Towards Personalized Federated Learning
尝试记录一下最近看的论文,顺便当个笔记同步了。
这篇是个性化联邦学习的综述,Towards Personalized Federated Learning
一、背景
传统联邦学习存在的问题及局限性:
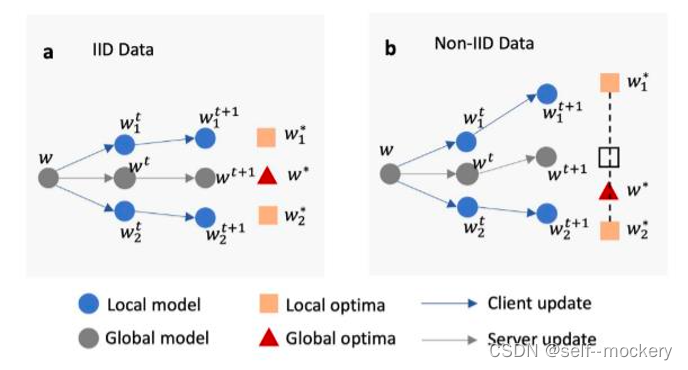
- 数据异构性,存在客户端漂移问题,导致FedAvg算法得到的全局模型并非是最优全局模型,存在偏差。
- 缺少个性化的解决方案,全局模型对于普通客户端来说适用,对于特殊客户端并不适用。
二、解决策略
2.1 策略一.全局模型个性化
个性化联邦学习的主要策略: FL训练+本地适应训练
主要分为:
- 基于数据的方法:旨在减少客户端数据集之间的统计异构性来解决用户漂移问题
- 基于模型的方法:旨在学习一个强大的全局模型,以便进行个性化设置或提高本地模型的适应性能
2.2 策略二.学习个性化模型
通过修改FL聚合过程来构建个性化模型
主要分为:
- 基于架构的方法:旨在提供针对每个客户量身定制的个性化模型体系结构
- 基于相似的方法:旨在利用客户端关系来提高个性化模型构建
三、具体方案
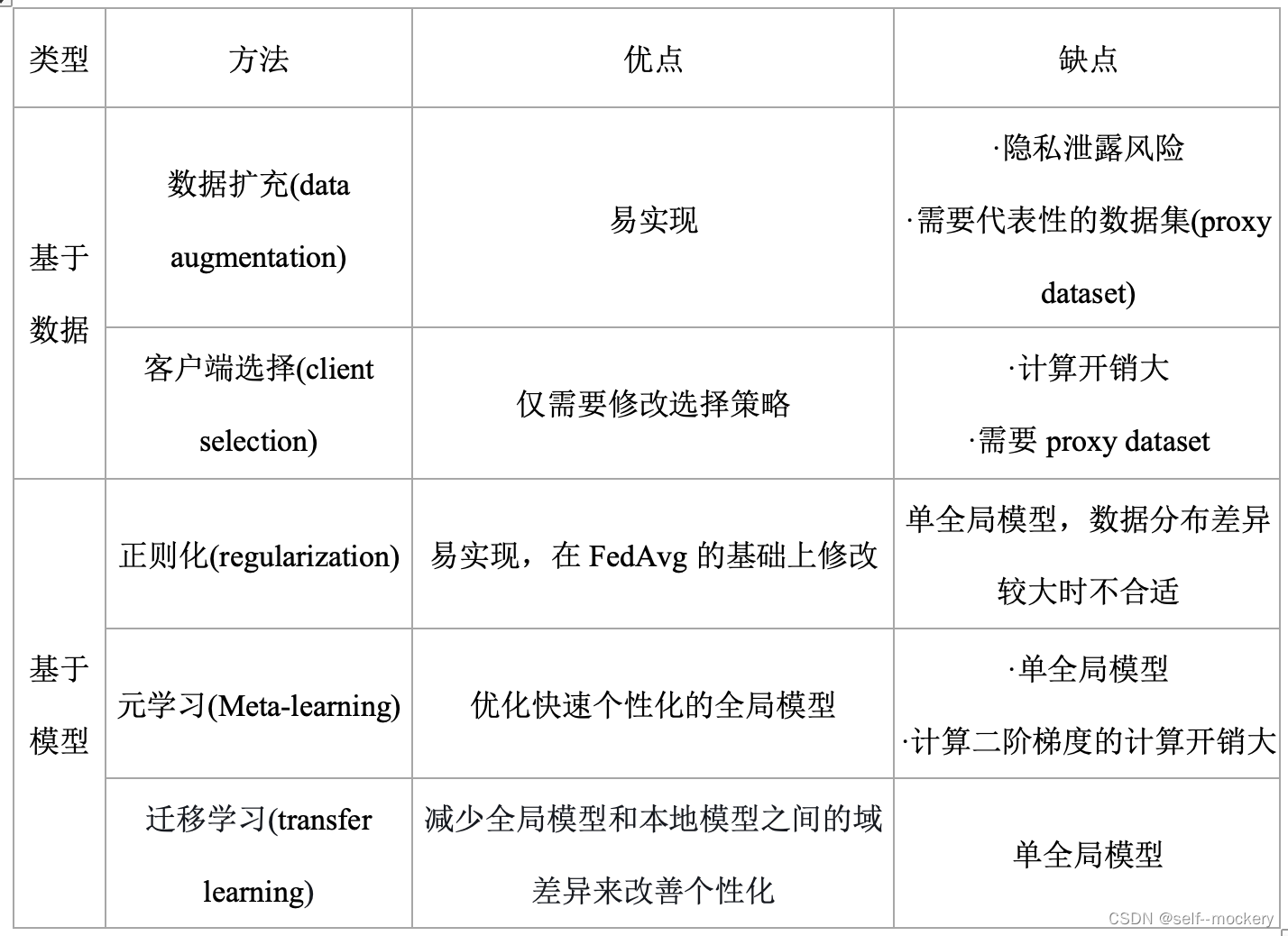
3.1 全局模型个性化
- 基于数据(data-based)
- 基于模型(model-based)
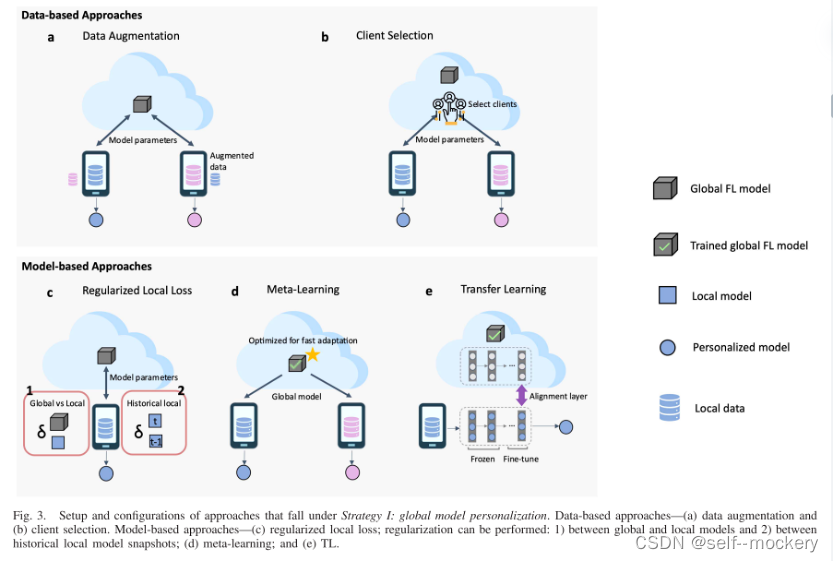
3.1.1 基于数据:减少客户端数据统计异构性
- 数据扩充(data augmentation):通过扩充数据,增加数据之间的统计同质性
(1)数据生成的过采样技术(SMOTE[1],ADASYN[2])和欠采样技术(Tomek link[3]);
(2)将少量按类均衡的全局数据分配给客户端的数据共享策略[4];
(3)使用GAN的联邦增强方法[5],训练少数类的数据样本,FL服务器将生成的GAN模型分发到客户端,以便生成附加数据,扩充本地数据集,提高同质性;
(4)Astraea,自适应FL框架[6];
(5)FedHome算法[7]:该算法使用FL训练生成式卷积自动编码器 (GCAE) 模型。在FL过程结束时,每个客户端对本地增强的类平衡数据集执行进一步的个性化。该数据集是通过基于本地数据对编码器网络的低维特征执行SMOTE算法来生成的。 - 客户端选择(client selection):设计FL客户端选择机制,提高模型泛化性能
基于数据的缺点:需要修改本地数据分布,可能会导致丢失与客户个性化相关的数据信息。
3.1.2 基于模型:在学习一个强大的全局模型,以便进行个性化设置或提高本地模型的适应性能
- 正则化(regularization)
(1)全局模型和本地局部模型之间,以解决由于统计数据异质性而在FL中普遍存在的客户端漂移问题
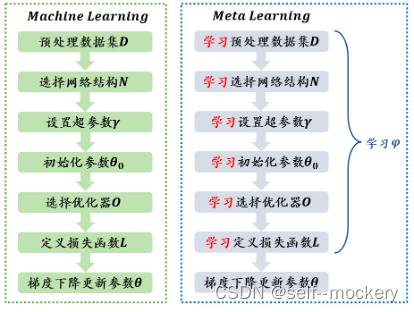
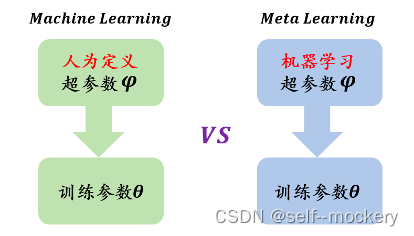
(2)历史局部模型之间:基于对比学习的FL-MOON[8] - 元学习(Meta-learning):learning to learn,让机器自动训练超参数,自己调参。
- 普通机器学习训练单位:样本数据;
- 元学习训练单位:任务,训练任务(Train Tasks)亦称跨任务(Across Tasks)和测试任务(Test Task)亦称单任务(Within Task);
典型的元学习优化算法:模型不可知元学习(model agnostic meta- learn,MAML)
 |  |
将元学习过程映射到FL过程中:元训练 —> FL全局训练; 元测试 —> FL个性化过程
(1) Pre-FedAvg[9],是在MAML基础上的FedAvg变种,以学习一个性能较好的初始全局模型
(2) pFedMe[10],在Pre-FedAvg的基础上优化,利用莫罗包络(Moreau envelopes),提高了准确性和收敛速率
(3) ARUBA框架[11],基于在线学习,实现FL设置下的自适应元学习。与FedAvg结合使用时,它提高了模型泛化性能,并消除了个性化过程中超参数优化的需要。
- 迁移学习(transfer learning)
旨在将知识从源域转移到目标域,其中两个域通常不同但相关。
(1) FedMD[12]:基于迁移学习(TL)和知识蒸馏(knowledge distillation,KD)
KD:是模型压缩的一种常用的方法,不同于模型压缩中的剪枝和量化,知识蒸馏是通过构建一个轻量化的小模型(student,学生模型),利用性能更好的大模型(teacher,教师模型)的监督信息(knowledge),来训练这个小模型,以期达到更好的性能和精度。
(2) FedHealth [13]
(3) FedSteg [14]
3.1.3 全局模型个性化方法对比
3.2 学习个性化模型
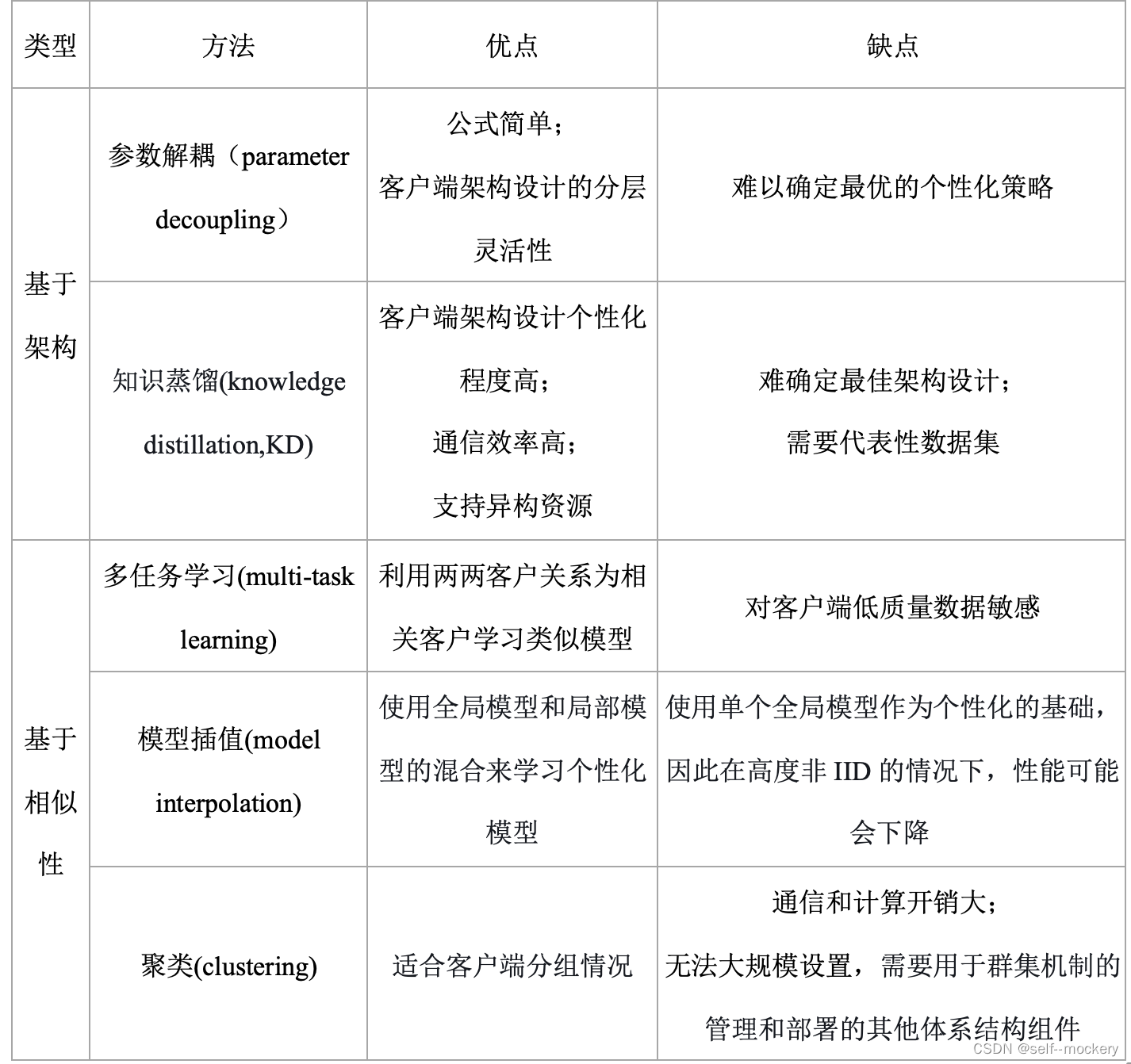
• 基于架构(architecture-based)
• 基于相似性(similarity-based)
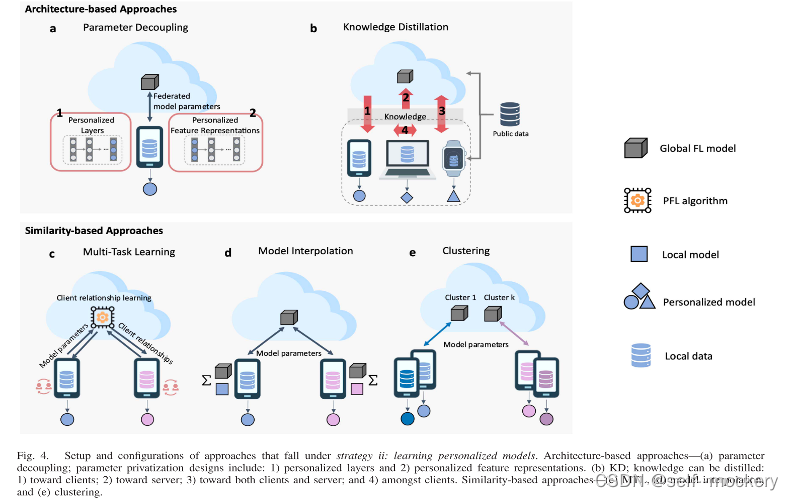
3.2.1 基于架构的方法:旨在通过针对每个客户量身定制的定制模型设计来实现个性化
• 参数解耦(parameter decoupling):实现每个客户端的个性化层
• KD:支持每个客户端的个性化模型架构
- 参数解耦(parameter decoupling):通过将局部私有模型参数与全局FL模型参数解耦来实现PFL
VS 拆分学习(split learning, SL):在SL中,深度网络在服务器和客户端之间按层划分。与参数解耦不同,SL中的服务器模型不会转移到客户端进行模型训练。相反,在前向传播期间仅共享客户端模型的分离层的权重,而在反向传播期间,来自分离层的梯度与客户端共享。因此,与FL相比,SL具有隐私优势,因为服务器和客户端无法完全访问全局和本地模型。但是,由于顺序的客户端训练过程,训练效率较低。SL在非IID数据上的表现也比FL差,通信开销更高。
(1)基础层+个性化层[15]:基础层与FL服务器共享以学习低级通用功能;个性化深层由客户端保持私有,进行本地训练实现个性化
(2)LG-FedAvg[16],将本地学习和全局联邦训练相结合
- 知识蒸馏(KD):考虑到客户端通信带宽、计算能力有限,KD的主要动机是提供更大程度的灵活性,以适应客户的个性化模型体系结构。同时,它还寻求通过减少资源需求来应对通信和计算能力挑战。
- 对客户端蒸馏
- 对服务器蒸馏
- 对客户端和服务器双向蒸馏
- 客户端之间的蒸馏
(1) FedMD[12]:基于迁移学习(TL)和知识蒸馏(knowledge distillation,KD):对于每一轮通信,每个客户端都基于更新的共识使用公共数据集训练其模型,并在此后在其私有数据集上微调其模型。这使每个客户能够获得自己的个性化模型,同时利用其他客户的知识。
(2)FedGen[17]:生成teacher模型在FL服务器中进行训练,并广播给客户端。然后,每个客户端使用所学知识作为归纳偏差在特征空间上生成增强表示,以调节其本地学习。
(3)FedDF[18]:FL服务器构造p个不同的原型模型,每个模型代表具有相同模型体系结构 (例如,ResNet和MobileNet) 的客户端。对于每个通信回合,首先在来自同一原型组的客户端之间执行FedAvg,以初始化学生模型。然后通过集成蒸馏执行跨体系结构学习,其中在未标记的公共数据集上评估客户端 (教师) 模型参数,以生成logit输出,该logit输出用于训练FL服务器中的每个学生模型。
(4)FedGKT[19]:使用交替最小化来通过双向蒸馏方法训练小边缘模型和大服务器模型,但由于需要将本地数据的真实标签上传,存在隐私安全问题。
(5)D-Distillation[20]:体系结构不可知分布式算法。它假设有一个IoT edge FL设置,其中每个边缘设备仅连接到几个相邻设备。只有连接的设备才能相互通信。学习算法是半监督的,对私有数据进行本地训练,对未标记的公共数据集进行联合训练。对于每一轮通信,每个客户端在接收其软决策广播的同时向其邻居广播其软决策广播。然后,每个客户通过共识算法基于其邻居的软决策更新其软决策。然后,更新后的软决策通过对客户端的局部损失进行正则化来更新客户端的模型权重。此过程通过网络中相邻FL客户端之间的知识转移来促进模型学习。
3.2.2 基于相似性的方法:旨在通过对客户关系进行建模来实现个性化
• 多任务学习(multi-task learning)
• 模型插值(model interpolation)
• 聚类(clustering)
- 多任务学习:MTL的目标是训练一个模型,该模型共同执行多个相关任务。
(1)MOCHA算法[20]:为每个FL客户端学习个性化模型。但不适合跨设备FL应用程序,因为所有客户端都需要参加每一轮FL模型训练。MOCHA的另一个缺点是它仅适用于凸模型,因此不适合深度学习实现。
(2)使用贝叶斯方法虚拟联邦MTL算法[21]:适合非凸模型,但计算成本大。
(3)FedAMP[22]:基于注意力机制
(4)FedCurv[23]:使用弹性权重整合(EWC)来防止跨学习任务移动时的灾难性遗忘。使用Fisher信息矩阵估计参数重要性,并执行惩罚步骤以保留重要参数。 - 模型插值
(1)引入惩罚参数,平衡模型泛化和个性化程度[24]
(2)APFL算法[25]:以通信高效的方式找到全局和局部模型的最佳组合,引入混合参数,控制全局和局部模型的权重。
(3)HeteroFL框架[26]:该框架基于单全局模型来训练具有不同计算复杂性的局部模型。通过根据每个客户端的计算能力和通信能力自适应地分配不同复杂程度的局部模型,实现PFL解决边缘计算场景下的系统异构性。 - 聚类:将类似的客户端进行分组聚类,使用同组客户端来进行同个模型的训练
(1)IFCA[27]:迭代联邦聚类算法,服务器构建K个全局模型,而不是单全局模型,并将这些模型广播给所有客户端进行本地损失计算。通信开销高。
(2)CBCA[28]:基于社区的联邦学习算法,训练了一个去噪自动编码器,并根据患者的私人数据的编码特征,对预定数量的聚类进行K-means聚类。然后为每个集群训练一个FL模型。
(3)FedGroup[29]:实现静态客户端集群策略和新客户冷启动机制的FL集群框架,基于分解余弦相似度 (EDC) 的欧氏距离,使用K-means算法对本地客户端进行聚类。
(4)学习多个全局模型的多中心公式[30]
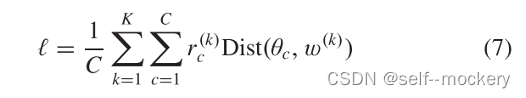
3.2.3 学习个性化模型方法对比
四、相关文献:
[1].N. V. Chawla, K. W. Bowyer, L. O. Hall, and W. P. Kegelmeyer, “SMOTE: Synthetic minority over-sampling technique,” J. Artif. Intell. Res., vol. 16, no. 1, pp. 321–357, 2002.
[2].H. He, Y. Bai, E. A. Garcia, and S. Li, “ADASYN: Adaptive synthetic sampling approach for imbalanced learning,” in Proc. IEEE Int.Joint Conf. Neural Netw. (IEEE World Congr. Comput. Intelligence),Jun. 2008, pp. 1322–1328.
[3].M. Kubat and S. Matwin, “Addressing the curse of imbalanced training sets: One-sided selection,” in Proc. ICML, 1997, pp. 179–186.
[4].Y. Zhao, M. Li, L. Lai, N. Suda, D. Civin, and V. Chandra, “Federated learning with non-IID data,” 2018, arXiv:1806.00582.
[5].E. Jeong, S. Oh, H. Kim, J. Park, M. Bennis, and S.-L. Kim, “Communication-efficient on-device machine learning: Federated dis-tillation and augmentation under non-IID private data,” 2018,arXiv:1811.11479.
[6].M. Duan, D. Liu, X. Chen, R. Liu, and Y. Tan, “Self-balancing federated learning with global imbalanced data in mobile systems,”IEEE Trans. Parallel Distrib. Syst., vol. 32, no. 1, pp. 59–71, Jul. 2021.
[7].Q. Wu, X. Chen, Z. Zhou, and J. Zhang, “FedHome: Cloud-edge based personalized federated learning for in-home health monitoring,”IEEE Trans. Mobile Comput., early access, Dec. 16, 2020, doi:10.1109/TMC.2020.3045266.
[8].Q. Li, B. He, and D. Song, “Model-contrastive federated learning,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2021, pp. 10713–10722.
[9]A. Fallah, A. Mokhtari, and A. Ozdaglar, “Personalized federated learning with theoretical guarantees: A model-agnostic meta-learning approach,” in Proc. NIPS, vol. 33, 2020, pp. 3557–3568.
[10]C. T. Dinh, N. Tran, and J. Nguyen, “Personalized federated learning with Moreau envelopes,” in Proc. Adv. Neural Inf. Process. Syst.(NIPS), vol. 33, 2020, pp. 21394–21405.
[11]M. Khodak, M.-F. Balcan, and A. Talwalkar, “Adaptive gradient-based meta-learning methods,” in Proc. NIPS, vol. 32, 2019, pp. 5917–5928.
[12]D. Li and J. Wang, “FedMD: Heterogenous federated learning via model distillation,” 2019, arXiv:1910.03581.
[13]Y. Chen, X. Qin, J. Wang, C. Yu, and W. Gao, “FedHealth: A federated transfer learning framework for wearable healthcare,” IEEE Intell. Syst.,vol. 35, no. 4, pp. 83–93, Jul. 2020.
[14]H. Yang, H. He, W. Zhang, and X. Cao, “FedSteg: A federated transfer learning framework for secure image steganalysis,” IEEE Trans. Netw. Sci. Eng., vol. 8, no. 2, pp. 1084–1094, Apr. 2021.
[15]M. G. Arivazhagan, V. Aggarwal, A. K. Singh, and S. Choudhary, “Fed-erated learning with personalization layers,” 2019, arXiv:1912.00818.
[16]P. Pu Liang et al., “Think locally, act globally: Federated learning with local and global representations,” 2020, arXiv:2001.01523.
[17]Z. Zhu, J. Hong, and J. Zhou, “Data-free knowledge distillation for heterogeneous federated learning,” in ICML, 2021.
[18]T. Lin, L. Kong, S. U. Stich, and M. Jaggi, “Ensemble distillation for robust model fusion in federated learning,” in Proc. NIPS, vol. 33,2020, pp. 2351–2363.
[19]C. He, M. Annavaram, and S. Avestimehr, “Group knowledge transfer:Federated learning of large cnns at the edge,” in Proc. NIPS, vol. 33,2020, pp. 14068–14080.
[20]V. Smith, C.-K. Chiang, M. Sanjabi, and A. S. Talwalkar, “Federated multi-task learning,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS),vol. 30, 2017, pp. 4427–4437.
[21]L. Corinzia, A. Beuret, and J. M. Buhmann, “Variational federated multi-task learning,” 2019, arXiv:1906.06268
[22]Y. Huang et al., “Personalized cross-silo federated learning on non-IID data,” in Proc. AAAI Conf. Artif. Intell., vol. 35, no. 9, 2021,
pp. 7865–7873.
[23]N. Shoham et al., “Overcoming forgetting in federated learning on non-IID data,” 2019, arXiv:1910.07796.
[24]F. Hanzely and P. Richtárik, “Federated learning of a mixture of global and local models,” 2020, arXiv:2002.05516.
[25]Y. Deng, M. M. Kamani, and M. Mahdavi, “Adaptive personalized federated learning,” 2020, arXiv:2003.13461
[26]E. Diao, J. Ding, and V. Tarokh, “Heterofl: Computation and commu-nication efficient federated learning for heterogeneous clients,” in Proc.ICLR, 2021, pp. 1–24.
[27]A. Ghosh, J. Chung, D. Yin, and K. Ramchandran, “An efficient framework for clustered federated learning,” in Proc. NIPS, vol. 33,
2020, pp. 19586–19597.
[28]L. Huang, A. L. Shea, H. Qian, A. Masurkar, H. Deng, and D. Liu, “Patient clustering improves efficiency of federated machine
learning to predict mortality and hospital stay time using distributed electronic medical records,” J. Biomed. Informat., vol. 99, Nov. 2019,Art. no. 103291.
[29]M. Duan et al., “FedGroup: Efficient federated learning via decomposed similarity-based clustering,” in Proc. IEEE Int. Conf Parallel Distrib. Process. Appl., Big Data Cloud Comput., Sustain. Comput. Commun., Social Comput. Netw.
(ISPA/BDCloud/SocialCom/SustainCom), Sep. 2021, pp. 228–237.
[30]M. Xie et al., “Multi-center federated learning,” 2020,arXiv:2005.01026.
文章出处登录后可见!