前言
ChatGPT已经发布一周了热度依旧不减,ChatGPT也各种大显神通,为各大网友“出谋划策”,有写周报的,有写绩效的甚至还有写论文的,作为一个NLP从业者,除了好好体验下其中的乐趣,其背后的原理当然也要有所了解,本文就从其技术细节为大家一一揭开奥秘。
ChatGPT的前世
ChatGPT出来之前,相信大家体验过很多智能问答机器人,大部分的评价都是“人工智障”,而ChatGPT则给人一种忽如一夜春风来,千树万树梨花开的感觉,怎么AI突然变得如此智能!实际上,ChatGPT的成功源自于2年前的GPT3+后期的RLHF优化,所以说

接下来我们就先简单回顾下GPT3,GPT3是一个基于transformer decoder的生成模型,其参数规模达到了1750亿,并且使用45TB数据进行训练,其预训练任务就是“句子接龙”,给定前文持续预测下一个字,因此只要有干净的文本数据就能作为模型的训练数据。虽然任务简单,但由于模型规模大数据量大,训练成本达到了数千万美元,在模型训练过程中还有一个小插曲,研究人员发现了代码中有一个小bug,但因为训练成本昂贵并未修复这个bug。
GPT3首次把模型的规模带到了千亿级别,开辟了大模型赛道,其次也为NLP带来了一种新的范式prompt,prompt为GPT3带来了0样本、小样本的学习能力,也为BERT base级别的模型带来了一些新的玩法。
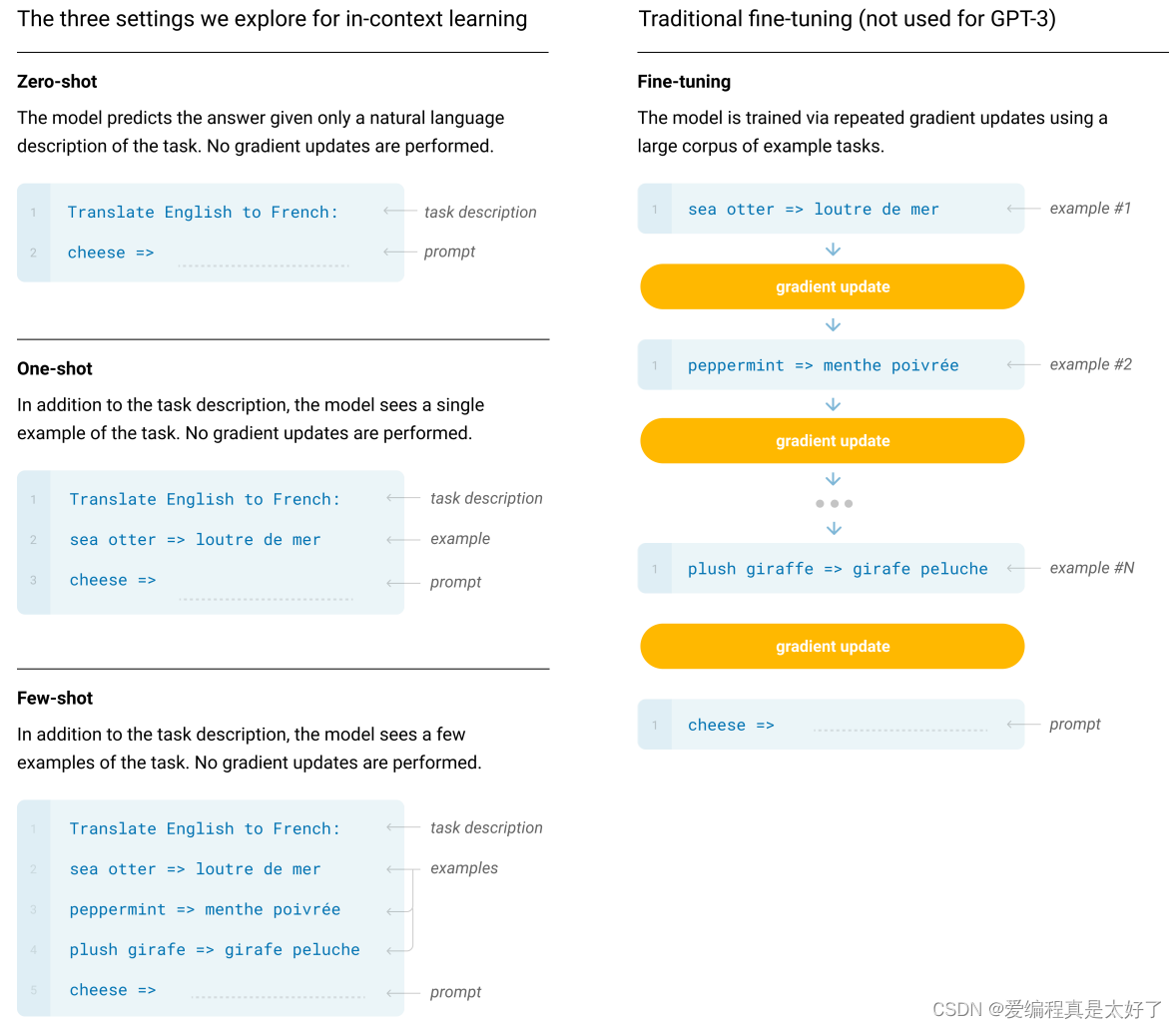
GPT3在AI圈内掀起了很大的浪花,但是并未出圈,其关键原因在于其存在严重的弱点
- 可能会产生偏见,因为它是基于现有数据训练的,如果有任何偏见存在于训练数据中,那么它的结果也会受到影响。
- 模型的训练和使用过程中存在安全漏洞,因为它会存储用户数据,而且它的使用还可能导致机器不可控。

这些问题被统一称为misalignment,随着语言模型的规模越来越大,模型的输出很难满足用户的需求,并且对于生成模型来说,如果要生成不同的答案就涉及到采样算法,那这对于生成的内容来说就更难控制了,那么怎么解决这个问题呢?接下来我们就来看看ChatGPT是怎么做到的。
管得住嘴的ChatGPT
在ChatGPT面世前OpenAI还出过一篇paper:Training language models to follow instructions with human feedback,一看这标题就能感觉到肯定少不了人工打标,这篇paper提出了对于GPT3的改进称为InstructGPT,InstructGPT的目标就是要解决GPT3“管不住嘴”的问题,其解决方案叫做RLHF,其包含3个步骤
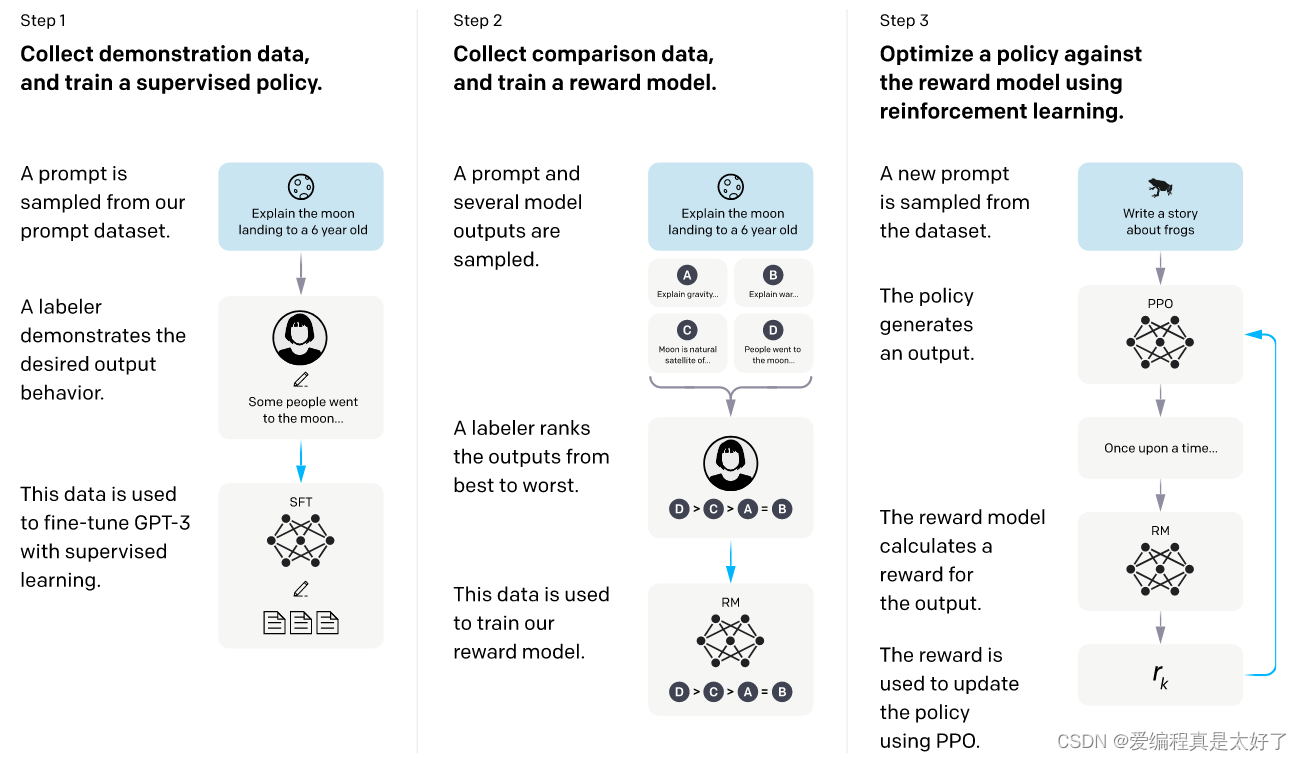
1、Collect demonstration data, and train a supervised policy
GPT3面世后,OpenAI提供了api,付费后即可集成到自己的项目中,用户使用的时候直接采用 prompt的方法做0样本或小样本的预测,这个过程让OpenAI收集到了大量的prompt数据,研究人员从这些prompt中采样一部分,人工对这些prompt做回答,得到的结果称为demonstration即有标签数据,再用这些demonstration继续fine-tuning GPT3,这个过程称为supervised fine-tuning (SFT)。GPT3的预训练阶段使用的是网上海量的数据,这些数据的质量鱼龙混杂,监督学习的目的就是让模型能生成更多符合人类预期的答案,从而尽可能避免生成一些有害的信息。
2、Collect comparison data, and train a reward model
但是监督学习毕竟需要标注大量数据,OpenAI在怎么有钱也不能这么造呀,于是乎OpenAI想了个办法,搞个模型来判断GPT3输出的有没有问题。于是在有了SFT模型后,继续采样prompt,让SFT模型输出多个不同的output,人工对output做排序,把这个结果拿去训练一个RM(reward model),这个模型和SFT结果一样,只是size小一些,paper中提到6B级别的模型比175B级别的模型更加稳定。注意这里的output是一个zero mean的,这样RM模型只要输出一个大于0的值那么就认为GPT3生成的内容是OK的。
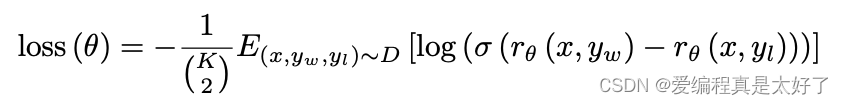
最后看下loss function,其中 表示的是RM,
表示的是用户输入的内容,
表示不同的答案,注意这里有一个组合数
训练的时候要把同一个组合数中的内容放到一个batch内,不然会出现过拟合的情况,K通常取4到9之间的一个值,可以看到这其实就是一个pairwise模型。
3、Optimize a policy against the reward model using PPO
有了RM,下一步我们就可以用RM的输出结果来反哺SFT模型了,其思路是采用RM的输出值作为reward,基于 RL的思路进行优化,
- policy:给GPT输入文本后输出结果的过程
- action:词典
- observation:输出文本
- objective function:一共包含三项,其中
是RM的输出分数,第二项是KL惩罚项,目的是为了让 RL模型的输出结果和SFT模型的输出结果差距不要太大,第三项则是为了保证RL模型能保留好语言模型的能力,整个模型称为PPO-ptx。有了这样的一个模型框架后 ,有新的prompt模型就能做到持续的自迭代。
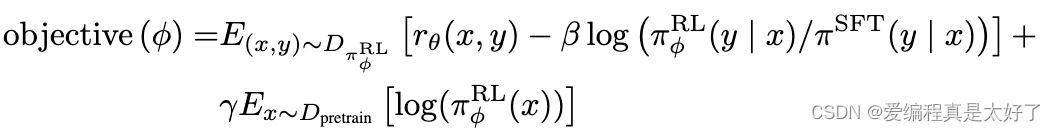
有多少人工才有多少智能
在RLHF的优化过程中其实存在很多的标注任务,OpenAI把标注这个过程看的其实非常的重,他们组建了一个40人的外包标注团队,并且基于以下标准 对标注人员做了一个严格的筛选:
- 确保标注人员对信息敏感,OpenAI首先准备了一份自己标注的数据,这些数据包含一些敏感信息,需要标注人员的标注结果和OpenAI认为的敏感信息是尽可能一致的。
- 排序阶段的标注需要和OpenAI研究人员标注的排序尽可能一致
- OpenAI构建了一些敏感prompt,让标注人员编写demonstration,研究人员对每个demonstration给一个1-7分的Likert scale(李克特量表),并针对标注人员计算平均分数。
- 询问标注人员对于哪些话题或者文化群体更能识别出敏感话题
基于以上4个标准OpenAI筛选出了个标注团队,可见只有高质量的数据才能给模型带来质的提升。
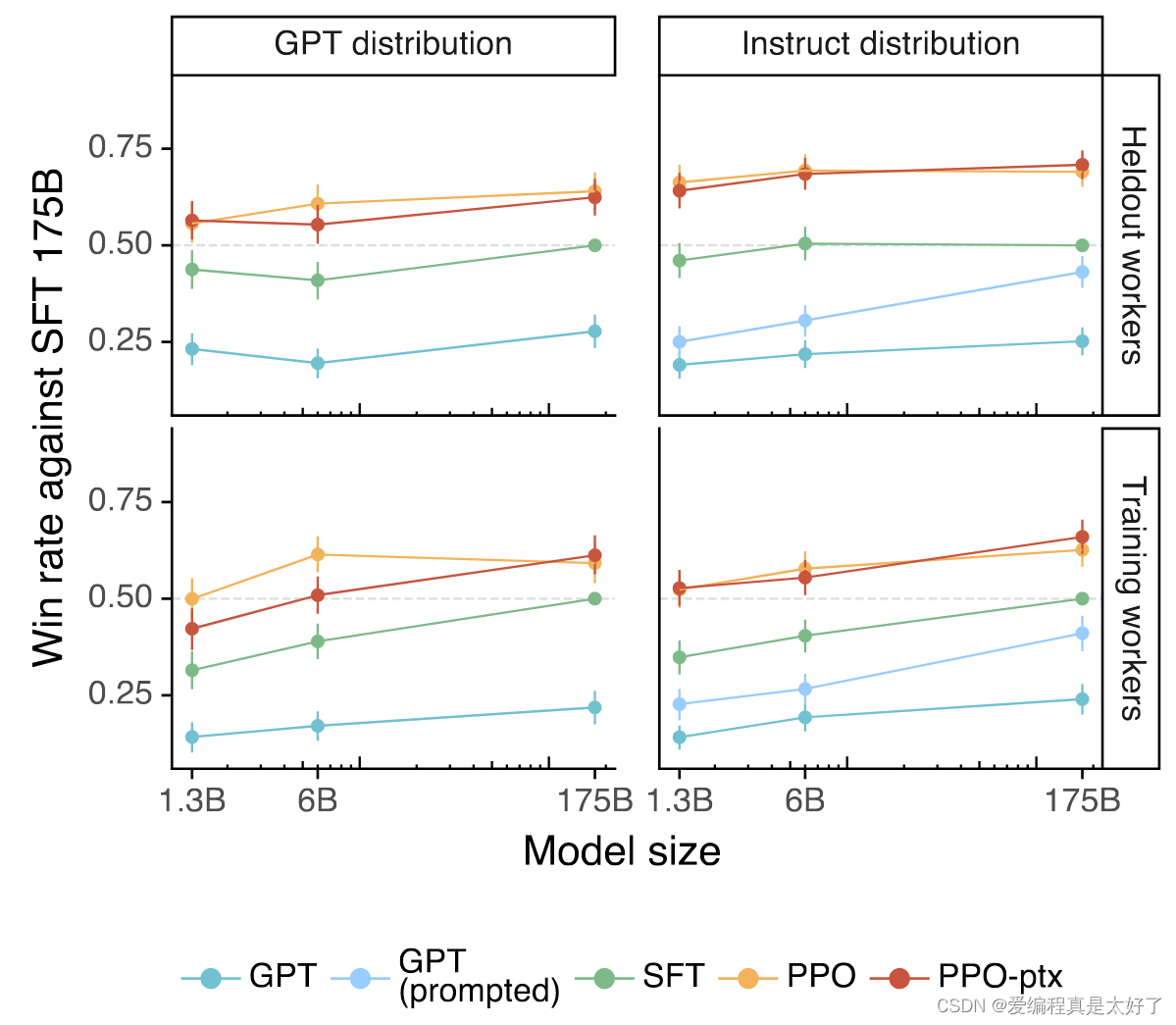
最后看看整体的效果,基于PPO-ptx的模型效果提升明显,特别是6B规模的模型效果出色。
思考
ChatGPT火了之后,大家都在讨论能否把ChatGPT应用到自己的业务中或者能否把RL应用到业务中减少些人力标注成本,这里也说说我自己对这两个问题的想法。
-
ChatGPT规模比较大,想直接落地难度还是很高的,仅仅算力就已经挡住了大部分人,但是从上文的效果图中也能看到,6B规模的模型在RLHF的思路下效果也是不错的,所以如果真的想朝着这个方向去落地,可以考虑下6B规模的模型,目前抱抱脸也有很多同规模大小的开源语言模型可以尝试下,不过RLHF的标注成本也不低能否承受也需要提前考虑清楚。
-
RL真的适合应用在NLP应用中码?我觉得还是要看场景,在ChatGPT中RL其实解决的是misalignment问题,GPT3本身已经具备了较强的生成能力,只是说容易“胡言乱语”,RL的任务只是纠正GPT3的这个缺点,并且RM的上限决定了GPT3能把这个缺点改进多少。所以说RL也不是万能的,在我看来ChatGPT使用RL更多是为了尽可能节约人工标注成本。
ChatGPT应该只是OpenAI的压轴戏,让我们一起期待23年初的GPT4能带给我们带来怎样的惊喜。
文章出处登录后可见!