什么是CLIP
Title: Learning transferable visual models from natural language supervision
paper:https://arxiv.org/pdf/2103.00020
代码:https://github.com/OpenAI/CLIP
2021开年,顶着地表最强语言模型GPT-3的光环,OpenAI在自然语言处理领域一路高歌猛进,于昨日推出两个跨越文本与图像次元的模型:DALL·E和CLIP,前者可以基于文本生成图像,后者则可以基于文本对图片进行分类,两者都意在打破自然语言处理和计算机视觉两大门派“泾渭分明”的界限,实现多模态AI系统。CLIP是一个预训练模型,就像BERT、GPT、ViT等预训练模型一样。首先使用大量无标签数据训练这些模型,然后训练好的模型就能实现,输入一段文本(或者一张图像),输出文本(图像)的向量表示。CLIP和BERT、GPT、ViT的区别在于,CLIP是多模态的,包含图像处理以及文本处理两个方面内容,而BERT、GPT是单文本模态的,ViT是单图像模态的。
作者提出CLIP的动机
1.现有CV模型大多都只能预测已知的图像类别,对于没有见过的图像类别,需要额外的信息才能识别。那么文本其实就提供了这样的额外信息。所以利用图像对应的文本数据,也许就能使模型能够分辨未见类的图像。
2.最近NLP领域中出现的BERT、GPT等预训练模型表明,用大规模的无监督数据训练模型,可以在多个下游NLP任务上获得非常好的结果,有些甚至超过使用人工标注的数据训练出的模型。而现有的CV模型基本都是基于人工标注的数据集训练的(比如ImageNet),那么仿照NLP中预训练模型,如果使用大量无监督(也就是非人工标注)的图像,CV模型能否实现突破呢?
3.目前也有很多研究者注意到natural language在CV中的作用,并尝试利用起来。但是实际的实验结果通常低于其他特殊设计的使用有监督数据的模型。但是作者认为,他们在CV模型中加入natural language数据后实际结果不够好的原因可能是数据规模仍然不够大,而不是natural language数据对CV无用。
CLIP的预训练数据是什么?
预训练数据是作者新构建的WIT数据集。鉴于现有CV数据集仍然不够大,且很少包含足够的natural language数据(大多CV数据集中的文本数据只是图像的类别指示,比如dog,cat等单词),所以作者从网上爬了4亿个图像-文本对,构建了数据集WIT(WebImageText)。WIT数据集中的文本都是图像相关的sentence,而不是single word,因此提供了足够的natural language数据。
CLIP的预训练任务是什么?
CLIP的预训练任务是预测给定的图像和文本是否是一对(paired),使用对比学习(contrastive learning)的loss。
本文采取了对比学习的方法来预训练CLIP。直接将image对应的text sentence作为一个整体,来判断text和image是否是一对。对于一个包含N个图像-文本对的batch而言,其中正样本是每张图像及其对应的文本,一共有N个,而其他所有图像和文本的组合都是不成对的,也就是负样本是N×N-N个。
CLIP的结构?
如下图所示,CLIP的主要结构是一个文本编码器Text Encoder和一个图像编码器Image Encoder,然后计算文本向量和图像向量的相似度以预测它们是否为一对
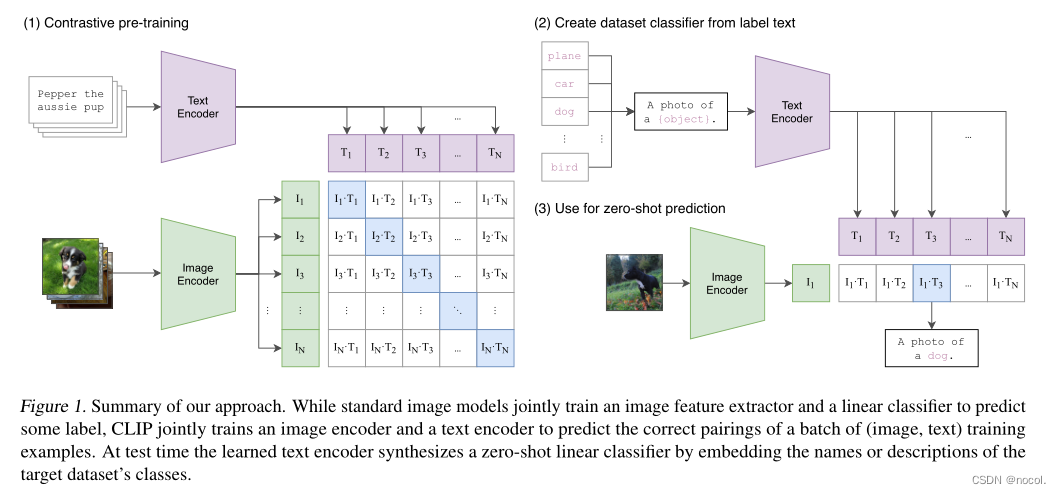
CLIP将图像和文本先分别输入一个图像编码器image_encoder和一个文本编码器text_encoder,得到图像和文本的向量表示 I-f 和 T_f 。然后将图像和文本的向量表示映射到一个joint multimodal sapce,得到新的可直接进行比较的图像和文本的向量表示 I_e 和T_e (这是多模态学习中常用的一种方法,不同模态的数据表示之间可能存在gap,无法进行直接的比较,因此先将不同模态的数据映射到同一个多模态空间,有利于后续的相似度计算等操作)。然后计算图像向量和文本向量之间的cosine相似度。最后,对比学习的目标函数就是让正样本对的相似度较高,负样本对的相似度较低。
clip做出的贡献
总结一下 clip这篇工作最大的贡献,在我看来就是他打破了之前这种固定种类标签的范式,意思就是说不论在你收集数据集的时候,还是在训练模型的时候,你都不需要像imagenet一样啊做1000类,或者像Coco一样做80类了,你直接就搜集这种图片文本的配对,然后用无监督的方式,要么去预测它的相似性,要么去生成它,总之呢是跟这种固定多少类别的范式呢说拜拜了。
这样的好处呢就是不仅在处理数据的时候更方便,训练起模型呢更方便,那最主要的就是在你做推理的时候呢更方便,甚至可以去zero short的啊做各种各样的分类任务,所以在clip这边工作出来之后,很快呢就一大批工作迅速跟进。那到现在为止,其实像物体检测、物体分割、啊视频动作识别、检索还有多模态,还有图像生成,基本上是每个领域都有利用clip的这个后续工作,它的影响力啊可见一斑。那如果我们按照沐神之前讲的那个如何判断一个工作的这个价值来说,clip在我看来呢应该就是100×100×100从新一度的角度来说,clip打破了这种固定类别标签的做法,彻底放飞了视觉模型的这个训练过程,引发了一大批后续的工作,所以新意度呢无疑是很高的,那从有效性上来说呢那就更不用说了,做了这么多数据集,效果这么好,泛化性能也这么好,甚至在某些情况下呢比人的这个 zero shot的性能还好,那有效性呢也毋庸置疑是100分。
最后呢就是问题大小,那 clip呢用一个模型就能解决大部分的这个分类任务,而且是zero shot的去解决这个问题本身呢就已经很大了。更何况呢你只要利用这个clip训练好的模型,再在其他领域里稍微适配一下,就能把别的领域的任务也全都做掉。所以说它这个问题大小啊也是100分,clip模型的这个灵活性和它的高效性,能让我们看到一点啊这个人工智障变人工智能的希望。所以综合从这三个角度来看, clip都是一篇价值极高的论文。
为什么CLIP要采用对比学习的方法
OpenAI是一家从来不愁计算资源的公司,他们喜欢将一切都gpt化(就是做生成式模型); 但是以往的工作表明(ResNeXt101-32x48d, Noisy Student EfficientNet-L2),训练资源往往需要很多,何况这些都只是在ImageNet上的结果,只是1000类的分类任务,而CLIP要做的是开发世界的视觉识别任务,所以训练的效率对于自监督的模型至关重要; 而如果任务改为给定一张图片去预测一个文本(或者给定一个文本去预测一张图片),那么训练效率将会非常低下(因为一个图片可能对应很多种说法,一个文本也对应着很多种场景); 所以与其做默写古诗词,不如做选择题!(只要判断哪一个文本与图片配对即可); 通过从预测任务改为只预测某个单词到只选出配对的答案,模型的训练效率一下提升了4倍。
什么是zero-shot
举个通俗的例子:假设斑马是未见过的类别,但根据描述和过去知识的印象即马(和马相似)、老虎(有条纹)、熊猫(颜色)相似进行推理出斑马的具体形态,从而能对新对象进行辨认。(如下图所示)零次学习就是希望能够模仿人类的这个推理过程,使得计算机具有识别新事物的能力。
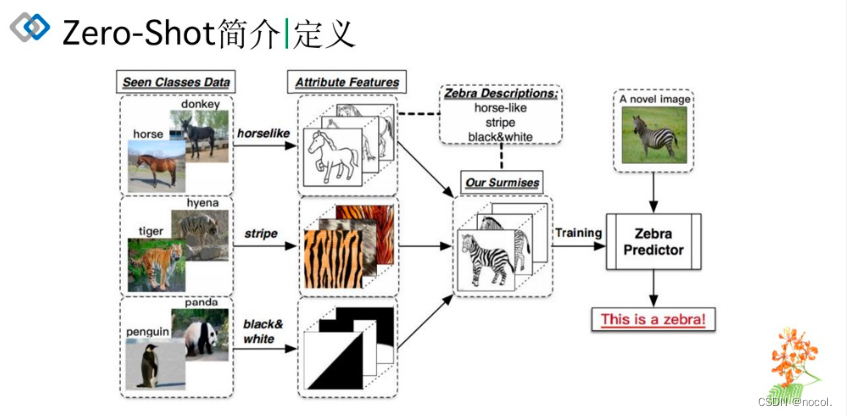
这是zero-shot介绍时常用的一张图,从见过的类别(第一列)中提取特征(如:外形像马、条纹、黑白),然后根据对未知类别特征的描述,测试未见过的类别。
从字面上来看,即是对某(些)类别完全不提供训练样本,也就是没有标注样本的迁移任务被称为零次学习。 zero-shot learning是为了能够识别在测试中出现,但在训练中没有遇到过的数据类别,我们可以学习到一个映射X->Y。如果这个映射足够好的话,我们就可以处理没有看到的类了,故可以被认为是迁移学习。
“zero-shot”践行者:按词分图的CLIP
如果说DALL·E是GPT-3在图像领域的延伸,那CLIP就是主打“zero-shot(零样本)”,攻破视觉领域的深度学习方法的三大难题。
1、训练所需大量数据集的采集和标注,会导致的较高成本。
2、训练好的视觉模型一般只擅长一类任务,迁移到其他任务需要花费巨大成本。
3、即使在基准测试中表现良好,在实际应用中可能也不如人意。
CLIP全称是Contrastive Language-Image Pre-training,根据字面意思,就是对比文本-图像预训练模型,只需要提供图像类别的文本描述,就能将图像进行分类。
怎么分?为什么能分?
为了识别出未曾见过的类别(图像或文本),Zero-shot这一概念可以追溯到十年前,而目前计算机视觉领域应用的重点是,利用自然语言作为灵活的预测空间,实现泛化和迁移。
文中多次提到的Zero shot transfer of CLIP 是什么意思?
本文的CLIP预训练时使用的数据集是WIT,而在ImageNet、STL10、Food101、CIFAR10、MNIST等其他数据集上直接测试。这意味着CLIP在训练时没有见过ImageNet这些数据集中的图像,那么这种测试实际上就是zero shot的。
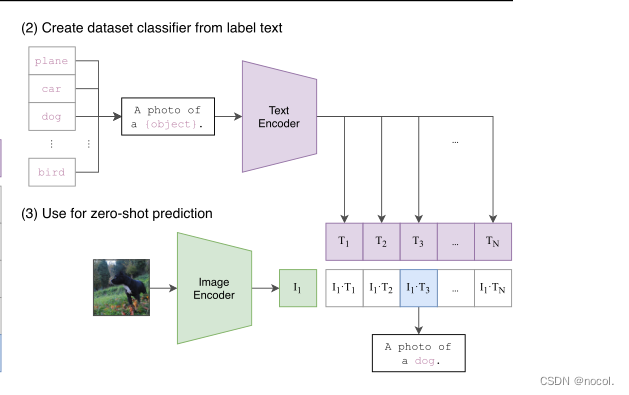
一个测试例子可以看下图,假设要测试的数据集是ImageNet,那么,因为CLIP在训练时用的所有数据来自WIT,而没有任何ImageNet的数据,所以CLIP在ImageNet上进行测试实际上就是Zero shot的。由于ImageNet中text数据只有表示图像类别的car,dog,bird等single word,而CLIP训练时text数据是sentence,为了弥补训练和测试的gap,作者将ImageNet中所有类别单词扩展为一句话“ A photo of a {car/dog/…/bird}. ” ,作为图像对应的sentence(该操作实际上是prompt engineering)。
下图中Text Encoder和Image Encoder是已经训练好的CLIP中的文本和图像编码器,要对任意一张来自ImageNet的图像进行分类,只需要将该图像输入Image Encoder中得到它的向量表示I1。然后将ImageNet数据集中所有类别标签扩展成的sentence输入Text Encoder,得到所有类别的向量表示T1—TN,然后计算I1与T1—TN的相似度,其中相似度最高的就是该图像对应的text数据,也就是该图像的分类结果。
CLIP的“足”与“不足”
1、从CLIP流程,看三大问题如何解决
简单来说,CLIP的任务就是识别一张图像所出现的各种视觉概念,并且学会它的名称。比如当任务是对猫和狗的图片进行分类,CLIP模型就需要判断,目前处理的这张图片的文字描述是更偏向于“一张猫的照片”,还是一张狗的照片。
在具体实现上,有如下流程:预训练图像编码器和文本编码器,得到相互匹配的图像和文本,基于此,CLIP将转换为zero-shot分类器。此外,数据集的所有类会被转换为诸如“一只狗的照片”之类的标签,以此标签找到能够最佳配对的图像。
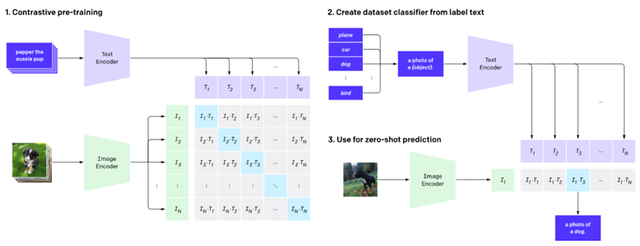
在这个过程中,CLIP也能解决之前提到的三大问题。
1、昂贵的数据集:25000人参与了ImageNet中1400万张图片的标注。与此相比,CLIP使用的是互联网上公开的文本-图像对,在标注方面,也利用自监督学习、对比方法、自训练方法以及生成建模等方法减少对人工标注的依赖。
2、只适用于单一任务:由于已经学会图片中的各种视觉概念,所以CLIP可以执行各种视觉任务,而不需要额外的训练和调整。如下也展示了CLIP模型识别各类型图像中视觉概念,无论是食物、场景还是地图,都是有不错的表现。
3、实际应用性能不佳:基准测试中表现好的模型在实际应用中很可能并没有这么好的水平。就像学生为了准备考试,只重复复习之前考过的题型一样,模型往往也仅针对基准测试中的性能进行优化。但CLIP模型可以直接在基准上进行评估,而不必在数据上进行训练。
2.CLIP的“足”:高效且灵活通用。
CLIP需要从未经标注、变化多端的数据中进行预训练,且要在“zero-shot”,即零样本的情况下使用。GPT-2/3模型已经验证了该思路的可行性,但这类模型需要大量的模型计算,为了减少计算量,OpenAI的研究人员采用了两种算法:对比目标(contrastive objective)和Vision Transformer。前者是为了将文本和图像连接起来,后者使计算效率比标准分类模型提高了三倍。
3.CLIP的“不足”:复杂任务仍有差距
尽管CLIP在识别常见物体上表现良好,但在如计算图像中物品数量、预测图片中物品的位置距离等更抽象、复杂的任务上,“zero-shot”CLIP表现仅略胜于随机分类,而在区分汽车模型、飞机型号或者花卉种类时,CLIP也不好。
且对于预训练阶段没有出现过的图像,CLIP泛化能力也很差。例如,尽管CLIP学习了OCR,但评估MNIST数据集的手写数字上,“zero-shot”CLIP准确率只达到了88%,远低于人类在数据集中的99.75%精确度。最后,研究人员发现,CLIP的“zero-shot”分类器对单词构造或短语构造比较敏感,但有时还是需要试验和错误“提示引擎”的辅助,才能表现良好。
CLIP是判别模型,预计它之后在图像领域会作为预训练模型,有更多的应用
文章出处登录后可见!