随着全民健身热潮的兴起,越来越多的人积极参加健身锻炼,但由于缺乏科学 的运动指导,使健身难以取得相应的效果。据市场调查显示,没有产品可以自动分析健身 运动并提供指导。而近年深度神经网络在人体姿态识别上已经取得了巨大的成功,针对这个现象,本文设计了一个基于 OpenCv 和 MediaPipe 中的 BlazePose 算法的 AI 健身教 练系统。该系统主要内容包括对于单人人体关键点的检测,关键点的连接,以及运动健 身关键点的角度变化展示。该 AI 健身教练系统可以实现从读入图片或者视频文件来处 理,显示出该运动健身的关键点的角度变化。
一、人体姿态识别的一些入门知识点
-
有没有人
-
人在哪里
-
这个人是谁
-
这个人此刻处于什么状态
-
这个人在当前一段时间里做什么
- 自上而下(Top-down)
- 首先检测人体,使用前置的目标检测网络标识出画面中的人体的边界框,HRnet()通过多分辨率融合以及保持高分辨率的方法极大的 提高了关键点的预测精度。由于Top-down在目标检测阶段就消除了大部分的背景,因此很少有背景噪点或其他人体的关键点,简化了关键点热图估计,但是在人体目标检测阶段会消耗大量的计算成本,并且不是端到端的算法
- 缺点:十分依赖人体姿态检测的结果(假如说有两个人靠的很近,有的时候会只得到一个方框信息,它的最终结果也会少一个人),算法速度与图片上人的数目成正比,假如说一张图有30个人,它要重复30次单人的人体估计,这样使得这个方法在复杂场景下变得十分缓慢
- 自下而上(Bottom-up)
- 首先预测图像中所有人体关键点位置,然后将关键点连接为不同的人体实例。
- 代表性工作有:
- DeepCut方法和DeeperCut方法开创性的将关键点关联问题表示为整数线性规划问题,可以有效解决,但是处理时间长达数小时。
- Openpose方法基本可以做到实时检测,其中的PAF组件用来预测人体不见,链接可能属于同一个人的关键点,PifPaf方法对该方法进一步拓展,提高了连接的准确度。
- Associative embeding方法将每个关键点映射一个识别对象所属的"标签",标签将每个预测的关键点与同一组的其他关键点直接关联,从而得到预测的人体姿态。
- PersonLab方法采用短距偏移提高关键点预测的精度,再通过贪婪解码和霍夫投票的方法分组,将预测的关键点联合为一个姿态估计实例。
- Bottom-up 普遍比 Top-down算法复杂度低,速度更快,而且这是端对端的算法。Top-down的精度相对来说会高一点。

二、Blazepose 算法简介
Demo的灵感起源于谷歌在CVPR2020年发布的一篇论文,Blazepose属于Bottom-up的一种类型,
这个算法的特征就在于整体速度得到了显著的提升,
blaze就是火焰,也就是说这个算法核心点更突出的是它的速率非常的快,而非准确性,相对于传统的openpose,fps是它的好几倍,准确度的差距也不是非常的大,就使得这个算法非常适用于今天的移动设备端的开发
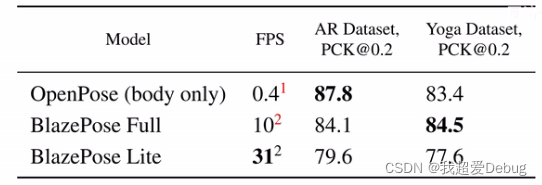
通过fps的比较可以明显看出Blazepose速率上的提升。
(pck@0.2是人体姿态检测的一个经典的指标,表示的是模型预测出来的点的坐标和真实的点坐标的欧氏距离如果小于整个人体躯干距离的百分之二十,判断为是预测对的)
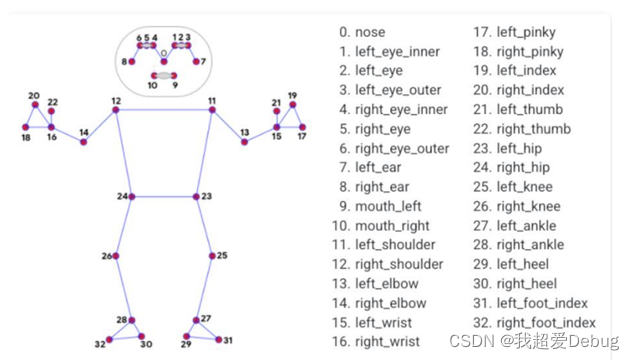
传统的coco数据集竞赛要求的是18个关键点,我们可以看到blazepose可以达到33个关键点,
这个文章的主要贡献点在于:
(1)新型的人体姿态跟踪方案;
(2)轻量化人体姿态估计网络。
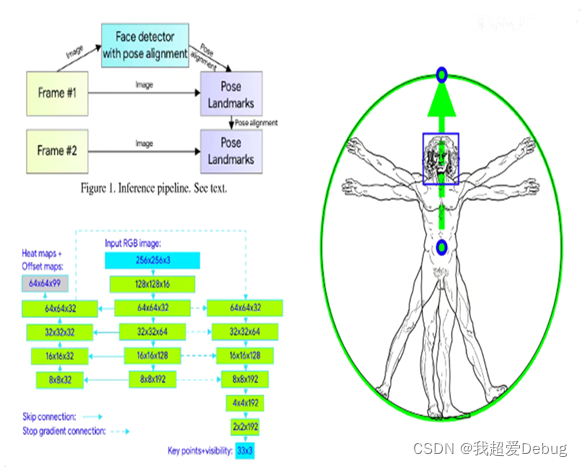
1.新型的人体姿态跟踪方法
把传统的人体姿态检测器升级成了人脸检测器,上一帧的图像进行人脸检测器后输出的数据可以作为下一帧图像的输入,这里也就是实现了人体姿态的追踪,只有当上一帧的图像中没有出现人脸时,就会重新进行检测,这会使得整体的速率更高
这个想法起源于达芬奇的《维特鲁威人》的启发图,通过人脸,人两肩的重点,两胯中点练成垂直的线段,以此画外接圆圈出人体的边界框。
2.轻量化人体姿态估计网络
网络模型结合了两种主流技术,
heat maps(热力图技术和回归编码器(regression encoder技术,
热力图就是说我输出的是一张灰度图像,大小和原来图像大小一致,但是像素代表着某一个关键点出现的概率,比如说在手肘部的位置,通过热力图可以看到标志着这里是肘部的关键点存在的区域与基于热图(heatmaps)的技术相反,基于回归(regression)的方法虽然对计算的要求较低且可扩展性较高,即使参数数量较少,堆叠式沙漏架构(stacked hourglass architecture) 也可以大大提高预测的准确性。使用编码器-解码器网络体系结构(encoder-decoder network architecture) 来预测所有关节的热图,随后是另一个直接回归到所有关节坐标的编码器。推理过程中我们可以舍弃热力图输出的图,而是直接获取关键点输出的结果,实线是跳连接(skip-connections,虚线是表示它不会顺着箭头反向传播回去,
真实预测中我们就不需要热力图输出的图,而是直接获取关键点输出的结果,这样就可以达到提升速度的目的
三、AI健身系统的实现
Media Pipe——Media Pipe是一个开源的跨平台框架,用于构建多模型机器学习管道。它可用于实现人脸检测、多手跟踪、头发分割、对象检测和跟踪等前沿模型。
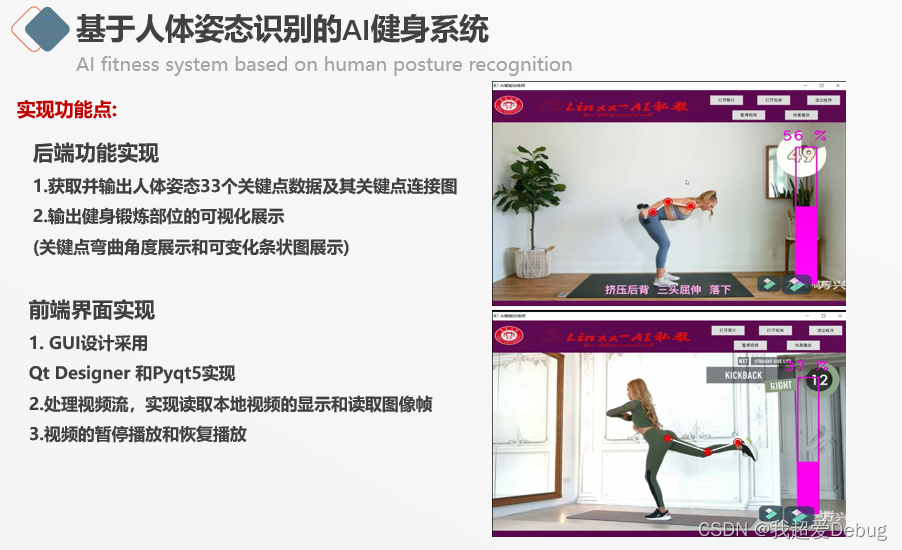
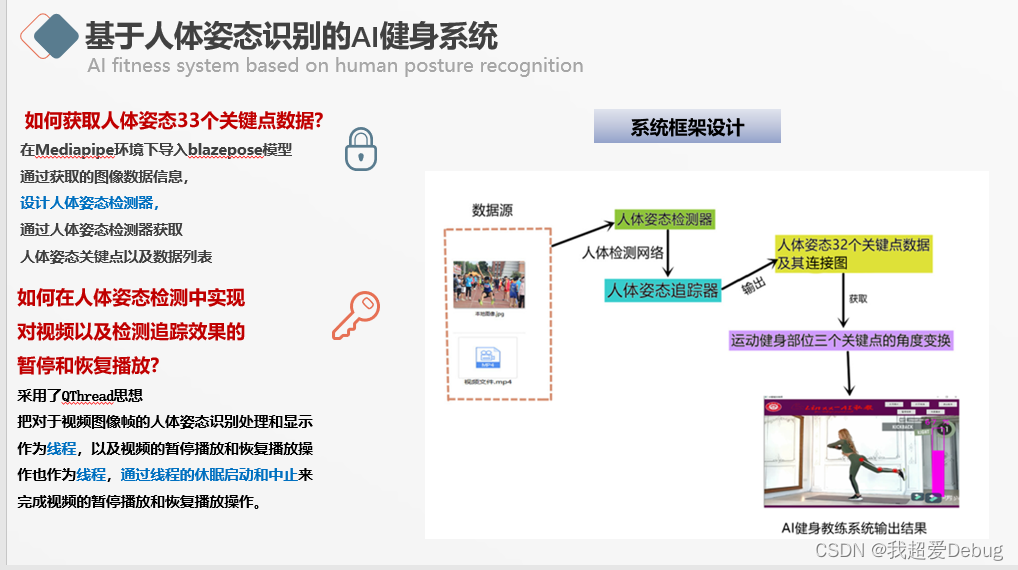
后端主要实现了获取并输出人体姿态33个关键点的数据,因为我做的是一个AI健身系统,就把要锻炼部位的关键点连接,在视觉上可以很明显的看到锻炼部位的弯曲角度,以及旁边的可变化条状图的展示,解决了传统健身模式上健身动作的力量施展不明确的问题
前端部分的GUI是用Qt Designer和pyqt5实现的,这里面的难点就在于这不是普通的视频的暂停播放和恢复播放,这里已经进行了人体姿态的关键点的识别和检测,以及相应的可视化,我们需要的是前后端同步实现暂停和恢复,
首先将视频抽帧,分为一帧一帧的图像。因为目标检测模块与二维人体姿态识别模块以图像作为输入,需要将视频处理为图像。在Mediapipe环境下导入的blazepose网络模型,通过设计人体姿态检测器来获取人体姿态的关键点正如我系统框架设计图所展示的,为了实现前后端同步的暂停和恢复,我用了QTread思想,把视频图像帧中的人体姿态识别和处理,视频的暂停播放和恢复播放也作为线程,通过对线程的休眠启动和中止来完成整个画面的的暂停和恢复播放
视频展示