如果您对 2018 年以来机器学习和人工智能领域取得的进步略有了解,您几乎肯定已经意识到自然语言处理 领域取得的巨大进步(也称为自然语言处理)。这一领域的大部分进展可归功于大型语言模型 ,也称为 LLM。这些 LLM 背后的架构是转换器的编码器-解码器,我们在第2章中讨论过。
Transformer 的成功来自架构并行处理输入数据的能力,以及通过注意力机制更好地理解上下文。我们已经在前面的章节中提到了 Vaswani 的“Attention Is All You Need”论文。在 transformer 出现之前,context 是由 vanilla RNN 或 LSTM 在没有注意的情况下捕获的。
Hugging Face 现在被广泛认为是与自然语言处理 (NLP) 相关的所有事物的一站式商店,不仅提供数据集和预训练模型,还提供社区甚至课程。
Hugging Face 是一家建立在使用开源软件和数据 原则基础上的新公司。真正意义上,NLP 的革命始于基于 transformer 架构的 NLP 模型的民主化。Hugging Face 不仅是开源这些模型的先驱,而且还以Transformers 库 的形式提供了方便易用的抽象,这使得使用和推断这些模型变得非常容易。
Hugging Face 为模型开发人员提供了一个中心位置或枢纽,用于在 huggingface存储库 中发布模型,这些模型可供希望在这些模型之上构建应用程序的消费者使用。例如,BERT(来自变压器的双向编码器表示) 模型由 Google 贡献给 huggingface。然后,这允许用户社区在他们的应用程序中使用这些模型。然后是来自 OpenAI 的 GPT 模型,如 GPT2,它们是生成模型,允许最终用户编写可以生成故事、小说等的应用程序。GPT2 也是 huggingface 生态系统的一部分。Hugging Face 不仅提供了用于使用这些模型的 API,还提供了一种使用我们自己的数据集对它们进行微调以及监控和基准测试这些模型的方法。因此,简而言之,像 huggingface 这样的生态系统 的出现确实为打算在基于自然语言处理的模型之上构建应用程序的开发人员提供了大量机会。
目前这些模型的范围不仅限于文本处理 。我们现在看到了视觉转换器和基于转换器的音频模型 的出现。人们正在为音频领域的音乐生成或语音克隆构建应用程序,并在视觉用例的情况下将它们用于伪造图像生成。还有一些模型挖掘了科学文献,可用于从科学期刊中提取知识。同样,基于法律相关文件的模型已经出现,人们可以利用它们在其之上构建问答系统。根据所使用的底层架构,这些模型有多种尺寸。例如,GPT3 模型 有大约 1750 亿个参数。
同样,他们训练数据集的大小和范围都显着增加。例如,原来的变压器被更大的Transformer-XL 取代;BERT-Base 中的参数数量从 1.1 亿增加到 Bert-Large 中的 3.4 亿;15亿参数的GPT2模型被1750亿参数的GPT3模型取代。中国推出了名为“悟道2.0”的模型,该模型拥有约1.75万亿个参数。缩放的支持者认为,随着我们增加这些模型的大小,我们也将实现通用人工智能 (AGI) 的目标。
为了举例说明这种大型模型所需的基础设施,GPT3 在一台拥有超过 10000 个 GPU 的超级计算机上进行了训练。这意味着训练这些模型只属于大公司的领域。现在,由于能够使用这些模型中的大部分,最终用户成为基于这些大型语言模型的应用程序开发生态系统的一部分。
Hugging Face平台的特点
由于 Hugging Face平台 基于基于注意力的 transformer 模型的理念,因此Transformers 库 处于 Hugging Face 生态系统的中心也就不足为奇了。随附的 Datasets 和Tokenizers 库 为 Transformers 库提供帮助。请记住,转换器无法理解其原始形式的文本,即一串字符。由于我们对转换器的输入是文本,因此该文本必须以一种使其可通过基于转换器的神经网络架构 使用的方式进行编码。为此,我们使用 huggingface 提供的 API 进行分词,这被称为分词器。
除了标记化之外,我们可能需要使用一些自定义数据集来微调现有模型或从头开始训练模型。为了在架构上保持统一,huggingface 通过数据集 API 为数据集提供了一个抽象。然后,用户可以拥有自己的数据集、上传数据集、训练/微调模型,还可以使用 huggingface API 上传训练好的模型。这完全是革命性 的。
Hugging Face的组成部分
huggingface 库基于一组丰富的抽象,抽象出基于自然语言处理创建应用程序的复杂性。这些抽象允许我们使用一个单一的接口来加载模型、使用分词器、跨各种模型、分词器和数据集使用数据集。对于通过使用这些抽象简化工作的开发人员来说,这确实是一种赋能体验。我们将在以下小节中讨论其中的一些抽象。
流水线
管道 为使用拥抱面模型存储库中的预训练模型提供了强大而方便的抽象。它提供了一个简单的应用程序编程接口 (API) ,专用于各种任务:
1.确定句子的整体情绪是否可以表征为正面或负面。
2.问答 接受一个问题并从与之对应的文本中提取答案。
3.掩码语言建模技术建议可能的词来用给定的上下文填充掩码输入。
4.命名实体识别程序将自动为输入中包含的每个标记分配一个标签。
5.将较长的文章或文章缩减为更简洁的摘要称为摘要。
管道是建立在三个拥抱面组件之上的抽象 ,即
1.分词器
2.模型
3.后处理器
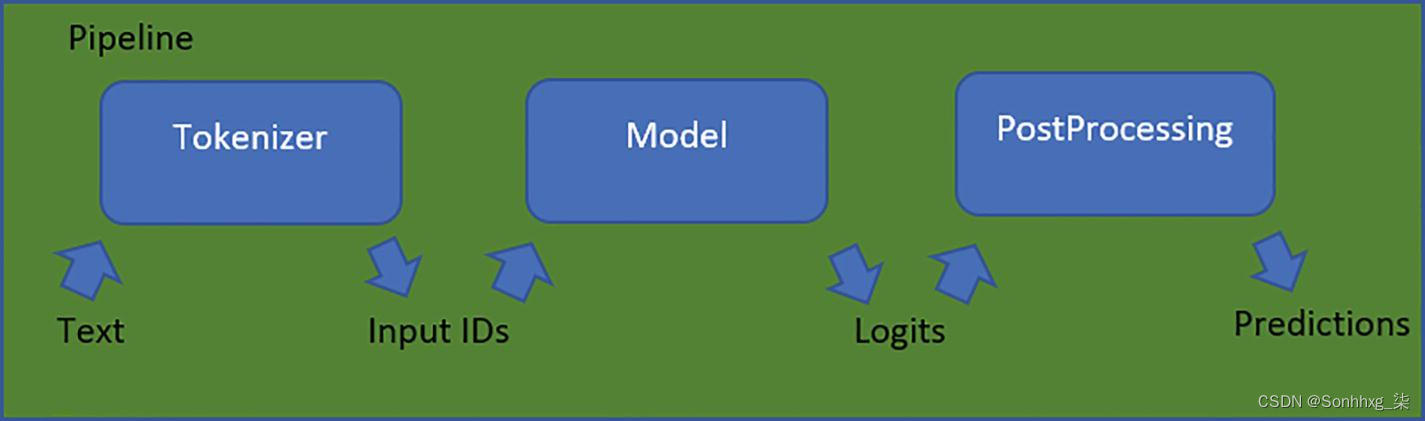
图 4-1 huggingface流水线 的工作流程
分词器
管道 中的第一个组件是标记 器,它将原始文本作为输入并将其转换为数字,以便模型可以解释它们。
分词器负责
1.将输入分离为单个标记的过程,这些标记可能是词、子词或符号(例如标点符号)
2.将每个标记转换为整数
3.将可能被证明有用的新变量引入模型
训练模型时,我们需要对输入进行标记化。那时会使用某种分词器。我们需要确保在实际输入上使用此模型期间,我们使用相同的分词器。AutoTokenizer 类 使这项任务变得简单,它将自动加载训练期间使用的分词器。这大大简化了开发人员的工作。
我们在以下代码中加载用于预训练 GPT2 模型 的分词器。
首先,在 Google Colab 中安装 Transformers 库:
!pip install transformers图4-2展示了huggingface的Transformers 库 的安装过程。
图 4-2 在 Google Colab 中安装Transformers 库
接下来,添加此代码。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2")
encoding = tokenizer("This is my first stab at AutoTokenizer")
print(encoding)清单 4-1 简单分词 器的代码
在Google Colab 中执行清单4-1会产生如图4-3所示的输出。
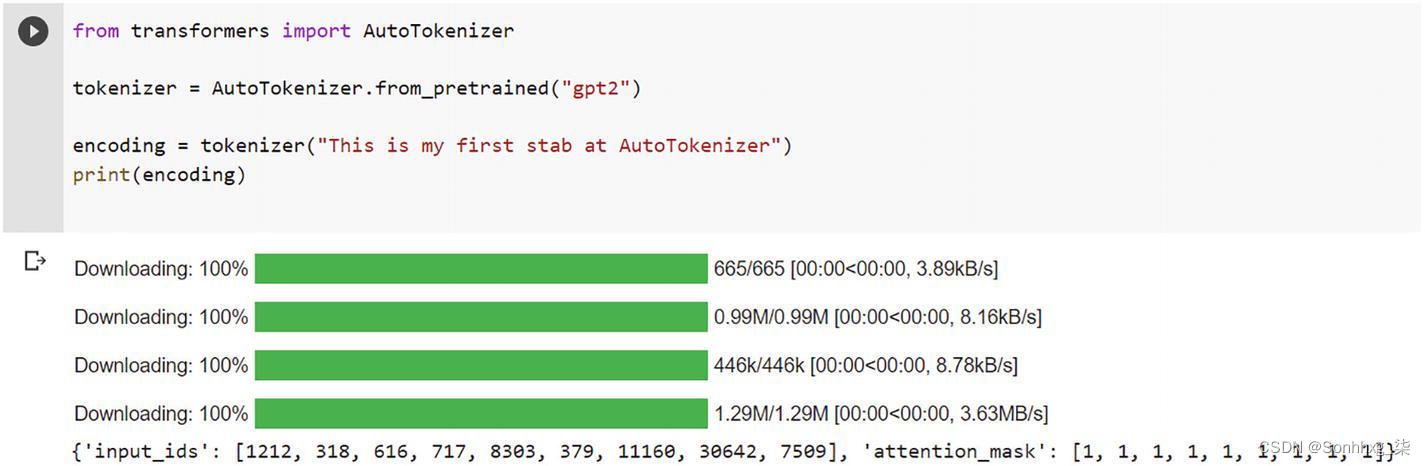
图 4-3下载分词器
分词器将提供一个包含以下条目的字典 :
您的令牌的数字表示称为输入 ID。
注意力掩码是一个掩码,指定哪些标记需要引起注意。
我们还可以将多个字符串作为输入传递给分词器。示例4-2中显示了一个示例,它将文本标记为两个句子。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2")
encoding = tokenizer("This is my first stab at AutoTokenizer","life is what happens when you are planning other things")
print(encoding)清单 4-2 使用分词器对文本进行分词的代码
这将为单个句子提供标记,如图4-4所示。

图 4-4 标记化句子
除了 GPT2,我们还可以使用其他模型,例如 BERT。清单4-3中给出了一个基于 BERT 的分词 器示例。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
encoding = tokenizer("This is my first stab at AutoTokenizer")
print(encoding)清单 4-3 使用 BERT 对文本进行分词
图4-5显示了基于 BERT 的分词器 的输出。这是通过在 Google Colab 中运行清单4-3来实现的。

图 4-5 执行基于 BERT 的分词器
输出编码是
{'input_ids': [101, 1188, 1110, 1139, 1148, 19428, 1120, 12983, 1942, 27443, 17260, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
这将返回一个包含以下三个重要项目的字典 :
1.对应于句子中每个标记的索引由输入 ids 变量表示。
2.注意掩码的值指定是否需要注意令牌。
3.当存在多个序列时,令牌类型 ids 变量用于确定令牌属于哪个序列。
我们可以通过解码 input_ids 取回输入,如下所示:
tokenizer.decode(encoding["input_ids"])其输出如图4-6所示。

图 4-6 通过将标记作为输入并返回文本作为输出来显示解码过程
可以看出,标记器在句子中插入了两个专门的标记 。这些标记称为CLS 和 SEP ,分别代表分类器和分隔符。标记器将负责为您添加任何必要的特殊标记,前提是所讨论的模型确实需要它们。
让我们将多个句子传递给这个分词器,如清单4-4所示。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
encoding = tokenizer("This is my first stab at AutoTokenizer","life is what happens when you are planning other things")
print(encoding)清单 4-4 此代码将两个句子作为输入并为它们生成标记
这导致多种编码 :
{'input_ids': [101, 1188, 1110, 1139, 1148, 19428, 1120, 12983, 1942, 27443, 17260, 102, 1297, 1110, 1184, 5940, 1165, 1128, 1168, 1163, 1632, 1128, 1168, 1632, 1165, 1128, 1168, 6 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
填充
当我们处理 一组句子时,它们各自的长度并不总是保持一致。模型的输入需要具有相同的大小,因为这是基于底层标准架构的。这就提出了一个问题。向包含的标记数量不足的句子添加填充标记是称为“填充 ”的策略的一个示例。
现在我们使用多个输入运行以下示例,并将 padding 设置为 true,如清单4-5所示。
from transformers import AutoTokenizer
bert_tk = AutoTokenizer.from_pretrained("bert-base-cased")
sentences=["This is my first stab at AutoTokenizer","life is what happens when you are planning other things","how are you"]
encoding = bert_tk(sentences,padding=True)
print(encoding)清单 4-5 此代码显示标记器的填充如何工作
这给出如下输出 :
{'input_ids': [[101, 1188, 1110, 1139, 1148, 19428, 1120, 12983, 1942, 27443, 17260, 102], [101, 1297, 1110, 1184, 5940, 1165, 1123, 3, 3 , 1168, 1614, 102], [101, 1293, 1132, 1128, 102, 0, 0, 0, 0, 0, 0, 0]], 'token_type_ids': [[0, 0, 0, 0, 0 , 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0] , 0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0 ]]}
正如我们所见,第三个句子 的长度较短,因此分词器用零填充了它。
截断
有时模型可能 无法处理太长的序列。在这种特殊情况下,您将需要将序列压缩到更易于管理的长度。
如果要截断序列以使其达到模型可接受的最大长度,请将截断参数设置为 true,如清单4-6所示。
from transformers import AutoTokenizer
bert_base_tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
sentences=["This is my first stab at AutoTokenizer","life is what happens when you are planning other things. so plan life accordingly","how are you"]
encoding = bert_base_tokenizer(sentences,padding=True,truncation=True)
print(encoding)清单 4-6 此代码显示截断标志 如何在分词器中工作
输出 如下所示:
{'input_ids': [[101, 1188, 1110, 1139, 1148, 19428, 1120, 12983, 1942, 27443, 17260, 102, 0, 0, 0, 0, 0], [101, 1297, 1110, 1184 , 5940, 1165, 1128, 1132, 3693, 1168, 1614, 119, 1177, 2197, 1297, 17472, 102], [101, 1293, 1132, 1128, 102, 0, 0, 0, 0, 0, 0 , 0, 0, 0, 0, 0, 0]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 , 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0 , 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1 , 1, 1, 1, 1, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 , 1, 1], [1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]}
管道的下一个阶段是模型。
AutoModel
我们将检查 AutoModel 如何在 加载预训练模型方面让我们的生活更简单。
加载预训练实例的过程通过Transformers 库 变得简单和统一。这表明您能够以与加载 AutoTokenizer 相同的方式加载AutoModel 。唯一的区别在于为手头的任务选择合适的自动模型。
如果我们以文本分类 为例,我们加载模型的方式如下所示。
我们将遵循以下步骤:
1.根据检查点的名称创建分词器实例和模型。确定模型为BERT模型,然后将checkpoint保存的权重加载进去。
2.获取令牌并将其传递给模型。
3.该模型返回对数。
4.用 softmax 来计算句子被分类的类别的概率(对于我们的以下示例为负或正)。
清单 4-7 分为多个部分,其中清单4-7-1解释了如何通过Transformers 库 加载分词器。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("siebert/sentiment-roberta-large-english")
sentences=["This is my first stab at AutoTokenizer","life is what happens when you are planning other things. so plan life accordingly","this is not tasty at all"]
encoding = tokenizer(sentences,padding=True,truncation=True,return_tensors="pt")
print(encoding)清单 4-7-1 加载分词器
这给出了以下输出:
{'input_ids': 张量([[ 0, 713, 16, 127, 78, 16735, 23, 8229, 45643, 6315,
2, 1, 1, 1, 1, 1, 1],
[ 0, 5367, 16, 99, 2594, 77, 47, 32, 1884, 97,
383, 4, 98, 563, 301, 14649, 2],
[ 0, 9226, 16, 45, 22307, 23, 1250, 2, 1, 1,
1, 1, 1, 1, 1, 1, 1]]), 'attention_mask': 张量([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0 , 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]])}
清单4-7-2显示了如何通过Transformers 库 加载模型。
# 用于加载模型
from transformers import AutoModelForSequenceClassification
model_name = "siebert/sentiment-roberta-large-english"
pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)清单 4-7-2 加载模型
#打印编码
pt_outputs = pt_model(**encoding)
print (pt_outputs)SequenceClassifierOutput(loss=None, logits=tensor([[ 3.0351, -2.1955], [-3.6225, 2.7819], [ 3.9581, -3.6334]], grad_fn=<AddmmBackward0>), hidden_states=None, attentions=None)
清单 4-7-3 生成对数
#用于打印logits
logits=pt_outputs.logits
print (logits)这输出
tensor([[ 3.0351,-2.1955],
[-3.6225, 2.7819],
[ 3.9581, -3.6334]], grad_fn=<AddmmBackward0>)
最后,我们使用 softmax 来打印输出概率 ,如清单4-7-4所示。
output = torch.softmax(logits, dim=1).tolist()[1]
print(output)清单 4-7-4
打印特定于个人情绪类别的概率
我们得到以下输出:
[[0.9946781396865845, 0.005321894306689501], [0.001651538535952568, 0.9983484745025635], [0.9994955062866211, 0.0005045001162]216067
我们可以看到所有三个句子的输出概率:
这是我第一次尝试 AutoTokenizer
第一列给出情绪为负面的概率 ,第二列给出情绪为正面的概率:
分数 [ 0.9946781396865845 , 0.005321894306689501]
这反映了句子中的负面情绪。
接下来是针对第二句:
生活就是当你在计划其他事情时发生的事情。所以相应地计划生活
[0.001651538535952568, 0.9983484745025635 ]
这反映了句子中的积极情绪。
现在我们研究一个称为pipeline 的包装类 ,它可以用更少的代码实现相同的任务,如清单4-8所示。
from transformers import pipeline
# 创建带有分词器和模型的管道实例
roberta_pipe = pipeline(
"sentiment-analysis",
model="siebert/sentiment-roberta-large-english",
tokenizer="siebert/sentiment-roberta-large-english",
return_all_scores = True
)
# 分析我们在前面的例子中使用的 3 个句子的情绪
roberta_pipe(sentences)清单 4-8 此代码显示如何使用管道 API 进行情绪分析
我们得到以下输出:
[[{'label': 'NEGATIVE', 'score': 0.9946781396865845}, {'label': 'POSITIVE', 'score': 0.005321894306689501}],
[{'label': 'NEGATIVE', 'score': 0.001651539234444499}, {'label': 'POSITIVE', 'score': 0.9983484745025635}],
[{'label': 'NEGATIVE', 'score': 0.9994955062866211}, {'label': 'POSITIVE', 'score': 0.0005045001744292676}]]
当我们在代码中没有使用和使用管道类 时,我们可以检查输出是否匹配。
概括
在本章中,我们讨论了 huggingface 库的架构及其组件,如分词器和模型。我们还学习了如何使用这些组件来完成一项简单的任务,例如分析句子的情感。在下一章中,我们将举出更多使用Transformers 库 执行不同类型任务的示例。
文章出处登录后可见!