Albumentations方法目录
- 前言
- 基础调用
- TODO LIST
- Pixel-level transforms
- AdvancedBlur(使用随机选择参数的广义正态滤波器)
- Blur(模糊)
- CLAHE(限制对比度自适应直方图均衡化)
- ChannelDropout(随机drop一个或多个通道)
- ChannelShuffle(通道打乱)
- ColorJitter(色彩抖动【亮度、对比度、饱和度】)
- Defocus(虚焦)
- Downscale(降质)
- Emboss(浮雕效果)
- Equalize(直方图均衡)
- FDA(Fourier-Domain-Adaptation,实现简单的风格迁移)
- FancyPCA(RGB图像色彩增强)
- FromFloat(乘最大值变整型,与ToFloat相反)
- GaussNoise
- GaussianBlur
- GlassBlur
- HistogramMatching(直方图匹配,会引起色调变化)
- HueSaturationValue(色调、饱和度、亮度)
- ISONoise(传感器噪声)
- ImageCompression(图像压缩)
- InvertImg(255-img)
- MedianBlur
- MotionBlur
- MultiplicativeNoise(乘性噪声)
- Normalize(归一化)
- PixelDistributionAdaptation
- Posterize(色调分层)
- RGBShift(RGB每个通道上值偏移)
- RandomBrightnessContrast(亮度、对比度)
- RandomFog(雾效果)
- RandomGamma(gamma变换)
- RandomRain(下雨效果)
- RandomShadow
- RandomSnow
- RandomSunFlare(太阳耀斑效果)
- RandomToneCurve
- RingingOvershoot
- Sharpen(锐化)
- Solarize(大于阈值反转)
- Spatter(镜头雨点泥点飞溅效果)
- Superpixels(超像素)
- TemplateTransform
- ToFloat(除最大值归一化,与FromFloat相反)
- ToGray(转灰度(三通道))
- ToRGB(灰度转三通道RGB)
- ToSepia(加棕褐色滤镜)
- UnsharpMask(锐化)
- ZoomBlur
- Spatial-level transforms
- Affine
- BBoxSafeRandomCrop
- CenterCrop(裁剪中心区域)
- CoarseDropout(矩形区域cutout)
- Crop(裁切)
- CropAndPad(裁剪或填充图像边缘)
- CropNonEmptyMaskIfExists(裁剪+缩放,可以忽略mask部分区域)
- ElasticTransform(弹性变换)
- Flip(翻转)
- GridDistortion(网格畸变)
- GridDropout(网格状cutout)
- HorizontalFlip(水平翻转)
- Lambda
- LongestMaxSize(长边等比例缩放至指定size)
- MaskDropout(随机抹除目标实例)
- NoOp(无操作)
- OpticalDistortion(光学畸变(桶形、枕形))
- PadIfNeeded(边界填充)
- Perspective(透视变换)
- PiecewiseAffine
- PixelDropout
- RandomCrop(随机裁剪)
- RandomCropFromBorders
- RandomCropNearBBox(指定rect附近裁剪)
- RandomGridShuffle(分块打乱)
- RandomResizedCrop(裁剪+缩放,裁剪区域宽高比随机)
- RandomRotate90(随机旋转90度n次,即0°,90°,180°,270°随机旋转)
- RandomScale(随机缩放)
- RandomSizedBBoxSafeCrop(裁剪+缩放,所有bboxes包含在内)
- RandomSizedCrop(裁剪+缩放,裁剪区域宽高比固定)
- Resize(缩放,bbox不变,keypoints变化)
- Rotate(旋转任意角度,旋转后可能丢失部分内容)
- SafeRotate(旋转任意角度,旋转后图像包含原始图像全部内容)
- ShiftScaleRotate(平移、缩放、旋转)
- SmallestMaxSize(短边等比例缩放至指定size)
- Transpose(转置,行列交换)
- VerticalFlip(垂直翻转)
前言
本文旨在详解albumentations 增强方法使用,结合源码了解参数含义和有效值范围,结合可视化结果直观了解各个增强方法的功能以及参数取值不同如何影响增强图像。
参照官网将所有增强方法划分为两个大类别介绍:Pixel-level transforms和Spatial-level transforms,两者区别在于该增强方法是否会引起图像附加属性变化(如masks, bounding boxes, keypoints)。Pixel-level不会,Spatial-level会,Spatial-level transforms有个总览表格记录每个增强方法会引起哪些附加属性变化。每个类别的增强方法按字母顺序排序,方便检索。
本文初期编辑时版本是Albumentations version : 1.3.0,v1.3相比以前版本有较大变化(变换方法新增,级目录重构等),建议更新至1.3.0及以上版本,否则有些变换调用不到或者路径不对。文中个别变换方法在1.3.0以上版本。如果某些函数调用不到,可以更新一下。
更新albumentations:pip install -U albumentations
文中代码默认import albumentations as A,若出现A.transformxx,等同于albumentations.transformxx
如有错误,可在评论区指出。
拓展阅读:
官方code网站:https://github.com/albumentations-team/albumentations
官方文档:https://albumentations.readthedocs.io/
部分增强可视化:Albumentations数据增强方法(文中VerticalFlip和HorizontalFlip结果反了)
道路场景图像增强:https://github.com/UjjwalSaxena/Automold–Road-Augmentation-Library
Albumentations已包含其中一些实现:RandomRain,RandomFog,RandomSunFlare,RandomShadow,RandomSnow。
基础调用
Notes
-
调用时注意默认参数p,大多都是p=0.5,偶尔有些是p=1。
查看base初始化参数:get_base_init_args()
查看transform初始化参数 :get_base_init_args() -
许多参数接受单个数字或者两个数字区间形式输入。两个数字区间形式一般都是在这范围中随机采样,若是单个数字,有些转化为默认区间(如ColorJitter参数,解释得很详细),有些直接用该值(如Spatter参数)。需注意区分。
-
各变换的
apply方法是核心,init方法中会对输入参数先进行些预处理工作,如单个数字转化为区间参数、检查参数是否在有效区间内等。 -
get_params()方法不可单独调用来追溯结果图对应的参数,因为单独调用get_params()方法时,又再一次随机采样了。
想要固定参数的话,可以将输入参数的区间边界值均设为相同值,这样random采样之后只能是其本身。 -
bounding box指的是归一化(x/width, y/height)后的坐标,float型,非整型绝对值。
-
有很多方法涉及图像边界补充,参数border_mode可视化:
OpenCV滤波之copyMakeBorder和borderInterpolate
OpenCV图像处理|1.16 卷积边界处理
OpenCV-扩充图像的边界 -
调用增强方法的demo code,以Sharpen方法为例:
import cv2 import albumentations as A if __name__ == "__main__": filename = 'src' src_img = cv2.imread(f'imgs/{filename}.jpg') dst_path = f'imgs/{filename}_aug.jpg' transform = A.Sharpen(alpha=(0.2, 0.5), lightness=(0.5, 1.0), p=0.5) img_aug = transform(image=src_img)['image'] cv2.imwrite(dst_path, img_aug)
to_tuple( )
单个输入参数转化为区间参数时经常用到这个功能函数。
注意 low 参数表示另一边界的填补值。
举例:
self.blur_limit = to_tuple(1, 3) # self.blur_limit = (1, 3)
self.blur_limit = to_tuple(5, 3) # self.blur_limit = (3, 5)
# source code
def to_tuple(param, low=None, bias=None):
"""Convert input argument to min-max tuple
Args:
param (scalar, tuple or list of 2+ elements): Input value.
If value is scalar, return value would be (offset - value, offset + value).
If value is tuple, return value would be value + offset (broadcasted).
low: Second element of tuple can be passed as optional argument
bias: An offset factor added to each element
"""
if low is not None and bias is not None:
raise ValueError("Arguments low and bias are mutually exclusive")
if param is None:
return param
if isinstance(param, (int, float)):
if low is None:
param = -param, +param
else:
param = (low, param) if low < param else (param, low)
elif isinstance(param, Sequence):
if len(param) != 2:
raise ValueError("to_tuple expects 1 or 2 values")
param = tuple(param)
else:
raise ValueError("Argument param must be either scalar (int, float) or tuple")
if bias is not None:
return tuple(bias + x for x in param)
return tuple(param)
获取初始化的默认base参数
method:get_base_init_args()
包含"always_apply"和"p"两个参数
# source code
def get_base_init_args(self) -> Dict[str, Any]:
return {"always_apply": self.always_apply, "p": self.p}
# demo code
transform1 = A.Emboss()
print(transform1.get_base_init_args())
# output
# {'always_apply': False, 'p': 0.5}
transform1 = A.Emboss(p=1)
print(transform1.get_base_init_args())
# output
# {'always_apply': False, 'p': 1}
获取初始化的默认transform参数
method:get_transform_init_args()
除基础参数always_apply、p以外的变换参数
注意:调用此函数前需先实现get_transform_init_args_names()方法指定需要获取的transform参数,因为BasicTransform类未实现该方法。
# source code from class Emboss(ImageOnlyTransform)
def get_transform_init_args_names(self): # 若变换的该方法未实现,需先实现
return ("alpha", "strength")
def get_transform_init_args(self) -> Dict[str, Any]:
return {k: getattr(self, k) for k in self.get_transform_init_args_names()}
# demo code
transform1 = A.Emboss()
print(transform1.get_transform_init_args())
# output
# {'alpha': (0.2, 0.5), 'strength': (0.2, 0.7)}
transform1 = A.Emboss(alpha=(0.1, 0.5))
print(transform1.get_transform_init_args())
# output
# {'alpha': (0.1, 0.5), 'strength': (0.2, 0.7)}
获取随机参数
method:get_params_dependent_on_targets()
此方法BasicTransform未实现,可以参考如下ChannelShuffle()的实现,返回想要查看的参数。
注意:不能单独调用此函数查看结果图对应的参数是什么,单独调用查看时随机数已改变。
# ChannelShuffle.get_params_dependent_on_targets
def get_params_dependent_on_targets(self, params):
img = params["image"]
ch_arr = list(range(img.shape[2]))
random.shuffle(ch_arr)
return {"channels_shuffled": ch_arr}
# demo code
# 查看ChannelShuffle变换随机生成的channels_shuffled参数
param = A.ChannelShuffle().get_params_dependent_on_targets(
dict(image=src_img))['channels_shuffled']
TODO LIST
- “Blur”
- “VerticalFlip”
- “HorizontalFlip”
- “Flip”
- “Normalize”
- “Transpose”
- “RandomGamma”
- “OpticalDistortion”
- “GridDistortion”
- “RandomGridShuffle”
- “HueSaturationValue”
- “PadIfNeeded”
- “RGBShift”
- “RandomBrightness”
- “RandomContrast”
- “MotionBlur”
- “MedianBlur”
- “GaussianBlur”
- “GaussNoise”
- “GlassBlur”
- “CLAHE”
- “ChannelShuffle”
- “InvertImg”
- “ToGray”
- “ToSepia”
- “JpegCompression”
- “ImageCompression”
- “CoarseDropout” ,功能涵盖"Cutout"
- “ToFloat”
- “FromFloat”
- “RandomBrightnessContrast”
- “RandomSnow”
- “RandomRain”
- “RandomFog”
- “RandomSunFlare”
- “RandomShadow”
- “RandomToneCurve”
- “Lambda”
- “ChannelDropout”
- “ISONoise”
- “Solarize”
- “Equalize”
- “Posterize”
- “Downscale”
- “MultiplicativeNoise”
- “FancyPCA”
- “MaskDropout”
- “GridDropout”
- “ColorJitter”
- “Sharpen”
- “Emboss”
- “Superpixels”
- “TemplateTransform”
- autoalbument
Pixel-level transforms
像素级变换将仅更改输入图像,对应的其他targets例如mask、bounding boxes和keypoints将保持不变。
Pixel-level transforms will change just an input image and will leave any additional targets such as masks, bounding boxes, and keypoints unchanged.
像素级变换列举如下:
功能:Blur the input image using a Generalized Normal filter with a randomly selected parameters.
参数说明:
ScaleFloatType = Union[float, Tuple[float, float]]
ScaleIntType = Union[int, Tuple[int, int]]
以下参数只有 blur_limit和rotate_limit是ScaleIntType,其余为ScaleFloatType,都是可以输入一个整数或者一个范围。整数输入会根据内部逻辑自动转为区间。最后变换应用参数由在区间内随机采样获取。
- blur_limit: 图像模糊的最大高斯核。可以为0或者正奇数。默认值:(3, 7)。
若为0,会根据sigma参数自动计算:round(sigma * (3 if img.dtype == np.uint8 else 4) * 2 + 1) + 1 - sigmaX_limit: X方向上的高斯核标准差. 可以为0或者正数。默认值:0
若为0,会根据ksize参数自动计算:sigma = 0.3*((ksize-1)*0.5 - 1) + 0.8
若为正数,会转化为区间范围(0, sigma_limit),在该范围内随机取值。 - sigmaY_limit: Y方向上的高斯核标准差.
- rotate_limit: 旋转高斯核的参数。若输入是一个整型,将转换为
(-rotate_limit, rotate_limit)。默认值: (-90, 90). - beta_limit: 控制分布形状的参数。 1为正态分布。默认值: (0.5, 8.0).
- noise_limit:控制噪声强度的乘性因子。必须为正数,最好在1.0附近。若为单个数字,会转化为区间 (0, noise_limit)。默认值: (0.75, 1.25).
注意:blur_limit与sigmaX_limit(sigmaY_limit)有计算依赖关系,两者不可同时为0!!!
# source code
class AdvancedBlur(ImageOnlyTransform):
"""Blur the input image using a Generalized Normal filter with a randomly selected parameters.
This transform also adds multiplicative noise to generated kernel before convolution.
Args:
blur_limit: maximum Gaussian kernel size for blurring the input image.
Must be zero or odd and in range [0, inf). If set to 0 it will be computed from sigma
as `round(sigma * (3 if img.dtype == np.uint8 else 4) * 2 + 1) + 1`.
If set single value `blur_limit` will be in range (0, blur_limit).
Default: (3, 7).
sigmaX_limit: Gaussian kernel standard deviation. Must be in range [0, inf).
If set single value `sigmaX_limit` will be in range (0, sigma_limit).
If set to 0 sigma will be computed as `sigma = 0.3*((ksize-1)*0.5 - 1) + 0.8`. Default: 0.
sigmaY_limit: Same as `sigmaY_limit` for another dimension.
rotate_limit: Range from which a random angle used to rotate Gaussian kernel is picked.
If limit is a single int an angle is picked from (-rotate_limit, rotate_limit). Default: (-90, 90).
beta_limit: Distribution shape parameter, 1 is the normal distribution. Values below 1.0 make distribution
tails heavier than normal, values above 1.0 make it lighter than normal. Default: (0.5, 8.0).
noise_limit: Multiplicative factor that control strength of kernel noise. Must be positive and preferably
centered around 1.0. If set single value `noise_limit` will be in range (0, noise_limit).
Default: (0.75, 1.25).
p (float): probability of applying the transform. Default: 0.5.
Reference:
https://arxiv.org/abs/2107.10833
Targets:
image
Image types:
uint8, float32
"""
def __init__(
self,
blur_limit: ScaleIntType = (3, 7),
sigmaX_limit: ScaleFloatType = (0.2, 1.0),
sigmaY_limit: ScaleFloatType = (0.2, 1.0),
rotate_limit: ScaleIntType = 90,
beta_limit: ScaleFloatType = (0.5, 8.0),
noise_limit: ScaleFloatType = (0.9, 1.1),
always_apply: bool = False,
p: float = 0.5,
):
super().__init__(always_apply, p)
self.blur_limit = to_tuple(blur_limit, 3)
self.sigmaX_limit = self.__check_values(to_tuple(sigmaX_limit, 0.0), name="sigmaX_limit")
self.sigmaY_limit = self.__check_values(to_tuple(sigmaY_limit, 0.0), name="sigmaY_limit")
self.rotate_limit = to_tuple(rotate_limit)
self.beta_limit = to_tuple(beta_limit, low=0.0)
self.noise_limit = self.__check_values(to_tuple(noise_limit, 0.0), name="noise_limit")
if (self.blur_limit[0] != 0 and self.blur_limit[0] % 2 != 1) or (
self.blur_limit[1] != 0 and self.blur_limit[1] % 2 != 1
):
raise ValueError("AdvancedBlur supports only odd blur limits.")
if self.sigmaX_limit[0] == 0 and self.sigmaY_limit[0] == 0:
raise ValueError("sigmaX_limit and sigmaY_limit minimum value can not be both equal to 0.")
if not (self.beta_limit[0] < 1.0 < self.beta_limit[1]):
raise ValueError("Beta limit is expected to include 1.0")
@staticmethod
def __check_values(
value: Sequence[float], name: str, bounds: Tuple[float, float] = (0, float("inf"))
) -> Sequence[float]:
if not bounds[0] <= value[0] <= value[1] <= bounds[1]:
raise ValueError(f"{name} values should be between {bounds}")
return value
def apply(self, img: np.ndarray, kernel: np.ndarray = None, **params) -> np.ndarray:
return FMain.convolve(img, kernel=kernel)
def get_params(self) -> Dict[str, np.ndarray]:
ksize = random.randrange(self.blur_limit[0], self.blur_limit[1] + 1, 2)
sigmaX = random.uniform(*self.sigmaX_limit)
sigmaY = random.uniform(*self.sigmaY_limit)
angle = np.deg2rad(random.uniform(*self.rotate_limit))
# Split into 2 cases to avoid selection of narrow kernels (beta > 1) too often.
if random.random() < 0.5:
beta = random.uniform(self.beta_limit[0], 1)
else:
beta = random.uniform(1, self.beta_limit[1])
noise_matrix = random_utils.uniform(self.noise_limit[0], self.noise_limit[1], size=[ksize, ksize])
# Generate mesh grid centered at zero.
ax = np.arange(-ksize // 2 + 1.0, ksize // 2 + 1.0)
# Shape (ksize, ksize, 2)
grid = np.stack(np.meshgrid(ax, ax), axis=-1)
# Calculate rotated sigma matrix
d_matrix = np.array([[sigmaX**2, 0], [0, sigmaY**2]])
u_matrix = np.array([[np.cos(angle), -np.sin(angle)], [np.sin(angle), np.cos(angle)]])
sigma_matrix = np.dot(u_matrix, np.dot(d_matrix, u_matrix.T))
inverse_sigma = np.linalg.inv(sigma_matrix)
# Described in "Parameter Estimation For Multivariate Generalized Gaussian Distributions"
kernel = np.exp(-0.5 * np.power(np.sum(np.dot(grid, inverse_sigma) * grid, 2), beta))
# Add noise
kernel = kernel * noise_matrix
# Normalize kernel
kernel = kernel.astype(np.float32) / np.sum(kernel)
return {"kernel": kernel}
def get_transform_init_args_names(self) -> Tuple[str, str, str, str, str, str]:
return (
"blur_limit",
"sigmaX_limit",
"sigmaY_limit",
"rotate_limit",
"beta_limit",
"noise_limit",
)
默认参数随机生成的三张结果图。可视化图像并排显示的时候压缩了,肉眼感受变化不明显。

功能:图像模糊
参数说明: blur_limit (int, (int, int)):模糊图像的最大kernel size. 有效值范围[3, inf),默认值:(3, 7).
# source code
class Blur(ImageOnlyTransform):
"""Blur the input image using a random-sized kernel.
Args:
blur_limit (int, (int, int)): maximum kernel size for blurring the input image.
Should be in range [3, inf). Default: (3, 7).
p (float): probability of applying the transform. Default: 0.5.
Targets:
image
Image types:
uint8, float32
"""
def __init__(self, blur_limit: ScaleIntType = 7, always_apply: bool = False, p: float = 0.5):
super().__init__(always_apply, p)
self.blur_limit = to_tuple(blur_limit, 3)
def apply(self, img: np.ndarray, ksize: int = 3, **params) -> np.ndarray:
return F.blur(img, ksize)
def get_params(self) -> Dict[str, Any]:
return {"ksize": int(random.choice(np.arange(self.blur_limit[0], self.blur_limit[1] + 1, 2)))}
def get_transform_init_args_names(self) -> Tuple[str, ...]:
return ("blur_limit",)

功能:对输入图像应用限制对比度自适应直方图均衡化(Contrast Limited Adaptive Histogram Equalization)
扩展阅读:
Image Enhancement – CLAHE
CLAHE算法学习
# source code
class CLAHE(ImageOnlyTransform):
"""Apply Contrast Limited Adaptive Histogram Equalization to the input image.
Args:
clip_limit (float or (float, float)): upper threshold value for contrast limiting.
If clip_limit is a single float value, the range will be (1, clip_limit). Default: (1, 4).
tile_grid_size ((int, int)): size of grid for histogram equalization. Default: (8, 8).
p (float): probability of applying the transform. Default: 0.5.
Targets:
image
Image types:
uint8
"""
def __init__(self, clip_limit=4.0, tile_grid_size=(8, 8), always_apply=False, p=0.5):
super(CLAHE, self).__init__(always_apply, p)
self.clip_limit = to_tuple(clip_limit, 1)
self.tile_grid_size = tuple(tile_grid_size)
def apply(self, img, clip_limit=2, **params):
if not is_rgb_image(img) and not is_grayscale_image(img):
raise TypeError("CLAHE transformation expects 1-channel or 3-channel images.")
return F.clahe(img, clip_limit, self.tile_grid_size)
def get_params(self):
return {"clip_limit": random.uniform(self.clip_limit[0], self.clip_limit[1])}
def get_transform_init_args_names(self):
return ("clip_limit", "tile_grid_size")

功能:随机drop一些通道,用固定值填充
参数说明:
channel_drop_range (int, int): [min_dropout_channel_num, max_dropout_channel_num](闭区间),表示在channel_drop_range范围内随机选一个数,作为drop的通道数量。具体drop的通道id随机choice产生。
其中min_dropout_channel_num > 0 (单通道图像不支持),max_dropout_channel_num < image_channels(不可全通道drop),min_dropout_channel_num可以等于max_dropout_channel_num,默认(1,1),即随机drop一个通道。
fill_value (int, float): 用来填充dropped channel的像素值,默认0。
drop机制详解:
-
确定drop的通道数量
num_drop_channels = random.randint(channel_drop_range[0], channel_drop_range[1]) -
在图像通道中随机选择num_drop_channels个通道drop,选中的通道用fill_value填充
channels_to_drop = random.sample(range(num_channels), k=num_drop_channels) -
对选中的 channels_to_drop 通道进行fill_value填充
def channel_dropout(img, channels_to_drop, fill_value=0): if len(img.shape) == 2 or img.shape[2] == 1: raise NotImplementedError("Only one channel. ChannelDropout is not defined.") img = img.copy() img[..., channels_to_drop] = fill_value return img
ChannelDropout源码如下:
# source code
class ChannelDropout(ImageOnlyTransform):
"""Randomly Drop Channels in the input Image.
Args:
channel_drop_range (int, int): range from which we choose the number of channels to drop.
fill_value (int, float): pixel value for the dropped channel.
p (float): probability of applying the transform. Default: 0.5.
Targets:
image
Image types:
uint8, uint16, unit32, float32
"""
def __init__(self, channel_drop_range=(1, 1), fill_value=0, always_apply=False, p=0.5):
super(ChannelDropout, self).__init__(always_apply, p)
self.channel_drop_range = channel_drop_range
self.min_channels = channel_drop_range[0]
self.max_channels = channel_drop_range[1]
if not 1 <= self.min_channels <= self.max_channels:
raise ValueError("Invalid channel_drop_range. Got: {}".format(channel_drop_range))
self.fill_value = fill_value
def apply(self, img, channels_to_drop=(0,), **params):
return F.channel_dropout(img, channels_to_drop, self.fill_value)
def get_params_dependent_on_targets(self, params):
img = params["image"]
num_channels = img.shape[-1]
if len(img.shape) == 2 or num_channels == 1:
raise NotImplementedError("Images has one channel. ChannelDropout is not defined.")
if self.max_channels >= num_channels:
raise ValueError("Can not drop all channels in ChannelDropout.")
num_drop_channels = random.randint(self.min_channels, self.max_channels)
channels_to_drop = random.sample(range(num_channels), k=num_drop_channels)
return {"channels_to_drop": channels_to_drop}
def get_transform_init_args_names(self):
return ("channel_drop_range", "fill_value")
@property
def targets_as_params(self):
return ["image"]
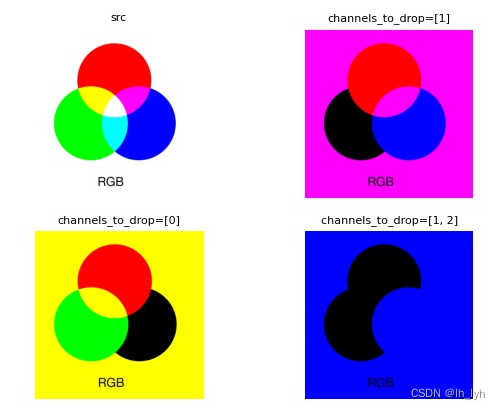
opencv读图是BGR格式,channels_to_drop=[1]时,drop G通道,用0填充,所以右上图像绿色部分变为黑色。
channels_to_drop=[0]时,drop B通道,用0填充,所以左下图像蓝色部分变为黑色。
channels_to_drop=[1,2]时,drop G,R通道,用0填充,所以右下图像绿色、红色部分变为黑色,白底部分有RGB三个通道,RG通道置为0,只剩B通道为255,所以背景变为蓝色。
功能:输入图像通道重排(rearrange channels)
# source code
class ChannelShuffle(ImageOnlyTransform):
"""Randomly rearrange channels of the input RGB image.
Args:
p (float): probability of applying the transform. Default: 0.5.
Targets:
image
Image types:
uint8, float32
"""
@property
def targets_as_params(self):
return ["image"]
def apply(self, img, channels_shuffled=(0, 1, 2), **params):
return F.channel_shuffle(img, channels_shuffled)
def get_params_dependent_on_targets(self, params):
img = params["image"]
ch_arr = list(range(img.shape[2]))
random.shuffle(ch_arr) # 生成随机通道列表
return {"channels_shuffled": ch_arr}
def get_transform_init_args_names(self):
return ()
####################### F.channel_shuffle
def channel_shuffle(img, channels_shuffled):
img = img[..., channels_shuffled]
return img
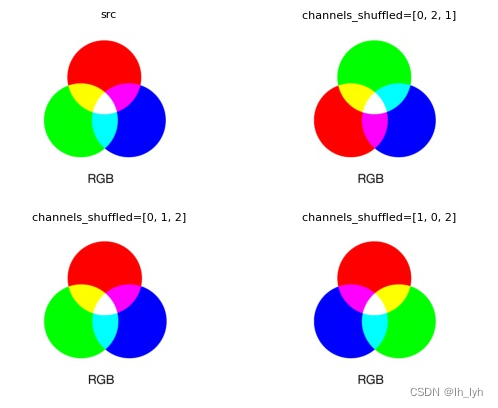
右上:opencv读图是BGR格式,channels_shuffled=[0,2,1],表示G通道和R通道交换,所以图中绿色和红色互换
右下:channels_shuffled=[1,0,2],表示B通道和G通道交换,所以图中蓝色和绿色互换
功能:随机改变图像的亮度、对比度、饱和度(参数均表示抖动幅度)
Randomly changes the brightness, contrast, and saturation of an image. Compared to ColorJitter from torchvision,
this transform gives a little bit different results because Pillow (used in torchvision) and OpenCV (used in
Albumentations) transform an image to HSV format by different formulas. Another difference – Pillow uses uint8
overflow, but we use value saturation.
参数(详见下方source code中的__check_values函数):
- 参数初始化:
brightness、contrast 、saturation 、hue 输入形式:一个数或者一个区间(float or tuple(list) of float (min, max))。
区间参数(输入为数字的话将内部转换为区间)需要满足各参数的有效区间(有效区间和数字转区间规则见下)。
所以各参数输入要求为:
brightness,contrast ,saturation:
hue:- 有效区间
brightness,contrast ,saturation有效区间为:[0, +inf]
hue有效区间为:[-0.5, 0.5] - 数字转区间内部逻辑
brightness,contrast ,saturation:[ max(0, 1 - input_value), 1 + input_value]
hue:[ - input_value, + input_value]
- 有效区间
Apply(详见下方source code中的get_params函数):
- 各变换factor确定:random.uniform(处理后的参数区间)
- 各变换apply顺序随机
# source code
class ColorJitter(ImageOnlyTransform):
"""Randomly changes the brightness, contrast, and saturation of an image. Compared to ColorJitter from torchvision,
this transform gives a little bit different results because Pillow (used in torchvision) and OpenCV (used in
Albumentations) transform an image to HSV format by different formulas. Another difference - Pillow uses uint8
overflow, but we use value saturation.
Args:
brightness (float or tuple of float (min, max)): How much to jitter brightness.
brightness_factor is chosen uniformly from [max(0, 1 - brightness), 1 + brightness]
or the given [min, max]. Should be non negative numbers.
contrast (float or tuple of float (min, max)): How much to jitter contrast.
contrast_factor is chosen uniformly from [max(0, 1 - contrast), 1 + contrast]
or the given [min, max]. Should be non negative numbers.
saturation (float or tuple of float (min, max)): How much to jitter saturation.
saturation_factor is chosen uniformly from [max(0, 1 - saturation), 1 + saturation]
or the given [min, max]. Should be non negative numbers.
hue (float or tuple of float (min, max)): How much to jitter hue.
hue_factor is chosen uniformly from [-hue, hue] or the given [min, max].
Should have 0 <= hue <= 0.5 or -0.5 <= min <= max <= 0.5.
"""
def __init__(
self,
brightness=0.2,
contrast=0.2,
saturation=0.2,
hue=0.2,
always_apply=False,
p=0.5,
):
super(ColorJitter, self).__init__(always_apply=always_apply, p=p)
self.brightness = self.__check_values(brightness, "brightness")
self.contrast = self.__check_values(contrast, "contrast")
self.saturation = self.__check_values(saturation, "saturation")
# hue参数初始化的offset和bounds均不同于上,
self.hue = self.__check_values(hue, "hue", offset=0, bounds=[-0.5, 0.5], clip=False)
@staticmethod
# 输入参数处理,需符合各参数有效区间
def __check_values(value, name, offset=1, bounds=(0, float("inf")), clip=True):
if isinstance(value, numbers.Number): # 数字转区间内部逻辑
if value < 0: # 单个数字输入不可为负数
raise ValueError("If {} is a single number, it must be non negative.".format(name))
value = [offset - value, offset + value]
if clip: # hue是不进行clip的,其他三个参数进行clip操作
value[0] = max(value[0], 0)
elif isinstance(value, (tuple, list)) and len(value) == 2:
if not bounds[0] <= value[0] <= value[1] <= bounds[1]: # 若是区间输入,需满足各自的有效区间
raise ValueError("{} values should be between {}".format(name, bounds))
else:
raise TypeError("{} should be a single number or a list/tuple with length 2.".format(name))
return value
def get_params(self):
brightness = random.uniform(self.brightness[0], self.brightness[1])
contrast = random.uniform(self.contrast[0], self.contrast[1])
saturation = random.uniform(self.saturation[0], self.saturation[1])
hue = random.uniform(self.hue[0], self.hue[1])
transforms = [
lambda x: F.adjust_brightness_torchvision(x, brightness),
lambda x: F.adjust_contrast_torchvision(x, contrast),
lambda x: F.adjust_saturation_torchvision(x, saturation),
lambda x: F.adjust_hue_torchvision(x, hue),
]
random.shuffle(transforms) # 各变换顺序随机
return {"transforms": transforms}
def apply(self, img, transforms=(), **params):
if not F.is_rgb_image(img) and not F.is_grayscale_image(img): # 仅支持单通道和三通道图像输入
raise TypeError("ColorJitter transformation expects 1-channel or 3-channel images.")
for transform in transforms:
img = transform(img)
return img
def get_transform_init_args_names(self):
return ("brightness", "contrast", "saturation", "hue")
注意以下结果图上显示的各参数因子是调用各自变化函数传入的参数,并非是ColorJitter的参数,对应关系见上述参数部分描述!
brightness变化:
参数影响:factor越大图像越亮,反之越暗
逻辑:clip(img_value*factor)
# F.adjust_brightness_torchvision函数内容
def _adjust_brightness_torchvision_uint8(img, factor):
lut = np.arange(0, 256) * factor
lut = np.clip(lut, 0, 255).astype(np.uint8)
return cv2.LUT(img, lut)
@preserve_shape
def adjust_brightness_torchvision(img, factor):
if factor == 0:
return np.zeros_like(img)
elif factor == 1:
return img
if img.dtype == np.uint8:
return _adjust_brightness_torchvision_uint8(img, factor)
return clip(img * factor, img.dtype, MAX_VALUES_BY_DTYPE[img.dtype])

contrast变化:
参数影响:factor越小,图像明暗对比越小,factor越大,图像明暗对比越大。
逻辑:clip(img_value * factor + mean * (1 - factor))
# F.adjust_contrast_torchvision函数内容
def _adjust_contrast_torchvision_uint8(img, factor, mean):
lut = np.arange(0, 256) * factor
lut = lut + mean * (1 - factor)
lut = clip(lut, img.dtype, 255)
return cv2.LUT(img, lut)
@preserve_shape
def adjust_contrast_torchvision(img, factor):
if factor == 1:
return img
if is_grayscale_image(img):
mean = img.mean()
else:
mean = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY).mean()
if factor == 0:
return np.full_like(img, int(mean + 0.5), dtype=img.dtype)
if img.dtype == np.uint8:
return _adjust_contrast_torchvision_uint8(img, factor, mean)
return clip(
img.astype(np.float32) * factor + mean * (1 - factor),
img.dtype,
MAX_VALUES_BY_DTYPE[img.dtype],
)

saturation变化:
参数影响:factor越小,图像越偏灰度,factor越大,图像色彩越鲜艳。
逻辑:clip(img * factor + gray * (1 - factor)),原图和灰度图加权融合
# F.adjust_saturation_torchvision函数内容
@preserve_shape
def adjust_saturation_torchvision(img, factor, gamma=0):
if factor == 1:
return img
if is_grayscale_image(img):
gray = img
return gray
else:
gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
gray = cv2.cvtColor(gray, cv2.COLOR_GRAY2RGB) # 三通道的值一致,方便后面与原图加权
if factor == 0:
return gray
# cv2.addWeighted:两个图像加权融合
# result = img * factor + gray * (1 - factor)+ gamma
result = cv2.addWeighted(img, factor, gray, 1 - factor, gamma=gamma)
if img.dtype == np.uint8:
return result
# OpenCV does not clip values for float dtype
return clip(result, img.dtype, MAX_VALUES_BY_DTYPE[img.dtype])

hue变化:
参数影响:factor越大,色调偏移越严重。factor=0,色调不变。
逻辑:图像转HSV颜色空间,np.mod(hue_value + factor * 180, 180) ,再转回RGB颜色空间
# F.adjust_hue_torchvision函数内容
def _adjust_hue_torchvision_uint8(img, factor):
img = cv2.cvtColor(img, cv2.COLOR_RGB2HSV)
lut = np.arange(0, 256, dtype=np.int16)
lut = np.mod(lut + 180 * factor, 180).astype(np.uint8)
img[..., 0] = cv2.LUT(img[..., 0], lut)
return cv2.cvtColor(img, cv2.COLOR_HSV2RGB)
def adjust_hue_torchvision(img, factor):
if is_grayscale_image(img):
return img
if factor == 0:
return img
if img.dtype == np.uint8:
return _adjust_hue_torchvision_uint8(img, factor)
img = cv2.cvtColor(img, cv2.COLOR_RGB2HSV)
img[..., 0] = np.mod(img[..., 0] + factor * 360, 360)
return cv2.cvtColor(img, cv2.COLOR_HSV2RGB)

补充阅读
对比度和饱和度有什么区别
对比度指的是最高亮度和最低亮度的比值。当图像对比度越高时,说明图像明暗差异越明显;饱和度指的是色彩的纯正程度,越纯正饱和度越高。如纯蓝、纯红、纯绿属于高饱和度,而灰蓝、玫红、草绿属于低饱和度,因此图像的饱和度越高说明图像色彩越鲜艳。对比度与饱和度在主体、特点与作用上都有不小的区别,下面就详细说明一下:
一、主体区别
1、对比度:指的是最高亮度和最低亮度的比值。当图像对比度越高时,那么图像明暗差异越明显。
2、饱和度:指的是色彩的纯正程度。当图像的饱和度越高时,那么图像色彩越鲜艳。二、特点区别
1、对比度:图像色彩差异范围越大代表对比度越大,反之则代表对比度越小。当对比度达到120:1时,就可容易地显示生动、丰富的色彩;而当对比度高达300:1时,就可以可支持各阶的颜色。
2、饱和度:饱和度取决于该色中含色成分和消色成分的比例。含色成分越大,饱和度越大;消色成分越大,饱和度越小。三、作用区别
1、对比度:对比度越大,图像越清晰醒目,色彩也越鲜明艳丽;反之,则会让整个画面都灰蒙蒙的。高对比度对于图像的清晰度、细节表现、灰度层次表现都有很大帮助。
2、饱和度:色度由光度线强弱和在不同波长的强度分布有关。最高的色度一般由单波长的强光达到,在波长分布不变的情况下,光强度越弱则色度越低。
功能:图像虚焦
参数:radius > 0,虚焦半径。若为单个数字,则默认转换为[1, radius_input_value] 。默认区间[3, 10]
alias_blur >= 0,高斯模糊的sigma参数。若为单个数字,则默认转换为[0, alias_blur input_value]。默认区间[0.1, 0.5]
参数影响:radius 参数越大,虚焦程度越高。alias_blur 参数变化,肉眼感受到的变化很小。
# source code
class Defocus(ImageOnlyTransform):
"""
Apply defocus transform. See https://arxiv.org/abs/1903.12261.
Args:
radius ((int, int) or int): range for radius of defocusing.
If limit is a single int, the range will be [1, limit]. Default: (3, 10).
alias_blur ((float, float) or float): range for alias_blur of defocusing (sigma of gaussian blur).
If limit is a single float, the range will be (0, limit). Default: (0.1, 0.5).
p (float): probability of applying the transform. Default: 0.5.
Targets:
image
Image types:
Any
"""
def __init__(
self,
radius: ScaleIntType = (3, 10),
alias_blur: ScaleFloatType = (0.1, 0.5),
always_apply: bool = False,
p: float = 0.5,
):
super().__init__(always_apply, p)
self.radius = to_tuple(radius, low=1)
self.alias_blur = to_tuple(alias_blur, low=0)
if self.radius[0] <= 0:
raise ValueError("Parameter radius must be positive")
if self.alias_blur[0] < 0:
raise ValueError("Parameter alias_blur must be non-negative")
def apply(self, img: np.ndarray, radius: int = 3, alias_blur: float = 0.5, **params) -> np.ndarray:
return F.defocus(img, radius, alias_blur)
def get_params(self) -> Dict[str, Any]:
return {
"radius": random_utils.randint(self.radius[0], self.radius[1] + 1),
"alias_blur": random_utils.uniform(self.alias_blur[0], self.alias_blur[1]),
}
def get_transform_init_args_names(self) -> Tuple[str, str]:
return ("radius", "alias_blur")
radius参数变化:

alias_blur参数变化:

功能:通过先降采样再上采样来降低图像质量 。变换前后不改变图像尺寸。
参数:0 < scale_min <= scale_max < 1,表示图像缩放的倍率。等同于resize函数中的scale参数。
interpolation 可以指定缩放方法,默认最近邻方法:cv2.INTER_NEAREST。有三种指定方式,见下方source code中args说明。
# interpolation 参数举例:
# 方法一:表示下采样和上采样均使用NEAREST方法
interpolation = cv2.INTER_NEAREST
# 方法二:表示下采样使用最近邻差值,上采样使用双线性差值
interpolation = dict(downscale=cv2.INTER_NEAREST, upscale=cv2.INTER_LINEAR)
# 方法三:下采样使用AREA方法,上采样使用CUBIC方法
interpolation = Downscale.Interpolation(downscale=cv2.INTER_AREA, upscale=cv2.INTER_CUBIC)
interpolation 选项:
INTER_NEAREST最近邻插值
INTER_LINEAR双线性插值(默认设置)
INTER_AREA使用像素区域关系进行重采样。 它可能是图像下采样的首选方法,因为它会产生无云纹理的结果。
但是当图像上采样时,它类似于INTER_NEAREST方法。
INTER_CUBIC4×4像素邻域的双三次插值
INTER_LANCZOS48×8像素邻域的Lanczos插值
# source code
class Downscale(ImageOnlyTransform):
"""Decreases image quality by downscaling and upscaling back.
Args:
scale_min (float): lower bound on the image scale. Should be < 1.
scale_max (float): lower bound on the image scale. Should be .
interpolation: cv2 interpolation method. Could be:
- single cv2 interpolation flag - selected method will be used for downscale and upscale.
- dict(downscale=flag, upscale=flag)
- Downscale.Interpolation(downscale=flag, upscale=flag) -
Default: Interpolation(downscale=cv2.INTER_NEAREST, upscale=cv2.INTER_NEAREST)
Targets:
image
Image types:
uint8, float32
"""
class Interpolation:
def __init__(self, *, downscale: int = cv2.INTER_NEAREST, upscale: int = cv2.INTER_NEAREST):
self.downscale = downscale
self.upscale = upscale
def __init__(
self,
scale_min: float = 0.25,
scale_max: float = 0.25,
interpolation: Optional[Union[int, Interpolation, Dict[str, int]]] = None,
always_apply: bool = False,
p: float = 0.5,
):
super(Downscale, self).__init__(always_apply, p)
if interpolation is None:
self.interpolation = self.Interpolation(downscale=cv2.INTER_NEAREST, upscale=cv2.INTER_NEAREST)
warnings.warn(
"Using default interpolation INTER_NEAREST, which is sub-optimal."
"Please specify interpolation mode for downscale and upscale explicitly."
"For additional information see this PR https://github.com/albumentations-team/albumentations/pull/584"
)
elif isinstance(interpolation, int):
self.interpolation = self.Interpolation(downscale=interpolation, upscale=interpolation)
elif isinstance(interpolation, self.Interpolation):
self.interpolation = interpolation
elif isinstance(interpolation, dict):
self.interpolation = self.Interpolation(**interpolation)
else:
raise ValueError(
"Wrong interpolation data type. Supported types: `Optional[Union[int, Interpolation, Dict[str, int]]]`."
f" Got: {type(interpolation)}"
)
if scale_min > scale_max:
raise ValueError("Expected scale_min be less or equal scale_max, got {} {}".format(scale_min, scale_max))
if scale_max >= 1:
raise ValueError("Expected scale_max to be less than 1, got {}".format(scale_max))
self.scale_min = scale_min
self.scale_max = scale_max
def apply(self, img: np.ndarray, scale: Optional[float] = None, **params) -> np.ndarray:
return F.downscale(
img,
scale=scale,
down_interpolation=self.interpolation.downscale,
up_interpolation=self.interpolation.upscale,
)
def get_params(self) -> Dict[str, Any]:
return {"scale": random.uniform(self.scale_min, self.scale_max)}
def get_transform_init_args_names(self) -> Tuple[str, str]:
return "scale_min", "scale_max"
def _to_dict(self) -> Dict[str, Any]:
result = super()._to_dict()
result["interpolation"] = {"upscale": self.interpolation.upscale, "downscale": self.interpolation.downscale}
return result
为方便可视化,scale设置为0.1,以下是用三种方式初始化指定不同插值方法的结果图:

# demo code
import cv2
import matplotlib.pyplot as plt
import albumentations as A
if __name__ == "__main__":
filename = '0'
title_key = 'scale_method'
src_img = cv2.imread(f'imgs/{filename}.jpg')
dst_path = f'imgs/{filename}_aug.jpg'
transform1 = A.Downscale(scale_min=0.1,
scale_max=0.1,
interpolation=cv2.INTER_NEAREST,
p=1)
transform2 = A.Downscale(scale_min=0.1,
scale_max=0.1,
interpolation=dict(downscale=cv2.INTER_LINEAR,
upscale=cv2.INTER_LINEAR),
p=1)
transform3 = A.Downscale(scale_min=0.1,
scale_max=0.1,
interpolation=A.Downscale.Interpolation(
downscale=cv2.INTER_AREA,
upscale=cv2.INTER_AREA),
p=1)
img_aug1 = transform1(image=src_img)['image']
img_aug2 = transform2(image=src_img)['image']
img_aug3 = transform3(image=src_img)['image']
param1 = 'INTER_NEAREST'
param2 = 'INTER_LINEAR'
param3 = 'INTER_AREA'
fontsize = 10
plt.subplot(221)
plt.axis('off')
plt.title('src', fontdict={'fontsize': fontsize})
plt.imshow(src_img[:, :, ::-1])
plt.subplot(222)
plt.axis('off')
plt.title(f'{title_key}={param1}', fontdict={'fontsize': fontsize})
plt.imshow(img_aug1[:, :, ::-1])
plt.subplot(223)
plt.axis('off')
plt.title(f'{title_key}={param2}', fontdict={'fontsize': fontsize})
plt.imshow(img_aug2[:, :, ::-1])
plt.subplot(224)
plt.axis('off')
plt.title(f'{title_key}={param3}', fontdict={'fontsize': fontsize})
plt.imshow(img_aug3[:, :, ::-1])
plt.savefig(dst_path)
功能:叠加浮雕效果
参数说明:
alpha ((float, float)): 调整浮雕图像的可见性,为0时只保留原图,为1.0时只保留浮雕图像。
result = (1 - alpha) * src_image + alpha * emboss_image
strength ((float, float)): 浮雕强度
alpha参数比strength参数影响大。
# source code
class Emboss(ImageOnlyTransform):
"""Emboss the input image and overlays the result with the original image.
Args:
alpha ((float, float)): range to choose the visibility of the embossed image. At 0, only the original image is
visible,at 1.0 only its embossed version is visible. Default: (0.2, 0.5).
strength ((float, float)): strength range of the embossing. Default: (0.2, 0.7).
p (float): probability of applying the transform. Default: 0.5.
Targets:
image
"""
def __init__(self, alpha=(0.2, 0.5), strength=(0.2, 0.7), always_apply=False, p=0.5):
super(Emboss, self).__init__(always_apply, p)
self.alpha = self.__check_values(to_tuple(alpha, 0.0), name="alpha", bounds=(0.0, 1.0))
self.strength = self.__check_values(to_tuple(strength, 0.0), name="strength")
@staticmethod
def __check_values(value, name, bounds=(0, float("inf"))):
if not bounds[0] <= value[0] <= value[1] <= bounds[1]:
raise ValueError("{} values should be between {}".format(name, bounds))
return value
@staticmethod
def __generate_emboss_matrix(alpha_sample, strength_sample):
matrix_nochange = np.array([[0, 0, 0], [0, 1, 0], [0, 0, 0]], dtype=np.float32)
matrix_effect = np.array(
[
[-1 - strength_sample, 0 - strength_sample, 0],
[0 - strength_sample, 1, 0 + strength_sample],
[0, 0 + strength_sample, 1 + strength_sample],
],
dtype=np.float32,
)
matrix = (1 - alpha_sample) * matrix_nochange + alpha_sample * matrix_effect
return matrix
def get_params(self):
alpha = random.uniform(*self.alpha)
strength = random.uniform(*self.strength)
emboss_matrix = self.__generate_emboss_matrix(alpha_sample=alpha, strength_sample=strength)
return {"emboss_matrix": emboss_matrix}
def apply(self, img, emboss_matrix=None, **params):
return F.convolve(img, emboss_matrix) # 卷积
def get_transform_init_args_names(self):
return ("alpha", "strength")
以下是对比可视化结果,alpha参数效果比strength参数效果明显。

功能:直方图均衡化
参数说明: mode (str): {‘cv’, ‘pil’}. 选择使用 OpenCV 或 Pillow 均衡方法。
by_channels (bool): 若为True,表示每个通道单独做直方图均衡;若为False,表示将图像转为YCbCr格式然后对Y通道进行直方图均衡。默认值:True
mask (np.ndarray, callable): 若提供该参数,表示仅mask覆盖范围内进行变换。
mask_params (list of str): Params for mask function.
注意:by_channels 设为False效果更自然些,色相色调差异更小。
# source code
class Equalize(ImageOnlyTransform):
"""Equalize the image histogram.
Args:
mode (str): {'cv', 'pil'}. Use OpenCV or Pillow equalization method.
by_channels (bool): If True, use equalization by channels separately,
else convert image to YCbCr representation and use equalization by `Y` channel.
mask (np.ndarray, callable): If given, only the pixels selected by
the mask are included in the analysis. Maybe 1 channel or 3 channel array or callable.
Function signature must include `image` argument.
mask_params (list of str): Params for mask function.
Targets:
image
Image types:
uint8
"""
def __init__(
self,
mode="cv",
by_channels=True,
mask=None,
mask_params=(),
always_apply=False,
p=0.5,
):
modes = ["cv", "pil"]
if mode not in modes:
raise ValueError("Unsupported equalization mode. Supports: {}. "
"Got: {}".format(modes, mode))
super(Equalize, self).__init__(always_apply, p)
self.mode = mode
self.by_channels = by_channels
self.mask = mask
self.mask_params = mask_params
def apply(self, image, mask=None, **params):
return F.equalize(image,
mode=self.mode,
by_channels=self.by_channels,
mask=mask)
def get_params_dependent_on_targets(self, params):
if not callable(self.mask):
return {"mask": self.mask}
return {"mask": self.mask(**params)}
@property
def targets_as_params(self):
return ["image"] + list(self.mask_params)
def get_transform_init_args_names(self):
return ("mode", "by_channels")



功能:傅里叶域自适应(Fourier Domain Adaptation from https://github.com/YanchaoYang/FDA),实现简单的风格迁移
参数说明:
reference_images (List[str] or List(np.ndarray)): 参考图像列表或者图像路径列表。若提供多个参考图像(列表长度大于1),将从中随机选择一张图像风格进行变换。
beta_limit (float or tuple of float): 论文中的系数,建议小于0.3,默认值为0.1。
read_fn (Callable): 读图的可调用函数,返回numpy array格式。默认值为read_rgb_image。
# 默认读图函数,对应的reference_images参数应为路径列表:
def read_rgb_image(path):
image = cv2.imread(path, cv2.IMREAD_COLOR)
return cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 若参考图像已经是numpy array格式,read_fn函数恒等读入即可(lambda x: x):
target_image = np.random.randint(0, 256, [100, 100, 3], dtype=np.uint8)
aug = A.FDA([target_image], read_fn=lambda x: x)

class FDA(ImageOnlyTransform):
"""
Fourier Domain Adaptation from https://github.com/YanchaoYang/FDA
Simple "style transfer".
Args:
reference_images (List[str] or List(np.ndarray)): List of file paths for reference images
or list of reference images.
beta_limit (float or tuple of float): coefficient beta from paper. Recommended less 0.3.
read_fn (Callable): Used-defined function to read image. Function should get image path and return numpy
array of image pixels.
Targets:
image
Image types:
uint8, float32
Reference:
https://github.com/YanchaoYang/FDA
https://openaccess.thecvf.com/content_CVPR_2020/papers/Yang_FDA_Fourier_Domain_Adaptation_for_Semantic_Segmentation_CVPR_2020_paper.pdf
Example:
>>> import numpy as np
>>> import albumentations as A
>>> image = np.random.randint(0, 256, [100, 100, 3], dtype=np.uint8)
>>> target_image = np.random.randint(0, 256, [100, 100, 3], dtype=np.uint8)
>>> aug = A.Compose([A.FDA([target_image], p=1, read_fn=lambda x: x)])
>>> result = aug(image=image)
"""
def __init__(
self,
reference_images: List[Union[str, np.ndarray]],
beta_limit=0.1,
read_fn=read_rgb_image,
always_apply=False,
p=0.5,
):
super(FDA, self).__init__(always_apply=always_apply, p=p)
self.reference_images = reference_images
self.read_fn = read_fn
self.beta_limit = to_tuple(beta_limit, low=0)
def apply(self, img, target_image=None, beta=0.1, **params):
return fourier_domain_adaptation(img=img, target_img=target_image, beta=beta)
def get_params_dependent_on_targets(self, params):
img = params["image"]
target_img = self.read_fn(random.choice(self.reference_images))
target_img = cv2.resize(target_img, dsize=(img.shape[1], img.shape[0]))
return {"target_image": target_img}
def get_params(self):
return {"beta": random.uniform(self.beta_limit[0], self.beta_limit[1])}
@property
def targets_as_params(self):
return ["image"]
def get_transform_init_args_names(self):
return ("reference_images", "beta_limit", "read_fn")
def _to_dict(self):
raise NotImplementedError("FDA can not be serialized.")
用已有图像跑的结果( beta_limit=0.1 ):

官方工程中的结果:

功能: RGB图像通过FancyPCA色彩增强。FancyPCA的色彩失真更小。
参数说明:
alpha (float): 影响特征值和特征向量的扰动程度。
class FancyPCA(ImageOnlyTransform):
"""Augment RGB image using FancyPCA from Krizhevsky's paper
"ImageNet Classification with Deep Convolutional Neural Networks"
Args:
alpha (float): how much to perturb/scale the eigen vecs and vals.
scale is samples from gaussian distribution (mu=0, sigma=alpha)
Targets:
image
Image types:
3-channel uint8 images only
Credit:
http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
https://deshanadesai.github.io/notes/Fancy-PCA-with-Scikit-Image
https://pixelatedbrian.github.io/2018-04-29-fancy_pca/
"""
def __init__(self, alpha=0.1, always_apply=False, p=0.5):
super(FancyPCA, self).__init__(always_apply=always_apply, p=p)
self.alpha = alpha
def apply(self, img, alpha=0.1, **params):
img = F.fancy_pca(img, alpha)
return img
def get_params(self):
return {"alpha": random.gauss(0, self.alpha)}
def get_transform_init_args_names(self):
return ("alpha", )

附官方网站的可视化结果:https://pixelatedbrian.github.io/2018-04-29-fancy_pca/
以下是三种场景变换结果,中间一列是FancyPCA结果,色彩失真度很小。

功能:像素值乘以最大值,将图像由浮点型变为整型。
相反的函数为ToFloat,除以最大值,由整型变为浮点型([0, 1.0])
# source code
class FromFloat(ImageOnlyTransform):
"""Take an input array where all values should lie in the range [0, 1.0], multiply them by `max_value` and then
cast the resulted value to a type specified by `dtype`. If `max_value` is None the transform will try to infer
the maximum value for the data type from the `dtype` argument.
This is the inverse transform for :class:`~albumentations.augmentations.transforms.ToFloat`.
Args:
max_value (float): maximum possible input value. Default: None.
dtype (string or numpy data type): data type of the output. See the `'Data types' page from the NumPy docs`_.
Default: 'uint16'.
p (float): probability of applying the transform. Default: 1.0.
Targets:
image
Image types:
float32
.. _'Data types' page from the NumPy docs:
https://docs.scipy.org/doc/numpy/user/basics.types.html
"""
def __init__(self, dtype="uint16", max_value=None, always_apply=False, p=1.0):
super(FromFloat, self).__init__(always_apply, p)
self.dtype = np.dtype(dtype)
self.max_value = max_value
def apply(self, img, **params):
return F.from_float(img, self.dtype, self.max_value)
def get_transform_init_args(self):
return {"dtype": self.dtype.name, "max_value": self.max_value}
# F.from_float()
def from_float(img, dtype, max_value=None):
if max_value is None:
try:
max_value = MAX_VALUES_BY_DTYPE[dtype]
except KeyError:
raise RuntimeError(
"Can't infer the maximum value for dtype {}. You need to specify the maximum value manually by "
"passing the max_value argument".format(dtype)
)
return (img * max_value).astype(dtype)
# MAX_VALUES_BY_DTYPE = {
# np.dtype("uint8"): 255,
# np.dtype("uint16"): 65535,
# np.dtype("uint32"): 4294967295,
# np.dtype("float32"): 1.0,
# }
功能: 加高斯噪声
参数说明:
var_limit ((float, float) or float): 噪声方差范围. 若为单个float数值,将转换为区间范围 (0, var_limit). 默认值: (10.0, 50.0).
mean (float): 噪声均值. 默认值: 0
per_channel (bool): 每个通道是否独立采样。默认值: True
# source code
class GaussNoise(ImageOnlyTransform):
"""Apply gaussian noise to the input image.
Args:
var_limit ((float, float) or float): variance range for noise. If var_limit is a single float, the range
will be (0, var_limit). Default: (10.0, 50.0).
mean (float): mean of the noise. Default: 0
per_channel (bool): if set to True, noise will be sampled for each channel independently.
Otherwise, the noise will be sampled once for all channels. Default: True
p (float): probability of applying the transform. Default: 0.5.
Targets:
image
Image types:
uint8, float32
"""
def __init__(self, var_limit=(10.0, 50.0), mean=0, per_channel=True, always_apply=False, p=0.5):
super(GaussNoise, self).__init__(always_apply, p)
if isinstance(var_limit, (tuple, list)):
if var_limit[0] < 0:
raise ValueError("Lower var_limit should be non negative.")
if var_limit[1] < 0:
raise ValueError("Upper var_limit should be non negative.")
self.var_limit = var_limit
elif isinstance(var_limit, (int, float)):
if var_limit < 0:
raise ValueError("var_limit should be non negative.")
self.var_limit = (0, var_limit)
else:
raise TypeError(
"Expected var_limit type to be one of (int, float, tuple, list), got {}".format(type(var_limit))
)
self.mean = mean
self.per_channel = per_channel
def apply(self, img, gauss=None, **params):
return F.gauss_noise(img, gauss=gauss)
def get_params_dependent_on_targets(self, params):
image = params["image"]
var = random.uniform(self.var_limit[0], self.var_limit[1])
sigma = var ** 0.5
random_state = np.random.RandomState(random.randint(0, 2 ** 32 - 1))
if self.per_channel:
gauss = random_state.normal(self.mean, sigma, image.shape)
else:
gauss = random_state.normal(self.mean, sigma, image.shape[:2])
if len(image.shape) == 3:
gauss = np.expand_dims(gauss, -1)
return {"gauss": gauss}
@property
def targets_as_params(self):
return ["image"]
def get_transform_init_args_names(self):
return ("var_limit", "per_channel", "mean")
var_limit值越大,噪声越明显。

功能:
# source code
功能:
# source code
功能:直方图匹配。调整输入图像的像素值,使其直方图匹配参考图像的直方图。每个通道独立进行,要求输入图与参考图通道数一致 。
直方图匹配可以作为图像处理(例如特征匹配)的轻量级归一化,尤其是图像的来源或条件不同时(例如照明)。
参数说明:(参数与FDA变换参数类似,FDA 中p=0.5,HistogramMatching中默认p=1)
-
reference_images (List[str] or List(np.ndarray)): 参考图像列表或者图像路径列表。若提供多个参考图像(列表长度大于1),将从中随机选择一张图像风格进行变换。
-
blend_ratio (float, float): 原图与变换图像加权叠加的加权因子。
blend_ratio_sample是直方图匹配图像的权重因子,原图权重因子是1 - blend_ratio_sample。img = cv2.addWeighted( matched, blend_ratio, img, 1 - blend_ratio, 0, dtype=get_opencv_dtype_from_numpy(img.dtype), ) -
read_fn (Callable): 读图的可调用函数,返回numpy array格式。默认值为read_rgb_image。
# 默认读图函数,对应的reference_images参数应为路径列表:
def read_rgb_image(path):
image = cv2.imread(path, cv2.IMREAD_COLOR)
return cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 若参考图像已经是numpy array格式,read_fn函数恒等读入即可(lambda x: x):
target_image = np.random.randint(0, 256, [100, 100, 3], dtype=np.uint8)
aug = A.HistogramMatching([target_image], read_fn=lambda x: x)
# source code
class HistogramMatching(ImageOnlyTransform):
"""
Apply histogram matching. It manipulates the pixels of an input image so that its histogram matches
the histogram of the reference image. If the images have multiple channels, the matching is done independently
for each channel, as long as the number of channels is equal in the input image and the reference.
Histogram matching can be used as a lightweight normalisation for image processing,
such as feature matching, especially in circumstances where the images have been taken from different
sources or in different conditions (i.e. lighting).
See:
https://scikit-image.org/docs/dev/auto_examples/color_exposure/plot_histogram_matching.html
Args:
reference_images (List[str] or List(np.ndarray)): List of file paths for reference images
or list of reference images.
blend_ratio (float, float): Tuple of min and max blend ratio. Matched image will be blended with original
with random blend factor for increased diversity of generated images.
read_fn (Callable): Used-defined function to read image. Function should get image path and return numpy
array of image pixels.
p (float): probability of applying the transform. Default: 1.0.
Targets:
image
Image types:
uint8, uint16, float32
"""
def __init__(
self,
reference_images: List[Union[str, np.ndarray]],
blend_ratio=(0.5, 1.0),
read_fn=read_rgb_image,
always_apply=False,
p=0.5,
):
super().__init__(always_apply=always_apply, p=p)
self.reference_images = reference_images
self.read_fn = read_fn
self.blend_ratio = blend_ratio
def apply(self, img, reference_image=None, blend_ratio=0.5, **params):
return apply_histogram(img, reference_image, blend_ratio)
def get_params(self):
return {
"reference_image": self.read_fn(random.choice(self.reference_images)),
"blend_ratio": random.uniform(self.blend_ratio[0], self.blend_ratio[1]),
}
def get_transform_init_args_names(self):
return ("reference_images", "blend_ratio", "read_fn")
def _to_dict(self):
raise NotImplementedError("HistogramMatching can not be serialized.")
可以看到中间图作为target之后,变换后的图像也偏绿色了。

下图来源:https://scikit-image.org/docs/dev/auto_examples/color_exposure/plot_histogram_matching.html

功能:随机改变图像的色调,饱和度,亮度。
参数说明: hue_shift_limit ,sat_shift_limit ,val_shift_limit 分别表示色调、饱和度、亮度变化范围。若输入是单个数字,将转化为区间( -input_val, input_val),在此区间内随机取值。
若任务对色彩敏感的话,色相hue_shift_limit 范围要小一点。
# source code
class HueSaturationValue(ImageOnlyTransform):
"""Randomly change hue, saturation and value of the input image.
Args:
hue_shift_limit ((int, int) or int): range for changing hue. If hue_shift_limit is a single int, the range
will be (-hue_shift_limit, hue_shift_limit). Default: (-20, 20).
sat_shift_limit ((int, int) or int): range for changing saturation. If sat_shift_limit is a single int,
the range will be (-sat_shift_limit, sat_shift_limit). Default: (-30, 30).
val_shift_limit ((int, int) or int): range for changing value. If val_shift_limit is a single int, the range
will be (-val_shift_limit, val_shift_limit). Default: (-20, 20).
p (float): probability of applying the transform. Default: 0.5.
Targets:
image
Image types:
uint8, float32
"""
def __init__(
self,
hue_shift_limit=20,
sat_shift_limit=30,
val_shift_limit=20,
always_apply=False,
p=0.5,
):
super(HueSaturationValue, self).__init__(always_apply, p)
self.hue_shift_limit = to_tuple(hue_shift_limit)
self.sat_shift_limit = to_tuple(sat_shift_limit)
self.val_shift_limit = to_tuple(val_shift_limit)
def apply(self, image, hue_shift=0, sat_shift=0, val_shift=0, **params):
if not is_rgb_image(image) and not is_grayscale_image(image):
raise TypeError(
"HueSaturationValue transformation expects 1-channel or 3-channel images."
)
return F.shift_hsv(image, hue_shift, sat_shift, val_shift)
def get_params(self):
return {
"hue_shift":
random.uniform(self.hue_shift_limit[0], self.hue_shift_limit[1]),
"sat_shift":
random.uniform(self.sat_shift_limit[0], self.sat_shift_limit[1]),
"val_shift":
random.uniform(self.val_shift_limit[0], self.val_shift_limit[1]),
}
def get_transform_init_args_names(self):
return ("hue_shift_limit", "sat_shift_limit", "val_shift_limit")



功能:加相机传感器噪声。
参数说明: color_shift (float, float): 色调hue变化范围。
intensity ((float, float): 控制颜色强度和亮度噪声的乘数因子。
# source code
class ISONoise(ImageOnlyTransform):
"""
Apply camera sensor noise.
Args:
color_shift (float, float): variance range for color hue change.
Measured as a fraction of 360 degree Hue angle in HLS colorspace.
intensity ((float, float): Multiplicative factor that control strength
of color and luminace noise.
p (float): probability of applying the transform. Default: 0.5.
Targets:
image
Image types:
uint8
"""
def __init__(self,
color_shift=(0.01, 0.05),
intensity=(0.1, 0.5),
always_apply=False,
p=0.5):
super(ISONoise, self).__init__(always_apply, p)
self.intensity = intensity
self.color_shift = color_shift
def apply(self,
img,
color_shift=0.05,
intensity=1.0,
random_state=None,
**params):
return F.iso_noise(img, color_shift, intensity,
np.random.RandomState(random_state))
def get_params(self):
return {
"color_shift": random.uniform(self.color_shift[0],
self.color_shift[1]),
"intensity": random.uniform(self.intensity[0], self.intensity[1]),
"random_state": random.randint(0, 65536),
}
def get_transform_init_args_names(self):
return ("intensity", "color_shift")
为了可视化明显,参数设置较大。
输入参数为区间,所以图中color_shift=0.02表示调用时color_shift=(0.02, 0.02)。


JpegCompression已弃用,功能同ImageCompression。
功能:jpg和webp格式图像压缩
参数说明: quality_lower (float): 图像最低质量. jpg in [0, 100],webp in [1, 100].
quality_upper (float): 图像最高质量. jpg in [0, 100],webp in [1, 100].
compression_type (ImageCompressionType): 压缩类型,内置两个选项: ImageCompressionType.JPEG or ImageCompressionType.WEBP. 默认类型: ImageCompressionType.JPEG
压缩前后分辨率不会变化。
# source code
class ImageCompression(ImageOnlyTransform):
"""Decrease Jpeg, WebP compression of an image.
Args:
quality_lower (float): lower bound on the image quality.
Should be in [0, 100] range for jpeg and [1, 100] for webp.
quality_upper (float): upper bound on the image quality.
Should be in [0, 100] range for jpeg and [1, 100] for webp.
compression_type (ImageCompressionType): should be ImageCompressionType.JPEG or ImageCompressionType.WEBP.
Default: ImageCompressionType.JPEG
Targets:
image
Image types:
uint8, float32
"""
class ImageCompressionType(IntEnum):
JPEG = 0
WEBP = 1
def __init__(
self,
quality_lower=99,
quality_upper=100,
compression_type=ImageCompressionType.JPEG,
always_apply=False,
p=0.5,
):
super(ImageCompression, self).__init__(always_apply, p)
self.compression_type = ImageCompression.ImageCompressionType(
compression_type)
low_thresh_quality_assert = 0
if self.compression_type == ImageCompression.ImageCompressionType.WEBP:
low_thresh_quality_assert = 1
if not low_thresh_quality_assert <= quality_lower <= 100:
raise ValueError(
"Invalid quality_lower. Got: {}".format(quality_lower))
if not low_thresh_quality_assert <= quality_upper <= 100:
raise ValueError(
"Invalid quality_upper. Got: {}".format(quality_upper))
self.quality_lower = quality_lower
self.quality_upper = quality_upper
def apply(self, image, quality=100, image_type=".jpg", **params):
if not image.ndim == 2 and image.shape[-1] not in (1, 3, 4):
raise TypeError(
"ImageCompression transformation expects 1, 3 or 4 channel images."
)
return F.image_compression(image, quality, image_type)
def get_params(self):
image_type = ".jpg"
if self.compression_type == ImageCompression.ImageCompressionType.WEBP:
image_type = ".webp"
return {
"quality": random.randint(self.quality_lower, self.quality_upper),
"image_type": image_type,
}
def get_transform_init_args(self):
return {
"quality_lower": self.quality_lower,
"quality_upper": self.quality_upper,
"compression_type": self.compression_type.value,
}
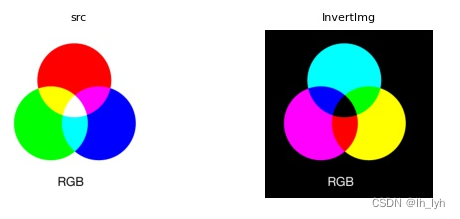
功能:255 – 像素值
# F.invert(img)
def invert(img):
return 255 - img
功能:
# source code
功能:
# source code
功能:将图像乘以一个随机数或数组。
参数说明: multiplier (float or tuple of floats):图像要乘的数。若输入是区间,乘数因子将在区间[multiplier[0], multiplier[1])内随机采样。 Default: (0.9, 1.1).
per_channel (bool): 是否对每个通道单独操作。若为True,每个通道乘数因子均不同。 Default False.
elementwise (bool): 是否是像素级别操作,若为True,每个像素的乘性因子均随机生成。Default False.
# source code
class MultiplicativeNoise(ImageOnlyTransform):
"""Multiply image to random number or array of numbers.
Args:
multiplier (float or tuple of floats): If single float image will be multiplied to this number.
If tuple of float multiplier will be in range `[multiplier[0], multiplier[1])`. Default: (0.9, 1.1).
per_channel (bool): If `False`, same values for all channels will be used.
If `True` use sample values for each channels. Default False.
elementwise (bool): If `False` multiply multiply all pixels in an image with a random value sampled once.
If `True` Multiply image pixels with values that are pixelwise randomly sampled. Defaule: False.
Targets:
image
Image types:
Any
"""
def __init__(
self,
multiplier=(0.9, 1.1),
per_channel=False,
elementwise=False,
always_apply=False,
p=0.5,
):
super(MultiplicativeNoise, self).__init__(always_apply, p)
self.multiplier = to_tuple(multiplier, multiplier)
self.per_channel = per_channel
self.elementwise = elementwise
def apply(self, img, multiplier=np.array([1]), **kwargs):
return F.multiply(img, multiplier)
def get_params_dependent_on_targets(self, params):
if self.multiplier[0] == self.multiplier[1]:
return {"multiplier": np.array([self.multiplier[0]])}
img = params["image"]
h, w = img.shape[:2]
if self.per_channel:
c = 1 if F.is_grayscale_image(img) else img.shape[-1]
else:
c = 1
if self.elementwise:
shape = [h, w, c]
else:
shape = [c]
multiplier = np.random.uniform(self.multiplier[0], self.multiplier[1], shape)
if F.is_grayscale_image(img) and img.ndim == 2:
multiplier = np.squeeze(multiplier)
return {"multiplier": multiplier}
@property
def targets_as_params(self):
return ["image"]
def get_transform_init_args_names(self):
return "multiplier", "per_channel", "elementwise"
elementwise =True时噪点较多,因为每个像素独立。

功能:图像归一化
归一化公式:img = (img – mean * max_pixel_value) / (std * max_pixel_value)
等同于:img = (img / max_pixel_value – mean) / std
默认参数:
mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225),
max_pixel_value=255.0
class Normalize(ImageOnlyTransform):
"""Normalization is applied by the formula: `img = (img - mean * max_pixel_value) / (std * max_pixel_value)`
Args:
mean (float, list of float): mean values
std (float, list of float): std values
max_pixel_value (float): maximum possible pixel value
Targets:
image
Image types:
uint8, float32
"""
def __init__(
self,
mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225),
max_pixel_value=255.0,
always_apply=False,
p=1.0,
):
super(Normalize, self).__init__(always_apply, p)
self.mean = mean
self.std = std
self.max_pixel_value = max_pixel_value
def apply(self, image, **params):
return F.normalize(image, self.mean, self.std, self.max_pixel_value)
def get_transform_init_args_names(self):
return ("mean", "std", "max_pixel_value")
功能:
# source code
功能:减少每个颜色通道的位数,达到色调分层。所以参数num_bits有效范围[0, 8]。
参数: num_bits ((int, int) or int, or list of ints [r, g, b], or list of ints [[r1, r1], [g1, g2], [b1, b2]]): number of high bits.
num_bits 数字越小,色调分层越明显。有效值范围:[0, 8],默认值:4。
# source code
class Posterize(ImageOnlyTransform):
"""Reduce the number of bits for each color channel.
Args:
num_bits ((int, int) or int,
or list of ints [r, g, b],
or list of ints [[r1, r1], [g1, g2], [b1, b2]]): number of high bits.
If num_bits is a single value, the range will be [num_bits, num_bits].
Must be in range [0, 8]. Default: 4.
p (float): probability of applying the transform. Default: 0.5.
Targets:
image
Image types:
uint8
"""
def __init__(self, num_bits=4, always_apply=False, p=0.5):
super(Posterize, self).__init__(always_apply, p)
if isinstance(num_bits, (list, tuple)):
if len(num_bits) == 3:
self.num_bits = [to_tuple(i, 0) for i in num_bits]
else:
self.num_bits = to_tuple(num_bits, 0)
else:
self.num_bits = to_tuple(num_bits, num_bits)
def apply(self, image, num_bits=1, **params):
return F.posterize(image, num_bits)
def get_params(self):
if len(self.num_bits) == 3:
return {
"num_bits":
[random.randint(i[0], i[1]) for i in self.num_bits]
}
return {"num_bits": random.randint(self.num_bits[0], self.num_bits[1])}
def get_transform_init_args_names(self):
return ("num_bits", )


功能:RGB每个通道上值偏移
参数说明: r_shift_limit ,g_shift_limit ,b_shift_limit ((int, int) or int) 分别表示R、G、B通道上的值偏移,若输入为单个数字,将转化为区间(-shift_limit, shift_limit),最终应用的值在区间内随机采样获取。
# source code
class RGBShift(ImageOnlyTransform):
"""Randomly shift values for each channel of the input RGB image.
Args:
r_shift_limit ((int, int) or int): range for changing values for the red channel. If r_shift_limit is a single
int, the range will be (-r_shift_limit, r_shift_limit). Default: (-20, 20).
g_shift_limit ((int, int) or int): range for changing values for the green channel. If g_shift_limit is a
single int, the range will be (-g_shift_limit, g_shift_limit). Default: (-20, 20).
b_shift_limit ((int, int) or int): range for changing values for the blue channel. If b_shift_limit is a single
int, the range will be (-b_shift_limit, b_shift_limit). Default: (-20, 20).
p (float): probability of applying the transform. Default: 0.5.
Targets:
image
Image types:
uint8, float32
"""
def __init__(
self,
r_shift_limit=20,
g_shift_limit=20,
b_shift_limit=20,
always_apply=False,
p=0.5,
):
super(RGBShift, self).__init__(always_apply, p)
self.r_shift_limit = to_tuple(r_shift_limit)
self.g_shift_limit = to_tuple(g_shift_limit)
self.b_shift_limit = to_tuple(b_shift_limit)
def apply(self, image, r_shift=0, g_shift=0, b_shift=0, **params):
if not F.is_rgb_image(image):
raise TypeError("RGBShift transformation expects 3-channel images.")
return F.shift_rgb(image, r_shift, g_shift, b_shift)
def get_params(self):
return {
"r_shift": random.uniform(self.r_shift_limit[0], self.r_shift_limit[1]),
"g_shift": random.uniform(self.g_shift_limit[0], self.g_shift_limit[1]),
"b_shift": random.uniform(self.b_shift_limit[0], self.b_shift_limit[1]),
}
def get_transform_init_args_names(self):
return ("r_shift_limit", "g_shift_limit", "b_shift_limit")
# F.shift_rgb,对于逐像素应用统一计算公式可使用查找表方式(cv2.LUT,look up table)
def _shift_image_uint8(img, value):
max_value = MAX_VALUES_BY_DTYPE[img.dtype]
lut = np.arange(0, max_value + 1).astype("float32")
lut += value
lut = np.clip(lut, 0, max_value).astype(img.dtype)
return cv2.LUT(img, lut)
@preserve_shape
def _shift_rgb_uint8(img, r_shift, g_shift, b_shift):
if r_shift == g_shift == b_shift:
h, w, c = img.shape
img = img.reshape([h, w * c])
return _shift_image_uint8(img, r_shift)
result_img = np.empty_like(img)
shifts = [r_shift, g_shift, b_shift]
for i, shift in enumerate(shifts):
result_img[..., i] = _shift_image_uint8(img[..., i], shift)
return result_img
def shift_rgb(img, r_shift, g_shift, b_shift):
if img.dtype == np.uint8:
return _shift_rgb_uint8(img, r_shift, g_shift, b_shift)
return _shift_rgb_non_uint8(img, r_shift, g_shift, b_shift)

功能:随机改变输入图像的亮度、对比度。相似变换:ColorJitter
参数说明:
- brightness_limit ((float, float) or float): 亮度变化因子,若输入为单个数字,将转化为区间
(-limit, limit),默认值:(-0.2, 0.2) - contrast_limit ((float, float) or float): 对比度变化因子,若输入为单个数字,将转化为区间
(-limit, limit),默认值:(-0.2, 0.2) - brightness_by_max (Boolean): 若为 True表示通过图像 dtype 最大值调整对比度,若为False表示通过图像平均值调整对比度。默认值:True
# source code
class RandomBrightnessContrast(ImageOnlyTransform):
"""Randomly change brightness and contrast of the input image.
Args:
brightness_limit ((float, float) or float): factor range for changing brightness.
If limit is a single float, the range will be (-limit, limit). Default: (-0.2, 0.2).
contrast_limit ((float, float) or float): factor range for changing contrast.
If limit is a single float, the range will be (-limit, limit). Default: (-0.2, 0.2).
brightness_by_max (Boolean): If True adjust contrast by image dtype maximum,
else adjust contrast by image mean.
p (float): probability of applying the transform. Default: 0.5.
Targets:
image
Image types:
uint8, float32
"""
def __init__(
self,
brightness_limit=0.2,
contrast_limit=0.2,
brightness_by_max=True,
always_apply=False,
p=0.5,
):
super(RandomBrightnessContrast, self).__init__(always_apply, p)
self.brightness_limit = to_tuple(brightness_limit)
self.contrast_limit = to_tuple(contrast_limit)
self.brightness_by_max = brightness_by_max
def apply(self, img, alpha=1.0, beta=0.0, **params):
return F.brightness_contrast_adjust(img, alpha, beta,
self.brightness_by_max)
def get_params(self):
return {
"alpha":
1.0 +
random.uniform(self.contrast_limit[0], self.contrast_limit[1]),
"beta":
0.0 +
random.uniform(self.brightness_limit[0], self.brightness_limit[1]),
}
def get_transform_init_args_names(self):
return ("brightness_limit", "contrast_limit", "brightness_by_max")
亮度变化(contrast_limit=(0.1, 0.1), brightness_by_max=True):

对比度变化(brightness_limit=(0.01, 0.01), brightness_by_max=True):

brightness_by_max变化:
brightness_limit=(0.1, 0.1), contrast_limit=(0.1, 0.1)

brightness_limit=(-0.1, -0.1), contrast_limit=(-0.1, -0.1)

功能:给输入图像添加雾的效果
参数说明: 所有参数为float型,有效区间为 [0, 1] 。
fog_coef_lower、fog_coef_upper:雾强度系数的最小最大值,最终应用的强度参数在这范围内采样获取。默认范围:[0.3, 1]
alpha_coef : 雾圈的透明度。默认值:0.08
# source code
class RandomFog(ImageOnlyTransform):
"""Simulates fog for the image
From https://github.com/UjjwalSaxena/Automold--Road-Augmentation-Library
Args:
fog_coef_lower (float): lower limit for fog intensity coefficient. Should be in [0, 1] range.
fog_coef_upper (float): upper limit for fog intensity coefficient. Should be in [0, 1] range.
alpha_coef (float): transparency of the fog circles. Should be in [0, 1] range.
Targets:
image
Image types:
uint8, float32
"""
def __init__(
self,
fog_coef_lower=0.3,
fog_coef_upper=1,
alpha_coef=0.08,
always_apply=False,
p=0.5,
):
super(RandomFog, self).__init__(always_apply, p)
if not 0 <= fog_coef_lower <= fog_coef_upper <= 1:
raise ValueError(
"Invalid combination if fog_coef_lower and fog_coef_upper. Got: {}"
.format((fog_coef_lower, fog_coef_upper)))
if not 0 <= alpha_coef <= 1:
raise ValueError(
"alpha_coef must be in range [0, 1]. Got: {}".format(
alpha_coef))
self.fog_coef_lower = fog_coef_lower
self.fog_coef_upper = fog_coef_upper
self.alpha_coef = alpha_coef
def apply(self, image, fog_coef=0.1, haze_list=(), **params):
return F.add_fog(image, fog_coef, self.alpha_coef, haze_list)
@property
def targets_as_params(self):
return ["image"]
def get_params_dependent_on_targets(self, params):
img = params["image"]
fog_coef = random.uniform(self.fog_coef_lower, self.fog_coef_upper)
height, width = imshape = img.shape[:2]
hw = max(1, int(width // 3 * fog_coef))
haze_list = []
midx = width // 2 - 2 * hw
midy = height // 2 - hw
index = 1
while midx > -hw or midy > -hw:
for _i in range(hw // 10 * index):
x = random.randint(midx, width - midx - hw)
y = random.randint(midy, height - midy - hw)
haze_list.append((x, y))
midx -= 3 * hw * width // sum(imshape)
midy -= 3 * hw * height // sum(imshape)
index += 1
return {"haze_list": haze_list, "fog_coef": fog_coef}
def get_transform_init_args_names(self):
return ("fog_coef_lower", "fog_coef_upper", "alpha_coef")

图像增强——伽马变换
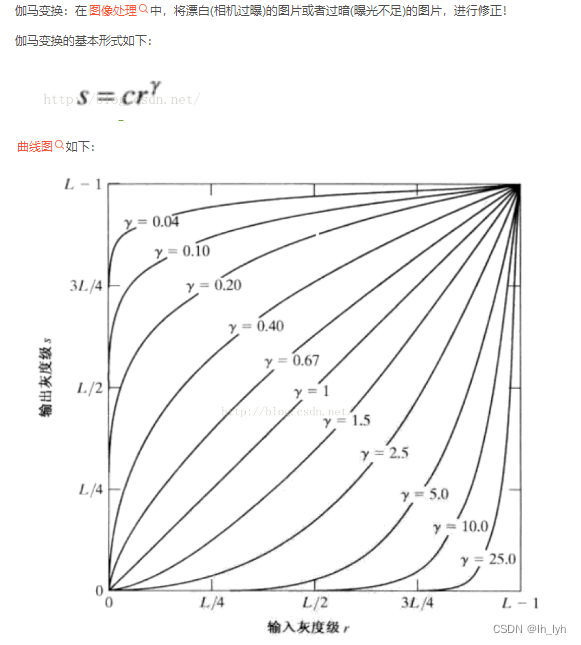
gamma<1时,整体提亮
gamma>1时,整体变暗
# source code
class RandomGamma(ImageOnlyTransform):
"""
Args:
gamma_limit (float or (float, float)): If gamma_limit is a single float value,
the range will be (-gamma_limit, gamma_limit). Default: (80, 120).
eps: Deprecated.
Targets:
image
Image types:
uint8, float32
"""
def __init__(self, gamma_limit=(80, 120), eps=None, always_apply=False, p=0.5):
super(RandomGamma, self).__init__(always_apply, p)
self.gamma_limit = to_tuple(gamma_limit)
self.eps = eps
def apply(self, img, gamma=1, **params):
return F.gamma_transform(img, gamma=gamma)
def get_params(self):
return {"gamma": random.uniform(self.gamma_limit[0], self.gamma_limit[1]) / 100.0}
def get_transform_init_args_names(self):
return ("gamma_limit", "eps")
主要参数:gamma_limit,默认(80, 120),若只输入一个数值,会被转换为(-gamma_limit, gamma_limit)
由get_params()函数可知,gamma_limit是gamma参数的100倍,所以gamma_limit范围内取值>100时,图像变暗,gamma_limit范围内取值<100时,图像变亮。

功能:给输入图像添加下雨效果
参数说明:
# 默认参数
slant_lower=-10,
slant_upper=10,
drop_length=20,
drop_width=1,
drop_color=(200, 200, 200),
blur_value=7,
brightness_coefficient=0.7,
rain_type=None
-
slant_lower、slant_upper: 控制雨线倾斜程度的,取值范围 [-20, 20]。slant_sample < 0雨线向左倾斜,反之向右。
-
drop_length: 雨线长度,取值范围 [0, 100]。指定rain_type参数时,传入的drop_length失效,使用内置数值,见rain_type参数部分代码。
-
drop_width: 雨线宽度,取值范围 [1, 5]。
-
drop_color (list of (r, g, b)): 雨线颜色。
# drop_length,drop_width, drop_color 都是绘制雨线(cv2.line)的参数 for (rain_drop_x0, rain_drop_y0) in rain_drops: rain_drop_x1 = rain_drop_x0 + slant rain_drop_y1 = rain_drop_y0 + drop_length cv2.line( image, (rain_drop_x0, rain_drop_y0), (rain_drop_x1, rain_drop_y1), drop_color, drop_width, ) -
blur_value (int): cv2.blur()的kernel_size,需要将雨天场景模糊处理,因为雨天大多都是朦胧的。
-
brightness_coefficient (float): 亮度因子,取值范围 [0, 1]。因为雨天往往都是阴天,光照不足。
-
rain_type: 下雨程度,One of [None, “drizzle”, “heavy”, “torrential”],从左到右依次递增。
if self.rain_type == "drizzle": num_drops = area // 770 drop_length = 10 elif self.rain_type == "heavy": num_drops = width * height // 600 drop_length = 30 elif self.rain_type == "torrential": num_drops = area // 500 drop_length = 60 else: drop_length = self.drop_length num_drops = area // 600
# source code
class RandomRain(ImageOnlyTransform):
"""Adds rain effects.
From https://github.com/UjjwalSaxena/Automold--Road-Augmentation-Library
Args:
slant_lower: should be in range [-20, 20].
slant_upper: should be in range [-20, 20].
drop_length: should be in range [0, 100].
drop_width: should be in range [1, 5].
drop_color (list of (r, g, b)): rain lines color.
blur_value (int): rainy view are blurry
brightness_coefficient (float): rainy days are usually shady. Should be in range [0, 1].
rain_type: One of [None, "drizzle", "heavy", "torrential"]
Targets:
image
Image types:
uint8, float32
"""
def __init__(
self,
slant_lower=-10,
slant_upper=10,
drop_length=20,
drop_width=1,
drop_color=(200, 200, 200),
blur_value=7,
brightness_coefficient=0.7,
rain_type=None,
always_apply=False,
p=0.5,
):
super(RandomRain, self).__init__(always_apply, p)
if rain_type not in ["drizzle", "heavy", "torrential", None]:
raise ValueError("raint_type must be one of ({}). Got: {}".format(
["drizzle", "heavy", "torrential", None], rain_type))
if not -20 <= slant_lower <= slant_upper <= 20:
raise ValueError(
"Invalid combination of slant_lower and slant_upper. Got: {}".
format((slant_lower, slant_upper)))
if not 1 <= drop_width <= 5:
raise ValueError(
"drop_width must be in range [1, 5]. Got: {}".format(
drop_width))
if not 0 <= drop_length <= 100:
raise ValueError(
"drop_length must be in range [0, 100]. Got: {}".format(
drop_length))
if not 0 <= brightness_coefficient <= 1:
raise ValueError(
"brightness_coefficient must be in range [0, 1]. Got: {}".
format(brightness_coefficient))
self.slant_lower = slant_lower
self.slant_upper = slant_upper
self.drop_length = drop_length
self.drop_width = drop_width
self.drop_color = drop_color
self.blur_value = blur_value
self.brightness_coefficient = brightness_coefficient
self.rain_type = rain_type
def apply(self, image, slant=10, drop_length=20, rain_drops=(), **params):
return F.add_rain(
image,
slant,
drop_length,
self.drop_width,
self.drop_color,
self.blur_value,
self.brightness_coefficient,
rain_drops,
)
@property
def targets_as_params(self):
return ["image"]
def get_params_dependent_on_targets(self, params):
img = params["image"]
slant = int(random.uniform(self.slant_lower, self.slant_upper))
height, width = img.shape[:2]
area = height * width
if self.rain_type == "drizzle":
num_drops = area // 770
drop_length = 10
elif self.rain_type == "heavy":
num_drops = width * height // 600
drop_length = 30
elif self.rain_type == "torrential":
num_drops = area // 500
drop_length = 60
else:
drop_length = self.drop_length
num_drops = area // 600
rain_drops = []
for _i in range(
num_drops): # If You want heavy rain, try increasing this
if slant < 0:
x = random.randint(slant, width)
else:
x = random.randint(0, width - slant)
y = random.randint(0, height - drop_length)
rain_drops.append((x, y))
return {
"drop_length": drop_length,
"slant": slant,
"rain_drops": rain_drops
}
def get_transform_init_args_names(self):
return (
"slant_lower",
"slant_upper",
"drop_length",
"drop_width",
"drop_color",
"blur_value",
"brightness_coefficient",
"rain_type",
)
可视化分析:
未在图上标明的参数使用的参数。
rain_type=None时,drop_length生效,左下长度30比右上默认长度20的雨线要长。
rain_type in [“drizzle”, “heavy”, “torrential”]时,drop_length失效,使用内置长度,torrential模式对应的长度为60。所以虽然右上和右下图的drop_length值一致,但是雨线长度不一样。

功能:
# source code
功能:
# source code
功能: 仿真太阳耀斑效果
参数说明:
-
flare_roi (float, float, float, float): 耀斑位置(x_min, y_min, x_max, y_max)。所有值在 [0, 1]范围内。默认值:(0, 0, 1, 0.5)
-
angle_lower、angle_upper (float): 应满足 0 <= angle_lower < angle_upper <= 1
-
num_flare_circles_lower 、num_flare_circles_upper (int): 耀斑圆圈个数。应满足 0 <= num_flare_circles_lower < num_flare_circles_upper。
-
src_radius (int): 耀斑半径(src_radius 是最大的半径,内圈半径等间隔采样),默认值400。结合图像分辨率定值,稍大一点没关系,外圈光晕的权重很小。
num_times = src_radius // 10 rad = np.linspace(1, src_radius, num=num_times) # 等间隔采样 for i in range(num_times): cv2.circle(overlay, point, int(rad[i]), src_color, -1) ... -
src_color ((int, int, int)): 耀斑颜色
# source code
class RandomSunFlare(ImageOnlyTransform):
"""Simulates Sun Flare for the image
From https://github.com/UjjwalSaxena/Automold--Road-Augmentation-Library
Args:
flare_roi (float, float, float, float): region of the image where flare will
appear (x_min, y_min, x_max, y_max). All values should be in range [0, 1].
angle_lower (float): should be in range [0, `angle_upper`].
angle_upper (float): should be in range [`angle_lower`, 1].
num_flare_circles_lower (int): lower limit for the number of flare circles.
Should be in range [0, `num_flare_circles_upper`].
num_flare_circles_upper (int): upper limit for the number of flare circles.
Should be in range [`num_flare_circles_lower`, inf].
src_radius (int):
src_color ((int, int, int)): color of the flare
Targets:
image
Image types:
uint8, float32
"""
def __init__(
self,
flare_roi=(0, 0, 1, 0.5),
angle_lower=0,
angle_upper=1,
num_flare_circles_lower=6,
num_flare_circles_upper=10,
src_radius=400,
src_color=(255, 255, 255),
always_apply=False,
p=0.5,
):
super(RandomSunFlare, self).__init__(always_apply, p)
(
flare_center_lower_x,
flare_center_lower_y,
flare_center_upper_x,
flare_center_upper_y,
) = flare_roi
if (
not 0 <= flare_center_lower_x < flare_center_upper_x <= 1
or not 0 <= flare_center_lower_y < flare_center_upper_y <= 1
):
raise ValueError("Invalid flare_roi. Got: {}".format(flare_roi))
if not 0 <= angle_lower < angle_upper <= 1:
raise ValueError(
"Invalid combination of angle_lower nad angle_upper. Got: {}".format((angle_lower, angle_upper))
)
if not 0 <= num_flare_circles_lower < num_flare_circles_upper:
raise ValueError(
"Invalid combination of num_flare_circles_lower nad num_flare_circles_upper. Got: {}".format(
(num_flare_circles_lower, num_flare_circles_upper)
)
)
self.flare_center_lower_x = flare_center_lower_x
self.flare_center_upper_x = flare_center_upper_x
self.flare_center_lower_y = flare_center_lower_y
self.flare_center_upper_y = flare_center_upper_y
self.angle_lower = angle_lower
self.angle_upper = angle_upper
self.num_flare_circles_lower = num_flare_circles_lower
self.num_flare_circles_upper = num_flare_circles_upper
self.src_radius = src_radius
self.src_color = src_color
def apply(self, image, flare_center_x=0.5, flare_center_y=0.5, circles=(), **params):
return F.add_sun_flare(
image,
flare_center_x,
flare_center_y,
self.src_radius,
self.src_color,
circles,
)
@property
def targets_as_params(self):
return ["image"]
def get_params_dependent_on_targets(self, params):
img = params["image"]
height, width = img.shape[:2]
angle = 2 * math.pi * random.uniform(self.angle_lower, self.angle_upper)
flare_center_x = random.uniform(self.flare_center_lower_x, self.flare_center_upper_x)
flare_center_y = random.uniform(self.flare_center_lower_y, self.flare_center_upper_y)
flare_center_x = int(width * flare_center_x)
flare_center_y = int(height * flare_center_y)
num_circles = random.randint(self.num_flare_circles_lower, self.num_flare_circles_upper)
circles = []
x = []
y = []
for rand_x in range(0, width, 10):
rand_y = math.tan(angle) * (rand_x - flare_center_x) + flare_center_y
x.append(rand_x)
y.append(2 * flare_center_y - rand_y)
for _i in range(num_circles):
alpha = random.uniform(0.05, 0.2)
r = random.randint(0, len(x) - 1)
rad = random.randint(1, max(height // 100 - 2, 2))
r_color = random.randint(max(self.src_color[0] - 50, 0), self.src_color[0])
g_color = random.randint(max(self.src_color[0] - 50, 0), self.src_color[0])
b_color = random.randint(max(self.src_color[0] - 50, 0), self.src_color[0])
circles += [
(
alpha,
(int(x[r]), int(y[r])),
pow(rad, 3),
(r_color, g_color, b_color),
)
]
return {
"circles": circles,
"flare_center_x": flare_center_x,
"flare_center_y": flare_center_y,
}
def get_transform_init_args(self):
return {
"flare_roi": (
self.flare_center_lower_x,
self.flare_center_lower_y,
self.flare_center_upper_x,
self.flare_center_upper_y,
),
"angle_lower": self.angle_lower,
"angle_upper": self.angle_upper,
"num_flare_circles_lower": self.num_flare_circles_lower,
"num_flare_circles_upper": self.num_flare_circles_upper,
"src_radius": self.src_radius,
"src_color": self.src_color,
}

功能: 锐化。(类似方法有UnsharpMask)
参数说明: alpha ((float, float)): 控制锐化图像的可视化程度。alpha=0表示只保留原图,alpha=1.0表示只保留锐化图。
lightness ((float, float)): 控制锐化图像的亮度。
# source code
class Sharpen(ImageOnlyTransform):
"""Sharpen the input image and overlays the result with the original image.
Args:
alpha ((float, float)): range to choose the visibility of the sharpened image. At 0, only the original image is
visible, at 1.0 only its sharpened version is visible. Default: (0.2, 0.5).
lightness ((float, float)): range to choose the lightness of the sharpened image. Default: (0.5, 1.0).
p (float): probability of applying the transform. Default: 0.5.
Targets:
image
"""
def __init__(self,
alpha=(0.2, 0.5),
lightness=(0.5, 1.0),
always_apply=False,
p=0.5):
super(Sharpen, self).__init__(always_apply, p)
self.alpha = self.__check_values(to_tuple(alpha, 0.0),
name="alpha",
bounds=(0.0, 1.0))
self.lightness = self.__check_values(to_tuple(lightness, 0.0),
name="lightness")
@staticmethod
def __check_values(value, name, bounds=(0, float("inf"))):
if not bounds[0] <= value[0] <= value[1] <= bounds[1]:
raise ValueError("{} values should be between {}".format(
name, bounds))
return value
@staticmethod
def __generate_sharpening_matrix(alpha_sample, lightness_sample):
matrix_nochange = np.array([[0, 0, 0], [0, 1, 0], [0, 0, 0]],
dtype=np.float32)
matrix_effect = np.array(
[[-1, -1, -1], [-1, 8 + lightness_sample, -1], [-1, -1, -1]],
dtype=np.float32,
)
matrix = (
1 - alpha_sample) * matrix_nochange + alpha_sample * matrix_effect
return matrix
def get_params(self):
alpha = random.uniform(*self.alpha)
lightness = random.uniform(*self.lightness)
sharpening_matrix = self.__generate_sharpening_matrix(
alpha_sample=alpha, lightness_sample=lightness)
return {"sharpening_matrix": sharpening_matrix}
def apply(self, img, sharpening_matrix=None, **params):
return F.convolve(img, sharpening_matrix)
def get_transform_init_args_names(self):
return ("alpha", "lightness")
效果比UnsharpMask强一些,UnsharpMask锐化效果更自然。

功能: 将大于阈值的像素反转(若输入为uint8型,反转即为255 – pixel_value)
# source code
class Solarize(ImageOnlyTransform):
"""Invert all pixel values above a threshold.
Args:
threshold ((int, int) or int, or (float, float) or float): range for solarizing threshold.
If threshold is a single value, the range will be [threshold, threshold]. Default: 128.
p (float): probability of applying the transform. Default: 0.5.
Targets:
image
Image types:
any
"""
def __init__(self, threshold=128, always_apply=False, p=0.5):
super(Solarize, self).__init__(always_apply, p)
if isinstance(threshold, (int, float)):
self.threshold = to_tuple(threshold, low=threshold)
else:
self.threshold = to_tuple(threshold, low=0)
def apply(self, image, threshold=0, **params):
return F.solarize(image, threshold)
def get_params(self):
return {
"threshold": random.uniform(self.threshold[0], self.threshold[1])
}
def get_transform_init_args_names(self):
return ("threshold", )
# F.solarize
def solarize(img, threshold=128):
"""Invert all pixel values above a threshold.
Args:
img (numpy.ndarray): The image to solarize.
threshold (int): All pixels above this greyscale level are inverted.
Returns:
numpy.ndarray: Solarized image.
"""
dtype = img.dtype
max_val = MAX_VALUES_BY_DTYPE[dtype]
if dtype == np.dtype("uint8"):
lut = [(i if i < threshold else max_val - i) for i in range(max_val + 1)]
prev_shape = img.shape
img = cv2.LUT(img, np.array(lut, dtype=dtype))
if len(prev_shape) != len(img.shape):
img = np.expand_dims(img, -1)
return img
result_img = img.copy()
cond = img >= threshold
result_img[cond] = max_val - result_img[cond]
return result_img

功能: 飞溅效果,可以模拟雨水或泥浆遮挡镜头。
参数说明: mean (float, or tuple of floats): 生成液体层(liquid layer)的正态分布均值。若是单个数字直接作为均值,若是区间参数,表示在这区间范围内[mean[0], mean[1])随机采样一个数值作为均值。默认值:0.65
std (float, or tuple of floats): 生成液体层的正态分布方差。若是单个数字直接作为方差,若是区间参数,表示在这区间范围内[std[0], std[1])随机采样一个数值作为方差。默认值:0.3
gauss_sigma (float, or tuple of floats): 液体层的高斯滤波sigma值。若是单个数字直接作为方差,若是区间参数,表示在这区间范围内[sigma[0], sigma[1])随机采样一个数值作为sigma。默认值:2
cutout_threshold (float, or tuple of floats): 液体层滤波阈值。若是单个数字直接作为阈值,若是区间参数,表示在这区间范围内[cutout_threshold[0], cutout_threshold[1])随机采样一个数值作为阈值。默认值:0.68
intensity (float, or tuple of floats): 飞溅强度。若是单个数字直接作为阈值,若是区间参数,表示在这区间范围内[intensity[0], intensity[1])随机采样一个数值作为阈值。默认值:0.6
mode (string, or list of strings): 飞溅类型。支持的选项为’rain’ 和 ‘mud’。若提供参数为mode=["rain", "mud"],表示对当前图像随机选择一种飞溅模式。默认值:‘rain’
mean,std,gauss_sigma 都会影响雨点或泥点的大小。
cutout_threshold会影响雨点或泥点的覆盖密度与面积。
intensity会影响雨点或泥点的轻重。
所有值若需调整均建议仅微调!!!!
具体可视化对比结果可看source code后面内容。
注意:mean参数不可偏离0.65太大,建议使用默认值,若设为0.5,会引起错误(rain模式),无法产生正确结果。若设置值偏大,图像完全偏离想要的结果。
错误提示: divide by zero encountered in true_divide m *= 1 / np.max(m, axis=(0, 1))
以下展示不同模式下mean值不同的结果:
rain模式:

mud模式:

# source code
class Spatter(ImageOnlyTransform):
"""
Apply spatter transform. It simulates corruption which can occlude a lens in the form of rain or mud.
Args:
mean (float, or tuple of floats): Mean value of normal distribution for generating liquid layer.
If single float it will be used as mean.
If tuple of float mean will be sampled from range `[mean[0], mean[1])`. Default: (0.65).
std (float, or tuple of floats): Standard deviation value of normal distribution for generating liquid layer.
If single float it will be used as std.
If tuple of float std will be sampled from range `[std[0], std[1])`. Default: (0.3).
gauss_sigma (float, or tuple of floats): Sigma value for gaussian filtering of liquid layer.
If single float it will be used as gauss_sigma.
If tuple of float gauss_sigma will be sampled from range `[sigma[0], sigma[1])`. Default: (2).
cutout_threshold (float, or tuple of floats): Threshold for filtering liqued layer
(determines number of drops). If single float it will used as cutout_threshold.
If tuple of float cutout_threshold will be sampled from range `[cutout_threshold[0], cutout_threshold[1])`.
Default: (0.68).
intensity (float, or tuple of floats): Intensity of corruption.
If single float it will be used as intensity.
If tuple of float intensity will be sampled from range `[intensity[0], intensity[1])`. Default: (0.6).
mode (string, or list of strings): Type of corruption. Currently, supported options are 'rain' and 'mud'.
If list is provided type of corruption will be sampled list. Default: ("rain").
p (float): probability of applying the transform. Default: 0.5.
Targets:
image
Image types:
uint8, float32
Reference:
| https://arxiv.org/pdf/1903.12261.pdf
| https://github.com/hendrycks/robustness/blob/master/ImageNet-C/create_c/make_imagenet_c.py
"""
def __init__(
self,
mean: ScaleFloatType = 0.65,
std: ScaleFloatType = 0.3,
gauss_sigma: ScaleFloatType = 2,
cutout_threshold: ScaleFloatType = 0.68,
intensity: ScaleFloatType = 0.6,
mode: Union[str, Sequence[str]] = "rain",
always_apply: bool = False,
p: float = 0.5,
):
super().__init__(always_apply=always_apply, p=p)
self.mean = to_tuple(mean, mean)
self.std = to_tuple(std, std)
self.gauss_sigma = to_tuple(gauss_sigma, gauss_sigma)
self.intensity = to_tuple(intensity, intensity)
self.cutout_threshold = to_tuple(cutout_threshold, cutout_threshold)
self.mode = mode if isinstance(mode, (list, tuple)) else [mode]
for i in self.mode:
if i not in ["rain", "mud"]:
raise ValueError(
f"Unsupported color mode: {mode}. Transform supports only `rain` and `mud` mods."
)
def apply(self,
img: np.ndarray,
non_mud: Optional[np.ndarray] = None,
mud: Optional[np.ndarray] = None,
drops: Optional[np.ndarray] = None,
mode: str = "",
**params) -> np.ndarray:
return F.spatter(img, non_mud, mud, drops, mode)
@property
def targets_as_params(self) -> List[str]:
return ["image"]
def get_params_dependent_on_targets(
self, params: Dict[str, Any]) -> Dict[str, Any]:
h, w = params["image"].shape[:2]
mean = random.uniform(self.mean[0], self.mean[1])
std = random.uniform(self.std[0], self.std[1])
cutout_threshold = random.uniform(self.cutout_threshold[0],
self.cutout_threshold[1])
sigma = random.uniform(self.gauss_sigma[0], self.gauss_sigma[1])
mode = random.choice(self.mode)
intensity = random.uniform(self.intensity[0], self.intensity[1])
liquid_layer = random_utils.normal(size=(h, w), loc=mean, scale=std)
liquid_layer = gaussian_filter(liquid_layer,
sigma=sigma,
mode="nearest")
liquid_layer[liquid_layer < cutout_threshold] = 0
if mode == "rain":
liquid_layer = (liquid_layer * 255).astype(np.uint8)
dist = 255 - cv2.Canny(liquid_layer, 50, 150)
dist = cv2.distanceTransform(dist, cv2.DIST_L2, 5)
_, dist = cv2.threshold(dist, 20, 20, cv2.THRESH_TRUNC)
dist = blur(dist, 3).astype(np.uint8)
dist = F.equalize(dist)
ker = np.array([[-2, -1, 0], [-1, 1, 1], [0, 1, 2]])
dist = F.convolve(dist, ker)
dist = blur(dist, 3).astype(np.float32)
m = liquid_layer * dist
m *= 1 / np.max(m, axis=(0, 1))
drops = m[:, :, None] * np.array(
[238 / 255.0, 238 / 255.0, 175 / 255.0]) * intensity
mud = None
non_mud = None
else:
m = np.where(liquid_layer > cutout_threshold, 1, 0)
m = gaussian_filter(m.astype(np.float32),
sigma=sigma,
mode="nearest")
m[m < 1.2 * cutout_threshold] = 0
m = m[..., np.newaxis]
mud = m * np.array([20 / 255.0, 42 / 255.0, 63 / 255.0])
non_mud = 1 - m
drops = None
return {
"non_mud": non_mud,
"mud": mud,
"drops": drops,
"mode": mode,
}
def get_transform_init_args_names(
self) -> Tuple[str, str, str, str, str, str]:
return "mean", "std", "gauss_sigma", "intensity", "cutout_threshold", "mode"
以下分别可视化不同参数变化的结果,未显示在图上的参数均使用默认参数。
mean变化:

std变化:

gauss_sigma变化:

cutout_threshold变化:

飞溅强度intensity变化:

飞溅模式mode变化:
右下角图像随机选择了rain模式。

概念理解:
超像素概念是2003年Xiaofeng Ren提出和发展起来的图像分割技术,是指具有相似纹理、颜色、亮度等特征的相邻像素构成的有一定视觉意义的不规则像素块。它利用像素之间特征的相似性将像素分组,用少量的超像素代替大量的像素来表达图片特征,很大程度上降低了图像后处理的复杂度,所以通常作为分割算法的预处理步骤。
功能: 将图像的部分或全部变为超像素表示,使用了SLIC(simple linear iterative cluster)算法。
参数说明:
-
p_replace (float or tuple of float): 表示当前图像分割块有p_replace的概率被average color填充。
p_replace=0,表示保留原图;
p_replace=0.5,表示所有分割块约有一半被平均色填充;
p_replace=1.0,表示所有分割块均被平均色填充,生成一个voronoi image(泰森多边形图); -
n_segments (int, or tuple of int): 大约生成的超像素数(算法可能偏离这个数字)
-
max_size (int or None): 表示图像长边最大尺寸,超过就 等比例resize到该尺寸(目的是算法加速),最终结果会resize到原始尺寸。若
max_size = None表示不进行reize。 -
interpolation (OpenCV flag): opencv插值方式,默认线性插值(cv2.INTER_LINEAR)。
插值方式可枚举值:
cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4
# source code
class Superpixels(ImageOnlyTransform):
"""Transform images partially/completely to their superpixel representation.
This implementation uses skimage's version of the SLIC algorithm.
Args:
p_replace (float or tuple of float): Defines for any segment the probability that the pixels within that
segment are replaced by their average color (otherwise, the pixels are not changed).
Examples:
* A probability of ``0.0`` would mean, that the pixels in no
segment are replaced by their average color (image is not
changed at all).
* A probability of ``0.5`` would mean, that around half of all
segments are replaced by their average color.
* A probability of ``1.0`` would mean, that all segments are
replaced by their average color (resulting in a voronoi
image).
Behaviour based on chosen data types for this parameter:
* If a ``float``, then that ``flat`` will always be used.
* If ``tuple`` ``(a, b)``, then a random probability will be
sampled from the interval ``[a, b]`` per image.
n_segments (int, or tuple of int): Rough target number of how many superpixels to generate (the algorithm
may deviate from this number). Lower value will lead to coarser superpixels.
Higher values are computationally more intensive and will hence lead to a slowdown
* If a single ``int``, then that value will always be used as the
number of segments.
* If a ``tuple`` ``(a, b)``, then a value from the discrete
interval ``[a..b]`` will be sampled per image.
max_size (int or None): Maximum image size at which the augmentation is performed.
If the width or height of an image exceeds this value, it will be
downscaled before the augmentation so that the longest side matches `max_size`.
This is done to speed up the process. The final output image has the same size as the input image.
Note that in case `p_replace` is below ``1.0``,
the down-/upscaling will affect the not-replaced pixels too.
Use ``None`` to apply no down-/upscaling.
interpolation (OpenCV flag): flag that is used to specify the interpolation algorithm. Should be one of:
cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4.
Default: cv2.INTER_LINEAR.
p (float): probability of applying the transform. Default: 0.5.
Targets:
image
"""
def __init__(
self,
p_replace: Union[float, Sequence[float]] = 0.1,
n_segments: Union[int, Sequence[int]] = 100,
max_size: Optional[int] = 128,
interpolation: int = cv2.INTER_LINEAR,
always_apply: bool = False,
p: float = 0.5,
):
super().__init__(always_apply=always_apply, p=p)
self.p_replace = to_tuple(p_replace, p_replace)
self.n_segments = to_tuple(n_segments, n_segments)
self.max_size = max_size
self.interpolation = interpolation
if min(self.n_segments) < 1:
raise ValueError(f"n_segments must be >= 1. Got: {n_segments}")
def get_transform_init_args_names(self) -> Tuple[str, str, str, str]:
return ("p_replace", "n_segments", "max_size", "interpolation")
def get_params(self) -> dict:
n_segments = random.randint(*self.n_segments)
p = random.uniform(*self.p_replace)
return {"replace_samples": random_utils.random(n_segments) < p, "n_segments": n_segments}
def apply(self, img: np.ndarray, replace_samples: Sequence[bool] = (False,), n_segments: int = 1, **kwargs):
return F.superpixels(img, n_segments, replace_samples, self.max_size, self.interpolation)
以下是可视化结果。
n_segments 越大,表示图像分割块越多。
p_replace 越大,表示被均色填充的概率越高,即有更多的分割块被填充。
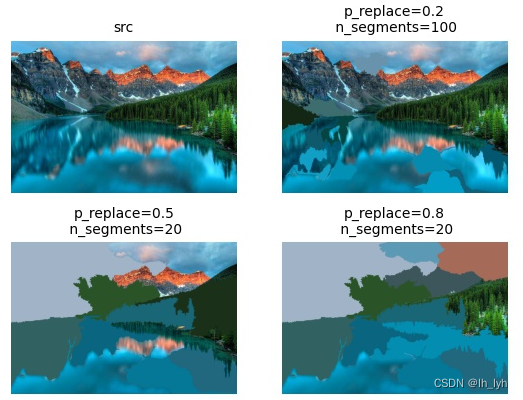
拓展阅读:
龙生龙,凤生凤,SLIC生超像素
功能: 除以最大值,转为float32输入,像素值范围变为[0, 1.0]
若未指定最大值,将通过图像类型判断最大值:
MAX_VALUES_BY_DTYPE = {
np.dtype("uint8"): 255,
np.dtype("uint16"): 65535,
np.dtype("uint32"): 4294967295,
np.dtype("float32"): 1.0,
}
与其相反的函数为
FromFloat,即img([0,1.0]) * max_value
# source code
class ToFloat(ImageOnlyTransform):
"""Divide pixel values by `max_value` to get a float32 output array where all values lie in the range [0, 1.0].
If `max_value` is None the transform will try to infer the maximum value by inspecting the data type of the input
image.
See Also:
:class:`~albumentations.augmentations.transforms.FromFloat`
Args:
max_value (float): maximum possible input value. Default: None.
p (float): probability of applying the transform. Default: 1.0.
Targets:
image
Image types:
any type
"""
def __init__(self, max_value=None, always_apply=False, p=1.0):
super(ToFloat, self).__init__(always_apply, p)
self.max_value = max_value
def apply(self, img, **params):
return F.to_float(img, self.max_value)
def get_transform_init_args_names(self):
return ("max_value",)
# F.to_float()
def to_float(img, max_value=None):
if max_value is None:
try:
max_value = MAX_VALUES_BY_DTYPE[img.dtype]
except KeyError:
raise RuntimeError(
"Can't infer the maximum value for dtype {}. You need to specify the maximum value manually by "
"passing the max_value argument".format(img.dtype)
)
return img.astype("float32") / max_value
功能: 将图像随机变为灰度图。注意变换后的灰度图仍为3通道。
# source code
class ToGray(ImageOnlyTransform):
"""Convert the input RGB image to grayscale. If the mean pixel value for the resulting image is greater
than 127, invert the resulting grayscale image.
Args:
p (float): probability of applying the transform. Default: 0.5. # 应用该变换的概率值,p=1表示将所有图都变为灰度图。
Targets:
image
Image types:
uint8, float32
"""
def apply(self, img, **params):
if is_grayscale_image(img):
warnings.warn("The image is already gray.")
return img
if not is_rgb_image(img):
raise TypeError("ToGray transformation expects 3-channel images.")
return F.to_gray(img)
def get_transform_init_args_names(self):
return ()
# F.to_gray(img)
def to_gray(img):
gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
return cv2.cvtColor(gray, cv2.COLOR_GRAY2RGB) # 灰度图转为三通道
以下是可视化结果,注意灰度图下方“x24BPP”,表示三通道图像。

功能: 将灰度图转为三通道灰度图
version 1.3.0中未包含此变换。
此变换默认p=1。(ToGray默认p=0.5)
# source code
class ToRGB(ImageOnlyTransform):
"""Convert the input grayscale image to RGB.
Args:
p (float): probability of applying the transform. Default: 1.
Targets:
image
Image types:
uint8, float32
"""
def __init__(self, always_apply=True, p=1.0):
super(ToRGB, self).__init__(always_apply=always_apply, p=p)
def apply(self, img, **params):
if is_rgb_image(img):
warnings.warn("The image is already an RGB.")
return img
if not is_grayscale_image(img):
raise TypeError("ToRGB transformation expects 2-dim images or 3-dim with the last dimension equal to 1.")
return F.gray_to_rgb(img)
def get_transform_init_args_names(self):
return ()
# F.gray_to_rgb(img)
def gray_to_rgb(img):
return cv2.cvtColor(img, cv2.COLOR_GRAY2RGB)
功能: 为图像添加棕褐色滤镜
# source code
class ToSepia(ImageOnlyTransform):
"""Applies sepia filter to the input RGB image
Args:
p (float): probability of applying the transform. Default: 0.5.
Targets:
image
Image types:
uint8, float32
"""
def __init__(self, always_apply=False, p=0.5):
super(ToSepia, self).__init__(always_apply, p)
self.sepia_transformation_matrix = np.matrix(
[[0.393, 0.769, 0.189], [0.349, 0.686, 0.168], [0.272, 0.534, 0.131]]
)
def apply(self, image, **params):
if not is_rgb_image(image):
raise TypeError("ToSepia transformation expects 3-channel images.")
return F.linear_transformation_rgb(image, self.sepia_transformation_matrix)
def get_transform_init_args_names(self):
return ()
# F.linear_transformation_rgb
@clipped
def linear_transformation_rgb(img, transformation_matrix):
result_img = cv2.transform(img, transformation_matrix)
return result_img



功能:使用USM算法锐化图像。
Sharpen the input image using Unsharp Masking processing and overlays the result with the original image.
参数说明:
-
主要参数及默认值:
blur_limit: Union[int, Sequence[int]] = (3, 7), sigma_limit: Union[float, Sequence[float]] = 0.0, alpha: Union[float, Sequence[float]] = (0.2, 0.5), threshold: int = 10 -
参数要求:
-
blur_limit (int or (int, int)):表示模糊输入图像的最大高斯核大小。必须为0或者奇数,有效值范围[0, inf)
若为0,会用round(sigma * (3 if img.dtype == np.uint8 else 4) * 2 + 1) + 1计算结果代替
若输入为单个数字,会转换为区间 (0, blur_limit)。源码中初始化有如下行: self.blur_limit = to_tuple(blur_limit, 3) # 表示3为另一边界值的填补值 举例: self.blur_limit = to_tuple(1, 3) # self.blur_limit = (1, 3) self.blur_limit = to_tuple(5, 3) # self.blur_limit = (3, 5) -
sigma_limit (float or (float, float)):高斯核标准差,有效值范围[0.0, inf)
若为0,会用sigma = 0.3*((ksize-1)*0.5 - 1) + 0.8计算结果代替
若输入为单个数字,会转换为区间 (0, sigma_limit) -
alpha (float or (float, float)): 控制锐化图像的透明度。结果图像是锐化图像和原图叠加的,alpha控制的就是锐化图像叠加比重。alpha = 0 表示只返回原图,alpha = 1 表示锐化部分全部叠加。
residual = image - blur # blur是应用高斯模糊(cv2.GaussianBlur)后的图像 sharp = image + alpha * residual # Avoid color noise artefacts. sharp = np.clip(sharp, 0, 1) -
threshold (int): 控制原图与smoothed图像之间具有高像素差异区域的锐化程度。有效值范围[0, 255]。threshold 值越大,表示平坦区域(即原图与smoothed图像之间的低像素差异区域)的锐化程度越小。(
(image - blur)*255 < threshold区域面积增大,该部分不参与锐化叠加)
其实可以理解为值越大,锐化程度越轻。residual = image - blur # blur是应用高斯模糊(cv2.GaussianBlur)后的图像 # Do not sharpen noise mask = np.abs(residual) * 255 > threshold mask = mask.astype("float32") -
注意:blur_limit 和 sigma_limit 的下限值不可同时为0
-
# source code
class UnsharpMask(ImageOnlyTransform):
"""
Sharpen the input image using Unsharp Masking processing and overlays the result with the original image.
Args:
blur_limit (int, (int, int)): maximum Gaussian kernel size for blurring the input image.
Must be zero or odd and in range [0, inf). If set to 0 it will be computed from sigma
as `round(sigma * (3 if img.dtype == np.uint8 else 4) * 2 + 1) + 1`.
If set single value `blur_limit` will be in range (0, blur_limit).
Default: (3, 7).
sigma_limit (float, (float, float)): Gaussian kernel standard deviation. Must be in range [0, inf).
If set single value `sigma_limit` will be in range (0, sigma_limit).
If set to 0 sigma will be computed as `sigma = 0.3*((ksize-1)*0.5 - 1) + 0.8`. Default: 0.
alpha (float, (float, float)): range to choose the visibility of the sharpened image.
At 0, only the original image is visible, at 1.0 only its sharpened version is visible.
Default: (0.2, 0.5).
threshold (int): Value to limit sharpening only for areas with high pixel difference between original image
and it's smoothed version. Higher threshold means less sharpening on flat areas.
Must be in range [0, 255]. Default: 10.
p (float): probability of applying the transform. Default: 0.5.
Reference:
arxiv.org/pdf/2107.10833.pdf
Targets:
image
"""
def __init__(
self,
blur_limit: Union[int, Sequence[int]] = (3, 7),
sigma_limit: Union[float, Sequence[float]] = 0.0,
alpha: Union[float, Sequence[float]] = (0.2, 0.5),
threshold: int = 10,
always_apply=False,
p=0.5,
):
super(UnsharpMask, self).__init__(always_apply, p)
self.blur_limit = to_tuple(blur_limit, 3)
self.sigma_limit = self.__check_values(to_tuple(sigma_limit, 0.0), name="sigma_limit")
self.alpha = self.__check_values(to_tuple(alpha, 0.0), name="alpha", bounds=(0.0, 1.0))
self.threshold = threshold
if self.blur_limit[0] == 0 and self.sigma_limit[0] == 0:
self.blur_limit = 3, max(3, self.blur_limit[1])
raise ValueError("blur_limit and sigma_limit minimum value can not be both equal to 0.")
if (self.blur_limit[0] != 0 and self.blur_limit[0] % 2 != 1) or (
self.blur_limit[1] != 0 and self.blur_limit[1] % 2 != 1
):
raise ValueError("UnsharpMask supports only odd blur limits.")
@staticmethod
def __check_values(value, name, bounds=(0, float("inf"))):
if not bounds[0] <= value[0] <= value[1] <= bounds[1]:
raise ValueError(f"{name} values should be between {bounds}")
return value
def get_params(self):
return {
"ksize": random.randrange(self.blur_limit[0], self.blur_limit[1] + 1, 2),
"sigma": random.uniform(*self.sigma_limit),
"alpha": random.uniform(*self.alpha),
}
def apply(self, img, ksize=3, sigma=0, alpha=0.2, **params):
return F.unsharp_mask(img, ksize, sigma=sigma, alpha=alpha, threshold=self.threshold)
def get_transform_init_args_names(self):
return ("blur_limit", "sigma_limit", "alpha", "threshold")
# F.unsharp_mask()
def unsharp_mask(image: np.ndarray, ksize: int, sigma: float = 0.0, alpha: float = 0.2, threshold: int = 10):
blur_fn = _maybe_process_in_chunks(cv2.GaussianBlur, ksize=(ksize, ksize), sigmaX=sigma)
input_dtype = image.dtype
if input_dtype == np.uint8:
image = to_float(image)
elif input_dtype not in (np.uint8, np.float32):
raise ValueError("Unexpected dtype {} for UnsharpMask augmentation".format(input_dtype))
blur = blur_fn(image)
residual = image - blur
# Do not sharpen noise
mask = np.abs(residual) * 255 > threshold
mask = mask.astype("float32")
sharp = image + alpha * residual
# Avoid color noise artefacts.
sharp = np.clip(sharp, 0, 1)
soft_mask = blur_fn(mask)
output = soft_mask * sharp + (1 - soft_mask) * image
return from_float(output, dtype=input_dtype)
可视化结果如下,左侧是原图,右侧是锐化结果。为效果明显,右图参数设为(ksize=5,sigma=0, alpha=1, threshold=0)。
拓展阅读:
Unsharp Mask(USM)锐化算法的的原理及其实现
超分辨率论文阅读—Real-ESRGAN(2021ICCV)
Spatial-level transforms
空间级变换将同时更改输入图像以及其他属性,例如masks, bounding boxes, and keypoints。
Spatial-level transforms will simultaneously change both an input image as well as additional targets such as masks, bounding boxes, and keypoints.
下表显示了每种变换支持哪些属性随之变化。
| Transform | Image | Masks | BBoxes | Keypoints |
|---|---|---|---|---|
| Affine | ✓ | ✓ | ✓ | ✓ |
| BBoxSafeRandomCrop | ✓ | ✓ | ✓ | |
| CenterCrop | ✓ | ✓ | ✓ | ✓ |
| CoarseDropout | ✓ | ✓ | ✓ | |
| Crop | ✓ | ✓ | ✓ | ✓ |
| CropAndPad | ✓ | ✓ | ✓ | ✓ |
| CropNonEmptyMaskIfExists | ✓ | ✓ | ✓ | ✓ |
| ElasticTransform | ✓ | ✓ | ✓ | |
| Flip | ✓ | ✓ | ✓ | ✓ |
| GridDistortion | ✓ | ✓ | ✓ | |
| GridDropout | ✓ | ✓ | ||
| HorizontalFlip | ✓ | ✓ | ✓ | ✓ |
| Lambda | ✓ | ✓ | ✓ | ✓ |
| LongestMaxSize | ✓ | ✓ | ✓ | ✓ |
| MaskDropout | ✓ | ✓ | ||
| NoOp | ✓ | ✓ | ✓ | ✓ |
| OpticalDistortion | ✓ | ✓ | ✓ | |
| PadIfNeeded | ✓ | ✓ | ✓ | ✓ |
| Perspective | ✓ | ✓ | ✓ | ✓ |
| PiecewiseAffine | ✓ | ✓ | ✓ | ✓ |
| PixelDropout | ✓ | ✓ | ✓ | ✓ |
| RandomCrop | ✓ | ✓ | ✓ | ✓ |
| RandomCropFromBorders | ✓ | ✓ | ✓ | ✓ |
| RandomCropNearBBox | ✓ | ✓ | ✓ | ✓ |
| RandomGridShuffle | ✓ | ✓ | ✓ | |
| RandomResizedCrop | ✓ | ✓ | ✓ | ✓ |
| RandomRotate90 | ✓ | ✓ | ✓ | ✓ |
| RandomScale | ✓ | ✓ | ✓ | ✓ |
| RandomSizedBBoxSafeCrop | ✓ | ✓ | ✓ | |
| RandomSizedCrop | ✓ | ✓ | ✓ | ✓ |
| Resize | ✓ | ✓ | ✓ | ✓ |
| Rotate | ✓ | ✓ | ✓ | ✓ |
| SafeRotate | ✓ | ✓ | ✓ | ✓ |
| ShiftScaleRotate | ✓ | ✓ | ✓ | ✓ |
| SmallestMaxSize | ✓ | ✓ | ✓ | ✓ |
| Transpose | ✓ | ✓ | ✓ | ✓ |
| VerticalFlip | ✓ | ✓ | ✓ | ✓ |
功能: 裁剪图像中心区域
参数说明: height、width (int): 裁剪区域高、宽。
# source code
class CenterCrop(DualTransform):
"""Crop the central part of the input.
Args:
height (int): height of the crop.
width (int): width of the crop.
p (float): probability of applying the transform. Default: 1.
Targets:
image, mask, bboxes, keypoints
Image types:
uint8, float32
Note:
It is recommended to use uint8 images as input.
Otherwise the operation will require internal conversion
float32 -> uint8 -> float32 that causes worse performance.
"""
def __init__(self, height, width, always_apply=False, p=1.0):
super(CenterCrop, self).__init__(always_apply, p)
self.height = height
self.width = width
def apply(self, img, **params):
return F.center_crop(img, self.height, self.width)
def apply_to_bbox(self, bbox, **params):
return F.bbox_center_crop(bbox, self.height, self.width, **params)
def apply_to_keypoint(self, keypoint, **params):
return F.keypoint_center_crop(keypoint, self.height, self.width, **params)
def get_transform_init_args_names(self):
return ("height", "width")
# F.center_crop
def get_center_crop_coords(height: int, width: int, crop_height: int, crop_width: int):
y1 = (height - crop_height) // 2
y2 = y1 + crop_height
x1 = (width - crop_width) // 2
x2 = x1 + crop_width
return x1, y1, x2, y2
def center_crop(img: np.ndarray, crop_height: int, crop_width: int):
height, width = img.shape[:2]
if height < crop_height or width < crop_width:
raise ValueError(
"Requested crop size ({crop_height}, {crop_width}) is "
"larger than the image size ({height}, {width})".format(
crop_height=crop_height, crop_width=crop_width, height=height, width=width
)
)
x1, y1, x2, y2 = get_center_crop_coords(height, width, crop_height, crop_width)
img = img[y1:y2, x1:x2]
return img
可以看到鸟的喙基本都在crop图的中心偏上一点的位置。

功能: 随机丢弃图像中的矩形区域,用固定值填充。(功能涵盖Cutout,额外增加mask处理)
参数说明:
-
max_holes (int): 需要cutout的最大区域个数。
-
max_height、max_width (int, float): 洞的最大尺寸。若为float,自动根据图像宽高计算(图像宽高 * float值)。
-
min_holes (int): 需要cutout的最小区域个数。若为
None,等同于max_holes 数值。Default:None. -
min_height、min_width (int, float): 洞的最小尺寸。若为
None,等同于相应max数值。Default:None.
若为float,自动根据图像宽高计算(图像宽高 * float值)。 -
fill_value (int, float, list of int, list of float): cutout区域像素填充值。
-
mask_fill_value (int, float, list of int, list of float): mask图像的cutout区域像素填充值。若为
None,不进行任何操作,返回原始mask。 Default:None.
# 构造函数,其余方法未拷贝,可点击标题跳转查看全部源码
class CoarseDropout(DualTransform):
"""CoarseDropout of the rectangular regions in the image.
Args:
max_holes (int): Maximum number of regions to zero out.
max_height (int, float): Maximum height of the hole.
If float, it is calculated as a fraction of the image height.
max_width (int, float): Maximum width of the hole.
If float, it is calculated as a fraction of the image width.
min_holes (int): Minimum number of regions to zero out. If `None`,
`min_holes` is be set to `max_holes`. Default: `None`.
min_height (int, float): Minimum height of the hole. Default: None. If `None`,
`min_height` is set to `max_height`. Default: `None`.
If float, it is calculated as a fraction of the image height.
min_width (int, float): Minimum width of the hole. If `None`, `min_height` is
set to `max_width`. Default: `None`.
If float, it is calculated as a fraction of the image width.
fill_value (int, float, list of int, list of float): value for dropped pixels.
mask_fill_value (int, float, list of int, list of float): fill value for dropped pixels
in mask. If `None` - mask is not affected. Default: `None`.
Targets:
image, mask
Image types:
uint8, float32
Reference:
| https://arxiv.org/abs/1708.04552
| https://github.com/uoguelph-mlrg/Cutout/blob/master/util/cutout.py
| https://github.com/aleju/imgaug/blob/master/imgaug/augmenters/arithmetic.py
"""
def __init__(
self,
max_holes=8,
max_height=8,
max_width=8,
min_holes=None,
min_height=None,
min_width=None,
fill_value=0,
mask_fill_value=None,
always_apply=False,
p=0.5,
):
super(CoarseDropout, self).__init__(always_apply, p)
self.max_holes = max_holes
self.max_height = max_height
self.max_width = max_width
self.min_holes = min_holes if min_holes is not None else max_holes
self.min_height = min_height if min_height is not None else max_height
self.min_width = min_width if min_width is not None else max_width
self.fill_value = fill_value
self.mask_fill_value = mask_fill_value
if not 0 < self.min_holes <= self.max_holes:
raise ValueError("Invalid combination of min_holes and max_holes. Got: {}".format([min_holes, max_holes]))
self.check_range(self.max_height)
self.check_range(self.min_height)
self.check_range(self.max_width)
self.check_range(self.min_width)
if not 0 < self.min_height <= self.max_height:
raise ValueError(
"Invalid combination of min_height and max_height. Got: {}".format([min_height, max_height])
)
if not 0 < self.min_width <= self.max_width:
raise ValueError("Invalid combination of min_width and max_width. Got: {}".format([min_width, max_width]))
def check_range(self, dimension):
if isinstance(dimension, float) and not 0 <= dimension < 1.0:
raise ValueError(
"Invalid value {}. If using floats, the value should be in the range [0.0, 1.0)".format(dimension)
)
...
...
...
未在图中声明的参数即使用的默认值。

功能: 裁剪图像,返回裁剪部分。
参数说明:
x_min (int): 裁剪区域的左上角x坐标,默认值:0
y_min (int): 裁剪区域的左上角y坐标,默认值:0
x_max (int): 裁剪区域的右下角x坐标,默认值:1024
y_max (int): 裁剪区域的右下角y坐标,默认值:1024
需注意此变换没有随机性,等同于img[y_min:y_max, x_min:x_max]。
# source code
class Crop(DualTransform):
"""Crop region from image.
Args:
x_min (int): Minimum upper left x coordinate.
y_min (int): Minimum upper left y coordinate.
x_max (int): Maximum lower right x coordinate.
y_max (int): Maximum lower right y coordinate.
Targets:
image, mask, bboxes, keypoints
Image types:
uint8, float32
"""
def __init__(self, x_min=0, y_min=0, x_max=1024, y_max=1024, always_apply=False, p=1.0):
super(Crop, self).__init__(always_apply, p)
self.x_min = x_min
self.y_min = y_min
self.x_max = x_max
self.y_max = y_max
def apply(self, img, **params):
return F.crop(img, x_min=self.x_min, y_min=self.y_min, x_max=self.x_max, y_max=self.y_max)
def apply_to_bbox(self, bbox, **params):
return F.bbox_crop(bbox, x_min=self.x_min, y_min=self.y_min, x_max=self.x_max, y_max=self.y_max, **params)
def apply_to_keypoint(self, keypoint, **params):
return F.crop_keypoint_by_coords(keypoint, crop_coords=(self.x_min, self.y_min, self.x_max, self.y_max))
def get_transform_init_args_names(self):
return ("x_min", "y_min", "x_max", "y_max")
(plt画图结果并排展示有缩放,可以看下裁剪的面部区域)

功能: 按像素数或者图像占比裁剪或填充图像上下左右四个边缘。此变换永远不会裁剪高度或宽度低于 1 的图像。
注意此变换会resize变换后的图像到原始图像大小。若要保持变换后的尺寸,需设置参数keep_size=False。
参数说明:
- px (int or tuple)、percent (float or tuple):
- px表示具体的像素数数值,percent 表示百分比(像素数除以宽或高 )
- px 和 percent 小于0表示crop操作,大于0表示pad操作。
- 这两个参数只能选择一个传值,另一个需为None。不可同时传值,也不可同时为None。
- 若传入参数为两个元素,表示图像四个边的px/percent值在该区间内随机采样。若
sample_independently=False,只采样一次,四个边共用这个值。 - 若传入参数为四个元素,每个元素依次表征图像的top,right, bottom, left(顺时针),每个元素可以是 单个数字或两个数字的列表,数字表示固定值,列表表示范围内随机采样,含义与上述一致。
- pad_mode (int): OpenCV border mode. opencv边界像素补充方法。可枚举值:cv2.BORDER_CONSTANT(常数), cv2.BORDER_REPLICATE(复制), cv2.BORDER_REFLECT(镜像 ), cv2.BORDER_WRAP, cv2.BORDER_REFLECT_101(镜像)。默认值:cv2.BORDER_CONSTANT
- pad_cval (number, Sequence[number]): 边界像素补充值(仅限border_mode=cv2.BORDER_CONSTANT)。
若为单个数字,直接用作填充值。若为两个元素的列表,则从该区间随机采样一个值,作为该图像的边缘填充值。@staticmethod def _get_pad_value(pad_value: Union[float, Sequence[float]]) -> Union[int, float]: if isinstance(pad_value, (int, float)): return pad_value if len(pad_value) == 2: a, b = pad_value if isinstance(a, int) and isinstance(b, int): return random.randint(a, b) return random.uniform(a, b) return random.choice(pad_value) - pad_cval_mask (number, Sequence[number]): 和 pad_cval含义一致,不过是针对mask操作的。
- keep_size (bool): crop或pad后的图像尺寸会改变。若设为True,表示将其resize到输入图像尺寸。若为False,则保留crop或pad之后变化了的尺寸。默认值:True。
- sample_independently (bool): 表示四个边操作的
px/percent值是否独立采样。默认值:True。 - interpolation (OpenCV flag): flag that is used to specify the interpolation algorithm. Should be one of:
cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4.
Default: cv2.INTER_LINEAR.
# 构造函数
class CropAndPad(DualTransform):
"""Crop and pad images by pixel amounts or fractions of image sizes.
Cropping removes pixels at the sides (i.e. extracts a subimage from a given full image).
Padding adds pixels to the sides (e.g. black pixels).
This transformation will never crop images below a height or width of ``1``.
Note:
This transformation automatically resizes images back to their original size. To deactivate this, add the
parameter ``keep_size=False``.
Args:
px (int or tuple):
The number of pixels to crop (negative values) or pad (positive values)
on each side of the image. Either this or the parameter `percent` may
be set, not both at the same time.
* If ``None``, then pixel-based cropping/padding will not be used.
* If ``int``, then that exact number of pixels will always be cropped/padded.
* If a ``tuple`` of two ``int`` s with values ``a`` and ``b``,
then each side will be cropped/padded by a random amount sampled
uniformly per image and side from the interval ``[a, b]``. If
however `sample_independently` is set to ``False``, only one
value will be sampled per image and used for all sides.
* If a ``tuple`` of four entries, then the entries represent top,
right, bottom, left. Each entry may be a single ``int`` (always
crop/pad by exactly that value), a ``tuple`` of two ``int`` s
``a`` and ``b`` (crop/pad by an amount within ``[a, b]``), a
``list`` of ``int`` s (crop/pad by a random value that is
contained in the ``list``).
percent (float or tuple):
The number of pixels to crop (negative values) or pad (positive values)
on each side of the image given as a *fraction* of the image
height/width. E.g. if this is set to ``-0.1``, the transformation will
always crop away ``10%`` of the image's height at both the top and the
bottom (both ``10%`` each), as well as ``10%`` of the width at the
right and left.
Expected value range is ``(-1.0, inf)``.
Either this or the parameter `px` may be set, not both
at the same time.
* If ``None``, then fraction-based cropping/padding will not be
used.
* If ``float``, then that fraction will always be cropped/padded.
* If a ``tuple`` of two ``float`` s with values ``a`` and ``b``,
then each side will be cropped/padded by a random fraction
sampled uniformly per image and side from the interval
``[a, b]``. If however `sample_independently` is set to
``False``, only one value will be sampled per image and used for
all sides.
* If a ``tuple`` of four entries, then the entries represent top,
right, bottom, left. Each entry may be a single ``float``
(always crop/pad by exactly that percent value), a ``tuple`` of
two ``float`` s ``a`` and ``b`` (crop/pad by a fraction from
``[a, b]``), a ``list`` of ``float`` s (crop/pad by a random
value that is contained in the list).
pad_mode (int): OpenCV border mode.
pad_cval (number, Sequence[number]):
The constant value to use if the pad mode is ``BORDER_CONSTANT``.
* If ``number``, then that value will be used.
* If a ``tuple`` of two ``number`` s and at least one of them is
a ``float``, then a random number will be uniformly sampled per
image from the continuous interval ``[a, b]`` and used as the
value. If both ``number`` s are ``int`` s, the interval is
discrete.
* If a ``list`` of ``number``, then a random value will be chosen
from the elements of the ``list`` and used as the value.
pad_cval_mask (number, Sequence[number]): Same as pad_cval but only for masks.
keep_size (bool):
After cropping and padding, the result image will usually have a
different height/width compared to the original input image. If this
parameter is set to ``True``, then the cropped/padded image will be
resized to the input image's size, i.e. the output shape is always identical to the input shape.
sample_independently (bool):
If ``False`` *and* the values for `px`/`percent` result in exactly
*one* probability distribution for all image sides, only one single
value will be sampled from that probability distribution and used for
all sides. I.e. the crop/pad amount then is the same for all sides.
If ``True``, four values will be sampled independently, one per side.
interpolation (OpenCV flag): flag that is used to specify the interpolation algorithm. Should be one of:
cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4.
Default: cv2.INTER_LINEAR.
Targets:
image, mask, bboxes, keypoints
Image types:
any
"""
def __init__(
self,
px: Optional[Union[int, Sequence[float], Sequence[Tuple]]] = None,
percent: Optional[Union[float, Sequence[float], Sequence[Tuple]]] = None,
pad_mode: int = cv2.BORDER_CONSTANT,
pad_cval: Union[float, Sequence[float]] = 0,
pad_cval_mask: Union[float, Sequence[float]] = 0,
keep_size: bool = True,
sample_independently: bool = True,
interpolation: int = cv2.INTER_LINEAR,
always_apply: bool = False,
p: float = 1.0,
):
super().__init__(always_apply, p)
if px is None and percent is None:
raise ValueError("px and percent are empty!")
if px is not None and percent is not None:
raise ValueError("Only px or percent may be set!")
self.px = px
self.percent = percent
self.pad_mode = pad_mode
self.pad_cval = pad_cval
self.pad_cval_mask = pad_cval_mask
self.keep_size = keep_size
self.sample_independently = sample_independently
self.interpolation = interpolation
右下图res3的参数sample_independently设为True,不同边的pad像素值不同。
左下图res2的参数percent为负数,表示crop。

功能: 若mask为空,等同于随机裁剪+缩放;若有mask,可以指定忽略的mask区域 ,在忽略区域外进行随机采点并crop出指定宽高区域。mask==0区域默认忽略,还会将指定ignore_values区域置为0忽略。
crop的逻辑如下,在mask非忽略区域随机取个点,在向左上方随机移动一段距离作为crop区域的左上顶点,右下顶点则为左上顶点加宽和高后的点。本变换能增加目标被crop到的概率。
if mask.any():
mask = mask.sum(axis=-1) if mask.ndim == 3 else mask
non_zero_yx = np.argwhere(mask)
y, x = random.choice(non_zero_yx)
x_min = x - random.randint(0, self.width - 1)
y_min = y - random.randint(0, self.height - 1)
x_min = np.clip(x_min, 0, mask_width - self.width)
y_min = np.clip(y_min, 0, mask_height - self.height)
else:
x_min = random.randint(0, mask_width - self.width)
y_min = random.randint(0, mask_height - self.height)
x_max = x_min + self.width
y_max = y_min + self.height
参数说明:
height 、width (int): crop区域的目标宽高。
ignore_values (list of int): mask需要忽略的像素值,0是默认忽略区域。注意输入是列表形式。
ignore_channels (list of int): mask需要忽略的通道。注意输入是列表形式。
# source code
class CropNonEmptyMaskIfExists(DualTransform):
"""Crop area with mask if mask is non-empty, else make random crop.
Args:
height (int): vertical size of crop in pixels
width (int): horizontal size of crop in pixels
ignore_values (list of int): values to ignore in mask, `0` values are always ignored
(e.g. if background value is 5 set `ignore_values=[5]` to ignore)
ignore_channels (list of int): channels to ignore in mask
(e.g. if background is a first channel set `ignore_channels=[0]` to ignore)
p (float): probability of applying the transform. Default: 1.0.
Targets:
image, mask, bboxes, keypoints
Image types:
uint8, float32
"""
def __init__(self, height, width, ignore_values=None, ignore_channels=None, always_apply=False, p=1.0):
super(CropNonEmptyMaskIfExists, self).__init__(always_apply, p)
if ignore_values is not None and not isinstance(ignore_values, list):
raise ValueError("Expected `ignore_values` of type `list`, got `{}`".format(type(ignore_values)))
if ignore_channels is not None and not isinstance(ignore_channels, list):
raise ValueError("Expected `ignore_channels` of type `list`, got `{}`".format(type(ignore_channels)))
self.height = height
self.width = width
self.ignore_values = ignore_values
self.ignore_channels = ignore_channels
def apply(self, img, x_min=0, x_max=0, y_min=0, y_max=0, **params):
return F.crop(img, x_min, y_min, x_max, y_max)
def apply_to_bbox(self, bbox, x_min=0, x_max=0, y_min=0, y_max=0, **params):
return F.bbox_crop(
bbox, x_min=x_min, x_max=x_max, y_min=y_min, y_max=y_max, rows=params["rows"], cols=params["cols"]
)
def apply_to_keypoint(self, keypoint, x_min=0, x_max=0, y_min=0, y_max=0, **params):
return F.crop_keypoint_by_coords(keypoint, crop_coords=(x_min, y_min, x_max, y_max))
def _preprocess_mask(self, mask):
mask_height, mask_width = mask.shape[:2]
if self.ignore_values is not None:
ignore_values_np = np.array(self.ignore_values)
mask = np.where(np.isin(mask, ignore_values_np), 0, mask)
if mask.ndim == 3 and self.ignore_channels is not None:
target_channels = np.array([ch for ch in range(mask.shape[-1]) if ch not in self.ignore_channels])
mask = np.take(mask, target_channels, axis=-1)
if self.height > mask_height or self.width > mask_width:
raise ValueError(
"Crop size ({},{}) is larger than image ({},{})".format(
self.height, self.width, mask_height, mask_width
)
)
return mask
def update_params(self, params, **kwargs):
super().update_params(params, **kwargs)
if "mask" in kwargs:
mask = self._preprocess_mask(kwargs["mask"])
elif "masks" in kwargs and len(kwargs["masks"]):
masks = kwargs["masks"]
mask = self._preprocess_mask(masks[0])
for m in masks[1:]:
mask |= self._preprocess_mask(m)
else:
raise RuntimeError("Can not find mask for CropNonEmptyMaskIfExists")
mask_height, mask_width = mask.shape[:2]
if mask.any():
mask = mask.sum(axis=-1) if mask.ndim == 3 else mask
non_zero_yx = np.argwhere(mask)
y, x = random.choice(non_zero_yx)
x_min = x - random.randint(0, self.width - 1)
y_min = y - random.randint(0, self.height - 1)
x_min = np.clip(x_min, 0, mask_width - self.width)
y_min = np.clip(y_min, 0, mask_height - self.height)
else:
x_min = random.randint(0, mask_width - self.width)
y_min = random.randint(0, mask_height - self.height)
x_max = x_min + self.width
y_max = y_min + self.height
params.update({"x_min": x_min, "x_max": x_max, "y_min": y_min, "y_max": y_max})
return params
def get_transform_init_args_names(self):
return ("height", "width", "ignore_values", "ignore_channels")
下图的mask非忽略区域是小鸟和蝴蝶所在的矩形区域。res1,res2,res3是随机crop结果。

功能: 弹性变换。
附官方展示图:
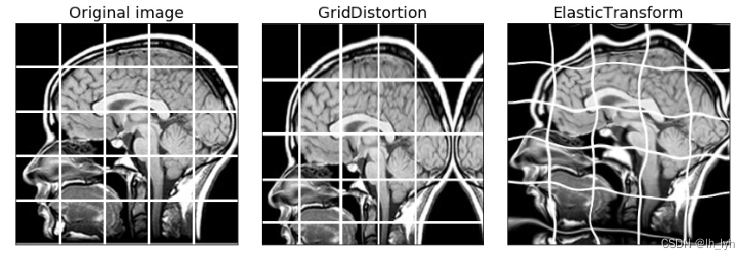
参数说明:
- alpha (float): 扭曲变换参数。默认值1,值越大扭曲效果越明显(如alpha=500,sigma=50)
- sigma (float): 高斯滤波参数。默认值50,值越小扭曲效果越明显(如alpha=100,sigma=20)。
- alpha_affine (float): 仿射变换参数,将转化为区间
(-alpha_affine, alpha_affine),默认值50。 - interpolation (OpenCV flag): opencv插值方法,可枚举值:cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4。默认值:cv2.INTER_LINEAR(mask使用的是cv2.INTER_NEAREST,代码已写死,未接受外部指定)
- border_mode (OpenCV flag): opencv边界像素补充方法。可枚举值:cv2.BORDER_CONSTANT(常数), cv2.BORDER_REPLICATE(复制), cv2.BORDER_REFLECT(镜像 ), cv2.BORDER_WRAP, cv2.BORDER_REFLECT_101(镜像)。默认值:cv2.BORDER_REFLECT_101
- value (int, float, list of ints, list of float): 边界像素补充值(仅限border_mode=cv2.BORDER_CONSTANT)
- mask_value (int, float, list of ints, list of float): 处理mask的边界像素补充值(仅限border_mode=cv2.BORDER_CONSTANT)
- approximate (boolean): 平滑时是否使用固定的kernel size。若为True,在512+的大图像上处理可达到约两倍加速,同时会带来抖动的副作用。默认值:False
- same_dxdy (boolean): x和y方向上是否使用相同的随机偏移值。若为True,也可达到约两倍加速,同时会带来抖动的副作用。默认值:False
# 构造函数
class ElasticTransform(DualTransform):
"""Elastic deformation of images as described in [Simard2003]_ (with modifications).
Based on https://gist.github.com/ernestum/601cdf56d2b424757de5
.. [Simard2003] Simard, Steinkraus and Platt, "Best Practices for
Convolutional Neural Networks applied to Visual Document Analysis", in
Proc. of the International Conference on Document Analysis and
Recognition, 2003.
Args:
alpha (float):
sigma (float): Gaussian filter parameter.
alpha_affine (float): The range will be (-alpha_affine, alpha_affine)
interpolation (OpenCV flag): flag that is used to specify the interpolation algorithm. Should be one of:
cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4.
Default: cv2.INTER_LINEAR.
border_mode (OpenCV flag): flag that is used to specify the pixel extrapolation method. Should be one of:
cv2.BORDER_CONSTANT, cv2.BORDER_REPLICATE, cv2.BORDER_REFLECT, cv2.BORDER_WRAP, cv2.BORDER_REFLECT_101.
Default: cv2.BORDER_REFLECT_101
value (int, float, list of ints, list of float): padding value if border_mode is cv2.BORDER_CONSTANT.
mask_value (int, float,
list of ints,
list of float): padding value if border_mode is cv2.BORDER_CONSTANT applied for masks.
approximate (boolean): Whether to smooth displacement map with fixed kernel size.
Enabling this option gives ~2X speedup on large images.
same_dxdy (boolean): Whether to use same random generated shift for x and y.
Enabling this option gives ~2X speedup.
Targets:
image, mask
Image types:
uint8, float32
"""
def __init__(
self,
alpha=1,
sigma=50,
alpha_affine=50,
interpolation=cv2.INTER_LINEAR,
border_mode=cv2.BORDER_REFLECT_101,
value=None,
mask_value=None,
always_apply=False,
approximate=False,
same_dxdy=False,
p=0.5,
):
super(ElasticTransform, self).__init__(always_apply, p)
...
...
# F.elastic_transform
@preserve_shape
def elastic_transform(
img,
alpha,
sigma,
alpha_affine,
interpolation=cv2.INTER_LINEAR,
border_mode=cv2.BORDER_REFLECT_101,
value=None,
random_state=None,
approximate=False,
same_dxdy=False,
):
"""Elastic deformation of images as described in [Simard2003]_ (with modifications).
Based on https://gist.github.com/ernestum/601cdf56d2b424757de5
.. [Simard2003] Simard, Steinkraus and Platt, "Best Practices for
Convolutional Neural Networks applied to Visual Document Analysis", in
Proc. of the International Conference on Document Analysis and
Recognition, 2003.
"""
if random_state is None:
random_state = np.random.RandomState(1234)
height, width = img.shape[:2]
# Random affine
center_square = np.float32((height, width)) // 2
square_size = min((height, width)) // 3
alpha = float(alpha)
sigma = float(sigma)
alpha_affine = float(alpha_affine)
pts1 = np.float32(
[
center_square + square_size,
[center_square[0] + square_size, center_square[1] - square_size],
center_square - square_size,
]
)
pts2 = pts1 + random_state.uniform(-alpha_affine, alpha_affine, size=pts1.shape).astype(np.float32)
matrix = cv2.getAffineTransform(pts1, pts2)
warp_fn = _maybe_process_in_chunks(
cv2.warpAffine, M=matrix, dsize=(width, height), flags=interpolation, borderMode=border_mode, borderValue=value
)
img = warp_fn(img)
if approximate:
# Approximate computation smooth displacement map with a large enough kernel.
# On large images (512+) this is approximately 2X times faster
dx = random_state.rand(height, width).astype(np.float32) * 2 - 1
cv2.GaussianBlur(dx, (17, 17), sigma, dst=dx)
dx *= alpha
if same_dxdy:
# Speed up even more
dy = dx
else:
dy = random_state.rand(height, width).astype(np.float32) * 2 - 1
cv2.GaussianBlur(dy, (17, 17), sigma, dst=dy)
dy *= alpha
else:
dx = np.float32(gaussian_filter((random_state.rand(height, width) * 2 - 1), sigma) * alpha)
if same_dxdy:
# Speed up
dy = dx
else:
dy = np.float32(gaussian_filter((random_state.rand(height, width) * 2 - 1), sigma) * alpha)
x, y = np.meshgrid(np.arange(width), np.arange(height))
map_x = np.float32(x + dx)
map_y = np.float32(y + dy)
remap_fn = _maybe_process_in_chunks(
cv2.remap, map1=map_x, map2=map_y, interpolation=interpolation, borderMode=border_mode, borderValue=value
)
return remap_fn(img)
下图中未显示的参数均使用默认值。
sigma值较小时alpha对扭曲程度影响比较灵敏。

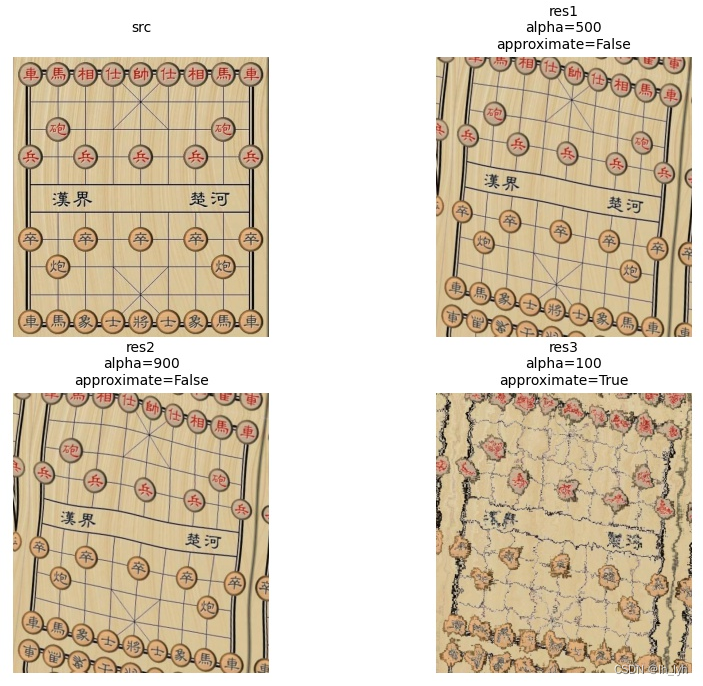

适用输入类型:image, mask, bboxes, keypoints
功能:水平翻转(d=1)、垂直翻转(d=0)、同时水平和垂直翻转(等同于图像旋转180°)(d=-1)
d是源码中随机生成的参数,控制翻转模式。
# source code
class Flip(DualTransform):
"""Flip the input either horizontally, vertically or both horizontally and vertically.
Args:
p (float): probability of applying the transform. Default: 0.5.
Targets:
image, mask, bboxes, keypoints
Image types:
uint8, float32
"""
def apply(self, img, d=0, **params):
"""Args:
d (int): code that specifies how to flip the input. 0 for vertical flipping, 1 for horizontal flipping,
-1 for both vertical and horizontal flipping (which is also could be seen as rotating the input by
180 degrees).
"""
return F.random_flip(img, d)
def get_params(self):
# Random int in the range [-1, 1]
return {"d": random.randint(-1, 1)}
def apply_to_bbox(self, bbox, **params):
return F.bbox_flip(bbox, **params)
def apply_to_keypoint(self, keypoint, **params):
return F.keypoint_flip(keypoint, **params)
def get_transform_init_args_names(self):
return ()

功能: 网格畸变。
附官方展示图:
参数说明:
-
num_steps (int): 图像分块数(横纵相等).
-
distort_limit (float, (float, float)): 若输入为单个数字,将转化为区间
(-distort_limit, distort_limit)。 默认范围: (-0.3, 0.3)。
在此区间会分别进行x和y方向上的采样:stepsx,stepsy。若值大于0,块处理后尺寸大于原始尺寸,小于0相反。 -
interpolation (OpenCV flag): 插值方法。Default: cv2.INTER_LINEAR.
可枚举值:cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4. -
border_mode (OpenCV flag): 边缘像素补充方法. Default: cv2.BORDER_REFLECT_101
可枚举值:cv2.BORDER_CONSTANT, cv2.BORDER_REPLICATE, cv2.BORDER_REFLECT, cv2.BORDER_WRAP, cv2.BORDER_REFLECT_101. -
value (int, float, list of ints, list of float): 边缘像素补充值,仅限常数补充时使用,即
border_mode = cv2.BORDER_CONSTANT. -
mask_value (int, float, list of ints, list of float): mask的边缘像素补充值,仅限常数补充时使用,即
border_mode = cv2.BORDER_CONSTANT. -
normalized (bool): 若设为True,失真范围不会超过图像边界,即图像内容与原图一致,不会丢失或者扩充图像边界。Default: False
# source code
class GridDistortion(DualTransform):
"""
Args:
num_steps (int): count of grid cells on each side.
distort_limit (float, (float, float)): If distort_limit is a single float, the range
will be (-distort_limit, distort_limit). Default: (-0.03, 0.03).
interpolation (OpenCV flag): flag that is used to specify the interpolation algorithm. Should be one of:
cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4.
Default: cv2.INTER_LINEAR.
border_mode (OpenCV flag): flag that is used to specify the pixel extrapolation method. Should be one of:
cv2.BORDER_CONSTANT, cv2.BORDER_REPLICATE, cv2.BORDER_REFLECT, cv2.BORDER_WRAP, cv2.BORDER_REFLECT_101.
Default: cv2.BORDER_REFLECT_101
value (int, float, list of ints, list of float): padding value if border_mode is cv2.BORDER_CONSTANT.
mask_value (int, float,
list of ints,
list of float): padding value if border_mode is cv2.BORDER_CONSTANT applied for masks.
normalized (bool): if true, distortion will be normalized to do not go outside the image. Default: False
See for more information: https://github.com/albumentations-team/albumentations/pull/722
Targets:
image, mask
Image types:
uint8, float32
"""
def __init__(
self,
num_steps: int = 5,
distort_limit: ScaleFloatType = 0.3,
interpolation: int = cv2.INTER_LINEAR,
border_mode: int = cv2.BORDER_REFLECT_101,
value: Optional[ImageColorType] = None,
mask_value: Optional[ImageColorType] = None,
normalized: bool = False,
always_apply: bool = False,
p: float = 0.5,
):
super(GridDistortion, self).__init__(always_apply, p)
self.num_steps = num_steps
self.distort_limit = to_tuple(distort_limit)
self.interpolation = interpolation
self.border_mode = border_mode
self.value = value
self.mask_value = mask_value
self.normalized = normalized
def apply(
self, img: np.ndarray, stepsx: Tuple = (), stepsy: Tuple = (), interpolation: int = cv2.INTER_LINEAR, **params
) -> np.ndarray:
return F.grid_distortion(img, self.num_steps, stepsx, stepsy, interpolation, self.border_mode, self.value)
def apply_to_mask(self, img: np.ndarray, stepsx: Tuple = (), stepsy: Tuple = (), **params) -> np.ndarray:
return F.grid_distortion(
img, self.num_steps, stepsx, stepsy, cv2.INTER_NEAREST, self.border_mode, self.mask_value
)
def apply_to_bbox(self, bbox: BoxInternalType, stepsx: Tuple = (), stepsy: Tuple = (), **params) -> BoxInternalType:
rows, cols = params["rows"], params["cols"]
mask = np.zeros((rows, cols), dtype=np.uint8)
bbox_denorm = F.denormalize_bbox(bbox, rows, cols)
x_min, y_min, x_max, y_max = bbox_denorm[:4]
x_min, y_min, x_max, y_max = int(x_min), int(y_min), int(x_max), int(y_max)
mask[y_min:y_max, x_min:x_max] = 1
mask = F.grid_distortion(
mask, self.num_steps, stepsx, stepsy, cv2.INTER_NEAREST, self.border_mode, self.mask_value
)
bbox_returned = bbox_from_mask(mask)
bbox_returned = F.normalize_bbox(bbox_returned, rows, cols)
return bbox_returned
def _normalize(self, h, w, xsteps, ysteps):
# compensate for smaller last steps in source image.
x_step = w // self.num_steps
last_x_step = min(w, ((self.num_steps + 1) * x_step)) - (self.num_steps * x_step)
xsteps[-1] *= last_x_step / x_step
y_step = h // self.num_steps
last_y_step = min(h, ((self.num_steps + 1) * y_step)) - (self.num_steps * y_step)
ysteps[-1] *= last_y_step / y_step
# now normalize such that distortion never leaves image bounds.
tx = w / math.floor(w / self.num_steps)
ty = h / math.floor(h / self.num_steps)
xsteps = np.array(xsteps) * (tx / np.sum(xsteps))
ysteps = np.array(ysteps) * (ty / np.sum(ysteps))
return {"stepsx": xsteps, "stepsy": ysteps}
@property
def targets_as_params(self):
return ["image"]
def get_params_dependent_on_targets(self, params):
h, w = params["image"].shape[:2]
stepsx = [1 + random.uniform(self.distort_limit[0], self.distort_limit[1]) for _ in range(self.num_steps + 1)]
stepsy = [1 + random.uniform(self.distort_limit[0], self.distort_limit[1]) for _ in range(self.num_steps + 1)]
if self.normalized:
return self._normalize(h, w, stepsx, stepsy)
return {"stepsx": stepsx, "stepsy": stepsy}
def get_transform_init_args_names(self):
return "num_steps", "distort_limit", "interpolation", "border_mode", "value", "mask_value", "normalized"
可以看到图上象棋有纵向和横向的拉伸。
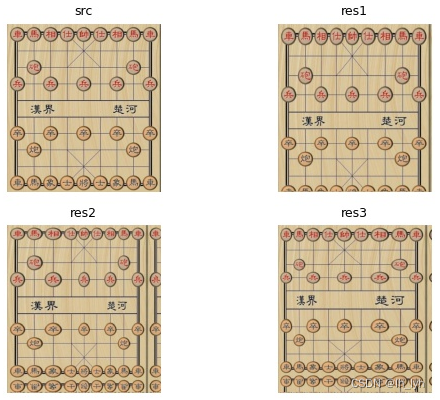
normalize参数设为true / false差别见如下结果:
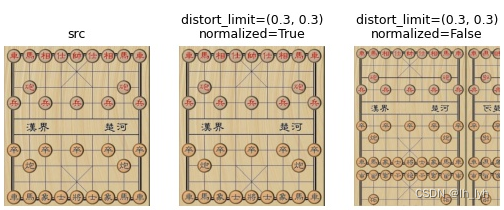
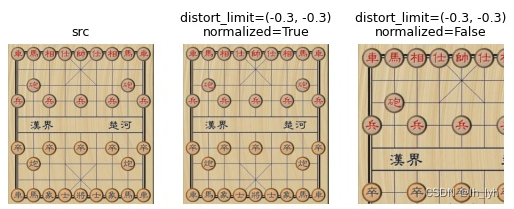
功能: 网格方块用固定值填充(默认黑色)
参数说明:
- ratio,unit_size_min ,unit_size_max ,holes_number_x ,holes_number_y 都是控制grids大小的。优先通过unit_size_min ,unit_size_max确定grid size,若为None,则通过holes_number_x ,holes_number_y 确定,若也为None,默认holes_number=10进行计算。
- shift_x ,shift_y 控制grids的起点偏移,默认0,所以结果图中黑块偏左上。
- random_offset :若设为True,随机生成偏移值,shift_x ,shift_y设置失效。
- fill_value :grids填充值,默认0,即黑色。
- mask_fill_value :mask图的grids部分填充值。若为
None,返回原始mask. Default:None.
# source code
class GridDropout(DualTransform):
"""GridDropout, drops out rectangular regions of an image and the corresponding mask in a grid fashion.
Args:
ratio (float): the ratio of the mask holes to the unit_size (same for horizontal and vertical directions).
Must be between 0 and 1. Default: 0.5.
unit_size_min (int): minimum size of the grid unit. Must be between 2 and the image shorter edge.
If 'None', holes_number_x and holes_number_y are used to setup the grid. Default: `None`.
unit_size_max (int): maximum size of the grid unit. Must be between 2 and the image shorter edge.
If 'None', holes_number_x and holes_number_y are used to setup the grid. Default: `None`.
holes_number_x (int): the number of grid units in x direction. Must be between 1 and image width//2.
If 'None', grid unit width is set as image_width//10. Default: `None`.
holes_number_y (int): the number of grid units in y direction. Must be between 1 and image height//2.
If `None`, grid unit height is set equal to the grid unit width or image height, whatever is smaller.
shift_x (int): offsets of the grid start in x direction from (0,0) coordinate.
Clipped between 0 and grid unit_width - hole_width. Default: 0.
shift_y (int): offsets of the grid start in y direction from (0,0) coordinate.
Clipped between 0 and grid unit height - hole_height. Default: 0.
random_offset (boolean): weather to offset the grid randomly between 0 and grid unit size - hole size
If 'True', entered shift_x, shift_y are ignored and set randomly. Default: `False`.
fill_value (int): value for the dropped pixels. Default = 0
mask_fill_value (int): value for the dropped pixels in mask.
If `None`, transformation is not applied to the mask. Default: `None`.
Targets:
image, mask
Image types:
uint8, float32
References:
https://arxiv.org/abs/2001.04086
"""
def __init__(
self,
ratio: float = 0.5,
unit_size_min: int = None,
unit_size_max: int = None,
holes_number_x: int = None,
holes_number_y: int = None,
shift_x: int = 0,
shift_y: int = 0,
random_offset: bool = False,
fill_value: int = 0,
mask_fill_value: int = None,
always_apply: bool = False,
p: float = 0.5,
):
super(GridDropout, self).__init__(always_apply, p)
self.ratio = ratio
self.unit_size_min = unit_size_min
self.unit_size_max = unit_size_max
self.holes_number_x = holes_number_x
self.holes_number_y = holes_number_y
self.shift_x = shift_x
self.shift_y = shift_y
self.random_offset = random_offset
self.fill_value = fill_value
self.mask_fill_value = mask_fill_value
if not 0 < self.ratio <= 1:
raise ValueError("ratio must be between 0 and 1.")
def apply(self, img: np.ndarray, holes: Iterable[Tuple[int, int, int, int]] = (), **params) -> np.ndarray:
return F.cutout(img, holes, self.fill_value)
def apply_to_mask(self, img: np.ndarray, holes: Iterable[Tuple[int, int, int, int]] = (), **params) -> np.ndarray:
if self.mask_fill_value is None:
return img
return F.cutout(img, holes, self.mask_fill_value)
def get_params_dependent_on_targets(self, params):
img = params["image"]
height, width = img.shape[:2]
# set grid using unit size limits
if self.unit_size_min and self.unit_size_max:
if not 2 <= self.unit_size_min <= self.unit_size_max:
raise ValueError("Max unit size should be >= min size, both at least 2 pixels.")
if self.unit_size_max > min(height, width):
raise ValueError("Grid size limits must be within the shortest image edge.")
unit_width = random.randint(self.unit_size_min, self.unit_size_max + 1)
unit_height = unit_width
else:
# set grid using holes numbers
if self.holes_number_x is None:
unit_width = max(2, width // 10)
else:
if not 1 <= self.holes_number_x <= width // 2:
raise ValueError("The hole_number_x must be between 1 and image width//2.")
unit_width = width // self.holes_number_x
if self.holes_number_y is None:
unit_height = max(min(unit_width, height), 2)
else:
if not 1 <= self.holes_number_y <= height // 2:
raise ValueError("The hole_number_y must be between 1 and image height//2.")
unit_height = height // self.holes_number_y
hole_width = int(unit_width * self.ratio)
hole_height = int(unit_height * self.ratio)
# min 1 pixel and max unit length - 1
hole_width = min(max(hole_width, 1), unit_width - 1)
hole_height = min(max(hole_height, 1), unit_height - 1)
# set offset of the grid
if self.shift_x is None:
shift_x = 0
else:
shift_x = min(max(0, self.shift_x), unit_width - hole_width)
if self.shift_y is None:
shift_y = 0
else:
shift_y = min(max(0, self.shift_y), unit_height - hole_height)
if self.random_offset:
shift_x = random.randint(0, unit_width - hole_width)
shift_y = random.randint(0, unit_height - hole_height)
holes = []
for i in range(width // unit_width + 1):
for j in range(height // unit_height + 1):
x1 = min(shift_x + unit_width * i, width)
y1 = min(shift_y + unit_height * j, height)
x2 = min(x1 + hole_width, width)
y2 = min(y1 + hole_height, height)
holes.append((x1, y1, x2, y2))
return {"holes": holes}
@property
def targets_as_params(self):
return ["image"]
def get_transform_init_args_names(self):
return (
"ratio",
"unit_size_min",
"unit_size_max",
"holes_number_x",
"holes_number_y",
"shift_x",
"shift_y",
"random_offset",
"fill_value",
"mask_fill_value",
)



适用输入类型:image, mask, bboxes, keypoints
功能:输入沿y轴翻转

功能: 保持缩放比例缩放图像,将长边调整为指定尺寸。相反调整短边的函数为SmallestMaxSize。
参数说明: max_size (int, list of int): maximum size of smallest side of the image after the transformation. 若输入为list,将从中随机选择一个数作为max_size。
interpolation (OpenCV flag): opencv插值方法,可枚举值:cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4。默认值:cv2.INTER_LINEAR
class LongestMaxSize(DualTransform):
"""Rescale an image so that maximum side is equal to max_size, keeping the aspect ratio of the initial image.
Args:
max_size (int, list of int): maximum size of the image after the transformation. When using a list, max size
will be randomly selected from the values in the list.
interpolation (OpenCV flag): interpolation method. Default: cv2.INTER_LINEAR.
p (float): probability of applying the transform. Default: 1.
Targets:
image, mask, bboxes, keypoints
Image types:
uint8, float32
"""
def __init__(
self,
max_size: Union[int, Sequence[int]] = 1024,
interpolation: int = cv2.INTER_LINEAR,
always_apply: bool = False,
p: float = 1,
):
super(LongestMaxSize, self).__init__(always_apply, p)
self.interpolation = interpolation
self.max_size = max_size
def apply(
self, img: np.ndarray, max_size: int = 1024, interpolation: int = cv2.INTER_LINEAR, **params
) -> np.ndarray:
return F.longest_max_size(img, max_size=max_size, interpolation=interpolation)
def apply_to_bbox(self, bbox: Sequence[float], **params) -> Sequence[float]:
# Bounding box coordinates are scale invariant
return bbox
def apply_to_keypoint(self, keypoint: Sequence[float], max_size: int = 1024, **params) -> Sequence[float]:
height = params["rows"]
width = params["cols"]
scale = max_size / max([height, width])
return F.keypoint_scale(keypoint, scale, scale)
def get_params(self) -> Dict[str, int]:
return {"max_size": self.max_size if isinstance(self.max_size, int) else random.choice(self.max_size)}
def get_transform_init_args_names(self) -> Tuple[str, ...]:
return ("max_size", "interpolation")

功能: 随机将图像和mask中的目标实例归零。
参数说明 :max_objects: 可以清零的最大标签数,也可以是区间参数 [min, max],最终应用数值在此区间内随机采样获取。
image_fill_value: 图像中归零区域填充值,默认0。也可设为’inpaint’ ,对归零区域进行修复(仅支持三通道图像)。
mask_fill_value: mask的归零区域填充值,默认0。
# source code
class MaskDropout(DualTransform):
"""
Image & mask augmentation that zero out mask and image regions corresponding
to randomly chosen object instance from mask.
Mask must be single-channel image, zero values treated as background.
Image can be any number of channels.
Inspired by https://www.kaggle.com/c/severstal-steel-defect-detection/discussion/114254
"""
def __init__(
self,
max_objects=1,
image_fill_value=0,
mask_fill_value=0,
always_apply=False,
p=0.5,
):
"""
Args:
max_objects: Maximum number of labels that can be zeroed out. Can be tuple, in this case it's [min, max]
image_fill_value: Fill value to use when filling image.
Can be 'inpaint' to apply inpaining (works only for 3-chahnel images)
mask_fill_value: Fill value to use when filling mask.
Targets:
image, mask
Image types:
uint8, float32
"""
super(MaskDropout, self).__init__(always_apply, p)
self.max_objects = to_tuple(max_objects, 1)
self.image_fill_value = image_fill_value
self.mask_fill_value = mask_fill_value
@property
def targets_as_params(self):
return ["mask"]
def get_params_dependent_on_targets(self, params):
mask = params["mask"]
label_image, num_labels = label(mask, return_num=True)
if num_labels == 0:
dropout_mask = None
else:
objects_to_drop = random.randint(self.max_objects[0], self.max_objects[1])
objects_to_drop = min(num_labels, objects_to_drop)
if objects_to_drop == num_labels:
dropout_mask = mask > 0
else:
labels_index = random.sample(range(1, num_labels + 1), objects_to_drop)
dropout_mask = np.zeros((mask.shape[0], mask.shape[1]), dtype=np.bool)
for label_index in labels_index:
dropout_mask |= label_image == label_index
params.update({"dropout_mask": dropout_mask})
return params
def apply(self, img, dropout_mask=None, **params):
if dropout_mask is None:
return img
if self.image_fill_value == "inpaint":
dropout_mask = dropout_mask.astype(np.uint8)
_, _, w, h = cv2.boundingRect(dropout_mask)
radius = min(3, max(w, h) // 2)
img = cv2.inpaint(img, dropout_mask, radius, cv2.INPAINT_NS)
else:
img = img.copy()
img[dropout_mask] = self.image_fill_value
return img
def apply_to_mask(self, img, dropout_mask=None, **params):
if dropout_mask is None:
return img
img = img.copy()
img[dropout_mask] = self.mask_fill_value
return img
def get_transform_init_args_names(self):
return ("max_objects", "image_fill_value", "mask_fill_value")
下图中标注目标为鸟所在区域(矩形框),以下是image_fill_value不同时的结果。

适用输入类型:image, mask, bboxes, keypoints
功能:保持原输入(does nothing)
# source code
class NoOp(DualTransform):
"""Does nothing"""
def apply_to_keypoint(self, keypoint: KeypointInternalType, **params) -> KeypointInternalType:
return keypoint
def apply_to_bbox(self, bbox: BoxInternalType, **params) -> BoxInternalType:
return bbox
def apply(self, img: np.ndarray, **params) -> np.ndarray:
return img
def apply_to_mask(self, img: np.ndarray, **params) -> np.ndarray:
return img
def get_transform_init_args_names(self) -> Tuple:
return ()
功能: 桶形 / 枕形畸变
参数说明:
- distort_limit (float, (float, float)): 若输入为单个数字,将转化为区间
(-distort_limit, distort_limit),默认值: (-0.05, 0.05)
distort_limit_sample > 0时是桶形畸变,distort_limit_sample < 0时是枕形畸变。 - shift_limit (float, (float, float))): 若输入为单个数字,将转化为区间
(-shift_limit, shift_limit),默认值: (-0.05, 0.05) - interpolation (OpenCV flag): opencv插值方法,可枚举值:cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4。默认值:cv2.INTER_LINEAR(mask使用的是cv2.INTER_NEAREST,代码已写死,未接受外部指定)
- border_mode (OpenCV flag): opencv边界像素补充方法。可枚举值:cv2.BORDER_CONSTANT(常数), cv2.BORDER_REPLICATE(复制), cv2.BORDER_REFLECT(镜像 ), cv2.BORDER_WRAP, cv2.BORDER_REFLECT_101(镜像)。默认值:cv2.BORDER_REFLECT_101
- value (int, float, list of ints, list of float): 边界像素补充值(仅限border_mode=cv2.BORDER_CONSTANT)
- mask_value (int, float, list of ints, list of float): 处理mask的边界像素补充值(仅限border_mode=cv2.BORDER_CONSTANT)
拓展阅读——border_mode详解:
OpenCV滤波之copyMakeBorder和borderInterpolate
OpenCV图像处理|1.16 卷积边界处理
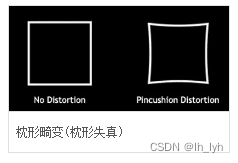
# source code
class OpticalDistortion(DualTransform):
"""
Args:
distort_limit (float, (float, float)): If distort_limit is a single float, the range
will be (-distort_limit, distort_limit). Default: (-0.05, 0.05).
shift_limit (float, (float, float))): If shift_limit is a single float, the range
will be (-shift_limit, shift_limit). Default: (-0.05, 0.05).
interpolation (OpenCV flag): flag that is used to specify the interpolation algorithm. Should be one of:
cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4.
Default: cv2.INTER_LINEAR.
border_mode (OpenCV flag): flag that is used to specify the pixel extrapolation method. Should be one of:
cv2.BORDER_CONSTANT, cv2.BORDER_REPLICATE, cv2.BORDER_REFLECT, cv2.BORDER_WRAP, cv2.BORDER_REFLECT_101.
Default: cv2.BORDER_REFLECT_101
value (int, float, list of ints, list of float): padding value if border_mode is cv2.BORDER_CONSTANT.
mask_value (int, float,
list of ints,
list of float): padding value if border_mode is cv2.BORDER_CONSTANT applied for masks.
Targets:
image, mask, bbox
Image types:
uint8, float32
"""
def __init__(
self,
distort_limit: ScaleFloatType = 0.05,
shift_limit: ScaleFloatType = 0.05,
interpolation: int = cv2.INTER_LINEAR,
border_mode: int = cv2.BORDER_REFLECT_101,
value: Optional[ImageColorType] = None,
mask_value: Optional[ImageColorType] = None,
always_apply: bool = False,
p: float = 0.5,
):
super(OpticalDistortion, self).__init__(always_apply, p)
self.shift_limit = to_tuple(shift_limit)
self.distort_limit = to_tuple(distort_limit)
self.interpolation = interpolation
self.border_mode = border_mode
self.value = value
self.mask_value = mask_value
def apply(
self, img: np.ndarray, k: int = 0, dx: int = 0, dy: int = 0, interpolation: int = cv2.INTER_LINEAR, **params
) -> np.ndarray:
return F.optical_distortion(img, k, dx, dy, interpolation, self.border_mode, self.value)
def apply_to_mask(self, img: np.ndarray, k: int = 0, dx: int = 0, dy: int = 0, **params) -> np.ndarray:
return F.optical_distortion(img, k, dx, dy, cv2.INTER_NEAREST, self.border_mode, self.mask_value)
def apply_to_bbox(self, bbox: BoxInternalType, k: int = 0, dx: int = 0, dy: int = 0, **params) -> BoxInternalType:
rows, cols = params["rows"], params["cols"]
mask = np.zeros((rows, cols), dtype=np.uint8)
bbox_denorm = F.denormalize_bbox(bbox, rows, cols)
x_min, y_min, x_max, y_max = bbox_denorm[:4]
x_min, y_min, x_max, y_max = int(x_min), int(y_min), int(x_max), int(y_max)
mask[y_min:y_max, x_min:x_max] = 1
mask = F.optical_distortion(mask, k, dx, dy, cv2.INTER_NEAREST, self.border_mode, self.mask_value)
bbox_returned = bbox_from_mask(mask)
bbox_returned = F.normalize_bbox(bbox_returned, rows, cols)
return bbox_returned
def get_params(self):
return {
"k": random.uniform(self.distort_limit[0], self.distort_limit[1]),
"dx": round(random.uniform(self.shift_limit[0], self.shift_limit[1])),
"dy": round(random.uniform(self.shift_limit[0], self.shift_limit[1])),
}
def get_transform_init_args_names(self):
return (
"distort_limit",
"shift_limit",
"interpolation",
"border_mode",
"value",
"mask_value",
)
下图为可视化结果,为变化明显,参数设置较大。默认参数变化很微小。
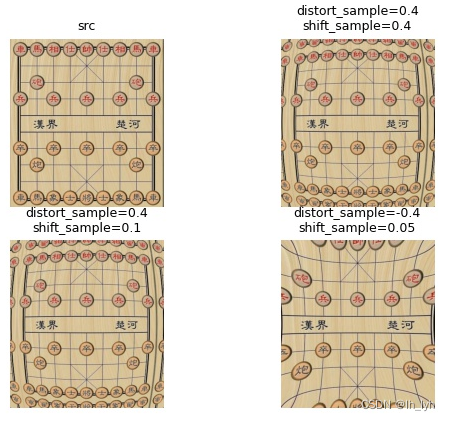
功能: 填充图像边缘到指定尺寸。(若图像大小大于指定尺寸,不进行任何操作,返回原图)
参数说明:
-
min_height ,min_width :结果图像的最小尺寸
-
position (Union[str, PositionType]):表示将原图置于什么位置,然后在其四周进行pad。(可以看code后面的可视化结果)
可枚举值:center,top_left,top_right,bottom_left,bottom_right,random -
border_mode (OpenCV flag): opencv边界像素补充方法。可枚举值:cv2.BORDER_CONSTANT(常数), cv2.BORDER_REPLICATE(复制), cv2.BORDER_REFLECT(镜像 ), cv2.BORDER_WRAP, cv2.BORDER_REFLECT_101(镜像)。默认值:cv2.BORDER_REFLECT_101
-
value (int, float, list of ints, list of float): 边界像素补充值(仅限border_mode=cv2.BORDER_CONSTANT)
-
mask_value (int, float, list of in, list of float): 处理mask的边界像素补充值(仅限border_mode=cv2.BORDER_CONSTANT)
# source code
class PadIfNeeded(DualTransform):
"""Pad side of the image / max if side is less than desired number.
Args:
min_height (int): minimal result image height.
min_width (int): minimal result image width.
pad_height_divisor (int): if not None, ensures image height is dividable by value of this argument.
pad_width_divisor (int): if not None, ensures image width is dividable by value of this argument.
position (Union[str, PositionType]): Position of the image. should be PositionType.CENTER or
PositionType.TOP_LEFT or PositionType.TOP_RIGHT or PositionType.BOTTOM_LEFT or PositionType.BOTTOM_RIGHT.
or PositionType.RANDOM. Default: PositionType.CENTER.
border_mode (OpenCV flag): OpenCV border mode.
value (int, float, list of int, list of float): padding value if border_mode is cv2.BORDER_CONSTANT.
mask_value (int, float,
list of int,
list of float): padding value for mask if border_mode is cv2.BORDER_CONSTANT.
p (float): probability of applying the transform. Default: 1.0.
Targets:
image, mask, bbox, keypoints
Image types:
uint8, float32
"""
class PositionType(Enum):
CENTER = "center"
TOP_LEFT = "top_left"
TOP_RIGHT = "top_right"
BOTTOM_LEFT = "bottom_left"
BOTTOM_RIGHT = "bottom_right"
RANDOM = "random"
def __init__(
self,
min_height: Optional[int] = 1024,
min_width: Optional[int] = 1024,
pad_height_divisor: Optional[int] = None,
pad_width_divisor: Optional[int] = None,
position: Union[PositionType, str] = PositionType.CENTER,
border_mode: int = cv2.BORDER_REFLECT_101,
value: Optional[ImageColorType] = None,
mask_value: Optional[ImageColorType] = None,
always_apply: bool = False,
p: float = 1.0,
):
if (min_height is None) == (pad_height_divisor is None):
raise ValueError("Only one of 'min_height' and 'pad_height_divisor' parameters must be set")
if (min_width is None) == (pad_width_divisor is None):
raise ValueError("Only one of 'min_width' and 'pad_width_divisor' parameters must be set")
super(PadIfNeeded, self).__init__(always_apply, p)
self.min_height = min_height
self.min_width = min_width
self.pad_width_divisor = pad_width_divisor
self.pad_height_divisor = pad_height_divisor
self.position = PadIfNeeded.PositionType(position)
self.border_mode = border_mode
self.value = value
self.mask_value = mask_value
def update_params(self, params, **kwargs):
params = super(PadIfNeeded, self).update_params(params, **kwargs)
rows = params["rows"]
cols = params["cols"]
if self.min_height is not None:
if rows < self.min_height:
h_pad_top = int((self.min_height - rows) / 2.0)
h_pad_bottom = self.min_height - rows - h_pad_top
else:
h_pad_top = 0
h_pad_bottom = 0
else:
pad_remained = rows % self.pad_height_divisor
pad_rows = self.pad_height_divisor - pad_remained if pad_remained > 0 else 0
h_pad_top = pad_rows // 2
h_pad_bottom = pad_rows - h_pad_top
if self.min_width is not None:
if cols < self.min_width:
w_pad_left = int((self.min_width - cols) / 2.0)
w_pad_right = self.min_width - cols - w_pad_left
else:
w_pad_left = 0
w_pad_right = 0
else:
pad_remainder = cols % self.pad_width_divisor
pad_cols = self.pad_width_divisor - pad_remainder if pad_remainder > 0 else 0
w_pad_left = pad_cols // 2
w_pad_right = pad_cols - w_pad_left
h_pad_top, h_pad_bottom, w_pad_left, w_pad_right = self.__update_position_params(
h_top=h_pad_top, h_bottom=h_pad_bottom, w_left=w_pad_left, w_right=w_pad_right
)
params.update(
{
"pad_top": h_pad_top,
"pad_bottom": h_pad_bottom,
"pad_left": w_pad_left,
"pad_right": w_pad_right,
}
)
return params
def apply(
self, img: np.ndarray, pad_top: int = 0, pad_bottom: int = 0, pad_left: int = 0, pad_right: int = 0, **params
) -> np.ndarray:
return F.pad_with_params(
img,
pad_top,
pad_bottom,
pad_left,
pad_right,
border_mode=self.border_mode,
value=self.value,
)
def apply_to_mask(
self, img: np.ndarray, pad_top: int = 0, pad_bottom: int = 0, pad_left: int = 0, pad_right: int = 0, **params
) -> np.ndarray:
return F.pad_with_params(
img,
pad_top,
pad_bottom,
pad_left,
pad_right,
border_mode=self.border_mode,
value=self.mask_value,
)
def apply_to_bbox(
self,
bbox: BoxInternalType,
pad_top: int = 0,
pad_bottom: int = 0,
pad_left: int = 0,
pad_right: int = 0,
rows: int = 0,
cols: int = 0,
**params
) -> BoxInternalType:
x_min, y_min, x_max, y_max = denormalize_bbox(bbox, rows, cols)[:4]
bbox = x_min + pad_left, y_min + pad_top, x_max + pad_left, y_max + pad_top
return normalize_bbox(bbox, rows + pad_top + pad_bottom, cols + pad_left + pad_right)
def apply_to_keypoint(
self,
keypoint: KeypointInternalType,
pad_top: int = 0,
pad_bottom: int = 0,
pad_left: int = 0,
pad_right: int = 0,
**params
) -> KeypointInternalType:
x, y, angle, scale = keypoint[:4]
return x + pad_left, y + pad_top, angle, scale
def get_transform_init_args_names(self):
return (
"min_height",
"min_width",
"pad_height_divisor",
"pad_width_divisor",
"border_mode",
"value",
"mask_value",
)
def __update_position_params(
self, h_top: int, h_bottom: int, w_left: int, w_right: int
) -> Tuple[int, int, int, int]:
if self.position == PadIfNeeded.PositionType.TOP_LEFT:
h_bottom += h_top
w_right += w_left
h_top = 0
w_left = 0
elif self.position == PadIfNeeded.PositionType.TOP_RIGHT:
h_bottom += h_top
w_left += w_right
h_top = 0
w_right = 0
elif self.position == PadIfNeeded.PositionType.BOTTOM_LEFT:
h_top += h_bottom
w_right += w_left
h_bottom = 0
w_left = 0
elif self.position == PadIfNeeded.PositionType.BOTTOM_RIGHT:
h_top += h_bottom
w_left += w_right
h_bottom = 0
w_right = 0
elif self.position == PadIfNeeded.PositionType.RANDOM:
h_pad = h_top + h_bottom
w_pad = w_left + w_right
h_top = random.randint(0, h_pad)
h_bottom = h_pad - h_top
w_left = random.randint(0, w_pad)
w_right = w_pad - w_left
return h_top, h_bottom, w_left, w_right
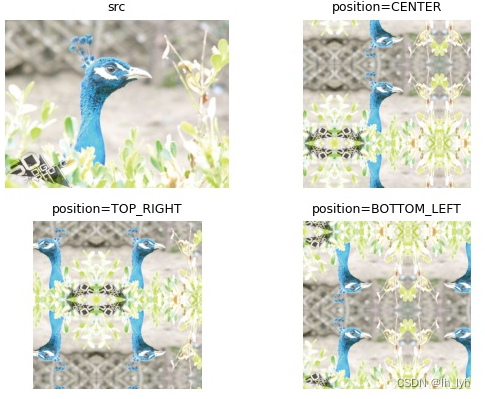
功能: 随机四点透视变换
参数说明:
- scale (float or (float, float)): 正态分布的标准差,用于控制新的子图像corners与完整图像corners的距离。
如果输入为单个数字,将转化为区间(0, scale),默认值:(0.05, 0.1) - keep_size (bool): 应用透视变换后是否将图像调整回原始大小。建议使用默认值True,若设为False,返回的图像是一个list,不是数组array,并且可能会有不同的shape。
- pad_mode(OpenCV flag): opencv边界像素补充方法。可枚举值:cv2.BORDER_CONSTANT(常数), cv2.BORDER_REPLICATE(复制), cv2.BORDER_REFLECT(镜像 ), cv2.BORDER_WRAP, cv2.BORDER_REFLECT_101(镜像)。默认值:cv2.BORDER_CONSTANT
- pad_val(int, float, list of ints, list of float): 边界像素补充值(仅限border_mode=cv2.BORDER_CONSTANT),默认值:0
- mask_pad_val(int, float, list of in, list of float): 处理mask的边界像素补充值(仅限border_mode=cv2.BORDER_CONSTANT),默认值:0
- fit_output (bool): 如果为 True,透视变换后图像平面大小和位置将被调整为捕获整个图像。 (如果 keep_size 设置为 True,则随后调整图像大小。)否则,部分转换后的图像可能会在图像平面之外。 使用大比例值时不应将此设置设置为 True,因为它可能会导致非常大的图像。默认值:False
scale越大,透视变换的角度越大;
keep_size建议设为True,保证与原始图像大小一致;
fit_output建议设为False,设为True会有黑边。

功能: 随机裁剪
参数说明: height、width (int): 裁剪区域的宽高。
class RandomCrop(DualTransform):
"""Crop a random part of the input.
Args:
height (int): height of the crop.
width (int): width of the crop.
p (float): probability of applying the transform. Default: 1.
Targets:
image, mask, bboxes, keypoints
Image types:
uint8, float32
"""
def __init__(self, height, width, always_apply=False, p=1.0):
super().__init__(always_apply, p)
self.height = height
self.width = width
def apply(self, img, h_start=0, w_start=0, **params):
return F.random_crop(img, self.height, self.width, h_start, w_start)
def get_params(self):
return {"h_start": random.random(), "w_start": random.random()}
def apply_to_bbox(self, bbox, **params):
return F.bbox_random_crop(bbox, self.height, self.width, **params)
def apply_to_keypoint(self, keypoint, **params):
return F.keypoint_random_crop(keypoint, self.height, self.width, **params)
def get_transform_init_args_names(self):
return ("height", "width")

功能: 在指定box区域附近裁剪图像。
参数说明:
-
max_part_shift (float, (float, float)): 高和宽方向上相对于
cropping_bbox最大偏移。 Default (0.3, 0.3). -
cropping_box_key (str): 指定的rect区域键值。 Default
cropping_bbox。rect区域坐标为四个数分别对应左上角x,y坐标,右下角x,y坐标。注意cropping_bbox未支持多个区域指定,从以下代码可以看出。bbox = params[self.cropping_bbox_key] h_max_shift = round((bbox[3] - bbox[1]) * self.max_part_shift[0]) w_max_shift = round((bbox[2] - bbox[0]) * self.max_part_shift[1])
class RandomCropNearBBox(DualTransform):
"""Crop bbox from image with random shift by x,y coordinates
Args:
max_part_shift (float, (float, float)): Max shift in `height` and `width` dimensions relative
to `cropping_bbox` dimension.
If max_part_shift is a single float, the range will be (max_part_shift, max_part_shift).
Default (0.3, 0.3).
cropping_box_key (str): Additional target key for cropping box. Default `cropping_bbox`
p (float): probability of applying the transform. Default: 1.
Targets:
image, mask, bboxes, keypoints
Image types:
uint8, float32
Examples:
>>> aug = Compose(RandomCropNearBBox(max_part_shift=(0.1, 0.5), cropping_box_key='test_box'),
>>> bbox_params=BboxParams("pascal_voc"))
>>> result = aug(image=image, bboxes=bboxes, test_box=[0, 5, 10, 20])
"""
def __init__(
self,
max_part_shift: Union[float, Tuple[float, float]] = (0.3, 0.3),
cropping_box_key: str = "cropping_bbox",
always_apply: bool = False,
p: float = 1.0,
):
super(RandomCropNearBBox, self).__init__(always_apply, p)
self.max_part_shift = to_tuple(max_part_shift, low=max_part_shift)
self.cropping_bbox_key = cropping_box_key
if min(self.max_part_shift) < 0 or max(self.max_part_shift) > 1:
raise ValueError("Invalid max_part_shift. Got: {}".format(max_part_shift))
def apply(
self, img: np.ndarray, x_min: int = 0, x_max: int = 0, y_min: int = 0, y_max: int = 0, **params
) -> np.ndarray:
return F.clamping_crop(img, x_min, y_min, x_max, y_max)
def get_params_dependent_on_targets(self, params: Dict[str, Any]) -> Dict[str, int]:
bbox = params[self.cropping_bbox_key]
h_max_shift = round((bbox[3] - bbox[1]) * self.max_part_shift[0])
w_max_shift = round((bbox[2] - bbox[0]) * self.max_part_shift[1])
x_min = bbox[0] - random.randint(-w_max_shift, w_max_shift)
x_max = bbox[2] + random.randint(-w_max_shift, w_max_shift)
y_min = bbox[1] - random.randint(-h_max_shift, h_max_shift)
y_max = bbox[3] + random.randint(-h_max_shift, h_max_shift)
x_min = max(0, x_min)
y_min = max(0, y_min)
return {"x_min": x_min, "x_max": x_max, "y_min": y_min, "y_max": y_max}
def apply_to_bbox(self, bbox: Tuple[float, float, float, float], **params) -> Tuple[float, float, float, float]:
return F.bbox_crop(bbox, **params)
def apply_to_keypoint(
self,
keypoint: Tuple[float, float, float, float],
x_min: int = 0,
x_max: int = 0,
y_min: int = 0,
y_max: int = 0,
**params
) -> Tuple[float, float, float, float]:
return F.crop_keypoint_by_coords(keypoint, crop_coords=(x_min, y_min, x_max, y_max))
指定的box区域是小鸟坐标,所以裁剪得到的三张图都包含小鸟。

**功能:**将图像分块,并随机打乱
参数说明: grid ((int, int)): 图像分为多少块,第一个数表示高度方向,第二个数表示宽度方向
# source code
class RandomGridShuffle(DualTransform):
"""
Random shuffle grid's cells on image.
Args:
grid ((int, int)): size of grid for splitting image.
Targets:
image, mask, keypoints
Image types:
uint8, float32
"""
def __init__(self,
grid: Tuple[int, int] = (3, 3),
always_apply: bool = False,
p: float = 0.5):
super(RandomGridShuffle, self).__init__(always_apply, p)
self.grid = grid
def apply(self, img: np.ndarray, tiles: np.ndarray = None, **params):
if tiles is not None:
img = F.swap_tiles_on_image(img, tiles)
return img
def apply_to_mask(self,
img: np.ndarray,
tiles: np.ndarray = None,
**params):
if tiles is not None:
img = F.swap_tiles_on_image(img, tiles)
return img
def apply_to_keypoint(self,
keypoint: Tuple[float, ...],
tiles: np.ndarray = None,
rows: int = 0,
cols: int = 0,
**params):
if tiles is None:
return keypoint
for (
current_left_up_corner_row,
current_left_up_corner_col,
old_left_up_corner_row,
old_left_up_corner_col,
height_tile,
width_tile,
) in tiles:
x, y = keypoint[:2]
if (old_left_up_corner_row <= y <
(old_left_up_corner_row + height_tile)) and (
old_left_up_corner_col <= x <
(old_left_up_corner_col + width_tile)):
x = x - old_left_up_corner_col + current_left_up_corner_col
y = y - old_left_up_corner_row + current_left_up_corner_row
keypoint = (x, y) + tuple(keypoint[2:])
break
return keypoint
def get_params_dependent_on_targets(self, params):
height, width = params["image"].shape[:2]
n, m = self.grid
if n <= 0 or m <= 0:
raise ValueError(
"Grid's values must be positive. Current grid [%s, %s]" %
(n, m))
if n > height // 2 or m > width // 2:
raise ValueError(
"Incorrect size cell of grid. Just shuffle pixels of image")
height_split = np.linspace(0, height, n + 1, dtype=np.int)
width_split = np.linspace(0, width, m + 1, dtype=np.int)
height_matrix, width_matrix = np.meshgrid(height_split,
width_split,
indexing="ij")
index_height_matrix = height_matrix[:-1, :-1]
index_width_matrix = width_matrix[:-1, :-1]
shifted_index_height_matrix = height_matrix[1:, 1:]
shifted_index_width_matrix = width_matrix[1:, 1:]
height_tile_sizes = shifted_index_height_matrix - index_height_matrix
width_tile_sizes = shifted_index_width_matrix - index_width_matrix
tiles_sizes = np.stack((height_tile_sizes, width_tile_sizes), axis=2)
index_matrix = np.indices((n, m))
new_index_matrix = np.stack(index_matrix, axis=2)
for bbox_size in np.unique(tiles_sizes.reshape(-1, 2), axis=0):
eq_mat = np.all(tiles_sizes == bbox_size, axis=2)
new_index_matrix[eq_mat] = random_utils.permutation(
new_index_matrix[eq_mat])
new_index_matrix = np.split(new_index_matrix, 2, axis=2)
old_x = index_height_matrix[new_index_matrix[0],
new_index_matrix[1]].reshape(-1)
old_y = index_width_matrix[new_index_matrix[0],
new_index_matrix[1]].reshape(-1)
shift_x = height_tile_sizes.reshape(-1)
shift_y = width_tile_sizes.reshape(-1)
curr_x = index_height_matrix.reshape(-1)
curr_y = index_width_matrix.reshape(-1)
tiles = np.stack([curr_x, curr_y, old_x, old_y, shift_x, shift_y],
axis=1)
return {"tiles": tiles}
@property
def targets_as_params(self):
return ["image"]
def get_transform_init_args_names(self):
return ("grid", )

功能: 裁剪图像某个区域,并缩放至指定尺寸。相似功能:RandomResizedCrop
参数说明:
height、width (int): 缩放的目标尺寸。
scale ((float, float)): 相对原始图像的裁剪范围。
ratio ((float, float)): 宽高比变化范围。
interpolation (OpenCV flag): 插值方式。 Should be one of:
cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4.
Default: cv2.INTER_LINEAR.
# source code
class RandomResizedCrop(_BaseRandomSizedCrop):
"""Torchvision's variant of crop a random part of the input and rescale it to some size.
Args:
height (int): height after crop and resize.
width (int): width after crop and resize.
scale ((float, float)): range of size of the origin size cropped
ratio ((float, float)): range of aspect ratio of the origin aspect ratio cropped
interpolation (OpenCV flag): flag that is used to specify the interpolation algorithm. Should be one of:
cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4.
Default: cv2.INTER_LINEAR.
p (float): probability of applying the transform. Default: 1.
Targets:
image, mask, bboxes, keypoints
Image types:
uint8, float32
"""
def __init__(
self,
height,
width,
scale=(0.08, 1.0),
ratio=(0.75, 1.3333333333333333),
interpolation=cv2.INTER_LINEAR,
always_apply=False,
p=1.0,
):
super(RandomResizedCrop, self).__init__(
height=height, width=width, interpolation=interpolation, always_apply=always_apply, p=p
)
self.scale = scale
self.ratio = ratio
def get_params_dependent_on_targets(self, params):
img = params["image"]
area = img.shape[0] * img.shape[1]
for _attempt in range(10):
target_area = random.uniform(*self.scale) * area
log_ratio = (math.log(self.ratio[0]), math.log(self.ratio[1]))
aspect_ratio = math.exp(random.uniform(*log_ratio))
# aspect_ratio = w / h
w = int(round(math.sqrt(target_area * aspect_ratio))) # skipcq: PTC-W0028
h = int(round(math.sqrt(target_area / aspect_ratio))) # skipcq: PTC-W0028
if 0 < w <= img.shape[1] and 0 < h <= img.shape[0]:
i = random.randint(0, img.shape[0] - h)
j = random.randint(0, img.shape[1] - w)
return {
"crop_height": h,
"crop_width": w,
"h_start": i * 1.0 / (img.shape[0] - h + 1e-10),
"w_start": j * 1.0 / (img.shape[1] - w + 1e-10),
}
# Fallback to central crop
in_ratio = img.shape[1] / img.shape[0]
if in_ratio < min(self.ratio):
w = img.shape[1]
h = int(round(w / min(self.ratio)))
elif in_ratio > max(self.ratio):
h = img.shape[0]
w = int(round(h * max(self.ratio)))
else: # whole image
w = img.shape[1]
h = img.shape[0]
i = (img.shape[0] - h) // 2
j = (img.shape[1] - w) // 2
return {
"crop_height": h,
"crop_width": w,
"h_start": i * 1.0 / (img.shape[0] - h + 1e-10),
"w_start": j * 1.0 / (img.shape[1] - w + 1e-10),
}
def get_params(self):
return {}
@property
def targets_as_params(self):
return ["image"]
def get_transform_init_args_names(self):
return "height", "width", "scale", "ratio", "interpolation"

功能: 0次或多次旋转图片90度,即对原图进行0°,90°,180°,270°随机旋转。
class RandomRotate90(DualTransform):
"""Randomly rotate the input by 90 degrees zero or more times.
Args:
p (float): probability of applying the transform. Default: 0.5.
Targets:
image, mask, bboxes, keypoints
Image types:
uint8, float32
"""
def apply(self, img, factor=0, **params):
"""
Args:
factor (int): number of times the input will be rotated by 90 degrees.
"""
return np.ascontiguousarray(np.rot90(img, factor))
def get_params(self):
# Random int in the range [0, 3]
return {"factor": random.randint(0, 3)}
def apply_to_bbox(self, bbox, factor=0, **params):
return F.bbox_rot90(bbox, factor, **params)
def apply_to_keypoint(self, keypoint, factor=0, **params):
return F.keypoint_rot90(keypoint, factor, **params)
def get_transform_init_args_names(self):
return ()
下图是随机旋转3次结果。

功能: 随机缩放图像,返回图像的尺寸已改变。
参数说明:
- scale_limit ((float, float) or float): 缩放因子变化范围。若输入为单个数字,将转化为区间
(1 - scale_limit, 1 + scale_limit)。应用的缩放因子将在此区间内随机采样获取。 默认缩放范围: (0.9, 1.1).scale_limit =0.1 => to_tuple(scale_limit, bias=1.0) => (0.9, 1.1)。注意bias=1.0,实际缩放范围为输入参数区间+1。 - interpolation (OpenCV flag): 插值方法。Default: cv2.INTER_LINEAR.
可枚举值:cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4.
class RandomScale(DualTransform):
"""Randomly resize the input. Output image size is different from the input image size.
Args:
scale_limit ((float, float) or float): scaling factor range. If scale_limit is a single float value, the
range will be (1 - scale_limit, 1 + scale_limit). Default: (0.9, 1.1).
interpolation (OpenCV flag): flag that is used to specify the interpolation algorithm. Should be one of:
cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4.
Default: cv2.INTER_LINEAR.
p (float): probability of applying the transform. Default: 0.5.
Targets:
image, mask, bboxes, keypoints
Image types:
uint8, float32
"""
def __init__(self, scale_limit=0.1, interpolation=cv2.INTER_LINEAR, always_apply=False, p=0.5):
super(RandomScale, self).__init__(always_apply, p)
self.scale_limit = to_tuple(scale_limit, bias=1.0)
self.interpolation = interpolation
def get_params(self):
return {"scale": random.uniform(self.scale_limit[0], self.scale_limit[1])}
def apply(self, img, scale=0, interpolation=cv2.INTER_LINEAR, **params):
return F.scale(img, scale, interpolation)
def apply_to_bbox(self, bbox, **params):
# Bounding box coordinates are scale invariant
return bbox
def apply_to_keypoint(self, keypoint, scale=0, **params):
return F.keypoint_scale(keypoint, scale, scale)
def get_transform_init_args(self):
return {"interpolation": self.interpolation, "scale_limit": to_tuple(self.scale_limit, bias=-1.0)}
注意输入参数与实际缩放的变换关系。下图中显示的参数为输入参数。

功能: 随机裁剪+缩放,裁剪区域确保所有bboxes包含在内。
参数说明:
-
height、width (int): 缩放的目标尺寸。
-
erosion_rate (float): 高度方向侵蚀率。宽度等比例计算。
img_h, img_w = params["image"].shape[:2] if len(params["bboxes"]) == 0: # less likely, this class is for use with bboxes. erosive_h = int(img_h * (1.0 - self.erosion_rate)) crop_height = img_h if erosive_h >= img_h else random.randint(erosive_h, img_h) crop_width = int(crop_height * img_w / img_h) -
interpolation (OpenCV flag): 插值方式。 可枚举值:cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4. Default: cv2.INTER_LINEAR.
class RandomSizedBBoxSafeCrop(DualTransform):
"""Crop a random part of the input and rescale it to some size without loss of bboxes.
Args:
height (int): height after crop and resize.
width (int): width after crop and resize.
erosion_rate (float): erosion rate applied on input image height before crop.
interpolation (OpenCV flag): flag that is used to specify the interpolation algorithm. Should be one of:
cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4.
Default: cv2.INTER_LINEAR.
p (float): probability of applying the transform. Default: 1.
Targets:
image, mask, bboxes
Image types:
uint8, float32
"""
def __init__(self, height, width, erosion_rate=0.0, interpolation=cv2.INTER_LINEAR, always_apply=False, p=1.0):
super(RandomSizedBBoxSafeCrop, self).__init__(always_apply, p)
self.height = height
self.width = width
self.interpolation = interpolation
self.erosion_rate = erosion_rate
def apply(self, img, crop_height=0, crop_width=0, h_start=0, w_start=0, interpolation=cv2.INTER_LINEAR, **params):
crop = F.random_crop(img, crop_height, crop_width, h_start, w_start)
return FGeometric.resize(crop, self.height, self.width, interpolation)
def get_params_dependent_on_targets(self, params):
img_h, img_w = params["image"].shape[:2]
if len(params["bboxes"]) == 0: # less likely, this class is for use with bboxes.
erosive_h = int(img_h * (1.0 - self.erosion_rate))
crop_height = img_h if erosive_h >= img_h else random.randint(erosive_h, img_h)
return {
"h_start": random.random(),
"w_start": random.random(),
"crop_height": crop_height,
"crop_width": int(crop_height * img_w / img_h),
}
# get union of all bboxes
x, y, x2, y2 = union_of_bboxes(
width=img_w, height=img_h, bboxes=params["bboxes"], erosion_rate=self.erosion_rate
)
# find bigger region
bx, by = x * random.random(), y * random.random()
bx2, by2 = x2 + (1 - x2) * random.random(), y2 + (1 - y2) * random.random()
bw, bh = bx2 - bx, by2 - by
crop_height = img_h if bh >= 1.0 else int(img_h * bh)
crop_width = img_w if bw >= 1.0 else int(img_w * bw)
h_start = np.clip(0.0 if bh >= 1.0 else by / (1.0 - bh), 0.0, 1.0)
w_start = np.clip(0.0 if bw >= 1.0 else bx / (1.0 - bw), 0.0, 1.0)
return {"h_start": h_start, "w_start": w_start, "crop_height": crop_height, "crop_width": crop_width}
def apply_to_bbox(self, bbox, crop_height=0, crop_width=0, h_start=0, w_start=0, rows=0, cols=0, **params):
return F.bbox_random_crop(bbox, crop_height, crop_width, h_start, w_start, rows, cols)
@property
def targets_as_params(self):
return ["image", "bboxes"]
def get_transform_init_args_names(self):
return ("height", "width", "erosion_rate", "interpolation")
下图bboxes设置了小鸟和蝴蝶的矩形框(坐标是归一化后的坐标)。可见三次随机crop都包含了小鸟和蝴蝶目标。

功能: 裁剪图像某个区域,并缩放至指定尺寸。与RandomResizedCrop功能类似,但是RandomResizedCrop自由度更高,宽高比是范围取值,而本变换RandomSizedCrop裁剪区域的宽高比是一个固定值。
参数说明:
min_max_height ((int, int)): 裁剪区域高度变化范围。
height、width (int): 缩放的目标尺寸。
scale ((float, float)): 相对原始图像的裁剪范围。
w2h_ratio (float): 裁剪区域宽高比。默认值:1.0
interpolation (OpenCV flag): 插值方式。 Should be one of:
cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4.
Default: cv2.INTER_LINEAR.
class RandomSizedCrop(_BaseRandomSizedCrop):
"""Crop a random part of the input and rescale it to some size.
Args:
min_max_height ((int, int)): crop size limits.
height (int): height after crop and resize.
width (int): width after crop and resize.
w2h_ratio (float): aspect ratio of crop.
interpolation (OpenCV flag): flag that is used to specify the interpolation algorithm. Should be one of:
cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4.
Default: cv2.INTER_LINEAR.
p (float): probability of applying the transform. Default: 1.
Targets:
image, mask, bboxes, keypoints
Image types:
uint8, float32
"""
def __init__(
self, min_max_height, height, width, w2h_ratio=1.0, interpolation=cv2.INTER_LINEAR, always_apply=False, p=1.0
):
super(RandomSizedCrop, self).__init__(
height=height, width=width, interpolation=interpolation, always_apply=always_apply, p=p
)
self.min_max_height = min_max_height
self.w2h_ratio = w2h_ratio
def get_params(self):
crop_height = random.randint(self.min_max_height[0], self.min_max_height[1])
return {
"h_start": random.random(),
"w_start": random.random(),
"crop_height": crop_height,
"crop_width": int(crop_height * self.w2h_ratio),
}
def get_transform_init_args_names(self):
return "min_max_height", "height", "width", "w2h_ratio", "interpolation"
下图参数设置:min_max_height=(50, 300), height=500, width=500, w2h_ratio=1.0。
因为w2h_ratio=1.0,所以三个结果图中crop区域都没有形变。(若height、width不一致,crop区域resize之后的结果图会有形变)

功能: resize图像到目标宽高,可指定插值方式,默认线性插值。
插值方法枚举:cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4
源码中resize之后,bounding box不变,keypoints对应比例变化。
作者注:这里bounding box应该是归一化后的坐标吧,所以不变。如果没有归一化,也是需要对应比例变化的。
class Resize(DualTransform):
"""Resize the input to the given height and width.
Args:
height (int): desired height of the output.
width (int): desired width of the output.
interpolation (OpenCV flag): flag that is used to specify the interpolation algorithm. Should be one of:
cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4.
Default: cv2.INTER_LINEAR.
p (float): probability of applying the transform. Default: 1.
Targets:
image, mask, bboxes, keypoints
Image types:
uint8, float32
"""
def __init__(self, height, width, interpolation=cv2.INTER_LINEAR, always_apply=False, p=1):
super(Resize, self).__init__(always_apply, p)
self.height = height
self.width = width
self.interpolation = interpolation
def apply(self, img, interpolation=cv2.INTER_LINEAR, **params):
return F.resize(img, height=self.height, width=self.width, interpolation=interpolation)
def apply_to_bbox(self, bbox, **params):
# Bounding box coordinates are scale invariant
return bbox
def apply_to_keypoint(self, keypoint, **params):
height = params["rows"]
width = params["cols"]
scale_x = self.width / width
scale_y = self.height / height
return F.keypoint_scale(keypoint, scale_x, scale_y)
def get_transform_init_args_names(self):
return ("height", "width", "interpolation")
# F.resize
@preserve_channel_dim
def resize(img, height, width, interpolation=cv2.INTER_LINEAR):
img_height, img_width = img.shape[:2]
if height == img_height and width == img_width:
return img
resize_fn = _maybe_process_in_chunks(cv2.resize, dsize=(width, height), interpolation=interpolation)
return resize_fn(img)
# F.keypoint_scale
def keypoint_scale(keypoint: KeypointInternalType, scale_x: float, scale_y: float) -> KeypointInternalType:
"""Scales a keypoint by scale_x and scale_y.
Args:
keypoint: A keypoint `(x, y, angle, scale)`.
scale_x: Scale coefficient x-axis.
scale_y: Scale coefficient y-axis.
Returns:
A keypoint `(x, y, angle, scale)`.
"""
x, y, angle, scale = keypoint[:4]
return x * scale_x, y * scale_y, angle, scale * max(scale_x, scale_y)
功能: 随机旋转任意角度。旋转后可能丢失部分内容。
参数说明:
- limit ((int, int) or int): 旋转角度变化范围。若输入为单个数字,将转化为区间
(-limit, limit). Default: (-90, 90) - interpolation (OpenCV flag): opencv插值方法,可枚举值:cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4。默认值:cv2.INTER_LINEAR(mask使用的是cv2.INTER_NEAREST,代码已写死,未接受外部指定)
- border_mode (OpenCV flag): opencv边界像素补充方法。可枚举值:cv2.BORDER_CONSTANT(常数), cv2.BORDER_REPLICATE(复制), cv2.BORDER_REFLECT(镜像 ), cv2.BORDER_WRAP(对边), cv2.BORDER_REFLECT_101(镜像)。默认值:cv2.BORDER_REFLECT_101
- value (int, float, list of ints, list of float): 边界像素补充值(仅限border_mode=cv2.BORDER_CONSTANT)
- mask_value (int, float, list of ints, list of float): 处理mask的边界像素补充值(仅限border_mode=cv2.BORDER_CONSTANT)
# source code
class Rotate(DualTransform):
"""Rotate the input by an angle selected randomly from the uniform distribution.
Args:
limit ((int, int) or int): range from which a random angle is picked. If limit is a single int
an angle is picked from (-limit, limit). Default: (-90, 90)
interpolation (OpenCV flag): flag that is used to specify the interpolation algorithm. Should be one of:
cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4.
Default: cv2.INTER_LINEAR.
border_mode (OpenCV flag): flag that is used to specify the pixel extrapolation method. Should be one of:
cv2.BORDER_CONSTANT, cv2.BORDER_REPLICATE, cv2.BORDER_REFLECT, cv2.BORDER_WRAP, cv2.BORDER_REFLECT_101.
Default: cv2.BORDER_REFLECT_101
value (int, float, list of ints, list of float): padding value if border_mode is cv2.BORDER_CONSTANT.
mask_value (int, float,
list of ints,
list of float): padding value if border_mode is cv2.BORDER_CONSTANT applied for masks.
p (float): probability of applying the transform. Default: 0.5.
Targets:
image, mask, bboxes, keypoints
Image types:
uint8, float32
"""
def __init__(
self,
limit=90,
interpolation=cv2.INTER_LINEAR,
border_mode=cv2.BORDER_REFLECT_101,
value=None,
mask_value=None,
always_apply=False,
p=0.5,
):
super(Rotate, self).__init__(always_apply, p)
self.limit = to_tuple(limit)
self.interpolation = interpolation
self.border_mode = border_mode
self.value = value
self.mask_value = mask_value
def apply(self, img, angle=0, interpolation=cv2.INTER_LINEAR, **params):
return F.rotate(img, angle, interpolation, self.border_mode, self.value)
def apply_to_mask(self, img, angle=0, **params):
return F.rotate(img, angle, cv2.INTER_NEAREST, self.border_mode, self.mask_value)
def get_params(self):
return {"angle": random.uniform(self.limit[0], self.limit[1])}
def apply_to_bbox(self, bbox, angle=0, **params):
return F.bbox_rotate(bbox, angle, params["rows"], params["cols"])
def apply_to_keypoint(self, keypoint, angle=0, **params):
return F.keypoint_rotate(keypoint, angle, **params)
def get_transform_init_args_names(self):
return ("limit", "interpolation", "border_mode", "value", "mask_value")

功能: 包含原始图像全部内容随机旋转任意角度。结果图可能存在artifacts,因为旋转后的图像可能会有不同的宽高比,调整大小后,它会以图像的原始宽高比恢复到原来的形状。
参数说明: (参数和Rotate一致)
- limit ((int, int) or int): 旋转角度变化范围。若输入为单个数字,将转化为区间
(-limit, limit). Default: (-90, 90) - interpolation (OpenCV flag): opencv插值方法,可枚举值:cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4。默认值:cv2.INTER_LINEAR(mask使用的是cv2.INTER_NEAREST,代码已写死,未接受外部指定)
- border_mode (OpenCV flag): opencv边界像素补充方法。可枚举值:cv2.BORDER_CONSTANT(常数), cv2.BORDER_REPLICATE(复制), cv2.BORDER_REFLECT(镜像 ), cv2.BORDER_WRAP(对边), cv2.BORDER_REFLECT_101(镜像)。默认值:cv2.BORDER_REFLECT_101
- value (int, float, list of ints, list of float): 边界像素补充值(仅限border_mode=cv2.BORDER_CONSTANT)
- mask_value (int, float, list of ints, list of float): 处理mask的边界像素补充值(仅限border_mode=cv2.BORDER_CONSTANT)
注意与Rotate对比。

功能: 应用仿射变换:平移、缩放、旋转
参数说明:
-
shift_limit ((float, float) or float): 平移因子变化范围(相对于图像宽高)。若输入为单个数字,将转化为区间
(-shift_limit, shift_limit)绝对值应在范围 [0, 1]内. Default: (-0.0625, 0.0625)。
优先使用shift_limit_x ,shift_limit_y 参数作为宽和高方向上的平移因子,若它们为None,则使用shift_limit 参数。self.shift_limit_x = to_tuple(shift_limit_x if shift_limit_x is not None else shift_limit) self.shift_limit_y = to_tuple(shift_limit_y if shift_limit_y is not None else shift_limit) dx = random.uniform(self.shift_limit_x[0], self.shift_limit_x[1]) dy = random.uniform(self.shift_limit_y[0], self.shift_limit_y[1]) -
scale_limit ((float, float) or float): 缩放因子变化范围。若输入为单个数字,将转化为区间
(-scale_limit, scale_limit)。Default: (-0.1, 0.1). -
rotate_limit ((int, int) or int): 旋转角度变化范围。若输入为单个数字,将转化为区间
(-rotate_limit, rotate_limit). Default: (-45, 45). -
interpolation (OpenCV flag): opencv插值方法,可枚举值:cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4。默认值:cv2.INTER_LINEAR(mask使用的是cv2.INTER_NEAREST,代码已写死,未接受外部指定)
-
border_mode (OpenCV flag): opencv边界像素补充方法。可枚举值:cv2.BORDER_CONSTANT(常数), cv2.BORDER_REPLICATE(复制), cv2.BORDER_REFLECT(镜像 ), cv2.BORDER_WRAP(对边), cv2.BORDER_REFLECT_101(镜像)。默认值:cv2.BORDER_REFLECT_101
-
value (int, float, list of ints, list of float): 边界像素补充值(仅限border_mode=cv2.BORDER_CONSTANT)
-
mask_value (int, float, list of ints, list of float): 处理mask的边界像素补充值(仅限border_mode=cv2.BORDER_CONSTANT)
-
shift_limit_x、shift_limit_y ((float, float) or float): 与 shift_limit 参数含义一致,分别表示x、y方向的平移因子。Default: None.
class ShiftScaleRotate(DualTransform):
"""Randomly apply affine transforms: translate, scale and rotate the input.
Args:
shift_limit ((float, float) or float): shift factor range for both height and width. If shift_limit
is a single float value, the range will be (-shift_limit, shift_limit). Absolute values for lower and
upper bounds should lie in range [0, 1]. Default: (-0.0625, 0.0625).
scale_limit ((float, float) or float): scaling factor range. If scale_limit is a single float value, the
range will be (-scale_limit, scale_limit). Default: (-0.1, 0.1).
rotate_limit ((int, int) or int): rotation range. If rotate_limit is a single int value, the
range will be (-rotate_limit, rotate_limit). Default: (-45, 45).
interpolation (OpenCV flag): flag that is used to specify the interpolation algorithm. Should be one of:
cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4.
Default: cv2.INTER_LINEAR.
border_mode (OpenCV flag): flag that is used to specify the pixel extrapolation method. Should be one of:
cv2.BORDER_CONSTANT, cv2.BORDER_REPLICATE, cv2.BORDER_REFLECT, cv2.BORDER_WRAP, cv2.BORDER_REFLECT_101.
Default: cv2.BORDER_REFLECT_101
value (int, float, list of int, list of float): padding value if border_mode is cv2.BORDER_CONSTANT.
mask_value (int, float,
list of int,
list of float): padding value if border_mode is cv2.BORDER_CONSTANT applied for masks.
shift_limit_x ((float, float) or float): shift factor range for width. If it is set then this value
instead of shift_limit will be used for shifting width. If shift_limit_x is a single float value,
the range will be (-shift_limit_x, shift_limit_x). Absolute values for lower and upper bounds should lie in
the range [0, 1]. Default: None.
shift_limit_y ((float, float) or float): shift factor range for height. If it is set then this value
instead of shift_limit will be used for shifting height. If shift_limit_y is a single float value,
the range will be (-shift_limit_y, shift_limit_y). Absolute values for lower and upper bounds should lie
in the range [0, 1]. Default: None.
p (float): probability of applying the transform. Default: 0.5.
Targets:
image, mask, keypoints
Image types:
uint8, float32
"""
def __init__(
self,
shift_limit=0.0625,
scale_limit=0.1,
rotate_limit=45,
interpolation=cv2.INTER_LINEAR,
border_mode=cv2.BORDER_REFLECT_101,
value=None,
mask_value=None,
shift_limit_x=None,
shift_limit_y=None,
always_apply=False,
p=0.5,
):
super(ShiftScaleRotate, self).__init__(always_apply, p)
self.shift_limit_x = to_tuple(shift_limit_x if shift_limit_x is not None else shift_limit)
self.shift_limit_y = to_tuple(shift_limit_y if shift_limit_y is not None else shift_limit)
self.scale_limit = to_tuple(scale_limit, bias=1.0)
self.rotate_limit = to_tuple(rotate_limit)
self.interpolation = interpolation
self.border_mode = border_mode
self.value = value
self.mask_value = mask_value
def apply(self, img, angle=0, scale=0, dx=0, dy=0, interpolation=cv2.INTER_LINEAR, **params):
return F.shift_scale_rotate(img, angle, scale, dx, dy, interpolation, self.border_mode, self.value)
def apply_to_mask(self, img, angle=0, scale=0, dx=0, dy=0, **params):
return F.shift_scale_rotate(img, angle, scale, dx, dy, cv2.INTER_NEAREST, self.border_mode, self.mask_value)
def apply_to_keypoint(self, keypoint, angle=0, scale=0, dx=0, dy=0, rows=0, cols=0, **params):
return F.keypoint_shift_scale_rotate(keypoint, angle, scale, dx, dy, rows, cols)
def get_params(self):
return {
"angle": random.uniform(self.rotate_limit[0], self.rotate_limit[1]),
"scale": random.uniform(self.scale_limit[0], self.scale_limit[1]),
"dx": random.uniform(self.shift_limit_x[0], self.shift_limit_x[1]),
"dy": random.uniform(self.shift_limit_y[0], self.shift_limit_y[1]),
}
def apply_to_bbox(self, bbox, angle, scale, dx, dy, **params):
return F.bbox_shift_scale_rotate(bbox, angle, scale, dx, dy, **params)
def get_transform_init_args(self):
return {
"shift_limit_x": self.shift_limit_x,
"shift_limit_y": self.shift_limit_y,
"scale_limit": to_tuple(self.scale_limit, bias=-1.0),
"rotate_limit": self.rotate_limit,
"interpolation": self.interpolation,
"border_mode": self.border_mode,
"value": self.value,
"mask_value": self.mask_value,
}
下图scale_limit=0, rotate_limit=0。shift_limit_x > 0时图像向右偏移,pad图像左侧。shift_limit_y > 0时图像向下偏移,pad图像上侧。反之<0时则向左向上偏移,pad图像的右方下方。

下图rotate_limit=0,shift_limit_x=(0., 0.), shift_limit_y=(0., 0.)。scale_limit_sample大于0时图像放大,小于0时图像缩小。

下图scale_limit=0,shift_limit_x=(0., 0.), shift_limit_y=(0., 0.)。旋转角度为逆时针旋转的角度。rotate_limit_sample大于0时图像向左旋转,小于0时图像向右旋转。

下图是默认参数随机生成的结果图。

功能: 保持缩放比例缩放图像,将短边调整为指定尺寸。相反调整长边的函数为LongestMaxSize
参数说明: max_size (int, list of int): maximum size of smallest side of the image after the transformation. 若输入为list,将从中随机选择一个数作为max_size。
interpolation (OpenCV flag): opencv插值方法,可枚举值:cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4。默认值:cv2.INTER_LINEAR
class SmallestMaxSize(DualTransform):
"""Rescale an image so that minimum side is equal to max_size, keeping the aspect ratio of the initial image.
Args:
max_size (int, list of int): maximum size of smallest side of the image after the transformation. When using a
list, max size will be randomly selected from the values in the list.
interpolation (OpenCV flag): interpolation method. Default: cv2.INTER_LINEAR.
p (float): probability of applying the transform. Default: 1.
Targets:
image, mask, bboxes, keypoints
Image types:
uint8, float32
"""
def __init__(
self,
max_size: Union[int, Sequence[int]] = 1024,
interpolation: int = cv2.INTER_LINEAR,
always_apply: bool = False,
p: float = 1,
):
super(SmallestMaxSize, self).__init__(always_apply, p)
self.interpolation = interpolation
self.max_size = max_size
def apply(
self, img: np.ndarray, max_size: int = 1024, interpolation: int = cv2.INTER_LINEAR, **params
) -> np.ndarray:
return F.smallest_max_size(img, max_size=max_size, interpolation=interpolation)
def apply_to_bbox(self, bbox: Sequence[float], **params) -> Sequence[float]:
return bbox
def apply_to_keypoint(self, keypoint: Sequence[float], max_size: int = 1024, **params) -> Sequence[float]:
height = params["rows"]
width = params["cols"]
scale = max_size / min([height, width])
return F.keypoint_scale(keypoint, scale, scale)
def get_params(self) -> Dict[str, int]:
return {"max_size": self.max_size if isinstance(self.max_size, int) else random.choice(self.max_size)}
def get_transform_init_args_names(self) -> Tuple[str, ...]:
return ("max_size", "interpolation")

功能:图像转置,行列交换

def transpose(img: np.ndarray) -> np.ndarray:
return img.transpose(1, 0, 2) if len(img.shape) > 2 else img.transpose(1, 0)
适用输入类型:image, mask, bboxes, keypoints
功能:输入沿x轴翻转

文章出处登录后可见!