数据集格式:VOC(xml)、YOLO(txt)、COCO(json)
本文主要对Label格式,以及LabelImg、Labelme、精灵标注助手Colabeler这常用的三种数据标注软件进行介绍。
1 Label格式
LabelImg是目标检测数据标注工具,可以标注标注两种格式:
VOC标签格式,标注的标签存储在xml文件
YOLO标签格式,标注的标签存储在txt文件中
COCO标签格式,标注的标签存储在json文件中
打开LabelImg后
我们在要标定数据的时候,一般是已经制定好了要标注物体的类别,这样在打开LabelImg之后,我们只要框定目标之后,选择要对应的标签即可。
labelimg JPEGImage predefined_classes.txt
说明:
JPEGImage 目录:存储的是图片的名字
Annotation 目录:用于存放标注图片的标签文件
predefined_classes.txt 文件:定义自己要标注的所有类别
predefined_classes.txt中定义的类别如下:
circle_red
circle_gray
rectangle_red
rectangle_gray
fingeprint_red
fingeprint_gray
other
执行命令,然后选择JPEGImage待标注图片数据文件夹,然后点选择文件夹,进行标注。
1.1 VOC数据格式(xml)
VOC数据集20分类。
VOC数据格式,会直接把每张图片标注的标签信息保存到一个xml文件中。
xml中标签格式:
<annotation>
图片的名字及基本信息
<folder>JPEGImage</folder>
<filename>000000.jpg</filename>
<path>D:\ZF\2_ZF_data\3_stamp_data\标注公章数据\JPEGImage\000000.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>500</width>
<height>402</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
每个目标的标定框坐标:即左上角的坐标和右下角的坐标
xmin
ymin
xmax
ymax
<object>
<name>circle_red</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>168</xmin>
<ymin>2</ymin>
<xmax>355</xmax>
<ymax>186</ymax>
</bndbox>
</object>
如果此图还有其他物体,重复<object></object>
</annotation>
1.2 YOLO数据格式(txt)
YOLO数据格式,会直接把每张图片标注的标签信息保存到一个txt文件中,同时会生成一个实际类别文件classes.txt,也保存到Annotation/classes.txt,用于实际标签与类别数字的对应。
txt中标签格式:
每一行代表标注的一个目标:5个数字分别是 class_num x y w h
0 0.521000 0.235075 0.362000 0.450249
0 0.213000 0.645522 0.418000 0.519900
0 0.794000 0.665423 0.376000 0.470149
第一个数表示 类别,数字0对应classes.txt中的第一个类circle_red,标注框的中心坐标(x,y),标注框的相对宽和高w,h。
实际类别文件classes.txt如下:
circle_red
circle_gray
rectangle_red
rectangle_gray
fingeprint_red
fingeprint_gray
other
1.3 COCO数据集格式(json)
COCO数据集80分类。
COCO数据集标注信息本身使用json文件存储(一个大的字典),其中又包含5个字段信息:info, licenses, images, annotations,categories,每个字段中又分为多个字典存储各自的信息,在实际中,‘info’ 和‘license’一般用不上,我们可以把它置空;COCO目标检测的标注信息中,box坐标信息是以x,y,w,h格式标注的,是GT框的左上角坐标(xmin, ymin)和宽高(width, height),和YOLO格式的标注信息有所不同。
image字段是包含多个image实例的列表,每一个image的实例是一个dict,其中最重要的是id字段,代表的是图片的id,每一张图片具有唯一的一个独特的id;width和height字段,代表的是图片的宽和高;file_name字段,代表的是图片的名字。
annotations字段是包含多个annotation实例的一个列表,annotation类型本身又包含了一系列的字段,如这个目标的category id和segmentation mask。segmentation格式取决于这个实例是一个单个的对象(即iscrowd=0,将使用polygons格式)还是一组对象(即iscrowd=1,将使用RLE格式)。
id字段:指的是这个annotation的一个id
image_id:等同于前面image字段里面的id。
category_id:类别id
segmentation:
area:标注区域面积
bbox:标注框,x,y为标注框的左上角坐标。
iscrowd:决定是RLE格式还是polygon格式。

categories字段是包含多个category实例的列表,而category结构体描述如下:
id:类别id
name:类别名字
supercatgory:
categories字段的id数,就是类别数。coco一共有80类,即id会递增到80。
1.4 VOC(XML)转换YOLO(TXT)
xml格式的标注信息中,box坐标信息是以(x,y)(x,y)格式标注的,也就是GroundTrueth框的左上角坐标(xmin, ymin)和右下角坐标(xmax, ymax);
txt格式的标注信息中,GT框坐标信息是以x,y,w,h格式标注的,也就是GT框的归一化中心点坐标(x, y)和归一化宽高(width, height)。
STEP1:maketxt.py,将原数据集划分为train、val和test三部分,其中train+val(组合成trainval部分)占总数据集90%,test部分占10%,train部分有占trainval部分的90%,因此,train: val: test = 8: 1: 1。
-import os
import random
'''
对图片数据集进行随机分类
以8: 1: 1的比例分为训练数据集,验证数据集和测试数据集
运行后在ImageSets文件夹中会出现四个文件
'''
ROOT = '../datasets/Fruit/'
trainval_percent = 0.9
train_percent = 0.9
xmlfilepath = ROOT + 'Annotations'
txtsavepath = ROOT + 'ImageSets'
# 获取该路径下所有文件的名称,存放在list中
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open(ROOT + 'ImageSets/trainval.txt', 'w')
ftest = open(ROOT + 'ImageSets/test.txt', 'w')
ftrain = open(ROOT + 'ImageSets/train.txt', 'w')
fval = open(ROOT + 'ImageSets/val.txt', 'w')
for i in list:
# 获取文件名称中.xml之前的序号
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
执行结果:
|——-Fruit
|---Annotations
|---001.xml
|---002.xml
... ...
|---340.xml
|---images
|---001.jpg
|---002.jpg
... ...
|---340.jpg
|---ImageSets
|---test.txt # 存放测试集图片名称
|---train.txt # 存放训练集图片名称
|---trainval.txt # 存放训练验证集图片名称
|---val.txt # 存放验证集图片名称
STEP2:voc2txt.py,将xml文件转化为txt文件,xml文件包含了对应的GT框以及图片长宽大小等信息,通过对其解析,并进行归一化最终读到txt文件中,同时生成train、val和test数据集中图片的绝对路径,用于索引到图片位置。
import xml.etree.ElementTree as ET # xml解析包
import os
sets = ['train', 'test', 'val']
classes = ['apple', 'banana', 'grape']
# 进行归一化操作
def convert(size, box): # size:(原图w,原图h) , box:(xmin,xmax,ymin,ymax)
dw = 1. / size[0] # 1/w
dh = 1. / size[1] # 1/h
x = (box[0] + box[1]) / 2.0 # 物体在图中的中心点x坐标
y = (box[2] + box[3]) / 2.0 # 物体在图中的中心点y坐标
w = box[1] - box[0] # 物体实际像素宽度
h = box[3] - box[2] # 物体实际像素高度
x = x * dw # 物体中心点x的坐标比(相当于 x/原图w)
w = w * dw # 物体宽度的宽度比(相当于 w/原图w)
y = y * dh # 物体中心点y的坐标比(相当于 y/原图h)
h = h * dh # 物体宽度的宽度比(相当于 h/原图h)
return (x, y, w, h) # 返回 相对于原图的物体中心点的x坐标比,y坐标比,宽度比,高度比,取值范围[0-1]
# year ='2012', 对应图片的id(文件名)
def convert_annotation(root, image_id):
'''
将对应文件名的xml文件转化为label文件,xml文件包含了对应的bunding框以及图片长宽大小等信息,
通过对其解析,然后进行归一化最终读到label文件中去,也就是说
一张图片文件对应一个xml文件,然后通过解析和归一化,能够将对应的信息保存到唯一一个label文件中去
labal文件中的格式: calss x y w h,同时,一张图片对应的类别有多个,所以对应的buinding的信息也有多个
'''
# 对应的通过year 找到相应的文件夹,并且打开相应image_id的xml文件,其对应bund文件
in_file = open(root + 'Annotations/%s.xml' %
(image_id), encoding='utf-8')
# 准备在对应的image_id 中写入对应的label,分别为
# <object-class> <x> <y> <width> <height>
out_file = open(root + 'labels/%s.txt' %
(image_id), 'w', encoding='utf-8')
# 解析xml文件
tree = ET.parse(in_file)
# 获得对应的键值对
root = tree.getroot()
# 获得图片的尺寸大小
size = root.find('size')
# 如果xml内的标记为空,增加判断条件
if size != None:
# 获得宽
w = int(size.find('width').text)
# 获得高
h = int(size.find('height').text)
# 遍历目标obj
for obj in root.iter('object'):
# 获得difficult
if obj.find('difficult'):
difficult = int(obj.find('difficult').text)
else:
difficult = 0
# 获得类别 =string 类型
cls = obj.find('name').text
# 如果类别不是对应在我们预定好的class文件中,或difficult==1则跳过
if cls not in classes or int(difficult) == 1:
continue
# 通过类别名称找到id
cls_id = classes.index(cls)
# 找到bndbox 对象
xmlbox = obj.find('bndbox')
# 获取对应的bndbox的数组 = ['xmin','xmax','ymin','ymax']
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
print(image_id, cls, b)
# 带入进行归一化操作
# w = 宽, h = 高, b= bndbox的数组 = ['xmin','xmax','ymin','ymax']
bb = convert((w, h), b)
# bb 对应的是归一化后的(x,y,w,h)
# 生成 calss x y w h 在label文件中
out_file.write(str(cls_id) + " " +
" ".join([str(a) for a in bb]) + '\n')
if __name__ == '__main__':
ROOT = '../datasets/Fruit/'
for image_set in sets:
'''
对所有的文件数据集进行遍历
做了两个工作:
1.将所有图片文件都遍历一遍,并且将其所有的全路径都写在对应的txt文件中去 方便定位
2.同时对所有的图片文件进行解析和转化,将其对应的 bundingbox 以及类别的信息全部解析写到 label 文件中去
最后再通过直接读取文件 就能找到对应的 label 信息
'''
# 先找labels文件夹如果不存在则创建
if not os.path.exists(ROOT + 'labels/'):
os.makedirs(ROOT + 'labels/')
# 读取在 ImageSets 中的train、test..等文件的内容
# 包含对应的文件名称
image_ids = open(ROOT + 'ImageSets/%s.txt' %
(image_set)).read().strip().split()
# 打开对应的.txt 文件对其进行写入准备
list_file = open(ROOT + '%s.txt' % (image_set), 'w')
# 将对应的文件_id以及全路径写进去并换行
for image_id in image_ids:
list_file.write(ROOT + 'images/%s.jpg\n' % (image_id))
# 开始解析xml文件的标注格式
convert_annotation(root=ROOT, image_id=image_id)
# 关闭文件
list_file.close()
结果如下:
|——-Fruit
|---Annotations
|---001.xml
|---002.xml
... ...
|---340.xml
|---images
|---001.jpg
|---002.jpg
... ...
|---340.jpg
|---ImageSets
|---test.txt # 存放测试集图片名称
|---train.txt # 存放训练集图片名称
|---trainval.txt # 存放训练验证集图片名称
|---val.txt # 存放验证集图片名称
|---labels
|---001.txt
|---002.txt
... ...
|---340.txt
|---test.txt # 存放测试集图片绝对路径
|---train.txt # 存放训练集图片绝对路径
|---val.txt # 存放验证集图片绝对路径
2. 标注工具
2.1 LabelImg:目标检测
Anaconda Prompt安装
conda create -n labelimg python=3.8
conda activate labelimg
pip install labelimg
标注步骤:
stpe1:打开软件
在Anaconda Prompt中进入labelimg环境
activate labelimg
stpe2:cd到指定文件夹下
stpe3:然后运行labelimg命令
(labelimg) D:\dataset>labelimg images labels.txt
images:存储图片的文件夹
labels.txt:指定要标注的所有类别
step4:标注前的设置
点击View显示如下图,然后把如下的几个选项勾上:
- Auto Save mode:切换到下一张图片时,会自动把上一张标注的图片标签自动保存下来,这样就不用每标注一样图片都按Ctrl+S保存一下了
- Display Labels:标注好图片之后,会把框和标签都显示出来
- Advanced Mode:这样标注的十字架就会一直悬浮在窗口,不用每次标完一个目标,再按一次W快捷键,调出标注的十字架
step5:设置常用快捷键
W:调出标注的十字架,开始标注
A:切换到上一张图片
D:切换到下一张图片
del:删除标注的矩形框
Ctrl+S:保存标注好的标签
Ctrl+鼠标滚轮:按住Ctrl,然后滚动鼠标滚轮,可以调整标注图片的显示大小
Ctrl+u:选择要标注图片的文件夹
Ctrl+r:选择标注好的label标签存放的文件夹 ↑→↓←:移动标注的矩形框的位置
step6:批量标注
点击Open Dir打开数据集所在文件夹
点击Create RectBox,创建矩形标注框,开始标注
选择标注类别
选择标注格式,labelimg中有三种标注格式,可以任选一种:
Pascal VOC(xml)
YOLO(txt)
CreateML(json)
点击Save,保存该张图片的标注文件
点击Next Image,进行下一张图片标注
2.2 Labelme:语义分割
Anaconda Prompt安装
conda create -n labelme python=3.8
conda activate labelme
pip install pyqt5 # pyqt5 can be installed via pip on python3
pip install labelme==3.16.2
标注步骤:
step1:打开软件
在Anaconda Prompt中进入labelme环境
activate labelme
stpe2:cd到指定文件夹下
step3:然后运行labelme命令
(labelme) D:\dataset>labelme --labels label.txt --output output
–labels:传入定义好的所有类别名称
–output:指定标注文件的保存地址
stpe4:批量标注
点击Open Dir打开数据集所在文件夹
点击Create Polygons,创建多边形标注形式,开始标注
选择标注类别
点击Save,保存该张图片的标注文件(json格式)
点击Next Image,进行下一张图片标注
2.3 精灵标注助手(Colabeler):实例分割&目标检测
相比于Labelme,LabelImg这些标注工具,精灵标注助手强大的地方在于支持实例分割、目标检测、文本标注、音频标注和视频标注等,并且完全免费,称得上业界良心!
精灵标注助手目前支持Windows/Mac/Linux平台,大家根据自己的系统下载相对应的版本。
标注步骤(以目标检测为例)
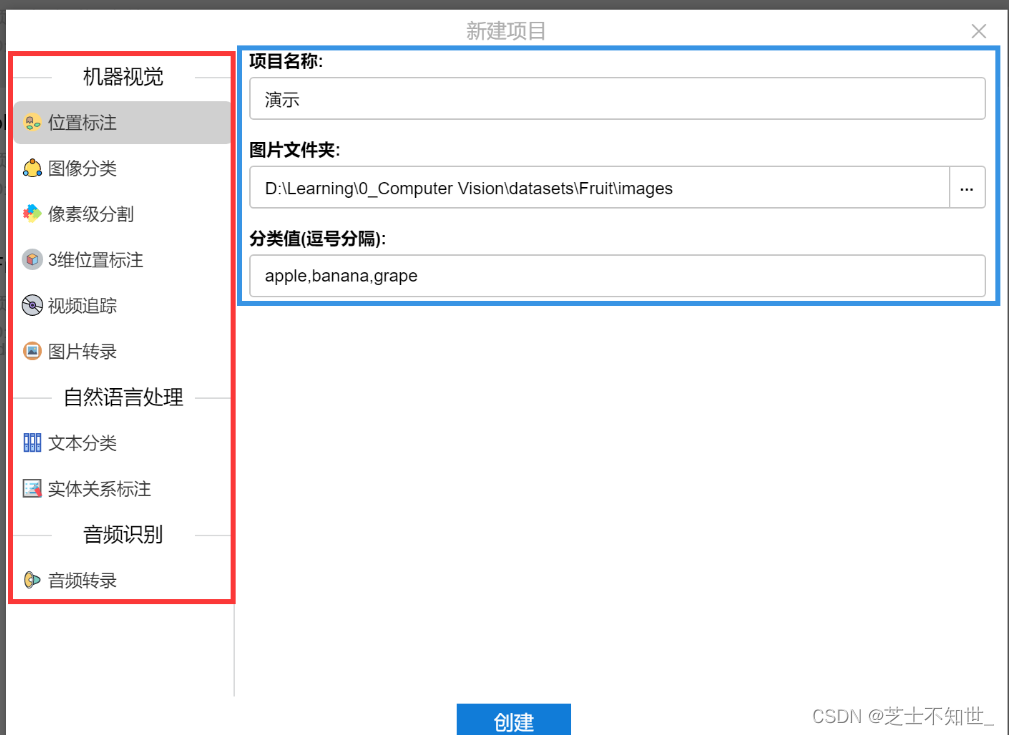
新建项目
打开软件,完成注册登录,点击左上角的新建,可以看到支持的项目类型非常多,这里选择第一个位置标注
然后再右侧填写相关信息,点击创建
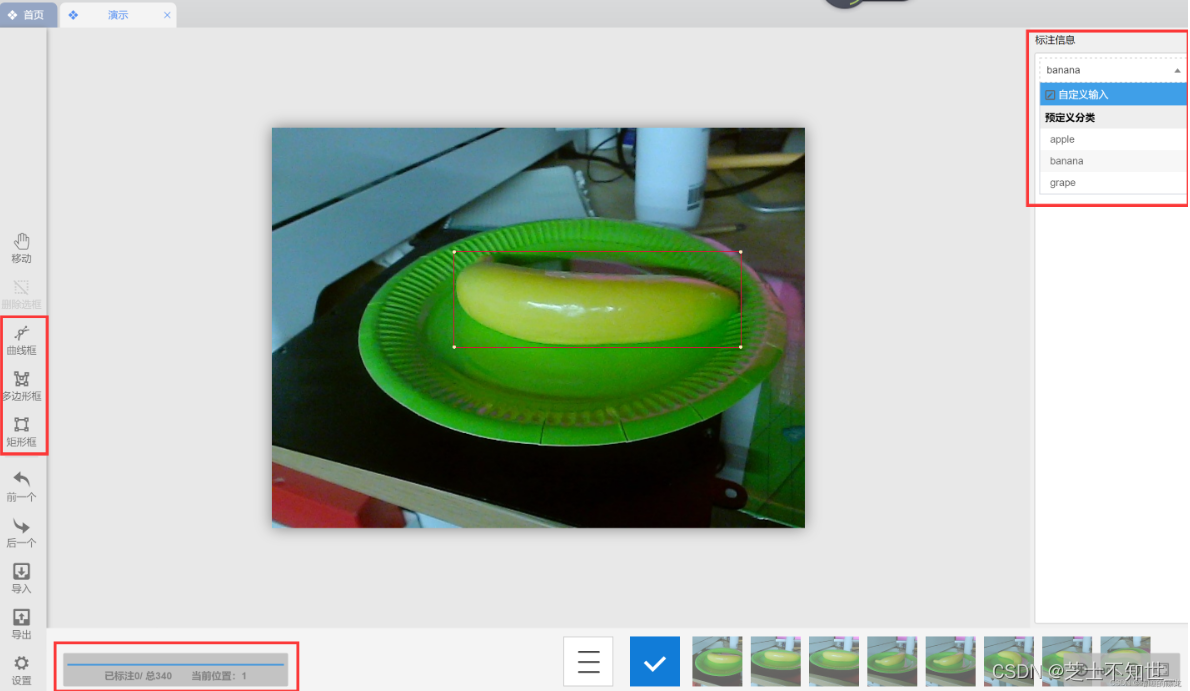
批量标注
可以选择三种标注框,这里选择矩形框,开始标注
之后在右上角选择标注信息
点击下方的对号√,或者Ctrl+s
然后可以点击左侧的前一个后一个,或者直接使用键盘的向左按钮和向右按钮来切换图片
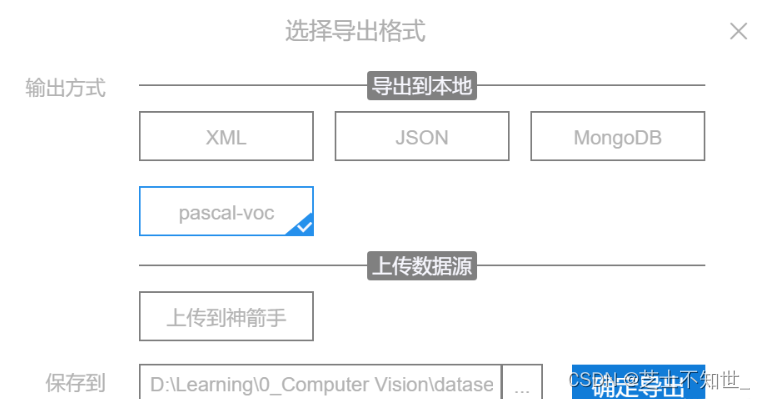
最后点击左侧下方的导出,可以选择标注文件的类型
文章出处登录后可见!