YOLO系列 — YOLOV7算法(三):YOLO V7算法train.py代码解析
先介绍下每个参数的含义(直接在代码上写吧)
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='', help='initial weights path') #初始化权重文件,如果有预训练模型,可以直接在此加载
parser.add_argument('--cfg', type=str, default=r'E:\work\People_Detect\yolov7-main\cfg\training\yolov7x.yaml', help='model.yaml path') #网络结构配置文件
parser.add_argument('--data', type=str, default='data/custom_data.yaml', help='data.yaml path') #训练数据集配置文件
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.p5.yaml', help='hyperparameters path') #超参数配置文件
parser.add_argument('--epochs', type=int, default=20) #训练迭代次数
parser.add_argument('--batch-size', type=int, default=2, help='total batch size for all GPUs') #训练批次大小
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes') #训练图片大小
parser.add_argument('--rect', action='store_true', help='rectangular training') #是否采用矩形训练,默认False
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training') #是否继续进行训练,如果设置成True,那么会自动寻找最近训练权重文件
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint') #不保存权重文件,默认False
parser.add_argument('--notest', action='store_true', help='only test final epoch') #不进行test,默认False
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check') #不自动调整anchor,默认False
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters') #是否进行超参数优化,默认是False,开启该选项,会加大训练时间,一般不需要
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket') #谷歌云盘bucket,一般不会用到
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training') #是否提前将训练数据进行缓存,默认是False
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training') #训练的时候是否选择图片权重进行训练
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu') #训练所使用的设备
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%') #是否进行多尺度训练,默认False
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class') #训练数据集是否只有一类
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer') #是否使用adam优化器
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode') #是否使用跨卡同步BN,在DDP模式使用
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify') #gpu编号
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers') #dataloader的最大worker数量
parser.add_argument('--project', default='runs/train', help='save to project/name') #训练结果保存路径
parser.add_argument('--entity', default=None, help='W&B entity') #wandb库对应的东西,一般不用管
parser.add_argument('--name', default='exp', help='save to project/name') #训练结果保存文件夹名称
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment') #判断下训练结果保存路径是否存在,如果存在的话,就不用重新创建
parser.add_argument('--quad', action='store_true', help='quad dataloader') #作用是兼顾速度和精度,选择折中的方案
parser.add_argument('--linear-lr', action='store_true', help='linear LR') #用于对学习速率进行调整,默认为 false,含义是通过余弦函数来降低学习率。
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon') #是否做标签平滑,防止出现过拟合
parser.add_argument('--upload_dataset', action='store_true', help='Upload dataset as W&B artifact table') #wandb库对应的东西
parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval for W&B') #wandb 库对应的东西
parser.add_argument('--save_period', type=int, default=-1, help='Log model after every "save_period" epoch') #用于记录训练日志信息
parser.add_argument('--artifact_alias', type=str, default="latest", help='version of dataset artifact to be used') #这一行参数表达的是想实现但还未实现的一个内容,忽略即可
opt = parser.parse_args()
这里,简单说下argparse这个库的用法吧,因为在detect.py和train.py中都是出现过的。
步骤:
1.parser = argparse.ArgumentParser()
2.parser.add_argument(需要传入的参数)
3.opt = parser.parse_args()
4.可以用**opt.**来调用对应的参数
# Set DDP variables
opt.world_size = int(os.environ['WORLD_SIZE']) if 'WORLD_SIZE' in os.environ else 1
opt.global_rank = int(os.environ['RANK']) if 'RANK' in os.environ else -1
set_logging(opt.global_rank)
跨卡多GPU训练,一般我们都是单机本地训练,所以用不到的,就不多讲了。
# Resume
wandb_run = check_wandb_resume(opt)
if opt.resume and not wandb_run: # resume an interrupted run
ckpt = opt.resume if isinstance(opt.resume, str) else get_latest_run() # specified or most recent path
assert os.path.isfile(ckpt), 'ERROR: --resume checkpoint does not exist'
apriori = opt.global_rank, opt.local_rank
with open(Path(ckpt).parent.parent / 'opt.yaml') as f:
opt = argparse.Namespace(**yaml.load(f, Loader=yaml.SafeLoader)) # replace
opt.cfg, opt.weights, opt.resume, opt.batch_size, opt.global_rank, opt.local_rank = '', ckpt, True, opt.total_batch_size, *apriori # reinstate
logger.info('Resuming training from %s' % ckpt)
else:
# opt.hyp = opt.hyp or ('hyp.finetune.yaml' if opt.weights else 'hyp.scratch.yaml')
opt.data, opt.cfg, opt.hyp = check_file(opt.data), check_file(opt.cfg), check_file(opt.hyp) # check files
assert len(opt.cfg) or len(opt.weights), 'either --cfg or --weights must be specified'
opt.img_size.extend([opt.img_size[-1]] * (2 - len(opt.img_size))) # extend to 2 sizes (train, test)
opt.name = 'evolve' if opt.evolve else opt.name
opt.save_dir = increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok | opt.evolve) # increment run
首先判断下在训练超参数中是否设置了继续训练,要是设置了然后判断下传入的是不是字符串,如果是字符串就认为传入的就是继续训练的权重文件,要是不是字符串那么就调用get_latest_run()函数来寻找last.pt,然后重新编写opt.yaml文件。要是没有设置继续训练,那么直接检测一些yaml文件是否存在,扩充下测试时候图片大小,最后创建下保存训练路径。
# DDP mode
opt.total_batch_size = opt.batch_size
device = select_device(opt.device, batch_size=opt.batch_size)
if opt.local_rank != -1:
assert torch.cuda.device_count() > opt.local_rank
torch.cuda.set_device(opt.local_rank)
device = torch.device('cuda', opt.local_rank)
dist.init_process_group(backend='nccl', init_method='env://') # distributed backend
assert opt.batch_size % opt.world_size == 0, '--batch-size must be multiple of CUDA device count'
opt.batch_size = opt.total_batch_size // opt.world_size
这里是采用DDP模式,一般用不上,就不管了~
# Hyperparameters
with open(opt.hyp) as f:
hyp = yaml.load(f, Loader=yaml.SafeLoader) # load hyps
解析超参数文件,将yaml文件格式转换成python内置字典格式,如下图所示。

# Train
logger.info(opt)
if not opt.evolve:
tb_writer = None # init loggers
if opt.global_rank in [-1, 0]:
prefix = colorstr('tensorboard: ')
logger.info(f"{prefix}Start with 'tensorboard --logdir {opt.project}', view at http://localhost:6006/")
tb_writer = SummaryWriter(opt.save_dir) # Tensorboard
train(hyp, opt, device, tb_writer)
这里判断是否进行超参数优化,其实一般我们都是默认False的,常规训练不需要该操作,效果已经很好了。而且如果进行超参数优化,训练时间会明显加长,所以这里我就没有把else模块的代码放出来了。下面直接进入train开始训练。
logger.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in hyp.items()))
save_dir, epochs, batch_size, total_batch_size, weights, rank = \
Path(opt.save_dir), opt.epochs, opt.batch_size, opt.total_batch_size, opt.weights, opt.global_rank
进行简单的赋值
# Directories
wdir = save_dir / 'weights'
wdir.mkdir(parents=True, exist_ok=True) # make dir
last = wdir / 'last.pt'
best = wdir / 'best.pt'
results_file = save_dir / 'results.txt'
创建权重文件保存路径,权重名字和训练日志txt文件
# Save run settings
with open(save_dir / 'hyp.yaml', 'w') as f:
yaml.dump(hyp, f, sort_keys=False)
with open(save_dir / 'opt.yaml', 'w') as f:
yaml.dump(vars(opt), f, sort_keys=False)
将训练的相关参数全部写入
# Configure
plots = not opt.evolve # create plots
cuda = device.type != 'cpu'
init_seeds(2 + rank)
with open(opt.data) as f:
data_dict = yaml.load(f, Loader=yaml.SafeLoader) # data dict
is_coco = opt.data.endswith('coco.yaml')
主要作用是解析data.yaml文件,判断训练集是否是coco数据集格式
loggers = {'wandb': None} # loggers dict
if rank in [-1, 0]:
opt.hyp = hyp # add hyperparameters
run_id = torch.load(weights).get('wandb_id') if weights.endswith('.pt') and os.path.isfile(weights) else None
wandb_logger = WandbLogger(opt, Path(opt.save_dir).stem, run_id, data_dict)
loggers['wandb'] = wandb_logger.wandb
data_dict = wandb_logger.data_dict
if wandb_logger.wandb:
weights, epochs, hyp = opt.weights, opt.epochs, opt.hyp # WandbLogger might update weights, epochs if resuming
nc = 1 if opt.single_cls else int(data_dict['nc']) # number of classes
names = ['item'] if opt.single_cls and len(data_dict['names']) != 1 else data_dict['names'] # class names
assert len(names) == nc, '%g names found for nc=%g dataset in %s' % (len(names), nc, opt.data) # check
这里主要是进行训练类别的计算。如果自定义数据集不止一个类别,但是又不小心将single_cls 设置为Ture的话,其实代码是不会报错的,但是这样就会在测试的时候不会正确的显示类别,所有的类别都变成了"items"。
# Model
pretrained = weights.endswith('.pt')
if pretrained:
with torch_distributed_zero_first(rank):
attempt_download(weights) # download if not found locally
ckpt = torch.load(weights, map_location=device) # load checkpoint
model = Model(opt.cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
exclude = ['anchor'] if (opt.cfg or hyp.get('anchors')) and not opt.resume else [] # exclude keys
state_dict = ckpt['model'].float().state_dict() # to FP32
state_dict = intersect_dicts(state_dict, model.state_dict(), exclude=exclude) # intersect
model.load_state_dict(state_dict, strict=False) # load
logger.info('Transferred %g/%g items from %s' % (len(state_dict), len(model.state_dict()), weights)) # report
else:
model = Model(opt.cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
with torch_distributed_zero_first(rank):
check_dataset(data_dict) # check
train_path = data_dict['train']
test_path = data_dict['val']
这部分代码首先是判断有没有传入预训练权重文件,分两类:
1.如果传入权重文件,直接model.load_state_dict加载模型
2.如果没有传入权重文件,创建模型实例,从头开始训练
这里,暂时先不讲网络结构相关的代码,等下篇blog单独来说说该部分~
最后,获取的train_path和test_path分别表示在data.yaml中训练数据集和测试数据集的地址。
# Freeze
freeze = [] # parameter names to freeze (full or partial)
for k, v in model.named_parameters():
v.requires_grad = True # train all layers
if any(x in k for x in freeze):
print('freezing %s' % k)
v.requires_grad = False
这部分代码是设置冻结层的。简单来说,就是冻结指定的层的权重,让他们在反向传播的时候不更新权重大小。作者这里列出来这部分代码的目的其实并不是鼓励使用冻结指定层,因为作者认为这样效果其实并不是很好。
# Optimizer
nbs = 64 # nominal batch size
accumulate = max(round(nbs / total_batch_size), 1) # accumulate loss before optimizing
hyp['weight_decay'] *= total_batch_size * accumulate / nbs # scale weight_decay
logger.info(f"Scaled weight_decay = {hyp['weight_decay']}")
nbs为模拟的batch_size; 就比如默认的话上面设置的opt.batch_size为16,这个nbs就为64,也就是模型梯度累积了64/16=4(accumulate)次之后再更新一次模型,变相的扩大了batch_size。
for k, v in model.named_modules():
if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter):
pg2.append(v.bias) # biases
if isinstance(v, nn.BatchNorm2d):
pg0.append(v.weight) # no decay
elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter):
pg1.append(v.weight) # apply decay
这里,先不着急解析代码,先简单来说下model.named_modules():
先说model.modules()迭代遍历模型的所有子层,而model.named_modules()不但返回模型的所有子层,还会返回这些层的名字。还有一个 model.parameters(),它的作用是迭代地返回模型的所有参数。
然后,用hasattr函数来判断遍历的每个层对象是否拥有相对应的属性,将所有参数分成三类:weight、bn, bias。
if opt.adam:
optimizer = optim.Adam(pg0, lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentum
else:
optimizer = optim.SGD(pg0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)
optimizer.add_param_group({'params': pg1, 'weight_decay': hyp['weight_decay']}) # add pg1 with weight_decay
optimizer.add_param_group({'params': pg2}) # add pg2 (biases)
logger.info('Optimizer groups: %g .bias, %g conv.weight, %g other' % (len(pg2), len(pg1), len(pg0)))
del pg0, pg1, pg2
选用优化器,并设置weights的优化方式。然后将其他的参数喂入优化器中。
if opt.linear_lr:
lf = lambda x: (1 - x / (epochs - 1)) * (1.0 - hyp['lrf']) + hyp['lrf'] # linear
else:
lf = one_cycle(1, hyp['lrf'], epochs) # cosine 1->hyp['lrf']
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
这里是设置学习率衰减方式,在训练参数那块opt.linear_lr默认的是False,所以最后还是使用的余弦退火方式进行衰减,相对应的函数是one_cycle。
# Image sizes
gs = max(int(model.stride.max()), 32) # grid size (max stride)
nl = model.model[-1].nl # number of detection layers (used for scaling hyp['obj'])
imgsz, imgsz_test = [check_img_size(x, gs) for x in opt.img_size] # verify imgsz are gs-multiples
获取网络的最大步长,预测头数量和训练及测试图片长宽大小。
# DP mode
if cuda and rank == -1 and torch.cuda.device_count() > 1:
model = torch.nn.DataParallel(model)
# SyncBatchNorm
if opt.sync_bn and cuda and rank != -1:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
logger.info('Using SyncBatchNorm()')
这块代码是跨卡训练,一般不考虑。
# Trainloader
dataloader, dataset = create_dataloader(train_path, imgsz, batch_size, gs, opt,
hyp=hyp, augment=True, cache=opt.cache_images, rect=opt.rect, rank=rank,
world_size=opt.world_size, workers=opt.workers,
image_weights=opt.image_weights, quad=opt.quad, prefix=colorstr('train: '))
mlc = np.concatenate(dataset.labels, 0)[:, 0].max() # max label class
nb = len(dataloader) # number of batches
assert mlc < nc, 'Label class %g exceeds nc=%g in %s. Possible class labels are 0-%g' % (mlc, nc, opt.data, nc - 1)
create_dataloader这部分代码是训练数据的读取,后面也是会单独拿出来解析,这里就跳过了。然后获取标签文件中所有类别数大小,如果与设定的类别数不一致就会报错。这里值得注意,dataset.labels是一个列表,内部一个element就是一个图片相对应的标签,而np.concatenate(dataset.labels, 0)就会将所有的标签的每行标签进行保存在一起,如下图所示:
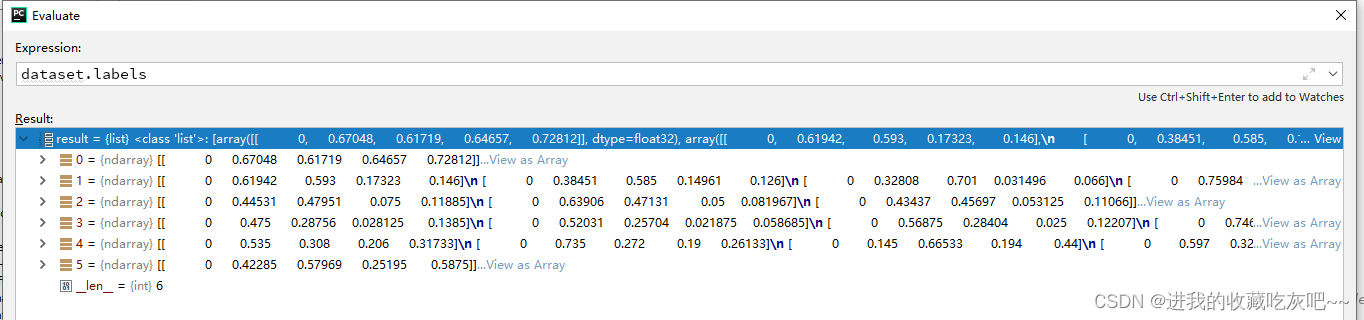
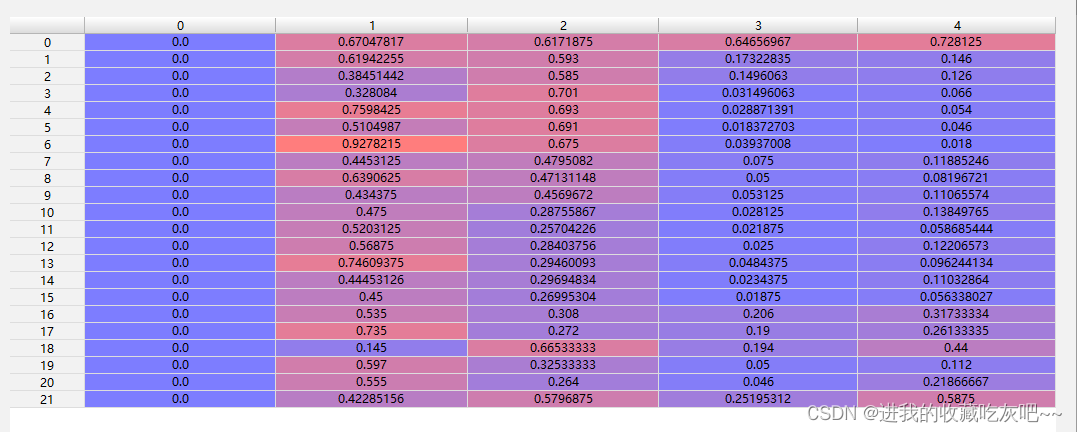
上图是dataset.labels,下图是np.concatenate(dataset.labels, 0)。
# Process 0
if rank in [-1, 0]:
testloader = create_dataloader(test_path, imgsz_test, batch_size * 2, gs, opt, # testloader
hyp=hyp, cache=opt.cache_images and not opt.notest, rect=True, rank=-1,
world_size=opt.world_size, workers=opt.workers,
pad=0.5, prefix=colorstr('val: '))[0]
if not opt.resume:
labels = np.concatenate(dataset.labels, 0)
c = torch.tensor(labels[:, 0]) # classes
# cf = torch.bincount(c.long(), minlength=nc) + 1. # frequency
# model._initialize_biases(cf.to(device))
if plots:
#plot_labels(labels, names, save_dir, loggers)
if tb_writer:
tb_writer.add_histogram('classes', c, 0)
# Anchors
if not opt.noautoanchor:
check_anchors(dataset, model=model, thr=hyp['anchor_t'], imgsz=imgsz)
model.half().float() # pre-reduce anchor precision
创建测试集dataloader(也是调用create_dataloader类,后面一起解析吧),然后将所有样本的标签拼接到一起shape为(total, 5),统计后做可视化,同时获得所有样本的类别,根据上面的统计对所有样本的类别,中心点xy位置,长宽wh做可视化。
check_anchors计算默认锚点anchor与数据集标签框的长宽比值,标签的长h宽w与anchor的长h_a宽w_a的比值, 即h/h_a, w/w_a都要在(1/hyp[‘anchor_t’], hyp[‘anchor_t’])是可以接受的,如果标签框满足上面条件的数量小于总数的99%,则根据k-mean算法聚类新的锚点anchor。
# Model parameters
hyp['box'] *= 3. / nl # scale to layers
hyp['cls'] *= nc / 80. * 3. / nl # scale to classes and layers
hyp['obj'] *= (imgsz / 640) ** 2 * 3. / nl # scale to image size and layers
hyp['label_smoothing'] = opt.label_smoothing
model.nc = nc # attach number of classes to model
model.hyp = hyp # attach hyperparameters to model
model.gr = 1.0 # iou loss ratio (obj_loss = 1.0 or iou)
model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) * nc # attach class weights
model.names = names
根据自己数据集的类别数设置分类损失的系数,位置损失的系数。设置类别数,超参数等操作
# Start training
t0 = time.time()
nw = max(round(hyp['warmup_epochs'] * nb), 1000) # number of warmup iterations, max(3 epochs, 1k iterations)
# nw = min(nw, (epochs - start_epoch) / 2 * nb) # limit warmup to < 1/2 of training
maps = np.zeros(nc) # mAP per class
results = (0, 0, 0, 0, 0, 0, 0) # P, R, mAP@.5, mAP@.5-.95, val_loss(box, obj, cls)
scheduler.last_epoch = start_epoch - 1 # do not move
scaler = amp.GradScaler(enabled=cuda)
compute_loss_ota = ComputeLossOTA(model) # init loss class
compute_loss = ComputeLoss(model) # init loss class
logger.info(f'Image sizes {imgsz} train, {imgsz_test} test\n'
f'Using {dataloader.num_workers} dataloader workers\n'
f'Logging results to {save_dir}\n'
f'Starting training for {epochs} epochs...')
torch.save(model, wdir / 'init.pt')
for epoch in range(start_epoch, epochs): # epoch ------------------------------------------------------------------
model.train()
首先计算下热身训练的迭代次数,然后model.train()开始训练。
文章出处登录后可见!