目录
一、前言
1.1 Transformer在视觉领域上使用的难点
在NLP中,输入transformer中的是一个序列,而在视觉领域,需要考虑如何将一个2d图片转化为一个1d的序列,最直观的想法就是将图片中的像素点输入到transformer中,但是这样会有一个问题,因为模型训练中图片的大小是224*224=50176,而正常的bert的序列长度是512,是bert的100倍,这个的复杂度太高了。
1.2 输入序列长度的改进
如果直接输入像素点复杂度太高的话,就想着如何降低这部分的复杂度
1)使用网络中间的特征图
比如用res50最后一个stage res4 的feature map size只有14*14=196,序列长度是满足预期的
2)孤立自注意力
使用local window而不是整张图,输入的序列长度可以由windows size来控制
3)轴自注意力
将在2d图片上的自注意力操作改为分别在图片的高和宽两个维度上做self-attention,可以大大降低复杂度,但是由于目前硬件没有对这种操作做加速,很难支持大规模的数据量级。
1.3 VIT对输入的改进
先将图片切分成一个个patch,然后每一个patch作为一个token输入到transformer中,但是由于整个transformer每个token之间都会做attention,所以输入本身并不存在一个顺序问题。但是对于图片而言,每个patch之间是有顺序的,所以类比bert,给每个patch embedding加上一个position embedding(是sum)。同时最终的输出也借鉴了bert, 用0和cls来替代整体,这部分对应的embedding就是最终的输出。
二、Vision Transformer模型
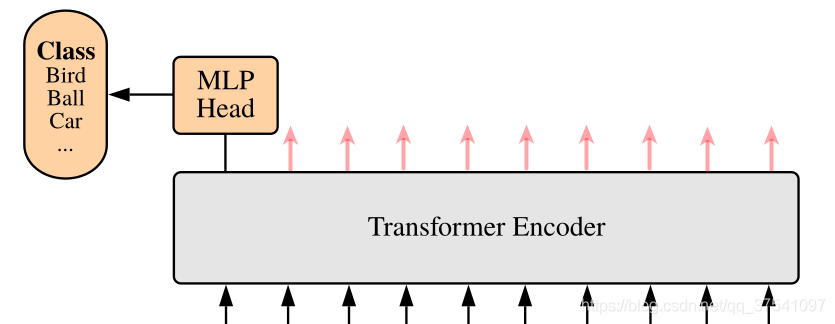
下图是原论文中给出的关于Vision Transformer(ViT)的模型框架。简单而言,模型由三个模块组成:
1.Linear Projection of Flattened Patches(Embedding层)
2.Transformer Encoder
3.MLP Head(最终用于分类的层结构)
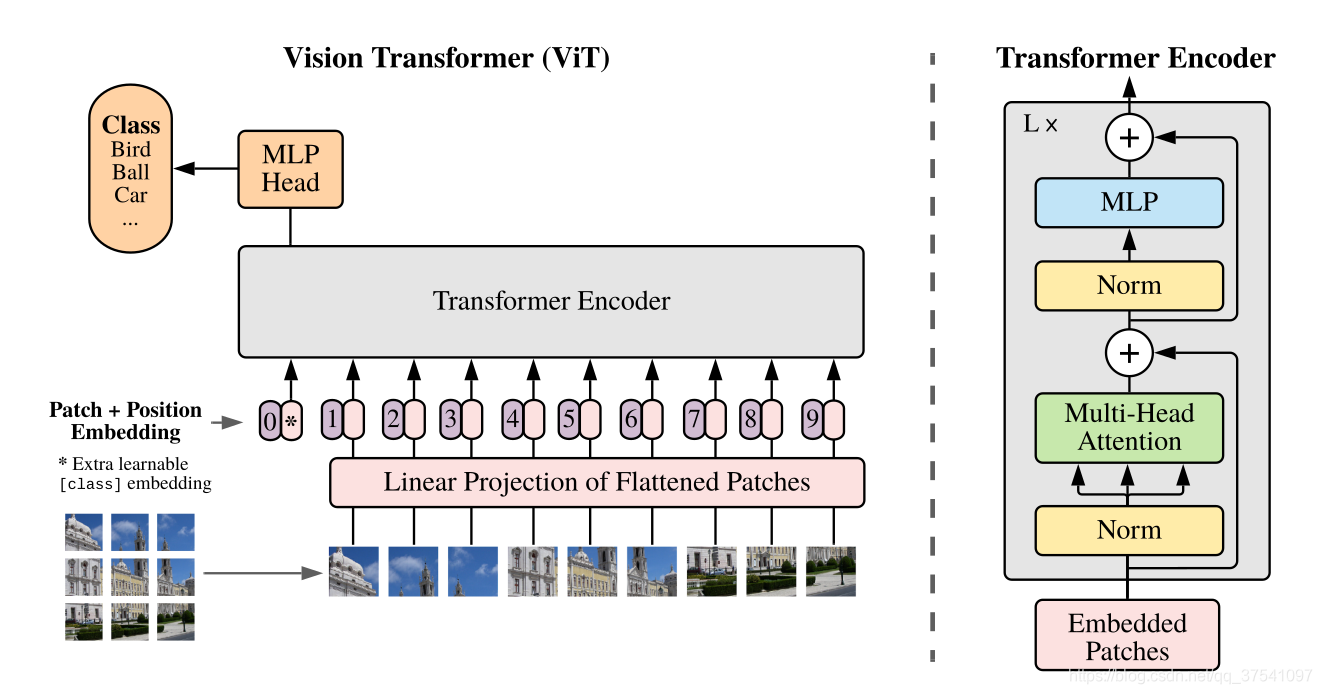
2.1 Embedding层
对于标准的Transformer模块,要求输入的是token(向量)序列,即二维矩阵[num_token, token_dim],如下图,token0-9对应的都是向量,以ViT-B/16为例,每个token向量长度为768。
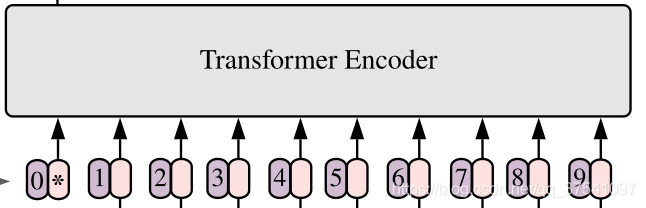
对于图像数据而言,其数据格式为[H, W, C]是三维矩阵明显不是Transformer想要的。所以需要先通过一个Embedding层来对数据做个变换。如下图所示,首先将一张图片按给定大小分成一堆Patches。以ViT-B/16为例,将输入图片(224×224)按照16×16大小的Patch进行划分,划分后会得到196个Patches。接着通过线性映射将每个Patch映射到一维向量中,以ViT-B/16为例,每个Patche数据shape为[16, 16, 3]通过映射得到一个长度为768的向量(后面都直接称为token)。[16, 16, 3] -> [768]
在代码实现中,直接通过一个卷积层来实现。 以ViT-B/16为例,直接使用一个卷积核大小为16×16,步距为16,卷积核个数为768的卷积来实现。通过卷积[224, 224, 3] -> [14, 14, 768],然后把H以及W两个维度展平即可[14, 14, 768] -> [196, 768],此时正好变成了一个二维矩阵,正是Transformer想要的。
2.2 Transformer Encoder
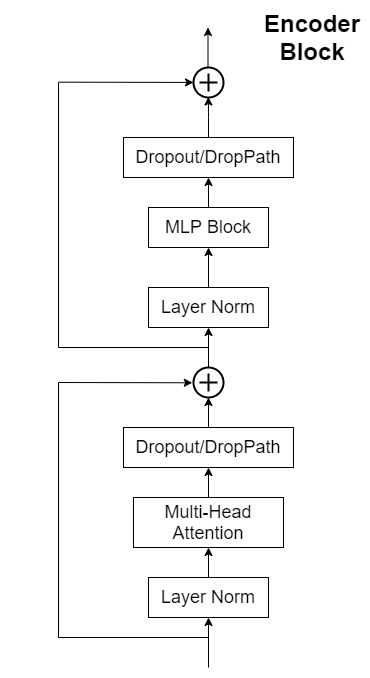
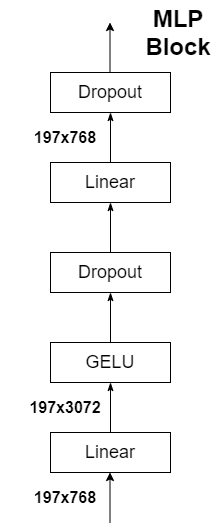
Transformer Encoder其实就是重复堆叠Encoder Block L次,主要由Layer Norm、Multi-Head Attention、Dropout和MLP Block几部分组成。
2.3 MLP Head
上面通过Transformer Encoder后输出的shape和输入的shape是保持不变的,以ViT-B/16为例,输入的是[197, 768]输出的还是[197, 768]。这里我们只是需要分类的信息,所以我们只需要提取出[class]token生成的对应结果就行,即[197, 768]中抽取出[class]token对应的[1, 768]。接着我们通过MLP Head得到我们最终的分类结果。MLP Head原论文中说在训练ImageNet21K时是由Linear+tanh激活函数+Linear组成。但是迁移到ImageNet1K上或者你自己的数据上时,只用一个Linear即可。
2.4 具体流程
1.首先将分辨率为 T × H × W 的输入视频,其中 T 为帧数、H 为高度、W 为宽度,分割成尺寸为1×16×16的非重叠块,然后在平坦图像块上逐点运用线性层,将其投影到潜在尺寸 D 中。就是1×16×16的核大小和步长的卷积,如表1中patch1阶段所示。

2.位置嵌入E ∈ 添加到长度为L且维数为D的投影序列的每个元素。
3.通过N个变换器块的顺序处理,产生的长度为L+1的序列,每个变换器块执行注意力(MHA)、多层感知机(MLP)和层规范化(LN)操作。通过以下公式计算:
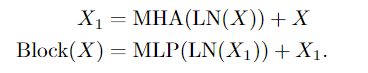
注:此处产生长度为L+1的序列是因为spacetime resolution + class token
4.N个连续块之后的结果序列被层规范化,通过线性层来预测输出。此处需要注意,默认情况下,MLP的输入是4D。
三、模型搭建参数
在论文的Table1中有给出三个模型(Base/ Large/ Huge)的参数,在源码中除了有Patch Size为16×16的外还有32×32的。
其中:
Layers就是Transformer Encoder中重复堆叠Encoder Block的次数 L。
Hidden Size就是对应通过Embedding层(Patch Embedding + Class Embedding + Position Embedding)后每个token的dim(序列向量的长度)
MLP Size是Transformer Encoder中MLP Block第一个全连接的节点个数(是token长度的4倍)
Heads代表Transformer中Multi-Head Attention的heads数。
四、结果分析
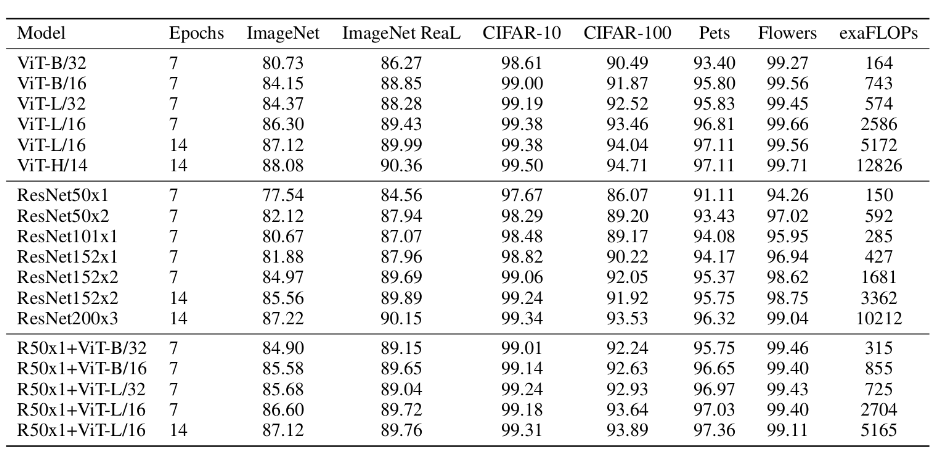
上表是论文用来对比ViT,Resnet(和刚刚讲的一样,使用的卷积层和Norm层都进行了修改)以及Hybrid模型的效果。通过对比可得出结论:
1.在训练epoch较少时Hybrid优于ViT -> Epoch小选Hybrid
2.当epoch增大后ViT优于Hybrid -> Epoch大选ViT
文章出处登录后可见!