



论文地址:https://arxiv.org/pdf/2201.11903.pdf
相关博客
【自然语言处理】【ChatGPT系列】WebGPT:基于人类反馈的浏览器辅助问答
【自然语言处理】【ChatGPT系列】ChatGPT的智能来自哪里?
【自然语言处理】【ChatGPT系列】Chain of Thought:从大模型中引导出推理能力
【自然语言处理】【ChatGPT系列】InstructGPT:遵循人类反馈指令来训练语言模型
【自然语言处理】【ChatGPT系列】大模型的涌现能力
【自然语言处理】【文本生成】CRINEG Loss:学习什么语言不建模
【自然语言处理】【文本生成】使用Transformers中的BART进行文本摘要
【自然语言处理】【文本生成】Transformers中使用约束Beam Search指导文本生成
【自然语言处理】【文本生成】Transformers中用于语言生成的不同解码方法
【自然语言处理】【文本生成】BART:用于自然语言生成、翻译和理解的降噪Sequence-to-Sequence预训练
【自然语言处理】【文本生成】UniLM:用于自然语言理解和生成的统一语言模型预训练
【自然语言处理】【多模态】OFA:通过简单的sequence-to-sequence学习框架统一架构、任务和模态
一、简介
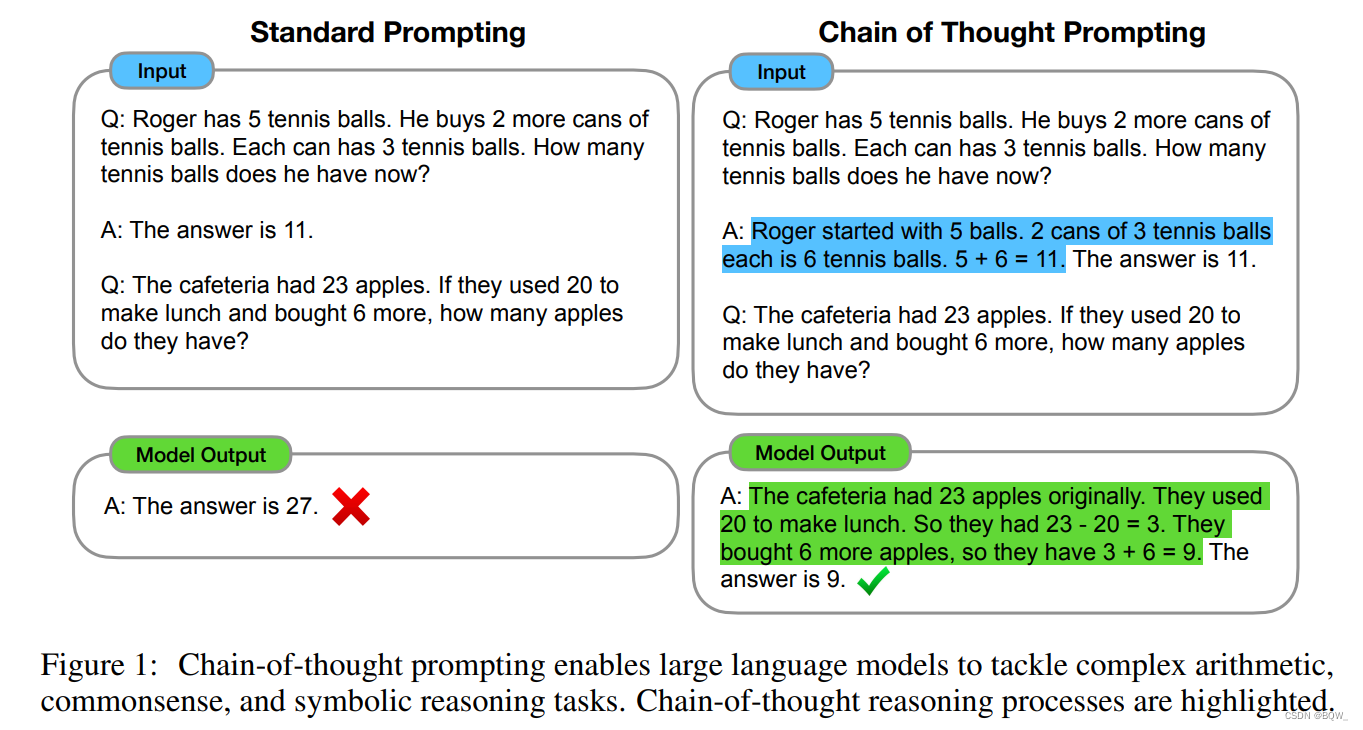
语言模型为自然语言处理带来了革命,而扩大语言模型规模可以提高下游任务效果、样本效率等一系列的好处。然而,单纯扩大语言模型的尺寸并不能够使算术、常识和符号推理获得更好的表现。文本尝试使用简单的方法来解锁大规模语言模型的推理能力,该方法主要来自于两个想法:(1) 算术推理能够从自然语言论据中受益,从而得到最终的答案。先前的研究通过从头训练或者微调预训练模型从而赋予模型生成自然语言中间步骤的能力。(2) 大规模语言模型通过checkpoint,而是通过任务相关的"输入-输出"示例来提示模型。

然而,上面的想法有一些限制。论据增强的训练和微调方法需要大量的高质量论据,这比简单的"输入-输出"样本对复杂的多。传统的
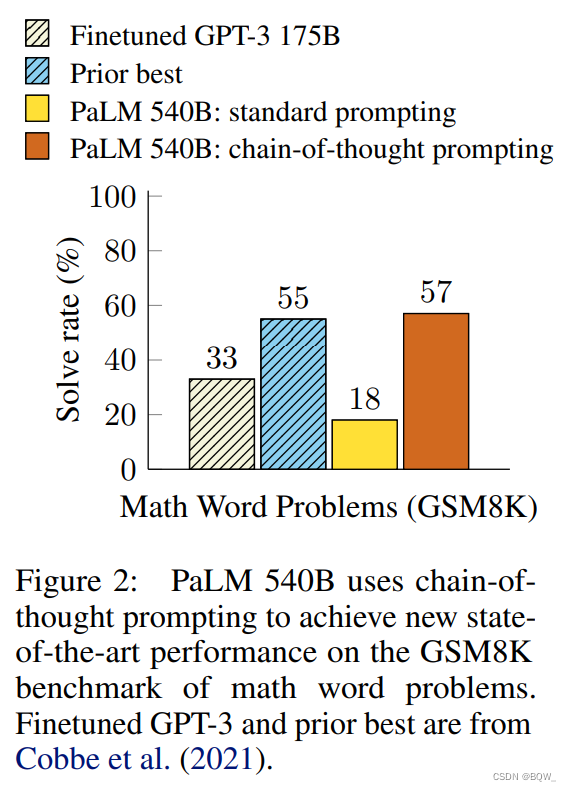

本文给出了一个在算法、常识和符号推理基准上的评估,结果显示checkpoint执行很多任务。本文的目标是赋予语言模型生成类似
二、
回想一下人类解决数学应用题这种复杂推理任务的过程。典型的做法是将问题分解为中间步骤并逐步解决并给出最终的答案:“Jane将2朵花送给她妈妈后还剩10朵…然后再送给她爸爸3朵后还有7朵…所以答案是7”。
考虑一下我们自己解决像数学应用题这样复杂推理任务的过程。典型的做法是将问题分解为中间步骤并逐步解决并给出最终的答案:“Jane将2朵花送给她妈妈后还剩10朵…然后再送给她爸爸3朵后还有7朵…所以答案是7”。本文的目标是赋予语言模型生成类似
图1展示了一个模型产生
- (1)
- (2)
- (3)
- (4)
三、算术推理
首先通过数学应用题来衡量语言模型的数学推理能力。虽然数学推理能力对人类很简单,但是对模型来说十分挣扎。当具有
1. 实验设置
-
基准
考虑5个数学应用题基准:(1) 数学应用题基准
-
标准
baseline是标准的
-
本文提出的方法是通过一个关联了答案的
-
语言模型
本文评估了5个大模型。
(1)
(2)
(3)
(4)
(5)
通过贪心解码的方法来采样。对于
2. 结果
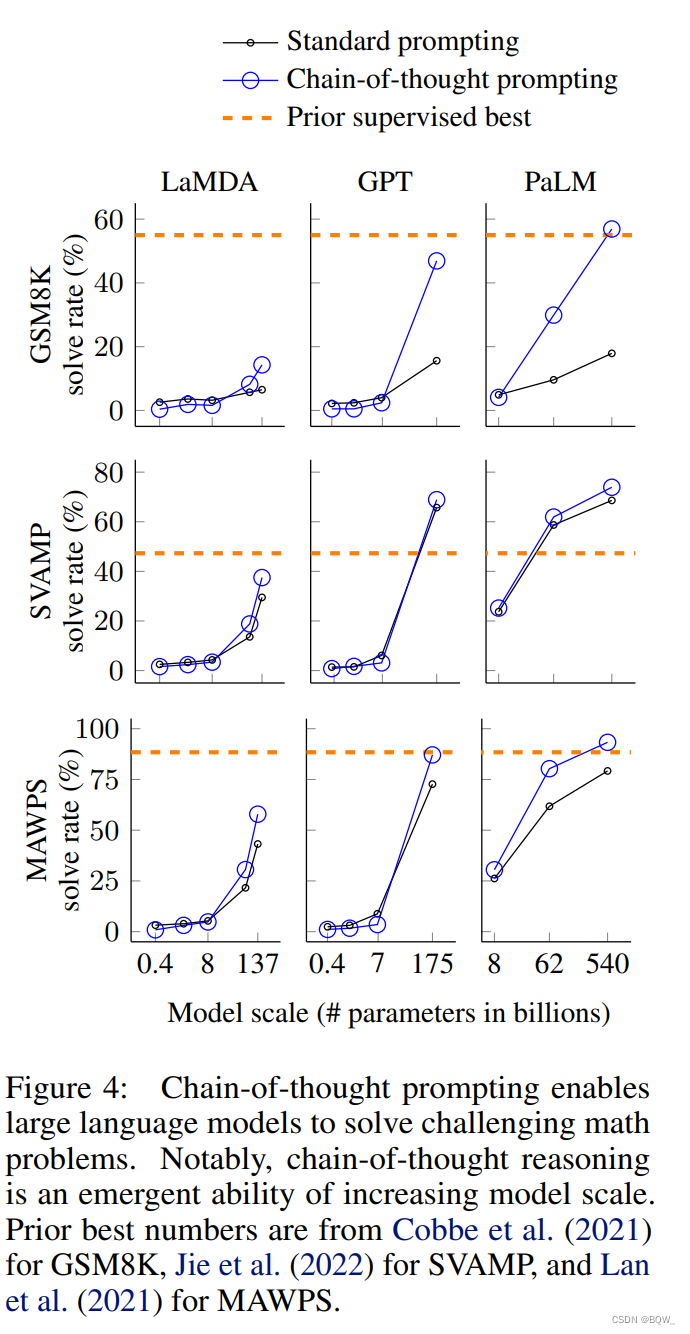

首先、上图展示了
第二、对于更复杂的问题
第三、基于
为了更好的理解
3. 消融实验
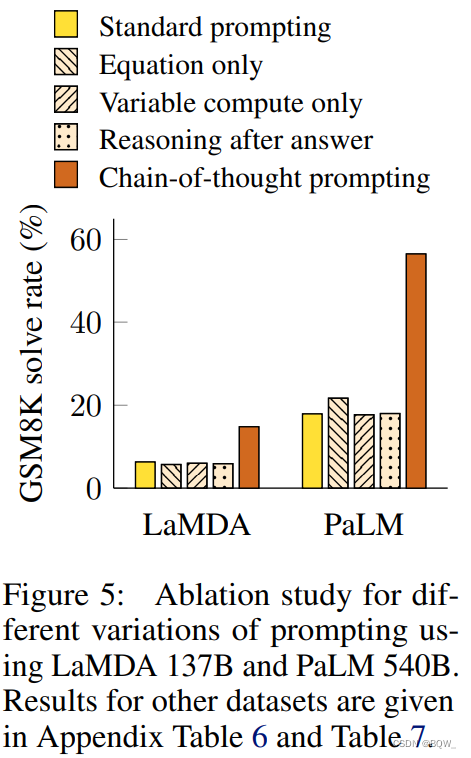

-
Equation only
-
Variable compute only
另一个直觉是,
-
Chain of thought after answer
4. 
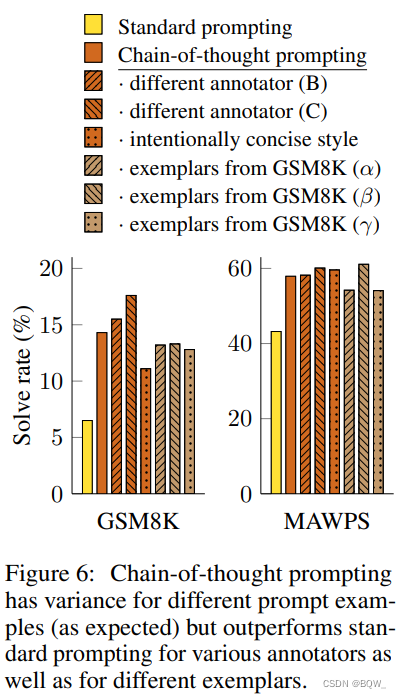

样本敏感性是
为了确认
除了标注者、独立编写的
四、常识推理
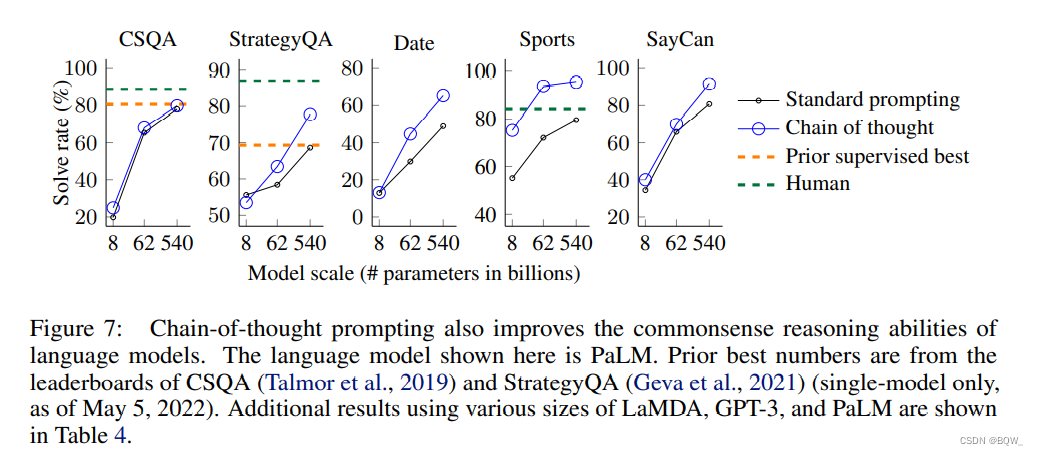

1. 基准
本文考虑覆盖了各类常识推理类型的5个数据集。(1)
2. 
遵循先前章节相同的实验设置。对于
3. 结果
上图展示了
上图重点介绍了
五、符号推理
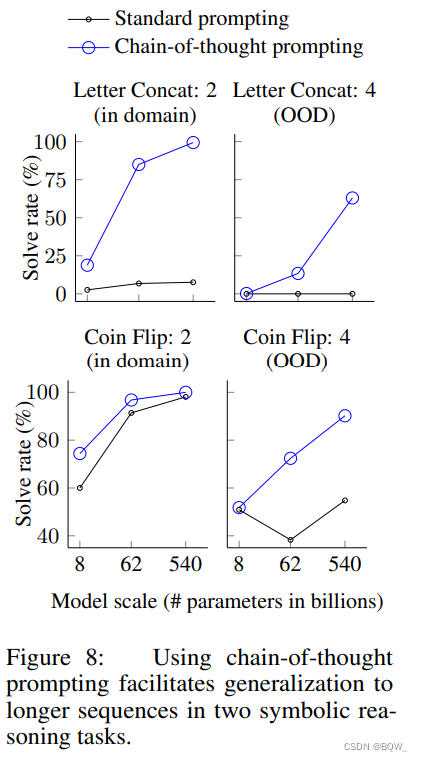

最后的实验会评估符号推理,其对于人类很简单,但是对语言模型非常有挑战。实验展示了
1. 任务
-
末尾字符拼接
该任务要求模型将名字中每个单词末尾字符拼接起来(例如:
-
硬币反转
该任务要求模型回答在人类在抛或者不抛硬币后,硬币是否仍然朝上。(例如:一个硬币朝上。Phoebe反转了硬币,而Osvaldo没有反转,那么硬币是否仍然朝上? -> no)。
由于这些符号推理任务构造过程是明确的,考虑一个领域内测试集,样本与训练/
2. 结果
上图是
对于领域外评估,标准的
文章出处登录后可见!