知识图谱
知识图谱Knowledge Graph/Vault,又称科学知识图谱,用各种不同的图形等可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识及它们之间的相互联系。采用图结构来描述知识,建模事物及事物间关系。提供了一种组织、管理和认知理解海量信息的能力。
一、图谱的本质
其本质是一种大规模语义网络,既包含了丰富的语义信息,又天然具有图的各种特征,其中,事物或实体属性值表示为“节点”,事物之间的关系或属性表示为“边”。节点可以是实体,如一个人、一部电影等,或是抽象的概念,如人工智能、知识图谱等。边可以是实体的属性,如姓名、电影名,或是实体之间的关系,如朋友、配偶。
知识图谱定义为G={E ,R ,F } 其中,E,R 和 F 分别表示实体、关系、事实的集合。
事实被定义为一个三元组 ( h,r,t )∈F ,其中,h 和 t 分别代表头实体和尾实体,r 代表头尾实体间的关系.
下图是名著《水浒传》的一个知识图谱片段。节点表示实体,边表示关系。
三元组(宋江, 结拜, 武松)表达了宋江与武松是结拜兄弟的事实。
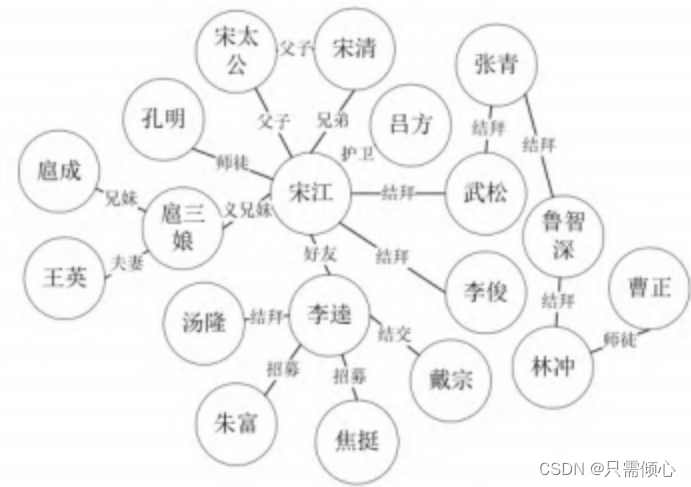 图1 知识图谱片段
图1 知识图谱片段
二、图谱的构建
知识图谱的构建技术分自顶向下和自底向上两种。
自顶向下构建:借助百科类网站等结构化数据源,从高质量数据中提取本体和模式信息,加入到知识库里。
自底向上构建:借助一定的技术手段,从公开采集的数据中提取出资源模式,选择其中置信度较高的信息,加入到知识库中。
2.1图谱的原始数据类型
原始数据类型一般来说分三类:
结构化数据(Structed Data),如:关系数据库、链接数据
半结构化数据(Semi-Structured Data),如:XML、JSON、百科
非结构化数据(Unstructured Data),如:图片、音频、视频
2.2图谱的主要研究内容
知识图谱的主要研究内容包括知识抽取、知识推理 、知识表示、知识融合 4 部分。目前被广泛应用于多个行业领域。
2.2.1知识抽取
知识抽取是从不同来源、结构的数据中提取知识,形成结构化数据存入知识图谱。对于结构化和半结构化的数据,可以直接利用映射、转换等操作。但对于非结构化数据而言,知识抽取较为困难。一般知识抽取任务包括命名实体识别、关系抽取(实体属性抽取、实体关系抽取)等。早期是基于规则、词典和人工标注等方法进行命名实体识别,随着人工智能的发展,如隐马尔可夫算法、条件随机场、卷积神经网络等这一类的机器学习、深度学习算法成为主流方法。关系抽取主要有递归神经网络、长短期记忆模型、远程监督等方法。
2.2.2知识推理
知识推理是从已有的知识中推理实体间可能存 在的关系或属性值.知识图谱通常是不完整
的。例如,实体间路径缺失、实体属性值缺失 等。因此,知识推理常用于知识图谱补全(knowledge graph completion),也可用于知识图 谱去噪(knowledge graph cleaning)等任务。
2.2.3知识表示
知识表示是对现实世界的一种抽象表达。知识表示方式主要分为符号表示和数值表示,符
号表示 , 如 , 网 络 本 体 语 言 (ontology wed language, OWL) 、 RDF(resource description framework)等,符号表示方便易于理解,但基本符号性质使 KG 难以操作。因此,提出了知识 图谱嵌入(knowledge graph embedding, KGE)或知识表示学(knowledge representation learning, KRL)方法,将知识图谱的实体和关系嵌入到连续向量空间中,从而实现对其语义信息和固有结构的表示。
2.2.4知识融合
知识融合是将从不同来源得到的同一实体或概念的描述信息融合起来。描述信息可以是同
种类型,也可以是不同类型。例如,图片、文字、音频、视频等。
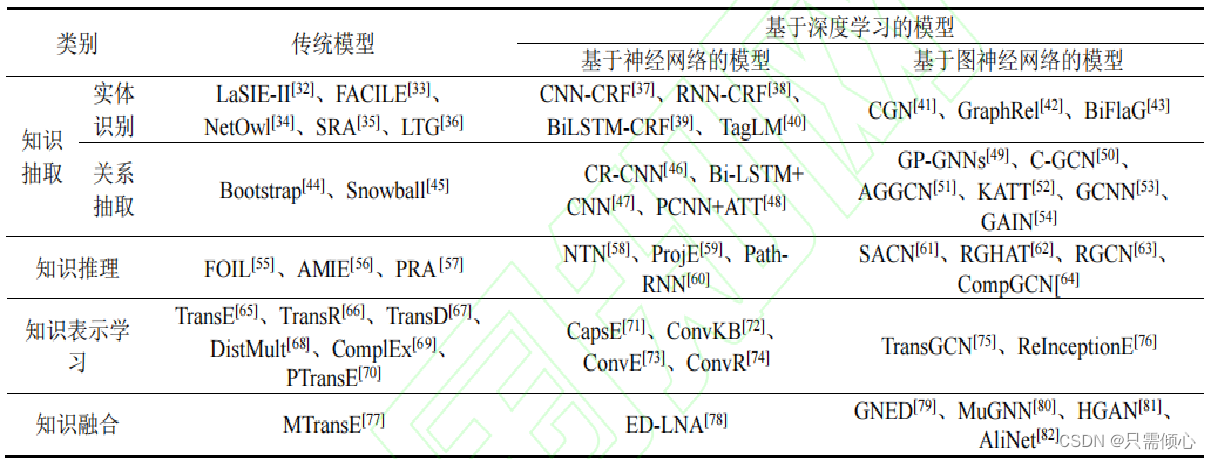
图2 图谱相关研究算法
三、图谱的存储与可视化
知识图谱主要有两种储存方式:
1.可以通过 RDF(资源描述框架)的规范存储格式来进行存储,比较常用的有 Jena等。
<RDF>
<Description about="https://www.123.org/RDF/">
<author>Mia</author>
<homepage> http://www.date.tech </homepage>
</Description>
</RDF>
2.使用图数据库来进行存储,目前主流的图形数据库有OrientDB, JanusGraph, Neo4j, Trinity等。其中Neo4j发展最迅猛,行业认可度最高。Neo4j是一款稳健的、可伸缩的高性能图数据库,它支持完整的ACID特性,即原子性(Atomicity)、一致性(Consistency),隔离性(Isolation)、持久性(Durability),最适合完整的企业级项目部署。
四、Neo4j的介绍与使用
Neo4j可以分为四层:查询层、编译层、执行层和数据层。
查询层 :Neo4j自身提供查询语言Cypher,但需专业人员操作。支持各种主流的编程语言对其操作,如Java python等。用户可以编写API接口来实现输入自然语言查询,也可以调用复杂查询接口进行查询。
编译层 :将查询层接收到的自然语言转化为机器语言并传递给下一层执行,利用优化器可以对查询语句进行优化,提高查询效率。
执行层 :执行层中的事务管理是对数据的增删查改操作进行管理,Neo中的数据是以节点和边构成的图谱网络,对数据的管理就变成了对节点或边的操作,如增加一条数据只需在图谱中添加一个节点(Node)和一条边((Edge),具有高度可扩展性和高可用性。另外,Neo4j的Import数据导入方式能够以每秒数十万节点的高速率数据批量导入,
4.1 Neo4j的安装详见参考资料2
4.2 Neo4j的批量导入
批量导入工具 neo4j-import,位于neo4j的bin目录下。
常用参数
–into:数据库名称
–bad-tolerance:能容忍的错误数据条数(即超过指定条数程序直接挂掉),默认1000
–multiline-fields:是否允许多行插入(即有些换行的数据也可读取)
–nodes:插入节点
–relationships:插入关系
更多参数可在cmd输入 neo4j-import 查看
数据准备:在excel中生成三个csv数据文件,并存放到neo4j安装目录的import文件夹下
启动 neo4j,浏览器打开http://localhost:7474/,在图中此处输入Cypher命令
# 1.导入电影表
LOAD CSV FROM 'file:///movies.csv' AS line CREATE (:Movie { movieId: line[0], title: line[1], year: toInteger(line[2]), tag:line[3] });
# 2.导入演员表
LOAD CSV FROM 'file:///actors.csv' AS line CREATE (:Actor { personId: line[0], name: line[1], type:line[2] });
# 3.导入关联表
LOAD CSV FROM 'file:///roles.csv' AS line
MATCH (from:Movie{movieId:line[2]}),(to:Actor{personId:line[0]})
MERGE (from)-[r:ACTED_IN{role:line[1]}]-> (to);

注:neo4j-import是为初次导入数据准备的,数据库目录必须是不存在的。
这里体现了neo4j-import工具的一个缺点,所有数据只能导入一次,如果之后想补充数据,只能删除库再导入。
参考资料
1.nlp-知识图谱简介
2.知识图谱构建-Neo4j的安装与环境配置
3.Neo4j:入门基础(二)之导入CSV文件
4. neo4j 使用 load csv 命令导入csv数据,并生成节点、关系
文章出处登录后可见!