
1 Review💖
- 不可否认,深度森林的提出很大程度是受深度学习算法启发。现如今,深度学习算法在诸多领域都展示出了傲人的实力,周志华教授作为国内集成学习领域的先驱,则在借鉴了深度学习算法结构的基础上,提出了深度森林算法。我们可以说深度森林是深度学习算法的一种变种,但按照周教授的说法,更准确的来说,深度森林应该是集成学习的一个重大突破。
- 根据周志华教授的观点,深度神经网络的成功主要归结为三点,分别是逐层处理(layer-by-layer processing)、模型内特征变化(in-model feature transformation)以及模型复杂度(sufficient model complexity)。而在此基础之上,如果将神经网络中可微模块替换成不可微模块,例如随机森林,则能够在确保模型有效性和稳定性的基础上,减少模型对于反向传播的依赖。并且经过实验证明,采用类似神经网络的结果进行随机森林的集成,能够获得一个超参数效果稳定、算法复杂性可控的全新的模型——这个模型就是深度森林。
- 深度森林又名多粒度扫描的级联森林,这也是深度森林中最核心的两个概念,其一是级联森林,其二则是多粒度扫描。
- 深度森林算法原理详情请见:http://t.csdn.cn/0grSA
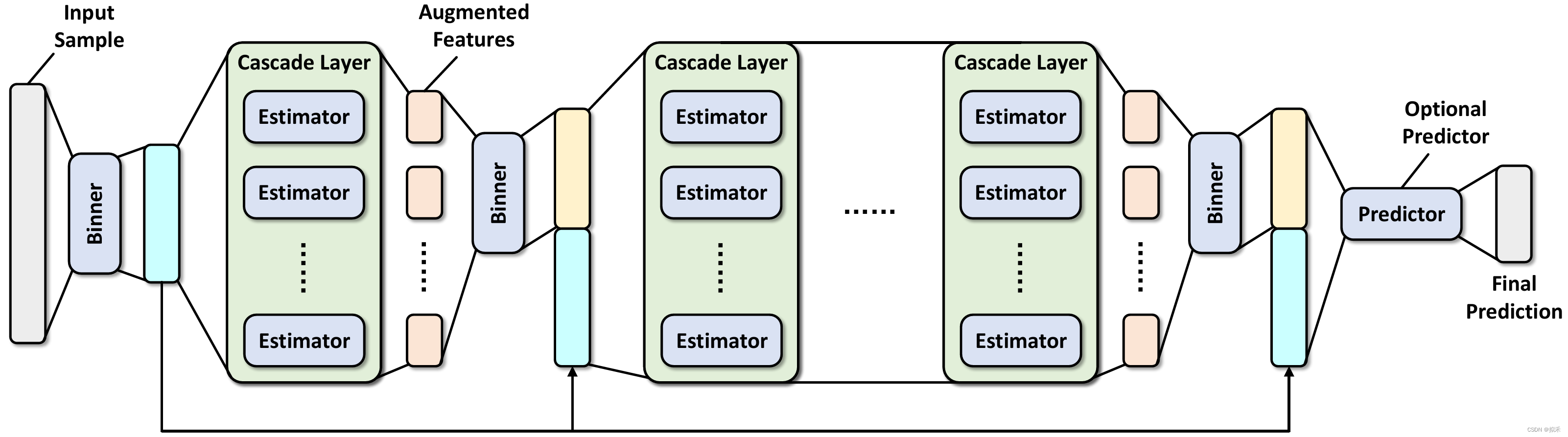
上图是深度森林模型的主要结构,其中Binner是用来减少构建决策树的分裂候选特征数量的类。
2 Installation and Use⭐️
快速安装:pip install deep-forest -i https://pypi.tuna.tsinghua.edu.cn/simple
from deepforest import CascadeForestClassifier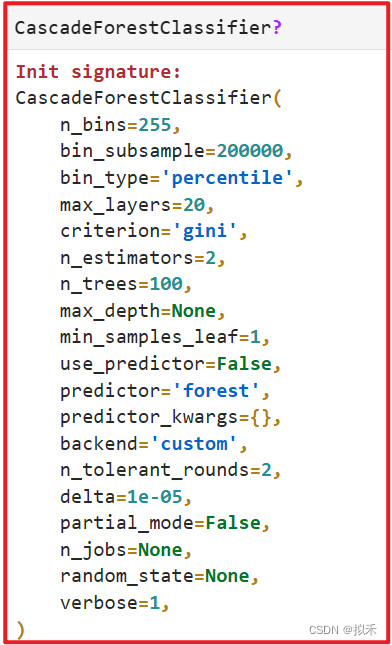
- 参数详情可见官方文档:API Reference — Deep Forest (DF21) documentation (deep-forest.readthedocs.io)
- 深度森林整体风格和sklearn非常一致
2.1 Classfication🔥
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from deepforest import CascadeForestClassifier
X, y = load_digits(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
model = CascadeForestClassifier(random_state=1)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
acc = accuracy_score(y_test, y_pred) * 100
print("\nTesting Accuracy: {:.3f} %".format(acc))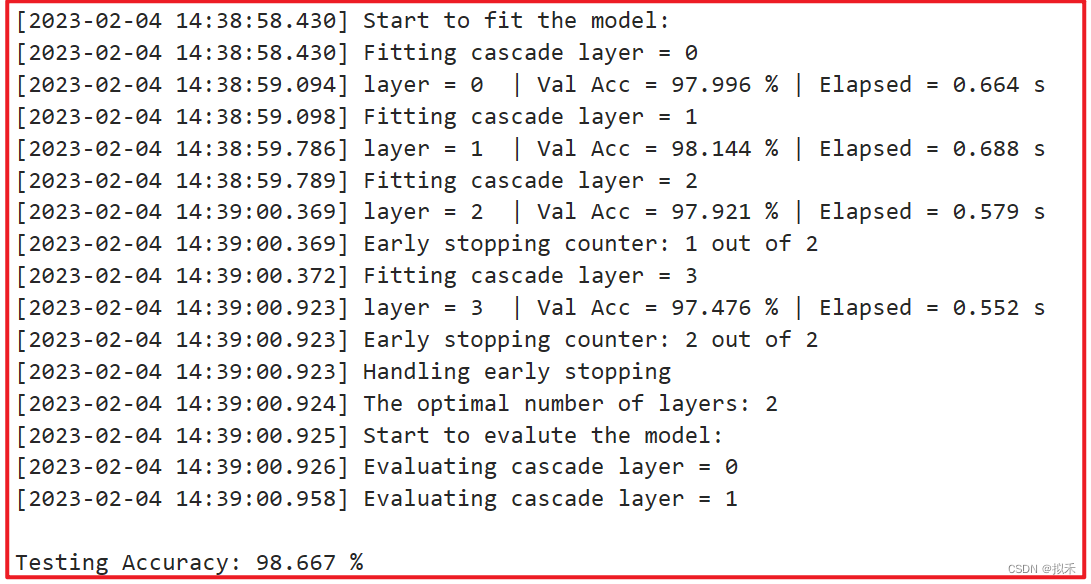
- 代码的运行过程中会输出一些中间信息。
- 尽管深度森林原理复杂,但实际的使用过程秉承了sklearn的一贯风格——代码简单,并且拥有一整套效果较好的初始化参数。
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.svm import SVC
X, y = load_digits(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
model = SVC(random_state=1)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
acc = accuracy_score(y_test, y_pred) * 100
print("\nTesting Accuracy: {:.3f} %".format(acc))
使用支持向量机SVC进行简单对比,效果相差不大,深度森林稍稍逊色。
2.2 Regression💘
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from deepforest import CascadeForestRegressor
X, y = load_boston(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
model = CascadeForestRegressor(random_state=1)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print("\nTesting MSE: {:.3f}".format(mse))回归问题使用的类是CascadeForestRegressor
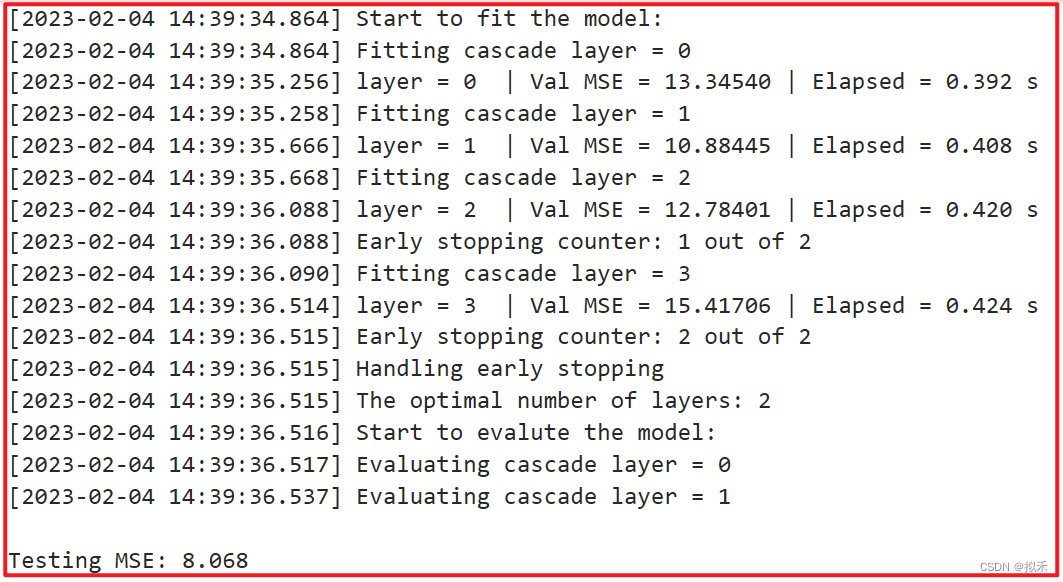
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.svm import SVR
X, y = load_boston(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
model = SVR()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print("\nTesting MSE: {:.3f}".format(mse))
- 使用支持向量机SVR进行简单对比,深度森林效果明显优于SVR。
- 此外,深度森林其实拥有天然的抗过拟合特性(自带交叉验证过程)。可以在不进行任何参数调整情况下,也能得到一个较好的结果。
文章出处登录后可见!
已经登录?立即刷新