一、主要方法
视频分类指将一段视频分类到预先制定类别集合中的某一个或多个。视频由空间维度和时间维度组成。包括静态图像特征,运动特征,音频特征,外部特征等。目前主要的方法有:双流网络,静态图像特征聚合,3D卷积以及基于transformer的视频分类。前三种方法前人已经做了很全面的总结不再赘述。经典论文如图所示。
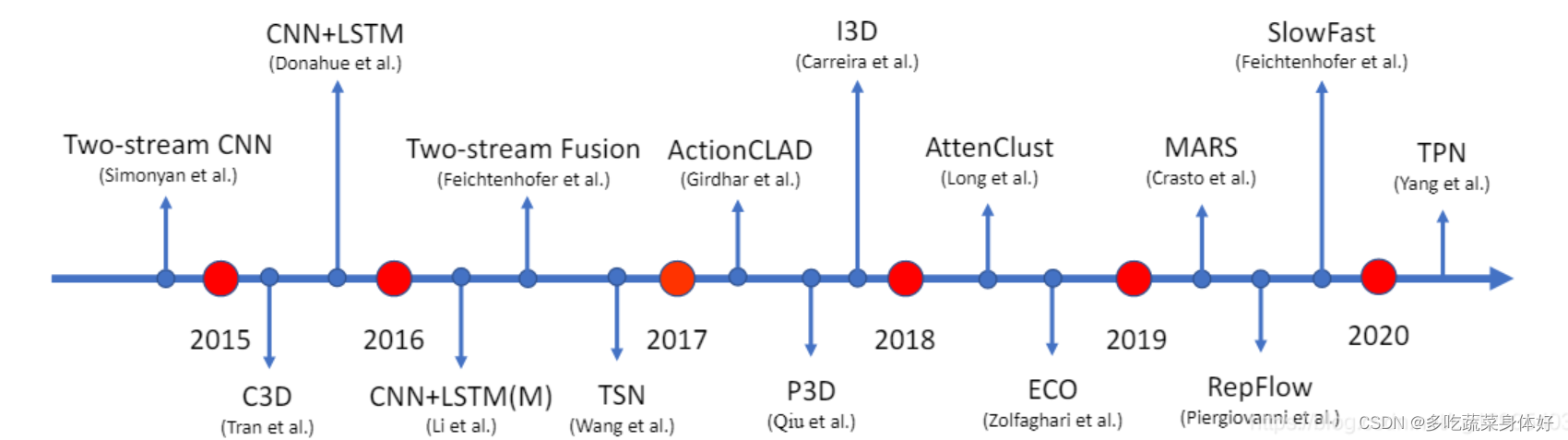
本文主要调研了基于transformer的视频分类方法。
二、基于transformer的视频分类
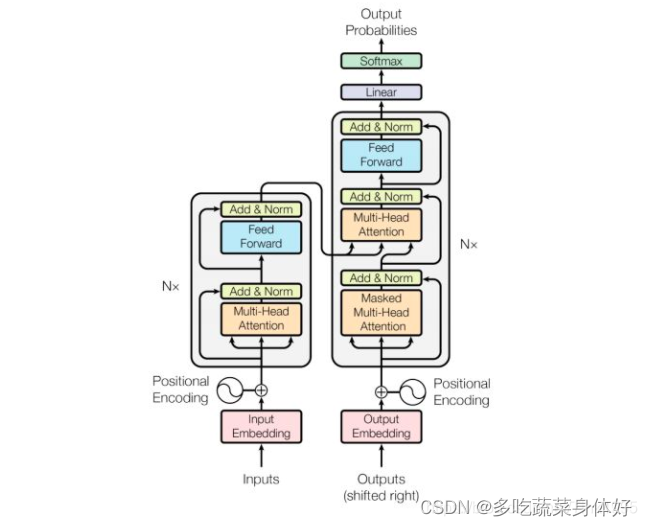
2.1、transformer结构
2.2、视频分类
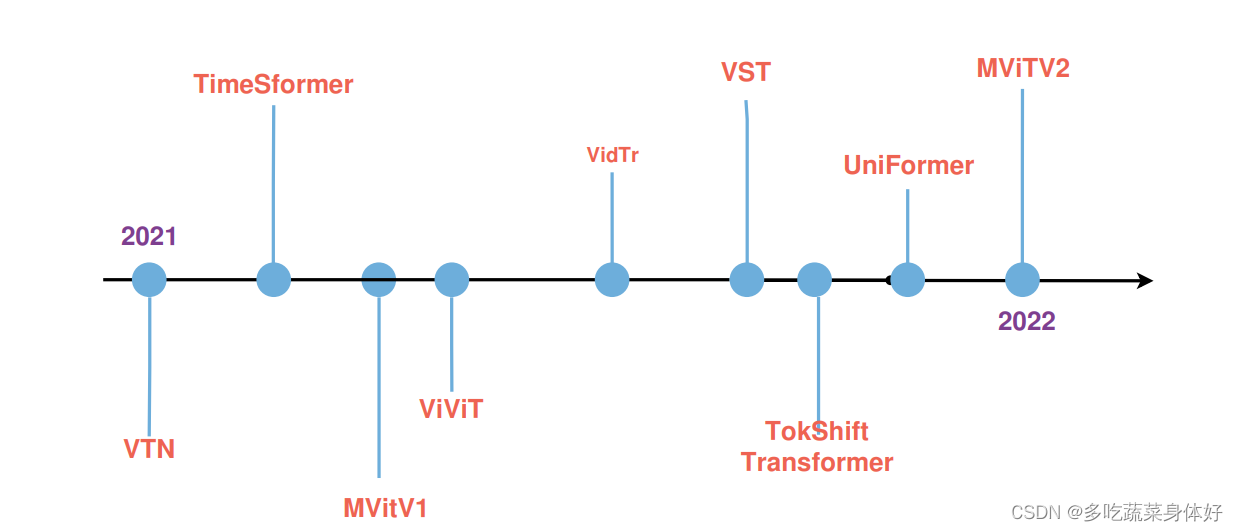
利用transformer进行视频分类任务是一个较新的研究方向,本文主要研究的视频分类方法如下图:(时间前后关系可能有点混乱)
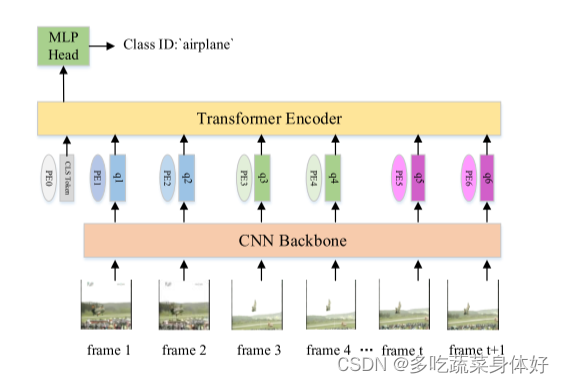
基于Transformer的视频分类方法基本框架如下图所示。具体流程是将视频的不同帧发送到 CNN 来提取特征。然后,将提取到的特征输入到 Transformer Encoder中。最后将编码后的特征输入到 MLP 头部,预测输入视频的标签。
2.2.1 VTN (Video Transformer Network) ICCV2021
首个提出将transformer用于视频分类的文章,为了解决使用3D网络计算量庞大的问题,提出使用2D网络架构来学习空间特征,并在随后的数据流中添加时间信息,在结果特征之上使用注意机制。感觉很像是CNN+LSTM算法把LSTM换成了Transformer。网络结构如下图:
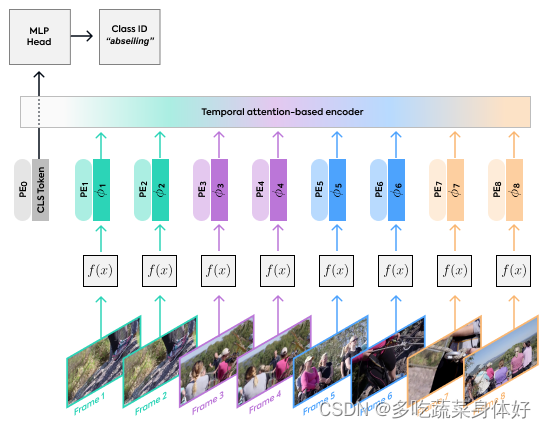
三个模块:
1、2D spatial feature extraction即F(X)
这里的f(x)可以是任何用于2D图像的网络,不论深浅、是否为预训练、基于卷积还是transformer、权重固定还是在训练中学习都可以。可以用CNN也可以用VIT等纯transformer。
论文中使用的:
ViT-B-VTN: 在ImageNet-21K上预训练, 12层,12个head
DeiT-B/BD/Ti-VTN:在ImageNet上预训练,12层,12个head
R50/101-VTN:在ImageNet上预训练,标准的2D ResNet-50 和 ResNet-101 网络
2、temporal-base encoder:
使用了 Longformer 结构,在inference可以一次性处理整个视频。它使用特征向量结合位置编码,在feature sequence前面加入了一个class token操作。使用与[CLS]分类标记相关的特征的最终状态作为视频的最终表示,并将其应用于给定的分类任务头。
3、classification MLP head
Longformer 的结果其实也是一个向量,最终需要通过FC进行分类。Longformer 的结果其实也是一个向量,最终需要通过FC进行分类。MLP包含两个线性层,Dropout,一个GELU非线性层。
2.2.2 TimeSformer CVPR2021
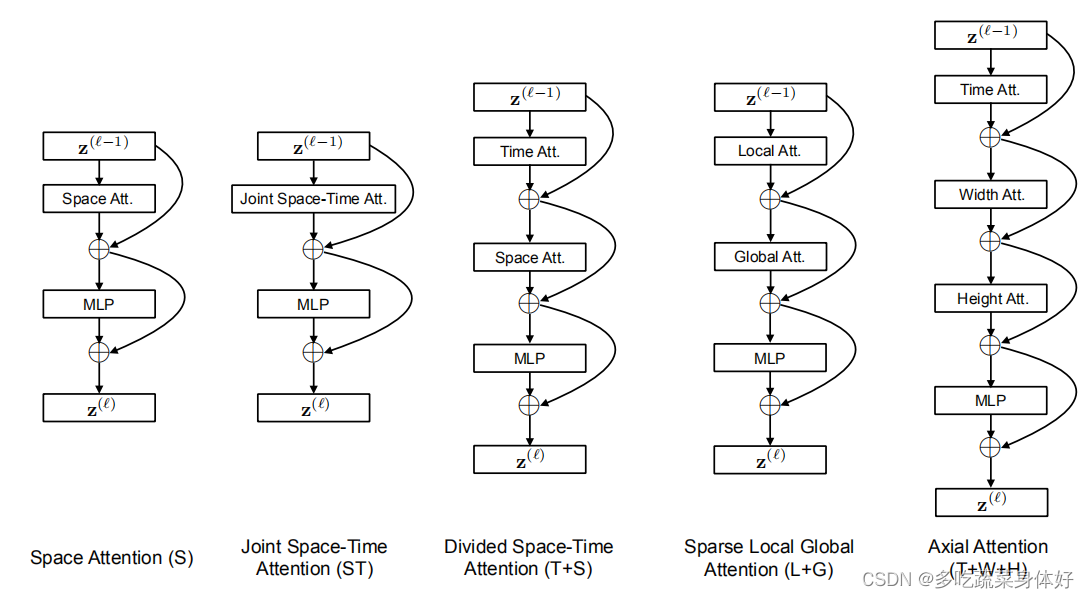
TimeSformer 是首个完全基于 Transformer 的视频架构。transformer处理单张图像简单来说是把图像分成一个一个的小patch,每一个patch当作一个token作为输入,直接送到transformer做分类.如果直接将VIT用于视频理解,就是取多帧,每一帧的图像都分成一个一个的小patch,之后也可以直接送入transformer,但这样的话输入的patch多了几倍,计算量难以接受。为了缓解此问题,TimeSformer通过两种方式减少了计算量:
1、将视频分解为不重复的帧。
2、采用了一种称为时间和空间分离注意机制的技术(时空分离注意力)。在时间注意力上,每个图像块仅关注在剩余帧的对应位置处提取的图像块。在空间注意力上,该图像块仅关注相同帧的提取图像块。(文章提出了几种基于时空容量(space-time volume)的可扩展自我注意设计结构。这其中最好的设计是“分散注意力(divided attention)”架构)
当使用时间注意力时,每个 patch(例如在下图中,蓝色的正方形)只与其他帧中相同空间位置的 patch(绿色正方形)进行比较。如果视频包含 T 帧,则每个 patch 只进行 T 次时间上的比较。当使用空间注意力时,每个 patch 仅与同一帧内的 patch(红色 patch)进行比较。因此,如果 N 是每帧中的 patch 数,则分割空间 – 时间注意力只对每个 patch 执行一共(T+N)次比较,而不是联合空间 – 时间注意力的方法所需的(T×N)次比较。此外,该研究发现与联合空间 – 时间注意力相比,分割空间 – 时间注意力不仅更有效,而且更准确。

2.2.3 MViTV1
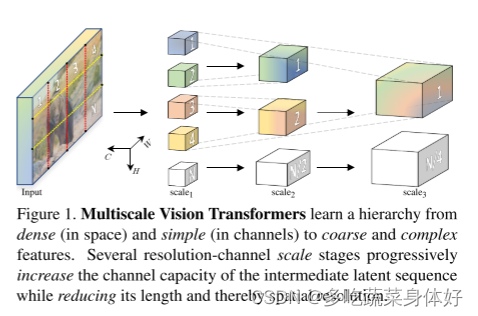
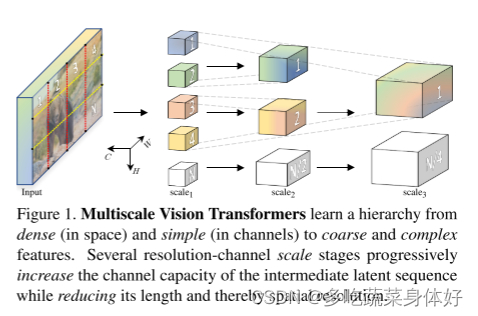
该文章首先给出了一个初步的结论,即在视觉任务中浅层主要作用高分辨率,提取low-level的特征, 而深层主要作用在空间分辨率没有那么高的但是更复杂的语义上,因此需要更多的通道去提取信息。
本文提出了用于视频和图像识别的多尺度视觉 Transformer,多尺度 Transformer 具有几个通道分辨率尺度阶段。从输入分辨率和较小的通道尺寸开始,这些阶段会在降低空间分辨率的同时分层扩展通道容量。这将创建一个多尺度的特征金字塔,其中早期的图层以高空间分辨率运行以对简单的低层视觉信息进行建模,而较深的图层则以空间粗糙但复杂的高维要素进行建模。
MViT不同stage具有不同的分辨率,最开始输入分辨率最大同时通道数最少,随着网络加深,扩展通道容量的同时降低空间分辨率,这样就搭建了一个多尺度的特征金字塔,早期基于较高分辨率可以建模简单的低级视觉信息,随着网络加深虽然空间信息较为粗糙但是却获得了更为复杂、维度更高的特征。结构如下图,右图为MHPA:
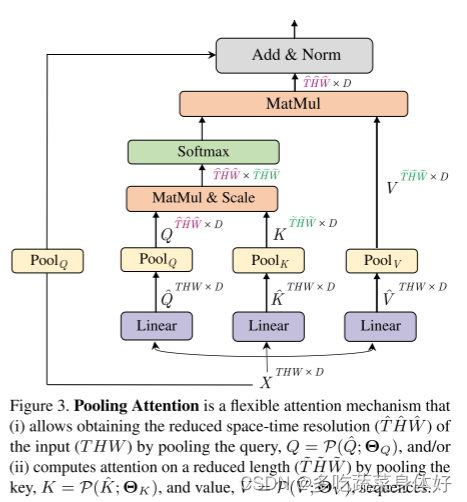
本文实现的核心是借鉴了CNN中的池化操作,MViT架构的核心是stage,每一个stage包含多个特定时-空分辨率和通道维度的Transformer block,MViT会逐渐扩展通道维度同时通过池化操作来降低输入分辨率。
MViT Transformer block的整体架构,建立在MHPA和MLP层的基础上。MHPA负责空间降采样,MLP负责通道扩展。
MViT的优势在于在视频的多尺度模型中包含隐式的时间偏置信息,因为ViT在训练视频Trabsformer模型时在打乱帧的视频上测试发现性能没有衰减,这说明ViT没有有效学习到时间信息,而是严重依赖于图像内容;而本文的MViT进行同样测试时可以看到有显著的性能下降,说明充分学习到了时间信息。
这篇论文也太难以理解了,存一下学习视频和参考博客:https://bit.ly/3L5avhT
[论文简析]MViT: Multiscale Vision Transformers[2104.11227]_哔哩哔哩_bilibili https://bit.ly/3er85hb
2.2.4 Vivit: A video vision transformer
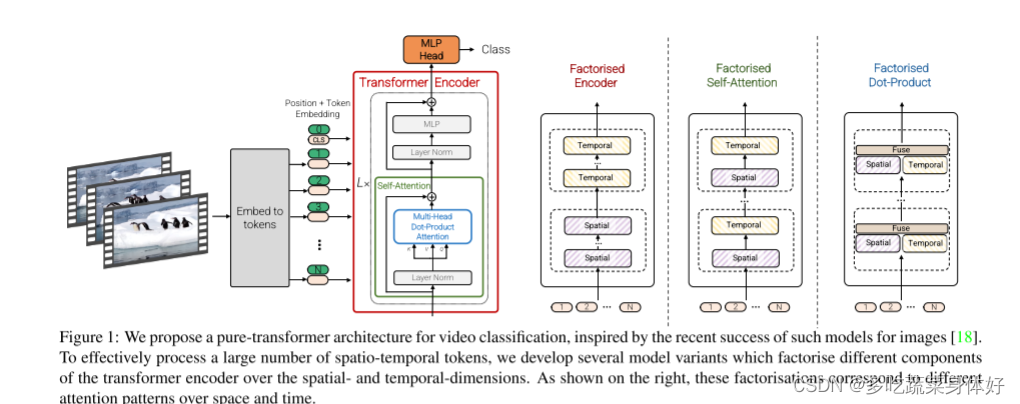
提出了四种用于视频分类的纯Transformer模型。共四种transformer结构:1.直接复用transformer 2.Factorised encoder 3.Factorised self-attention 4.Factorised dot-product attention。
1. spatial-temporal attention这种方式和vit的设置一样,把视频采样得到的时空token一起输入transformer encoder,即时间空间维度上的token会一起联合做self-attetion。这样能够最大程度上地融合时间信息,但是计算量会很大。
2. Factorised encoder这种方式把encoder划分成了两个部分,前一个部分是对同一帧图像内的token进行空间上的融合,后一部分encoder是对不同帧进行时间上的融合,这种”late-fusion”的方式大大减小了计算量
3. Factorised self-attention这个是在encoder内部进行时空划分,多头自注意力机制被分解为时间注意力+空间注意力,先后顺序没有关系。
4. Factorised dot-product attention最后这类2,3两种有一样计算复杂度,但是分解操作在MSA中操作。
两种token的构建方法:
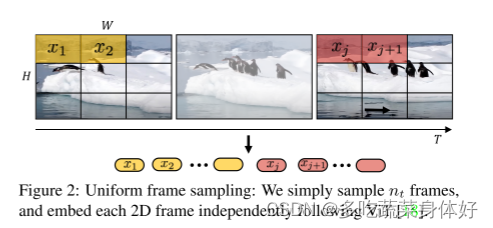
1、Uniform frame sampling :从输入视频片段中均匀采样帧,使用与ViT相同的方法独立嵌入每个2D帧,并将所有这些token concat到一起。
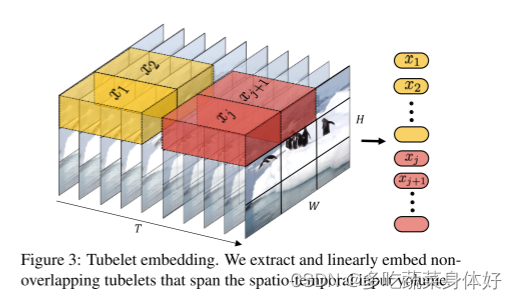
2、Tubelet embedding:1中的均匀采样方式是2D的,Tubelet embedding可看做在3D层面上提取特征,定义非重叠的tube同时在空间和时间维度上进行线性映射,tubelet embedding融合了时间维度的帧信息,即这种构建方式获取的序列token同时融合了空间和时间信息。
即本文有两种输入方式,一种是最直接的方式:在输入的clip中均匀采样n帧然后将每帧按照vit中的方式划分成一个个patch输入embbedding网络生成patch embbedding再concatenate在一起。另一种输入方式是:时空同时采样取出一个cube,然后把这个3D cube经过投影网络映射为patch embedding.这样的方式能够更好地把时空信息融合在一起。
参考博客:https://baijiahao.baidu.com/s?id=1719371930280255086&wfr=spider&for=pc
2.2.5 Vidtr
传统基于卷积的视频分类建模方法一般是先提取图像特征,再对多帧图像特征进行聚合得到视频特征。考虑到 Transformer 模型在时序数据建模上具有先天优势,再加上 ViT 在图像分类领域上的成功,因此作者提出了 VidTr 这一基于 Transformer 直接对视频像素级数据进行时空特征提取的分类模型。作者首先提出了 vanilla video transformer 直接利用 ViT 对视频进行像素级数据建模,但存在内存消耗过大的问题,因此借鉴了R(2+1)D模型中3D卷积空域和时域分离执行的思想,提出了 separable-attention 分别执行 spatial & temporal attention,spatial attention 能够关注到信息量更大的patches,temporal attention 能够减少视频数据中存在的过多冗余。
结构如下图:
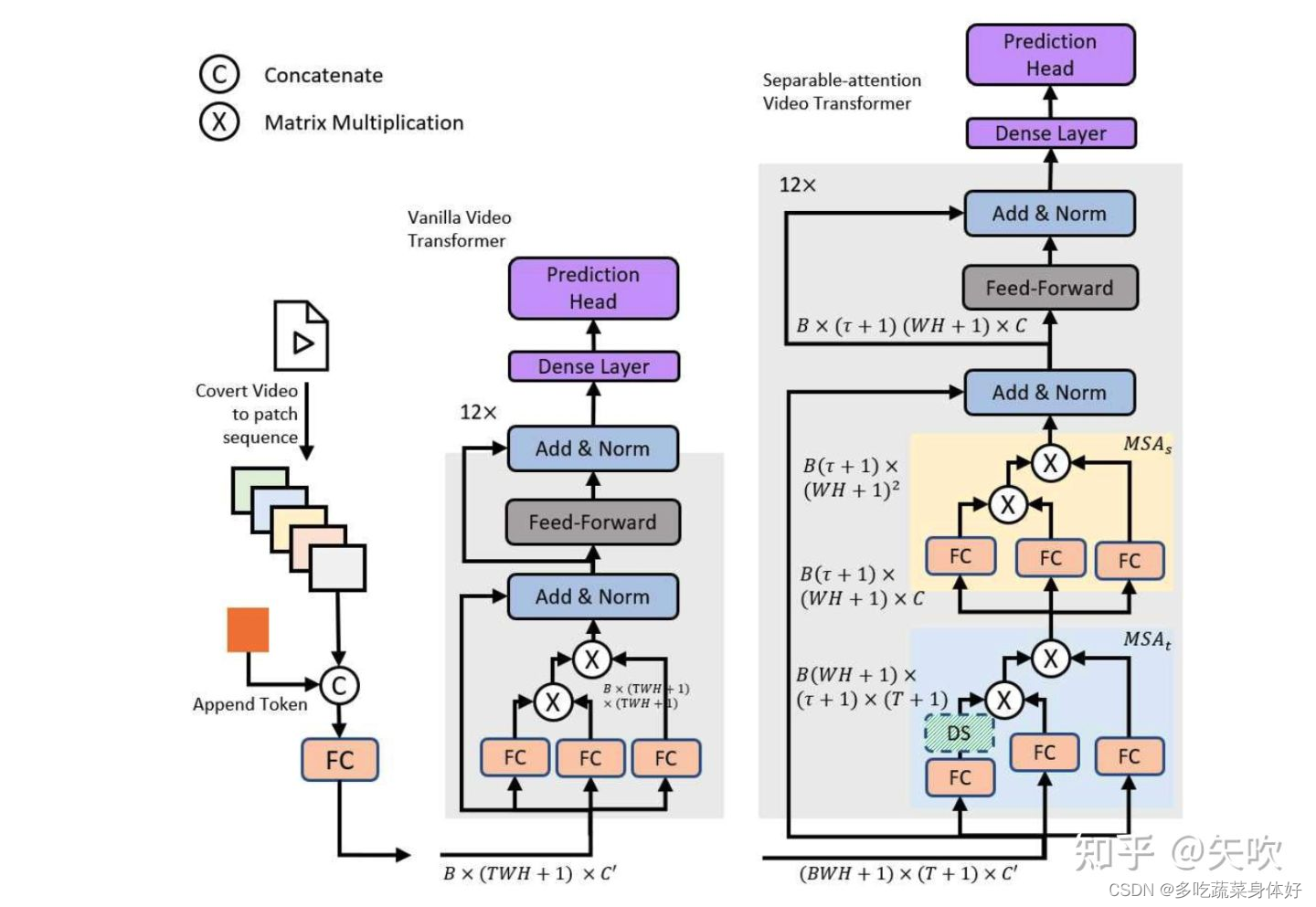
一个基础的 transformer encoder 结构由两部分组成:MSA(multi-headed self-attention)和MLP(multi-layer perceptron)。VidTr中作者将传统的 MSA 结构解耦为 spatial 和 temporal 进行两阶段计算。具体做法是将一维的 embedding 序列 分解为二维的 embedding 序列 ,同时增加对应空间的分类 token 和对应时间的分类 token,两种 token 的交集 intersection 用于最终的视频分类。首先在每个 spatial location 独立进行 temporal attention 的计算得到,然后对其进行 spatial attention 的计算。
2.2.6 TokShift Transformer
这篇网上一篇中文博客也没有,很难看懂。但无非也是提出了新的transformer结构。所提出的 Token Shift Module 使用零参数和零 FLOP,对每个 Transformer 编码器内的时间关系进行建模。
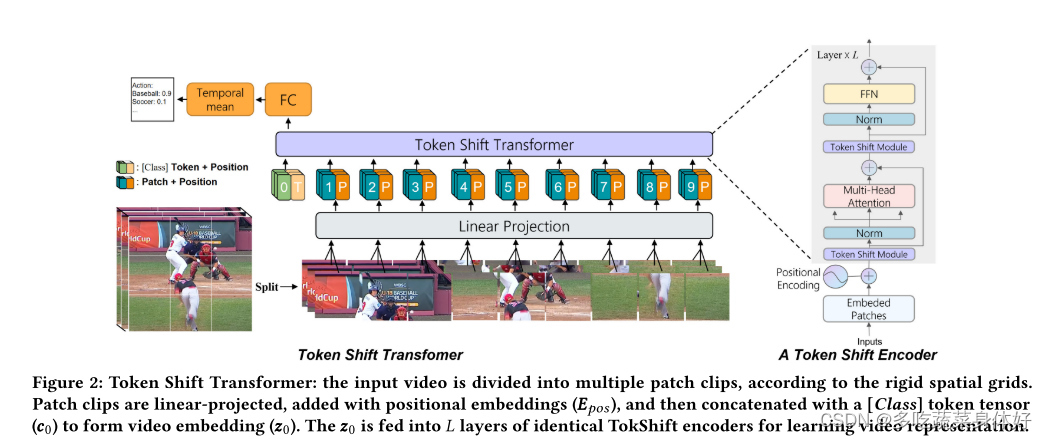
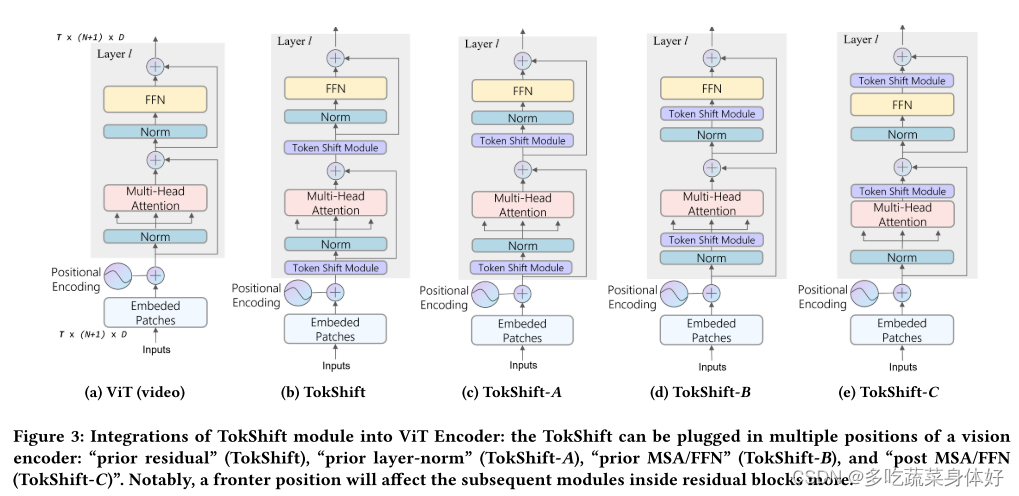
2.2.7 MViTV2
本文提出的多尺度 ViT (MViTv2) 首先延续了 MViTv1 的池化注意力模型,并在相对位置 embedding 上做了改进。其次,提出了 Hybrid window attention (Hwin),其实就是将池化注意力和窗口注意力进行有效结合。
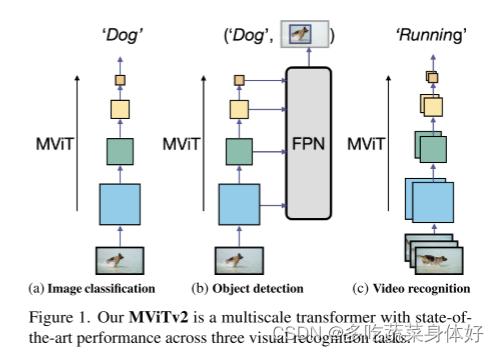
改进的 MViT 架构包含以下内容:
- 创建强大的 baselines,沿着两个坐标轴的方向改善池化注意力:(a) 平移不变位置 embeddings,使用分解的位置距离在 Transformer block 中注入位置信息;(b) 一个残差池化(residual pooling)连接,用于补偿注意计算中池化跨距(pooling stride)的影响。
- 利用改进的 MViT 结构,采用了一个标准的密集预测框架:Mask R-CNN [36] with Feature Pyramid Networks (FPN) [53],并将其应用于目标检测和实例分割。本文研究了 MViT 是否可以通过集中注意力来克服计算和内存成本来处理高分辨率的视觉输入。
2.2.8 Video Swin Transformer CVPR 2022
Video Swin Transformer 是 Swin Transformer 在视频领域的扩展,在视频 Transformer 中引入局部性的归纳偏置。与之前的方法相比,即使使用时空分解也可以全局计算自注意力,因此可以获得更好的速度-准确度权衡。所提出的视频架构的局部性是通过调整为图像域设计的 Swin Transformer来实现的,同时继续利用预训练图像模型的力量。
Swin Transformer的最大特点是类似于CNN中的conv+pooling结构,在Swin Transformer中是Swin Transformer Block + Patch merging。通过多个stage,token数越来越少,每个token的感受野也会越来越大。同时,token数的递减以及window transformer计算使得计算量减少。
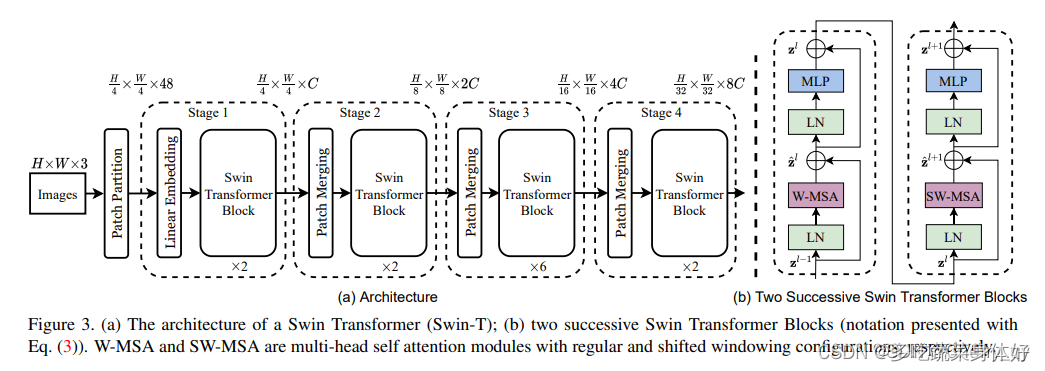
Swim Transformer主要包含三个阶段:image to token,model stages,head。
Image to token类似于VIT,直接将输入图像划分为互不重叠大小为4*4的图像块,然后利用线性层对图像块进行embedding,再加上position embedding。
Model stages类似于vgg或resnet结构,Model stages由多个重复的stage组成,每个model stag由Swin Transformer Block 和 Patch merging组成。随着网络的加深,Swin Transformer 可以提取较VIT更好的高层特征。Swin Transformer Block 由可以分为两部分,W-MSA and SW-MSA。MSA即为transformer 中的MSA(Multihead self attention)。在Swin Transformer中加入了window和shift window。Patch merging类似于max pooing,将4个patch合成一个新的patch,而后再利用线性层控制通道维度为2C。
Head:图像经过model stages 之后已经是可用的高层特征了,head部分就是根据任务进行计算就好,比如分类任务,可以直接用mlp进行分类。
Video Swin Transformer基本结构和Swin Transformer几乎完全一致,只是在计算时多了时间维度。Video Swin Transformer由三个部分组成:video to token, model stages,head。
Video to token 在image to token中,是将4×4的图像块作为一组。而在Video to token中,输入视频数据为T*H*W*3,首先通过3D Patch Partition得到T/2*H/4*W/4个尺寸为2 * 4 * 4 * 3 的3D Patch。而后再进行线性embedding以及position embedding。后续处理中时间维度是不变的。
Model stages 每个model stage包括Video Swin Transformer Block 和 Patch merging组成。Video Swin Transformer Block可以分为两部分,Video W-MSA 和 Video SW-MSA。这里相当于将Swin Transformer Block计算由二维拓展到三维。滑动窗口是3D的。
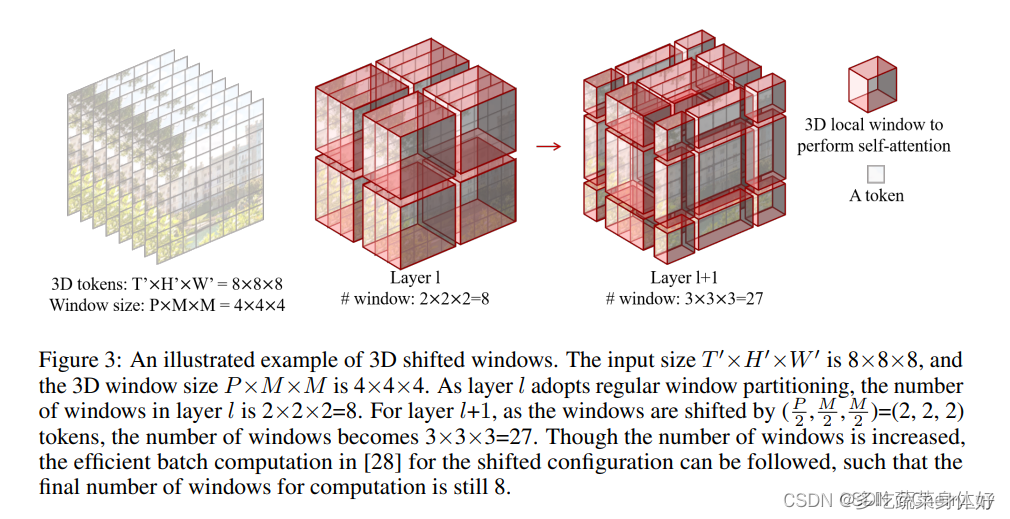
Patch merging类似于max pooing,将相邻(2*2窗口内)token特征合并,而后再利用线性层降维。例如second stage的线性层将每个token 4C维度的特征映射到 2C 维度。这里每次进行patching merging,视频帧数是不变的。
Head:在经过Model stages之后,得到了多帧数据的高维特征,用于视频分类时需要进行简单的帧融合(average),作者代码中用的是I3D Head。
2.2.9 UniFormer ICLR2022
Unified transFormer (UniFormer)提出了一种整合3D卷积和时空自注意力机制的transformer结构,该结构能在计算量和精度之间取得平衡。不同于传统的transformer结构,论文中提出的relation aggregator分别处理 video redundancy and dependency,而不是在所有层都使用自注意力机制。在浅层,aggregator利用一个小的learnable matrix学习局部的关系,通过聚合小的3D邻域的token信息极大地减少计算量。在深层,aggregator通过相似性比较学习全局关系,可以灵活的建立远距离视频帧token之间的长程依赖关系。每个UniFormer block主要由三部分组成,动态位置编码DPE、多头关系聚合器MHRA)及Transformer必备的前馈层FFN。
文章出处登录后可见!