最近在学习在服务器的ubuntu环境上配置用多个显卡训练,之前只用一个显卡训练实在是太慢了点
先看看服务器上有几个显卡:
nvidia-smi
即可得到具体的显卡信息:
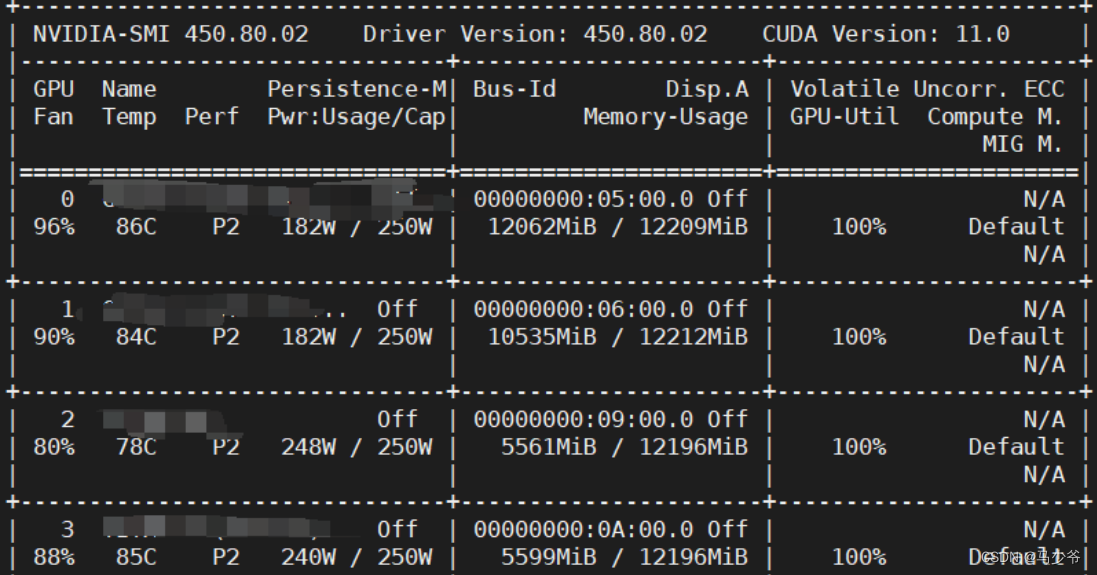
每个显卡之前有对应的编号。
然后得知自己服务器上总共有多少显卡后,插入以下代码:
#一机多卡设置
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1,2,3'#设置所有可以使用的显卡,共计四块
device_ids = [0,1]#选中其中两块
model = nn.DataParallel(model, device_ids=device_ids)#并行使用两块
#net = torch.nn.Dataparallel(model) # 默认使用所有的device_ids
model = model.cuda()
有两个注意点:
(1)笔者自己使用该代码时,虽然device_ids中选择的是0/1两块显卡,但是实际上却是在2/3两块显卡上运行的,这个可能是显示问题,大家可以运行之后再使用nvidia-smi命令查看到底是在哪两块显卡上训练的
(2)这个代码是要写在模型装载之后,比如说举例
model = CANNet2s()
在这后加上图示代码,才可以将model分配到硬件上,此处我使用的是model.cuda()函数,大家也可以用todevice。
对比一下只使用一张显卡:
#一机单卡设置
model = model.cuda()
将会自动选择一张可以用的显卡进行训练。
参考文献:https://blog.csdn.net/qq_45860671/article/details/122413798
修改cycleGan中的代码如下
原代码
disc_H = Discriminator(in_channels=3).to(config.DEVICE)
disc_Z = Discriminator(in_channels=3).to(config.DEVICE)
gen_Z = Generator(img_channels=3, num_residuals=9).to(config.DEVICE)
gen_H = Generator(img_channels=3, num_residuals=9).to(config.DEVICE)
修改后的代码:
disc_H = Discriminator(in_channels=3)
disc_Z = Discriminator(in_channels=3)
gen_Z = Generator(img_channels=3, num_residuals=9)
gen_H = Generator(img_channels=3, num_residuals=9)
#使用多gpu加速
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
disc_H = nn.DataParallel(disc_H, device_ids=[0,1])
disc_Z = nn.DataParallel(disc_Z, device_ids=[0,1])
gen_Z = nn.DataParallel(gen_Z, device_ids=[0,1])
gen_H = nn.DataParallel(gen_H, device_ids=[0,1])
disc_H.to(config.DEVICE)
disc_Z.to(config.DEVICE)
gen_Z.to(config.DEVICE)
gen_H.to(config.DEVICE)
参考文献:
https://blog.csdn.net/qq_34904125/article/details/118725862
文章出处登录后可见!
已经登录?立即刷新