
>>>深度学习Tricks,第一时间送达<<<
目录
CVPR19 单幅图像超分辨率来了!!!
论文题目:Second-order Attention Network for Single Image Super-Resolution
代码地址:https://github.com/daitao/SAN
3.配置yolov5/yolov7_SOCA moudle.yaml文件
CVPR19 单幅图像超分辨率来了!!!
(一)前沿介绍
论文题目:Second-order Attention Network for Single Image Super-Resolution
论文地址:CVPR19 超分辨率
代码地址:https://github.com/daitao/SAN

基于CNN的超分辨方法虽然取得了最好的结果,但此类方法关注更宽或更深的结构设计,忽略了中间层特征之间的关系。基于此,本文提出了二阶注意力机制(SOCA)更好的学习特征之间的联系,此模块通过利用二阶特征的分布自适应的学习特征的内部依赖关系,SOCA的机制是网络能够专注于更有益的信息且能够提高判别学习的能力。此外,本文提出了一种非局部加强残差组结构能进一步结合非局部操作来提取长程的空间上下文信息。通过堆叠非局部残差组,本文的方法能够利用LR图像的信息且能够忽略低频信息。总体上该论文贡献主要有以下三点:
1.提出了用于图像超分辨的深度二阶注意力网络,
2.提出了二阶注意力机制通过利用高阶的特征自适应的调整特征,另外利用了协方差归一化的方法来加速网络的训练。
3.提出了非局部加强残差组NLRG结构构建网络,进一步结合非局部操作来提取空间上的上下文信息,并共享残差结构来学习深度特征,另外通过跳跃链接来过滤低频信息且简化了深层网络的训练。
1.SOCA moudle结构图
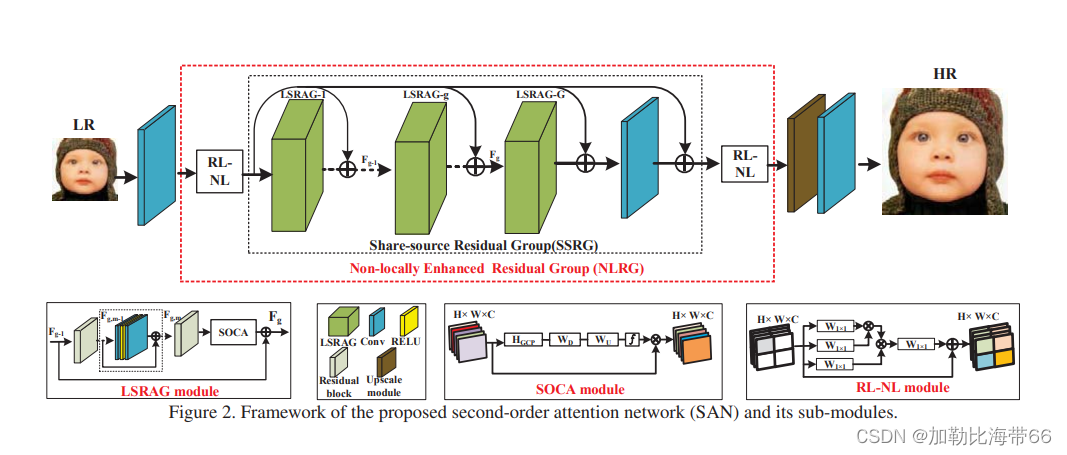
2.相关实验结果

(二)YOLOv5/YOLOv7改进之结合SOCA
改进方法和其他注意力机制一样,分三步走:
1.配置common.py文件
#SOCA moudle 单幅图像超分辨率
class Covpool(Function):
@staticmethod
def forward(ctx, input):
x = input
batchSize = x.data.shape[0]
dim = x.data.shape[1]
h = x.data.shape[2]
w = x.data.shape[3]
M = h*w
x = x.reshape(batchSize,dim,M)
I_hat = (-1./M/M)*torch.ones(M,M,device = x.device) + (1./M)*torch.eye(M,M,device = x.device)
I_hat = I_hat.view(1,M,M).repeat(batchSize,1,1).type(x.dtype)
y = x.bmm(I_hat).bmm(x.transpose(1,2))
ctx.save_for_backward(input,I_hat)
return y
@staticmethod
def backward(ctx, grad_output):
input,I_hat = ctx.saved_tensors
x = input
batchSize = x.data.shape[0]
dim = x.data.shape[1]
h = x.data.shape[2]
w = x.data.shape[3]
M = h*w
x = x.reshape(batchSize,dim,M)
grad_input = grad_output + grad_output.transpose(1,2)
grad_input = grad_input.bmm(x).bmm(I_hat)
grad_input = grad_input.reshape(batchSize,dim,h,w)
return grad_input
class Sqrtm(Function):
@staticmethod
def forward(ctx, input, iterN):
x = input
batchSize = x.data.shape[0]
dim = x.data.shape[1]
dtype = x.dtype
I3 = 3.0*torch.eye(dim,dim,device = x.device).view(1, dim, dim).repeat(batchSize,1,1).type(dtype)
normA = (1.0/3.0)*x.mul(I3).sum(dim=1).sum(dim=1)
A = x.div(normA.view(batchSize,1,1).expand_as(x))
Y = torch.zeros(batchSize, iterN, dim, dim, requires_grad = False, device = x.device)
Z = torch.eye(dim,dim,device = x.device).view(1,dim,dim).repeat(batchSize,iterN,1,1)
if iterN < 2:
ZY = 0.5*(I3 - A)
Y[:,0,:,:] = A.bmm(ZY)
else:
ZY = 0.5*(I3 - A)
Y[:,0,:,:] = A.bmm(ZY)
Z[:,0,:,:] = ZY
for i in range(1, iterN-1):
ZY = 0.5*(I3 - Z[:,i-1,:,:].bmm(Y[:,i-1,:,:]))
Y[:,i,:,:] = Y[:,i-1,:,:].bmm(ZY)
Z[:,i,:,:] = ZY.bmm(Z[:,i-1,:,:])
ZY = 0.5*Y[:,iterN-2,:,:].bmm(I3 - Z[:,iterN-2,:,:].bmm(Y[:,iterN-2,:,:]))
y = ZY*torch.sqrt(normA).view(batchSize, 1, 1).expand_as(x)
ctx.save_for_backward(input, A, ZY, normA, Y, Z)
ctx.iterN = iterN
return y
@staticmethod
def backward(ctx, grad_output):
input, A, ZY, normA, Y, Z = ctx.saved_tensors
iterN = ctx.iterN
x = input
batchSize = x.data.shape[0]
dim = x.data.shape[1]
dtype = x.dtype
der_postCom = grad_output*torch.sqrt(normA).view(batchSize, 1, 1).expand_as(x)
der_postComAux = (grad_output*ZY).sum(dim=1).sum(dim=1).div(2*torch.sqrt(normA))
I3 = 3.0*torch.eye(dim,dim,device = x.device).view(1, dim, dim).repeat(batchSize,1,1).type(dtype)
if iterN < 2:
der_NSiter = 0.5*(der_postCom.bmm(I3 - A) - A.bmm(der_sacleTrace))
else:
dldY = 0.5*(der_postCom.bmm(I3 - Y[:,iterN-2,:,:].bmm(Z[:,iterN-2,:,:])) -
Z[:,iterN-2,:,:].bmm(Y[:,iterN-2,:,:]).bmm(der_postCom))
dldZ = -0.5*Y[:,iterN-2,:,:].bmm(der_postCom).bmm(Y[:,iterN-2,:,:])
for i in range(iterN-3, -1, -1):
YZ = I3 - Y[:,i,:,:].bmm(Z[:,i,:,:])
ZY = Z[:,i,:,:].bmm(Y[:,i,:,:])
dldY_ = 0.5*(dldY.bmm(YZ) -
Z[:,i,:,:].bmm(dldZ).bmm(Z[:,i,:,:]) -
ZY.bmm(dldY))
dldZ_ = 0.5*(YZ.bmm(dldZ) -
Y[:,i,:,:].bmm(dldY).bmm(Y[:,i,:,:]) -
dldZ.bmm(ZY))
dldY = dldY_
dldZ = dldZ_
der_NSiter = 0.5*(dldY.bmm(I3 - A) - dldZ - A.bmm(dldY))
grad_input = der_NSiter.div(normA.view(batchSize,1,1).expand_as(x))
grad_aux = der_NSiter.mul(x).sum(dim=1).sum(dim=1)
for i in range(batchSize):
grad_input[i,:,:] += (der_postComAux[i] \
- grad_aux[i] / (normA[i] * normA[i])) \
*torch.ones(dim,device = x.device).diag()
return grad_input, None
class Triuvec(Function):
@staticmethod
def forward(ctx, input):
x = input
batchSize = x.data.shape[0]
dim = x.data.shape[1]
dtype = x.dtype
x = x.reshape(batchSize, dim*dim)
I = torch.ones(dim,dim).triu().t().reshape(dim*dim)
index = I.nonzero()
y = torch.zeros(batchSize,dim*(dim+1)/2,device = x.device)
for i in range(batchSize):
y[i, :] = x[i, index].t()
ctx.save_for_backward(input,index)
return y
@staticmethod
def backward(ctx, grad_output):
input,index = ctx.saved_tensors
x = input
batchSize = x.data.shape[0]
dim = x.data.shape[1]
dtype = x.dtype
grad_input = torch.zeros(batchSize,dim,dim,device = x.device,requires_grad=False)
grad_input = grad_input.reshape(batchSize,dim*dim)
for i in range(batchSize):
grad_input[i,index] = grad_output[i,:].reshape(index.size(),1)
grad_input = grad_input.reshape(batchSize,dim,dim)
return grad_input
def CovpoolLayer(var):
return Covpool.apply(var)
def SqrtmLayer(var, iterN):
return Sqrtm.apply(var, iterN)
def TriuvecLayer(var):
return Triuvec.apply(var)
class SOCA(nn.Module):
def __init__(self, channel, reduction=8):
super(SOCA, self).__init__()
self.max_pool = nn.MaxPool2d(kernel_size=2)
self.conv_du = nn.Sequential(
nn.Conv2d(channel, channel // reduction, 1, padding=0, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(channel // reduction, channel, 1, padding=0, bias=True),
nn.Sigmoid()
)2.配置yolo.py文件
加入SOCA moudle模块。
3.配置yolov5/yolov7_SOCA moudle.yaml文件
添加方法灵活多变,Backbone或者Neck都可。示例如下:
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, C3, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[-1, 1, SOCA, [1024]],
[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
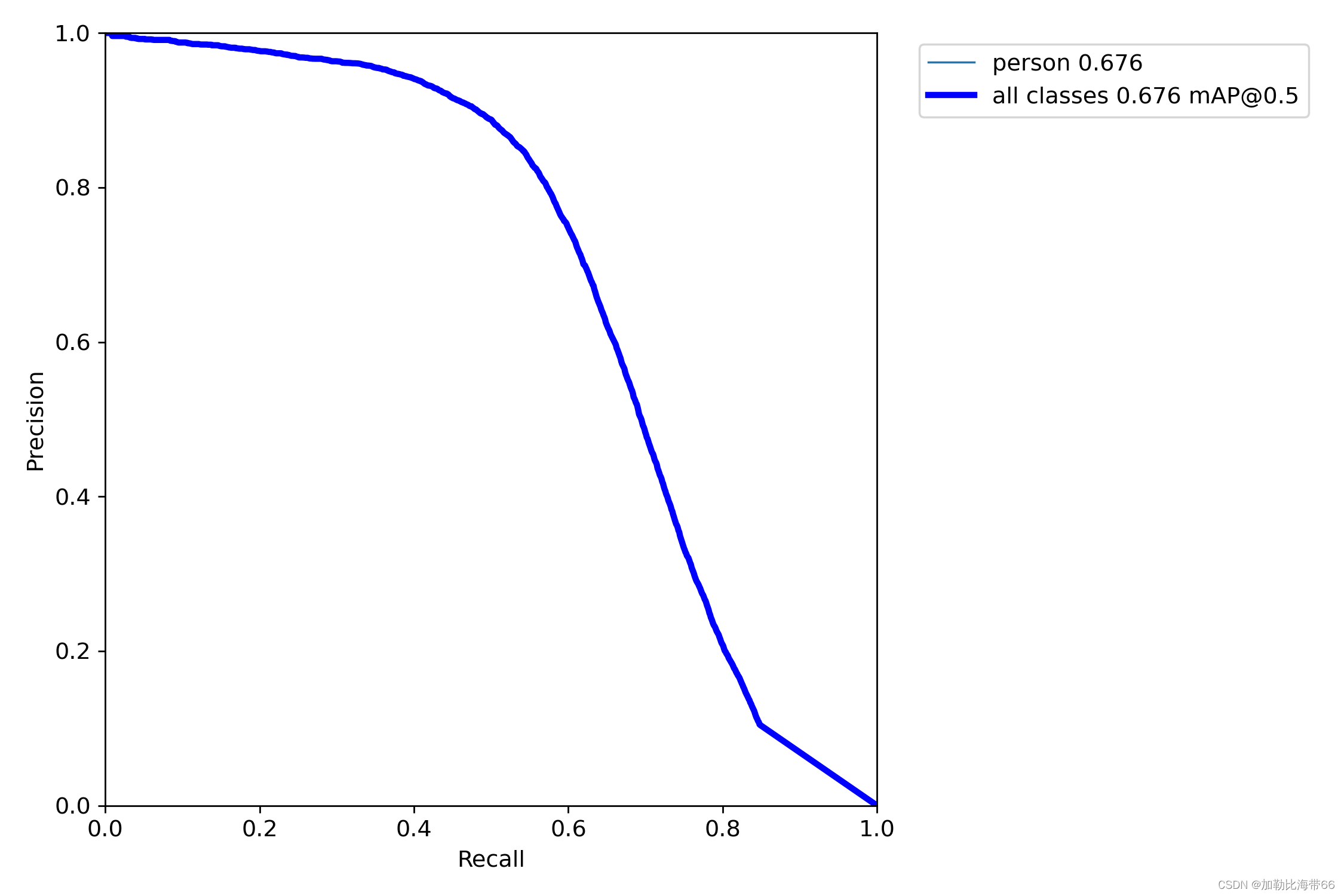
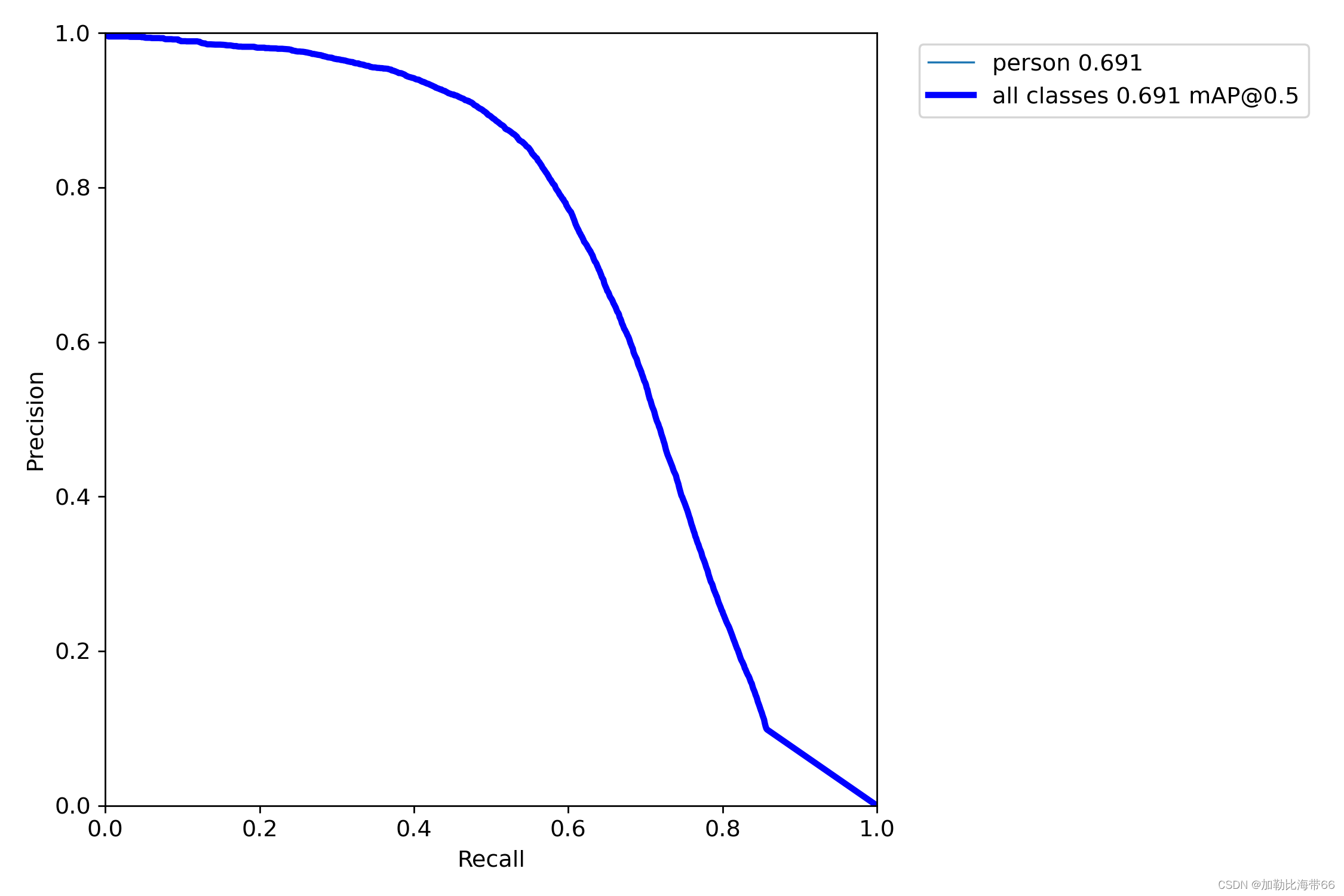
]💡PS:来自粉丝小伙伴的实验对比图~👇👇👇
①实验前:
②实验后:
关于算法改进及论文投稿可关注并留言博主的CSDN/QQ
>>>一起交流!互相学习!共同进步!<<<
文章出处登录后可见!
已经登录?立即刷新