背景
在工业上使用较多的基于深度学习从目标检测算法,那毫无疑问应该是yolo,凭借这效率和精度方面的优势,在一众深度学习目标检测算法中脱颖而出。目前最新的版本是yoloV7,根据yoloV7论文中描述:
YOLOv7 surpasses all known object detectors in both speed and accuracy in the range from 5 FPS to 160 FPS and has the highest accuracy 56.8% AP among all known real-time object detectors with 30 FPS or higher on GPU V100. YOLOv7-E6 object detector (56 FPS V100, 55.9% AP) outperforms both transformer-based detector SWIN L Cascade-Mask R-CNN (9.2 FPS A100, 53.9% AP) by 509% in speed and 2% in accuracy, and convolutional based detector ConvNeXt-XL Cascade-Mask R-CNN (8.6 FPS A100, 55.2% AP) by 551% in speed and 0.7% AP in accuracy, as well as YOLOv7 outperforms: YOLOR, YOLOX, Scaled-YOLOv4, YOLOv5, DETR, Deformable DETR, DINO-5scale-R50, ViT-Adapter-B and many other object detectors in speed and accuracy. Moreover, we train YOLOv7 only on MS COCO dataset from scratch without using any other datasets or pre-trained weights
已知对象检测算法中获得了最高的精度,达到了 56.8% 的平均精度(AP),并且效率远超基于transformer(transformer-based)和基于卷积(convolutional-based)的模型。并且训练只使用了coco数据集,没有任何预训练权重。
今天试着下载看了下,发现文档说明齐全。今天大概花了一天时间,完成了从配环境,准备数据集,训练模型到tensorRT部署等多个步骤。
也得益于之前用过yolov3,对深度学习这一套流程比较熟悉。平时也有点工程经验,遇到的坑几乎网上一查或者仔细一琢磨,基本就解决了。接下来就对这一过程做个记录。
参考资料:
YOLOV7论文地址:https://arxiv.org/pdf/2207.02696.pdf
YOLOV7源码地址:https://github.com/WongKinYiu/yolov7
YOLO进化史:https://zhuanlan.zhihu.com/p/539932517
YOLOV7 tensorRT部署:https://zhuanlan.zhihu.com/p/556570703
源码下载
从github克隆代码:https://github.com/WongKinYiu/yolov7
环境配置
这是一个python工程,推荐使用PyCharm。
笔者使用的是Windows系统,如果不用conda的话,只能使用PyCharm提供的虚拟环境功能,在工程下新建一个python环境,这个环境不会影响别的工程。Pycharm会识别requirements.txt中需要的包,自动提示你安装。
这里的torch需要注意,如果使用默认的requirements.txt中版本,可能GPU不会启用,表现就是:
import torch
torch.cuda.is_available() #返回值为false
因此要自行安装,按照自己的环境,选择装不同的版本,pytorch官网提供了一个便捷的工具来生成安装指令。
https://pytorch.org/get-started/locally/

这里笔者的环境供参考:
cuda:10.2
cudnn:8.2.2.26
TensorRT:8.2.2.1
这些版本一定要匹配,笔者在这儿踩过坑,把cuda重新安装了一遍,又下载了好几版的cudnn和tensorRT才测试成功。
测试数据集准备
yolov7测试数据集是coco,因此下载了coco val2017数据集,train2017暂时没有下载。
在data/coco.yaml文件中:
# download command/URL (optional)
download: bash ./scripts/get_coco.sh
可以看到提供了一个下载coco的脚本,但只能在Linux下跑,Windows下需要自己下载。
val2017就够了,要自己训练的话,可以下载train2017,可以看到笔者也在下载train2017。
同样在data/coco.yaml中,设置文件路径
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: H:/baiduyundownloads/coco2017/train2017.txt # 118287 images
val: H:/baiduyundownloads/coco2017/val2017.txt # 5000 images
test: H:/baiduyundownloads/coco2017/test-dev2017.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
精度测试
然后可以运行
python test.py --data data/coco.yaml --img 640 --batch 32 --conf 0.001 --iou 0.65 --device 0 --weights yolov7.pt --name yolov7_640_val
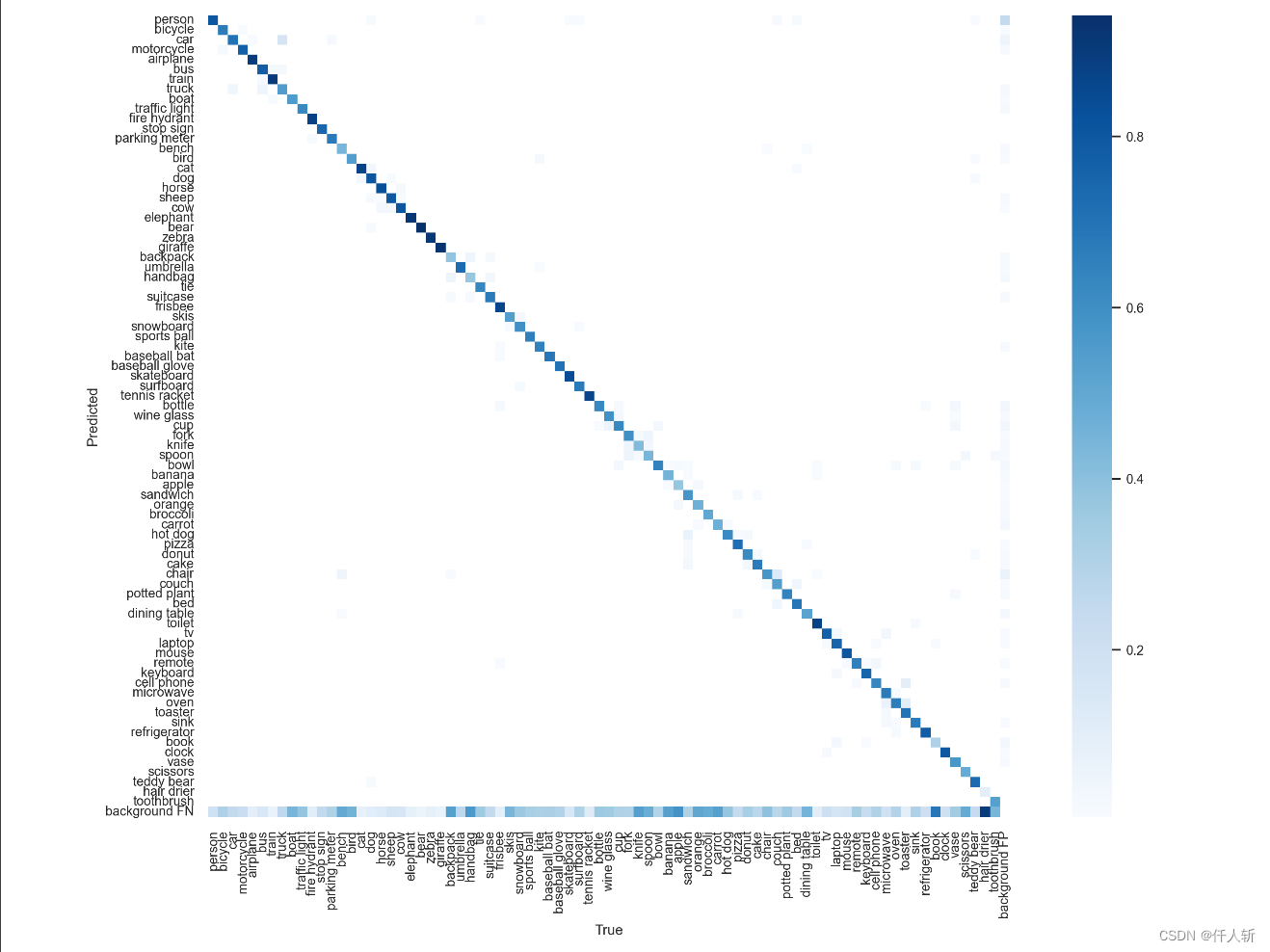
在run/test/yolov7目录下,可以看到confusion_matrix。
训练模型
python train.py --workers 8 --device 0 --batch-size 32 --data data/coco.yaml --img 640 640 --cfg cfg/training/yolov7.yaml --weights '' --name yolov7 --hyp data/hyp.scratch.p5.yaml
模型训练可以从零开始,也可以在预训练权重上使用自己的数据集。这一步笔者没有实际执行。
模型导出为onnx
python export.py --weights ./yolov7-tiny.pt --dynamic-batch --grid --simplify --topk-all 100 --iou-thres 0.65 --conf-thres 0.35 --img-size 640 640
这一步不跟着Readme,去掉命令中的end2end,加入dynamic-batch。
这里选择yolov7-tiny模型,执行命令后,生成yolov7-tiny.onnx。
tensorRT部署
使用这个仓库
https://github.com/shouxieai/tensorRT_Pro
下的tensorRT_Pro/example-simple_yolo/目录中的工程,可以将.onnx模型转为.trtmodel模型。

然后可以用这个模型,在c++端进行推理:

推理结果写到文件:

文章出处登录后可见!