兜兜转转还是来到了C++,欠的债该还的得还,因此本篇文章试图从C++来撬动tensorrt 完成转换模型和推理,而不是借助python库
文章目录
前言
希望本篇文章结束后,我能回答两个问题:
- python不好用么,为什么还要转C++; yolov5的export.py 已经实现在python端的模型转化了啊?
不需要c++的可以看这个《【深度学习】目标检测 yolov5模型量化安装教程以及转ONXX,torchscript,engine和速度比较一栏表》 - C++的学习曲线那么陡峭,性能在服务器端不如go,所以为什么不是go?
go 在服务器端性能牛,但是在终端设备不咋样,所以从这个角度,还是C++
一、Tensorrt前置
首先需要有个环境,搭建环境的指引《【深度学习】基于深度学习的linux服务器,需要搭建哪些服务,一步步搭建深度学习的环境,cuda,pytorch,opencv,ftp服务, nfs服务 docker等等》
文章很长,是深度学习的最大化安装,基于进入Tensorrt的操作,至少要安装显卡驱动,cuda,cudann,tensorrt,gpu的torch环境,并且他们之间的版本要匹配。老实说,新手直接绕道《【深度学习】目标检测 yolov5模型量化安装教程以及转ONXX,torchscript,engine和速度比较一栏表》
读到后面你会发现,我在模型转换的时候,踩了yolov的各种坑,你会看到我用yolov5的 tag7.0 tag6.1 tag6.2 都有问题.
尚不清楚是pytorch的版本问题,还是tensorrt的版本问题,我再量化那篇文章用的是pytorch1.8 没遇到问题.
1.1 Tensorrt基本概念
本章节你将了解TensorRT中的以下几个关键概念:Runtime、CudaEngine、ExecutionContext、与Binding。
在使用ONNX Runtime的Python API执行模型推演大致分四步:
-
初始化:使用onnx格式存储的模型文件初始化 InferenceSession 。
-
预处理:将输入数据做预处理。
-
执行推演:调用 run 方法执行模型推演,获得模型输出。
-
后处理:执行后处理逻辑。
TensorRT的推演与其类似,只是要更加复杂一些: -
模型准备:TensorRT使用私有模型格式,其它格式的模型文件如ONNX需要先完成转换才可以被使用。该转换过程可以通过调 用TensorRT的C++或者Python API来在线实现,也可以通过 trtexec 这个工具离线完成。
-
初始化:包括初始化运行时 Runtime ,使用 Runtime 加载模型文件形成 CudaEngine ,再基于 CudaEngine 创建 ExecutionContext ;这三者组合起来可以大致等同为 ONNX Runtime中的 InferenceSession 。此外还需要按照模型的输入与输出规格分别申请CPU一侧的内存与GPU一侧的显存,指向这些存储区域的指针集合称为 Binding 。
-
将输入数据做预处理,然后将其从CPU侧存储(内存)拷贝到GPU侧存储(显存)。
-
调用 ExecutionContext 的enqueueV2 方法异步执行模型推演,然后调用 cudaStreamSynchronize 方法同步结果,获得模型输出。
-
将输出结果从GPU侧存储(显存)拷贝到CPU侧存储(内存),然后执行后处理逻辑。
1.2 异步推演说明
TensorRT支持同步与异步推演,这里以异步推演作为说明实例。
与ONNX Runtime Python API的推演流程相比,TensorRT C++ API推演明显有着更加底层、更加细粒度的数据与流程控制。这些正是使用C++作为开发语言与Python相比所带来的主要区别。
接下来,你将通过YOLO v5这个实例来掌握TensorRT的实际使用过程。本章节所涉及到的概念都会出现在代码中,希望到时候你看到它们时不会感觉太陌生。
二、实战YOLO V5推演
本章节你将借助YOLO v5模型推演的完整代码掌握TensorRT C++ 推演API,以及将ONNX格式神经网络模型转换为TensorRT专用格式的具体方法。
YOLO v5是一款在物体检测领域颇为流行的神经网络模型。在这里我们不会深入探究其原理与设计,而将直接使用GitHub上的一款开源实现所生成的预训练模型。在此基础上,本章节展示了以下内容。
- 使用TensorRT的 trtexec 工具将ONNX模型文件转换为TensorRT的Engine格式。
- 使用CMake构建TensorRT工程。
- 使用OpenCV实现输入图像读取与存储。
- YOLO v5模型预处理与后处理。
- 使用TensorRT实现YOLO v5模型推演。
让我们开始吧!
1.TensorRT模型转换
首先下载YOLO v5预训练好的模型权重文件,其地址为:
https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.pt
然后遵循官方教程,导出ONNX格式模型:
代码如下(示例):
在写一次吧,安装
pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime-gpu openvino-dev tensorflow # GPU
其实只需要onnx相关的,其它的有tf使用的,apple使用的opencv使用的,用不到 ,我这里偷个懒,安装少的
pip install -r requirements.txt onnx onnxruntime-gpu # GPU
上边这一步完成后,你应当获得一个ONNX格式模型文件 yolov5s.onnx 。
转换一版试一下:
python export.py --weights weights/yolov5s.pt -- --include onnx engine
转化报错,原因是:https://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html,默认安装的1.13,匹配11.6的吗我的是11.4,换回来重新运行
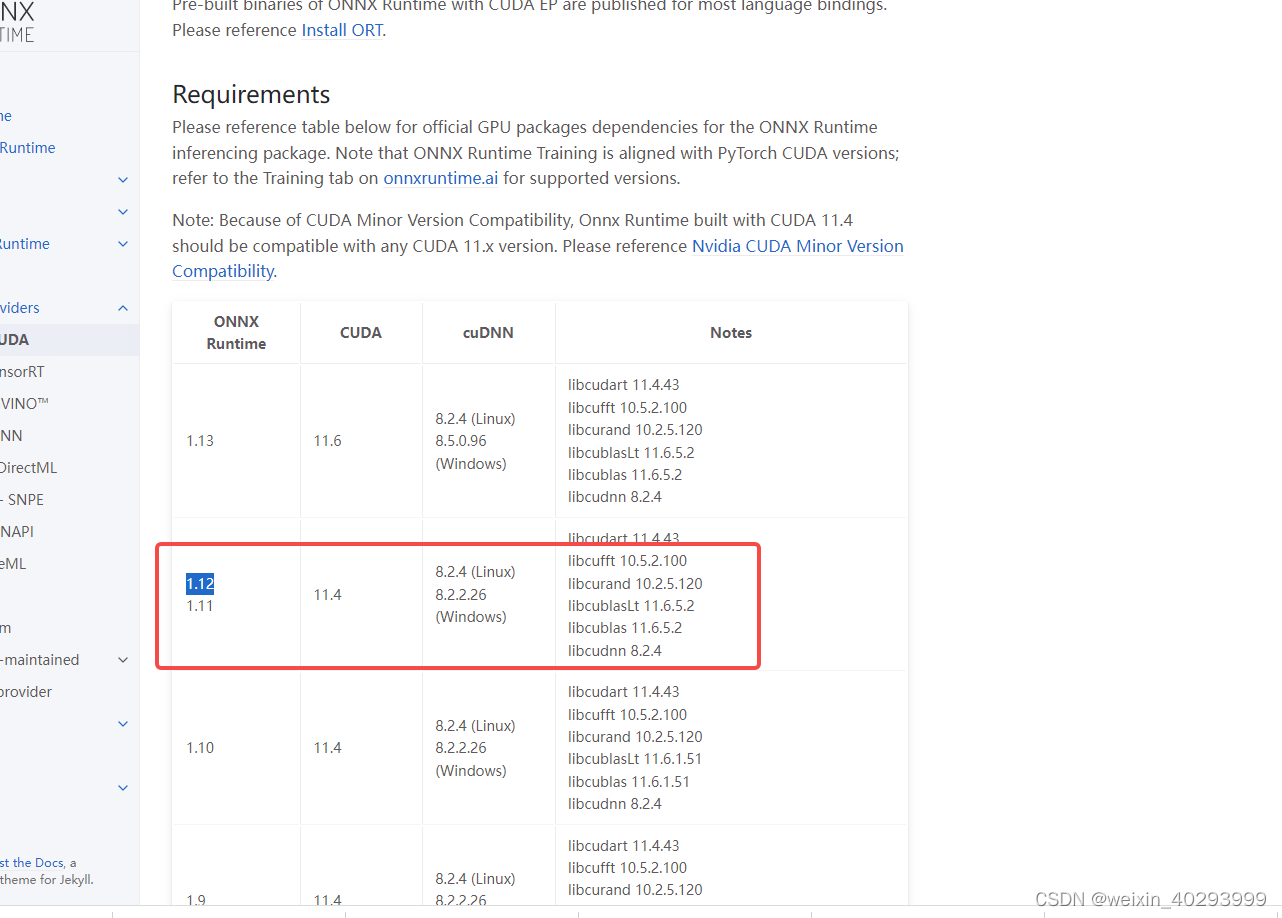
接下来,使用如下命令将其转换为TensoRT格式模型文件。
还是报错
[8] Assertion failed: scales.is_weights() && "Resize scales must be an initializer!"
TensorRT: export failure ❌ 4.3s: failed to load ONNX file: weights/yolov5s.onnx
解决问题指引:
https://blog.csdn.net/zaf0516/article/details/122932651
snap install netron
pip install onnx-simplifier
pip install onnx_graphsurgeon --index-url https://pypi.ngc.nvidia.com
还是报错:
指引是改模型,我偷个懒,退一下版本 yolov5 tag6.2搞下来试一试,现在用的是最新的用于分割的tag7.0
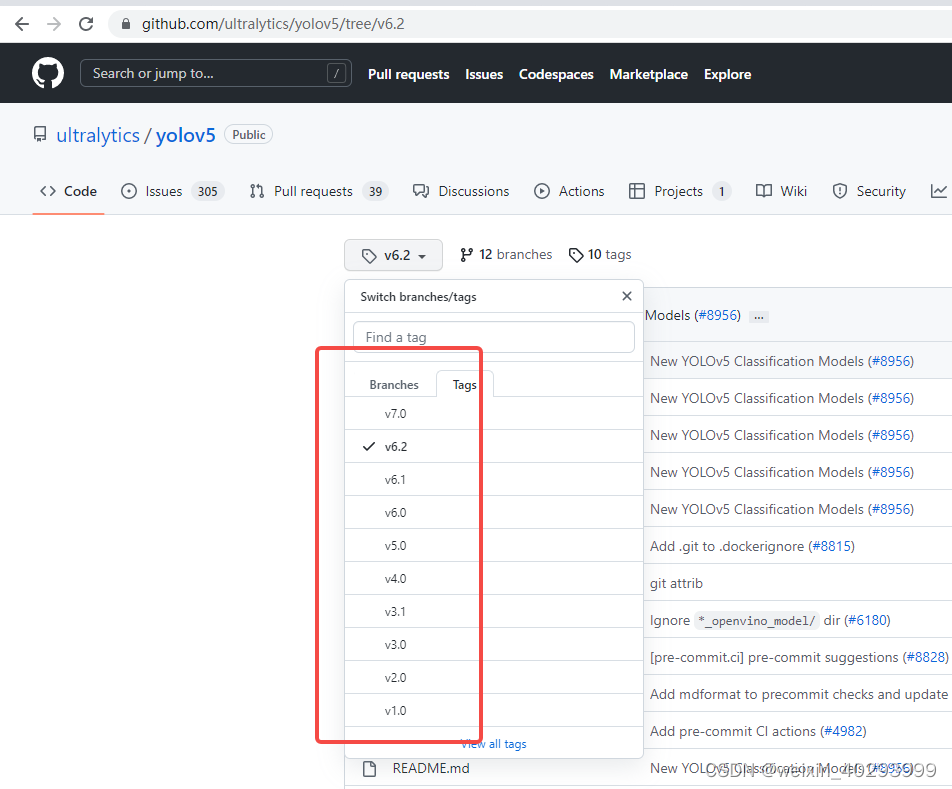
都是相同的错误,先不改了,直接转onnx是可以的
python export.py --weights weights/yolov5s.pt --device 0 --include onnx
切換到6.1 上面報錯,解決指引
https://blog.csdn.net/Thebest_jack/article/details/124723687
然后转换engine
trtexec --onnx=weights/yolov5s.onnx --saveEngine=yolov5s.engine
问题出来了,不管用7.0 还是 6.1, 6.2 都报错
[12/07/2022-20:49:09] [E] [TRT] ModelImporter.cpp:776: --- End node ---
[12/07/2022-20:49:09] [E] [TRT] ModelImporter.cpp:779: ERROR: builtin_op_importers.cpp:3609 In function importResize:
[8] Assertion failed: scales.is_weights() && "Resize scales must be an initializer!"
[12/07/2022-20:49:09] [E] Failed to parse onnx file
[12/07/2022-20:49:09] [I] Finish parsing network model
[12/07/2022-20:49:09] [E] Parsing model failed
[12/07/2022-20:49:09] [E] Failed to create engine from model.
[12/07/2022-20:49:09] [E] Engine set up failed
&&&& FAILED TensorRT.trtexec [TensorRT v8205] # trtexec --onnx=weights/yolov5s.onnx --saveEngine=yolov5s.engine
python 命令和trtexec命令都报错
trtexec --onnx=weights/yolov5s.onnx --saveEngine=yolov5s.engine
[12/07/2022-20:53:43] [E] [TRT] ModelImporter.cpp:776: --- End node ---
[12/07/2022-20:53:43] [E] [TRT] ModelImporter.cpp:779: ERROR: builtin_op_importers.cpp:3609 In function importResize:
[8] Assertion failed: scales.is_weights() && "Resize scales must be an initializer!"
[12/07/2022-20:53:43] [E] Failed to parse onnx file
[12/07/2022-20:53:43] [I] Finish parsing network model
[12/07/2022-20:53:43] [E] Parsing model failed
[12/07/2022-20:53:43] [E] Failed to create engine from model.
[12/07/2022-20:53:43] [E] Engine set up failed
&&&& FAILED TensorRT.trtexec [TensorRT v8205] # trtexec --onnx=weights/yolov5s.onnx --saveEngine=yolov5s.engine
python export.py --weights weights/yolov5s.pt --device 0 --include onnx engine
所以要替换模型了,明天见!
分割线,mmp今天阳性了,明天请了天假,今明两天搞定它!!!
restart 还是用yolov5 tag7.0
环境:
torch 1.12.1
torchaudio 0.12.1
torchvision 0.13.1
NVIDIA-SMI 470.63.01 Driver Version: 470.63.01 CUDA Version: 11.4
cuda:11.4
cudnn: cudann:cudnn-11.4-linux-x64-v8.2.4.15.tgz 8.2.4
tensorrt: 8.2.5.1
我会以这个环境为起点,试图debug,让他在yolov5的项目包python export.py 转onnx 和 engine都成功!
错误再现
(base) [root@localhost road_water_yolov5-7.0]# python export.py --weights weights/yolov5s.pt --device 0 --include onnx engine
export: data=data/coco128.yaml, weights=['weights/yolov5s.pt'], imgsz=[640, 640], batch_size=1, device=0, half=False, inplace=False, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=12, verbose=False, workspace=4, nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45, conf_thres=0.25, include=['onnx', 'engine']
Unknown option: -C
usage: git [--version] [--help] [-c name=value]
[--exec-path[=<path>]] [--html-path] [--man-path] [--info-path]
[-p|--paginate|--no-pager] [--no-replace-objects] [--bare]
[--git-dir=<path>] [--work-tree=<path>] [--namespace=<name>]
<command> [<args>]
YOLOv5 🚀 2022-12-2 Python-3.9.12 torch-1.12.1 CUDA:0 (NVIDIA GeForce RTX 3080 Ti, 12054MiB)
Fusing layers...
YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients, 16.4 GFLOPs
PyTorch: starting from weights/yolov5s.pt with output shape (1, 25200, 85) (14.1 MB)
ONNX: starting export with onnx 1.12.0...
ONNX: export success ✅ 2.7s, saved as weights/yolov5s.onnx (28.0 MB)
TensorRT: starting export with TensorRT 8.2.5.1...
[12/08/2022-18:42:33] [TRT] [I] [MemUsageChange] Init CUDA: CPU +466, GPU +0, now: CPU 3433, GPU 1917 (MiB)
[12/08/2022-18:42:34] [TRT] [I] [MemUsageSnapshot] Begin constructing builder kernel library: CPU 3433 MiB, GPU 1917 MiB
[12/08/2022-18:42:34] [TRT] [I] [MemUsageSnapshot] End constructing builder kernel library: CPU 3586 MiB, GPU 1961 MiB
[12/08/2022-18:42:34] [TRT] [I] ----------------------------------------------------------------
[12/08/2022-18:42:34] [TRT] [I] Input filename: weights/yolov5s.onnx
[12/08/2022-18:42:34] [TRT] [I] ONNX IR version: 0.0.7
[12/08/2022-18:42:34] [TRT] [I] Opset version: 12
[12/08/2022-18:42:34] [TRT] [I] Producer name: pytorch
[12/08/2022-18:42:34] [TRT] [I] Producer version: 1.12.1
[12/08/2022-18:42:34] [TRT] [I] Domain:
[12/08/2022-18:42:34] [TRT] [I] Model version: 0
[12/08/2022-18:42:34] [TRT] [I] Doc string:
[12/08/2022-18:42:34] [TRT] [I] ----------------------------------------------------------------
[12/08/2022-18:42:34] [TRT] [W] onnx2trt_utils.cpp:366: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
[12/08/2022-18:42:34] [TRT] [E] ModelImporter.cpp:773: While parsing node number 141 [Resize -> "onnx::Concat_271"]:
[12/08/2022-18:42:34] [TRT] [E] ModelImporter.cpp:774: --- Begin node ---
[12/08/2022-18:42:34] [TRT] [E] ModelImporter.cpp:775: input: "onnx::Resize_266"
input: "onnx::Resize_270"
input: "onnx::Resize_445"
output: "onnx::Concat_271"
name: "Resize_141"
op_type: "Resize"
attribute {
name: "coordinate_transformation_mode"
s: "asymmetric"
type: STRING
}
attribute {
name: "cubic_coeff_a"
f: -0.75
type: FLOAT
}
attribute {
name: "mode"
s: "nearest"
type: STRING
}
attribute {
name: "nearest_mode"
s: "floor"
type: STRING
}
[12/08/2022-18:42:34] [TRT] [E] ModelImporter.cpp:776: --- End node ---
[12/08/2022-18:42:34] [TRT] [E] ModelImporter.cpp:779: ERROR: builtin_op_importers.cpp:3609 In function importResize:
[8] Assertion failed: scales.is_weights() && "Resize scales must be an initializer!"
TensorRT: export failure ❌ 4.1s: failed to load ONNX file: weights/yolov5s.onnx
ONNX: starting export with onnx 1.12.0...
ONNX: export success ✅ 2.6s, saved as weights/yolov5s.onnx (28.0 MB)
Export complete (11.8s)
Results saved to /root/workplace/road_water_yolov5-7.0/weights
Detect: python detect.py --weights weights/yolov5s.onnx
Validate: python val.py --weights weights/yolov5s.onnx
PyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'weights/yolov5s.onnx')
Visualize: https://netron.app
onnx 转换成功了,.engine没有
用c++的方式转换:
(base) [root@localhost road_water_yolov5-7.0]# trtexec --onnx=weights/yolov5s.onnx --saveEngine=yolov5s.engine
&&&& RUNNING TensorRT.trtexec [TensorRT v8205] # trtexec --onnx=weights/yolov5s.onnx --saveEngine=yolov5s.engine
[12/08/2022-18:48:42] [I] === Model Options ===
[12/08/2022-18:48:42] [I] Format: ONNX
[12/08/2022-18:48:42] [I] Model: weights/yolov5s.onnx
[12/08/2022-18:48:42] [I] Output:
[12/08/2022-18:48:42] [I] === Build Options ===
[12/08/2022-18:48:42] [I] Max batch: explicit batch
[12/08/2022-18:48:42] [I] Workspace: 16 MiB
[12/08/2022-18:48:42] [I] minTiming: 1
[12/08/2022-18:48:42] [I] avgTiming: 8
[12/08/2022-18:48:42] [I] Precision: FP32
[12/08/2022-18:48:42] [I] Calibration:
[12/08/2022-18:48:42] [I] Refit: Disabled
[12/08/2022-18:48:42] [I] Sparsity: Disabled
[12/08/2022-18:48:42] [I] Safe mode: Disabled
[12/08/2022-18:48:42] [I] DirectIO mode: Disabled
[12/08/2022-18:48:42] [I] Restricted mode: Disabled
[12/08/2022-18:48:42] [I] Save engine: yolov5s.engine
[12/08/2022-18:48:42] [I] Load engine:
[12/08/2022-18:48:42] [I] Profiling verbosity: 0
[12/08/2022-18:48:42] [I] Tactic sources: Using default tactic sources
[12/08/2022-18:48:42] [I] timingCacheMode: local
[12/08/2022-18:48:42] [I] timingCacheFile:
[12/08/2022-18:48:42] [I] Input(s)s format: fp32:CHW
[12/08/2022-18:48:42] [I] Output(s)s format: fp32:CHW
[12/08/2022-18:48:42] [I] Input build shapes: model
[12/08/2022-18:48:42] [I] Input calibration shapes: model
[12/08/2022-18:48:42] [I] === System Options ===
[12/08/2022-18:48:42] [I] Device: 0
[12/08/2022-18:48:42] [I] DLACore:
[12/08/2022-18:48:42] [I] Plugins:
[12/08/2022-18:48:42] [I] === Inference Options ===
[12/08/2022-18:48:42] [I] Batch: Explicit
[12/08/2022-18:48:42] [I] Input inference shapes: model
[12/08/2022-18:48:42] [I] Iterations: 10
[12/08/2022-18:48:42] [I] Duration: 3s (+ 200ms warm up)
[12/08/2022-18:48:42] [I] Sleep time: 0ms
[12/08/2022-18:48:42] [I] Idle time: 0ms
[12/08/2022-18:48:42] [I] Streams: 1
[12/08/2022-18:48:42] [I] ExposeDMA: Disabled
[12/08/2022-18:48:42] [I] Data transfers: Enabled
[12/08/2022-18:48:42] [I] Spin-wait: Disabled
[12/08/2022-18:48:42] [I] Multithreading: Disabled
[12/08/2022-18:48:42] [I] CUDA Graph: Disabled
[12/08/2022-18:48:42] [I] Separate profiling: Disabled
[12/08/2022-18:48:42] [I] Time Deserialize: Disabled
[12/08/2022-18:48:42] [I] Time Refit: Disabled
[12/08/2022-18:48:42] [I] Skip inference: Disabled
[12/08/2022-18:48:42] [I] Inputs:
[12/08/2022-18:48:42] [I] === Reporting Options ===
[12/08/2022-18:48:42] [I] Verbose: Disabled
[12/08/2022-18:48:42] [I] Averages: 10 inferences
[12/08/2022-18:48:42] [I] Percentile: 99
[12/08/2022-18:48:42] [I] Dump refittable layers:Disabled
[12/08/2022-18:48:42] [I] Dump output: Disabled
[12/08/2022-18:48:42] [I] Profile: Disabled
[12/08/2022-18:48:42] [I] Export timing to JSON file:
[12/08/2022-18:48:42] [I] Export output to JSON file:
[12/08/2022-18:48:42] [I] Export profile to JSON file:
[12/08/2022-18:48:42] [I]
[12/08/2022-18:48:42] [I] === Device Information ===
[12/08/2022-18:48:42] [I] Selected Device: NVIDIA GeForce RTX 3080 Ti
[12/08/2022-18:48:42] [I] Compute Capability: 8.6
[12/08/2022-18:48:42] [I] SMs: 80
[12/08/2022-18:48:42] [I] Compute Clock Rate: 1.665 GHz
[12/08/2022-18:48:42] [I] Device Global Memory: 12053 MiB
[12/08/2022-18:48:42] [I] Shared Memory per SM: 100 KiB
[12/08/2022-18:48:42] [I] Memory Bus Width: 384 bits (ECC disabled)
[12/08/2022-18:48:42] [I] Memory Clock Rate: 9.501 GHz
[12/08/2022-18:48:42] [I]
[12/08/2022-18:48:42] [I] TensorRT version: 8.2.5
[12/08/2022-18:48:43] [I] [TRT] [MemUsageChange] Init CUDA: CPU +474, GPU +0, now: CPU 486, GPU 491 (MiB)
[12/08/2022-18:48:43] [I] [TRT] [MemUsageSnapshot] Begin constructing builder kernel library: CPU 486 MiB, GPU 491 MiB
[12/08/2022-18:48:43] [I] [TRT] [MemUsageSnapshot] End constructing builder kernel library: CPU 640 MiB, GPU 533 MiB
[12/08/2022-18:48:43] [I] Start parsing network model
[12/08/2022-18:48:43] [I] [TRT] ----------------------------------------------------------------
[12/08/2022-18:48:43] [I] [TRT] Input filename: weights/yolov5s.onnx
[12/08/2022-18:48:43] [I] [TRT] ONNX IR version: 0.0.7
[12/08/2022-18:48:43] [I] [TRT] Opset version: 12
[12/08/2022-18:48:43] [I] [TRT] Producer name: pytorch
[12/08/2022-18:48:43] [I] [TRT] Producer version: 1.12.1
[12/08/2022-18:48:43] [I] [TRT] Domain:
[12/08/2022-18:48:43] [I] [TRT] Model version: 0
[12/08/2022-18:48:43] [I] [TRT] Doc string:
[12/08/2022-18:48:43] [I] [TRT] ----------------------------------------------------------------
[12/08/2022-18:48:43] [W] [TRT] onnx2trt_utils.cpp:366: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
[12/08/2022-18:48:43] [E] [TRT] ModelImporter.cpp:773: While parsing node number 141 [Resize -> "onnx::Concat_271"]:
[12/08/2022-18:48:43] [E] [TRT] ModelImporter.cpp:774: --- Begin node ---
[12/08/2022-18:48:43] [E] [TRT] ModelImporter.cpp:775: input: "onnx::Resize_266"
input: "onnx::Resize_270"
input: "onnx::Resize_445"
output: "onnx::Concat_271"
name: "Resize_141"
op_type: "Resize"
attribute {
name: "coordinate_transformation_mode"
s: "asymmetric"
type: STRING
}
attribute {
name: "cubic_coeff_a"
f: -0.75
type: FLOAT
}
attribute {
name: "mode"
s: "nearest"
type: STRING
}
attribute {
name: "nearest_mode"
s: "floor"
type: STRING
}
[12/08/2022-18:48:43] [E] [TRT] ModelImporter.cpp:776: --- End node ---
[12/08/2022-18:48:43] [E] [TRT] ModelImporter.cpp:779: ERROR: builtin_op_importers.cpp:3609 In function importResize:
[8] Assertion failed: scales.is_weights() && "Resize scales must be an initializer!"
[12/08/2022-18:48:43] [E] Failed to parse onnx file
[12/08/2022-18:48:43] [I] Finish parsing network model
[12/08/2022-18:48:43] [E] Parsing model failed
[12/08/2022-18:48:43] [E] Failed to create engine from model.
[12/08/2022-18:48:43] [E] Engine set up failed
&&&& FAILED TensorRT.trtexec [TensorRT v8205] # trtexec --onnx=weights/yolov5s.onnx --saveEngine=yolov5s.engine
问题再一次明晰:
python脚本转onnx能成功,但无论python还是C++由onnx转engine都失败!!!
而且从export.py的代码分析,python代码,也是调用的C++的
[8] Assertion failed: scales.is_weights() && “Resize scales must be an initializer!”
报错是这个,
1,目前不确认是onnx不能供转化engine使用,还是engine的转换代码有问题
2,不确认是pytorch的版本问题,还是yolov的版本问题,还是tensorrt的版本问题
我们假设:onnx没问题,是转换.engine有问题, 有onnx.load 的几个文件
(base) [root@localhost python3.9]# grep -r onnx.load /root/miniconda3/pkgs
/root/miniconda3/pkgs/pytorch-1.12.1-py3.9_cuda11.3_cudnn8.3.2_0/lib/python3.9/site-packages/torch/utils/tensorboard/_onnx_graph.py: m = onnx.load(fname)
/root/miniconda3/pkgs/pytorch-1.12.1-py3.9_cuda11.3_cudnn8.3.2_0/lib/python3.9/site-packages/caffe2/python/onnx/backend.py: model = onnx.load(f);
/root/miniconda3/pkgs/pytorch-1.12.1-py3.9_cuda11.3_cudnn8.3.2_0/lib/python3.9/site-packages/caffe2/python/trt/test_trt.py: model_def = onnx.load(os.path.join(model_dir, 'model.onnx'))
/root/miniconda3/pkgs/pytorch-1.12.1-py3.9_cuda11.3_cudnn8.3.2_0/lib/python3.9/site-packages/caffe2/contrib/aten/docs/sample.py:graph = onnx.load(f.name)
用一个图片来推理,验证假设,mmp todesk连不到公司了 睡觉!!!
在家用wls2 的ubuntu系统试试,基础情况
torch 1.13.0+cu116
torchaudio 0.13.0+cu116
torchvision 0.14.0+cu116
nvidia-smi -l
Fri Dec 9 03:52:56 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 510.73.01 Driver Version: 512.78 CUDA Version: 11.6 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... On | 00000000:01:00.0 Off | N/A |
| N/A 51C P0 25W / N/A | 0MiB / 8192MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
(base) justin@DESKTOP-NIK28BI:~/software$ nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Tue_Mar__8_18:18:20_PST_2022
Cuda compilation tools, release 11.6, V11.6.124
Build cuda_11.6.r11.6/compiler.31057947_0
cuda: cuda_11.6.2_510.47.03_linux.run
cudann: cudnn-linux-x86_64-8.5.0.96_cuda11-archive.tar.xz
# tensorrt
version="8.5.1.7"
arch=$(uname -m)
cuda="cuda-11.6"
cudnn="cudnn8.5"
tar -xzvf TensorRT-${version}.Linux.${arch}-gnu.${cuda}.${cudnn}.tar.gz
用的是yolov5 最新的包,应该是tag7.0
执行转换命令
python export.py --weights weights/yolov5s.pt --device 0 --include onnx engine
都转换成功了!!! 问题明晰,可能是torch版本的问题
/usr/local/TensorRT-8.5.1.7/bin/trtexec --onnx=weights/yolov5s.onnx --saveEngine=weights/yolov5s.engine
用c++ 也能转出来.
————————————————————————————————————–分割线——————————————————————————————————————————-
3. 再来一遍
2023.1.13
cudnn的版本在这里
/usr/local/cuda-11.1/include/cudnn_version.h
环境:cuda 11.1
#ifndef CUDNN_VERSION_H_
#define CUDNN_VERSION_H_
#define CUDNN_MAJOR 8
#define CUDNN_MINOR 0
#define CUDNN_PATCHLEVEL 5
cudnn:8.05
tenssort:TensorRT v8501
yolov5tag7
转化命令
trtexec --onnx=yolov5s-seg.onnx --saveEngine=yolov5s-seg.engine
trtexec找不到的话,再解压包的这里/usr/local/TensorRT-8.5.1.7/bin/trtexec
我是把他mv到/usr/local 下了 你可以export 或者绝对路径使用
最后输出这个,说明成功了。

能转化成功,但是安装opencv的C++版本装不上,换了2台server都装不上
···········································································
2023.1.18
在docker 上搞
升级cmake指引:https://www.lhl.zone/Linux/33.html
ref:https://blog.csdn.net/qq_41043389/article/details/127754384
opencv C++的安装指引:https://docs.opencv.org/4.5.5/d7/d9f/tutorial_linux_install.html
opencv 的下载:https://opencv.org/releases/
我安装的是4.5.5, 安装成功了。哈哈~
cudnn的版本在这里
/usr/local/cuda-11.1/include/cudnn_version.h
环境:cuda 11.1
#ifndef CUDNN_VERSION_H_
#define CUDNN_VERSION_H_
#define CUDNN_MAJOR 8
#define CUDNN_MINOR 0
#define CUDNN_PATCHLEVEL 5
cudnn:8.05
tenssort:TensorRT v8501
yolov5tag7
转化命令
trtexec --onnx=yolov5s-seg.onnx --saveEngine=yolov5s-seg.engine
trtexec找不到的话,再解压包的这里/usr/local/TensorRT-8.5.1.7/bin/trtexec
我是把他mv到/usr/local 下了 你可以export 或者绝对路径使用
最后输出这个,说明成功了。
······································
走这个blog指引的时候 走不通,找不到cuda环境。哎~。
https://blog.csdn.net/qq_41043389/article/details/127754384
报错也先记录一下:
(py38) [root@localhost build]# cmake ..
-- The C compiler identification is GNU 4.8.5
-- The CXX compiler identification is GNU 4.8.5
-- Check for working C compiler: /usr/bin/cc
-- Check for working C compiler: /usr/bin/cc -- works
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Detecting C compile features
-- Detecting C compile features - done
-- Check for working CXX compiler: /usr/bin/c++
-- Check for working CXX compiler: /usr/bin/c++ -- works
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Found OpenCV: /usr/local (found version "4.5.5")
-- Found CUDA: /usr/local/cuda (found version "11.1")
-- libraries: /usr/local/cuda/lib64/libcudart.so
-- include path: /usr/local/cuda/include
CMake Error: Could not find cmake module file: CMakeDetermineCUDACompiler.cmake
CMake Error: Error required internal CMake variable not set, cmake may be not be built correctly.
Missing variable is:
CMAKE_CUDA_COMPILER_ENV_VAR
CMake Error: Could not find cmake module file: /app/Yolov5-instance-seg-tensorrt-main/build/CMakeFiles/3.7.2/CMakeCUDACompiler.cmake
CMake Error: Could not find cmake module file: CMakeCUDAInformation.cmake
CMake Error: Could not find cmake module file: CMakeTestCUDACompiler.cmake
-- Configuring incomplete, errors occurred!
See also "/app/Yolov5-instance-seg-tensorrt-main/build/CMakeFiles/CMakeOutput.log".
用docker安装首先要安装cmake,接着安装opencv2,还要安装gxx
我把history也贴出来
1 ls
2 python -V
3 pip list
4 pip uninstall python
5 pip uninstall python
6 which pip
7 conda uninstall python
8 ls
9 python -V
10 pip list
11 pip uninstall python
12 pip uninstall python
13 which pip
14 conda uninstall python
15 which pip
16 cat ~/.condarc
17 nvcc -V
18 python
19 conda create -n py38 python=3.8
20 conda activate py38
21 conda install pytorch1.8.0 torchvision0.9.0 torchaudio==0.8.0 cudatoolkit=11.1 -c pytorch -c conda-forge
22 ls
23 cd app
24 ls
25 pip install -r requirements.txt
26 conda install pytorch1.8.0 torchvision0.9.0 torchaudio==0.8.0 cudatoolkit=11.1 -c pytorch -c conda-forge
27 conda install pytorch1.8.0 torchvision0.9.0 torchaudio==0.8.0 cudatoolkit=11.1 -c pytorch -c conda-forge
28 conda activate py38
29 import tensorrt
30 python
31 import torch
32 python
33 echo $LD_LIBRARY_PATH
34 find / -name libnvinfer.so.8
35 vim ~/.bashrc
36 fg
37 source ~/.bashrc
38 vim ~/.bashrc
39 vim /etc/profile
40 source /etc/profile
41 source ~/.bashrc
42 conda env list
43 ls
44 cd app/
45 ls
46 cd weights/
47 ls
48 which trtexec
49 /software/TensorRT-8.5.1.7/bin/trtexec --onnx=yolov5m6.onnx --saveEngine=yolov5m6.engine
50 export LD_LIBRARY_PATH=/software/TensorRT-8.5.1.7/targets/x86_64-linux-gnu/lib:$LD_LIBRARY_PATH
51 /software/TensorRT-8.5.1.7/bin/trtexec --onnx=yolov5m6.onnx --saveEngine=yolov5m6.engine
52 程cd 。。
53 cd。 ..
54 cd ..
55 ls
56 cd cpp_project/
57 g++ -verson
58 g++ -V
59 g++ --help
60 g++ --version
61 ls
62 g++ yolov5_trt.cpp
63 which yum
64 yum install glog-devel
65 yum install glog-devel
66 yum install gflags-devel glog-devel
67 cd /software/
68 wget https://google-glog.googlecode.com/files/glog-0.3.3.tar.gz
69 ls
70 ls -alh
71 sudo chmod -R 0777 glog-0.3.3.tar.gz
72 chmod -R 0777 glog-0.3.3.tar.gz
73 tar glog-0.3.3.tar.gz
74 tar zxvf glog-0.3.3.tar.gz
75 cd glog-0.3.3
76 ./configure
77 make && make install
78 cd /app/
79 cd cpp_project/
80 history
81 g++ yolov5_trt.cpp
82 cd /software/
83 ls
84 unzip opencv-4.5.5.zip
85 yum install unzip
86 unzip opencv-4.5.5.zip
87 mkdir -p build && cd build
88 cmake ../opencv-4.5.5
89 cd ..
90 ;s
91 ;s
92 ls
93 tar -zxvf cmake-3.25.1.tar.gz
94 cd cmake-3.25.1
95 ls -alh
96 ./bootstrap
97 yum install libssl-dev
98 yum install openssl
99 yum install openssl-devel
100 ./bootstrap
101 make
102 make install
103 cd -
104 ls
105 cd /app/
106 ;s
107 ls
108 cd cpp_project/
109 ls
110 history | grep gcc
111 history | grep g++
112 g++ yolov5_trt.cpp
113 cd /software/
114 ls
115 cd build/
116 cmake ../opencv-4.5.5
117 cmake --build .
118 make -j4
119 ls bin
120 ls lib
121 ls OpenCVConfig*.cmake
122 ls
123 make install
124 程cd ▒/app
125 cd /app/
126 ls
127 cd cpp_project/
128 ls
129 history | grep g++
130 ▒g++ yolov5_trt.cpp
131 g++ yolov5_trt.cpp
132 cd ..
133 ls
134 cd ..
135 cd software/
136 ls
137 unzip opencv-2.4.13.6.zip
138 cd opencv-2.4.13.6
139 mkdir release
140 cd release/
141 cmake -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/usr/local ..
142 cmake -D CMAKE_BUILD_TYPE=RELEASE -DCMAKE_INSTALL_PREFIX=/usr/local ..
143 cmake -DCMAKE_BUILD_TYPE=RELEASE -DCMAKE_INSTALL_PREFIX=/usr/local ..
144 cd ..
145 cd ..
146 ls
147 cd opencv-2.4.13.6
148 ls
149 rm -rf release/
150 mkdir release
151 cd release
152 cmake -DCMAKE_BUILD_TYPE=RELEASE -DCMAKE_INSTALL_PREFIX=/usr/local ..
153 make
154 cd /app/
155 g++ yolov5_trt.cpp
156 cd cpp_project/
157 g++ yolov5_trt.cpp
158 g++ yolov5_trt.cpp
159 cd /
160 ls
161 cd app/
162 ls
163 cd ..
164 ls
165 cd /app/
166 ls
167 cd ..
168 ls
169 ps
170 ls
171 cd opt/
172 ls
173 cd ..
174 cd app/
175 ls
176 cd ..
177 ls
178 ls
179 cd software/
180 ls
181 cd opencv-2.4.13.6
182 ls
183 cat CMakeLists.txt
184 cd ..
185 ls
186 rm -rf opencv-2.4.13.6
187 unzip opencv-2.4.13.6.zip
188 rm -rf build/
189 cd opencv-2.4.13.6
190 mkdir build && cd build
191 cmake ..
192 make -j4
193 ls
194 cd ..
195 ls
196 vim CMakeLists.txt
197 grep -rn "compute"
198 grep -rn "compute_20"
199 rm -rf build/
200 grep -rn "compute_20"
201 mkdir build && cd build
202 cd ..
203 ls
204 vim CMakeLists.txt
205 mkdir build && cd build
206 rm -rf build/
207 mkdir build && cd build
208 cmake .. -DCMAKE_BUILD_TYPE=Release -DCUDA_nppi_LIBRARY=true -DWITH_CUDA=OFF -DBUILD_TIFF=ON
209 make -j4
210 make install
211 opencv_vision
212 cd ..
213 ls
214 cd ..
215 ls
216 cd ..
217 cd app/
218 cd cpp_project/
219 history | grep g++
220 ▒g++ yolov5_trt.cpp
221 g++ yolov5_trt.cpp
222 find / NvInfer.h
223 echo PATH
224 echo $PATH
225 ls
226 cd /software/
227 ls
228 cd TensorRT-8.5.1.7
229 ls
230 pwd
231 cd ..
232 ls
233 cd ..
234 ls
235 cd app/
236 ls
237 cd cpp_project/
238 g++ yolov5_trt.cpp
239 g++ yolov5_trt.cpp
240 find -name NvInfer.h
241 cd /
242 find -name NvInfer.h
243 cd app/cpp_project/
244 g++ yolov5_trt.cpp
245 find / -name cuda_runtime_api.h
246 g++ yolov5_trt.cpp
247 g++ yolov5_trt.cpp
248 mv /software/TensorRT-8.5.1.7 /usr/local/
249 cp /usr/local/TensorRT-8.5.1.7/ /software/
250 cp -r /usr/local/TensorRT-8.5.1.7 /software/TensorRT-8.5.1.7
251 export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/TensorRT-8.5.1.7/lib
252 g++ yolov5_trt.cpp
253 g++ yolov5_trt.cpp
254 mkdir build && cd build
255 cmake ..
256 make
257 ls
258 cd ..
259 ls
260 cd build
261 ls
262 程cd ..
263 ls
264 cd ..
265 ls
266 g++ yolov5_trt.cpp
267 find / NvInfer.h
268 find / -name NvInfer.h
269 g++ yolov5_trt.cpp
270 g++ yolov5_trt.cpp
271 vim /usr/local/TensorRT-8.5.1.7/include/NvInferRuntimeCommon.h:19:30
272 vim /usr/local/TensorRT-8.5.1.7/include/NvInferRuntimeCommon.h 19
273 g++ yolov5_trt.cpp
274 find / -name cuda_runtime_api.h
275 vim /usr/local/TensorRT-8.5.1.7/include/NvInferRuntimeCommon.h 19
276 g++ yolov5_trt.cpp
277 find / -name NvOnnxParser.h
278 g++ yolov5_trt.cpp
279 find / -name cuda_runtime_api.h
280 g++ yolov5_trt.cpp
281 g++ yolov5_trt.cpp
282 g++ yolov5_trt.cpp
283 clear
284 g++ yolov5_trt.cpp
285 history
总结
没完成,但情况开始清晰:
1.环境冲突的问题已解决
2.主要是c++不灵光所致
c++不灵光包括cmakelist不会写,只能挨家挨户的找指引,其实应该自己写出一个c++版本的前后处理来掉yolov5.engine权重!!!加油
结论清晰了,补充c++ 和继续尝试去吧~!!!
20230130
文章出处登录后可见!