论文:
DBNet:Real-time Scene Text Detection with Differentiable BinarizationReal-time Scene Text Detection with Differentiable Binarization
DBNet++:Real-Time Scene Text Detection with Differentiable Binarization and Adaptive Scale Fusion
Github:https://github.com/MhLiao/DB
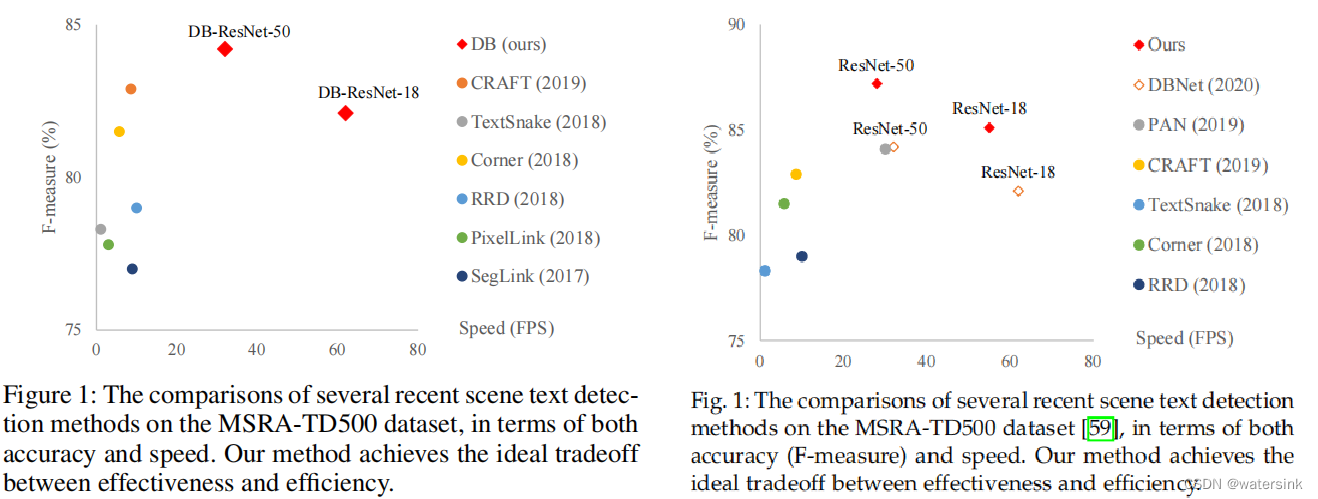
在MSRA-TD500数据集上的测试效果。DBNet的检测效果F1值和速度FPS都比其他算法要好很多。而DBNet++比DBNet速度约略,精度要高。
主要贡献:
- DBNet,DBNet++在5个场景任意方向文本检测的数据集上(水平文本,多方向文本,曲形文本)都取得了最好的效果。
- DBNet的速度快,能够输出高度鲁棒的二进制分割图,大大的简化了后处理操作。
- 即使使用ResNet-18这样的轻量网络,检测效果也非常好。
- 在推理测试阶段,DB模块可以移除而不会对最终效果有影响。
- DBNet++通过提出ASF模块来优化多尺度分割的效果。
文本检测方法汇总:
| 名称 | 代表方法 | 优点 | 缺点 |
| 基于回归 (Regression-based)的方法 | TextBoxes++,EAST,DeepReg,DeRPN | 后处理简单,只需要NMS操作 | 对于任意形状的文本效果不行 |
| 基于部件 (Part-based)的方法 | SegLink, SegLink++ | 尤其擅长长文本行 | 连接算法比较复杂 |
| 基于分割(Segmentation-based)的方法 | Mask TextSpotter, PSENet,SAE | 可以出来任意形状的文本 | 后处理较为麻烦,大概会占用整个推理30%的时间 |
DBNet网络结构:
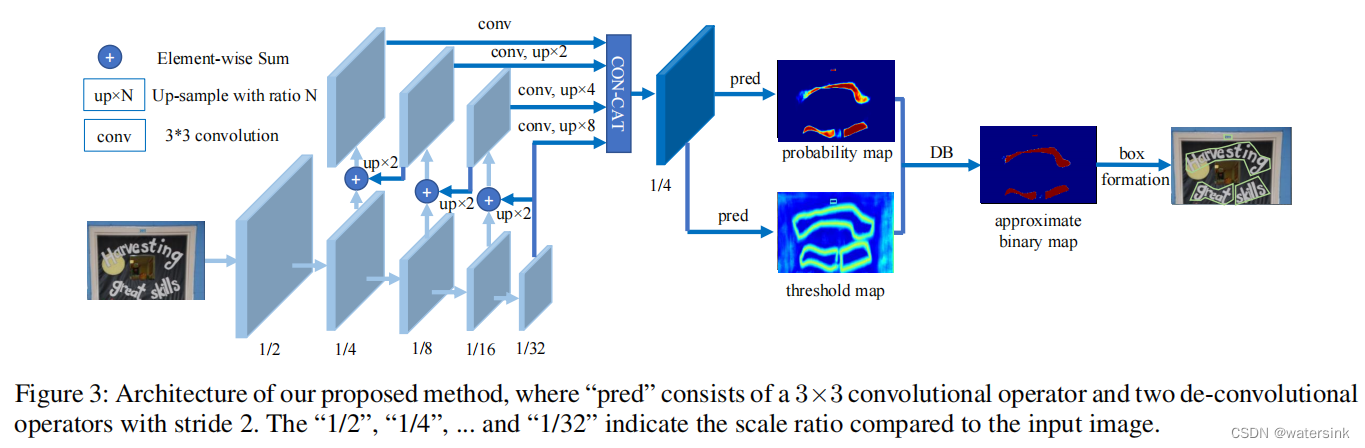
网络输入假设为w*h*3。网络整体结构采用FPN的设计思想,进行了5次下采样,3次上采样操作。最终的输出特征图大小为原图的1/4。网络头部部分,分别引出2个分支。一个负责预测概率图(probability map,(w/4)*(h/4)*1),代销为,另一个负责预测阈值图(threshold map,(w/4)*(h/4)*1)。概率图经过阈值图处理,进行二值化后得到二值图(approximate binary map,(w/4)*(h/4)*1)。最后经过后处理操作得到最终文字的边。
DBNet++网络结构:
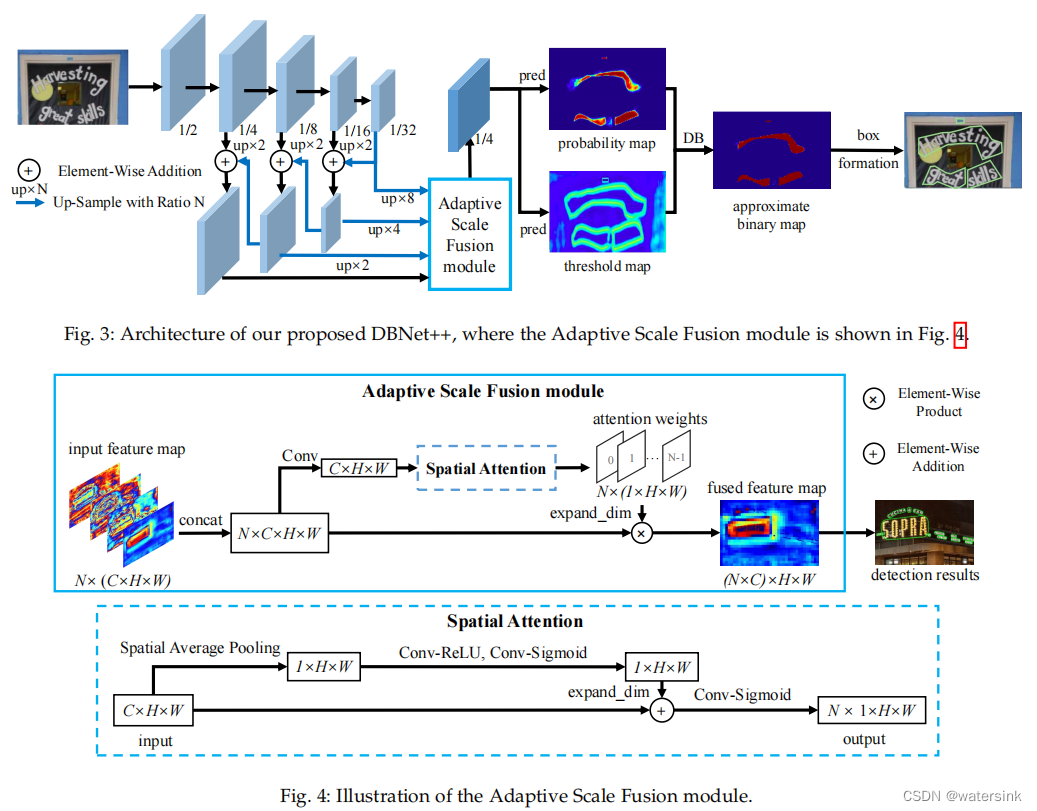
DBNet++在DBNet的基础上增加了ASF(Adaptive Scale Fusion)模块。不同尺度的特征通过ASF模块处理,可以得到更佳的融合特征。
ASF模块通过引入空间attention机制,使得融合后的特征更加鲁棒。
其中N表示要融合的特征数,这里N=4,表示从4个不同的分支引出的特征。
传统二值化 vs差异二值化:
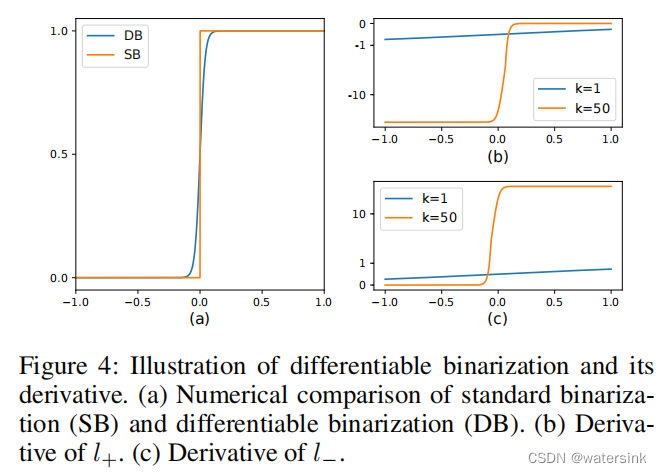
传统二值化Standard binarization
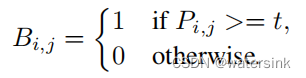
传统的二值化,只是使用固定的阈值t进行二值化处理。
差异二值化Differentiable binarization
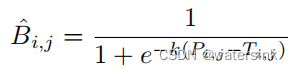
差异二值化,每个像素都使用不同的阈值进行二值化处理。而这个不同的阈值矩阵又是网络学习得到的。为了保证整个优化过程有梯度的传递,这里又将概率图和阈值图的差传入sigmoid函数,以此来保证梯度的传递。通过梯度优化,保证了不同的图片使用不同的阈值矩阵,达到最佳的二值化效果。
这里k被设置为50
定义损失函数为二分类交叉熵,l+表示正样本的loss,l-表示负样本的loss。
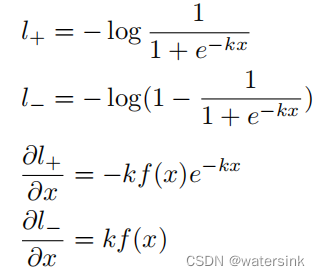
分别对正负样本函数求导,得到下面的梯度公式。
其中x<0时,取l+,x>0时,取l-
可变形卷积Deformable convolution:
在ResNet-18和ResNet-50的主干网络conv3,conv4,conv5中使用了可变形卷积,以此保证足够大的感受野。
标签制作:
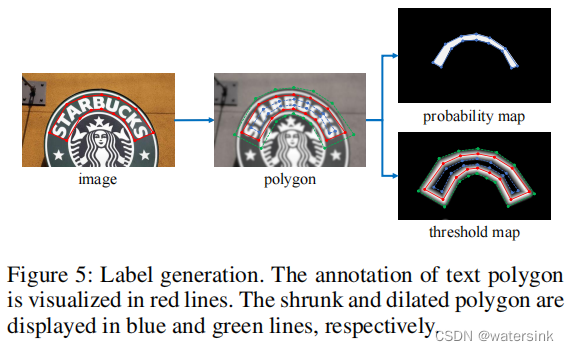
为了增大相邻文字之间的间距,缓解文字离得太近或者部分重叠的情况。概率图(probability map)的制作会在原始红色多边形的基础上,使用Vatti clipping算法,向内收缩D的距离。
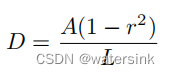
r表示收缩率,这里设置为0.4
A表示原始红色多边形的面积
L表示原始红色多边形的周长
阈值图(threshold map)在红色多边形的基础上,分别向内收缩D距离形成蓝色多边形,向外扩张D距离形成绿色多边形。蓝色多边形和绿色多边形之间的像素形成阈值图。然后计算图内每个像素离最近的边(蓝色边,绿色边)的归一化距离,形成最终的阈值图。阈值图看起来中间像素亮,边缘像素暗。
后处理操作:
后处理操作中,使用概率图(probability map)或者使用二值图(approximate binary map)都是可以的。两者在效果上是一样的。这样在推理过程中,就可以去掉网络中的二值化过程,直接使用概率图。这样网络中的二值化过程的loss就更像一个辅助loss,来使得网络训练的效果更好。
后处理过程如下,
- 使用固定阈值0.2对概率图或者二值图进行二值化操作,得到二值图
- 从二值图中获得连通域区域
- 将连通域区域向外膨胀D’得到真实的多边形轮廓
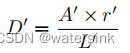
其中r’=1.5
A’为网络输出的二值化后的连通区域的面积
L’为网络输出的二值化后的连通区域的周长
损失函数:
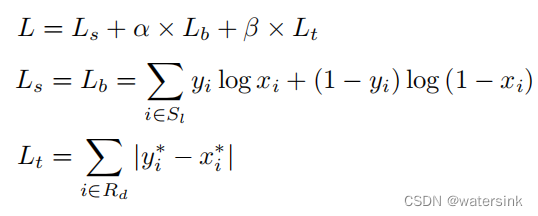
a=1.0
β=10
Ls:概率图(probability map)的loss,采用二分类交叉熵损失,并基于ohem难例挖掘,保证正负样本比例为1:3
Lb:二值图(binary map)的loss,采用二分类交叉熵损失,并基于ohem难例挖掘,保证正负样本比例为1:3
Lt:阈值图(threshold map)的loss,采用L1损失,其中Rd表示绿色膨胀轮廓内的像素
实验结果:
DBNet 
DBNet++

DBNet VS DBNet++

总结:
- 速度快,精度高
- 能检测任意形状的文本,横着,竖着,斜着,曲形等多种类型的文本
- 缺点,DBNet,DBNet++不能解决环形文字里面还有文字的情况。
One limitation of our method is that it can not deal with cases “text inside text”, which means that a text instance is inside another text instance.
4.通过提出DB(Differentiable Binarization),类似额外约束的loss,使得模型训练效果更佳。
5.DBNet++在DBNet的基础上,通过引入ASF模块,在少量耗时增加的代价下,提升了准确性。
6.可变形卷积(Deformable convolution)的引入,对精度提升巨大。
文章出处登录后可见!