformer 块上进行了演示,但该技术也可以应用于其他地方。在微调 Stable Diffusion 的情况下,LoRA 可以应用于将图像表示与描述它们的提示相关联的交叉注意层。下图的细节 (摘自 Stable Diffusion 论文) 并不重要,只需要注意黄色块是负责建立图文之间的关系表示就行。

潜在扩散架构
Lora用作模型增量风格实例

2d风格图

lora做了光照、3d风格把2d转3d风格
生产工序
图片输入前前置处理工序(图片对齐、图片打标)
图片打标
CodeFormer(pth权重文件)(图片&脸部修复)
下载pth到对应文件夹下
torch_deepdanbooru(现在deepdanbooru的模型读取路径)
把pt权重文件下到该路径即可
deepbooru( 老黄历现在不需要了 只需准备上面torch_deepdanbooru的权重文件 deepbooru 分析图片的tag&自训练前对数据集的文本分析)
安装相应依赖 (注意依赖中包含tensorflow及tensorflow-io)
解压后放到models/deepbooru目录下即可
ESRGAN(图片修复)
下载pth到对应文件夹下
GFPGAN(用于三次元脸部修复的GAN)
下载pth到对应文件夹下
LDSR(用LDM来提升分辨率)
下载pth到对应文件夹下并改名为model.ckpt
SwinIR(另一种提升分辨率的模型)
下载pth到对应文件夹下
mmdet (yolo实现的自动生成蒙版的插件的依赖存放路径)
outpaint
当数据集比例不一时、可以通过outpaint外绘来统一、避免裁掉很多细节
示例:9:16 -> 1:1

图片经过几道引擎生产
图片后处理工序(图片质量打分、图片修改、)
aesthetic-gradients(根据美学权重优化图片)
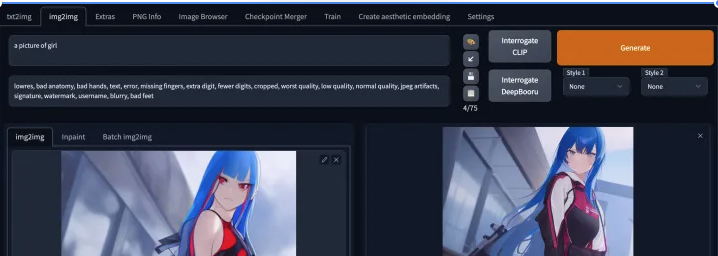
图片修改-loopback 迭代草图
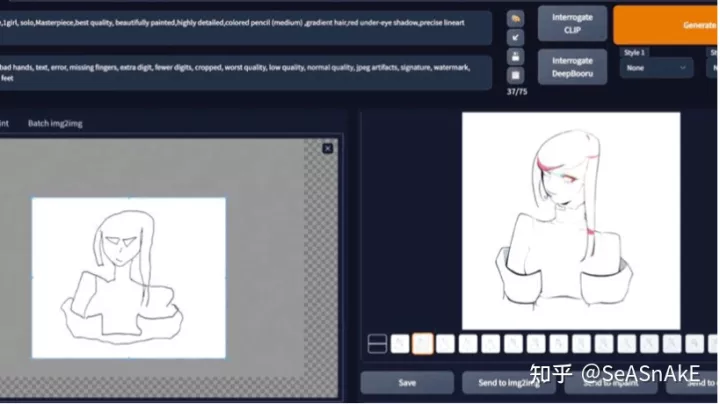
(loopback还可配合inpaint进行修图、类似ps 美图秀秀里的修补功能)

工艺组合成piepleline
例子跟进,1周内更新一个版本
例子
https://github.com/idpen/finetune-stable-diffusion
文章出处登录后可见!