Unet语义分割
目录
语义指具有人们可用语言探讨的意义,分割指图像分割。语义分割即能够将整张图的每个部分分割开,使每个部分都有一定意义。和目标检测不同的是,目标检测只需要找到图片中目标,打上框然后分出类别。语义分割是以描边的形式,将整张图不留缝隙的分割成每个区域,每个区域是一个类别,没有类别的默认为背景background。

2.语义分割原理
要识别出整张图片的每个部分,就意味着要精确到像素点,所以语义分割实际上是对图像中每一个像素点进行分类,确定每个点的类别(如属于背景、人、汽车、马等),从而进行区域划分。
那如何做到将像素点上色呢?
语义分割的输出和图像分类网络类似,图像分类类别数是一个一维的one hot 矩阵。例如:三分类的[0,1,0]。语义分割任务最后的输出特征图是一个三维结构,大小与原图类似,通道数就是类别数。其中通道数是类别数,每个通道所标记的像素点,是该类别在图像中的位置,最后通过argmax 取每个通道有用像素 合成一张图像,用不同颜色表示其类别位置。如下图:
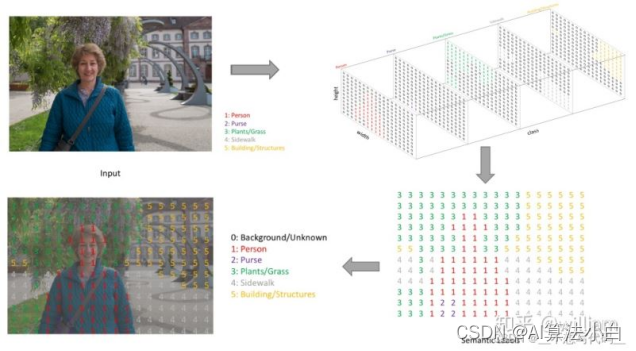
3. 语义分割意义
CNN 的强大之处在于它的多层结构能自动学习特征,并且可以学习到多个层次的特征。如,较浅的卷积层感知域较小,学习到一些局部区域的特征;较深的卷积层具有较大的感知域,能够学习到更加抽象一些的特征。这些抽象的特征对分类很有帮助,有助于分类性能的提高。可以很好地判断出一幅图像中包含什么类别的物体。但是劣势很明显,这些抽象特征对物体的大小、位置和方向等敏感性更低,这就需要语义分割来判断图像每个像素点的类别,进行精确分割,分割是像素级别的。
4.语义分割应用场景
自动驾驶:自动驾驶汽车有「环境感知」的能力,以便其可以安全行驶。
医疗影像诊断:机器可以智能地对医疗影像进行分析,降低医生的工作负担,大大减少了运行诊断测试所需的时间,如细胞的分割识别,肺部形状诊断。
无人机落点判定:无人机落地前,对地面空地图片进行识别分割,根据大小形状判断是否能安全降落。
5.先行知识储备
(1)encoder-decoder:,encoder为分类网络,用于提取特征,而decoder则是将encoder的先前丢失的空间信息逐渐恢复,该类方法虽然有一定的效果,能恢复部分信息,但毕竟信息已经丢失了,不可能完全恢复。典型算法结构还有segnet/refineNet。
(2)上采样:在卷积神经网络中,由于输入图像通过卷积神经网络(CNN)提取特征后,输出的尺寸往往会变小,而有时我们需要将图像恢复到原来的尺寸以便进行进一步的计算,这个使图像由小分辨率映射到大分辨率的操作。Unet中就需要将下采样的特征图,放大到原图大小提高分辨率,基于原图像素点做分类。卷积是改变通道数如(1*128*40*40)=>(1*64*40*40),上采样是改变尺寸如(1*128*40*40)=>(1*128*80*80)。方法:双线性插值法,转置卷积。
(3)特征融合:由于 CNN 在进行 convolution 和 pooling 过程中丢失了图像细节,即 feature map size 逐渐变小,所以不能很好地指出物体的具体轮廓、指出每个像素具体属于哪个物体,无法做到精确的分割。目的是把从图像中提取的特征,合并成一个比输入特征更具有判别能力的特征。如何正确融合特征是一个难题。融合不同尺度的特征是提高分割性能的一个重要手段。低层特征分辨率更高,包含更多位置、细节信息,但是由于经过的卷积更少,其语义性更低,噪声更多。高层特征具有更强的语义信息,但是分辨率很低,对细节的感知能力较差。特征融合综合利用多种图像特征,实现多特征的优势互补,获得更加鲁棒和准确性的识别结果。在Unet中上采样同时时就是将下采样的高层特征进行融合。两个经典的特征融合的方法
1)concat:系列特征融合,直接将连个特征进行连接。两个输入特征x和y的维数若为p和q,输出特征z的维数为p+q。保证俩者high+width一致。能完整保留图片所有信息但通道数C会增加(*2),因此会导致后面卷积的参数变多。如(1*64*40*40)add(1*64*40*40)=>(1*128*40*40)
2)add:并行策略,将这两个特征向量组合成复合向量,对于输入特征x和y,z=x+iy,其中i是虚数单位。保证俩者通道数C+high+width一致。没有concant信息多,但是融合后C+high+width不变。如(1*64*40*40)add(1*64*40*40)=>(1*64*40*40)
(4)FPN特征化图像金字塔
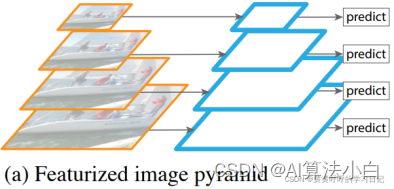
先是对原始图像进行缩放,获得不同尺寸的图像,然后基于每种尺寸的图像生成不同尺寸的特征图,最后基于多尺寸特征图进行预测。这种方法需要针对每种尺寸的图片生成特征图,会消耗较多的计算和内存资源。
6.语义分割流程

7.数据集准备
安装labelme
pip install labe1me==3.16.7 -i https://mirrors.aliyun.com/pypi/simple/
将图片打标签

标签好图片格式为json,我们要经过二值化掩膜,转换成png格式
8.算法网络架构
UNet:简单实用,主要在医学领域
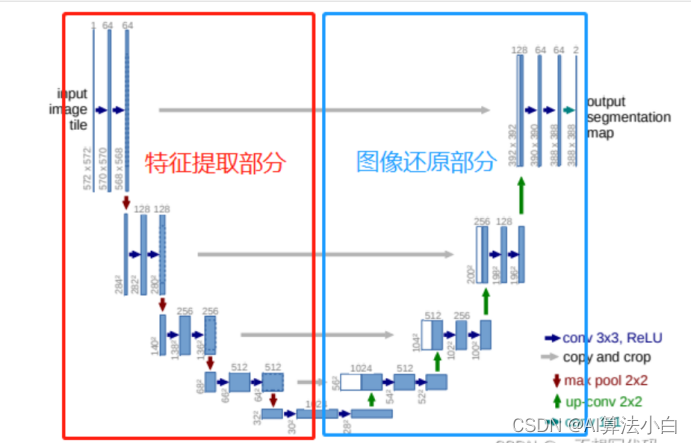
红色方框中是下采样,特征提取部分,和其他卷积神经网络一样,都是通过堆叠卷积提取图像特征,通过池化来压缩特征图,特征提取部分可以使用优秀的网络,例如:Resnet50,VGG等。蓝色方框中为上采样,图像还原部分。
第一部分是主干特征提取部分,我们可以利用主干部分获得一个又一个的特征层,Unet的主干特征提取部分与VGG相似,为卷积和最大池化的堆叠。利用主干特征提取部分我们可以获得五个初步有效特征层,在第二步中,我们会利用这五个有效特征层可以进行特征融合。
第二部分是加强特征提取部分,我们可以利用主干部分获取到的五个初步有效特征层进行上采样,并且进行特征融合(对上采样得到的结果进行通道的堆叠),获得一个最终的,融合了所有特征的有效特征层。
第三部分是预测部分,我们会利用最终获得的最后一个有效特征层对每一个特征点进行分类,相当于对每一个像素点进行分类。
其他算法结构:条件随机场:无向概率图模型,增加像素点与像素点之间的关联性;GAN对抗网络;DeepLabv1-v3;Dilation10; PSPNet (2016);FCN
9.实现流程(pytorch)
(1)数据预处理
JPEGImages文件夹下存放原始图片,SegmentationClass文件夹下存放二值化标签图。
Data.py作为相关处理脚本,写的就一个类,MyDataset类,为了给一张图片的具体路径,输出JPEGImages文件夹和SegmentationClass文件夹里面的原始图片和标签图,前者用来放入net网络训练,后者用来作为y_true算损失。
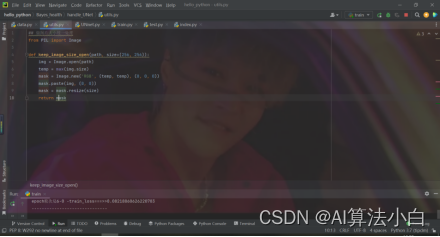
Utils.py作为相关脚本,只有一个函数,keep_image_size_open(),统一图片大小,写入图片路径,输出(256*256)大小的图片。
(2.)UNnet网络构造
UNnet.py作为相关脚本,一共有四个类。根据网络结构细节,一共有两次卷积、下采样、上采样,分别写出三个类:Conv_Block()、DownSamle()、UpSample()
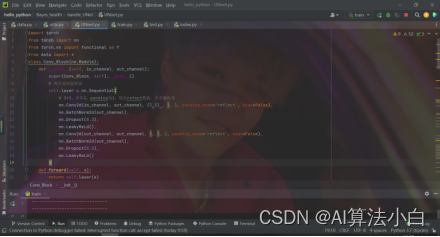
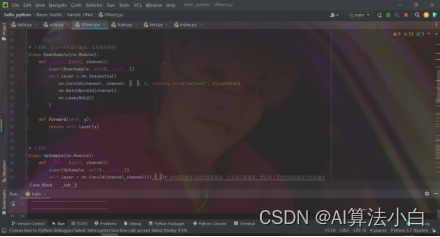
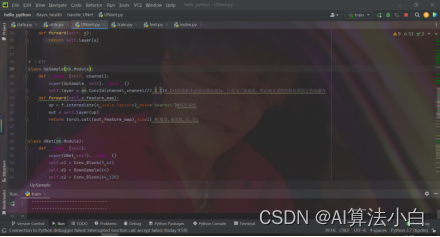
第四个类是构建网络,根据论文中的网络架构,将这些功能连接在一起

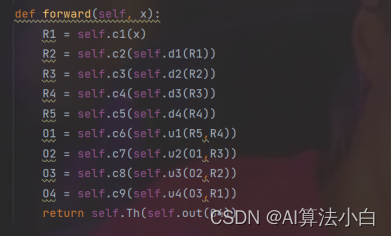
最主要理解的函数:
super(UNet,self).__init__()
(3)训练
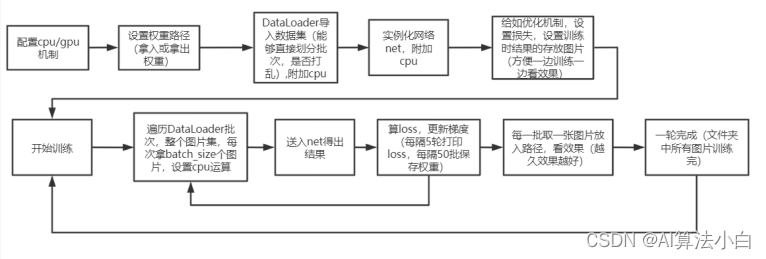
Train.py为相关文脚本。没有构建类,所需要的类都来自于上面脚本和pytorch框架。主要在于逻辑理解。采用无限循环的方法,直到损失到达预期标准或者观察到训练的结果图片很准确,然后手动截止。
最主要理解的函数:
data_loader = DataLoader(data.MyDataset(data_path),batch_size=2,shuffle=True)
net.load_state_dict(torch.load(weigth_path))
if os.path.exists(weigth_path):
opt = optim.Adam(net.parameters())
opt.zero_grad()
train_loss.backward()
opt.step()
torch.save(net.state_dict(),weigth_path)
img = torch.stack([_image,_segment_image,_out_image],dim=0)
transform = transforms.Compose([
transforms.ToTensor()
])
(4).测试

10.评估指标(没用到)
(1) 平均交并比MIoU(Mean Intersection over Union), 类似于目标检测,计算两个集合的交并比,两个集合分别是真实值(Ground truth)和预测值(predicted segmentation),是一个交集与并集的比值,平均交并比为对各类的交并比进行平均。这样的评价指标可以判断目标的捕获程度(使预测标签与标注尽可能重合),也可以判断模型的精确程度(使并集尽可能重合)。

(2) 像素准确率(Pixel Accuracy): 正确分类的像素数量与所有像素数量的比值.
(3) 像素准确率平均值(MPA):PA的变体,每个类内正确分类的像素数量和该类的所有像素点数 (Ground truth)的比值,之后求所有类的平均。
11.损失函数
(1) Class entropy loss二分类或多分类交叉熵损失,对每个像素点做分类的损失。其中二分类交叉熵损失为:BCELOSS: binary_cross_entropy

(2) Focal loss,考虑到class像素点不均衡的情况,如:天空和人在一张图片中占比相差太大。可以给更大的权重某一类别,提高它的重要性。
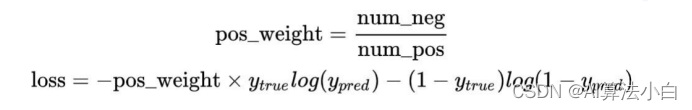
12.UNet论文
知网搜索:U-Net: Convolutional Networks for Biomedical Image Segmentation
文章出处登录后可见!