AIGC:Stable Diffusion(一项普通人就能实现的AI前沿科技)的简介、Stable Diffusion2.0的改进、安装、使用方法(文本到图像/图像修改/超分辨率/图像修复)之详细攻略
导读:Stable Diffusion能够通过文本 prompt 生成图像,执行图像的超分辨率、风格迁移、图像修复等任务,随着影响力逐渐变大,基于Stable Diffusion 二次开发应用会越来越多。当然,它最牛叉在,它不仅是一个开源模型,而且能够在消费级GPU上就能运行,关键是效果还不错,相比AIGC的明星产品DALL-E 2,Stable Diffusion是一项普通人就能自行部署、自己娱乐的AIGC科技产品。
近期,Hugging Face社区以Stable Diffusion为核心的技术,构建了一个包含扩展和工具的庞大生态系统,这也极大地推动了Stable Diffusion的迅速发展。
那么,Stable Diffusion到底有多优秀呢?举个例子吧,就在前几天,苹果官方开发人员亲自部署优化,手把手教大家如何直接将 Stable Diffusion 模型转换为自家 iPhone、iPad 和 Mac 可以运行的版本,从而实现在C端快速出图。能够让互联网科技巨头公司主动采用,Stable Diffusion本身确实非常了不起,打铁还需自身硬呀。
目录
Stable Diffusion模型的简介
Stable Diffusion模型的背景
| 作者 | Robin Rombach *、 Andreas Blattmann *、 Dominik Lorenz、 Patrick Esser、 Björn Ommer 作者来自Stability AI的Robin Romabach和AI视频剪辑技术创业公司Runway ML的Patrick Esser,由Björn Ommer教授博士领导。该项目的技术基础主要来自于这两位开发者之前在计算机视觉大会 CVPR22 上合作发表的潜扩散模型(Latent Diffusion Model)研究,并且得到了 LAION 和 Eleuther AI 两大开源组织的大力支持。 |
| 组织 | Stability AI,LAION,Eleuther AI |
| 时间 | Stable Diffusion2.0:2022年11月24日 Stable Diffusion1.0:2022年08月08日 |
| 官网 | |
| Github | |
| 论文 | 《High-Resolution Image Synthesis with Latent Diffusion Models》 |
Stable Diffusion模型的各方评价
Stability AI团队激动地说,就像Stable Diffusion的第一次迭代一样,我们努力优化模型,让它在单个GPU 上运行,因为我们希望从一开始就让尽可能多的人可以使用它。
创始人兼CEO Emad Mostaque谈及了Stability AI创立的初衷、使命和终极目标。一直以来Emad致力于为研究者消除计算和资金的限制。
Emad 相信,图像才是杀手级的应用。图像生成模型可以迅速创造,并引导人们迅速消费。它们的竞争对手是Snapchat或TikTok,在那里你可以创建像Pokémon GO这样火爆的游戏。但同时,它们也能被以足够低的成本,又好又快地整合到许多不同的领域。
Emad 认为像DALL-E 2这样对人类有积极作用的技术,应该被广泛应用,只有这样,才能扩大它们积极的一面,并遏制它们的负面用途。
Stability AI 的产品副总裁兴奋的表示:Stable Diffusion 2.0 是有史以来发布的最强大的开源项目之一。这是迈向创造力、表达能力和沟通民主化的又一大步。
业界普遍认为,Stability AI的迅速崛起给OpenAI造成了不小压力。John Carmack(AGI初创公司Keen Technologies创始人,前Oculus CTO)表示:Stable Diffusion是一个开源炸弹。OpenAI虽然资金充裕,但从商业化以及产品化的角度很难与其匹敌。
Stability AI公司的简介
Stability AI,总部位于英国伦敦,公司背后的出资人是数学家、计算机科学家Emad Mostaque,来自孟加拉国,今年39岁,毕业于牛津大学数学和计算机科学学院,曾在一家对冲基金公司工作过13年。凭借Stability AI和他的私人财富,Mostaque希望能够培育一个开源AI研究社区。创业公司之前就支持创建「LAION 5B」数据集。
OpenAI创立之初的愿景,是希望把人工智能带给大众,将技术民主化。正如Stability AI官网顶部的Slogan是AI by the people,for the people。Stability AI 是一家基于使命驱动的开源AI,Stability AI的目标是在学术和产业界之外打造第三极。为独立研究者和学术研究者消除障碍,来建立类似Eleuther AI, LAION等的新模式。
Stability AI不光有Stable Diffusion,还聚集了EleutherAI和LAION等知名开源项目,以及生物模型OpenBioML、音频生成Harmonai、人类偏好学习Carperai、新冠研究Caiac和多模态DeepFloyd等更多项目。
2022年10月26日,Stability AI公司的Stable Diffusion的AI文生图模型,宣布获得了1.01亿美元,估值已到达 10 亿美元,成为新晋独角兽。
Stable Diffusion模型的论文介绍
《High-Resolution Image Synthesis with Latent Diffusion Models》论文摘要
| By decomposing the image formation process into a sequential application of denoising autoencoders, diffusion models (DMs) achieve state-of-the-art synthesis results on image data and beyond. Additionally, their formulation allows for a guiding mechanism to control the image generation process without retraining. However, since these models typically operate directly in pixel space, optimization of powerful DMs often consumes hundreds of GPU days and inference is expensive due to sequential evaluations. To enable DM training on limited computational resources while retaining their quality and flexibility, we apply them in the latent space of powerful pretrained autoencoders. In contrast to previous work, training diffusion models on such a representation allows for the first time to reach a near-optimal point between complexity reduction and detail preservation, greatly boosting visual fidelity. By introducing cross-attention layers into the model architecture, we turn diffusion models into powerful and flexible generators for general conditioning inputs such as text or bounding boxes and high-resolution synthesis becomes possible in a convolutional manner. Our latent diffusion models (LDMs) achieve new state of the art scores for image inpainting and class-conditional image synthesis and highly competitive performance on various tasks, including unconditional image generation, text-to-image synthesis, and super-resolution, while significantly reducing computational requirements compared to pixel-based DMs. | 通过将图像形成过程分解为降噪自动编码器的顺序应用,扩散模型(DM)在图像数据和其他数据上实现了最先进的合成结果。此外,它们的公式表述允许一种引导机制来控制图像生成过程而无需再重新训练。然而,由于这些模型通常直接在像素空间中操作,因此强大的 DM 的优化通常会消耗数百个 GPU 天,并且由于顺序评估,推理非常昂贵。为了在有限的计算资源上进行DM训练,同时保持其质量和灵活性,我们将其应用于强大的预训练自动编码器的潜在空间。与之前的工作相比,在这种表示上训练扩散模型第一次允许在复杂性降低和细节保留之间达到一个接近最优的点,极大地提高了视觉保真度。通过在模型体系结构中引入交叉注意力层,我们将扩散模型转化为强大而灵活的生成器,用于文本或边界框等一般条件输入,并以卷积方式实现高分辨率合成。我们的潜在扩散模型(LDM)在图像嵌入和类条件图像合成方面取得了新的艺术得分,并在各种任务上具有很强的竞争力,包括无条件图像生成、文本到图像合成和超分辨率,同时与基于像素的DM相比显著减少了计算需求。 |
Stable Diffusion模型的总结
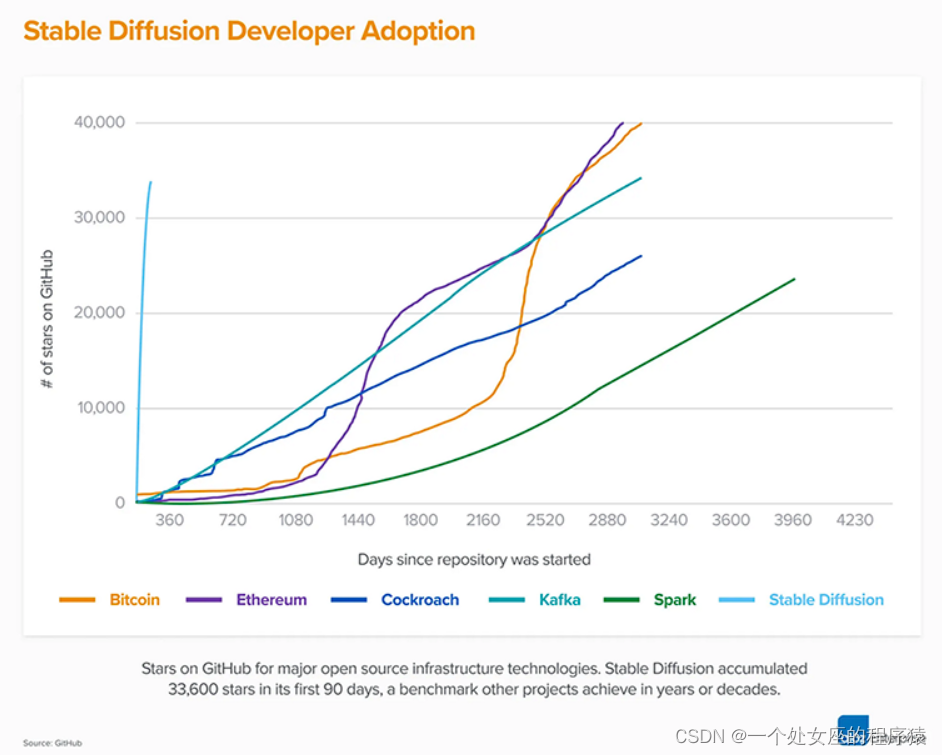
| 简介 | 2022年08月,号称最强文本生成图像的模型Stable Diffusion诞生;这是一种潜在的文本到图像扩散模型。 Stable Diffusion是最新的扩散模型。在生成图像方面,它在所生成图像的质量、速度和成本上都取得了巨大突破。 (1)、Stable Diffusion能够在消费级显卡上实现DALL-E 2级别的图像生成,生成效率却提高了30倍。 |
| 影响 | (1)、最初的Stable Diffusion一经发布,就掀起了一场文本到图像模型领域的新革命。Stable Diffusion 1.0彻底改变了开源AI模型的性质,并且在全球范围内催生了数百种新模型。 (2)、Stable Diffusion是最快达到10K Github star星数的项目之一,在不到2个月的时间里飙升至33K星,如上图所示。 (3)、作为目前可用性最高的开源模型,Stable Diffusion在短短2个月的时间里已经被全球超过20万名开发者下载和使用。 (4)、Stability AI面向消费者的产品名为DreamStudio,目前已经拥有超过100万名注册用户—他们共同创建了超过1.7亿张图像。 |
| 特点 | (1)、普通人就能接触到的AIGC科技产品:相比较于DALL-E等大模型,Stable Diffusion让用户使用消费级的显卡便能够迅速实现文生图,它的生成效率是DALL-E的30倍。 (2)、Stable Diffusion 完全免费开源,所有代码均在 GitHub 上公开,任何人都可以拷贝使用。在用户层面,它无疑是十分成功的。 (3)、用户广泛:目前,Stable Diffusion已经有超过20万开发者下载和获得授权,各渠道累计日活用户超过1000万。而面向消费者的DreamStudio则已获得了超过150万用户,已生成超过1.7亿图像。 (4)、存在争议:同时,它的惊艳艺术风格、以及图像涉及的版权、法律等问题也引发了诸多争议。 |
| 硬件 | Stability AI训练Stable Diffusion的模型,是在拥有4,000个Nvidia A100 GPU的服务器上。 Stable Diffusion模型第一个版本训练耗资60万美元。 |
| 意义 | (1)、就像 Stable Diffusion 的第一次迭代一样,我们努力优化模型以在单个 GPU 上运行——我们希望从一开始就让尽可能多的人可以使用它。我们已经看到,当数百万人接触到这些模型时,他们共同创造了一些真正令人惊叹的东西。 (2)、这就是开源的力量:挖掘数百万有才华的人的巨大潜力,他们可能没有资源来训练最先进的模型,但有能力用一个模型做一些令人难以置信的事情。 (3)、这个新版本连同其强大的新功能,如 depth2img 和更高分辨率的升级功能,将成为无数应用程序的基础,并激发新的创造潜力。 |
Stable Diffusion2.0简介及其改进点
Stable Diffusion2.0比较Stable Diffusion1.0,新的算法比之前的更高效、更稳健。
1、New Text-to-Image Diffusion Models
(1)、基于LAION-5B扩大了训练数据集
模型在Stability AI的DeepFloyd团队创建的LAION-5B数据集上进行训练,比LAION-400M大14倍。
备注:LAION-400M曾是世界上最大的可公开访问的图像文本数据集。
(2)、基于NSFW 删除数据集内“不可描述内容”
使用 LAION的NSFW过滤器,会过滤掉一些“不可描述内容”,即成人内容。哈哈,这也引起了reddit上,让部分搞笑网友进行了差评。
当然,这次模型的关键组件功能被改进,使得Stable Diffusion更难生成某些引起争议和批评的图像了,比如广受评论的裸体和情色内容、名人的逼真照片以及模仿特定艺术家作品的图像。
备注:NSFW即Not Suitable For Work,其实就是一些不适合上班时间浏览的东西。
(3)、基于OpenCLIP显著提高了图像生成质量
Stable Diffusion 2.0 版本使用了在LAION开发的全新文本编码器 (OpenCLIP) 上,从头开始训练文本到图像模型。
与早期的 1.0 版本相比,文本-图像模型显著提高了图像生成质量,此次模型可以生成输出默认分辨率为 512×512 像素和 768×768 像素的图像。
2、Super-resolution Upscaler Diffusion Models
(4)、引入超分辨率扩散模型(Upscaler Diffusion)提高了图像分辨率
Stable Diffusion 2.0包含了一个Upscaler Diffusion模型,该模型将生成图像的分辨率提高了 4 倍。比如 Upscaler 将低分辨率生成的图像 (128×128) 升级(upscaling)为更高分辨率的图像(512×512)。有了Upscaler Diffusion的加持,结合文本到图像模型,Stable Diffusion 2.0可以生成分辨率为2048×2048或更高的图像。
3、Depth-to-Image Diffusion Model
(5)、引入深度引导稳定扩散模型(depth2img)保持图像连贯性
这是一种新的深度引导稳定扩散(depth-guided stable diffusion)模型,它扩展了V1中先前的图像到图像的特性,为创造性的应用提供了全新的可能性。
通过使用现有模型,Depth2img能够推断输入图像的深度,然后使用文本和深度信息生成新图像。
depth2img可以提供各种新的创新性应用,生成的图像与原始图像有很大的不同,但仍然保持了图像的连贯性和深度。用于图像–图像结构的保持和形状的合成,为创意应用提供了全新的可能性。

4、Updated Inpainting Diffusion Model
(6)、引入文本引导修复扩散模型(text-guided)实现智能替换
引入了一个新的文本引导(text-guided)修复模型,在新的Stable Diffusion 2.0文本到图像的基础上,进行了微调,这使得智能和快速切换图像的部分非常容易。这样,用户就可以非常智能、快速地替换图像的部分内容,比如图中豹子的嘴巴和鼻子是不变的,其他部分可以随意改变。
关于Stability AI对Stable Diffusion的开源的观点
Stability AI的免费开源VS OpenAI的趋向商业化
Stability AI对标公司——OpenAI和DeepMind
有时候那些大型的AI公司,他们有一种家长式的本能,拒绝公布图像生成的代码。以OpenAI、DeepMind等这些公司为例,OpenAI一开始的初衷是「希望AI民主化」,但基于现实商业化原因,只对一部分模型开源。
相对来说,Stability AI与OpenAI旗下多款AI工具平台不同,开发者可以免费从其官网下载Stability AI的底层代码,来训练自己的模型。
备注01:2019年,马斯克因为战略分歧退出了OpenAI,整个公司的结构随之发生变化,焦点也变了,他们变得更加重视产品,尽管实际上并没有侧重在产品研发。虽然现有这些模型很强大能做很多事,却还没有技术扩散曲线。
备注02:Stability AI首席执行官Emad Mostaque曾说,关于寻找的贡献者人才的类型,我们不希望看到的是被高度企业化的人,他们的思维方式往往固定在一种方式,总想着如何赚快钱。
Stable Diffusion对标产品——DALL-E
与OpenAI的DALL-E等不同,Stable Diffusion是一款完全开源的软件。这允许社区的小伙伴一同开发、改进这款产品,并让开发人员免费将其集成到他们的产品中。
关于技术开源的善恶
如果DALL-E 2对每个人都开放,假如你输入了某个提示,却产生了非常可怕的东西,这是一种严重的负面影响。人们可能就会说这些模型显然不适合发布之类的。那么如果有人来找你,说你的模型产生了可怕的输出,你会对这些人说什么?
Emad解释到,技术无好坏,但使用的方式却分善恶。
争议—AI式“不可描述内容”是否道德
Stable Diffusion早期曾因“不可描述内容”生成神器之名蜚声海内外,比如情色图片等。
在最新的Stable Diffusion2.0版本开源之后,Mostaque说:“在开放模式中不能有儿童和NSFW,因为这两种图像可以结合起来制作儿童性虐待素材”。这正是Stable Diffusion从训练数据中删除裸体和色情图片的初心。
但是有的用户认为,这种删除行为违背了开源社区的精神哲学,因为删除NSFW内容设立了审查制度,这有很大的主观性。选择是否制作NSFW内容的权力,应该掌握在用户手中,而不是由审查模式来评判。
所以,Stable Diffusion的定位是开源的,这意味着「这类」训练数据可以很容易地添回第三方版本,而且新软件不会影响早期版本。也就是说,模型通过再训练还是回归到了“平民化”开源的本质。
争议—AI式“复制”是否合法
Stability AI首席执行官Emad Mostaque在Discord上表示:“一个好的模型应该可以供所有人使用,如果你想添加东西,那就自行添加”。这意味着Stable Diffusion在使用方式上的限制比较少,但也因此,它招致了大量批评。
Stable Diffusion1.0版本,和其他图像生成模型在未经艺术家同意的情况下,在他们的作品上进行训练,并重现他们作品的风格,许多艺术家大为恼火。
所以,在最新的Stable Diffusion 2.0版本中,进行了更新,对软件编码和检索数据的方式进行更改,因此,模型复制艺术家作品的能力大大降低。
Stable Diffusion模型的使用方法
0、Stable Diffusion模型的两种实现方法
T1、在线网页演示实现
Stable Diffusion 2 – a Hugging Face Space by stabilityai
T2、本地下载部署实现
硬件要求:8G的VRAM只能输出256的图像
| 第1步 | 第一步,安装项目的环境依赖 conda install pytorch==1.12.1 torchvision==0.13.1 -c pytorch pip install transformers==4.19.2 diffusers invisible-watermark pip install -e . |
| 第2步 | 第二步,创建新的conda环境 conda create –name sd2 python=3.10 |
| 第3步 | 第三步,安装所需的包 pip install -r requirements.txt |
| 第4步 | 第四步,安装watermark包(可选) pip install transformers==4.19.2 diffusers invisible-watermark |
| 第5步 | 第五步,获取CUDA最新版本(linux系统) conda install -c nvidia/label/cuda-11.4.0 cuda-nvcc conda install -c conda-forge gcc conda install -c conda-forge gxx_linux-64=9.5.0 |
| 第6步 | 第六步,安装xformer git clone https://github.com/facebookresearch/xformers.git cd xformers git submodule update –init –recursive pip install -r requirements.txt pip install -e . cd ../stable-diffusion |
| 第7步 | 第七步,下载所需的权重模型 |
| 第8步 | 第八步,测试 python scripts/txt2img.py –prompt "a professional photograph of an astronaut riding a horse" –ckpt .\models\512-base-ema.ckpt –config configs/stable-diffusion/v2-inference-v.yaml –H 512 –W 512 –plms –n_samples 1 |
T3、C端优化部署应用
相比较于基于服务器部署,在C端设备上部署 Stable Diffusion,除了减少部署服务器开销之外,更能直接触达用户和保护隐私,因为数据不出本地。当然,这还需要对Stable Diffusion模型进行优化。
Github地址:https://github.com/apple/ml-stable-diffusion
1、文本到图像

参考采样脚本如下所示
第一步,下载模型权重
第二步,两种方法采样
从SD2.0-v模型中采样,执行以下命令
python scripts/txt2img.py --prompt "a professional photograph of an astronaut riding a horse" --ckpt <path/to/768model.ckpt/> --config configs/stable-diffusion/v2-inference-v.yaml --H 768 --W 768从基本模型中采样,执行以下命令
python scripts/txt2img.py --prompt "a professional photograph of an astronaut riding a horse" --ckpt <path/to/model.ckpt/> --config <path/to/config.yaml/> 2、图像修改

 此方法可用于基础模型本身的样本。例如,以匿名 discord 用户生成的这个样本为例。使用gradio或streamlit脚本depth2img.py,MiDaS 模型首先根据此输入推断出单眼深度估计,然后扩散模型以(相对)深度输出为条件。
此方法可用于基础模型本身的样本。例如,以匿名 discord 用户生成的这个样本为例。使用gradio或streamlit脚本depth2img.py,MiDaS 模型首先根据此输入推断出单眼深度估计,然后扩散模型以(相对)深度输出为条件。
该模型对于照片写实风格特别有用;看例子。对于 1.0 的最大强度,该模型会删除所有基于像素的信息,并且仅依赖于文本提示和推断的单眼深度估计。
{kind=link}
第一步,下载模型权重,将后者放在文件夹中midas_models
深度条件稳定扩散模型和dpt_hybridMiDaS模型权重
第二步,执行以下命令
python scripts/gradio/depth2img.py configs/stable-diffusion/v2-midas-inference.yaml <path-to-ckpt>3、图像超分辨率/图像放大
用于文本引导的 x4 超分辨率模型的 Gradio 或 Streamlit 演示。该模型既可用于真实输入,也可用于合成示例。对于后者,我们建议设置更高的 noise_level,例如noise_level=100。

第一步,下载模型权重,
stabilityai/stable-diffusion-x4-upscaler · Hugging Face
第二步,执行以下命令
python scripts/gradio/superresolution.py configs/stable-diffusion/x4-upscaling.yaml <path-to-checkpoint>4、图像修复

修复模型的 Gradio 或 Streamlit 演示。该脚本向RunwayML存储库中的演示添加了不可见的水印,但两者应该可以与检查点/配置互换使用。
第一步,下载模型权重,
stabilityai/stable-diffusion-2-inpainting · Hugging Face
第二步,执行以下命令
python scripts/gradio/inpainting.py configs/stable-diffusion/v2-inpainting-inference.yaml <path-to-checkpoint>参考文章
Stable Diffusion 2.0 Release — Stability.Ai
https://www.reddit.com/r/StableDiffusion/comments/z36mm2/stable_diffusion_20_announcement/
文章出处登录后可见!