1.GAN
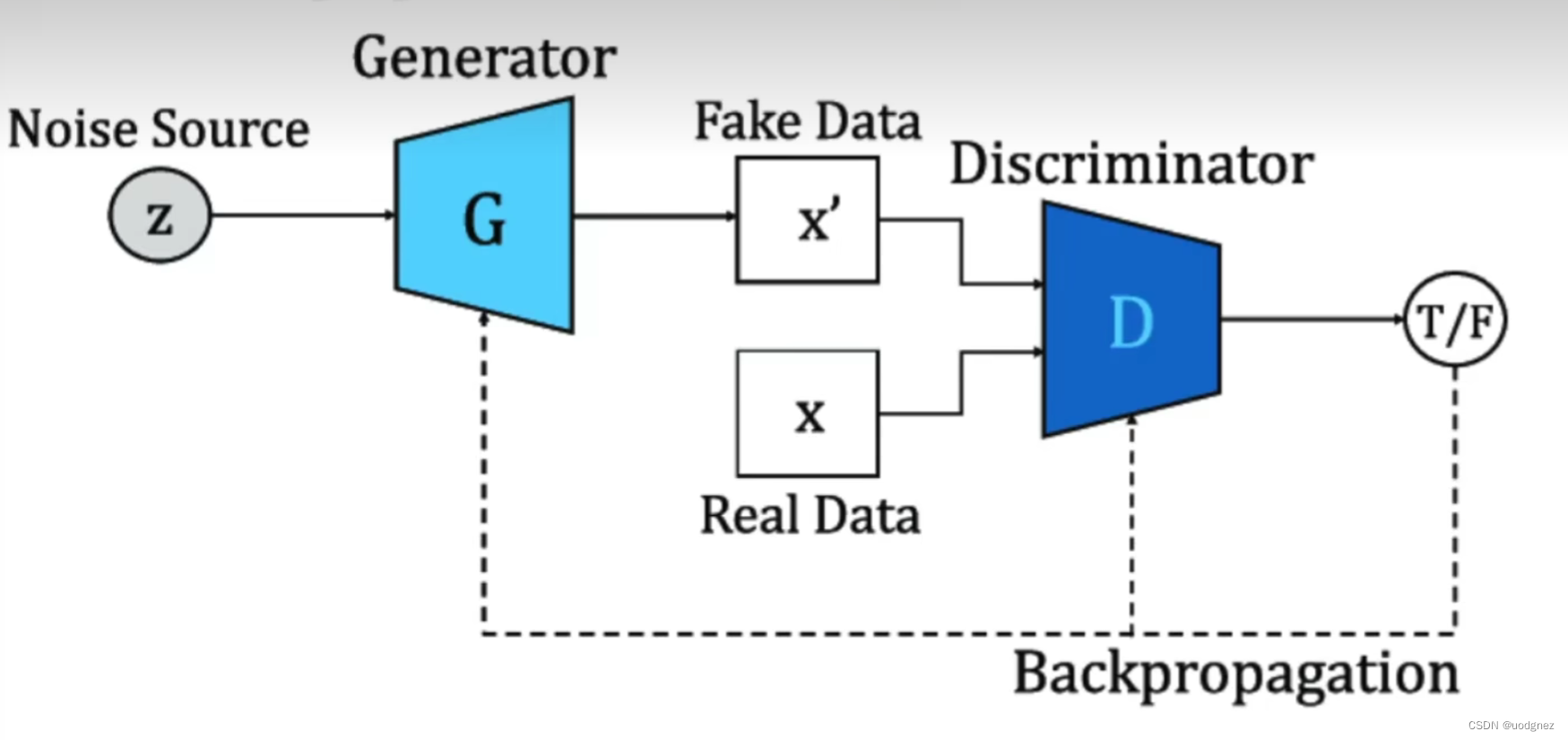
在训练过程中,生成器和判别器的目标是相矛盾的,并且这种矛盾可以体现在判别器的判断准确性上。生成器的目标是生成尽量真实的数据,最好能够以假乱真、让判别器判断不出来,因此生成器的学习目标是让判别器上的判断准确性越来越低;相反,判别器的目标是尽量判别出真伪,因此判别器的学习目标是让自己的判别准确性越来越高。
当生成器生成的数据越来越真时,判别器为维持住自己的准确性,就必须向辨别能力越来越强的方向迭代。当判别器越来越强大时,生成器为了降低判别器的判断准确性,就必须生成越来越真的数据。在这个奇妙的关系中,判别器判断的准确性由GAN论文中定义的特殊交叉熵来衡量,判别器与生成器共同影响交叉熵
,同时训练、相互内卷,对该交叉熵的控制时此消彼长的,这是真正的零和博弈。
2. 特殊交叉熵
在生成器与判别器的内卷关系中,GAN的特殊交叉熵公式如下:
其中,字母是原始GAN论文中指定用来表示该交叉熵的字母,对数
的底数为自然底数
,
表示共有
个样本,因此以上表达式是全部样本交叉的均值表达式。
除此之外,表示任意真实数据,
与真实数据相同结构的任意随机数据,
表示在生成器中基于
生成的假数据,而
表示判别器在真实数据
上判断出的结果,
表示判别器在假数据
上判断出的结果,其中
与
都是样本为“真”的概率,即标签为
的概率。
在原始论文中,这一交叉熵被认为是一种“损失”,但它有两个特殊之处:
- 不同于二分类交叉熵等常见的损失函数,损失
与
都是概率,因此这两个值的范围都在
之间。对于底数为
的对数函数来说,在定义域为
。因此理论上来说,损失
- 损失
不难发现,在的表达式中,两部分对数都与判别器
有关,而只有后半部分的对数与生成器
有关。因此我们可以按如下方式分割损失函数:
对判别器:
从判别器的角度来看,由于判别器希望自己尽量能够判断正确,而输出概率又是“数据为真”的概率,所以最佳情况就是所有的真实样本上的输出都无比接近
,而所有的假样本上的输出
都无比接近
。因此对判别器来说,最佳损失值是:
这说明判别器希望以上损失越大越好,且最大值理论上可达
,且判别器追求大
的本质是令
接近
,令
接近
。不难发现,对判别器而言,
更像是一个存在上限的积极的指标(比如准确率)。
而从生成器的角度来看,生成器无法影响,只能影响
,因此只有损失的后半段与生成器相关。因此对生成器:
生成器的目标是令输出的数据越真越好,最好让判别器完全判断不出,因此生成器希望越接近
越好。因此对生成器来说,最佳损失是(去掉常数项):
这说明生成器希望以上损失越小越好,且最小理论值可达负无穷,且生成器追求小
的本质是令
接近
。对生成器而言,
更像是一个损失,即算法表现越好,该指标的值越低。从整个生成对抗网络的角度来看,我们(使用者)的目标与生成器的目标相一致,因此对我们而言,
被定义为损失,它应该越低越好。
在原始论文当中,该损失被表示为如下形式:
即先从判别器的角度令损失最大化,又从生成器的角度令损失最小化,即可让判别器和生成器在共享损失的情况下实现对抗。其中表示期望,第一个期望
是所有
都是真实数据时
的期望;第二个期望
是所有数据都是生成数据时
的期望。当真实数据、生成数据的样本点固定时,期望就等于均值。
如此,通过共享以上损失函数,生成器与判别器实现了在训练过程中互相对抗,的本质就是最小化
的同时最大化
。并且,在最开始训练时,由于生成器生成的数据与真实数据差异很大,因此
应该接近
,
应该接近
。理论上来说,只要训练顺利,最终
和
都应该非常接近
,但实际上这样的情况并不常见。
B站up:菜菜
文章出处登录后可见!