本文大量参考英文文献Understanding Latent Space in Machine Learning,并给出一些个人浅显的理解。本意在记录,其次在分享。
1.什么是潜在编码?
事实上,接触过深度学习或机器学习,应该就算是接触过潜在编码。潜在编码我的理解就是一种降维或者说是压缩,旨在用更少的信息去表达数据的本质。
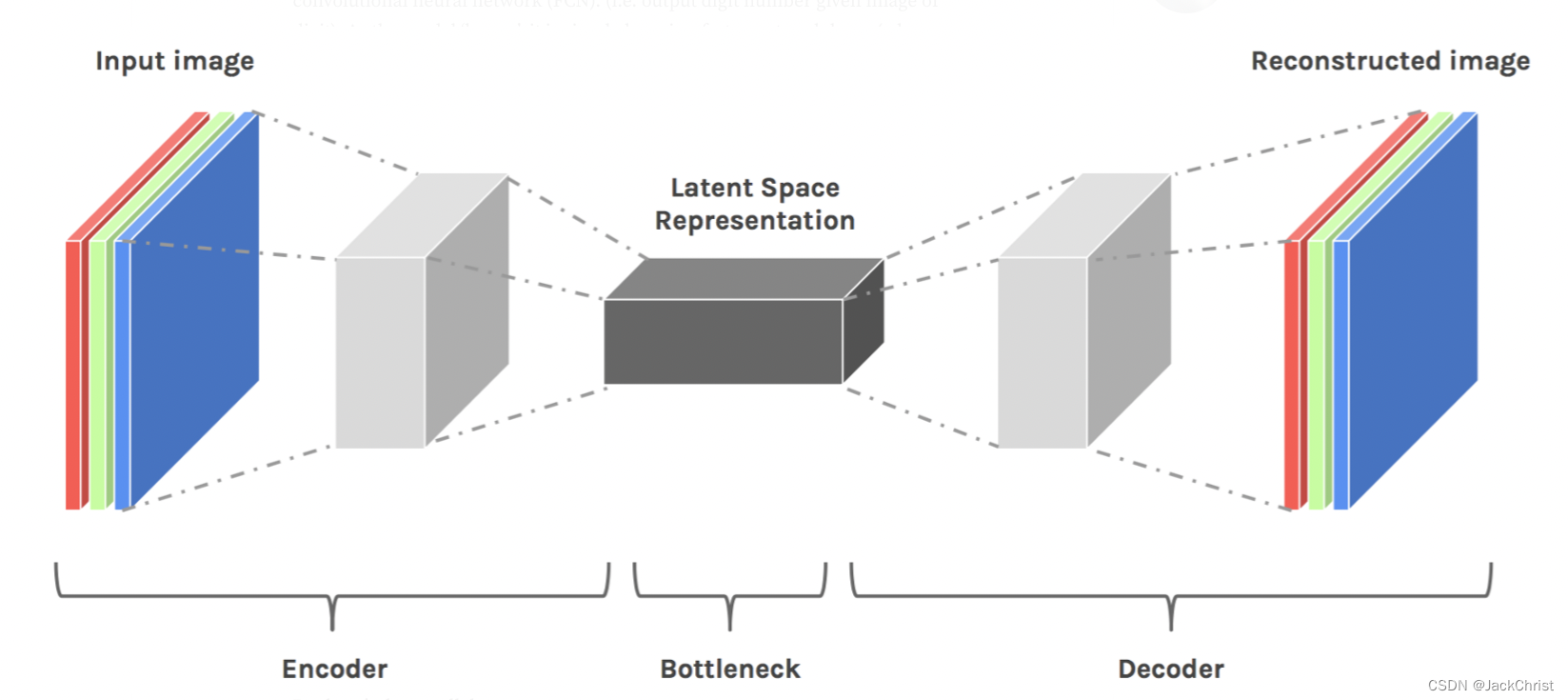
上图是一个简单的encoder-decoder架构,如果把整个网络看成一个花瓶,最细的地方则称之为瓶颈。我们知道,压缩一般都是有损的,这里也不例外,但如果损失的是噪声或者是无用信息是我们最喜欢的了(这样就可以达到信息压缩的目的)
通过encoder压缩之后,更重要的是恢复,我们理应认为,能恢复的才算成功压缩了的,那么我们就可以认为这个latent space representation是真的表达出了input image中最关键的信息。
2.什么是潜在空间?
我个人的理解是,潜在空间和潜在编码是一个意思,编码->空间是符合直觉的,例如3×1的编码就可以画成三维空间的一个点。
3.进一步理解同类潜在编码相似
首先定义什么是同类,椅子和椅子是同类,狗和狗是同类。如图所示,如果使用完整的3D表征去表示A椅子和B椅子,那么他们之间是不会接近的,一眼就可以看出来一个黄色一个黑色,朝向也不同。但,如果把一些"个性化的特征"去掉,仅保留一类的特征,那么它们在潜在空间中的点是非常非常接近的,例如把颜色去掉。在空间中想象,A椅子和B椅子此时会很接近,我们就认为很相似。

4.潜在编码的应用
那么,我们如果完美的得到一个东西的潜在表征,即latent code(也可以叫latent space or latent space representation),我们可以利用它做什么?
这里不得不提到 Antoencoders 和 Generative models。
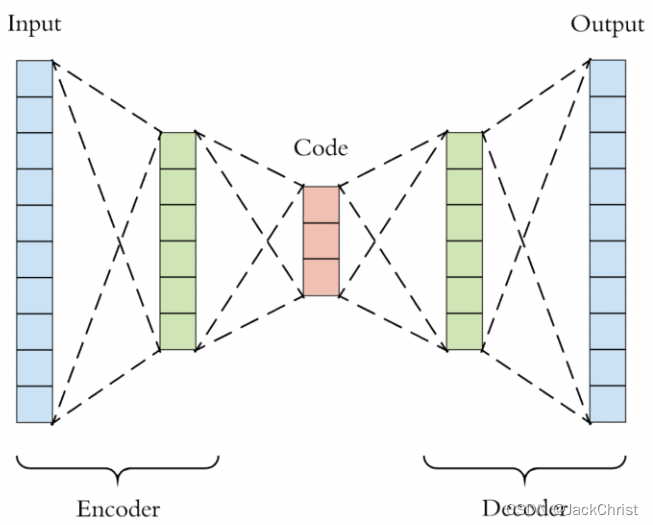
自编码器,顾名思义,自己给自己编码,可以发现本网络输出和输入都是一个东西,如果以输出"定英雄"那么我们认为是无意义的,但如果观察其过程,我们知道latent coder 通过Decoder恢复成了自己,具体的实施就更简单了,只需要把输出与输入做相似度损失,然后反向传播,慢慢地就像了。
潜在空间插值
同类在空间中是相近的,例如两把椅子的向量为[0.1,0.1]和[0.12,0.12],把这两个喂入网络中,生成的当然是椅子,那如果输入[0.11,0.11]呢?当然也是椅子,这就是插值。下图展示了插值的效果,可以看到同类周围插值就相似但有微小区别的。最简单的应用就是把它当成一种数据增强去扩大数据集。

下图为两把椅子之间进行线性插值的效果图。

5.结论
潜在空间可以用少量的数据表示某一个(类)信息,在3D表示等领域中也有更为具体的应用。
文章出处登录后可见!