目录
赛题背景
商家一般会在 “双十一”,“双十二” 等节日进行大规模的促销,比如各种折扣券和现金券。然而,被低价、折扣、各种让利吸引的用户往往在这次消费之后就再也没有购买,主要为了“薅羊毛”,针对这些用户的促销并没有带来未来销量的提高,只是增加了相应的营销成本。因此店铺有迫切的需求,想知道哪些用户可能会成为重复购买其店铺商品的忠诚用户,以便对这些有潜力的用户进行精准营销,以降低促销成本,提高投资回报率。
这个赛题的目标就是给一堆数据(用户、店铺的历史行为),然后用训练好的模型预测新用户是否会在6个月内再次从同一店铺购买商品。所以这是一个典型的二分类问题。
常见的分类算法:朴素贝叶斯,决策树,支持向量机,KNN,逻辑回归等等;
集成学习:随机森林,GBDT(梯度提升决策树),Adaboot,XGBoost,LightGBM,CatBoost等等;
神经网络:MLP(多层神经网络),DL(深度学习)等。
本赛题的数据量不大,一把用不到深度学习,根据赛题特点,集成算法,尤其是XGBoost,LightGBM,CatBoost等算法效果会比较好。
全代码
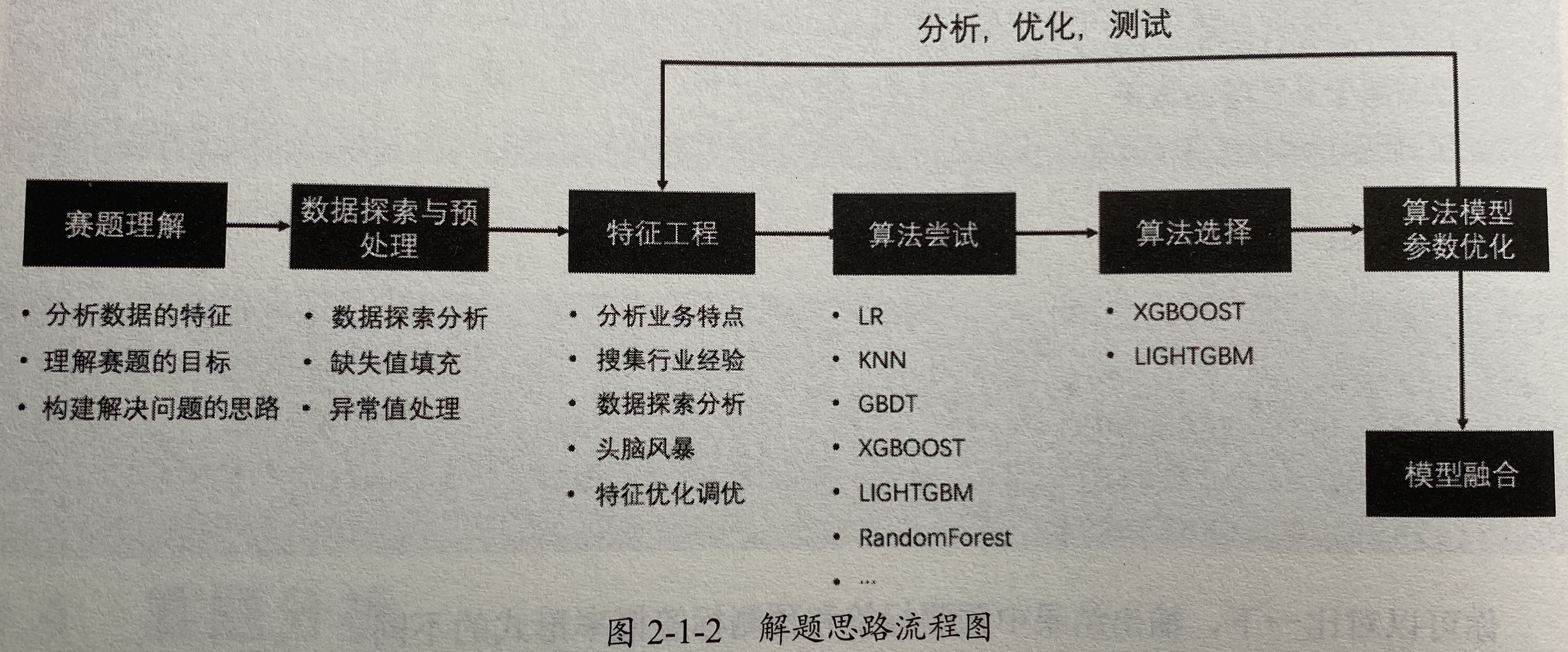
一个典型的机器学习实战算法基本包括 1) 数据处理,2) 特征选取、优化,和 3) 模型选取、验证、优化。 因为 “数据和特征决定了机器学习的上限,而模型和算法知识逼近这个上限而已。” 所以在解决一个机器学习问题时大部分时间都会花在数据处理和特征优化上。
大家最好在jupyter notebook上一段一段地跑下面的代码,加深理解。
机器学习的基本知识可以康康我的其他文章哦 好康的。
导入包
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings("ignore")
读取数据(训练数据前10000行,测试数据前100条)
train_data = pd.read_csv('train_all.csv',nrows=10000)
test_data = pd.read_csv('test_all.csv',nrows=100)
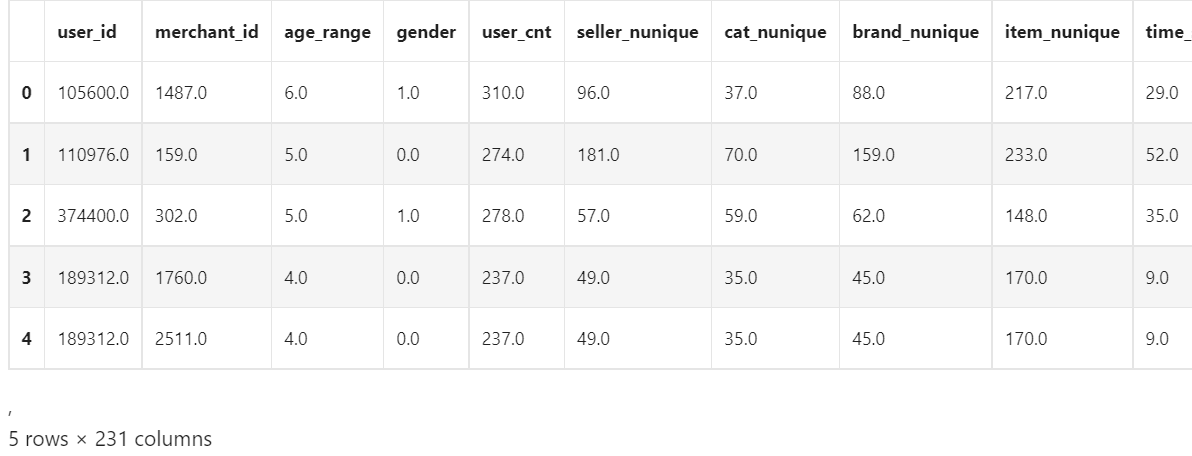
train_data.head()
test_data.head()
读取全部数据
train_data.columns
获取训练和测试数据
features_columns = [col for col in train_data.columns if col not in ['user_id','label']]
train = train_data[features_columns].values
test = test_data[features_columns].values
target =train_data['label'].values
切分40%数据用于线下验证
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=100, max_depth=2, random_state=0, n_jobs=-1)
X_train, X_test, y_train, y_test = train_test_split(train, target, test_size=0.4, random_state=0)
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
clf = clf.fit(X_train, y_train)
clf.score(X_test, y_test)
交叉验证:评估估算器性能
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=100, max_depth=2, random_state=0, n_jobs=-1)
scores = cross_val_score(clf, train, target, cv=5)
print(scores)
print("Accuracy: %0.2f (+/- %0.2f)" % (scores.mean(), scores.std() * 2))
F1验证
from sklearn import metrics
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=100, max_depth=2, random_state=0, n_jobs=-1)
scores = cross_val_score(clf, train, target, cv=5, scoring='f1_macro')
print(scores)
print("F1: %0.2f (+/- %0.2f)" % (scores.mean(), scores.std() * 2))
ShuffleSplit切分数据
from sklearn.model_selection import ShuffleSplit
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=100, max_depth=2, random_state=0, n_jobs=-1)
cv = ShuffleSplit(n_splits=5, test_size=0.3, random_state=0)
cross_val_score(clf, train, target, cv=cv)
模型调参
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
from sklearn.ensemble import RandomForestClassifier
# Split the dataset in two equal parts
X_train, X_test, y_train, y_test = train_test_split(train, target, test_size=0.5, random_state=0)
# model
clf = RandomForestClassifier(n_jobs=-1)
# Set the parameters by cross-validation
tuned_parameters = {
'n_estimators': [50, 100, 200]
# ,'criterion': ['gini', 'entropy']
# ,'max_depth': [2, 5]
# ,'max_features': ['log2', 'sqrt', 'int']
# ,'bootstrap': [True, False]
# ,'warm_start': [True, False]
}
scores = ['precision']
for score in scores:
print("# Tuning hyper-parameters for %s" % score)
print()
clf = GridSearchCV(clf, tuned_parameters, cv=5,
scoring='%s_macro' % score)
clf.fit(X_train, y_train)
print("Best parameters set found on development set:")
print()
print(clf.best_params_)
print()
print("Grid scores on development set:")
print()
means = clf.cv_results_['mean_test_score']
stds = clf.cv_results_['std_test_score']
for mean, std, params in zip(means, stds, clf.cv_results_['params']):
print("%0.3f (+/-%0.03f) for %r"
% (mean, std * 2, params))
print()
print("Detailed classification report:")
print()
print("The model is trained on the full development set.")
print("The scores are computed on the full evaluation set.")
print()
y_true, y_pred = y_test, clf.predict(X_test)
print(classification_report(y_true, y_pred))
print()
模糊矩阵
import itertools
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
from sklearn.ensemble import RandomForestClassifier
# label name
class_names = ['no-repeat', 'repeat']
# Split the data into a training set and a test set
X_train, X_test, y_train, y_test = train_test_split(train, target, random_state=0)
# Run classifier, using a model that is too regularized (C too low) to see
# the impact on the results
clf = RandomForestClassifier(n_jobs=-1)
y_pred = clf.fit(X_train, y_train).predict(X_test)
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print("Normalized confusion matrix")
else:
print('Confusion matrix, without normalization')
print(cm)
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.tight_layout()
# Compute confusion matrix
cnf_matrix = confusion_matrix(y_test, y_pred)
np.set_printoptions(precision=2)
# Plot non-normalized confusion matrix
plt.figure()
plot_confusion_matrix(cnf_matrix, classes=class_names,
title='Confusion matrix, without normalization')
# Plot normalized confusion matrix
plt.figure()
plot_confusion_matrix(cnf_matrix, classes=class_names, normalize=True,
title='Normalized confusion matrix')
plt.show()

from sklearn.metrics import classification_report
from sklearn.ensemble import RandomForestClassifier
# label name
class_names = ['no-repeat', 'repeat']
# Split the data into a training set and a test set
X_train, X_test, y_train, y_test = train_test_split(train, target, random_state=0)
# Run classifier, using a model that is too regularized (C too low) to see
# the impact on the results
clf = RandomForestClassifier(n_jobs=-1)
y_pred = clf.fit(X_train, y_train).predict(X_test)
print(classification_report(y_test, y_pred, target_names=class_names))

不同的分类模型
LR 模型
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
stdScaler = StandardScaler()
X = stdScaler.fit_transform(train)
# Split the data into a training set and a test set
X_train, X_test, y_train, y_test = train_test_split(X, target, random_state=0)
clf = LogisticRegression(random_state=0, solver='lbfgs', multi_class='multinomial').fit(X_train, y_train)
clf.score(X_test, y_test)
KNN 模型
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
stdScaler = StandardScaler()
X = stdScaler.fit_transform(train)
# Split the data into a training set and a test set
X_train, X_test, y_train, y_test = train_test_split(X, target, random_state=0)
clf = KNeighborsClassifier(n_neighbors=3).fit(X_train, y_train)
clf.score(X_test, y_test)
tree树模型
from sklearn import tree
# Split the data into a training set and a test set
X_train, X_test, y_train, y_test = train_test_split(train, target, random_state=0)
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X_train, y_train)
clf.score(X_test, y_test)
bagging模型
from sklearn.ensemble import BaggingClassifier
from sklearn.neighbors import KNeighborsClassifier
# Split the data into a training set and a test set
X_train, X_test, y_train, y_test = train_test_split(train, target, random_state=0)
clf = BaggingClassifier(KNeighborsClassifier(), max_samples=0.5, max_features=0.5)
clf = clf.fit(X_train, y_train)
clf.score(X_test, y_test)
随机森林模型
from sklearn.ensemble import RandomForestClassifier
# Split the data into a training set and a test set
X_train, X_test, y_train, y_test = train_test_split(train, target, random_state=0)
clf = clf = RandomForestClassifier(n_estimators=10, max_depth=3, min_samples_split=12, random_state=0)
clf = clf.fit(X_train, y_train)
clf.score(X_test, y_test)
ExTree模型
from sklearn.ensemble import ExtraTreesClassifier
# Split the data into a training set and a test set
X_train, X_test, y_train, y_test = train_test_split(train, target, random_state=0)
clf = ExtraTreesClassifier(n_estimators=10, max_depth=None, min_samples_split=2, random_state=0)
clf = clf.fit(X_train, y_train)
clf.score(X_test, y_test)
clf.n_features_
clf.feature_importances_[:10]
AdaBoost模型
from sklearn.ensemble import AdaBoostClassifier
# Split the data into a training set and a test set
X_train, X_test, y_train, y_test = train_test_split(train, target, random_state=0)
clf = AdaBoostClassifier(n_estimators=10)
clf = clf.fit(X_train, y_train)
clf.score(X_test, y_test)
GBDT模型
from sklearn.ensemble import GradientBoostingClassifier
# Split the data into a training set and a test set
X_train, X_test, y_train, y_test = train_test_split(train, target, random_state=0)
clf = GradientBoostingClassifier(n_estimators=10, learning_rate=1.0, max_depth=1, random_state=0)
clf = clf.fit(X_train, y_train)
clf.score(X_test, y_test)
VOTE模型投票
from sklearn import datasets
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.preprocessing import StandardScaler
stdScaler = StandardScaler()
X = stdScaler.fit_transform(train)
y = target
clf1 = LogisticRegression(solver='lbfgs', multi_class='multinomial', random_state=1)
clf2 = RandomForestClassifier(n_estimators=50, random_state=1)
clf3 = GaussianNB()
eclf = VotingClassifier(estimators=[('lr', clf1), ('rf', clf2), ('gnb', clf3)], voting='hard')
for clf, label in zip([clf1, clf2, clf3, eclf], ['Logistic Regression', 'Random Forest', 'naive Bayes', 'Ensemble']):
scores = cross_val_score(clf, X, y, cv=5, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))
lgb 模型
import lightgbm
X_train, X_test, y_train, y_test = train_test_split(train, target, test_size=0.4, random_state=0)
X_test, X_valid, y_test, y_valid = train_test_split(X_test, y_test, test_size=0.5, random_state=0)
clf = lightgbm
train_matrix = clf.Dataset(X_train, label=y_train)
test_matrix = clf.Dataset(X_test, label=y_test)
params = {
'boosting_type': 'gbdt',
#'boosting_type': 'dart',
'objective': 'multiclass',
'metric': 'multi_logloss',
'min_child_weight': 1.5,
'num_leaves': 2**5,
'lambda_l2': 10,
'subsample': 0.7,
'colsample_bytree': 0.7,
'colsample_bylevel': 0.7,
'learning_rate': 0.03,
'tree_method': 'exact',
'seed': 2017,
"num_class": 2,
'silent': True,
}
num_round = 10000
early_stopping_rounds = 100
model = clf.train(params,
train_matrix,
num_round,
valid_sets=test_matrix,
early_stopping_rounds=early_stopping_rounds)
pre= model.predict(X_valid,num_iteration=model.best_iteration)
print('score : ', np.mean((pre[:,1]>0.5)==y_valid))
xgb 模型
import xgboost
X_train, X_test, y_train, y_test = train_test_split(train, target, test_size=0.4, random_state=0)
X_test, X_valid, y_test, y_valid = train_test_split(X_test, y_test, test_size=0.5, random_state=0)
clf = xgboost
train_matrix = clf.DMatrix(X_train, label=y_train, missing=-1)
test_matrix = clf.DMatrix(X_test, label=y_test, missing=-1)
z = clf.DMatrix(X_valid, label=y_valid, missing=-1)
params = {'booster': 'gbtree',
'objective': 'multi:softprob',
'eval_metric': 'mlogloss',
'gamma': 1,
'min_child_weight': 1.5,
'max_depth': 5,
'lambda': 100,
'subsample': 0.7,
'colsample_bytree': 0.7,
'colsample_bylevel': 0.7,
'eta': 0.03,
'tree_method': 'exact',
'seed': 2017,
"num_class": 2
}
num_round = 10000
early_stopping_rounds = 100
watchlist = [(train_matrix, 'train'),
(test_matrix, 'eval')
]
model = clf.train(params,
train_matrix,
num_boost_round=num_round,
evals=watchlist,
early_stopping_rounds=early_stopping_rounds
)
pre = model.predict(z,ntree_limit=model.best_ntree_limit)
print('score : ', np.mean((pre[:,1]>0.3)==y_valid))
自己封装模型
Stacking,Bootstrap,Bagging技术实践
"""
导入相关包
"""
import pandas as pd
import numpy as np
import lightgbm as lgb
from sklearn.metrics import f1_score
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.model_selection import StratifiedKFold
class SBBTree():
"""
SBBTree
Stacking,Bootstap,Bagging
"""
def __init__(
self,
params,
stacking_num,
bagging_num,
bagging_test_size,
num_boost_round,
early_stopping_rounds
):
"""
Initializes the SBBTree.
Args:
params : lgb params.
stacking_num : k_flod stacking.
bagging_num : bootstrap num.
bagging_test_size : bootstrap sample rate.
num_boost_round : boost num.
early_stopping_rounds : early_stopping_rounds.
"""
self.params = params
self.stacking_num = stacking_num
self.bagging_num = bagging_num
self.bagging_test_size = bagging_test_size
self.num_boost_round = num_boost_round
self.early_stopping_rounds = early_stopping_rounds
self.model = lgb
self.stacking_model = []
self.bagging_model = []
def fit(self, X, y):
""" fit model. """
if self.stacking_num > 1:
layer_train = np.zeros((X.shape[0], 2))
self.SK = StratifiedKFold(n_splits=self.stacking_num, shuffle=True, random_state=1)
for k,(train_index, test_index) in enumerate(self.SK.split(X, y)):
X_train = X[train_index]
y_train = y[train_index]
X_test = X[test_index]
y_test = y[test_index]
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
gbm = lgb.train(self.params,
lgb_train,
num_boost_round=self.num_boost_round,
valid_sets=lgb_eval,
early_stopping_rounds=self.early_stopping_rounds)
self.stacking_model.append(gbm)
pred_y = gbm.predict(X_test, num_iteration=gbm.best_iteration)
layer_train[test_index, 1] = pred_y
X = np.hstack((X, layer_train[:,1].reshape((-1,1))))
else:
pass
for bn in range(self.bagging_num):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=self.bagging_test_size, random_state=bn)
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
gbm = lgb.train(self.params,
lgb_train,
num_boost_round=10000,
valid_sets=lgb_eval,
early_stopping_rounds=200)
self.bagging_model.append(gbm)
def predict(self, X_pred):
""" predict test data. """
if self.stacking_num > 1:
test_pred = np.zeros((X_pred.shape[0], self.stacking_num))
for sn,gbm in enumerate(self.stacking_model):
pred = gbm.predict(X_pred, num_iteration=gbm.best_iteration)
test_pred[:, sn] = pred
X_pred = np.hstack((X_pred, test_pred.mean(axis=1).reshape((-1,1))))
else:
pass
for bn,gbm in enumerate(self.bagging_model):
pred = gbm.predict(X_pred, num_iteration=gbm.best_iteration)
if bn == 0:
pred_out=pred
else:
pred_out+=pred
return pred_out/self.bagging_num
测试自己封装的模型类
"""
TEST CODE
"""
from sklearn.datasets import make_classification
from sklearn.datasets import load_breast_cancer
from sklearn.datasets import make_gaussian_quantiles
from sklearn import metrics
from sklearn.metrics import f1_score
# X, y = make_classification(n_samples=1000, n_features=25, n_clusters_per_class=1, n_informative=15, random_state=1)
X, y = make_gaussian_quantiles(mean=None, cov=1.0, n_samples=1000, n_features=50, n_classes=2, shuffle=True, random_state=2)
# data = load_breast_cancer()
# X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
params = {
'task': 'train',
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'num_leaves': 9,
'learning_rate': 0.03,
'feature_fraction_seed': 2,
'feature_fraction': 0.9,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'min_data': 20,
'min_hessian': 1,
'verbose': -1,
'silent': 0
}
# test 1
model = SBBTree(params=params, stacking_num=2, bagging_num=1, bagging_test_size=0.33, num_boost_round=10000, early_stopping_rounds=200)
model.fit(X,y)
X_pred = X[0].reshape((1,-1))
pred=model.predict(X_pred)
print('pred')
print(pred)
print('TEST 1 ok')
# test 1
model = SBBTree(params, stacking_num=1, bagging_num=1, bagging_test_size=0.33, num_boost_round=10000, early_stopping_rounds=200)
model.fit(X_train,y_train)
pred1=model.predict(X_test)
# test 2
model = SBBTree(params, stacking_num=1, bagging_num=3, bagging_test_size=0.33, num_boost_round=10000, early_stopping_rounds=200)
model.fit(X_train,y_train)
pred2=model.predict(X_test)
# test 3
model = SBBTree(params, stacking_num=5, bagging_num=1, bagging_test_size=0.33, num_boost_round=10000, early_stopping_rounds=200)
model.fit(X_train,y_train)
pred3=model.predict(X_test)
# test 4
model = SBBTree(params, stacking_num=5, bagging_num=3, bagging_test_size=0.33, num_boost_round=10000, early_stopping_rounds=200)
model.fit(X_train,y_train)
pred4=model.predict(X_test)
fpr, tpr, thresholds = metrics.roc_curve(y_test+1, pred1, pos_label=2)
print('auc: ',metrics.auc(fpr, tpr))
fpr, tpr, thresholds = metrics.roc_curve(y_test+1, pred2, pos_label=2)
print('auc: ',metrics.auc(fpr, tpr))
fpr, tpr, thresholds = metrics.roc_curve(y_test+1, pred3, pos_label=2)
print('auc: ',metrics.auc(fpr, tpr))
fpr, tpr, thresholds = metrics.roc_curve(y_test+1, pred4, pos_label=2)
print('auc: ',metrics.auc(fpr, tpr))
# auc: 0.7281621243885396
# auc: 0.7710471146419509
# auc: 0.7894369046305492
# auc: 0.8084519474787597
天猫复购场景实战
读取特征数据
import pandas as pd
import numpy as np
import lightgbm as lgb
from sklearn.metrics import f1_score
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.model_selection import StratifiedKFold
train_data = pd.read_csv('train_all.csv',nrows=10000)
test_data = pd.read_csv('test_all.csv',nrows=100)
features_columns = [col for col in train_data.columns if col not in ['user_id','label']]
train = train_data[features_columns].values
test = test_data[features_columns].values
target =train_data['label'].values
设置模型参数
params = {
'task': 'train',
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'num_leaves': 9,
'learning_rate': 0.03,
'feature_fraction_seed': 2,
'feature_fraction': 0.9,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'min_data': 20,
'min_hessian': 1,
'verbose': -1,
'silent': 0
}
model = SBBTree(params=params,
stacking_num=5,
bagging_num=3,
bagging_test_size=0.33,
num_boost_round=10000,
early_stopping_rounds=200)
模型训练
model.fit(train, target)
预测结果
pred = model.predict(test)
df_out = pd.DataFrame()
df_out['user_id'] = test_data['user_id'].astype(int)
df_out['predict_prob'] = pred
df_out.head()
保存结果
"""
保留数据头,不保存index
"""
df_out.to_csv('df_out.csv',header=True,index=False)
print('save OK!')
以上内容和代码全部来自于《阿里云天池大赛赛题解析(机器学习篇)》这本好书,十分推荐大家去阅读原书!
文章出处登录后可见!
已经登录?立即刷新