1 前言
本文为自己自学内容的记录,其中多有借鉴别人博客的地方,一并在参考文献中给出链接,其中大部分截图来自李宏毅深度学习PPT课件。其中内容有理解不到位的地方,各位大佬在评论区给出修改意见,感恩。
本文前置知识高斯混合模型和EM算法,如果不了解这两种算法直接看VAE模型会有理解上的障碍。
2 VAE模型
2.1 VAE模型推导
VAE模型的初始化推导和EM算法的推导有相似之处,不同的是在VAE模型中隐变量是一个连续的无穷维而不是跟高斯分布一样为有限的离散变量,所以在VAE的参数估计中用到了神经网络。
VAE是一个深度生成模型,其最终目的是生成出概率分布,
即输入数据。在VAE中,通过高斯混合模型(Gaussian Mixture Model)来生成
,也就是说
是由一系列高斯分布叠加而成的,每一个高斯分布都有它自己的参数
和
。

那么要找的这个映射关系如何获得?这里就需要用到神经网络,那么为什么不用极大似然估计,因为在VAE模型中隐变量数量假设是高维无限的,没有办法用积分去做,所以用神经网络去拟合(神经网络可以拟合任意函数)。如下图所示:

对于某一个向量我们知道了如何找到
,那么对连续变量
依据全概率公式有:
但是很难直接计算积分部分,因为我们很难穷举出所有的向量用于计算积分。又因为
难以计算,那么真实的后验概率
同样是不容易计算的,这也就是为什么下文要引入
来近似真实后验概率
。
因此我们用极大似然估计来估计,有似然函数
:
这里额外引入一个分布 ,
,这个分布表示形式如下:

注意:这里为什么需要引入额外的分布,跟EM算法的求解过程做对比,在EM算法中
是可以取到
,从而令散度等于零不断的抬升下界进行极大似然估计,但是在VAE中由于
是很难求的所以引入一个变量q(x)对其进行近似。
接下来进行公式的推导,由于在EM算法中已经推导出了ELBO+KL的形式,这里就直接拿来用:
根据KL divergence的性质 当且仅当
取等号,因此有
因此便得到了的一个下界称为Evidence Lower Bound (ELBO),简称
。最大化
就等价于最大化似然函数
。那么接下来具体看
:
推导到这一步就会发现这种形式的公式是看VAE相关论文经常给出的形式。同时到了这一步也可以看出,最大化似然函数就是最大化
,也即最小化
和最大化
。
- 最小化
,使后验分布近似值
接近先验分布
。也就是说通过
不能太离谱,要与某个分布相当才行,这里是对中间编码生成起了限制作用。当
其中表示向量
和
表示
和
的第
个元素。(这里的
和
.
- 最大化
,即在给定编码器输出
越大越好。这部分也就相当于最小化Reconstruction Error(重建损失)
由此我们可以得出VAE的原理图:

2.2 重参化技巧
在前面VAE的介绍中样本经过Encoder生成了隐变量的一个分布 ,然后从这个分布中采样
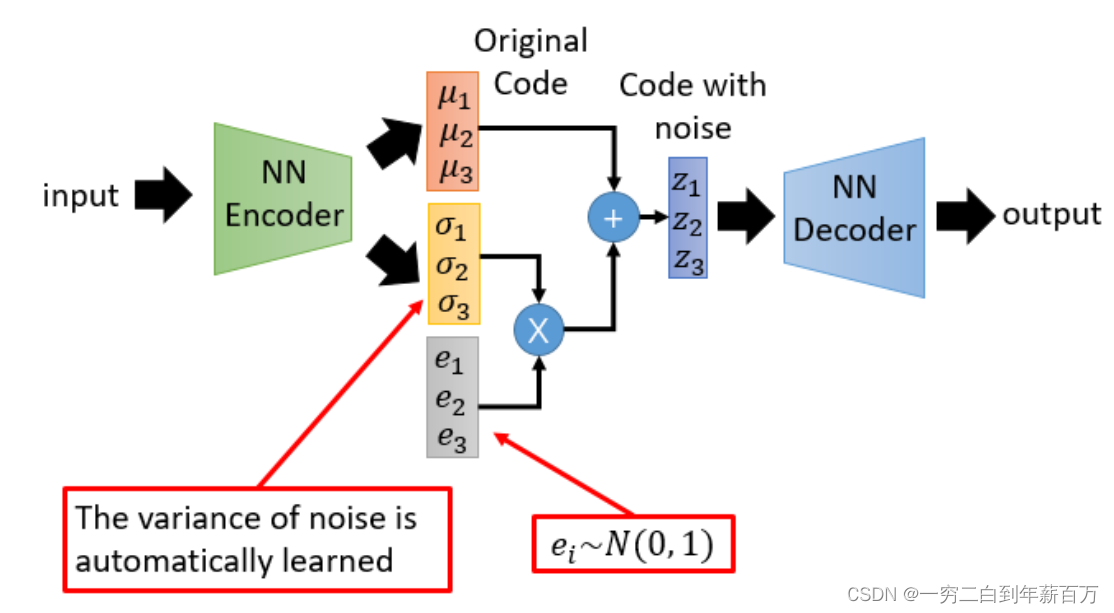
进行Decoder,注意“采样”这个操作是不可微的,因此不能做反向传播,所以用reparameterization trick来解决这个问题,示意图如下:
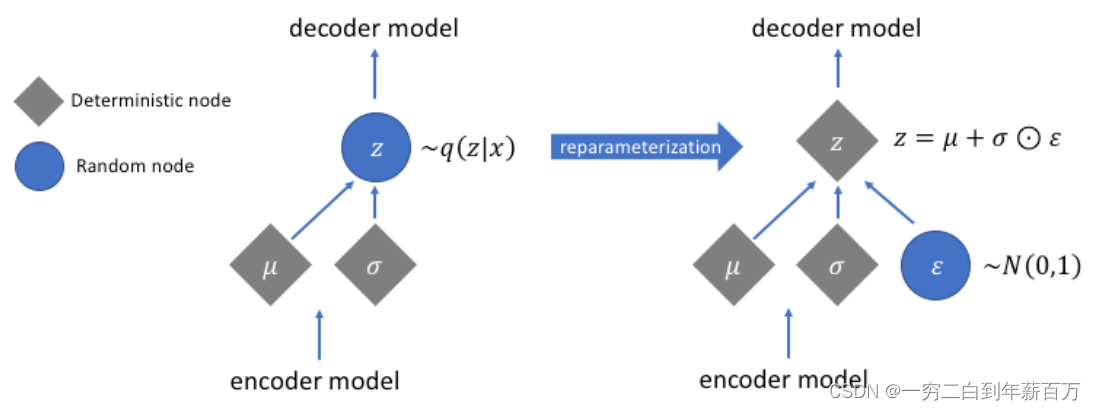
我们引入一个外部向量,通过
计算编码
(
表示element-wise乘法,
的每一维都服从标准高斯分布即
N(0,1),由此loss的梯度可以通过
和
分支传递到encoder model处(
并不需要梯度信息来更新)。
这里利用了这样一个事实[3]:考虑单变量高斯分布,假设,从中采样一个
,就相当于先从
中采样一个
,再令
最终的VAE的形式如下:
3 QA
3.1 生成体现在什么地方
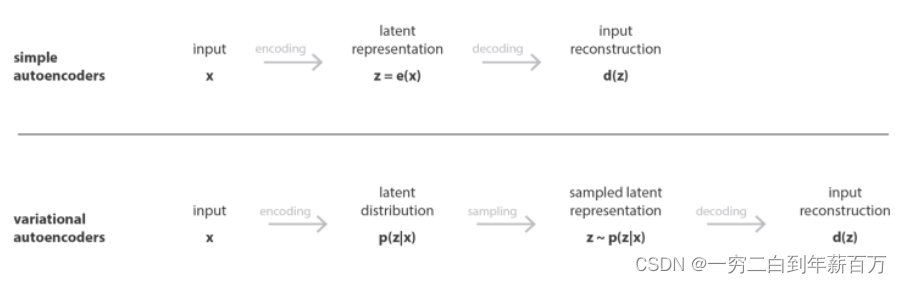
3.2 AE和VAE的区别
将把表示为输入数据,把
表示为潜在变量(编码表示)。在普通的自编码器中,编码器将输入
转换为潜在变量
,而解码器将
转换为重构的输出。而在可变自编码器中,编码器将
转换为潜在变量
的概率分布,然后对潜在变量
随机采样,再由解码器解码成重构输出。自编码器(确定性)和可变自编码器(概率性)的区别。
4 另一种角度理解VAE
5 总结
其实那么多数学公式推导,我自己都有点晕,但是本质上就是用自编码器去产生很多高斯分布,去拟合样本的分布,然后某个x对应的高斯分布里采样z,然后复原成x,跟GAN区别就是这个是完全去模仿分布,只能生成数据中已有的图片,很难创造新的图片,最多也就是插值图片了。
也可以理解成图片的特征向量z采样于某种高斯分布,我们要把他给找出来,我们希望这个分布贴近标准正太分布,然后通过编码器生成对应均值和方差,然后采样z,希望z又能复原图片,这样就找到了这个z背后的高斯分布。这个高斯分布的均值就是最大概率生成特征z,可以复原图片,当然均值旁边采样出来的z可能可以复原的不是很像,但是也是在数据集里的,如果有2个图片的特征分布都在这个点有所重合的话,可能就是2个图片中间的插值图片了。
不足
VAE在产生新数据的时候是基于已有数据来做的,或者说是对已有数据进行某种组合而得到新数据的,它并不能生成或创造出新数据。另一方面是VAE产生的图像比较模糊。
而大名鼎鼎的GAN利用对抗学习的方式,既能生成新数据,也能产生较清晰的图像。后续的更是出现了很多种变形。
6 参考文献
[1]【深度学习】VAE(Variational Auto-Encoder)原理
[2]【干货】深入理解变分自编码器
[3]变分自编码器VAE:原来是这么一回事 | 附开源代码
[4]Auto-encoding variational bayes
[5]【机器学习】白板推导系列(三十二) ~ 变分自编码器(VAE)
[6]PyTorch实现VAE
[7]使用(VAE)生成建模,理解可变自动编码器背后的数学原理
文章出处登录后可见!