为什么要有神经网络
我们已经学会了线性回归和逻辑回归,它们在拟合曲线与划分类别方面的表现都还不错,为什么我们还需要神经网络呢?因为在许多应用场景中,特征值的数量远超之前练习中的规模,一张灰度图就包含成千上万的像素点信息,对于这样的问题,光是一次项就有成千上万个,若再考虑高次项,矩阵的大小将超出算法的承受范围。因此,我们需要可以更有效表示复杂多项式的工具——神经网络。
神经网络的基本结构
输入数据的一层为输入层,输出结果的一层为输出层,中间都是隐藏层(可以没有,也可以有不只一层)。
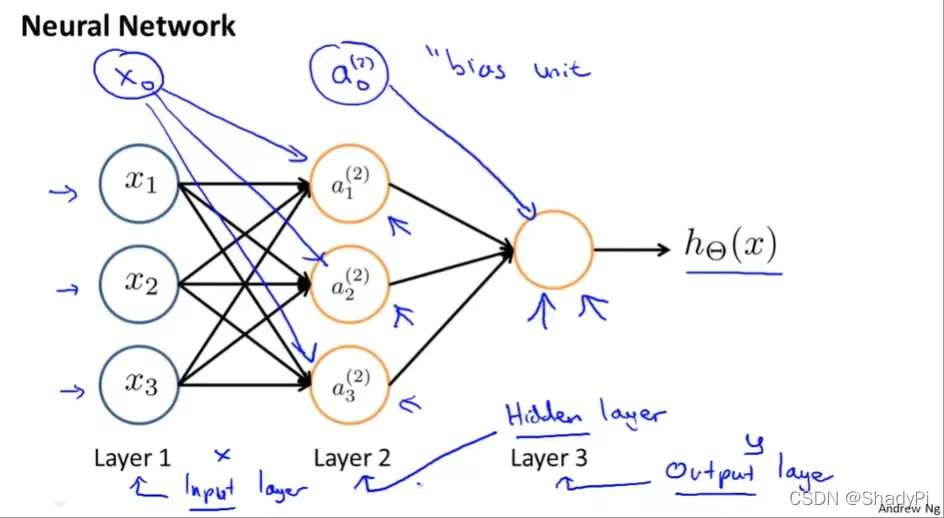
除了输入节点和由输入运算得到的节点一般还会在网络中加入偏置,即
。
我们定义为网络层数,
为第
层的节点个数。
为第
层第
个单元的值,而
表示从第
层向第
层的转移矩阵,其中
表示从
向
转移的权值,因此
的大小为
神经网络中的运算
正向传播
单个列向量传播
在输入层后续的节点中,我们都引入了逻辑函数,转移的代数形式为
很显然,层与层之间的转移可以写成矩阵运算形式,令
的
乘上
的
在套用逻辑函数就可以得到
完成一次从
层到
层的转移。注意这里
在运算之前要在加上偏置单位
,一般
。
矩阵传播
输入数据也有可能不止一个列向量,而是包含了多组数据的矩阵,令表示第
组数据中第
个特征值,输入矩阵
为
矩阵
此时,要进行向前传播运算,则先在矩阵左侧增加一列
,再乘以参数矩阵的转置,通过逻辑函数得到下一层,通用的矩阵算式为
这样做的好处是,矩阵始终是
行的,对应
个样本,添加偏置只需要在左侧加一列
的
向量就可以了,不过每次参数矩阵都要专职一下。
如此一直到输出层,找到每行最大值所在索引,就能知道每个样本被分到哪一类了。
反向传播
代价函数
正向传播是利用已有参数进行预测,要优化参数则需要反向传播,这时也要用到代价函数的概念。令为输出层的单元个数,一般为分类问题中种类的个数,则代价函数为
看起来很复杂,实际上只是把正则化逻辑回归代价函数的拟合程度部分扩展到了类,把正则项扩展到了
层的所有矩阵。可以与正则化逻辑回归代价函数比对起来观察:
计算误差
既然要修正,首先就要定义误差,表示第
层第
个单元的误差。显然,对于输出层,就有
,向量化之后就是
。
得到了输出层的误差,接下来就要反推之前所有隐藏层的误差了(输入层无误差)。大致的思路是误差乘以参数矩阵传递一下再乘以逻辑函数的倒数,即
其中,,故
最终得到的误差传播公式为
计算梯度
定义,矩阵运算形式为
将误差与单元激励值相乘并累加后,经过一系列很复杂以至于吴恩达没讲的推导以后,我们就得到了梯度的表达式:
注意为偏置,不参与正则化,故没有正则项。
综上,每次我们用已有参数进行一次向前传播,再进行一次向后传播修改参数,如此迭代多次就可以得到一个较准确的模型了。
版权声明:本文为博主ShadyPi原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/ShadyPi/article/details/122645573