目录
一、模型量化是什么?
模型量化是由模型、量化两个词组成。我们要准确理解模型量化,要看这两个词分别是什么意思。
在计算机视觉、深度学习的语境下,模型特指卷积神经网络,用于提取图像/视频视觉特征。
量化是指将信号的连续取值近似为有限多个离散值的过程,可理解成一种信息压缩的方法。在计算机系统上考虑这个概念的话,量化有若干相似的术语,低精度可能是最通用的概念。常规精度一般使用 FP32(32位浮点,单精度)存储模型权重;低精度则表示 FP16(半精度浮点),INT8(8位的定点整数)等等数值格式。目前,低精度往往指代INT8,因此也有人称量化为“定点化”,但是严格来讲所表示的范围是缩小的。定点化特指scale为2的幂次的线性量化,是一种更加实用的量化方法。
简而言之,我们常说的模型量化就是将浮点存储(运算)转换为整型存储(运算)的一种模型压缩技术。举个例子,即原来表示一个权重或偏置需要使用FP32表示,使用了INT8量化后只需要使用一个INT8来表示就可以了。
注:以下主要基于INT8量化介绍。
二、为什么要做模型量化?
现有的深度学习框架,比如:TensorFlow,Pytorch,Caffe, MixNet等,在训练深度神经网络时,往往都会使用FP32的数据精度来表示权值、偏置、激活值等。在深度学习模型性能提高的同时,计算也越来越复杂,计算开销和内存需求逐渐增加。仅 8 层的 AlexNet需要0.61 亿个网络参数和 7.29 亿次浮点型计算,花费约 233MB 内存。随后的 VGG-16的网络参数达到 1.38 亿,浮点型计算次数为 156 亿,需要约 553MB 内存。为了克服深层网络的梯度消失问题。He 提出了 ResNet网络,首次在ILSVRC 比赛中实现了低于 5%的 top-5 分类错误,偏浅的 ResNet-50 网络参数就达到 0.25 亿,浮点型计算次数高达 41.2亿,内存花费约 102MB。
| Network | Model Size(MB) | GFLOPS |
| AlexNet | 214 | 0.72 |
| VGG-13 | 532 | 11.3 |
| VGG-16 | 552 | 15.6 |
| VGG-19 | 576 | 19.6 |
| ResNet-50 | 102 | 4.12 |
| ResNet-101 | 178 | 7.84 |
| ResNet-152 | 240 | 23.1 |
| GoogleNet | 27 | 1.6 |
| InceptionV3 | 89 | 6 |
| MobileNet | 38 | 0.58 |
| SequeezeNet | 30 | 0.84 |
表1 不同模型的模型大小及浮点运算次数
庞大的网络参数意味着更大的内存存储,而增长的浮点型计算次数意味着训练成本和计算时间的增长,这极大地限制了在资源受限设备,例如智能手机、智能手环等上的部署。如表2所示,深度模型在 Samsung Galaxy S6 的推理时间远超 Titan X 桌面级显卡,实时性较差,无法满足实际应用的需要。
| 设备 | |||
| Samsung Galaxy S6 | Titan X | ||
| 模型 | AlexNet | 117 | 0.54 |
| GoogleNet | 273 | 1.83 | |
| VGG-16 | 1926 | 10.67 | |
表2 不同模型在不同设备上的推理时间(单位:ms)
三、模型量化的目标是什么?

图1 不同精度数值内存占用情况及运算功耗
- 更小的模型尺寸。
- 更低的运算功耗。
- 更低的运存占用。
- 更快的计算速度。
- 持平的推理精度。
四、模型量化的必要条件
量化是否一定能加速计算?回答是否定的,许多量化算法都无法带来实质性加速。
引入一个概念:理论计算峰值。在高性能计算领域,这概念一般被定义为:单位时钟周期内能完成的计算个数乘上芯片频率。
什么样的量化方法可以带来潜在、可落地的速度提升呢?我们总结需要满足两个条件:
- 量化数值的计算在部署硬件上的峰值性能更高 。
- 量化算法引入的额外计算(overhead)少 。
要准确理解上述条件,需要有一定的高性能计算基础知识,限于篇幅就不展开讨论了。现直接给出如下结论:已知提速概率较大的量化方法主要有如下三类,
- 二值化,其可以用简单的位运算来同时计算大量的数。对比从nvdia gpu到x86平台,1bit计算分别有5到128倍的理论性能提升。且其只会引入一个额外的量化操作,该操作可以享受到SIMD(单指令多数据流)的加速收益。
- 线性量化,又可细分为非对称,对称几种。在nvdia gpu,x86和arm平台上,均支持8bit的计算,效率提升从1倍到16倍不等,其中tensor core甚至支持4bit计算,这也是非常有潜力的方向。由于线性量化引入的额外量化/反量化计算都是标准的向量操作,也可以使用SIMD进行加速,带来的额外计算耗时不大。
- 对数量化,一个比较特殊的量化方法。可以想象一下,两个同底的幂指数进行相乘,那么等价于其指数相加,降低了计算强度。同时加法也被转变为索引计算。但没有看到有在三大平台上实现对数量化的加速库,可能其实现的加速效果不明显。只有一些专用芯片上使用了对数量化。
五、模型量化的分类
5.1 线性量化和非线性量化
根据映射函数是否是线性可以分为两类,即线性量化和非线性量化,本文主要研究的是线性量化技术。
5.2 逐层量化、逐组量化和逐通道量化
根据量化的粒度(共享量化参数的范围)可以分为逐层量化、逐组量化和逐通道量化。
- 逐层量化,以一个层为单位,整个layer的权重共用一组缩放因子S和偏移量Z;
- 逐组量化,以组为单位,每个group使用一组S和Z;
- 逐通道量,化则以通道为单位,每个channel单独使用一组S和Z;
当 group=1 时,逐组量化与逐层量化等价;当 group=num_filters (即dw卷积)时,逐组量化逐通道量化等价。
5.3 N比特量化
根据存储一个权重元素所需的位数,可以将其分为8bit量化、4bit量化、2bit量化和1bit量化等。
5.4 权重量化和权重激活量化
5.4.1 权重与激活的概念
我们来看一个简单的深度学习网络,如图2所示
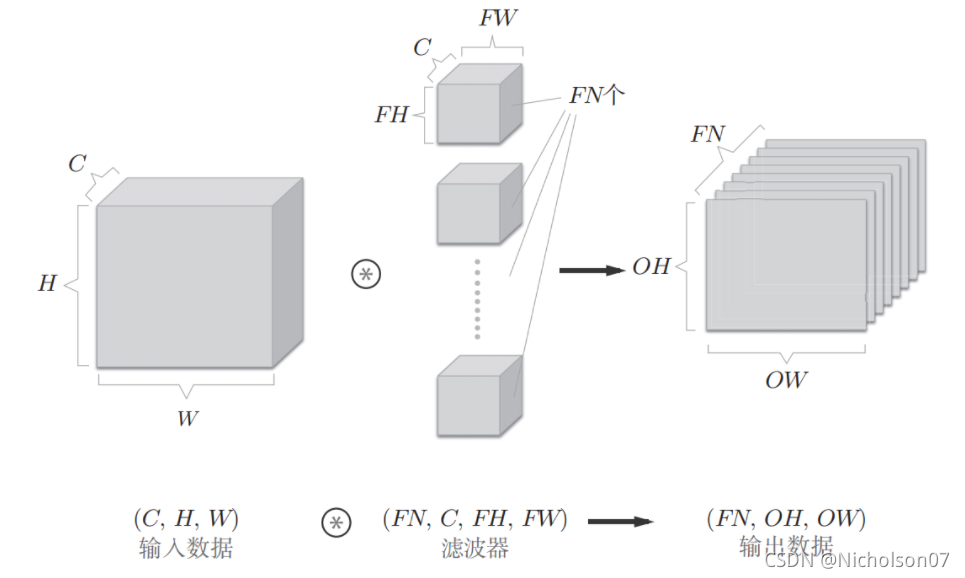
图2 深度学习网络维度示意图
其中滤波器就是权重,而输入和输出数据则是分别是上一层和当前层的激活值,假设输入数据为[3,224,224],滤波器为[2,3,3,3],使用如下公式可以计算得到输出数据为[2,222,222]
因此,权重有2*3*3*3=54个(不含偏置),上一层的激活值有3*224*224=150528个,下一层的激活值有2*222*222=98568个,显然激活值的数量远大于权重。
想了解深度学习网络相关知识可以看这篇文章。(17条消息) 《深度学习入门-基于Python的理论与实现》读书笔记_Nicholson的博客-CSDN博客
5.4.2 权重量化和权重激活量化
根据需要量化的参数可以分类两类:权重量化和权重激活量化。
- 权重量化,即仅仅需要对网络中的权重执行量化操作。由于网络的权重一般都保存下来了,因而我们可以提前根据权重获得相应的量化参数S和Z,而不需要额外的校准数据集。一般来说,推理过程中,权重值的数量远小于激活值,仅仅对权重执行量化的方法能带来的压缩力度和加速效果都一般。
- 权重激活量化,即不仅对网络中的权重进行量化,还对激活值进行量化。由于激活层的范围通常不容易提前获得,因而需要在网络推理的过程中进行计算或者根据模型进行大致的预测。
5.4.3 激活量化方式
根据激活值的量化方式,可以分为在线量化和离线量化。
- 在线量化,即指激活值的S和Z在实际推断过程中根据实际的激活值动态计算;
- 离线量化,即指提前确定好激活值的S和Z,需要小批量的一些校准数据集支持。由于不需要动态计算量化参数,通常离线量化的推断速度更快些。
通常使用以下的三种方法来确定相关的量化参数。
- 指数平滑法,即将校准数据集送入模型,收集每个量化层的输出特征图,计算每个batch的S和Z值,并通过指数平滑法来更新S和Z值。
- 直方图截断法,即在计算量化参数Z和S的过程中,由于有的特征图会出现偏离较远的奇异值,导致max非常大,所以可以通过直方图截取的形式,比如抛弃最大的前1%数据,以前1%分界点的数值作为max计算量化参数。
- KL散度校准法,即通过计算KL散度(也称为相对熵,用以描述两个分布之间的差异)来评估量化前后的两个分布之间存在的差异,搜索并选取KL散度最小的量化参数Z和S作为最终的结果。TensorRT中就采用了这种方法。
5.5 训练时量化和训练后量化
训练后量化(Post-Training Quantization,PTQ),PTQ不需要再训练,因此是一种轻量级的量化方法。在大多数情况下,PTQ足以实现接近FP32性能的INT8量化。然而,它也有局限性,特别是针对激活更低位的量化,如4bit、2bit。这时就有了训练时量化的用武之地。
训练时量化也叫量化感知训练(Quantization-Aware-Training,QAT),它可以获得高精度的低位量化,但是缺点也很明显,就是需要修改训练代码,并且反向传播过程对梯度的量化误差很大,也容易导致不能收敛。
本文主要讨论的时训练后量化。
六、量化的数学基础
6.1 定点数和浮点数
量化过程可以分为两部分:将模型从 FP32 转换为INT8,以及使用INT8 进行推理。本节说明这两部分背后的算术原理。如果不了解基础算术原理,在考虑量化细节时通常会感到困惑。
从事计算机科学的人很少了解算术运算的执行方式。由于量化桥接了固定点和浮点,在接触相关研究和解决方案之前,有必要先了解它们的基础知识。
定点和浮点都是数值的表示方式,它们区别在于,将整数部分和小数部分分开的点,位于哪里。定点保留特定位数整数和小数,而浮点保留特定位数的有效数字和指数。
| Fixed-point | Floating-point | |
| Format | IIIII.FFFFF | significand×base^exponet |
| Decimal | 12345.78901,00123.90000 | 1.2345678901×10^4,1.239×10^2 |
| Hex | A1C7D.FF014,00000.000FD | A.1C7DFF014×16^4,F.D×16^-4 |
| Binary | 10111.01011,00110.00000 | 1.011101011×2^4,1.1×2^2 |
表3 定点和浮点的格式与示例
在指令集的内置数据类型中,定点是整数,浮点是二进制格式。一般来说,指令集层面的定点是连续的,因为它是整数,且两个邻近的可表示数字的间隙是 1 。而浮点代表实数,其数值间隙由指数确定,因而具有非常宽的值域。同时也可以知道浮点的数值间隙是不均匀的,在相同的指数范围内,可表示数值数量也相同,且值越接近零就越准确。例如,[1,2) 中浮点值的数量与 [0.5,1)、[2,4)、[4,8)等相同。另外,我们也可以得知定点数数值与想要表示的真值是一致的,而浮点数数值与想要表示的真值是有偏差的。
| 数值范围 | 可取值数量 | |
| FP32 | [(2^23-2)×2^127,(2-2^-23)×2^127] | 2^32 |
| INT32 | [-2^16,2^16-1] | 2^32 |
表4 FP32和INT32的数值范围及可取值数量
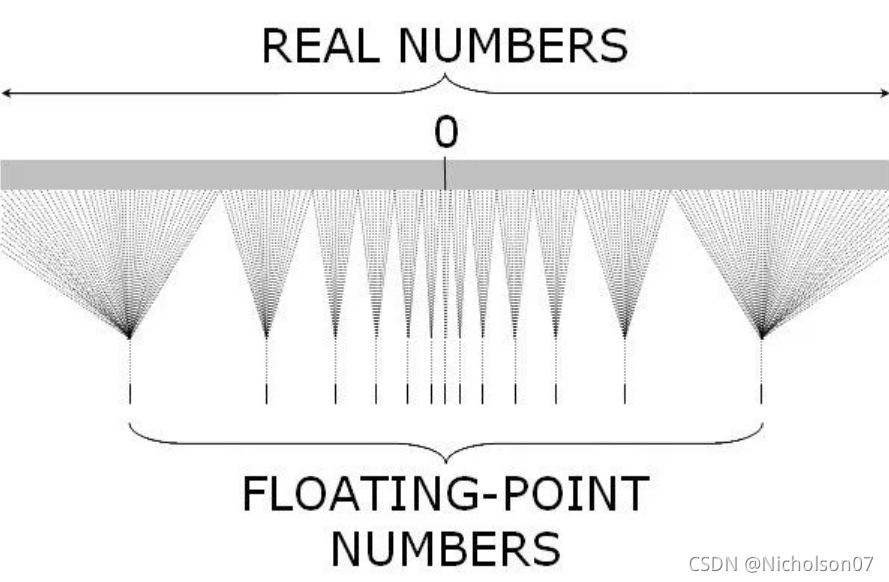
图3 浮点数与定点数对照关系示意图
举个例子,假设每个指数范围内可表示数值量为2,例如[2^0,2^1)范围内的数值转换成浮点数只能表示成{1,1.5}。
| 指数 | 真值范围 | FP32可表示的数值 | 最大误差 |
| 0 | [2^0,2^1) | {1,1.5} | 约等于0.5 |
| 3 | [2^3,2^4) | {8,12} | 约等于4 |
表5 浮点数数值间隙不同的示例
6.2 线性量化(线性映射)
6.2.1 量化
TensorRT使用的就是线性量化,它可以用以下数学表达式来表示:
其中,X表示原始的FP32数值;Z表示映射的零点Zero Point;S表示缩放因子Scale;表示的是近似取整的数学函数,可以是四舍五入、向上取整、向下取整等;
表示的是量化后的一个整数值。
clip函数如下:

图4 对称带符号量化、对称无符号量化和非对称量化
6.2.2 反量化
根据量化的公式不难推导出,反量化公式如下:
当Z=0时,,
。
可以发现当S取大时,可以扩大量化域,但同时,单个INT8数值可表示的FP32范围也变广了,因此INT8数值与FP32数值的误差(量化误差)会增大;而当S取小时,量化误差虽然减小了,但是量化域也缩小了,被舍弃的参数会增多。
举个例子,假设Z=0,使用向下取整。
| S | INT8=1时表示的FP32数值范围 | 最大误差 | 量化域 |
| 10 | [10,20) | 约等于10 | [-1280,1280) |
| 100 | [100,200) | 约等于100 | [-12800,12800) |
表6 不同缩放尺度的影响
七、TensorRT INT8量化原理
7.1 TensorRT是什么
NVIDIA®TensorRT™的核心是一个C++库,可促进对NVIDIA图形处理单元(GPU)的高性能推理。 它旨在与TensorFlow,Caffe,PyTorch,MXNet等训练框架以互补的方式工作。它专门致力于在GPU上快速有效地运行已经训练好的网络,以生成结果。一些训练框架(例如TensorFlow)已经集成了TensorRT,因此可以将其用于框架内加速推理。
图5 TensorRT是可编程的推理加速器
7.2 使用TensorRT INT8量化的前提
- 硬件上必须是Nvidia的显卡,并且计算能力大于等于6.1。Nvidia GPU的计算能力可以在这个网上找到。 CUDA GPU | NVIDIA Developer
- 软件上对平台、编译器等有限制;一些网络层无法使用,并且对兼容的网络层输入输出也有一定限制。具体参考TensorRT-Support-Matrix-Guide.pdf
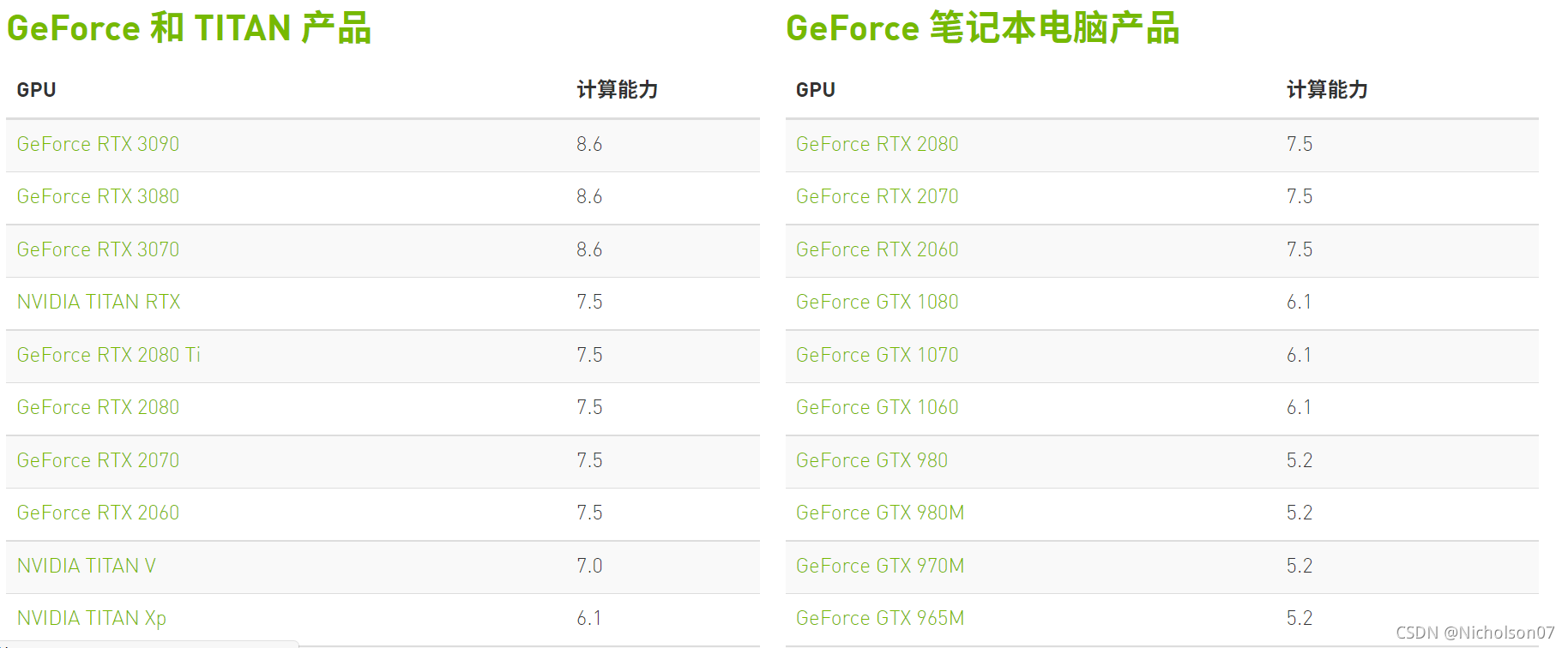
图6 TensorRT量化支持的显卡型号
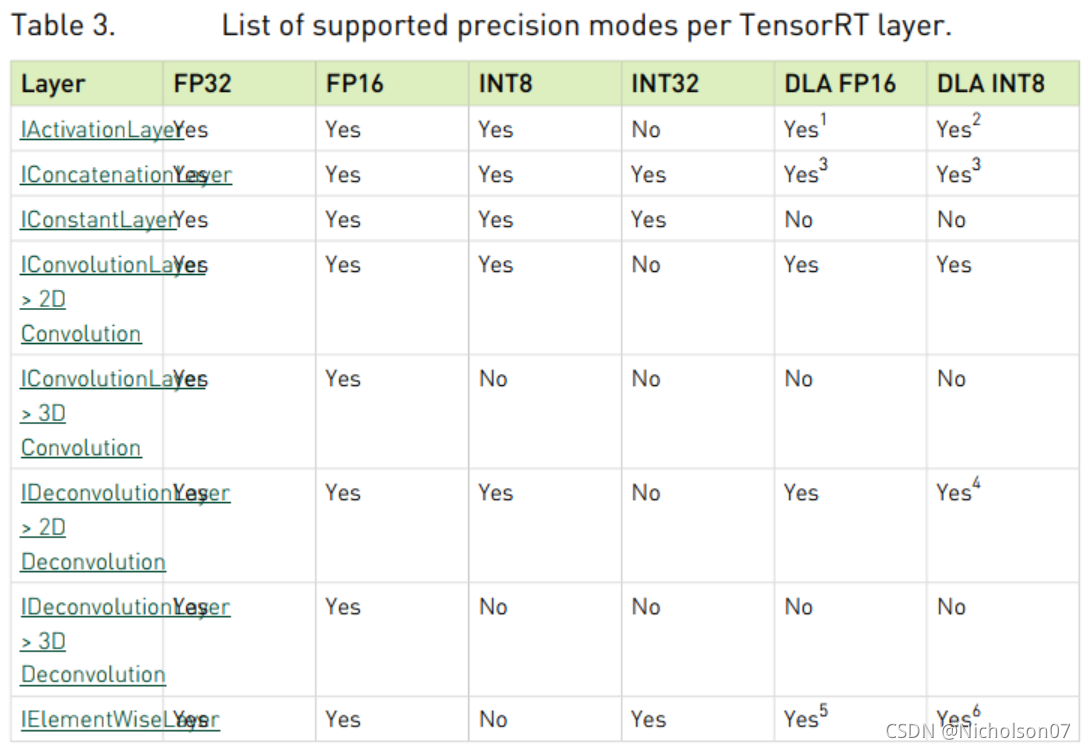
图7 TensorRT量化支持的网络层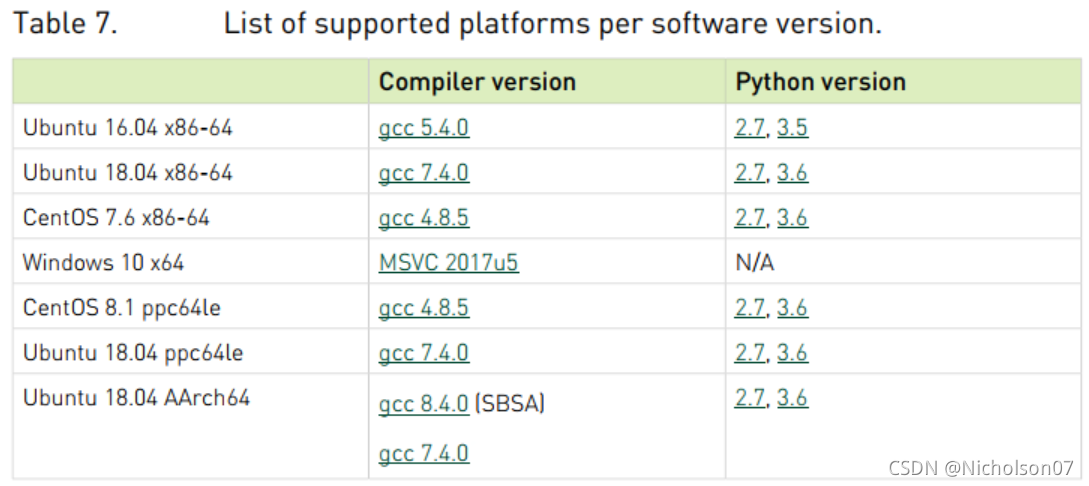
图8 TensorRT量化支持的平台和编译器
7.3 INT8量化流程
卷积的基本公式如下。
其中X是上一层的输出,即原始输入或者上一层的激活值;W是当前层的权重;b是当前层的偏置;Y是当前层的输出,即当前层的激活值。
TensorRT官方文档告诉我们在量化过程中偏置可以忽略不记,见图9,因此卷积的基本公式就简化成了以下形式。

图9 TensorRT官网文档说明可以省略bias
除去bias后,整个量化过程其实很简单,详见下图10-14。
- 通过线性映射的方式将激活值和权重从FP32转换为INT8;
- 执行卷积层运算得到INT32位激活值,如果直接使用INT8保存的话会造成过多的累计损失;
- 通过再量化的方式转换回INT8作为下一层的输入;
- 当网络为最后一层时,使用反量化转换回FP32。
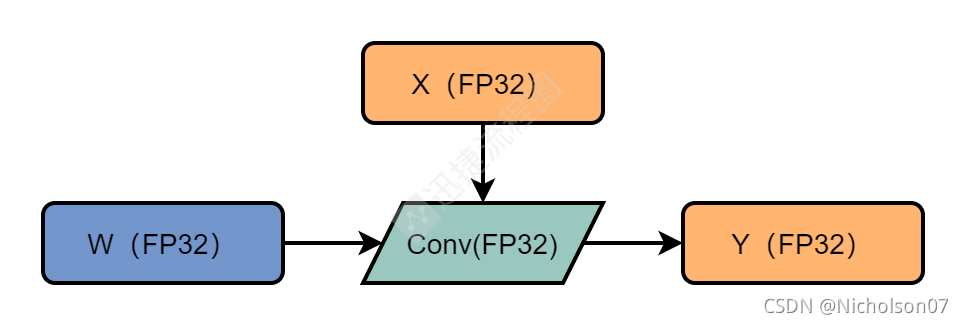
图10 FP32卷积层推理流程
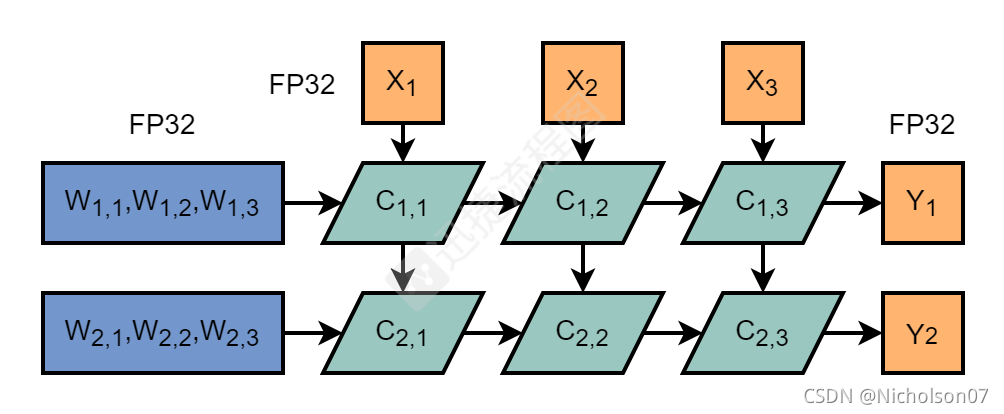
图11 FP32卷积层推理流程-细节展开图
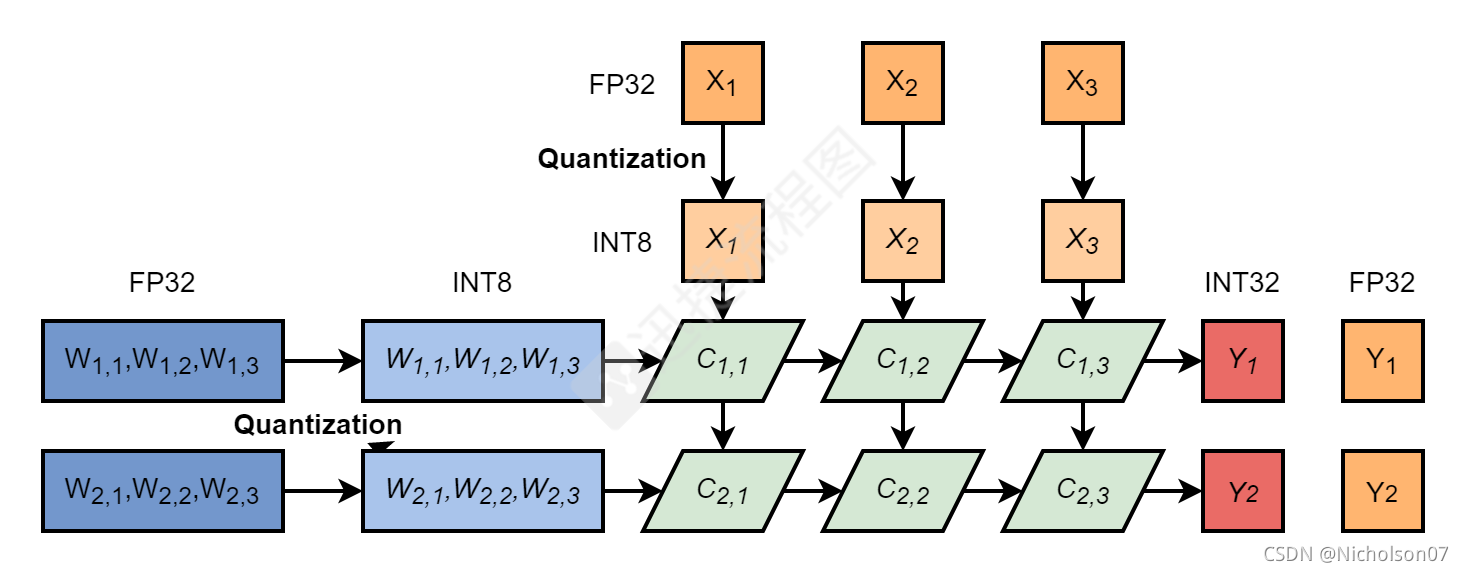 图12 INT8卷积层推理流程-量化
图12 INT8卷积层推理流程-量化
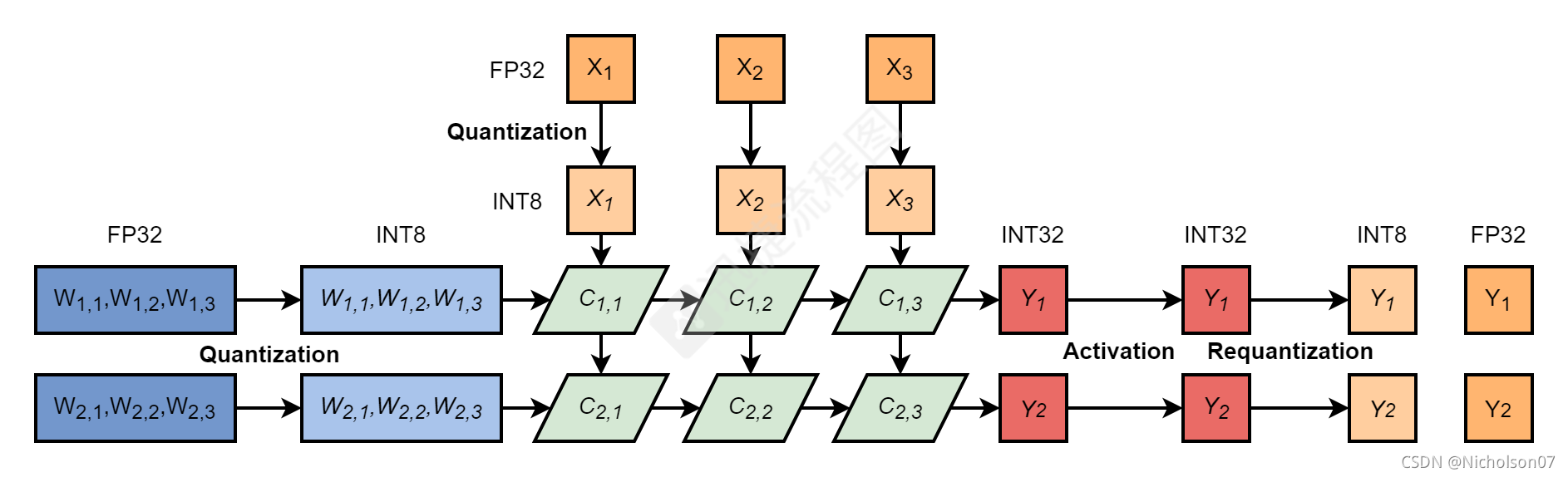
图13 INT8卷积层推理流程-激活与再量化
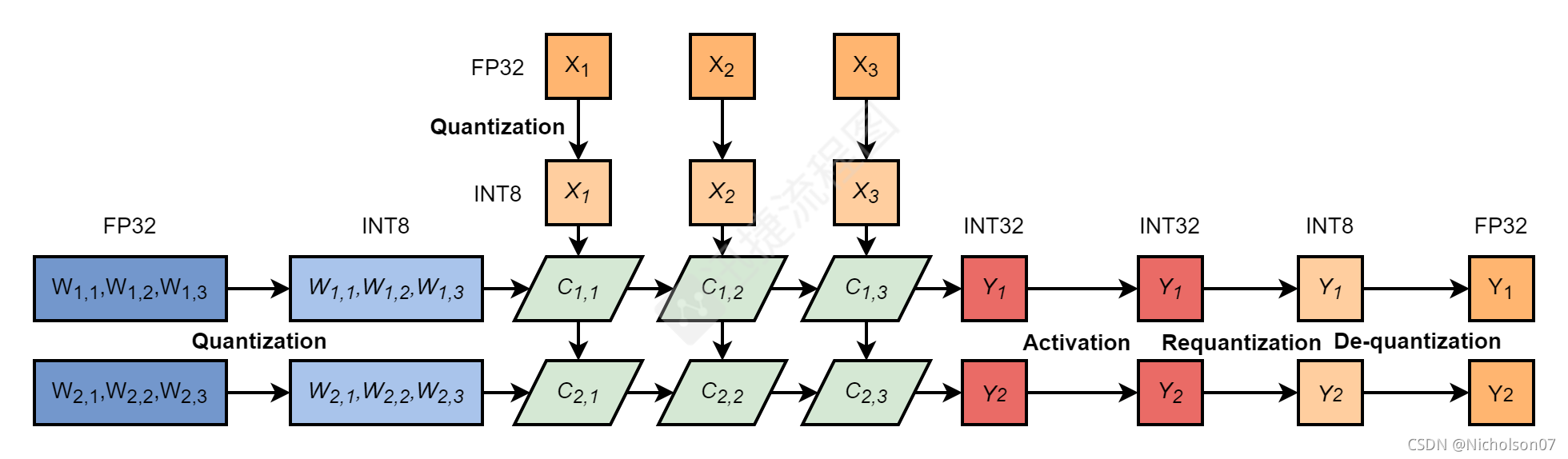 图14 INT8卷积层推理流程-反量化
图14 INT8卷积层推理流程-反量化
整个流程中的关键部分就是FP32至INT8的量化、INT32至INT8的再量化以及INT8至FP32的反量化,其实三者的基本原理都是6.2所讲的线性量化(线性映射)。
量化和反量化就不再赘述,但是再量化需要展开解释一下。前文提到了TensorRT的量化忽略了bias,简化了量化流程,但是有些层确实需要bias时,该怎么处理呢?这里影响到的主要就是再量化的过程,具体流程见图15-16。
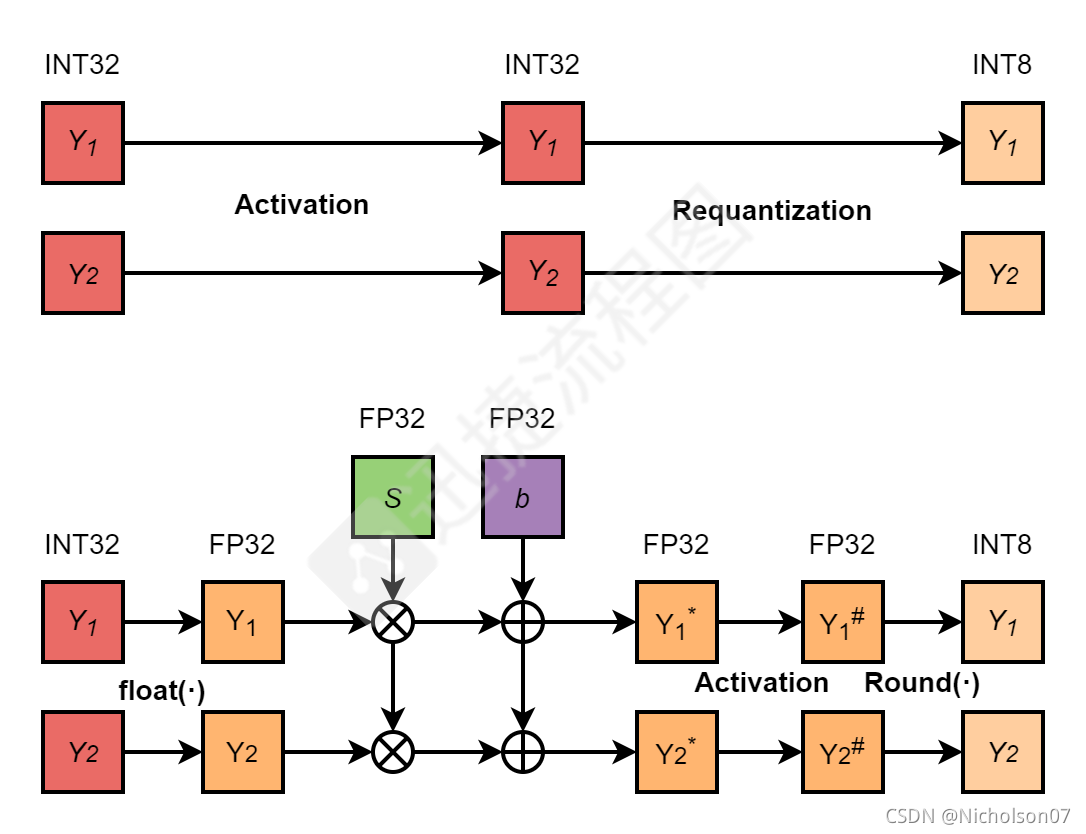
图15 INT8卷积层推理流程-含bias的再量化

图16 官方伪代码
7.4 INT8校准
7.4.1 为什么需要校准这个过程
我们首先要明确的是,需要INT8校准的前提是使用到了激活量化,具体原因读者可以回顾一下5.4节。
那么为什么需要这个过程有三个主要原因:
1.网络的激活值不会保存在网络参数中,属于运行过程中产生的值,因此我们难以预先确定它的范围;
2.读者回顾6.2.2的分析可知,当S取大时,可以扩大量化域,但同时,单个INT8数值可表示的FP32范围也变广了,因此INT8数值与FP32数值的误差(量化误差)会增大;而当S取小时,量化误差虽然减小了,但是量化域也缩小了,被舍弃的参数会增多。
3.但是为什么对于不同模型都可行?如果有些模型缩小量化域导致的精度下降更明显,那INT8量化后的精度是不是必然有大幅下降了呢?
其实不然,读者回顾6.1可知,量化属于浮点数向定点数转换的过程,由于浮点数的可表示数值间隙密度不同,导致零点附近的浮点数可表示数值很多,大约2^31个,约等于可表示数值量的一半。因此,越是靠近零点的浮点数表示越准确,越是远离原点的位置越有可能是噪声,并且网络的权重和激活大多分布在零点附近,因此适当的缩小量化域能提升量化精度几乎是必然的。
7.4.2 INT8校准的目的
通过以上分析也很清晰了,INT8校准就是一种权衡,为了找到合适的缩放参数,使得量化后的INT8数值能更准确的表示出量化前的FP32数值,并且又不能舍弃太多远离零点的非噪声参数。
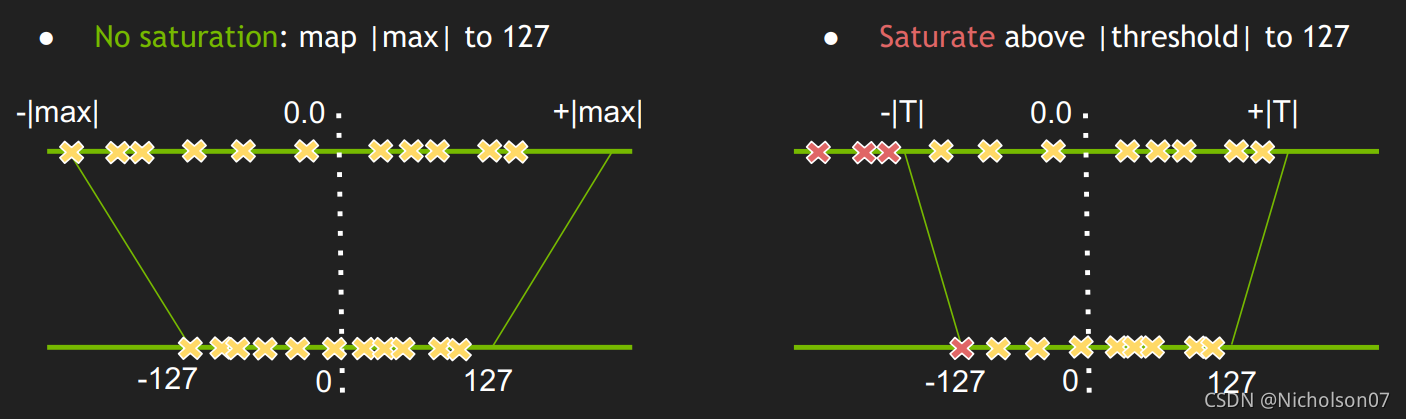
图17 官方INT8校准示意图
7.4.3 如何实现INT8校准
7.4.3.1 校准前激活分布
举个例子,我们使用同一批图片在不同模型上训练,然后从不同网络层中可以得到对应的激活值分布,见图18。
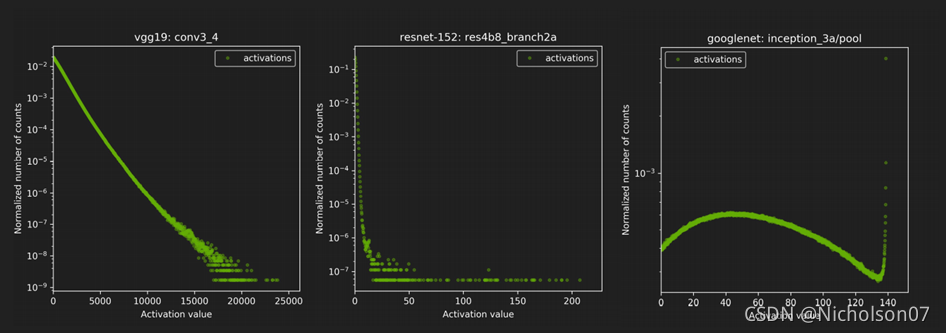
图18 同一批数据在不同网络不同层上得到的激活值分布(官方)
可以发现分布都不相同,那么如何选取最优的阈值呢?
这就需要一个定量的衡量指标,回顾前文5.4.3可以知道常用的手段是指数平滑法、直方图截断法和KL散度校准法,TensorRT使用的是KL散度校准法。
7.4.3.2 KL散度校准法原理
KL散度校准法也叫相对熵,一听这个名字是不是感觉和交叉熵、信息熵啥的有关系,没错,我们来看KL的公式:
其中p表示真实分布,q表示非真实分布、模型分布或p的近似分布。
可以发现相对熵=交叉熵-信息熵。那么交叉熵和信息熵又是什么呢?
信息熵表示的是随机变量分布的混乱程度或整个系统的不确定性,随机变量越混乱(无序性)或系统的不确定性就越大,熵越大。当随机分布为均匀分布时,熵最大。
交叉熵,其用来衡量在给定的真实分布下,使用非真实分布所指定的策略消除系统的不确定性所需要付出的努力的大小。交叉熵一定是大于等于信息熵的。
相对熵,用来衡量真实分布与非真实分布的差异大小。
具体可以看这边文章。
如何通俗的解释交叉熵与相对熵? – 知乎 (zhihu.com)
现在问题就很简单了,我们的目的就是改变量化域,实则就是改变真实的分布,并使得修改后得真实分布在量化后与量化前相对熵越小越好。
7.4.3.3 具体实现流程
- 需要准备500张(TensorRT官方推荐)校准用的数据集;
- 使用校准数据集在FP32精度的网络下推理,并收集激活值的直方图;
- 不断调整阈值,并计算相对熵,得到最优解。
官方伪代码如下:

图19 KL校准的官方伪代码
- 将校准集下得到的直方图划分成2048个Bins(官方推荐)
- 在[128,2048]范围内循环执行以下3-5步骤
- 将第i个bin后的所有数值累加到第i-1个bin上,并对前i个bins归一化,作为P分布(真实分布)
- 对P量化得到Q并归一化
- 计算P与Q的相对熵
- 得到最小相对熵的i,阈值T=(i+0.5)*bin的宽度
7.4.3.4 校准后数据分布
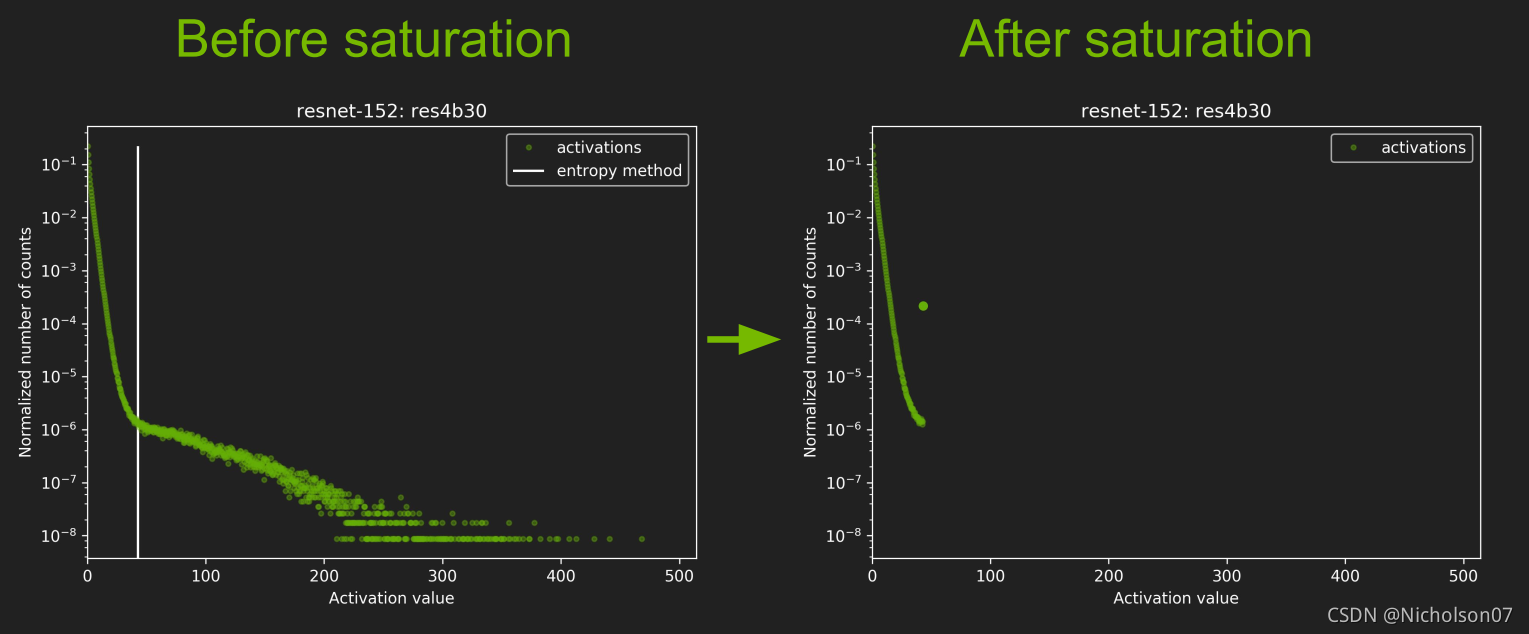
图20 校准后分布1(官方)
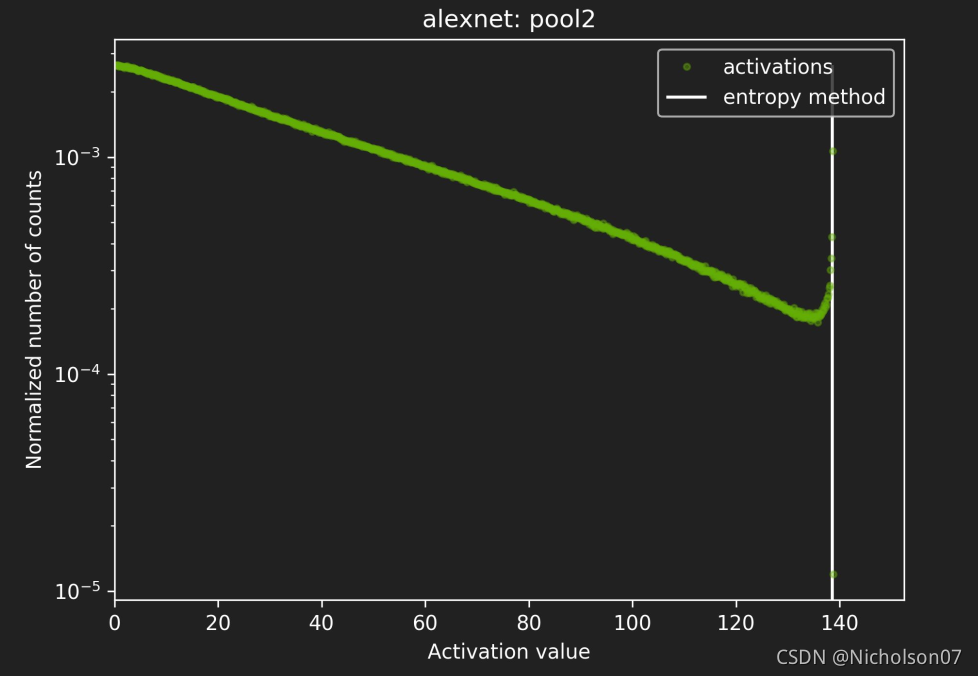
图21 校准后分布2(官方)
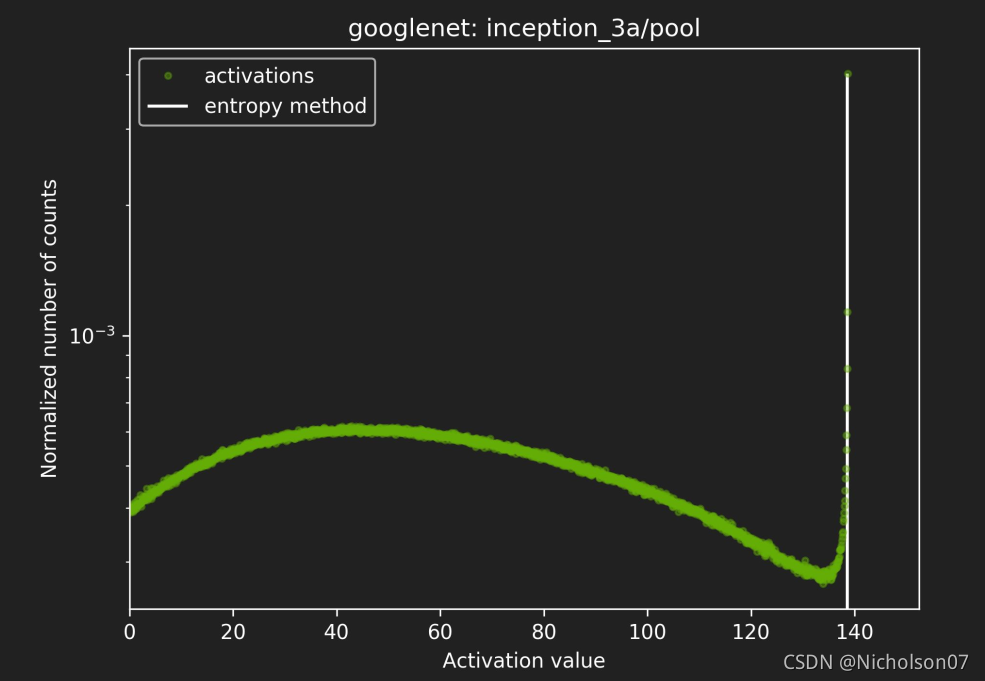
图22 校准后分布3(官方)
7.5 量化后准确度和速度提升效果
加速后的准确度几乎没有下降。
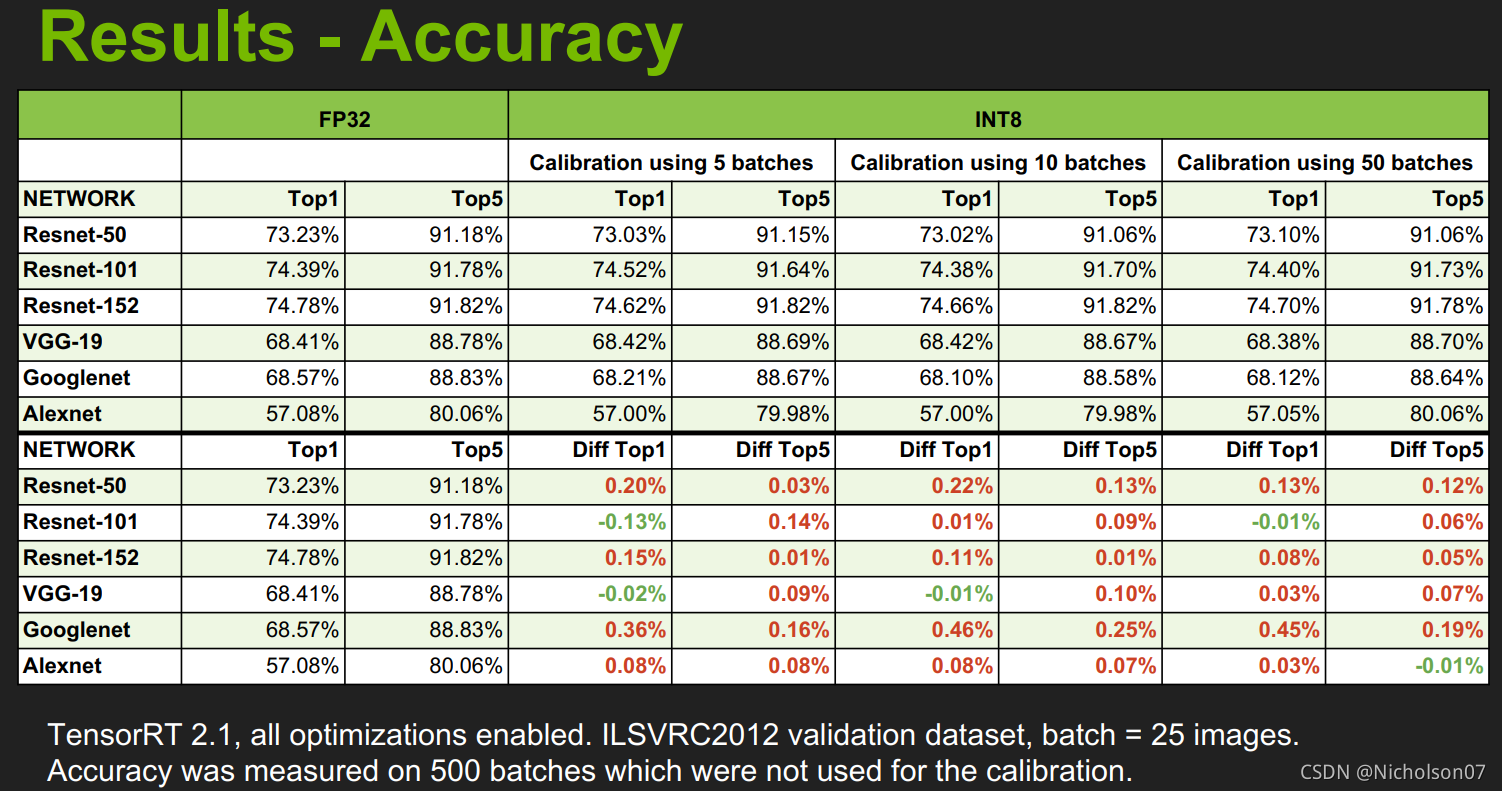
图23 量化后准确度(官方)
量化后的加速效果比较,从结果上可以发现,在不同GPU上推理的加速效果不同,并且随着batchsize提高,加速效果也在提升。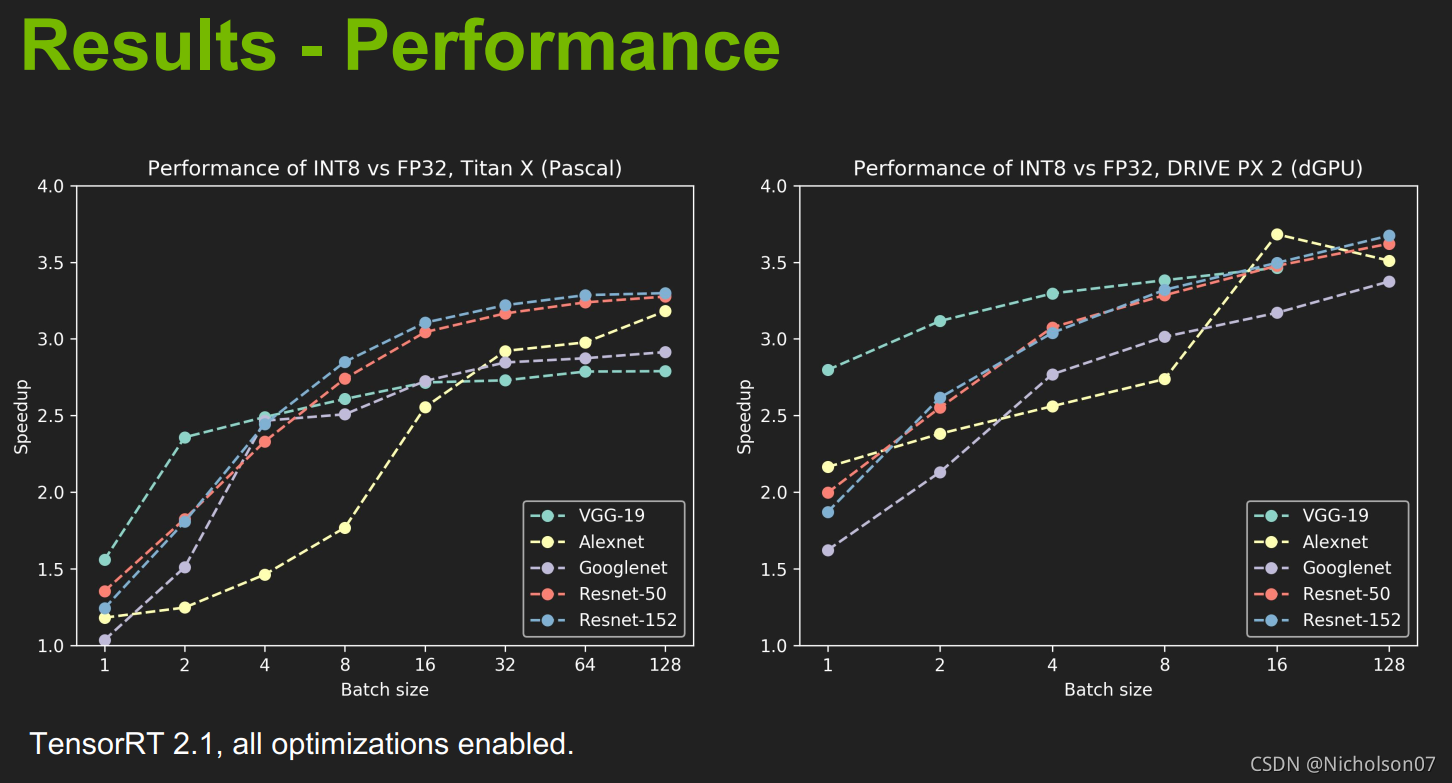
图24 量化后速度提升效果(官方)
7.6 总结
- 一种自动化,无参数的 FP32 到 INT8 的转换方法;
- 通过最小化KL散度来选择量化的阈值;
- 量化后精度几乎持平,速度有很大提升。
八、C++实现TensorRT INT8量化
8.1 程序流程
TensorRT在做的其实只有一件事,就是把不同框架下训练得到的模型转换成Engine,然后使用Engine进行推理。这里支持的框架包括ONNX、TensorFlow等,见图25。
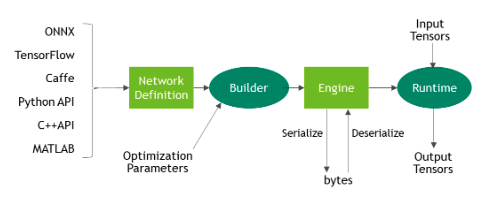
图25 TensorRT流程(官方)
下面我们来讲一下具体的细节,读者也可以参考官方示例,sampleINT8,由于代码比较长,我就贴在附录里了,感兴趣的读者可以参考。
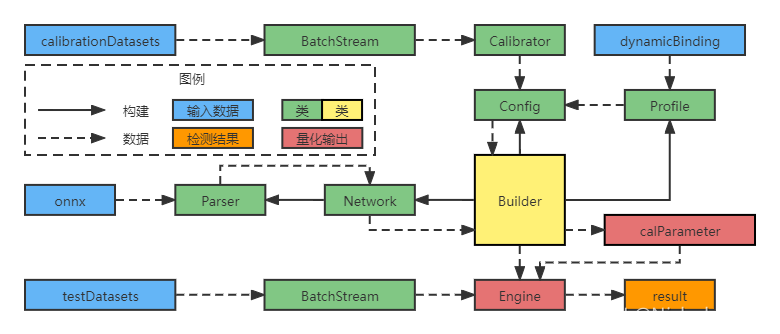
图26 TensorRT INT8程序流程图
- 构建Builder,并使用Builder构建Network用于存储模型信息;
- 使用Network构建Parser用于从onnx文件中解析模型信息并回传给Network;
- 使用Builder构建Profile用于设置动态维度,并从dynamicBinding中获取动态维度信息;
- 构建Calibrator用于校准模型,并通过BatchStream加载校准数据集;
- 使用Builder构建Config用于配置生成Engine的参数,包括Calibrator和Profile;
- Builder使用Network中的模型信息和Config中的参数生成Engine以及校准参数calParameter;
- 通过BatchStream加载待测试数据集并传入Engine,输出最终结果result。
其中值得注意的是Calibrator和BatchStream,这两个类都是需要根据项目需要重写的。
8.2 Calibrator
为了将校准数据集输入TensorRT,我们需要用到IInt8Calibrator抽象类,TensorRT一共提供了四种IInt8Calibrator:
- IEntropyCalibratorV2:最适合卷积网络CNN的校准器,并且本文也是使用这个类实现的;
- IMinMaxCalibrator:这适合自然语言处理NLP中;
- IEntropyCalibrator:已经弃用;
- ILegacyCalibrator:已经弃用,且需要用户手动设置参数。
IInt8Calibrator实现的功能也很简单:
- getBatchSize:获取校准过程中的batchSize;
- getBatch:获取校准过程中的输入;
- writeCalibrationCache:由于校准花费的时间比较长,调用该函数将校准参数结果写入本地文件,方便下次直接读取。
- readCalibrationCache:读取保存在本地的校准参数文件,在生成引擎过程中会自动调用。
废话不多说了,直接上代码,个人的开发代码不方便上传就给大家看看官方代码了,我在这里修改得主要是一些函数的参数罢了,大体的功能是一样的。
/*
* Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
#ifndef ENTROPY_CALIBRATOR_H
#define ENTROPY_CALIBRATOR_H
#include "BatchStream.h"
#include "NvInfer.h"
//! \class EntropyCalibratorImpl
//!
//! \brief Implements common functionality for Entropy calibrators.
//!
template <typename TBatchStream>
class EntropyCalibratorImpl
{
public:
EntropyCalibratorImpl(
TBatchStream stream, int firstBatch, std::string networkName, const char* inputBlobName, bool readCache = true)
: mStream{stream}
, mCalibrationTableName("CalibrationTable" + networkName)
, mInputBlobName(inputBlobName)
, mReadCache(readCache)
{
nvinfer1::Dims dims = mStream.getDims();
mInputCount = samplesCommon::volume(dims);
CHECK(cudaMalloc(&mDeviceInput, mInputCount * sizeof(float)));
mStream.reset(firstBatch);
}
virtual ~EntropyCalibratorImpl()
{
CHECK(cudaFree(mDeviceInput));
}
int getBatchSize() const noexcept
{
return mStream.getBatchSize();
}
bool getBatch(void* bindings[], const char* names[], int nbBindings) noexcept
{
if (!mStream.next())
{
return false;
}
CHECK(cudaMemcpy(mDeviceInput, mStream.getBatch(), mInputCount * sizeof(float), cudaMemcpyHostToDevice));
ASSERT(!strcmp(names[0], mInputBlobName));
bindings[0] = mDeviceInput;
return true;
}
const void* readCalibrationCache(size_t& length) noexcept
{
mCalibrationCache.clear();
std::ifstream input(mCalibrationTableName, std::ios::binary);
input >> std::noskipws;
if (mReadCache && input.good())
{
std::copy(std::istream_iterator<char>(input), std::istream_iterator<char>(),
std::back_inserter(mCalibrationCache));
}
length = mCalibrationCache.size();
return length ? mCalibrationCache.data() : nullptr;
}
void writeCalibrationCache(const void* cache, size_t length) noexcept
{
std::ofstream output(mCalibrationTableName, std::ios::binary);
output.write(reinterpret_cast<const char*>(cache), length);
}
private:
TBatchStream mStream;
size_t mInputCount;
std::string mCalibrationTableName;
const char* mInputBlobName;
bool mReadCache{true};
void* mDeviceInput{nullptr};
std::vector<char> mCalibrationCache;
};
//! \class Int8EntropyCalibrator2
//!
//! \brief Implements Entropy calibrator 2.
//! CalibrationAlgoType is kENTROPY_CALIBRATION_2.
//!
template <typename TBatchStream>
class Int8EntropyCalibrator2 : public IInt8EntropyCalibrator2
{
public:
Int8EntropyCalibrator2(
TBatchStream stream, int firstBatch, const char* networkName, const char* inputBlobName, bool readCache = true)
: mImpl(stream, firstBatch, networkName, inputBlobName, readCache)
{
}
int getBatchSize() const noexcept override
{
return mImpl.getBatchSize();
}
bool getBatch(void* bindings[], const char* names[], int nbBindings) noexcept override
{
return mImpl.getBatch(bindings, names, nbBindings);
}
const void* readCalibrationCache(size_t& length) noexcept override
{
return mImpl.readCalibrationCache(length);
}
void writeCalibrationCache(const void* cache, size_t length) noexcept override
{
mImpl.writeCalibrationCache(cache, length);
}
private:
EntropyCalibratorImpl<TBatchStream> mImpl;
};
#endif // ENTROPY_CALIBRATOR_H从代码中可以看到,校准器类中没有直接实现getBatchSize和getBatch,而是使用TBatchStream模板类实现,这就是BatchSteam的作用了。
8.3 BatchStream
BatchStream类继承于IBatchStream,它实现的功能就是从给定的数据集中读取数据和标签,实现预处理并能按要求的BatchSize遍历数据和标签,具体如下:
- reset:设置起始的Batch索引;
- next:索引加一,准备读取下一个batch,直到数据集遍历完成;
- skip:跳转到指定索引的Batch;
- getBatch:获取当前索引的数据;
- getLabels:获取当前索引的标签;
- getBatchesRead:获取当前索引;
- getBatchSize:获取BatchSize;
- getDims:获取当前数据的维度;
- readDataFile:读取数据集中的数据;
- readLabelsFile:读取数据集中的标签。
前八个是IBatchSize中已经定义的函数,后两个是自己定义的私有函数,不是必须的。
同样给大家看看官方代码,这里包含了一个针对MNIST任务的重写类,读者也得按需重写。
/*
* Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
#ifndef BATCH_STREAM_H
#define BATCH_STREAM_H
#include "NvInfer.h"
#include "common.h"
#include <algorithm>
#include <stdio.h>
#include <vector>
class IBatchStream
{
public:
virtual void reset(int firstBatch) = 0;
virtual bool next() = 0;
virtual void skip(int skipCount) = 0;
virtual float* getBatch() = 0;
virtual float* getLabels() = 0;
virtual int getBatchesRead() const = 0;
virtual int getBatchSize() const = 0;
virtual nvinfer1::Dims getDims() const = 0;
};
class MNISTBatchStream : public IBatchStream
{
public:
MNISTBatchStream(int batchSize, int maxBatches, const std::string& dataFile, const std::string& labelsFile,
const std::vector<std::string>& directories)
: mBatchSize{batchSize}
, mMaxBatches{maxBatches}
, mDims{3, {1, 28, 28}} //!< We already know the dimensions of MNIST images.
{
readDataFile(locateFile(dataFile, directories));
readLabelsFile(locateFile(labelsFile, directories));
}
void reset(int firstBatch) override
{
mBatchCount = firstBatch;
}
bool next() override
{
if (mBatchCount >= mMaxBatches)
{
return false;
}
++mBatchCount;
return true;
}
void skip(int skipCount) override
{
mBatchCount += skipCount;
}
float* getBatch() override
{
return mData.data() + (mBatchCount * mBatchSize * samplesCommon::volume(mDims));
}
float* getLabels() override
{
return mLabels.data() + (mBatchCount * mBatchSize);
}
int getBatchesRead() const override
{
return mBatchCount;
}
int getBatchSize() const override
{
return mBatchSize;
}
nvinfer1::Dims getDims() const override
{
return Dims{4, {mBatchSize, mDims.d[0], mDims.d[1], mDims.d[2]}};
}
private:
void readDataFile(const std::string& dataFilePath)
{
std::ifstream file{dataFilePath.c_str(), std::ios::binary};
int magicNumber, numImages, imageH, imageW;
file.read(reinterpret_cast<char*>(&magicNumber), sizeof(magicNumber));
// All values in the MNIST files are big endian.
magicNumber = samplesCommon::swapEndianness(magicNumber);
ASSERT(magicNumber == 2051 && "Magic Number does not match the expected value for an MNIST image set");
// Read number of images and dimensions
file.read(reinterpret_cast<char*>(&numImages), sizeof(numImages));
file.read(reinterpret_cast<char*>(&imageH), sizeof(imageH));
file.read(reinterpret_cast<char*>(&imageW), sizeof(imageW));
numImages = samplesCommon::swapEndianness(numImages);
imageH = samplesCommon::swapEndianness(imageH);
imageW = samplesCommon::swapEndianness(imageW);
// The MNIST data is made up of unsigned bytes, so we need to cast to float and normalize.
int numElements = numImages * imageH * imageW;
std::vector<uint8_t> rawData(numElements);
file.read(reinterpret_cast<char*>(rawData.data()), numElements * sizeof(uint8_t));
mData.resize(numElements);
std::transform(
rawData.begin(), rawData.end(), mData.begin(), [](uint8_t val) { return static_cast<float>(val) / 255.f; });
}
void readLabelsFile(const std::string& labelsFilePath)
{
std::ifstream file{labelsFilePath.c_str(), std::ios::binary};
int magicNumber, numImages;
file.read(reinterpret_cast<char*>(&magicNumber), sizeof(magicNumber));
// All values in the MNIST files are big endian.
magicNumber = samplesCommon::swapEndianness(magicNumber);
ASSERT(magicNumber == 2049 && "Magic Number does not match the expected value for an MNIST labels file");
file.read(reinterpret_cast<char*>(&numImages), sizeof(numImages));
numImages = samplesCommon::swapEndianness(numImages);
std::vector<uint8_t> rawLabels(numImages);
file.read(reinterpret_cast<char*>(rawLabels.data()), numImages * sizeof(uint8_t));
mLabels.resize(numImages);
std::transform(
rawLabels.begin(), rawLabels.end(), mLabels.begin(), [](uint8_t val) { return static_cast<float>(val); });
}
int mBatchSize{0};
int mBatchCount{0}; //!< The batch that will be read on the next invocation of next()
int mMaxBatches{0};
Dims mDims{};
std::vector<float> mData{};
std::vector<float> mLabels{};
};
到这里就把整个程序实现的流程和关键部分说明了。
九、量化效果测试
最后为了实际测试量化的效果,我选取不同复杂度的模型进行了测试,分别是Alexnet、Resnet50、VGG13,具体的参数量和FLOPS(每秒浮点运算次数,Floating-Point Operations Per Second)可以参考第二章的表1和下图27。
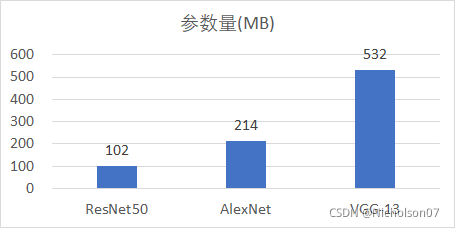
a 参数量比较
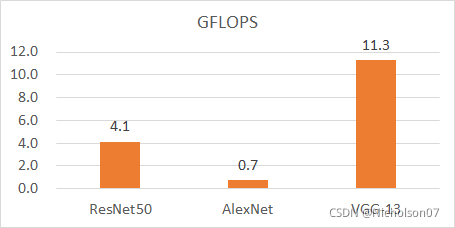
b 计算量比较
图27 三种模型的比较
参考第三章,测试的对比组就很清晰了,分别是引擎尺寸(引擎尺寸与模型尺寸还有一些差异,比较引擎尺寸更加有意义)、运算功耗、显存占用、推理速度以及检测精度。其中,前三种都影响到了硬件的需求,我们把他们分为物理性能;后两类体现了引擎的检测效果,可以分为另一类检测性能。
另外,运算功耗和显存占用需要使用Nvidia的命令行指令,在anaconda prompt中输入如下指令即可显示显卡的详细信息,见图28。
nvidia-smi -l 2 #l参数表示刷新间隔(s)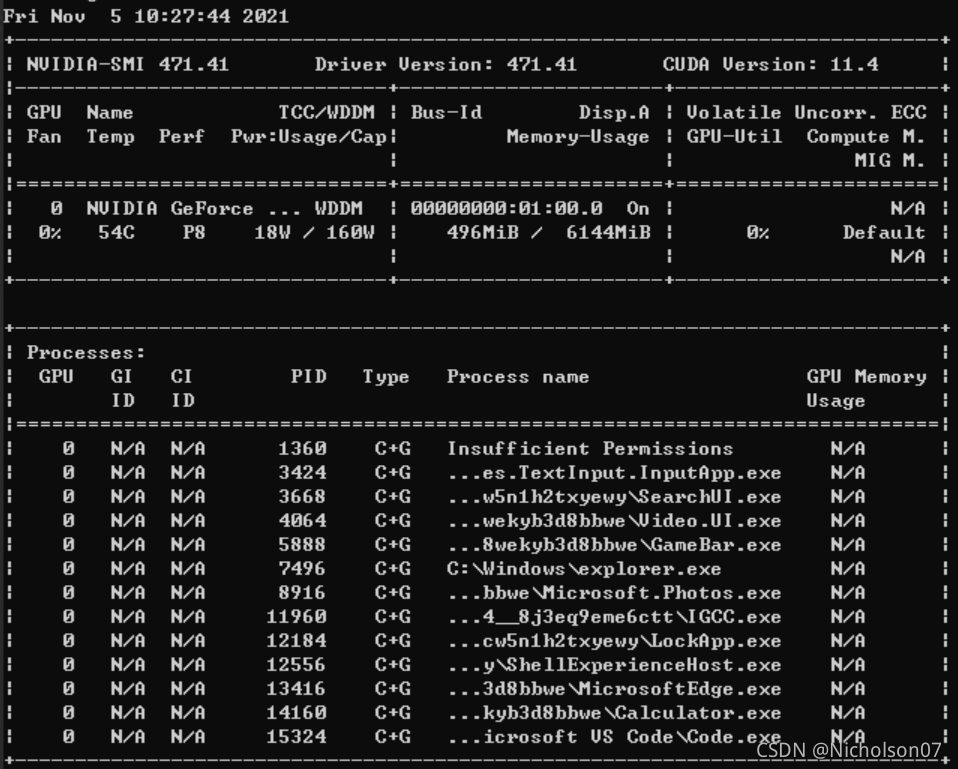
图28 显卡信息
表格参数详解:
-
GPU:本机中的GPU编号(有多块显卡的时候,从0开始编号)图上GPU的编号是:0
-
Fan:风扇转速(0%-100%),N/A表示没有风扇
-
Name:GPU类型,图上GPU的类型是:Tesla T4
-
Temp:GPU的温度(GPU温度过高会导致GPU的频率下降)
-
Perf:GPU的性能状态,从P0(最大性能)到P12(最小性能),图上是:P0
-
Persistence-M:持续模式的状态,持续模式虽然耗能大,但是在新的GPU应用启动时花费的时间更少,图上显示的是:off
-
Pwr:Usager/Cap:能耗表示,Usage:用了多少,Cap总共多少
-
Bus-Id:GPU总线相关显示,domain:bus:device.function
-
Disp.A:Display Active ,表示GPU的显示是否初始化
-
Memory-Usage:显存使用率
-
Volatile GPU-Util:GPU使用率
-
Uncorr. ECC:关于ECC的东西,是否开启错误检查和纠正技术,0/disabled,1/enabled
-
Compute M:计算模式,0/DEFAULT,1/EXCLUSIVE_PROCESS,2/PROHIBITED
-
Processes:显示每个进程占用的显存使用率、进程号、占用的哪个GPU
也可以使用以下指令直接将结果写入文件,具体详见GPU之nvidia-smi命令详解 – 简书 (jianshu.com)
nvidia-smi -l 2 --format=csv --filename=gpucost.csv --query-gpu=timestamp,memory.total,memeory.used9.1 测试环境
- GPU NVIDIA GeForce RTX 2060
- CUDA 10.2.89
- CUDNN 7.6.5
- TensorRT 7.2.1
9.2 物理性能
注:除BatchSize和DataSize作为变量时,其他测试下BatchSize=5,DataSize=500张。
9.2.1引擎尺寸
结合图27a可以发现,引擎尺寸与模型的参数量正相关,且随着量化位数降低,有明显的下降,从FP32-INT8能下降约80%,从FP16-INT8也有约50%。
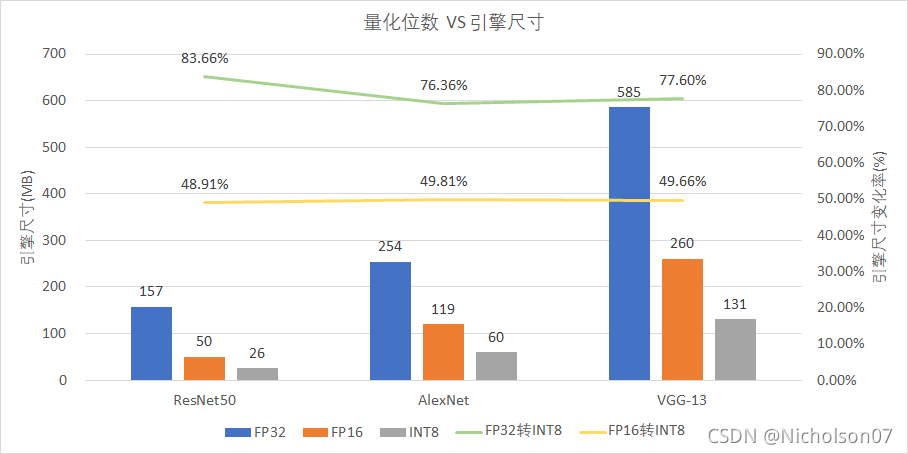
图29 引擎大小
9.2.2 运算功耗
结合图27b可以发现,整体趋势是,模型计算量FLOPS越大,运算功耗下降比例越高。
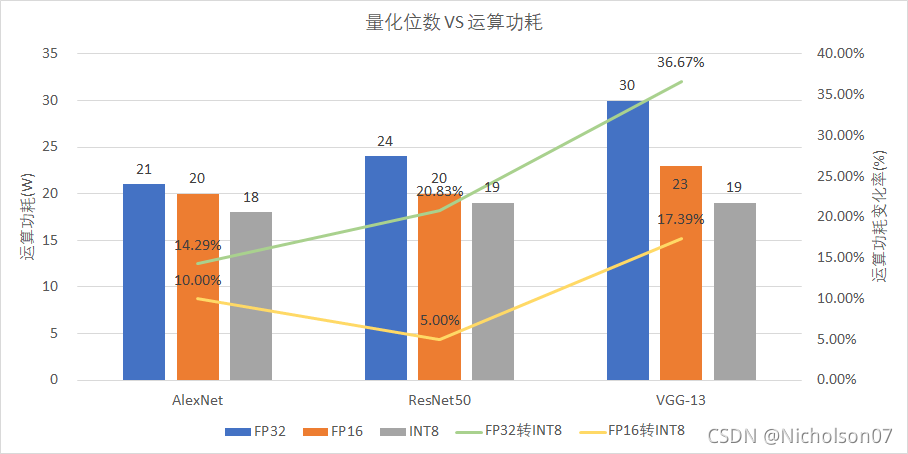
图30 运行功耗
9.2.3 显存占用
结合图27b可以发现,对于大模型计算量较大的模型来说,显存占用下降比较明显,但似乎上限是50%。
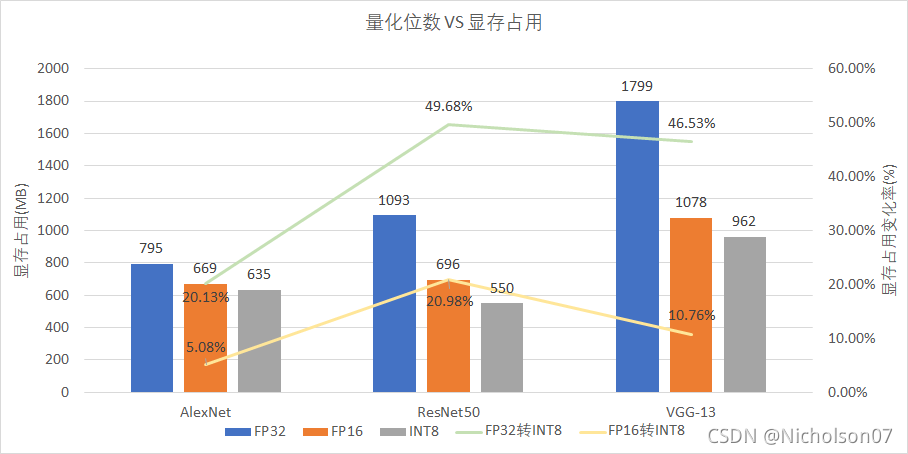
图31 显存占用
9.3 检测效果
检测效果是我们最关心的点,毕竟量化的主要目的就是在保持准确度的前提下提升速度。
9.3.1 推理速度
从图上我们可以发现,INT8量化后的推理速度相对于FP32和FP16都有显著提升。相对于FP32来说模型FLOPS越高,加速效果越好,VGG-13的提速效果达到了7倍,但是从FP16到INT8的效果就与模型复杂度关系不大了,约2倍不到。
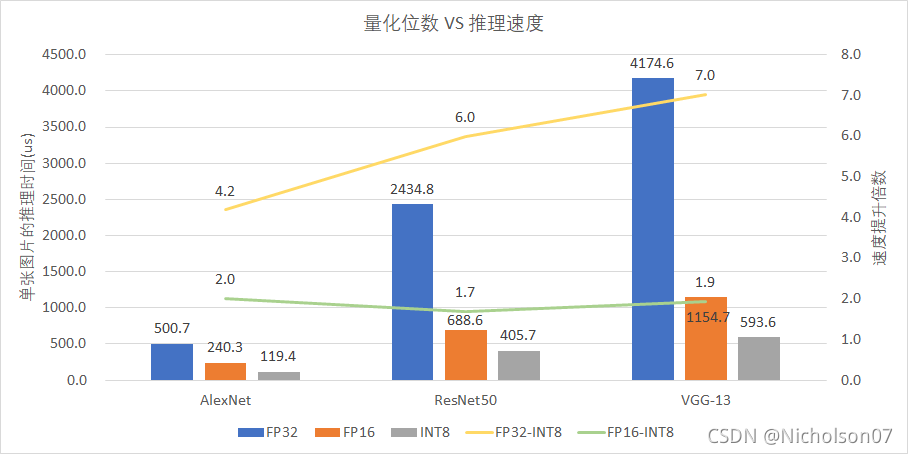
图32 推理速度
9.3.2 检测准确度
可以看到INT8量化后数据集的准确度相比FP32下几乎没有变化,这直接验证了INT8量化的可行性。
在这基础上,我们进一步测试一下校准数据集大小以及推理时的BatchSize对检测准确度的影响。首先比较了校准数据集大小的影响。可以看到随着数据集变大,准确度略有下降。但是考虑到官方推荐是500张校准数据集,之后有机会可以进一步验证是否与其他因素有关。
| BatchSize=5 | FP32 | FP16 | INT8(数据集大小) | |||||
| 100 | 300 | 500 | 700 | 900 | ||||
| 准确度(%) | ||||||||
| Network | AlexNet | 87.84% | 87.73% | 88.64% | 88.52% | 88.52% | 88.52% | 88.41% |
| ResNet50 | 97.61% | 97.61% | 97.73% | 97.61% | 97.61% | 97.50% | 97.39% | |
| VGG-13 | 97.39% | 97.39% | 97.39% | 97.27% | 97.16% | 97.16% | 97.05% | |
| FP32转INT8 准确度变化(%) | ||||||||
| AlexNet | 87.84% | 87.73% | 0.80% | 0.68% | 0.68% | 0.68% | 0.57% | |
| ResNet50 | 97.61% | 97.61% | 0.11% | 0.00% | 0.00% | -0.11% | -0.23% | |
| VGG-13 | 97.39% | 97.39% | 0.00% | -0.11% | -0.23% | -0.23% | -0.34% | |
表7 检测准确度测试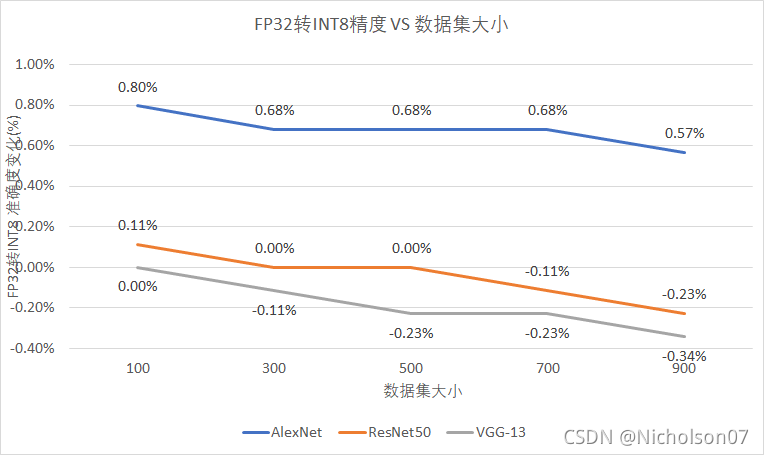
图33 检测准确度测试
然后我们比较了一下BatchSize的影响,从图上可以更清晰的看到准确度有先上升后下降的趋势,在BatchSize=8时达到了最高值,按照官方的数据,应该不会有下降的过程,我认为是显卡性能的关系,有机会可以用其他显卡再测试一下。
| DataSize=500 | BatchSize | ||||||||
| 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | ||
| 单张图片推理时间(us) | |||||||||
| Network | AlexNet | 132.199 | 122.701 | 122.666 | 119.574 | 122.919 | 121.464 | 142.217 | 177.197 |
| ResNet50 | 476.866 | 446.152 | 436.84 | 405.513 | 448.45 | 473.267 | 454.716 | 433.675 | |
| VGG-13 | 617.144 | 618.869 | 614.11 | 609.547 | 625.358 | 633.083 | 634.107 | 691.968 | |
| 单张图片推理时间变化率(%) | |||||||||
| AlexNet | 0.00% | 7.18% | 7.21% | 9.55% | 7.02% | 8.12% | -7.58% | -34.04% | |
| ResNet50 | 0.00% | 6.44% | 8.39% | 14.96% | 5.96% | 0.75% | 4.64% | 9.06% | |
| VGG-13 | 0.00% | -0.28% | 0.49% | 1.23% | -1.33% | -2.58% | -2.75% | -12.12% | |
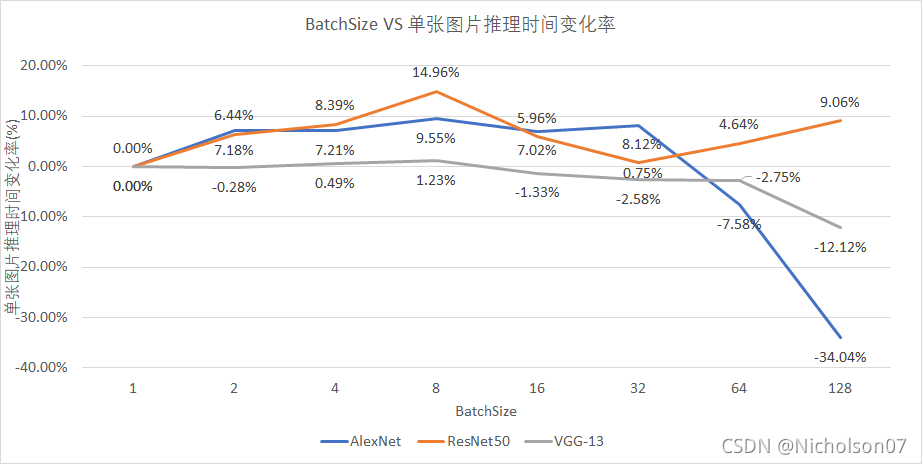
9.4 总结
- FP32-FP16及FP16-INT8转换均能减少约50%引擎尺寸,并能有效降低运算功耗和显存占用;
- 从FP32-INT8可大幅提升推理速度,且与模型FLOPS成正比,但从FP16-INT8只能提高2倍左右;
- INT8量化后准确度相比FP32几乎没有下降,但随校准数据集增大有略微下降(后半句存疑);
- INT8量化后推理速度随BatchSize增大而增大,但会受显卡运算能力限制(后半句存疑);
十、附录
sampleINT8.cpp
/*
* Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
//!
//! SampleINT8.cpp
//! This file contains the implementation of the sample. It creates the network using
//! the caffe model.
//! It can be run with the following command line:
//! Command: ./sample_int8 [-h or --help] [-d=/path/to/data/dir or --datadir=/path/to/data/dir]
//!
#include "BatchStream.h"
#include "EntropyCalibrator.h"
#include "argsParser.h"
#include "buffers.h"
#include "common.h"
#include "logger.h"
#include "NvCaffeParser.h"
#include "NvInfer.h"
#include <cuda_runtime_api.h>
#include <cstdlib>
#include <fstream>
#include <iostream>
#include <sstream>
using samplesCommon::SampleUniquePtr;
const std::string gSampleName = "TensorRT.sample_int8";
//!
//! \brief The SampleINT8Params structure groups the additional parameters required by
//! the INT8 sample.
//!
struct SampleINT8Params : public samplesCommon::CaffeSampleParams
{
int nbCalBatches; //!< The number of batches for calibration
int calBatchSize; //!< The calibration batch size
std::string networkName; //!< The name of the network
};
//! \brief The SampleINT8 class implements the INT8 sample
//!
//! \details It creates the network using a caffe model
//!
class SampleINT8
{
public:
SampleINT8(const SampleINT8Params& params)
: mParams(params)
, mEngine(nullptr)
{
initLibNvInferPlugins(&sample::gLogger.getTRTLogger(), "");
}
//!
//! \brief Function builds the network engine
//!
bool build(DataType dataType);
//!
//! \brief Runs the TensorRT inference engine for this sample
//!
bool infer(std::vector<float>& score, int firstScoreBatch, int nbScoreBatches);
//!
//! \brief Cleans up any state created in the sample class
//!
bool teardown();
private:
SampleINT8Params mParams; //!< The parameters for the sample.
nvinfer1::Dims mInputDims; //!< The dimensions of the input to the network.
std::shared_ptr<nvinfer1::ICudaEngine> mEngine; //!< The TensorRT engine used to run the network
//!
//! \brief Parses a Caffe model and creates a TensorRT network
//!
bool constructNetwork(SampleUniquePtr<nvinfer1::IBuilder>& builder,
SampleUniquePtr<nvinfer1::INetworkDefinition>& network, SampleUniquePtr<nvinfer1::IBuilderConfig>& config,
SampleUniquePtr<nvcaffeparser1::ICaffeParser>& parser, DataType dataType);
//!
//! \brief Reads the input and stores it in a managed buffer
//!
bool processInput(const samplesCommon::BufferManager& buffers, const float* data);
//!
//! \brief Scores model
//!
int calculateScore(
const samplesCommon::BufferManager& buffers, float* labels, int batchSize, int outputSize, int threshold);
};
//!
//! \brief Creates the network, configures the builder and creates the network engine
//!
//! \details This function creates the network by parsing the caffe model and builds
//! the engine that will be used to run the model (mEngine)
//!
//! \return Returns true if the engine was created successfully and false otherwise
//!
bool SampleINT8::build(DataType dataType)
{
auto builder = SampleUniquePtr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(sample::gLogger.getTRTLogger()));
if (!builder)
{
return false;
}
if ((dataType == DataType::kINT8 && !builder->platformHasFastInt8())
|| (dataType == DataType::kHALF && !builder->platformHasFastFp16()))
{
return false;
}
auto network = SampleUniquePtr<nvinfer1::INetworkDefinition>(builder->createNetworkV2(0));
if (!network)
{
return false;
}
auto config = SampleUniquePtr<nvinfer1::IBuilderConfig>(builder->createBuilderConfig());
if (!config)
{
return false;
}
auto parser = SampleUniquePtr<nvcaffeparser1::ICaffeParser>(nvcaffeparser1::createCaffeParser());
if (!parser)
{
return false;
}
auto constructed = constructNetwork(builder, network, config, parser, dataType);
if (!constructed)
{
return false;
}
ASSERT(network->getNbInputs() == 1);
mInputDims = network->getInput(0)->getDimensions();
ASSERT(mInputDims.nbDims == 3);
return true;
}
//!
//! \brief Uses a caffe parser to create the network and marks the
//! output layers
//!
//! \param network Pointer to the network that will be populated with the network
//!
//! \param builder Pointer to the engine builder
//!
bool SampleINT8::constructNetwork(SampleUniquePtr<nvinfer1::IBuilder>& builder,
SampleUniquePtr<nvinfer1::INetworkDefinition>& network, SampleUniquePtr<nvinfer1::IBuilderConfig>& config,
SampleUniquePtr<nvcaffeparser1::ICaffeParser>& parser, DataType dataType)
{
mEngine = nullptr;
const nvcaffeparser1::IBlobNameToTensor* blobNameToTensor
= parser->parse(locateFile(mParams.prototxtFileName, mParams.dataDirs).c_str(),
locateFile(mParams.weightsFileName, mParams.dataDirs).c_str(), *network,
dataType == DataType::kINT8 ? DataType::kFLOAT : dataType);
for (auto& s : mParams.outputTensorNames)
{
network->markOutput(*blobNameToTensor->find(s.c_str()));
}
// Calibrator life time needs to last until after the engine is built.
std::unique_ptr<IInt8Calibrator> calibrator;
config->setAvgTimingIterations(1);
config->setMinTimingIterations(1);
config->setMaxWorkspaceSize(1_GiB);
if (dataType == DataType::kHALF)
{
config->setFlag(BuilderFlag::kFP16);
}
if (dataType == DataType::kINT8)
{
config->setFlag(BuilderFlag::kINT8);
}
builder->setMaxBatchSize(mParams.batchSize);
if (dataType == DataType::kINT8)
{
MNISTBatchStream calibrationStream(mParams.calBatchSize, mParams.nbCalBatches, "train-images-idx3-ubyte",
"train-labels-idx1-ubyte", mParams.dataDirs);
calibrator.reset(new Int8EntropyCalibrator2<MNISTBatchStream>(
calibrationStream, 0, mParams.networkName.c_str(), mParams.inputTensorNames[0].c_str()));
config->setInt8Calibrator(calibrator.get());
}
if (mParams.dlaCore >= 0)
{
samplesCommon::enableDLA(builder.get(), config.get(), mParams.dlaCore);
if (mParams.batchSize > builder->getMaxDLABatchSize())
{
sample::gLogError << "Requested batch size " << mParams.batchSize
<< " is greater than the max DLA batch size of " << builder->getMaxDLABatchSize()
<< ". Reducing batch size accordingly." << std::endl;
return false;
}
}
// CUDA stream used for profiling by the builder.
auto profileStream = samplesCommon::makeCudaStream();
if (!profileStream)
{
return false;
}
config->setProfileStream(*profileStream);
SampleUniquePtr<IHostMemory> plan{builder->buildSerializedNetwork(*network, *config)};
if (!plan)
{
return false;
}
SampleUniquePtr<IRuntime> runtime{createInferRuntime(sample::gLogger.getTRTLogger())};
if (!runtime)
{
return false;
}
mEngine = std::shared_ptr<nvinfer1::ICudaEngine>(
runtime->deserializeCudaEngine(plan->data(), plan->size()), samplesCommon::InferDeleter());
if (!mEngine)
{
return false;
}
return true;
}
//!
//! \brief Runs the TensorRT inference engine for this sample
//!
//! \details This function is the main execution function of the sample. It allocates the buffer,
//! sets inputs and executes the engine.
//!
bool SampleINT8::infer(std::vector<float>& score, int firstScoreBatch, int nbScoreBatches)
{
float ms{0.0f};
// Create RAII buffer manager object
samplesCommon::BufferManager buffers(mEngine, mParams.batchSize);
auto context = SampleUniquePtr<nvinfer1::IExecutionContext>(mEngine->createExecutionContext());
if (!context)
{
return false;
}
MNISTBatchStream batchStream(mParams.batchSize, nbScoreBatches + firstScoreBatch, "train-images-idx3-ubyte",
"train-labels-idx1-ubyte", mParams.dataDirs);
batchStream.skip(firstScoreBatch);
Dims outputDims = context->getEngine().getBindingDimensions(
context->getEngine().getBindingIndex(mParams.outputTensorNames[0].c_str()));
int64_t outputSize = samplesCommon::volume(outputDims);
int top1{0}, top5{0};
float totalTime{0.0f};
while (batchStream.next())
{
// Read the input data into the managed buffers
ASSERT(mParams.inputTensorNames.size() == 1);
if (!processInput(buffers, batchStream.getBatch()))
{
return false;
}
// Memcpy from host input buffers to device input buffers
buffers.copyInputToDevice();
cudaStream_t stream;
CHECK(cudaStreamCreate(&stream));
// Use CUDA events to measure inference time
cudaEvent_t start, end;
CHECK(cudaEventCreateWithFlags(&start, cudaEventBlockingSync));
CHECK(cudaEventCreateWithFlags(&end, cudaEventBlockingSync));
cudaEventRecord(start, stream);
bool status = context->enqueue(mParams.batchSize, buffers.getDeviceBindings().data(), stream, nullptr);
if (!status)
{
return false;
}
cudaEventRecord(end, stream);
cudaEventSynchronize(end);
cudaEventElapsedTime(&ms, start, end);
cudaEventDestroy(start);
cudaEventDestroy(end);
totalTime += ms;
// Memcpy from device output buffers to host output buffers
buffers.copyOutputToHost();
CHECK(cudaStreamDestroy(stream));
top1 += calculateScore(buffers, batchStream.getLabels(), mParams.batchSize, outputSize, 1);
top5 += calculateScore(buffers, batchStream.getLabels(), mParams.batchSize, outputSize, 5);
if (batchStream.getBatchesRead() % 100 == 0)
{
sample::gLogInfo << "Processing next set of max 100 batches" << std::endl;
}
}
int imagesRead = (batchStream.getBatchesRead() - firstScoreBatch) * mParams.batchSize;
score[0] = float(top1) / float(imagesRead);
score[1] = float(top5) / float(imagesRead);
sample::gLogInfo << "Top1: " << score[0] << ", Top5: " << score[1] << std::endl;
sample::gLogInfo << "Processing " << imagesRead << " images averaged " << totalTime / imagesRead << " ms/image and "
<< totalTime / batchStream.getBatchesRead() << " ms/batch." << std::endl;
return true;
}
//!
//! \brief Cleans up any state created in the sample class
//!
bool SampleINT8::teardown()
{
//! Clean up the libprotobuf files as the parsing is complete
//! \note It is not safe to use any other part of the protocol buffers library after
//! ShutdownProtobufLibrary() has been called.
nvcaffeparser1::shutdownProtobufLibrary();
return true;
}
//!
//! \brief Reads the input and stores it in a managed buffer
//!
bool SampleINT8::processInput(const samplesCommon::BufferManager& buffers, const float* data)
{
// Fill data buffer
float* hostDataBuffer = static_cast<float*>(buffers.getHostBuffer(mParams.inputTensorNames[0]));
std::memcpy(hostDataBuffer, data, mParams.batchSize * samplesCommon::volume(mInputDims) * sizeof(float));
return true;
}
//!
//! \brief Scores model
//!
int SampleINT8::calculateScore(
const samplesCommon::BufferManager& buffers, float* labels, int batchSize, int outputSize, int threshold)
{
float* probs = static_cast<float*>(buffers.getHostBuffer(mParams.outputTensorNames[0]));
int success = 0;
for (int i = 0; i < batchSize; i++)
{
float *prob = probs + outputSize * i, correct = prob[(int) labels[i]];
int better = 0;
for (int j = 0; j < outputSize; j++)
{
if (prob[j] >= correct)
{
better++;
}
}
if (better <= threshold)
{
success++;
}
}
return success;
}
//!
//! \brief Initializes members of the params struct using the command line args
//!
SampleINT8Params initializeSampleParams(const samplesCommon::Args& args, int batchSize)
{
SampleINT8Params params;
// Use directories provided by the user, in addition to default directories.
params.dataDirs = args.dataDirs;
params.dataDirs.emplace_back("data/mnist/");
params.dataDirs.emplace_back("int8/mnist/");
params.dataDirs.emplace_back("samples/mnist/");
params.dataDirs.emplace_back("data/samples/mnist/");
params.dataDirs.emplace_back("data/int8/mnist/");
params.dataDirs.emplace_back("data/int8_samples/mnist/");
params.batchSize = batchSize;
params.dlaCore = args.useDLACore;
params.nbCalBatches = 10;
params.calBatchSize = 50;
params.inputTensorNames.push_back("data");
params.outputTensorNames.push_back("prob");
params.prototxtFileName = "deploy.prototxt";
params.weightsFileName = "mnist_lenet.caffemodel";
params.networkName = "mnist";
return params;
}
//!
//! \brief Prints the help information for running this sample
//!
void printHelpInfo()
{
std::cout << "Usage: ./sample_int8 [-h or --help] [-d or --datadir=<path to data directory>] "
"[--useDLACore=<int>]"
<< std::endl;
std::cout << "--help, -h Display help information" << std::endl;
std::cout << "--datadir Specify path to a data directory, overriding the default. This option can be used "
"multiple times to add multiple directories."
<< std::endl;
std::cout << "--useDLACore=N Specify a DLA engine for layers that support DLA. Value can range from 0 to n-1, "
"where n is the number of DLA engines on the platform."
<< std::endl;
std::cout << "batch=N Set batch size (default = 32)." << std::endl;
std::cout << "start=N Set the first batch to be scored (default = 16). All batches before this batch will "
"be used for calibration."
<< std::endl;
std::cout << "score=N Set the number of batches to be scored (default = 1800)." << std::endl;
}
int main(int argc, char** argv)
{
if (argc >= 2 && (!strncmp(argv[1], "--help", 6) || !strncmp(argv[1], "-h", 2)))
{
printHelpInfo();
return EXIT_SUCCESS;
}
// By default we score over 57600 images starting at 512, so we don't score those used to search calibration
int batchSize = 32;
int firstScoreBatch = 16;
int nbScoreBatches = 1800;
// Parse extra arguments
for (int i = 1; i < argc; ++i)
{
if (!strncmp(argv[i], "batch=", 6))
{
batchSize = atoi(argv[i] + 6);
}
else if (!strncmp(argv[i], "start=", 6))
{
firstScoreBatch = atoi(argv[i] + 6);
}
else if (!strncmp(argv[i], "score=", 6))
{
nbScoreBatches = atoi(argv[i] + 6);
}
}
if (batchSize > 128)
{
sample::gLogError << "Please provide batch size <= 128" << std::endl;
return EXIT_FAILURE;
}
if ((firstScoreBatch + nbScoreBatches) * batchSize > 60000)
{
sample::gLogError << "Only 60000 images available" << std::endl;
return EXIT_FAILURE;
}
samplesCommon::Args args;
samplesCommon::parseArgs(args, argc, argv);
SampleINT8 sample(initializeSampleParams(args, batchSize));
auto sampleTest = sample::gLogger.defineTest(gSampleName, argc, argv);
sample::gLogger.reportTestStart(sampleTest);
sample::gLogInfo << "Building and running a GPU inference engine for INT8 sample" << std::endl;
std::vector<std::string> dataTypeNames = {"FP32", "FP16", "INT8"};
std::vector<std::string> topNames = {"Top1", "Top5"};
std::vector<DataType> dataTypes = {DataType::kFLOAT, DataType::kHALF, DataType::kINT8};
std::vector<std::vector<float>> scores(3, std::vector<float>(2, 0.0f));
for (size_t i = 0; i < dataTypes.size(); i++)
{
sample::gLogInfo << dataTypeNames[i] << " run:" << nbScoreBatches << " batches of size " << batchSize
<< " starting at " << firstScoreBatch << std::endl;
if (!sample.build(dataTypes[i]))
{
if (!samplesCommon::isDataTypeSupported(dataTypes[i]))
{
sample::gLogWarning << "Skipping " << dataTypeNames[i]
<< " since the platform does not support this data type." << std::endl;
continue;
}
return sample::gLogger.reportFail(sampleTest);
}
if (!sample.infer(scores[i], firstScoreBatch, nbScoreBatches))
{
return sample::gLogger.reportFail(sampleTest);
}
}
auto isApproximatelyEqual = [](float a, float b, double tolerance) { return (std::abs(a - b) <= tolerance); };
const double tolerance{0.01};
const double goldenMNIST{0.99};
if ((scores[0][0] < goldenMNIST) || (scores[0][1] < goldenMNIST))
{
sample::gLogError << "FP32 accuracy is less than 99%: Top1 = " << scores[0][0] << ", Top5 = " << scores[0][1]
<< "." << std::endl;
return sample::gLogger.reportFail(sampleTest);
}
for (unsigned i = 0; i < topNames.size(); i++)
{
for (unsigned j = 1; j < dataTypes.size(); j++)
{
if (scores[j][i] != 0.0f && !isApproximatelyEqual(scores[0][i], scores[j][i], tolerance))
{
sample::gLogError << "FP32(" << scores[0][i] << ") and " << dataTypeNames[j] << "(" << scores[j][i]
<< ") " << topNames[i] << " accuracy differ by more than " << tolerance << "."
<< std::endl;
return sample::gLogger.reportFail(sampleTest);
}
}
}
if (!sample.teardown())
{
return sample::gLogger.reportFail(sampleTest);
}
return sample::gLogger.reportPass(sampleTest);
}参考资料
(17条消息) 模型量化详解_WZZ18191171661的博客-CSDN博客_模型量化原理
Nvidia TensorRT文档——开发者指南 – 简书 (jianshu.com)
https://on-demand.gputechconf.com/gtc/2017/presentation/s7310-8-bit-inference-with-tensorrt.pdf
如何通俗的解释交叉熵与相对熵? – 知乎 (zhihu.com)
GPU之nvidia-smi命令详解 – 简书 (jianshu.com)
[1]高晗, 田育龙, 许封元,等. 深度学习模型压缩与加速综述[J]. 软件学报, 2021, 32(1):25.
[2] Nagel M , Fournarakis M , Amjad R A , et al. A White Paper on Neural Network Quantization. 2021.
文章出处登录后可见!