本文主要介绍Logistic回归和Softmax回归
一、回归与分类回忆
给定数据点集合 和相应的标签
,对于一个新的数据点x,预测它的标签(目标是找到一个映射
):
如果是一个连续的集合,称其为回归(regression)
如果是一个离散的集合,称其为分类(classfication)
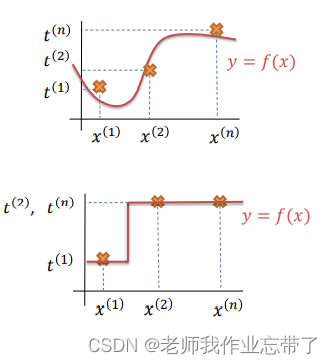
多项式回归
考虑一个回归问题,输入x和输出y都是标量。寻找一个函数 来拟合数据
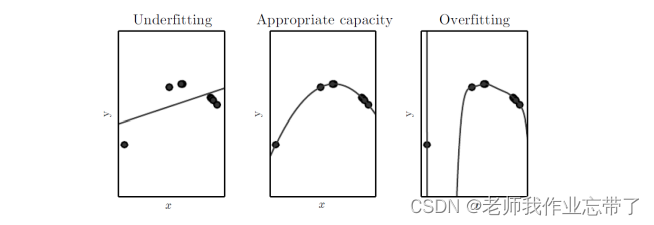
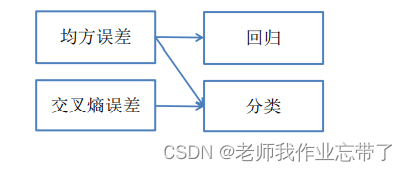
无论是线性回归还是非线性回归,我们一般都是通过一些成本函数如最小均方误差(MSE),作为损失函数,来确定 f 的参数。
线性回归
是线性的
其中(偏置/残差/误差项)可以融入
并且得到
- 设均方误差(MSE)为成本函数
- 通过最小化成本函数来找到最优的w和b
如最小二乘法、梯度下降法使得损失函数最小来求解参数。
利用回归进行二分类
在特征空间,一个线性分类器对应一个超平面

两种典型的线性分类器:
- 感知机
- SVM(AI遮天传 ML-SVM入门)
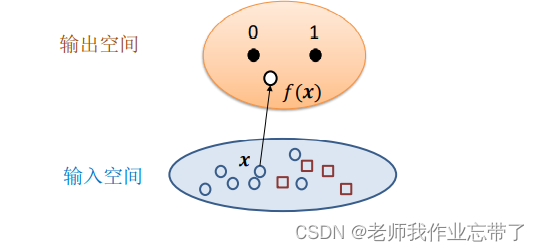
- 回归 – 预测连续的
- 分类 – 预测
利用线性回归进行二分类:
假定,考虑一维特征的情况
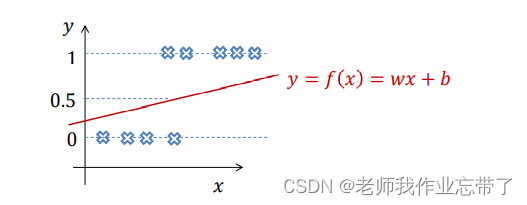
假定,考虑高维特征的情况
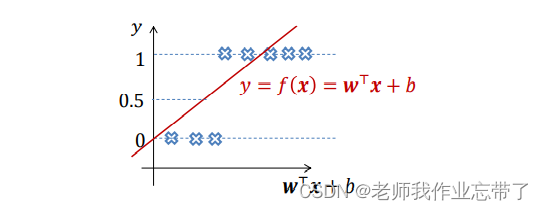
使用非线性回归进行二分类
可以是非线性函数,如:logisitic sigoid function
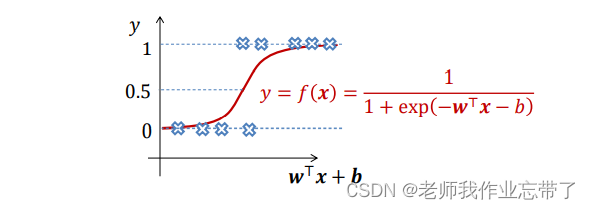
同理我们可以用训练线性回归模型的方法训练非线性回归,只不过原来的
变成了
注:这里的h是一个函数如 logisitic sigoid function
从概率的角度看问题
假设标签服从均值为 的正态分布,则其极大似然估计等同于最小化:

- 对于回归问题(t是连续的),正态分布假设是自然的。
- 对于分类问题(t是离散的),正态分布假设会很奇怪。
- 对于二分类问题的数据分布有更适合的假设 —-> 伯努利分布
为什么伯努利分布更适合二分类问题呢?
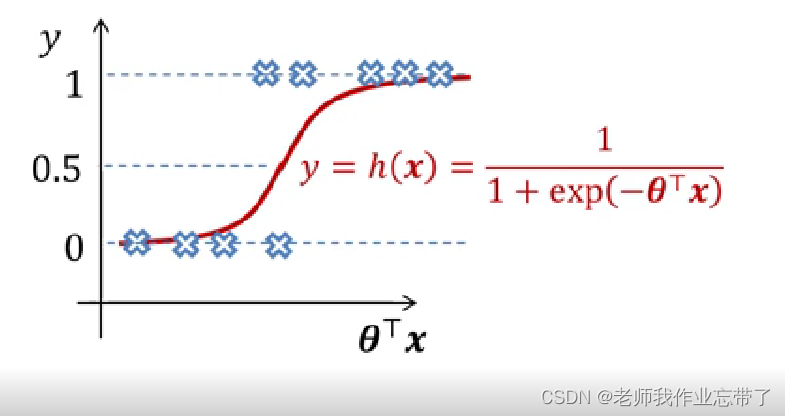
二、Logistic回归
对于一个二分类任务,一个0-1单元足以表示一个标签
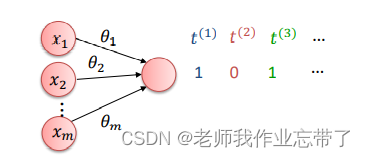
尝试学习条件概率(已经将b融入,x为输入,t为标签)
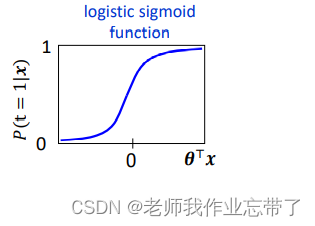
我们的目标是寻找一个 值使得概率
当x属于类别1时,取很大的值如0.99999。
当x属于类别2时,取很小的值如0.00001 (因此 取很大的值)
我们实质上是在用另一个连续函数 h 来 “回归” 一个离散的函数 (x -> t)
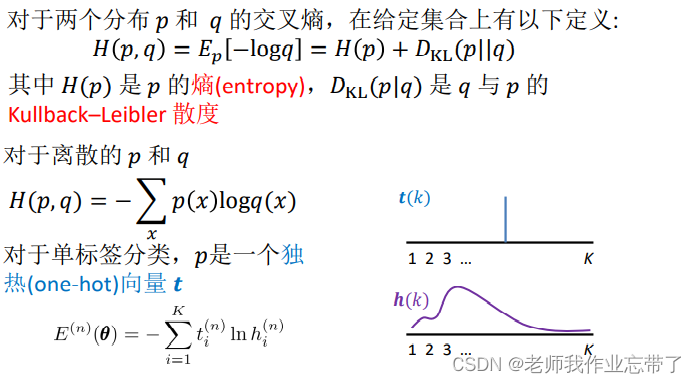
交叉熵误差函数(CSE)
对于伯努利分布,我们最大化条件数据似然,得到等同于最小化:

得到新的损失函数(CSE)
我们拿出其中一项:
- 可见,如果t=1, 则E = -ln(h)
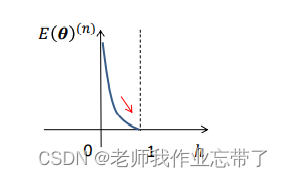
- 如果t=0, 则E = -ln(1-h)
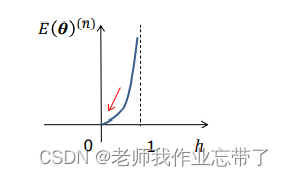
可见河里。
训练和测试

二分类问题总结

三、SoftMax回归
我们上面讲解了一维和多维二分类,其实对于多分类,只是增加了函数个数作为维度。
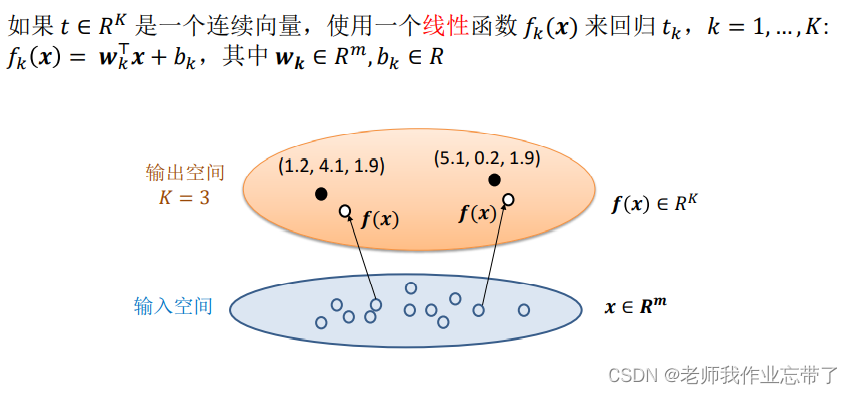
如上图,比如对于一个x,三个函数的结果为1.2、4.1、1.9,那么便可根据后续操作对其进行回归或者分类。这三个函数可能是线性的,也可能是非线性的,如logistic回归。
选择均方误差(MSE)作为损失函数
对其使用最小二乘法/梯度下降法进行计算得出参数。
标签类别的表示
对于分类问题,即经过一个映射f 输出是一个离散的集合,我们有两种表示标签的方法:

对于第一种方法,类别之间有了远近的关系,因此我们一般使用第二种表示法。 每一个维度只有0-1两种结果。
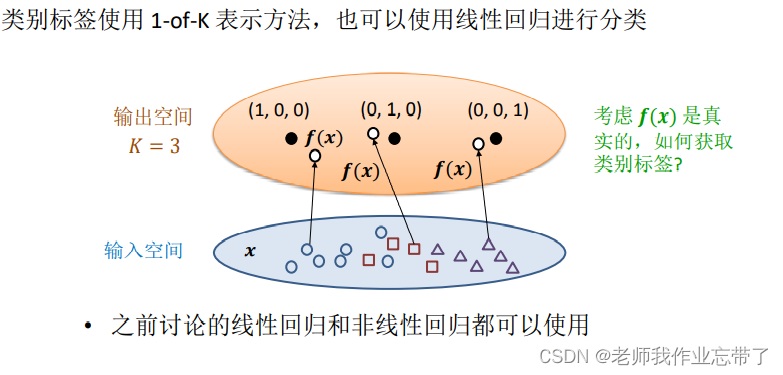
我们只需看输出的某个点里哪一类代表的点更近即可进行分类。
概率角度:
我们上面提到,对于二分类任务,伯努利分布更加适合,因此我们引入了logistic回归。
而当面对多分类任务(K>2)时,我们选择 统筹 multinoulli/categorical 分布
回顾统筹 multinoulli/categorical 分布

统筹分布学习:
- 令
采取以下形式:
明显地, 并且
- 给定一个测试输入x,对每一个k=1,2,…,K,估计
– 当x属于第K个类时,取很大的值
– 当x属于其他类时,取很小的值
- 由于
是一个(连续的)概率,我们需要将它转换为符合分类的离散值。
Softmax函数
下列函数被称为Softmax函数:
- 如果
都成立,则对于所有的
z_{j }” class=”mathcode” src=”https://latex.codecogs.com/gif.latex?z_%7Bi%7D%20%3E%20z_%7Bj%20%7D”/> 对于所有
。
同样,我们最大条件似然得到交叉熵误差函数:
注:
对于每个K,只有一个非0项(因为如(0,0,0,1,0,0))
计算梯度

向量-矩阵形式

训练和测试

随机梯度下降

在整个训练集中,最小化成恨函数的计算开销非常大,我们通常将训练集划分为较小的子集或 minibatches 然后在单个 minibatches (xi,yi)上优化成本函数,并取平均值。
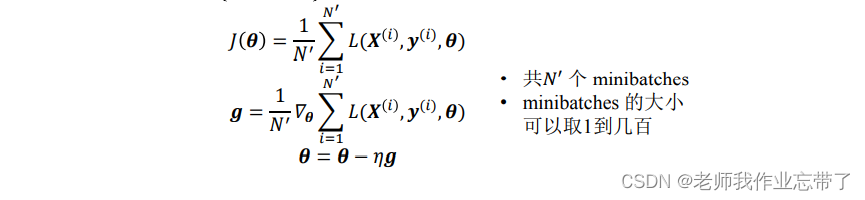
引入偏置bias
到目前为止,我们已经假设
其中
有时偏置项可以引入到 中,参数成为{w,b}
得到
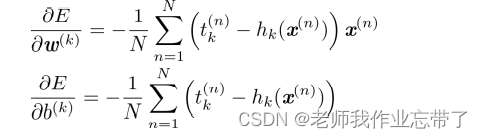
正则化通常只应用在w上
Softmax过度参数化
有假设
新的参数 会得到同样的预测结果
最小化交叉熵函数可以有无限多个解,因为:
其中
四、Softmax回顾和logistic回顾的关系
Softmax回归中,令K=2
其中h是softmax函数 g 是logistic函数
如果定义一个新的变量 那么就和logistic回归是相同的
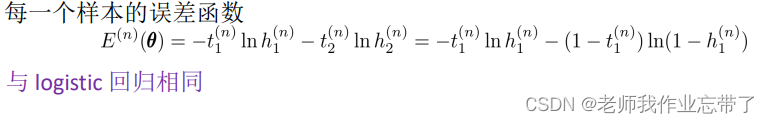
五、总结


一般意义的交叉熵
文章出处登录后可见!